"我不断地告诉大家,未来十年最热门的职业是统计学家。很多人认为我是开玩笑, 谁又能想到计算机工程师会是20世纪90年代最诱人的职业呢?如何解释数据、处理数据、从中抽取价值、展示和交流数据结果,在未来十年将是最重要的职业技能,甚至是大学,中学,小学的学生也必需具备的技能,因为我们每时每刻都在接触大量的免费信息,如何理解数据、从中抽取有价值的信息才是其中的关键。这里统计学家只是其中的一个关键环节,我们还需要合理的展示数据、交流和利用数据。我确实认为,能够从数据分析中领悟到有价值信息是非常重要的。职业经理人尤其需要能够合理使用和理解自己部门产生的数据。"
--McKinsey Quarterly,2009年1月
简介部分,作者介绍了自己早年为什么对机器学习感兴趣,后期的学习过程,以及对机器学习应用在工业界的客观态度。虽然本书出版于12年初,作者的灵感来源于10年前的一篇论文 Top 10 Algorithms in Data Mining ,但本书的许多实战应用依然是不过时,作为入门书籍足足够够。
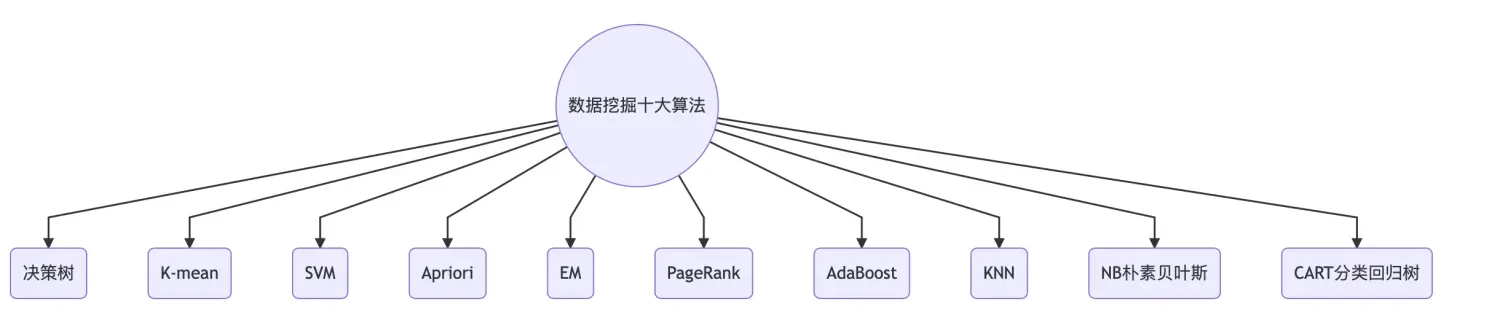
数据挖掘十大算法
机器学习实战 主要分为4个部分,分类 、回归预测 、无监督学习 、其他工具。
对于前两章,在接下来我会侧重于实践部分,提炼方法论;对于后两章,由于目前工业界推荐算法发展迅猛,可能会叠加一些别的书籍一起看。进度应该会慢一些,外援需求也多一些( '-ωก̀ ) 希望我不要半途而废呀
代码地址
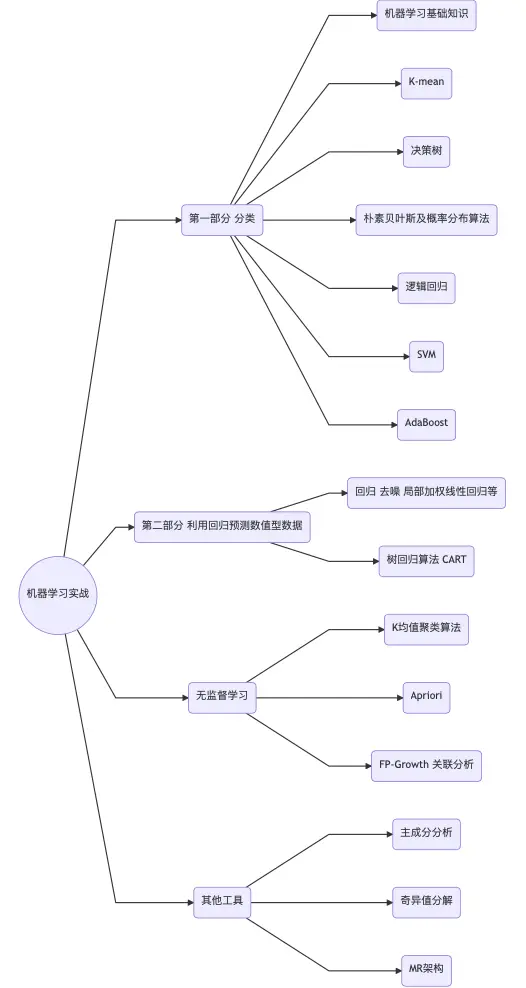
本书结构
一、分类
机器学习基础
@作者 机器学习能让我们自数据集中受到启发,换句话说,我们会利用计算机来彰显数据背后的真实含义,这才是机器学习的真实含义。
什么是机器学习?
机器学习就是把无序的数据转换成有用的信息。
什么是监督学习?
预测目标变量的分类信息,主要分为分类 和回归两类
如何区分监督学习,无监督学习?
知乎@王丰
是否有监督(supervised),就看输入数据是否有标签(label)。输入数据有标签,则为有监督学习,没标签则为无监督学习。
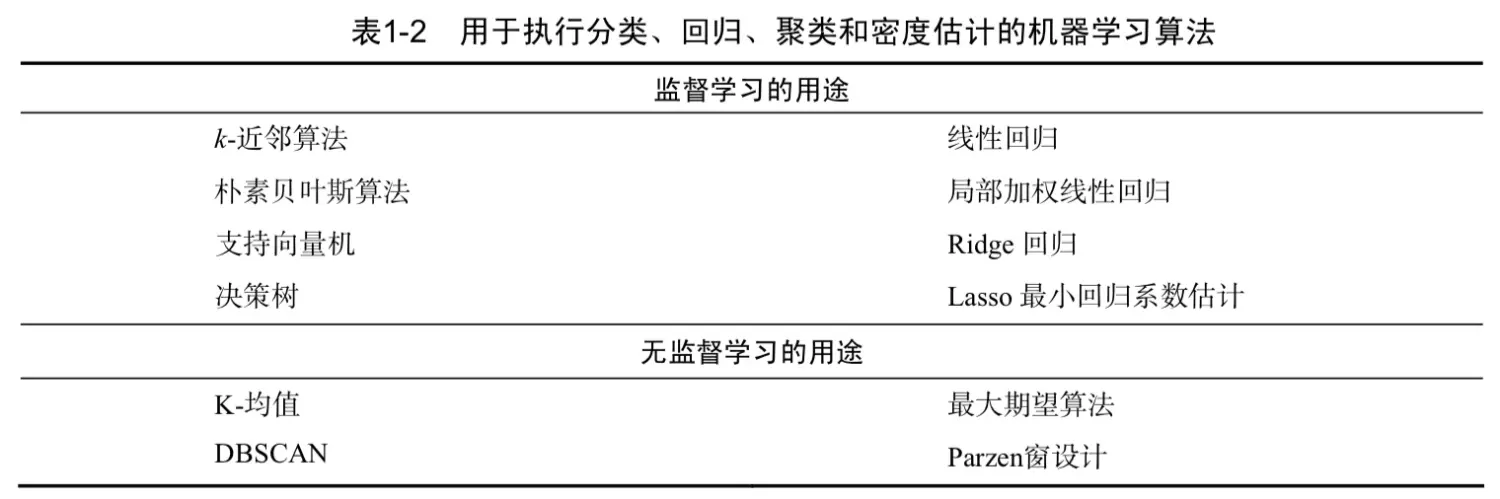
属性/特征挑选tips
通常的做法是测量所有可测属性,而后再挑选出重要部分。
如何测试机器学习算法的效果?
通常使用两套独立的样本集:训练数据和测试数据。当机器学习程序开始运行时,使用训练样本集作为算法的输入,训练完成之后输入测试样本。输入测试样本时并不提供测试样本的目标变量,由程序决定样本属于哪个类别。比较测试样本预测的目标变量值与实际样本类别之间的差别,就可以得出算法的实际精确度。
知识表示
某些算法可以产生很容易理解的知识表示,而某些算法的知识表示也许只能为计算机所理解。知识表示可以采用规则集的形式,也可以采用概率分布的形式,甚至可以是训练样本集中的一个实例。在某些场合中,人们可能并不想建立一个专家系统,而仅仅对机器学习算法获取的信息感兴趣。此时,采用何种方式表示知识就显得非常重要了。
如何选择合适的算法?
首先要考虑机器学习算法的目的,如果想要预测目标变量的值,则可以选择监督学习算法, 否则可以选择无监督学习算法。
- 确定选择监督学习算法之后,需要进一步确定目标变量类型,如果目标变量是离散型,如是/否、1/2/3、A/B/C或者红/黄/黑等,则可以选择分类器算法;如果目标变量是连续型的数值,如0.0100.00、-999999或者+∞~-∞等,则需要选择回归算法。
- 如果不想预测目标变量的值,则可以选择无监督学习算法。进一步分析是否需要将数据划分 为离散的组。如果这是唯一的需求,则使用聚类算法;如果还需要估计数据与每个分组的相似程度,则需要使用密度估计算法。
其次 需要考虑数据问题。主要应该了解数据的以下特征:特征值是离散型变量还是连续型变量,特征值中是否存在缺失的值,何种原因造成缺失值,数据中是否存在异常值,某个特征发生的频率如何(是否罕见得如同海底捞针),等等。充分了解上面提到的这些数据特性可以缩短选择机器学习算法的时间。
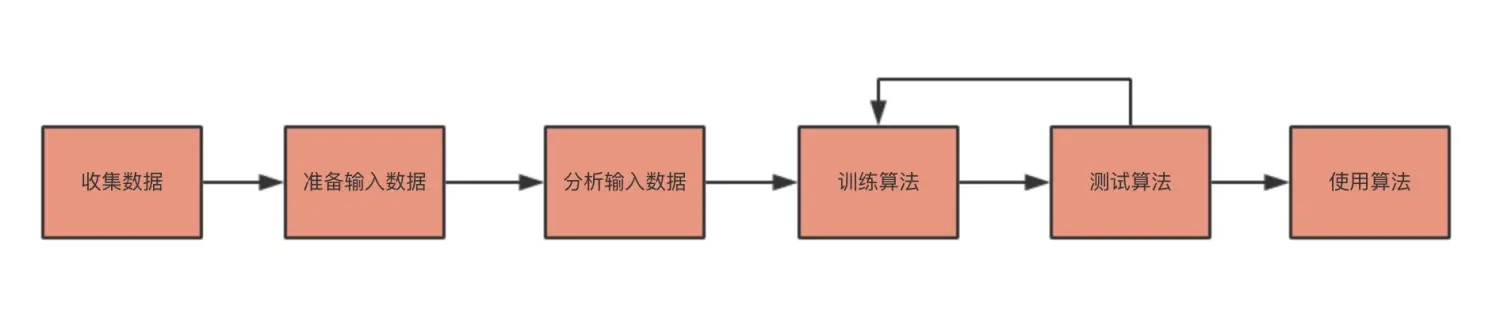
如何开发机器学习?
开发机器学习的的步骤
一点点小感想:由于初版时间过早,作者使用的数据格式主要是List,而不是现在大热的dataframe,后面上手的时候,应该会改写作者的代码,改为dataframe格式的
最后编辑于:2024-10-27 15:05:08
© 著作权归作者所有,转载或内容合作请联系作者

喜欢的朋友记得点赞、收藏、关注哦!!!