从广义上来讲:数据结构就是
一组数据的存储结构, 算法就是操作数据的方法数据结构是为算法服务的,算法是要作用在特定的数据结构上的。
10个最常用的数据结构:数组、链表、栈、队列、散列表、二叉树、堆、跳表、图、Trie树
10个最常用的算法:递归、排序、二分查找、搜索、哈希算法、贪心算法、分治算法、回溯算法、动态规划、字符串匹配算法
本文总结了20个最常用的数据结构和算法,不管是应付面试还是工作需要,只要集中精力攻克这20个知识点就足够了。
数据结构和算法(三):二分查找、跳表、散列表、哈希算法的传送门
数据结构和算法(四):二叉树、红黑树、递归树、堆和堆排序、堆的应用的传送门
第二十六章 贪心算法
一、什么是贪心算法
-
- 贪心算法是指在对问题求解时,总是做出在当前看来 是最好的选择,也就是说不从整体考虑,而是从局部看来是最优解,所以贪心算法得到的结果不一定是最优的。
-
- 贪心算法没有固定的算法解决框架,算法的关键 就是贪婪策略的选择,根据不同问题选择不同的策略。
-
- 贪心算法的适用场景比较有限,更多是用来指导设计基础算法,比如最小生成树算法、单源最短路径算法等。
二、使用贪心算法的解决问题的思路
-
- 当我们看到此类数据时,首先要联想到贪心算法 :针对一组数据,我们定义了限制值和期望值,希望从中选择几个数据,在满足限制值 的前提下,期望值最大。(例如:从宝库中只能拿100kg的物品,从黄金、白银、纯铁怎么选择,使得价值最大,这里面限制值就是100kg,期望值就是价值最大。)
-
- 将问题抽象成限制值、期望值后,就可以尝试选择合适的贪婪策略去解决了,在刚才那个例子中,贪婪策略就是尽量多拿单价最高的金属。
-
- 选择不同的贪婪策略后,看下贪心算法产生的结果是否是最优的。从实践的角度来说,大部分能用贪心算法解决的问题,贪心算法的正确性都是显而易见的,也不需要严格证明。
三、贪心算法实战分析
-
- 分糖果
-
(1). 假设我们有m个糖果和n个孩子,要把糖果分给孩子吃,糖果多孩子少,每个糖果的大小不等,每个孩子对糖果的需求也不相同,只要糖果的大小超过了孩子的需求,那么这个孩子就会得到满足,请问:如何分配糖果,才能满足最多数量的孩子呢?
-
(2). 解决这个问题的第一步,我们把问题抽象成:在n个孩子中,选择一部分孩子分配糖果,使得满足的孩子最多。这里m个糖果就是限制值,最多满足的孩子就是期望值。
-
(3). 解决这个问题的第二步,尝试用贪心算法解决。对应一个孩子来说,如果小的糖果就可以解决,那么没必要用大的糖果,所以分配糖果的时候我们可以用需求最小的孩子开始分配。
-
(4). 我们的分配策略就是:每次从剩下的孩子中选择需求最小的孩子,分配给能满足他的最少糖果,这样的分配方案,就是满足孩子最多的方案,这也是显而易见的最优方案。
-
- 区间覆盖
-
(1). 假设有n个区间,区间的起始端点和结束端点分别是a1,a2、b1,b2...,我们从这n个区间内选取一部分不相交的区间,问:怎么选择,才能使得不相交的区间个数最多呢?
-
(2). 解决问题第一步,我们把问题抽象化,假设n个区间的最左侧是min端点,最右侧是max端点,这个问题就相当于,从n个区间中选取几个不相交的区间,从左到右将min,max覆盖完。
-
(3). 解决问题的第二步,选择合适的贪婪策略尝试解决,我们每次选择的时候,选择左边端点不重合,右边端点尽可能小的区间,使得剩下的区域尽可能大,就可以放置更多的区间。如下图:
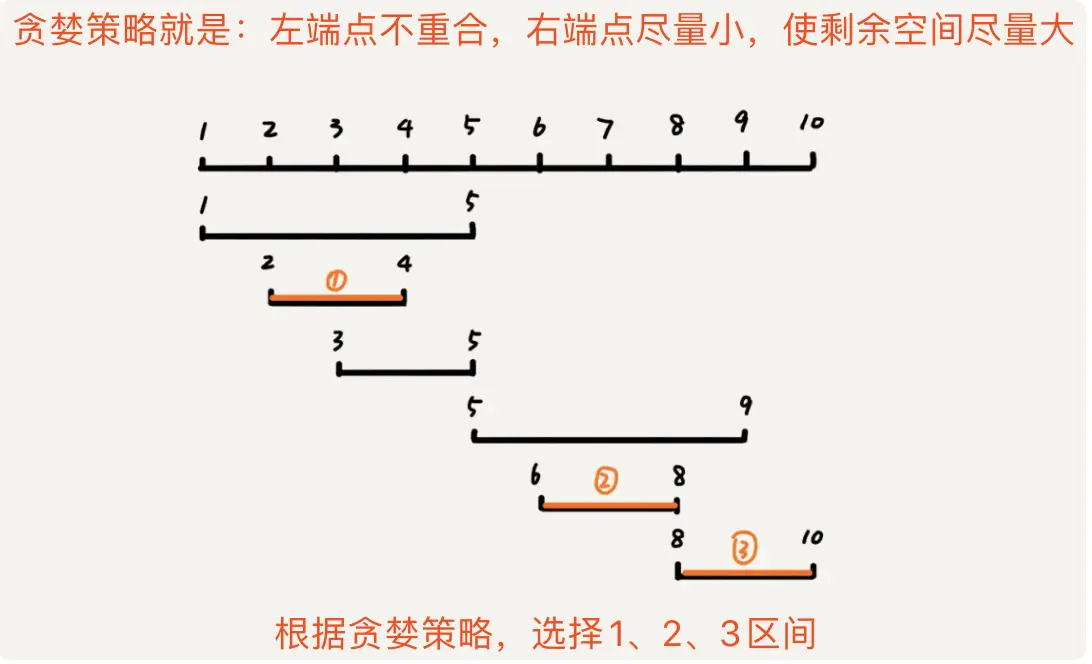
区间覆盖.png
-
- 如何用贪心算法实现霍夫曼压缩编码
-
(1). 假设有1000个字符,每个字符占1个字节,一共占1000个字节,也就是8000bit的存储空间;如果我们统计发现这1000个字符,只有6种字符,分别为a、b、c、d、e、f的话,我们就可以用3个bit来表示他们,如下图,这样我们就可以只占用3000bit的空间了,比原来节省了很多,那么我们还有更节省空间的方法吗?(3个bit其实可以存放8种不同的字符,2 x 2 x 2 = 8)
a(000)、b(001)、c(010)、d(011)、e(100)、f(101)
-
(2). 霍夫曼编码就登场了,霍夫曼编码广泛应用于数据压缩中,压缩率在20%~90%之间,霍夫曼编码不仅会考察文本中有多少个字符,还会统计字符出现的频率,根据频率不同,选择不同长度的编码,频率高的字符选用短编码,频率低的字符选用稍长编码,霍夫曼编码试图使用不等长的编码方式,来进一步增加压缩效率。
-
(3). 由于霍夫曼编码是不等长的,所以解压缩的时候就比较困难,不知道该读取1位还是2位还是3位来解压缩,所以为了避免这种歧义,霍夫曼编码要求各个字符的编码之间,不能出现一个字符的编码是另一个字符编码的前缀。
-
(4). 在上面那个例子中,我们假设这6个字符出现的频率从高到低依次是a、b、c、d、e、f,我们采用霍夫曼编码的方式进行编码后,就是下图的样子,任意一个字符的编码都不是其他字符编码的前缀,在解压缩的时候,就可以以 读取尽可能长的可解压二进制串 的方式来解压,就不会出现解压歧义了,通过霍夫曼编码来压缩,这1000个字符只需要占用2100bit的存储空间就够了。
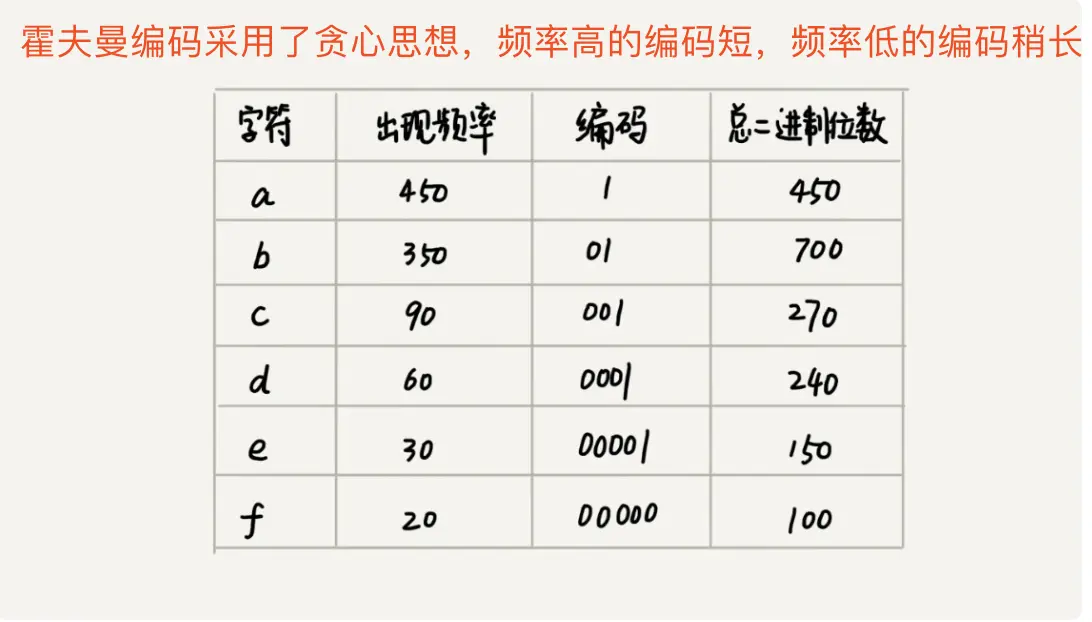
采用霍夫曼编码对1000个字符进行压缩 -
(5). 霍夫曼编码的思想并不难理解,但是如何根据字符出现的频率,选用不同长度的编码呢? 这里可以这样处理,如下图:把每个字符都看作一个节点,把频率最低的两个节点f、c组合在一起生成一个父节点x,x的频率为f、c频率之和,再把x节点和频率次低的d节点组合生成父节点y,一直重复下去,直到把字符处理完;接下来,给每条边上画一个权值,指向左节点的边统一记做0,指向右节点的边统一记做1,那么从根节点到叶子节点的路径,就是叶子节点对应字符的霍夫曼编码了。
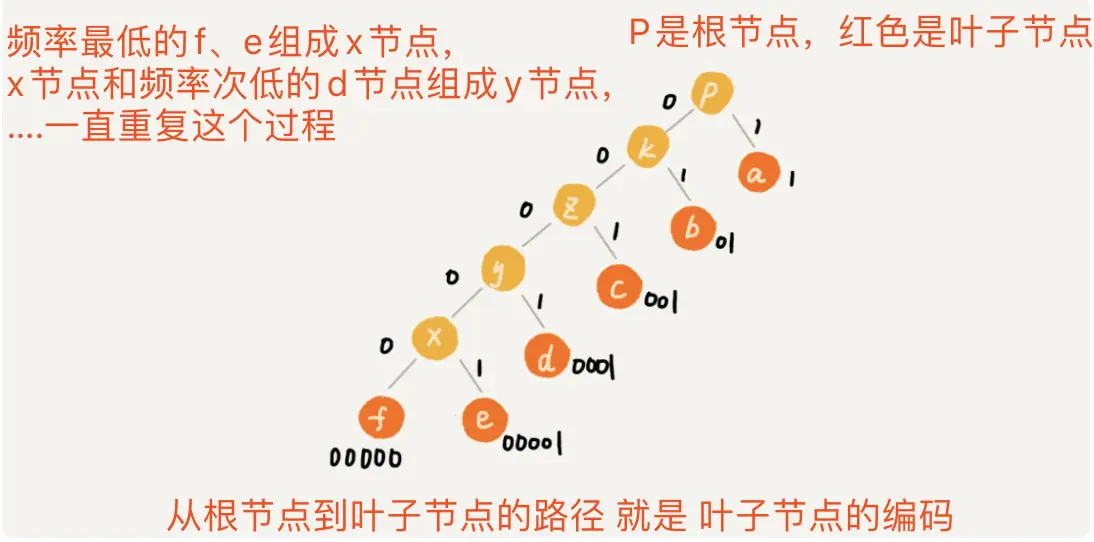
霍夫曼编码如何根据字符频率选编码
第二十七章 分治算法
一、什么是分治算法?
-
- 分治算法的核心思想就是四个字:分而治之,就是将原问题分解成n个小问题,解决这些小问题后,将结果合并,就可以得到原问题的解了。
-
- 想用分治算法解决问题,一般需要满足以下条件:
- (1). 原问题与分解成的小问题具有相同模式
- (2). 子问题之间没有关联性,可以独立求解(需要跟动态规划区分开)
- (3). 具有分解终止条件,也就是说,当问题足够小时,可以直接求解
- (4). 可以将子问题合并成原问题,并且合并操作复杂度不能太高,不然就起不到降低总体算法复杂度的目的了
二、分治思想在海量数据处理中的应用
-
- 假设要给10G的订单数据按照金额进行排序,但是我们机器的内存只有2G,无法一次性加载到内存,也就无法单纯的利用快排、归并算法来解决了,就可以使用分治思想来解决
-
- 面对10G的订单数据,我们可以先扫描一遍订单,根据订单金额划分出几个金额区间,例如1到100元的放到一个文件中,100到200元的放到另一个文件中,以此类推,这样每个小文件都可以加载到内存中,最后将这些小文件合并,就得到有序的10G订单数据了。
-
- 如果订单数据存储在类似于GFS的分布式系统上,就可以将多个小文件并行加载到多台机器上并行处理,这样处理速度就会加快很多,这就是分治思想的一个应用。
第二十八章 回溯算法
第二十九章 初始动态规划
第三十章 动态规划实战
第三十一章 拓扑排序
一、什么是拓扑排序?
-
- 从局部有序推断出全局的顺序就叫做拓扑排序 ,例如,我们穿衣服的时候是有一定顺序的,你必须先穿袜子才能穿鞋,你必须先穿内裤才能穿秋裤,假设我们有8件衣服,可以按照下面的顺序进行穿衣服,就可以满足局部关系的前提下满足全局有序。

拓扑排序.png
- 从局部有序推断出全局的顺序就叫做拓扑排序 ,例如,我们穿衣服的时候是有一定顺序的,你必须先穿袜子才能穿鞋,你必须先穿内裤才能穿秋裤,假设我们有8件衣服,可以按照下面的顺序进行穿衣服,就可以满足局部关系的前提下满足全局有序。
-
- 我们知道,算法是构建在具体数据结构之上的 ,我们想进行拓扑排序,就需要先把问题背景抽象成具体的数据结构 ,我们把衣服之间的依赖关系抽象 成一个有向图 ,每件衣服对应图中的一个点 ,依赖关系就是顶点之间的边 ,而且这个图不仅是有向图,还得是有向无环图,因为图中一旦有了环,就无法进行拓扑排序了,所以拓扑排序是基于有向无环图的一个算法。抽象成的数据结构如下:
public class Graph {
private int v; // 顶点的个数
private LinkedListadj[]; // 邻接表 public Graph(int v) { this.v = v; adj = new LinkedList[v]; for (int i=0; i<v; ++i) { adj[i] = new LinkedList<>(); } } public void addEdge(int s, int t) { // s先于t,边s->t adj[s].add(t); }}
二、如何在有向无环图上进行拓扑排序?
-
- Kahn算法
-
(1). 我们从图中找到入度为0的顶点,进行输出(如果一个顶点的入度为0,就意味着没有顶点先于这个顶点了,所以这个顶点就应该输出了),并且把这个顶点从图中删除,即把这个顶点可达的顶点的入度都减一;
-
(2). 然后我们重复上述过程,直到输出所有顶点,这样输出的序列就是拓扑排序之后的序列了。(输出的序列就是满足局部依赖关系的全局序列)
-
(3). 具体代码实现如下
public void topoSortByKahn() {
int[] inDegree = new int[v]; // 统计每个顶点的入度
for (int i = 0; i < v; ++i) {
for (int j = 0; j < adj[i].size(); ++j) {
int w = adj[i].get(j); // i->w
inDegree[w]++;
}
}
LinkedListqueue = new LinkedList<>();
for (int i = 0; i < v; ++i) {
if (inDegree[i] == 0) queue.add(i);
}
while (!queue.isEmpty()) {
int i = queue.remove();
System.out.print("->" + i);
for (int j = 0; j < adj[i].size(); ++j) {
int k = adj[i].get(j);
inDegree[k]--;
if (inDegree[k] == 0) queue.add(k);
}
}
}
-
- DFS算法
-
(1). 首先根据邻接表,构造出逆邻接表,在逆邻接表中,边s->t表示s依赖于t,也就是s后于t执行。
-
(2). 然后我们递归处理每个顶点,先输出这个顶点可以到达的所有顶点,然后在输出它自己。
-
(3). 代码实现如下:
public void topoSortByDFS() {
// 先构建逆邻接表,边s->t表示,s依赖于t,t先于s
LinkedListinverseAdj[] = new LinkedList[v];
for (int i = 0; i < v; ++i) { // 申请空间
inverseAdj[i] = new LinkedList<>();
}
for (int i = 0; i < v; ++i) { // 通过邻接表生成逆邻接表
for (int j = 0; j < adj[i].size(); ++j) {
int w = adj[i].get(j); // i->w
inverseAdj[w].add(i); // w->i
}
}
boolean[] visited = new boolean[v];
for (int i = 0; i < v; ++i) { // 深度优先遍历图
if (visited[i] == false) {
visited[i] = true;
dfs(i, inverseAdj, visited);
}
}
}private void dfs(
int vertex, LinkedListinverseAdj[], boolean[] visited) {
for (int i = 0; i < inverseAdj[vertex].size(); ++i) {
int w = inverseAdj[vertex].get(i);
if (visited[w] == true) continue;
visited[w] = true;
dfs(w, inverseAdj, visited);
} // 先把vertex这个顶点可达的所有顶点都打印出来之后,再打印它自己
System.out.print("->" + vertex);
}
三、Kahn算法和DFS算法进行拓扑排序的时间复杂度
-
- 从Kahn算法的代码中可以看出,每个顶点和每条边都被访问了一次,所以时间复杂度是O(V+E),V是顶点个数,E是边的个数
-
- 从DFS算法可以看出,每个顶点被访问两次,每条边被访问一次,所以时间复杂度也是O(V+E),V是顶点个数,E是边的个数
-
- 如果我们想知道数据库中所有用户的推荐关系之间,有没有存在环,就可以使用拓扑排序,把用户之间的的推荐关系从数据库加载到内存中,构建成今天所讲的这种有向图数据结构,再利用拓扑排序,就可以很快检测出是否存在环了。
第三十二章 最短路径
第三十三章 位图
最后编辑于:2024-10-27 15:08:47
© 著作权归作者所有,转载或内容合作请联系作者

喜欢的朋友记得点赞、收藏、关注哦!!!