一、为什么需要日志分析系统?
日志主要包括系统日志、应用程序日志和安全日志。系统运维和开发人员可以通过日志了解服务器软硬件信息、检查配置过程中的错误及错误发生的原因。经常分析日志可以了解服务器的负荷,性能安全性,从而及时采取措施纠正错误
往往单台机器的日志我们使用 grep、awk 等工具就能基本实现简单分析,但是当日志被分散的储存不同的设备上。如果你管理数十上百台服务器,你还在使用依次登录每台机器的传统方法查阅日志。这样是不是感觉很繁琐和效率低下。
如果:
• 你有很多台机器
• 你有各种各样的Log
只要满足这两个条件其中之一,那么一套日志系统是很有必要的。优秀的日志系统可以让你及时发现问题,轻松追查故障原因,进而提高生产力。
二、什么是 ELK
ELK 即 elasticsearch + logstash + kibana,ELK 平台是一套完整的日志集中处理解决方案,将 ElasticSearch、Logstash 和 Kiabana 三个开源工具配合使用, 完成更强大的用户对日志的查询、排序、统计需求。

Logstash:用于收集并处理日志,将日志信息存储到Elasticsearch里面Elasticsearch:用于存储收集到的日志信息Kibana:通过Web端的可视化界面来查看日志(数据可视化)
ELK 的工作原理
- 在所有需要收集日志的服务器上部署
Logstash;或者先将日志进行集中化管理在日志服务器上,在日志服务器上部署Logstash。 Logstash收集日志,将日志格式化并输出到Elasticsearch中。Elasticsearch对格式化后的数据进行索引和存储。Kibana从 ES 群集中查询数据生成图表,并进行前端数据的展示。
三、搭建 ELK
1.安装 elasticsearch
https://blog.csdn.net/ShockChen7/article/details/142760578
2.安装kibana
https://blog.csdn.net/ShockChen7/article/details/142760578
3.安装logstash
1.拉取 logstash镜像
bash
docker pull logstash:8.8.1 2.创建并运行容器
使用以下命令创建一个新的 logstash 容器并将其启动:
typescript
docker run --name some-logstash \
-e ES_JAVA_OPTS="-Xms1g -Xmx2g" \
-e TZ=Asia/Shanghai \
-p 5044:5044 \
-p 5000:5000 \
-d logstash:8.8.1 创建挂载目录、复制数据卷
bash
mkdir -vp /root/my-logstash
#赋于权限
sudo chown -R 1000:1000 /root/my-logstash
#复制数据卷
docker cp some-logstash:/usr/share/logstash/config /root/my-logstash/
docker cp some-logstash:/usr/share/logstash/pipeline /root/my-logstash/注:下载的包一定要和 ElasticSearch 的版本一致,我这边选择的版本是8.8.1
3.配置
Logstash 的 Settings 配置文件通常是 logstash.yml,这是 Logstash 的全局配置文件,用于设置 Logstash 运行的一些基本参数。
在本地编辑文件
bash
vim /root/my-logstash/config/logstash.yml在 logstash.yml 末尾加上以下配置,文件的作用是为 Logstash 配置全局参数,比如日志级别、管道线程数、队列类型等。
bash
http.host: "0.0.0.0"
xpack.monitoring.enabled: true
# xpack.monitoring.elasticsearch.username: logstash_system #es xpack账号密码
# xpack.monitoring.elasticsearch.password: "123456"
xpack.monitoring.elasticsearch.hosts: ["http://127.0.0.1:9200"]修改 logstash.conf 为以下配置,默认的基础上,将 input 的 beat 改为 tcp 端口 5044
bash
vim /root/my-logstash/pipeline/logstash.conf
bash
input {
tcp {
port => 5044
##格式json 否则中文会变成unicode编码
codec => json_lines
}
}
output {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "my_log-%{+YYYY.MM.dd}"
#user => "elastic" #es xpack账号密码
#password => "changeme"
}
}注意 :如果你的 es 运行在 docker 中,这里的配置中包括上面的,不能是 localhost ,而应该是你 docker 容器的 IP
使用命令可以查看指定容器的IP
bash
docker inspect -f '{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' your_container_name另一种做法是将
es和logstash和kibana放在同一个docker网络中
4.停止、删除容器
bash
docker stop some-logstash
docker rm some-logstash5.重新挂载文件启动容器
bash
docker run --name some-logstash \
-e ES_JAVA_OPTS="-Xms1g -Xmx2g" \
-e TZ=Asia/Shanghai \
--restart=always --privileged=true \
-v /root/my-logstash/config:/usr/share/logstash/config \
-v /root/my-logstash/pipeline:/usr/share/logstash/pipeline \
-p 5044:5044 \
-p 5000:5000 \
-d logstash:8.8.1 6.检查可用性
检测 Docker 中的 Logstash 是否能够正常接收和打印消息
四、springboot项目集成
1.添加logstash依赖
xml
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>7.0.1</version>
</dependency>2.准备logback-spring.xml文件
放在 src/main/resources 下面即可:
xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<include resource="org/springframework/boot/logging/logback/base.xml" />
<appender name="LOGSTASH" class="net.logstash.logback.appender.LogstashTcpSocketAppender">
<!-- 此处填写的是logstash采集日志的端口 -->
<destination>192.168.11.131:5044</destination>
<encoder charset="UTF-8" class="net.logstash.logback.encoder.LogstashEncoder" />
</appender>
<root level="INFO">
<!-- 配置哪个级别使用该appender -->
<appender-ref ref="LOGSTASH" />
</root>
</configuration>Spring Boot 官方推荐优先使用带有 -spring 的文件名作为你的日志配置(如使用 logback-spring.xml ,而不是 logback.xml ),命名为 logback-spring.xml 的日志配置文件,spring boot 可以为它添加一些spring boot 特有的配置项
3.进行测试
java
package com.ruoyi.web;
import com.ruoyi.common.utils.http.HttpUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class Test {
private static final Logger log = LoggerFactory.getLogger(HttpUtils.class);
public static void main(String[] args) {
log.info("输出info");
log.debug("输出debug");
log.error("输出error");
}
}五、查看日志
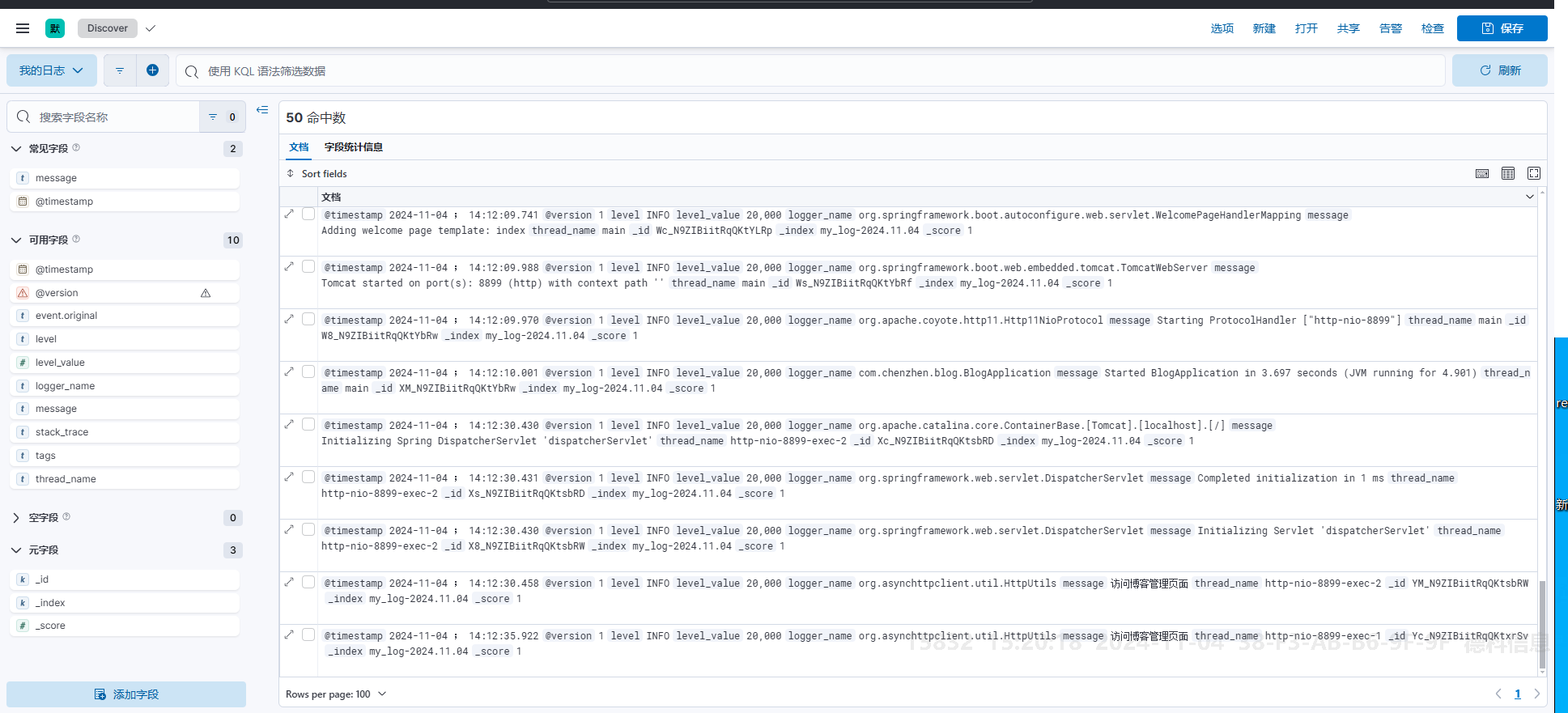
使用Kibana的开发者工具
在 Kibana 开发者工具中执行如下语句可以查看到对应日志记录:
bash
GET my_log-2024.11.01/_search
{
"query": {
"match_all": {}
}
}查询结果如下:
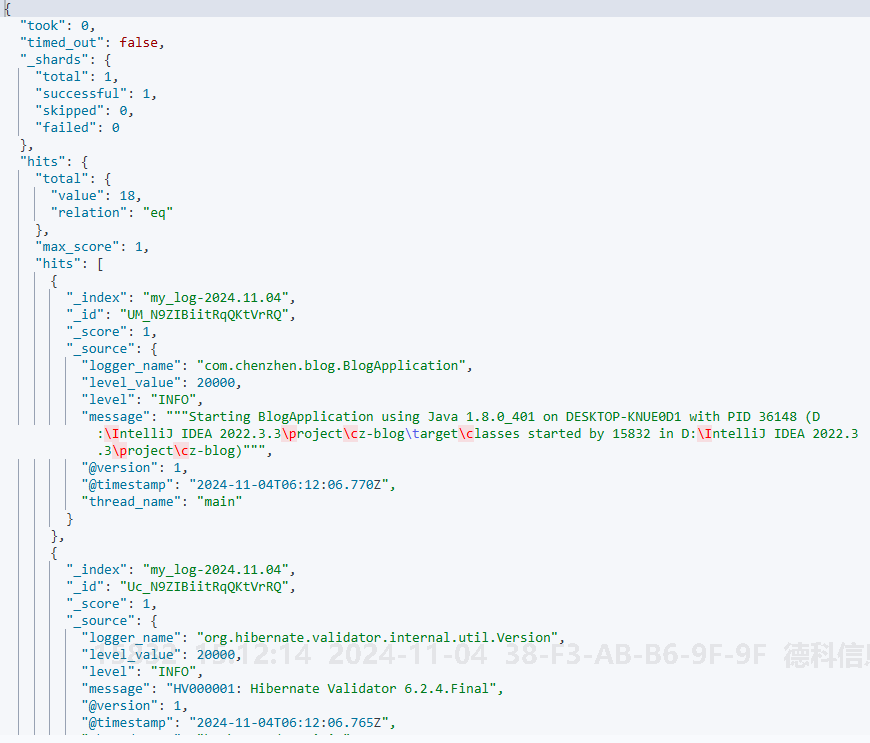
可以看到,这里的数据即我们代码中测试的相关日志。但这里的结果并不方便观察和整理。并且时间格式也不理想,时区也并不是北京时间。
使用 Kibana 的 Discover 功能
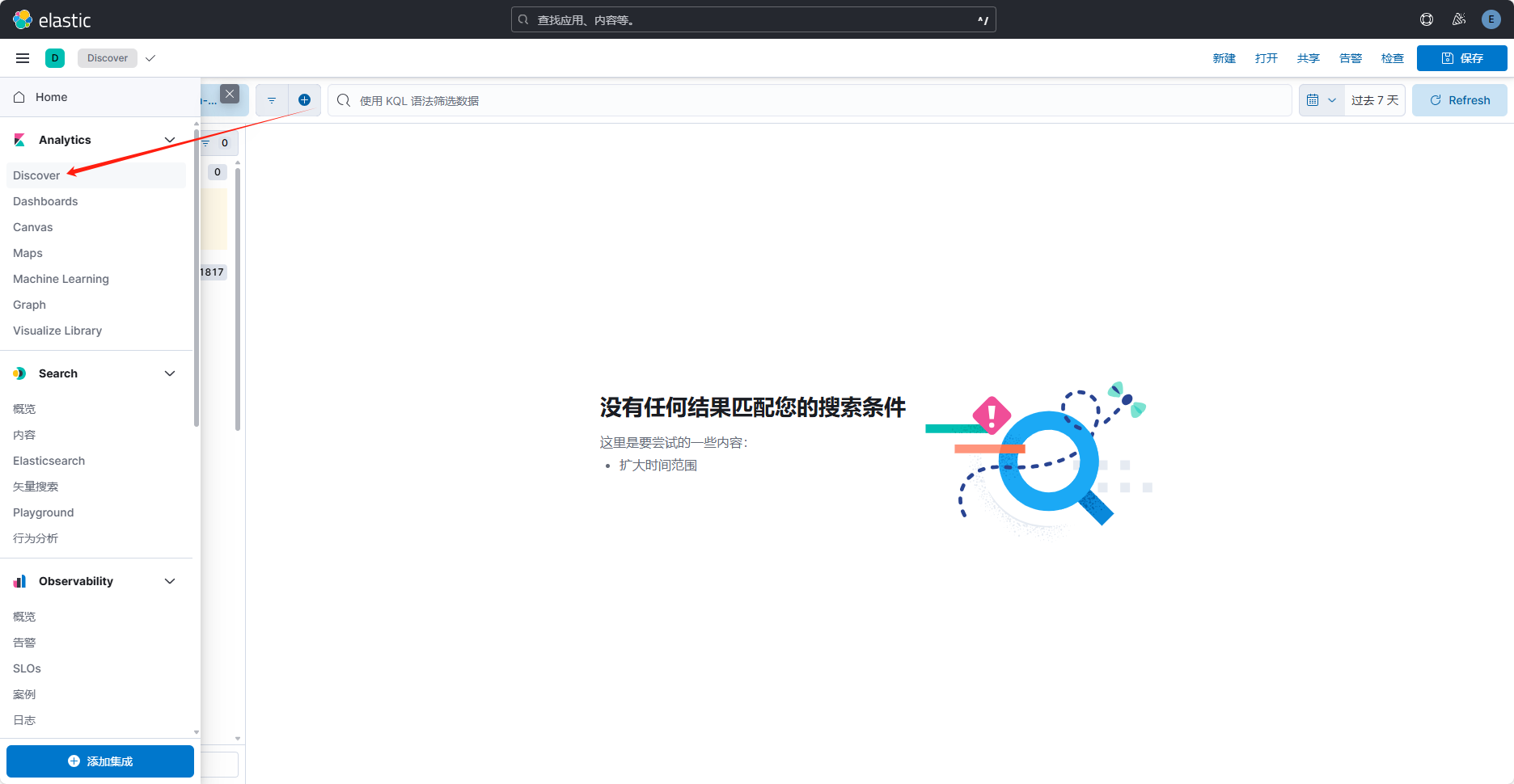
进入后创建一个数据视图:
创建时,输入名称,和索引模式即可:
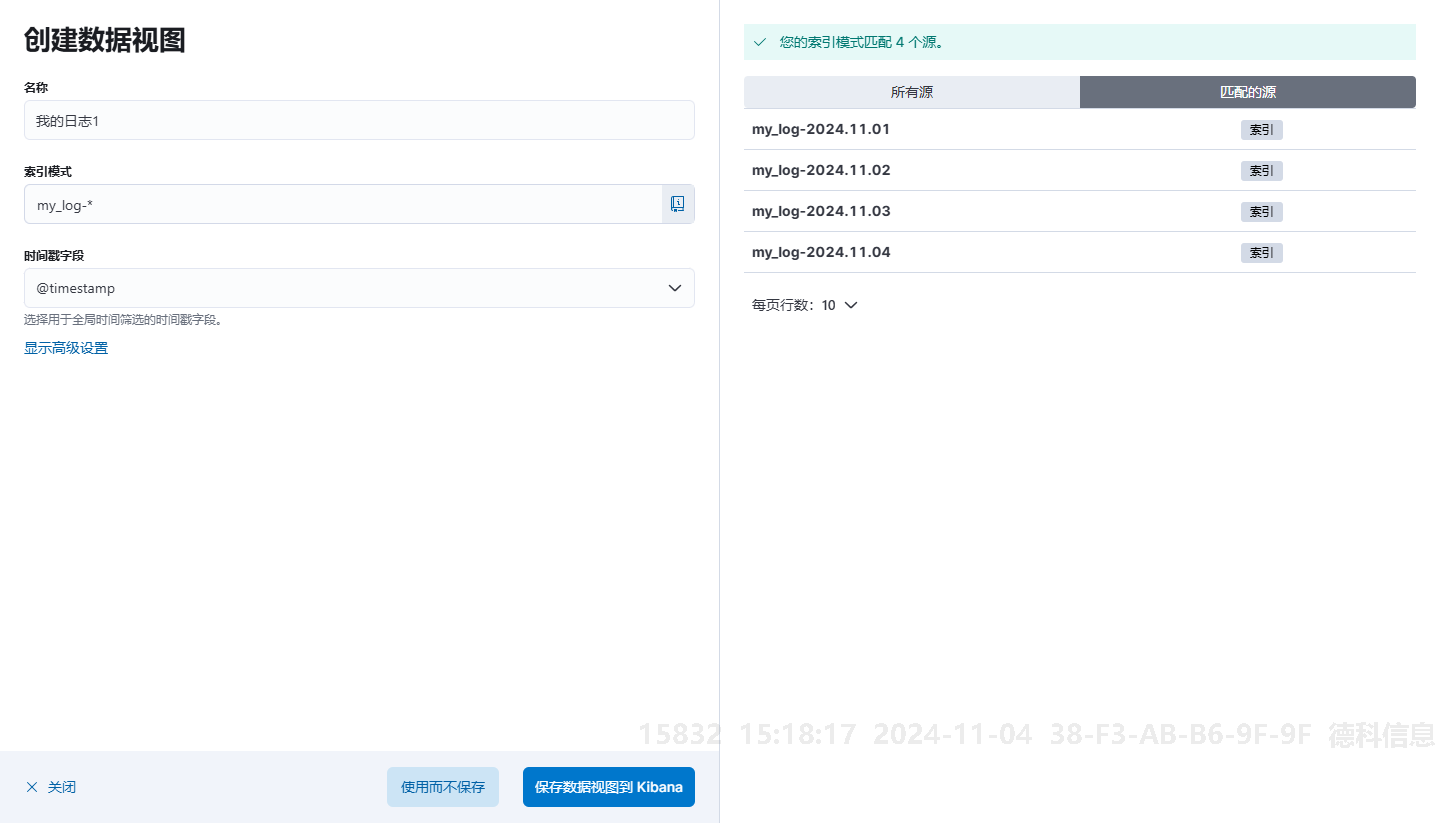
这里的索引模式需要和匹配的源对应,支持通配符,上图即使用 * 通配符创建。填写好后, 点击保存数据视图到 Kibana。
创建好的数据视图如下:
六、添加es动态模板
根据上面的 logstash.conf 配置文件,动态生成的索引。数据结构除了 @timestamp 字段为date类型,其他的都将默认声明为 text 类型,即都将分词。如下:
bash
GET my_log-2024.11.04/_mapping
bash
{
"my_log-2024.11.04": {
"mappings": {
"properties": {
"@timestamp": {
"type": "date"
},
"@version": {
"type": "long"
},
"level": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"level_value": {
"type": "long"
},
"logger_name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"message": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"thread_name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
}这会导致浪费大量的空间和性能,比如我们的 logger_name 、thread_name 和 level 字段,完全没有必要进行分词,精准查找即可,所以现在我们需要在 logstash 上传日志到es时,精准的建立字段的类型。这里采用es动态索引模板的方式。
使用 Kibana 开发者工具执行如下指令,创建索引模板:
bash
PUT /_index_template/my_log_template
{
"index_patterns": ["my_log-*"],
"template": {
"mappings": {
"properties": {
"@timestamp": {
"type": "date"
},
"data": {
"type": "text" ,
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"level": {
"type": "keyword"
},
"logger_name": {
"type": "keyword"
},
"thread_name": {
"type": "keyword"
}
}
}
}
}这个模板将自动应用于任何以 my_log- 开头的新索引。当让适用于以 my_log- 开头的索引名称。如果字段名称可以和模板对应上,那么字段类型将跟模板一致。
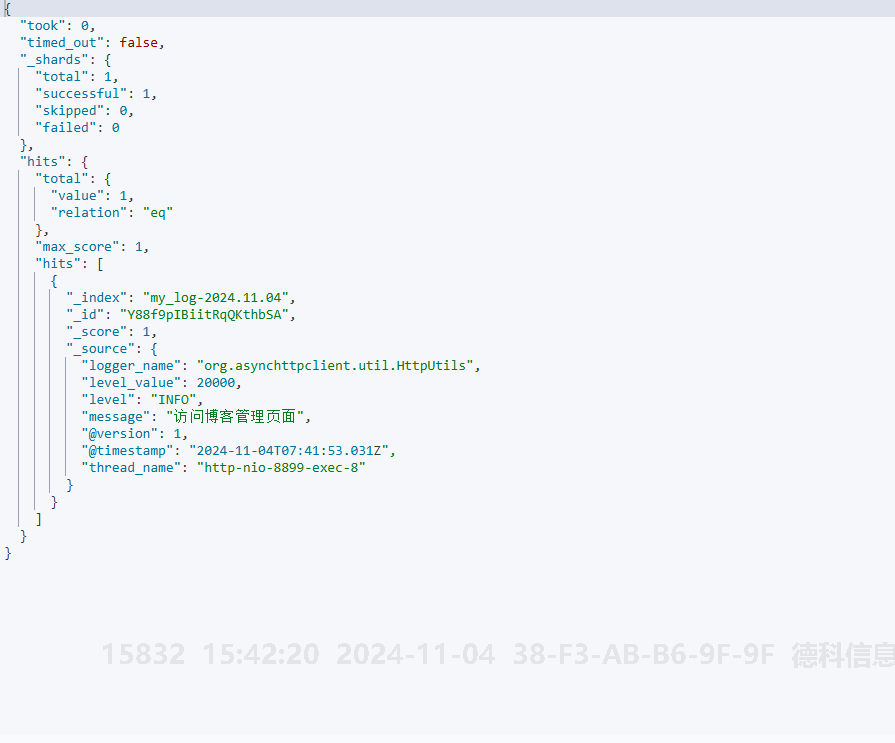
创建模板后,再次测试日志插入,查看类型,发现模板已经生效:
参考文章如下: