一、上下文
从前面的博客,我们已经了解了Kafka的设计思想、常用命令、参数配置、示例代码。下面我们从源码的角度来看下Kafka的生产者的内部细节。源码下载链接:https://downloads.apache.org/kafka/3.8.0/kafka-3.8.0-src.tgz
二、构建KafkaProducer
KafkaProducer注释说明
producer是一个将记录推送到Kafka集群的客户端
producer是线程安全的,且跨线程共享单个生产者实例通常比拥有多个实例更快。
它有一个缓冲内存池和一个后台I/O线程组成,缓冲内存池保存尚未传输到服务器的记录,后台I/O线程负责将这些记录转换为requests并将其传输到集群。使用后不关闭将泄漏这些资源。
send(ProducerRecord) send() 是异步执行的,调用时,它会将记录添加到待处理记录发送的缓冲区中,并立即返回。这允许producer将单个记录分批处理以提高效率。
acks配置控制着请求被视为完成的标准。默认设置"all"将导致阻止记录的完整提交,这是最慢但最持久的设置。
如果请求失败,producer可以自动重试,重试次数默认为:Integer.MAX_VALUE。建议使用delivery.timeout.ms来控制重试行为。
producer为每个分区维护一个缓冲区,来缓存未发送记录。这些缓冲区的大小由batch.size配置指定。
默认情况下,即使缓冲区中有额外的未使用空间,也可以立即发送缓冲区中的数据。如果你想减少请求的数量,你可以将linger.ms设置为大于0的值。这将指示producer在发送请求之前等待该毫秒数,希望一个批次可以传输更多的记录。这类似于TCP中的Nagle算法。
buffer.memory控制producer可用于缓冲的内存总量。如果记录的发送速度超过了它们传输到broker的速度,那么这个缓冲空间将耗尽。当缓冲区空间用尽时,其他发送请求将被阻止。阻塞时间的阈值由max.block.ms决定,超过该阈值后,它将抛出TimeoutException。
key.serializer和value.serializer指示如何将用户提供的key和value对象及其ProducerCrecord转换为字节。
从Kafka 0.11开始,KafkaProducer支持另外两种模式:幂等生产者和事务生产者。幂等生产者将Kafka的交付语义从至少一次交付增强到精确一次交付。特别是生产者重试将不再引入重复。事务生产者允许应用程序以原子方式向多个分区(和主题!)发送消息。
从Kafka 3.0开始,enable.idmopotence配置默认为true。启用幂等性时,重试配置将默认为Integer.MAX_VALUE,acks将默认为all。没有提供API对等幂生成器的更改,因此不需要修改现有的应用程序来利用这一特性。
为了利用幂等生产者,必须避免应用程序级的重发,因为这些重发无法进行重复数据消除。因此,如果应用程序启用幂等性,建议不设置重试配置,因为它将默认为Integer.MAX_VALUE。此外,如果send(ProducerRecord)在无限次重试后仍返回错误(例如,如果消息在发送前在缓冲区中过期),则建议关闭生产者并检查最后生成的消息的内容,以确保其不重复。最后,生产者只能保证在单个会话中发送的消息的幂等性。
要使用事务生产者和其API,必须设置transaction.id属性。如果设置了transactional.id,幂等性将与幂等性所依赖的生产者配置一起自动启用。此外,事务中包含的topic应配置为持久性。特别是,replicay.factor应至少为3,这些topic的min.insync.rexplications应设置为2。最后,为了从端到端实现事务保证,consumer也必须配置为只读取已提交的消息。
transactional.id的目的是在单个生产者实例的多个会话之间实现事务恢复。它通常来源于分区的、有状态的应用程序中的分片标识符。因此,对于在分区应用程序中运行的每个生产者实例,它应该是唯一的。
所有新的事务API都是阻塞的,并在失败时抛出异常。下面的示例说明了如何使用新的API。
java
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("transactional.id", "my-transactional-id");
Producer<String, String> producer = new KafkaProducer<>(props, new StringSerializer(), new StringSerializer());
producer.initTransactions();
try {
producer.beginTransaction();
for (int i = 0; i < 100; i++)
producer.send(new ProducerRecord<>("my-topic", Integer.toString(i), Integer.toString(i)));
producer.commitTransaction();
} catch (ProducerFencedException | OutOfOrderSequenceException | AuthorizationException e) {
//我们无法从这些异常中恢复,因此我们唯一的选择是关闭生产商并退出。
producer.close();
} catch (KafkaException e) {
//对于所有其他异常,只需中止事务并重试。
producer.abortTransaction();
}
producer.close();
}正如示例中暗示的那样,每个生产者只能有一个打开的事务。在beginTransaction()和commitTransaction()调用之间发送的所有消息都将是单个事务的一部分。当指定了transaction.id时,生产者发送的所有消息都必须是事务的一部分。
事务生产者使用异常来传达错误状态。特别是,不需要为producer.send()指定回调,也不需要对返回的Future调用.get。
通过在收到KafkaException时调用producer.abortTransaction(),我们可以确保任何成功的写入都被标记为中止,从而保持事务保证。
此客户端可以与0.10.0或更高版本的broker进行通信。较旧或较新的broker可能不支持某些客户端功能。例如,事务API需要0.11.0或更高版本的代理。调用运行的broker版本中不可用的API时,您将收到UnsupportedVersionException。
KafkaProducer源码分析
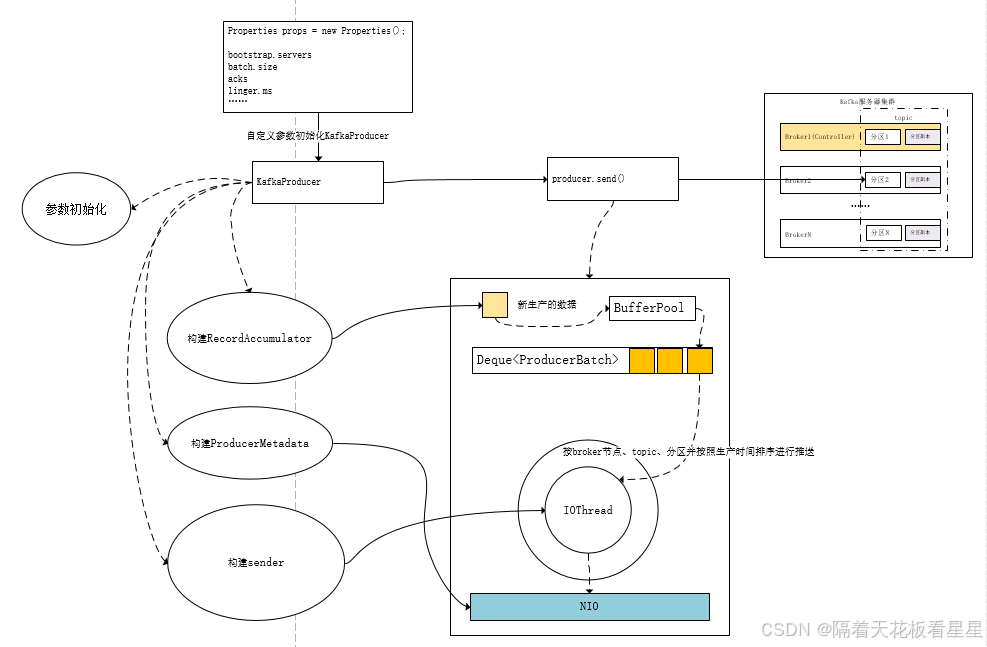
从KafkaProducer源码中可以看出主要有四部(初始化参数、构建RecordAccumulator、ProducerMetadata、Sender和IOThread)分构成,下面我们逐一来分析下
1、初始化参数
java
//我们配置的参数
this.producerConfig = config;
//系统时间
this.time = time;
//获取transactional.id
//解释:用于事务传递的TransactionalId。这实现了跨越多个生产者会话的可靠性语义,因为它允许客户端保证在开始任何新事务之前,
//使用相同TransactionalId的事务已经完成。如果没有提供TransactionalId,则生产者仅限于幂等传递。
//如果配置了TransactionalId,则隐含了enable.idmopotence为true。默认情况下,未配置TransactionId意味着无法使用事务.
String transactionalId = config.getString(ProducerConfig.TRANSACTIONAL_ID_CONFIG);
//配置client.id
//解释:发出请求时传递给服务器的id字符串。
//这样做的目的是通过允许在服务器端请求日志中包含逻辑应用程序名称,能够跟踪除ip/port之外的请求来源。
this.clientId = config.getString(ProducerConfig.CLIENT_ID_CONFIG);
//此类提供了一种使用通用上下文对日志记录器进行检测的方法,该上下文可用于自动丰富日志消息。
//例如,在KafkaConsumer中,知道消费者的groupId通常很有用,因此可以将其添加到上下文对象中,然后将其传递给所有依赖组件,以构建新的记录器。
//这消除了手动将groupId添加到每条消息中的需要。
LogContext logContext;
if (transactionalId == null)
logContext = new LogContext(String.format("[Producer clientId=%s] ", clientId));
else
logContext = new LogContext(String.format("[Producer clientId=%s, transactionalId=%s] ", clientId, transactionalId));
log = logContext.logger(KafkaProducer.class);
log.trace("Starting the Kafka producer");
Map<String, String> metricTags = Collections.singletonMap("client-id", clientId);
//metrics.num.samples
//为计算指标而维护的样本数量
//metrics.sample.window.ms
//计算度量样本的时间窗口
//metrics.recording.level
//指标的最高记录级别
MetricConfig metricConfig = new MetricConfig().samples(config.getInt(ProducerConfig.METRICS_NUM_SAMPLES_CONFIG))
.timeWindow(config.getLong(ProducerConfig.METRICS_SAMPLE_WINDOW_MS_CONFIG), TimeUnit.MILLISECONDS)
.recordLevel(Sensor.RecordingLevel.forName(config.getString(ProducerConfig.METRICS_RECORDING_LEVEL_CONFIG)))
.tags(metricTags);
//用作指标报告器的类列表
List<MetricsReporter> reporters = CommonClientConfigs.metricsReporters(clientId, config);
//用于客户端遥测的Metrics Reporter的实现,它管理客户端遥测收集过程的生命周期。客户端遥测报告器负责收集客户端遥测数据并将其发送给broker
this.clientTelemetryReporter = CommonClientConfigs.telemetryReporter(clientId, config);
this.clientTelemetryReporter.ifPresent(reporters::add);
MetricsContext metricsContext = new KafkaMetricsContext(JMX_PREFIX,
config.originalsWithPrefix(CommonClientConfigs.METRICS_CONTEXT_PREFIX));
this.metrics = new Metrics(metricConfig, reporters, time, metricsContext);
this.producerMetrics = new KafkaProducerMetrics(metrics);
//分区器
//通过 partitioner.class 指定
//确定生成记录时将记录发送到哪个分区。可用选项包括:
//如果未设置,则使用默认分区逻辑。此策略将记录发送到分区,直到该分区至少产生 batch.size 字节。
//如果没有指定分区,但存在key,请根据key的哈希值选择分区
//如果没有分区或key,请选择在分区产生至少 batch.size 字节时发生变化的粘性分区
//org.apache.kafka.clients.producer.RoundRobinPartitioner 分区策略
//其中一系列连续记录中的每条记录都被发送到不同的分区,无论是否提供了"key",直到分区用完,过程重新开始。(轮询推送)
//注意:创建新批次时,会导致分布不均
this.partitioner = config.getConfiguredInstance(
ProducerConfig.PARTITIONER_CLASS_CONFIG,
Partitioner.class,
Collections.singletonMap(ProducerConfig.CLIENT_ID_CONFIG, clientId));
//检查分区器是否已弃用,如果已弃用,请记录警告。
warnIfPartitionerDeprecated();
//获取 partitioner.ignore.keys
//当设置为"true"时,生产者将不会使用记录键来选择分区。如果为"false",
//当存在key时,生产者将根据key的哈希值选择分区。
//注意:如果使用自定义分区器,此设置无效。
this.partitionerIgnoreKeys = config.getBoolean(ProducerConfig.PARTITIONER_IGNORE_KEYS_CONFIG);
//获取 retry.backoff.ms 默认值 100
//在尝试重试对给定topic分区的失败请求之前等待的时间。这避免了在某些故障情况下在紧循环中重复发送请求。此值是初始退避值,
// 对于每个失败的请求,它将呈指数级增加,直到达到retrie.backoff.max.ms值
long retryBackoffMs = config.getLong(ProducerConfig.RETRY_BACKOFF_MS_CONFIG);
//retry.backoff.max.ms 默认1000
//向broker重试重复失败的请求时等待的最长时间(毫秒)。
//如果提供,每个客户端的回退将随着每个失败的请求呈指数级增长,直到达到这个最大值。为了防止所有客户端在重试时同步,
// 将对退避应用系数为0.2的随机抖动,导致退避落在计算值以下20%至以上20%的范围内。如果将retry.backoff.ms设置为高于retire.backoff.max.ms,
// 则try.backoff/max.ms将从一开始就用作恒定的回退,而不会有任何指数级的增加
long retryBackoffMaxMs = config.getLong(ProducerConfig.RETRY_BACKOFF_MAX_MS_CONFIG);
if (keySerializer == null) {
//key.serializer
//必须实现Serializer接口
this.keySerializer = config.getConfiguredInstance(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
Serializer.class);
this.keySerializer.configure(config.originals(Collections.singletonMap(ProducerConfig.CLIENT_ID_CONFIG, clientId)), true);
} else {
//如果用户构造KafkaProducer手动给出了 则忽略 key.serializer 配置
config.ignore(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG);
this.keySerializer = keySerializer;
}
if (valueSerializer == null) {
//value.serializer
this.valueSerializer = config.getConfiguredInstance(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
Serializer.class);
this.valueSerializer.configure(config.originals(Collections.singletonMap(ProducerConfig.CLIENT_ID_CONFIG, clientId)), false);
} else {
//如果用户构造KafkaProducer手动给出了 则忽略 value.serializer 配置
config.ignore(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG);
this.valueSerializer = valueSerializer;
}
//拦截器
//interceptor.classes
//用作拦截器的类列表。实现ProducerInterceptor接口
//在发布到Kafka集群之前,由生产者接收。允许您拦截(并可能修改)记录
//默认情况下,没有拦截器
List<ProducerInterceptor<K, V>> interceptorList = ClientUtils.configuredInterceptors(config,
ProducerConfig.INTERCEPTOR_CLASSES_CONFIG,
ProducerInterceptor.class);
if (interceptors != null)
this.interceptors = interceptors;
else
this.interceptors = new ProducerInterceptors<>(interceptorList);
//监听器
//把拦截器和指标统计器放入监听器中
ClusterResourceListeners clusterResourceListeners = ClientUtils.configureClusterResourceListeners(
interceptorList,
reporters,
Arrays.asList(this.keySerializer, this.valueSerializer));
//max.request.size
//request的最大大小(字节)。
//此设置将限制生产者在单个请求中发送的记录批数,以避免发送大量请求。这也有效地限制了最大未压缩记录批大小。
// 请注意,服务器对记录批大小有自己的上限(如果启用了压缩,则在压缩后),这可能与此不同。
this.maxRequestSize = config.getInt(ProducerConfig.MAX_REQUEST_SIZE_CONFIG);
//buffer.memory
//生产者可以用来缓冲等待发送到服务器的记录的内存总字节数。
//如果记录的发送速度超过了它们可以传递到服务器的速度,生产者将阻止 max.block.ms ,之后将抛出异常。
//此设置应大致 = 生产者将使用的总内存,但不是硬限制,因为生产者使用的并非所有内存都用于缓冲。
//一些额外的内存将用于压缩(如果启用了压缩)以及维护正在进行的请求。
this.totalMemorySize = config.getLong(ProducerConfig.BUFFER_MEMORY_CONFIG);
//压缩
this.compression = configureCompression(config);
//max.block.ms
//该配置控制 KafkaProducer 的
// send() 、partitionsFor()、initTransactions()、SendOffsetsToToAction()、commitTransaction() 和 aboutTransaction()
//将阻塞多长时间。对于<send(),此超时限制了等待元数据获取和缓冲区分配的总时间(用户提供的序列化器或分区器中的阻塞不计入此超时)。
//对于partitionsFor(),如果元数据不可用,则此超时限制了等待元数据的时间。与事务相关的方法总是阻塞,但如果无法发现事务协调器或在超时内没有响应,则可能会超时。
this.maxBlockTimeMs = config.getLong(ProducerConfig.MAX_BLOCK_MS_CONFIG);
//发送超时时间
int deliveryTimeoutMs = configureDeliveryTimeout(config, log);
//维护节点api版本
this.apiVersions = new ApiVersions();
this.transactionManager = configureTransactionState(config, logContext);
// There is no need to do work required for adaptive partitioning, if we use a custom partitioner.
//如果我们使用自定义分区器,则不需要进行自适应分区所需的工作。
//如果没有自定义分区器 且 partitioner.adaptive.partitioning.enable = true 自适应分区将开启
//partitioner.adaptive.partitioning.enable
//当设置为"true"时,生产者将尝试适应代理性能,并向托管在更快代理上的分区生成更多消息。
//若为"false",生产者将尝试统一分发消息。注意:如果使用自定义分区器,此设置无效
//因此最好不要自定义分区器,因为这样会损失与brokers性能d 最佳匹配
boolean enableAdaptivePartitioning = partitioner == null &&
config.getBoolean(ProducerConfig.PARTITIONER_ADPATIVE_PARTITIONING_ENABLE_CONFIG);
//分区配置 : 需要两个参数
//1、是否尝试适应 brokers 性能
//2、partitioner.availability.timeout.ms
// 如果broker在 partitioner.availability.timeout.ms 时间内无法处理来自分区的生成请求,则分区器将该分区视为不可用。
// 如果该值为0,则禁用此逻辑。注意:如果使用自定义分区器或将 partitioner.adaptive.partitioning.enable 设置为"false",则此设置无效
RecordAccumulator.PartitionerConfig partitionerConfig = new RecordAccumulator.PartitionerConfig(
enableAdaptivePartitioning,
config.getLong(ProducerConfig.PARTITIONER_AVAILABILITY_TIMEOUT_MS_CONFIG)
);
// As per Kafka producer configuration documentation batch.size may be set to 0 to explicitly disable
// batching which in practice actually means using a batch size of 1.
//据Kafka生产者配置文档,batch.size可以设置为0以显式禁用批处理,这实际上意味着使用1的批处理大小。
//在 1 和 batch.size 中取一个最大值
int batchSize = Math.max(1, config.getInt(ProducerConfig.BATCH_SIZE_CONFIG));2、构建RecordAccumulator
java
this.accumulator = new RecordAccumulator(logContext,
batchSize,
compression,
lingerMs(config),
retryBackoffMs,
retryBackoffMaxMs,
deliveryTimeoutMs,
partitionerConfig,
metrics,
PRODUCER_METRIC_GROUP_NAME,
time,
apiVersions,
transactionManager,
//在这里初始化 累加器的 内存池 总共的内存大小 批次大小
new BufferPool(this.totalMemorySize, batchSize, metrics, time, PRODUCER_METRIC_GROUP_NAME));3、构建ProducerMetadata
java
//bootstrap.servers host1:port1,host2:port2,...
//client.dns.lookup
//将 brokers 的地址列表一个一个拿出来去解析,将成功解析的地址放入 addresses 中
List<InetSocketAddress> addresses = ClientUtils.parseAndValidateAddresses(config);
//ProducerMetadata
if (metadata != null) {
this.metadata = metadata;
} else {
this.metadata = new ProducerMetadata(retryBackoffMs,
retryBackoffMaxMs,
config.getLong(ProducerConfig.METADATA_MAX_AGE_CONFIG),
config.getLong(ProducerConfig.METADATA_MAX_IDLE_CONFIG),
logContext,
clusterResourceListeners,
Time.SYSTEM);
this.metadata.bootstrap(addresses);
}4、构建Sender和IOThread
java
//sender
//处理向Kafka集群发送produce请求的后台线程。此线程发出元数据请求以更新其集群视图,然后向相应的节点发送生成请求。
this.sender = newSender(logContext, kafkaClient, this.metadata);
String ioThreadName = NETWORK_THREAD_PREFIX + " | " + clientId;
//一个 IO 线程 其实干活的是 sender
this.ioThread = new KafkaThread(ioThreadName, this.sender, true);
//调起这个线程
this.ioThread.start();记录累加器详解
记录累加器充当一个队列,将记录累积到要发送到服务器的 MemoryRecords 实例中。
我们先看看它初始化时都做了什么?
java
this.logContext = logContext;
this.log = logContext.logger(RecordAccumulator.class);
this.closed = false;
this.flushesInProgress = new AtomicInteger(0);
this.appendsInProgress = new AtomicInteger(0);
this.batchSize = batchSize;//batch.size
this.compression = compression;//压缩格式 GZIP LZ4 ZSTD
this.lingerMs = lingerMs; //linger.ms
this.retryBackoff = new ExponentialBackoff(retryBackoffMs, //retry.backoff.ms 默认值 100
CommonClientConfigs.RETRY_BACKOFF_EXP_BASE,
retryBackoffMaxMs, //retry.backoff.max.ms 默认1000
CommonClientConfigs.RETRY_BACKOFF_JITTER);
this.deliveryTimeoutMs = deliveryTimeoutMs; //delivery.timeout.ms
this.enableAdaptivePartitioning = partitionerConfig.enableAdaptivePartitioning; //partitioner.adaptive.partitioning.enable 是否尝试适应 brokers 性能
this.partitionAvailabilityTimeoutMs = partitionerConfig.partitionAvailabilityTimeoutMs; //partitioner.availability.timeout.ms
this.free = bufferPool; //BufferPool(this.totalMemorySize, batchSize, metrics, time, PRODUCER_METRIC_GROUP_NAME))
this.incomplete = new IncompleteBatches(); //一个线程安全的辅助类,用于保存尚未确认的批处理(包括已发送和未发送的批处理)。
this.muted = new HashSet<>(); //producer对每一个topic的分区都有一个socket。mute是将socket静音
this.time = time;
this.apiVersions = apiVersions;
nodesDrainIndex = new HashMap<>();
this.transactionManager = transactionManager;元数据详解
构造时用了以下配置参数:
retryBackoffMs:retry.backoff.ms 默认值 100
retryBackoffMaxMs:retry.backoff.max.ms 默认1000
metadata.max.age.ms:一段时间(毫秒),在此之后,即使我们没有看到任何分区领导层发生变化,我们也会强制刷新元数据,以主动发现任何新的代理或分区。
metadata.max.idle.ms:控制生产者为空闲主题缓存元数据的时间。如果自上次生成主题以来经过的时间超过元数据空闲持续时间,则主题的元数据将被遗忘,下次访问它将强制执行元数据获取请求。
clusterResourceListeners:监听器
从这些参数中我们也应该知道 生产者的元数据,就是它将要发送给每一个topic的分区信息
sender详解
它时一个后台线程,它既复负责获取元数据得到整个集群的视图消息,又负责发送数据到broker
简化下,平时写线程有这样一种方法
new Thread(new Runnable() ).start();
在Kafka中 Thread 就是 KafkaThread , Runnable 就是 sender
我们看看 sender初始化时都做了什么?
java
//max.in.flight.requests.per.connection
//在阻塞之前,客户端将在单个连接上发送的未确认请求的最大数量。
//请注意,如果此配置设置为大于1,并且<code>enable.idmopotence</code>设置为false,则存在"因重试导致发送失败后消息重新排序"的风险(即,如果启用了重试);"如果禁用重试,或者如果将<code>enable.idmpotence</code>设置为true,则将保留排序。"此外,启用幂等性要求此配置的值小于或等于5。"如果设置了冲突的配置,并且未显式启用幂等性,则禁用幂等性。";
int maxInflightRequests = producerConfig.getInt(ProducerConfig.MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION);
//request.timeout.ms
//配置控制客户端等待请求响应的最长时间。
//如果在超时时间过去之前没有收到响应,客户端将在必要时重新发送请求,或者在"重试次数用尽"的情况下使请求失败。
int requestTimeoutMs = producerConfig.getInt(ProducerConfig.REQUEST_TIMEOUT_MS_CONFIG);
ProducerMetrics metricsRegistry = new ProducerMetrics(this.metrics);
Sensor throttleTimeSensor = Sender.throttleTimeSensor(metricsRegistry.senderMetrics);
//默认 kafkaClient 就是 null
//创建出的client 为 NetworkClient
//用于异步请求/响应网络i/o的网络客户端。这是一个内部类,用于实现面向用户的生产者和消费者客户端。
//这个类不是线程安全的!
KafkaClient client = kafkaClient != null ? kafkaClient : ClientUtils.createNetworkClient(producerConfig,
this.metrics,
"producer",
logContext,
apiVersions,
time,
maxInflightRequests,
metadata,
throttleTimeSensor,
clientTelemetryReporter.map(ClientTelemetryReporter::telemetrySender).orElse(null));
//acks 确认
//很多地方都会有ack 比如 tcp发送请求时 需要返回 ack
//producer要求leader在考虑请求完成之前收到的确认数量。这控制了发送的记录的持久性。允许以下设置:
//acks=0 如果设置为零,则生产者根本不会等待服务器的任何确认。记录将立即添加到套接字缓冲区并被视为已发送。在这种情况下,无法保证服务器已收到记录,并且重试配置将不会生效(因为客户端通常不会知道任何故障)。为每条记录返回的偏移量将始终设置为-1
//acks=1 这意味着leader将把记录写入其本地日志,但不会等待所有followers的完全确认。在这种情况下,如果leader在确认记录后立即失败,但在followers复制记录之前失败,那么记录就会丢失
//acks=all 这意味着leader将等待整套同步副本确认记录。这保证了只要至少有一个同步副本仍然有效,记录就不会丢失。这是最有力的保证。这相当于acks=-1设置。请注意,启用幂等性要求此配置值为"all"。如果设置了冲突的配置,并且未显式启用幂等性,则禁用幂等性。
short acks = Short.parseShort(producerConfig.getString(ProducerConfig.ACKS_CONFIG));
//传入的这些参数都是推送数据所需要的直接参数
return new Sender(logContext,
client, //NetworkClient
metadata, //topic 分区 的元数据
this.accumulator, //记录累加器
maxInflightRequests == 1, //在阻塞前,客户端将在单个连接上发送的未确认请求的最大数量。
producerConfig.getInt(ProducerConfig.MAX_REQUEST_SIZE_CONFIG), //max.request.size
acks, //请求完成之前收到的确认数量
producerConfig.getInt(ProducerConfig.RETRIES_CONFIG), //retries 重试次数
metricsRegistry.senderMetrics,
time,
requestTimeoutMs, // request.timeout.ms 客户端等待请求响应的最长时间
producerConfig.getLong(ProducerConfig.RETRY_BACKOFF_MS_CONFIG), //retry.backoff.ms 默认 100 在尝试重试对给定主题分区的失败请求之前等待的时间量 此值是初始退避值,对于每个失败的请求,它将呈指数级增加,直到达到retrie.backoff.max.ms (默认1000) 值
this.transactionManager,
apiVersions);三、发送数据
1、将数据放入RecordAccumulator
当KafkaProducer构成成功后,发送数据只需要一行代码
//异步发送 producer.send(new ProducerRecord<>(topic, key, value), new ProducerCallback(key, value)); //同步发送 RecordMetadata metadata = producer.send(new ProducerRecord<>(topic, key, value)).get();
下面我们来看看send背后都做了什么?
1、拦截器处理
2、循环请求直到获取元数据(因为没有元数据,都不知道数据往哪发)
3、计算获取元数据消耗的时间,并用max.block.ms计算剩下的时间
4、对key、value进行序列化
5、根据key、value、元数据计算分区(默认使用哈希函数对序列化key计算分区)
6、在记录的消息头中设置为只读
7、将key、value、记录消息头、魔数进行压缩
8、将压缩后的数据和max.request.size、buffer.memory进行比较,超过直接报异常
9、将key、value、元数据、回调函数、记录消息头等添加到RecordAccumulator中
10、唤醒sender线程
11、返回future
下面是对应源码:
java
public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) {
//拦截可能被修改的记录;此方法不抛出异常
ProducerRecord<K, V> interceptedRecord = this.interceptors.onSend(record);
return doSend(interceptedRecord, callback);
}
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) {
//Append回调处理以下内容:
// - 呼叫拦截器和完成后的用户回叫
// - 记住在RecordAccumulator.append中计算的分区
AppendCallbacks appendCallbacks = new AppendCallbacks(callback, this.interceptors, record);
try {
throwIfProducerClosed();
//首先确保主题的元数据可用
long nowMs = time.milliseconds();
ClusterAndWaitTime clusterAndWaitTime;
try {
clusterAndWaitTime = waitOnMetadata(record.topic(), record.partition(), nowMs, maxBlockTimeMs);
} catch (KafkaException e) {
//.....
}
nowMs += clusterAndWaitTime.waitedOnMetadataMs;
long remainingWaitMs = Math.max(0, maxBlockTimeMs - clusterAndWaitTime.waitedOnMetadataMs);
Cluster cluster = clusterAndWaitTime.cluster;
//序列化key value
byte[] serializedKey;
try {
serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key());
} catch (ClassCastException cce) {
//......
}
byte[] serializedValue;
try {
serializedValue = valueSerializer.serialize(record.topic(), record.headers(), record.value());
} catch (ClassCastException cce) {
//.......
}
//尝试计算分区,但请注意,在此调用后,它可以是RecordMetadata。未知分区,
// 这意味着RecordAccumulator将使用内置逻辑(可能考虑代理负载、每个分区产生的数据量等)选择一个分区。
int partition = partition(record, serializedKey, serializedValue, cluster);
//设置数据是只读 这也符合kafka的思想,不对数据做修改,只做流转
setReadOnly(record.headers());
Header[] headers = record.headers().toArray();
//使用给定字段获取保存记录所需的批大小的上限估计值。这只是一个估计,因为它没有考虑到压缩算法的开销。
int serializedSize = AbstractRecords.estimateSizeInBytesUpperBound(apiVersions.maxUsableProduceMagic(),
compression.type(), serializedKey, serializedValue, headers);
//验证记录大小是否太大
ensureValidRecordSize(serializedSize);
long timestamp = record.timestamp() == null ? nowMs : record.timestamp();
// 自定义分区器可以利用onNewBatch回调。
boolean abortOnNewBatch = partitioner != null;
// Append the record to the accumulator. Note, that the actual partition may be
// calculated there and can be accessed via appendCallbacks.topicPartition.
//将记录附加到累加器中。
// 请注意,实际的分区可以在那里计算,并且可以通过appendCallbacks.topicPartition访问。
RecordAccumulator.RecordAppendResult result = accumulator.append(record.topic(), partition, timestamp, serializedKey,
serializedValue, headers, appendCallbacks, remainingWaitMs, abortOnNewBatch, nowMs, cluster);
assert appendCallbacks.getPartition() != RecordMetadata.UNKNOWN_PARTITION;
//是否要创建新的 批处理
if (result.abortForNewBatch) {
int prevPartition = partition;
onNewBatch(record.topic(), cluster, prevPartition);
partition = partition(record, serializedKey, serializedValue, cluster);
if (log.isTraceEnabled()) {
log.trace("Retrying append due to new batch creation for topic {} partition {}. The old partition was {}", record.topic(), partition, prevPartition);
}
result = accumulator.append(record.topic(), partition, timestamp, serializedKey,
serializedValue, headers, appendCallbacks, remainingWaitMs, false, nowMs, cluster);
}
//将分区成功附加到累加器后,将其添加到事务中(如果正在进行)。我们之前无法执行此操作,因为分区可能未知,
// 或者在批处理关闭时(如"abortForNewBatch"所示)最初选择的分区可能会更改。请注意,
// "Sender"将拒绝从累加器中取出批处理,直到它们被添加到事务中。
if (transactionManager != null) {
transactionManager.maybeAddPartition(appendCallbacks.topicPartition());
}
if (result.batchIsFull || result.newBatchCreated) {
//由于主题{}分区{}已满或正在接收新批,正在唤醒发件人
log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), appendCallbacks.getPartition());
this.sender.wakeup();
}
return result.future;
} catch (ApiException e) {
//........
}
}2、RecordAccumulator是如何放数据的
1、计算有效分区,并将其告知回调函数
2、 检查是否有正在处理的批次,如果有则从双端队列中的尾部取出一个ProducerBatch,并将数据异步的放入
3、如果没有需要建立新批次(ProducerBatch),从内存池申请一块内存,用新申请的内存创建新批次
4、将数据放到这个批次中
5、将这个批次放到双端队列末尾
6、释放内存
下面是对应源码:
java
public RecordAppendResult append(String topic,
int partition,
long timestamp,
byte[] key,
byte[] value,
Header[] headers,
AppendCallbacks callbacks,
long maxTimeToBlock,
boolean abortOnNewBatch,
long nowMs,
Cluster cluster) throws InterruptedException {
TopicInfo topicInfo = topicInfoMap.computeIfAbsent(topic, k -> new TopicInfo(logContext, k, batchSize));
//我们跟踪追加线程的数量,以确保在aboutIncompleteBatches())中不会错过批处理。
appendsInProgress.incrementAndGet();
ByteBuffer buffer = null;
if (headers == null) headers = Record.EMPTY_HEADERS;
try {
//循环以重试,以防我们遇到分区器的竞争条件。
while (true) {
//如果消息没有任何分区关联性,那么我们会根据代理的可用性和性能选择一个分区。
// 请注意,在这里,我们在持有双端队列锁之前会查看当前分区,因此我们需要确保在等待双端队列锁定时它没有更改。
final BuiltInPartitioner.StickyPartitionInfo partitionInfo;
final int effectivePartition;
if (partition == RecordMetadata.UNKNOWN_PARTITION) {
partitionInfo = topicInfo.builtInPartitioner.peekCurrentPartitionInfo(cluster);
effectivePartition = partitionInfo.partition();
} else {
partitionInfo = null;
effectivePartition = partition;
}
//现在我们知道了有效分区,让调用者知道。
setPartition(callbacks, effectivePartition);
//检查我们是否有正在处理的批次
Deque<ProducerBatch> dq = topicInfo.batches.computeIfAbsent(effectivePartition, k -> new ArrayDeque<>());
synchronized (dq) {
//获取锁后,验证分区是否没有更改,然后重试。
if (partitionChanged(topic, topicInfo, partitionInfo, dq, nowMs, cluster))
continue;
RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callbacks, dq, nowMs);
if (appendResult != null) {
//若队列中的批处理不完整,我们将禁用开关
boolean enableSwitch = allBatchesFull(dq);
topicInfo.builtInPartitioner.updatePartitionInfo(partitionInfo, appendResult.appendedBytes, cluster, enableSwitch);
return appendResult;
}
}
//我们没有正在进行的记录批次,请尝试分配新批次
if (abortOnNewBatch) {
//返回一个结果,该结果将导致另一个调用追加。
return new RecordAppendResult(null, false, false, true, 0);
}
if (buffer == null) {
byte maxUsableMagic = apiVersions.maxUsableProduceMagic();
int size = Math.max(this.batchSize, AbstractRecords.estimateSizeInBytesUpperBound(maxUsableMagic, compression.type(), key, value, headers));
log.trace("Allocating a new {} byte message buffer for topic {} partition {} with remaining timeout {}ms", size, topic, partition, maxTimeToBlock);
// 如果我们耗尽缓冲区空间,此调用可能会阻塞。
buffer = free.allocate(size, maxTimeToBlock);
// 如果上述缓冲区分配受阻,请更新当前时间。注意:获取时间可能很昂贵,因此应避免在锁下调用它。
nowMs = time.milliseconds();
}
synchronized (dq) {
//获取锁后,验证分区是否没有更改,然后重试。
if (partitionChanged(topic, topicInfo, partitionInfo, dq, nowMs, cluster))
continue;
RecordAppendResult appendResult = appendNewBatch(topic, effectivePartition, dq, timestamp, key, value, headers, callbacks, buffer, nowMs);
//将缓冲区设置为null,这样释放就不会将其返回到空闲池,因为它已在批处理中使用。
if (appendResult.newBatchCreated)
buffer = null;
//若队列中的批处理不完整,我们将禁用开关
boolean enableSwitch = allBatchesFull(dq);
topicInfo.builtInPartitioner.updatePartitionInfo(partitionInfo, appendResult.appendedBytes, cluster, enableSwitch);
return appendResult;
}
}
} finally {
//解除内存分配
free.deallocate(buffer);
appendsInProgress.decrementAndGet();
}
}3、sender发送数据
这里我们只描述正常情况下发送数据的情况,比如事务管理器处于失败状态、元数据中对应分区的leader信息不明确等情况暂不考虑
1、记录下当前时间
2、获取准备发送数据的分区列表
3、判断列表中的节点释放准备好接收数据,只保留准备好的节点
4、从双端队列取出数据,并为每一个节点分配一个List<ProducerBatch>>
5、对每个分区的批次按照时间进行排序
6、将取完的topci对应的分区静音(mute)
7、将数据以节点的方式一台一台进行发送
8、找到一个批次中的数据的最小magic version ,并将其他数据中的magic version也进行同步调整(kafka发送数据之前还考虑了 每个borker 的版本是否不同的问题)
9、构建ClientRequest
10、将给定的请求交给NetworkClient排队等待发送
11、将请求再次封装成NetworkSend交给selector,未来将在poll(long) poll()完成发送
12、传输层注册要给 OP_WRITE 事件
13、KafkaClient调用poll方法操作socket进行写操作(最终调用的是selector的poll())
下面是对应源码:
Sender
java
public class Sender implements Runnable {
public void run() {
log.debug("Starting Kafka producer I/O thread.");
if (transactionManager != null)
transactionManager.setPoisonStateOnInvalidTransition(true);
//主循环,一直运行到调用close
while (running) {
try {
runOnce();
} catch (Exception e) {
log.error("Uncaught error in kafka producer I/O thread: ", e);
}
}
//..........
this.client.close();
}
void runOnce() {
if (transactionManager != null) {
try {
//事务的相关操作.......
} catch (AuthenticationException e) {
//.........
}
}
long currentTimeMs = time.milliseconds();
//按照节点为每个分区构建请求,并添加写事件
long pollTimeout = sendProducerData(currentTimeMs);
//调用selector.poll()将数据交给socket发到对应broker
client.poll(pollTimeout, currentTimeMs);
}
private long sendProducerData(long now) {
MetadataSnapshot metadataSnapshot = metadata.fetchMetadataSnapshot();
//获取准备发送数据的分区列表
RecordAccumulator.ReadyCheckResult result = this.accumulator.ready(metadataSnapshot, now);
//如果有任何分区的领导者尚不清楚,请强制更新元数据
if (!result.unknownLeaderTopics.isEmpty()) {
//leader未知的主题集包含领导人选举待定的主题以及可能已过期的主题。
// 将主题再次添加到元数据中以确保其包含在内,并请求元数据更新,因为有消息要发送到主题。
for (String topic : result.unknownLeaderTopics)
this.metadata.add(topic, now);
result.unknownLeaderTopics);
this.metadata.requestUpdate(false);
}
//删除我们尚未准备好发送的任何节点
Iterator<Node> iter = result.readyNodes.iterator();
long notReadyTimeout = Long.MAX_VALUE;
while (iter.hasNext()) {
Node node = iter.next();
//启动与给定节点的连接(如果需要),如果已经连接,则返回true。只有在调用轮询时,节点的准备状态才会改变。
if (!this.client.ready(node, now)) {
//仅更新延迟统计的readyTimeMs,以便每次批处理就绪时都向前移动
// (然后readyTimeMs和drainTimeMs之间的差值将表示数据等待节点的时间)。
this.accumulator.updateNodeLatencyStats(node.id(), now, false);
iter.remove();
notReadyTimeout = Math.min(notReadyTimeout, this.client.pollDelayMs(node, now));
} else {
//更新readyTimeMs和drainTimeMs,这将"重置"节点延迟。
this.accumulator.updateNodeLatencyStats(node.id(), now, true);
}
}
//创建生产请求
Map<Integer, List<ProducerBatch>> batches = this.accumulator.drain(metadataSnapshot, result.readyNodes, this.maxRequestSize, now);
addToInflightBatches(batches);
if (guaranteeMessageOrder) {
//将所有已排空的分区静音
for (List<ProducerBatch> batchList : batches.values()) {
for (ProducerBatch batch : batchList)
this.accumulator.mutePartition(batch.topicPartition);
}
}
accumulator.resetNextBatchExpiryTime();
List<ProducerBatch> expiredInflightBatches = getExpiredInflightBatches(now);
List<ProducerBatch> expiredBatches = this.accumulator.expiredBatches(now);
expiredBatches.addAll(expiredInflightBatches);
//如果之前已将过期的批发送到broker,请重置生产者id。同时更新过期批次的指标
if (!expiredBatches.isEmpty())
log.trace("Expired {} batches in accumulator", expiredBatches.size());
for (ProducerBatch expiredBatch : expiredBatches) {
String errorMessage = "Expiring " + expiredBatch.recordCount + " record(s) for " + expiredBatch.topicPartition
+ ":" + (now - expiredBatch.createdMs) + " ms has passed since batch creation";
failBatch(expiredBatch, new TimeoutException(errorMessage), false);
if (transactionManager != null && expiredBatch.inRetry()) {
//这确保了在当前飞行中的批次完全解决之前,不会排出新的批次。
transactionManager.markSequenceUnresolved(expiredBatch);
}
}
sensors.updateProduceRequestMetrics(batches);
//如果我们有任何准备发送的节点+有可发送的数据,请在0超时的情况下轮询,
// 这样就可以立即循环并尝试发送更多数据。否则,超时将是下一批到期时间和检查数据可用性的延迟时间之间的较小值。
// 请注意,由于延迟、回退等原因,节点可能有尚未发送的数据。这特别不包括具有可发送数据但尚未准备好发送的节点,因为它们会导致繁忙的循环。
long pollTimeout = Math.min(result.nextReadyCheckDelayMs, notReadyTimeout);
pollTimeout = Math.min(pollTimeout, this.accumulator.nextExpiryTimeMs() - now);
pollTimeout = Math.max(pollTimeout, 0);
if (!result.readyNodes.isEmpty()) {
log.trace("Nodes with data ready to send: {}", result.readyNodes);
//如果某些分区已经准备好发送,则选择时间将为0;否则,如果某个分区已经积累了一些数据但尚未准备好,
// 则选择时间将是现在与其延迟到期时间之间的时间差;否则,选择时间将是现在和元数据到期时间之间的时间差;
pollTimeout = 0;
}
sendProduceRequests(batches, now);
return pollTimeout;
}
private void sendProduceRequests(Map<Integer, List<ProducerBatch>> collated, long now) {
for (Map.Entry<Integer, List<ProducerBatch>> entry : collated.entrySet())
sendProduceRequest(now, entry.getKey(), acks, requestTimeoutMs, entry.getValue());
}
private void sendProduceRequest(long now, int destination, short acks, int timeout, List<ProducerBatch> batches) {
if (batches.isEmpty())
return;
//从这里可以看出,这里认为 生产者处理的一批数据中 有不同 topci 和分区的 数据 ,需要将他们放到一块分开发向不同的 broker
final Map<TopicPartition, ProducerBatch> recordsByPartition = new HashMap<>(batches.size());
// find the minimum magic version used when creating the record sets
//找到创建记录集时使用的最小魔术版本
//Magic 版本 在 crc 之前,没有被压缩的一个值 在网络协议中,Magic也被用来标识协议的类型和版本,确保接收方能够正确解析和处理发送的数据
byte minUsedMagic = apiVersions.maxUsableProduceMagic();
for (ProducerBatch batch : batches) {
if (batch.magic() < minUsedMagic)
minUsedMagic = batch.magic();
}
ProduceRequestData.TopicProduceDataCollection tpd = new ProduceRequestData.TopicProduceDataCollection();
for (ProducerBatch batch : batches) {
TopicPartition tp = batch.topicPartition;
MemoryRecords records = batch.records();
//如有必要,将其转换为所使用的最小magic。
// 一般来说,生产者开始构建批处理的时间和我们发送请求的时间之间可能会有延迟,我们可能已经根据过时的元数据选择了消息格式。
// 在最坏的情况下,我们乐观地选择使用新的消息格式,但发现代理不支持它,因此我们需要在发送之前在客户端进行下转换。
// 这是为了处理集群升级的边缘情况,在这些情况下,代理可能并不都支持相同的消息格式版本。
// 例如,如果一个分区从支持新魔术版本的代理迁移到不支持的代理,那么我们需要进行转换。
//kafka发送数据之前还考虑了 每个borker 的版本是否不同的问题 , 考虑的太全了
if (!records.hasMatchingMagic(minUsedMagic))
records = batch.records().downConvert(minUsedMagic, 0, time).records();
ProduceRequestData.TopicProduceData tpData = tpd.find(tp.topic());
if (tpData == null) {
tpData = new ProduceRequestData.TopicProduceData().setName(tp.topic());
tpd.add(tpData);
}
tpData.partitionData().add(new ProduceRequestData.PartitionProduceData()
.setIndex(tp.partition())
.setRecords(records));
recordsByPartition.put(tp, batch);
}
String transactionalId = null;
if (transactionManager != null && transactionManager.isTransactional()) {
transactionalId = transactionManager.transactionalId();
}
ProduceRequest.Builder requestBuilder = ProduceRequest.forMagic(minUsedMagic,
new ProduceRequestData()
.setAcks(acks)
.setTimeoutMs(timeout)
.setTransactionalId(transactionalId)
.setTopicData(tpd));
RequestCompletionHandler callback = response -> handleProduceResponse(response, recordsByPartition, time.milliseconds());
String nodeId = Integer.toString(destination);
ClientRequest clientRequest = client.newClientRequest(nodeId, requestBuilder, now, acks != 0,
requestTimeoutMs, callback);
//将给定的请求排队等待发送。请求只能在就绪连接上发送。
client.send(clientRequest, now);
log.trace("Sent produce request to {}: {}", nodeId, requestBuilder);
}
}KafkaClient
最后都是调用的NetworkClient
用于异步请求/响应网络i/o的网络客户端。这是一个内部类,用于实现面向用户的生产者和消费者客户端。
java
public class NetworkClient implements KafkaClient {
/*用于执行网络输入/输出的选择器 */
private final Selectable selector;
public void send(ClientRequest request, long now) {
doSend(request, false, now);
}
private void doSend(ClientRequest clientRequest, boolean isInternalRequest, long now) {
//........
AbstractRequest.Builder<?> builder = clientRequest.requestBuilder();
try {
doSend(clientRequest, isInternalRequest, now, builder.build(version));
} catch (UnsupportedVersionException unsupportedVersionException) {
//........
}
}
private void doSend(ClientRequest clientRequest, boolean isInternalRequest, long now, AbstractRequest request) {
String destination = clientRequest.destination();
//制作消息头
RequestHeader header = clientRequest.makeHeader(request.version());
Send send = request.toSend(header);
InFlightRequest inFlightRequest = new InFlightRequest(
clientRequest,
header,
isInternalRequest,
request,
send,
now);
this.inFlightRequests.add(inFlightRequest);
//将给定的请求排队,以便在后续的{@link#poll(long)poll()}调用中发送
selector.send(new NetworkSend(clientRequest.destination(), send));
}
public List<ClientResponse> poll(long timeout, long now) {
ensureActive();
if (!abortedSends.isEmpty()) {
List<ClientResponse> responses = new ArrayList<>();
handleAbortedSends(responses);
completeResponses(responses);
return responses;
}
long metadataTimeout = metadataUpdater.maybeUpdate(now);
long telemetryTimeout = telemetrySender != null ? telemetrySender.maybeUpdate(now) : Integer.MAX_VALUE;
try {
this.selector.poll(Utils.min(timeout, metadataTimeout, telemetryTimeout, defaultRequestTimeoutMs));
} catch (IOException e) {
log.error("Unexpected error during I/O", e);
}
// 处理已完成的操作
long updatedNow = this.time.milliseconds();
List<ClientResponse> responses = new ArrayList<>();
handleCompletedSends(responses, updatedNow);
handleCompletedReceives(responses, updatedNow);
handleDisconnections(responses, updatedNow);
handleConnections();
handleInitiateApiVersionRequests(updatedNow);
handleTimedOutConnections(responses, updatedNow);
handleTimedOutRequests(responses, updatedNow);
completeResponses(responses);
return responses;
}
}Selector
一个用于进行无阻塞多连接网络I/O的nioSelector接口。
此类与NetworkSend和network Receive配合使用,以传输以大小分隔的网络请求和响应
通过执行以下操作,可以将连接添加到与整数id关联的nioSelector中
java
nioSelector.connect("42", new InetSocketAddress("google.com", server.port), 64000, 64000);connect调用不会阻止TCP连接的创建,因此connect方法仅开始启动连接。成功调用此方法并不意味着已建立有效连接。
发送请求、接收响应、处理连接完成和断开现有连接都是使用poll()调用完成的。
java
nioSelector.send(new NetworkSend(myDestination, myBytes));
nioSelector.send(new NetworkSend(myOtherDestination, myOtherBytes));
nioSelector.poll(TIMEOUT_MS);nioSelector维护了几个列表,每次调用poll()时都会重置这些列表,这些列表可以通过各种getter获得。每次调用poll()都会重置这些值。
java
public class Selector implements Selectable, AutoCloseable {
private final java.nio.channels.Selector nioSelector;
//每个节点一个 KafkaChannel
private final Map<String, KafkaChannel> channels;
//开始连接到给定的地址,并将连接添加到与给定id号关联的nioSelector
//请注意,此调用仅启动连接,连接将在未来的poll()调用中完成。检查connected(),查看在给定的轮询调用后完成了哪些连接(如果有的话)。
public void connect(String id, InetSocketAddress address, int sendBufferSize, int receiveBufferSize) throws IOException {
ensureNotRegistered(id);
SocketChannel socketChannel = SocketChannel.open();
SelectionKey key = null;
try {
configureSocketChannel(socketChannel, sendBufferSize, receiveBufferSize);
boolean connected = doConnect(socketChannel, address);
//注册OP_CONNECT事件
key = registerChannel(id, socketChannel, SelectionKey.OP_CONNECT);
if (connected) {
// 对于立即连接的通道,OP_CONNECT不会触发
log.debug("Immediately connected to node {}", id);
immediatelyConnectedKeys.add(key);
key.interestOps(0);
}
} catch (IOException | RuntimeException e) {
if (key != null)
immediatelyConnectedKeys.remove(key);
channels.remove(id);
socketChannel.close();
throw e;
}
}
//当连接被其他线程接受但由Selector处理时,在现有通道中注册nioSelector在服务器端使用此选项,
//如果"channels"或"closingChannels"中已经存在具有相同连接id的连接,则会引发异常。必
//须选择连接ID,以避免在重用远程端口时发生冲突。Kafka broker 在连接id中添加递增索引,以避免在处理与同一远程主机:
//端口的新连接时,broker可能尚未关闭现有连接的时间窗口中重复使用。
//
public void register(String id, SocketChannel socketChannel) throws IOException {
ensureNotRegistered(id);
//注册读事件
registerChannel(id, socketChannel, SelectionKey.OP_READ);
this.sensors.connectionCreated.record();
// 默认为空客户端信息,因为ApiVersionsRequest不是必需的。在这种情况下,我们仍然希望解释连接。
ChannelMetadataRegistry metadataRegistry = this.channel(id).channelMetadataRegistry();
if (metadataRegistry.clientInformation() == null)
metadataRegistry.registerClientInformation(ClientInformation.EMPTY);
}
//如果nioSelector在等待I/O时被阻塞,请中断它。
public void wakeup() {
this.nioSelector.wakeup();
}
public void setSend(NetworkSend send) {
this.send = send;
//传输层注册要给 OP_WRITE 事件
this.transportLayer.addInterestOps(SelectionKey.OP_WRITE);
}
//............
}四、总结
从以上过程我们概括的来画下总结图: