
LLM评估是指在人工智能系统中评估和改进语言和语言模型的过程。在人工智能领域,特别是在自然语言处理(NLP)及相关领域,LLM评估具有至高无上的地位。通过评估语言生成和理解模型,LLM评估有助于细化人工智能驱动的语言相关任务和应用程序,确保在语言发挥关键作用的各种场景中增强准确性和适应性。

LLM大模型CI Devops与传统软件的不同之处
随着大模型的版本升级和应用的持续,对大模型的评估也绝非一次性,而是需要多次迭代的过程。建立一个有效的、可持续的评估过程非常重要。如今,许多大模型服务通过LLMOps实现了CI、CE、CD(持续集成、持续评估、持续部署),大大提高了大模型的可用性。
评测框架
为评估大模型在不同应用程序中的质量,可以借鉴一些有效的项目。下面列举了一些受到广泛认可框架,如:Microsoft Azure AI Studio中的Prompt Flow、结合LangChain的Weights Biases、LangChain的LangSmith、Confidence-ai的DeepEval、TruEra等等。
1)Azure AI Studio(Microsoft)
Azure AI Studio是一个用于构建、评估和部署AGI以及自定义Copilots的一体化AI平台。



自行索取资料:
Evaluation of generative AI applications with Azure AI Studio - Azure AI Studio | Microsoft Learn
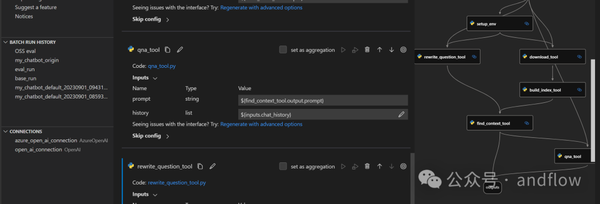
2)Prompt Flow (Microsoft)
Prompt Flow是一套用于简化基于LLM的人工智能应用的开发工具,缩短端到端的开发周期,支持从构思、原型设计、测试和评估到生产、部署和监控的一体化开发流程。它还提供了一个VS Code扩展,基于UI的交互式流程设计器。
自行索取资料:
Quick start --- Prompt flow documentation (microsoft.github.io)
3)Weights & Biases(Weights & Biases)
这是一个机器学习平台,用于快速跟踪实验、对数据集进行版本和迭代、评估模型性能、复制模型、可视化结果和发现回归,并与同事共享成果。

自行索取资料:
W&B Docs | Weights & Biases Documentation (wandb.ai)
https://docs.wandb.ai/tutorials
https://learn.deeplearning.ai/evaluating-debugging-generative-ai
https://docs.wandb.ai/tutorials
4)LangSmith (LangChain)
可以帮助用户跟踪和评估大语言模型的应用和AI Agent,以帮助用户实现从大模型的原型到生产环境。

自行索取资料:
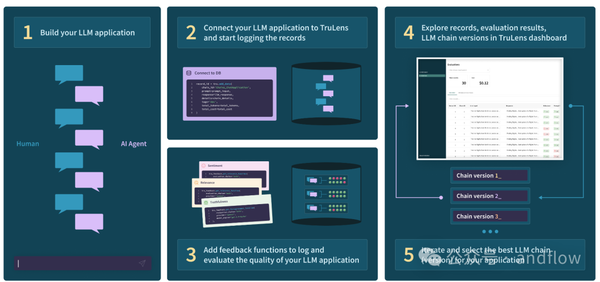
5)TruLens (TruEra)
TruLens提供了一套用于开发和监控神经网络(包括LLM)的工具。可以使用TruLens-Eval评估LLM和基于LLM的应用程序,以及使用TruLens-Explain的深度学习可解释性。
自行索取资料:
GitHub - truera/trulens: Evaluation and Tracking for LLM Experiments
https://www.trulens.org/trulens_eval/getting_started/
https://learn.deeplearning.ai/building-evaluating-advanced-rag
6)Vertex AI Studio (Google)
Vertex AI Studio可以用于评估通用大模型和优化后的生成式AI模型的性能。它使用一组指标对您提供的评估数据集对模型进行评估。

自行索取资料:
https://cloud.google.com/vertex-ai?hl=zh
https://cloud.google.com/vertex-ai/docs/generative-ai/models/evaluate-models?hl=zh-cn
7)Amazon Bedrock
Amazon Bedrock支持用于大模型的评估。模型评估作业的执行结果可以用于对比选型,帮助选择最适合下游生成式AI模型。模型评估作业支持大型语言模型(LLM)的常见功能,例如:文本生成、文本分类、问答和文本摘要等。
自行索取资料:
https://docs.aws.amazon.com/bedrock/latest/userguide/what-is-bedrock.html
https://docs.aws.amazon.com/bedrock/latest/userguide/model-evaluation.html
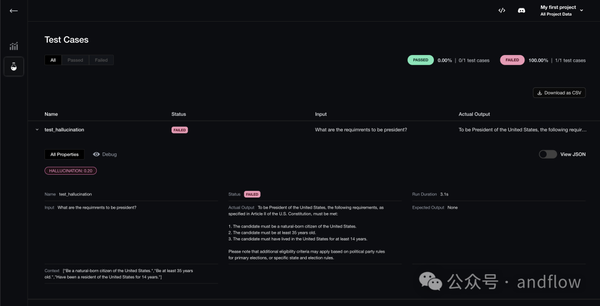
8)DeepEval (Confident AI)
这是一个用于评估LLM的开源框架。它类似于Pytest,但专门用于单元测试LLM输出。DeepEval结合了最新的研究,根据G-Eval,幻象,答案相关性,RAGAS等指标评估LLM输出,它使用LLM和其他各种NLP模型,在您的机器上本地运行以进行评估。无论您的应用程序是通过RAG或微调,LangChain或LlamaIndex实现的,DeepEval都可以覆盖您。有了它,你可以轻松地确定最佳超参数,以改善你的RAG管道,防止即时漂移,甚至可以放心地从OpenAI过渡到托管你自己的Llama2。
自行索取资料:
https://github.com/confident-ai/deepeval
https://github.com/confident-ai/deepeval/tree/main/examples
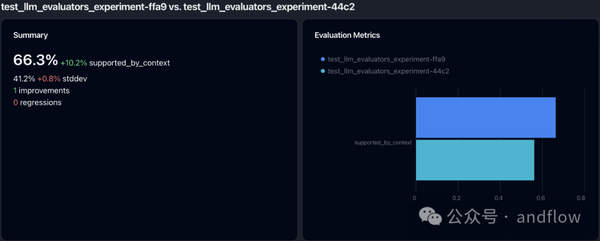
9)Parea AI
Parea可以帮助AI工程师构建可靠的、可落地的LLM应用程序。Parea提供了用于调试、测试、评估和监控基于LLM的应用程序。
自行索取资料:
https://docs.parea.ai/evaluation/overview
https://docs.parea.ai/blog/eval-metrics-for-llm-apps-in-prod
10)test-suite-sql-eval
test-suite-sql-eval是一个开源的基于精简测试集的Text-to-SQL语义评估框架。项目包含11个文本到SQL任务的测试套件评估指标。与现有的其他度量方法相比,该方法能够有效地计算语义准确度的上界。在我们的EMNLP 2020论文中提出了这一点:使用蒸馏测试套件对文本到SQL进行语义评估。
自行索取资料:
https://github.com/taoyds/test-suite-sql-eval
11)RAGAs
Ragas是一个可帮助评估检索增强生成(RAG)的框架。RAG表示一类使用外部数据来增强LLM上下文的LLM应用程序。现有的工具和框架可以帮助您构建这些管道,但评估它并量化管道性能可能很困难。这就是Ragas(RAG评估)的用武之地。
自行索取资料:
https://github.com/explodinggradients/ragas
12)ARES
这是一个检索增强生成(RAG)系统的自动评估框架。