数据库的概念
数据库是"按照数据结构来组织、存储和管理数据的仓库"。是一个长期存储在计算机内的、有组织的、可共享的、统一管理的大量数据的集合。
数据库是存放数据的仓库。它的存储空间很大,可以存放百万条、千万条、上亿条数据。但是数据库并不是随意地将数据进行存放,是有一定的规则的,否则查询的效率会很低。当今世界是一个充满着数据的互联网世界,充斥着大量的数据。即这个互联网世界就是数据世界。数据的来源有很多,比如出行记录、消费记录、浏览的网页、发送的消息等等。
数据库分类
常见的关系型数据库有: MySQL、SQL Server、Oracle、SQLite。
MySQL:免费产品,内存存储引擎使用较少。
SQL Server:微软的商业化产品,是为了适应大数据等业务产品新添加的存储引擎,微软SQL语句兼容性好,商业化成熟度高。
Oracle:基于内存计算的关系数据库, 提供了响应时间极短且吞吐量极高的应用程序。
SQLite :专为嵌入式设计的一款轻型的数据库,是遵守ACID的关系型数据库管理系统。
不管哪一个数据库,它的核心都是SQL语句:SQL (Structured Query Language:结构化查询语言) 是用于管理关系数据库管理系统(RDBMS)。 SQL 的范围包括数据插入、查询、更新和删除,数据库模式创建和修改,以及数据访问控制。所以,学习的重点应该放到如何利用SQL语句进行操作数据库。
数据库安装
下面以SQLite数据库为例,来进行学习。SQLite是一个软件库,实现了自给自足的、无服务器的、零配置的、事务性的 SQL 数据库引擎。SQLite安装步骤如下:
- 从SQLite 下载页面,下载Windows 区预编译的二进制文件。下载 sqlite-tools-win32-*.zip。
- 创建文件夹
C:\bin,并在此文件夹下解压上面的压缩文件。 - 添加
C:\bin到系统的环境变量即可。
添加环境变量的方法:
- 右键
此电脑,点击属性。桌面上没有的可以在资源管理器找到。
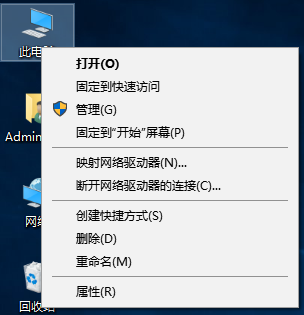
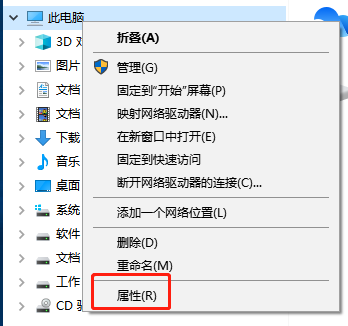
- 找到
高级系统设置选项。
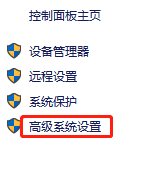
- 点击环境变量。
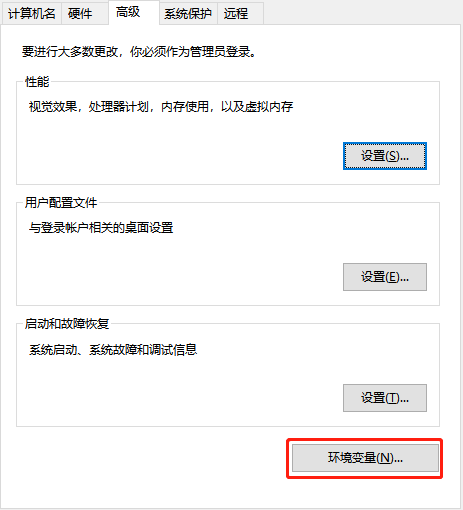
- 找到
Path,然后点编辑。
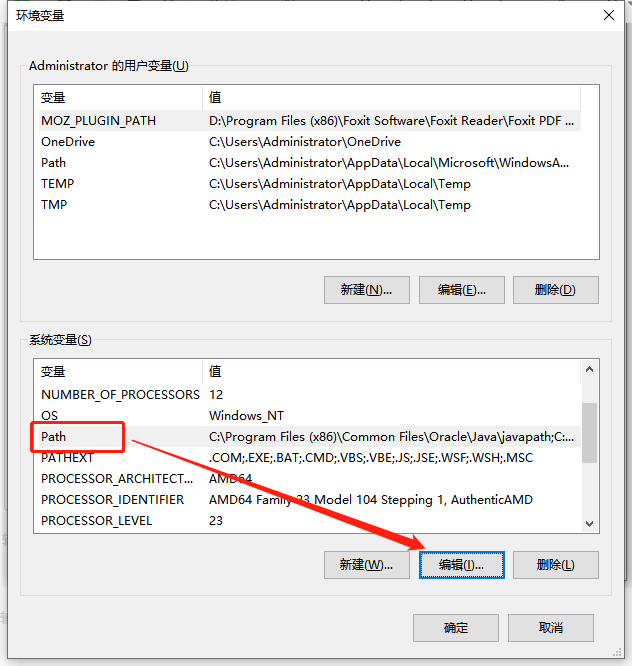
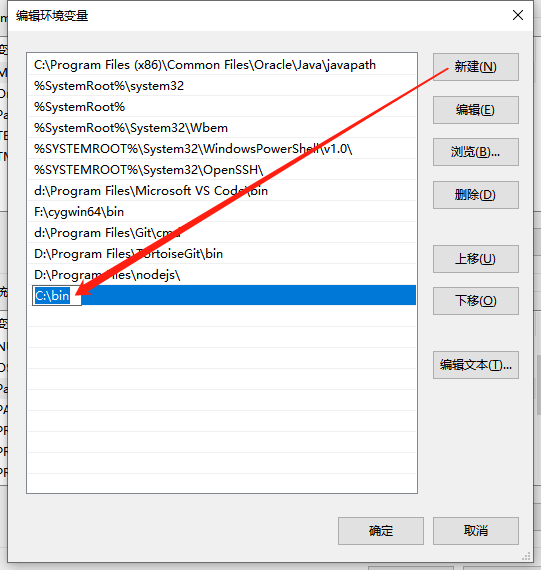
- 点击
新建,增加解压的目录,然后点确定即可。
SQLite命令
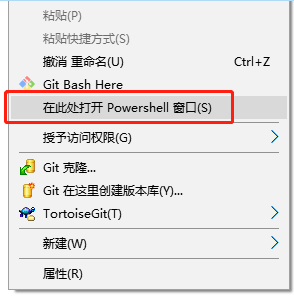
在任意位置建立一个工作目录,然后在文件夹内按住Shift键,点击鼠标右键,会出现PowerShell选项,点击打开(如果没有PowerShell,使用cmd也可)。
在命令提示符下键入 sqlite3,在 SQLite命令提示符下,可以使用各种 SQLite 命令。
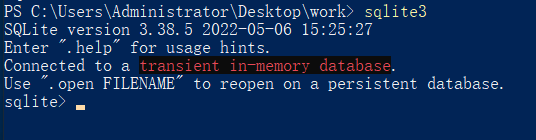
SQLite的命令都是以.开头的,比如输入.help即可查看命令的帮助文档。
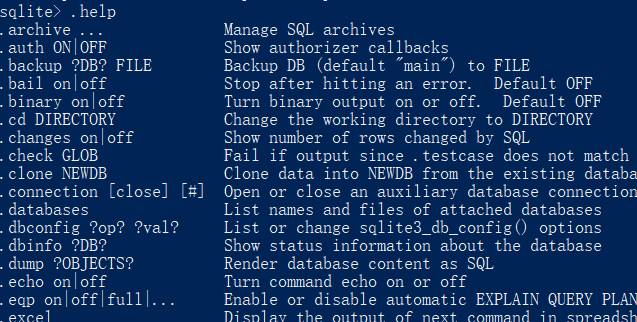
注:清屏的命令是clear或者cls
常用的命令集合
help:打开帮助
quit:退出SQLite 命令提示符
database:显示当前打开的数据库文件
tables:显示数据库中所有表名
schema <table_name>:查看表的结构
mode column:列模式显示
header on:打开表头
SQLite 数据类型
|---------|-------------------------------------------------|
| 存储类 | 描述 |
| NULL | 值是一个 NULL 值。 |
| INTEGER | 值是一个带符号的整数,根据值的大小存储在 1、2、3、4、6 或 8 字节中。 |
| REAL | 值是一个浮点值,存储为 8 字节的 IEEE 浮点数字。 |
| TEXT | 值是一个文本字符串,使用数据库编码(UTF-8、UTF-16BE 或 UTF-16LE)存储。 |
| BLOB | 值是一个 blob 数据,完全根据它的输入存储。 |
数据库操作
创建数据库
数据库本质就是一个文件,通常以db作为后缀名。使用sqlite3 命令来创建,可以在打开sqlite命令提示符之前就创建,命令如下:
$ sqlite3 test.db也可以打开后使用.open 命令来创建。
sqlite>.open test.db以上两种方式,如果test.db 存在则直接会打开,不存在就创建它。
数据库和表
数据库是个文件,而表其实就是文件里存储数据的容器。可以把数据库理解为excel文件,而表就是excel中一张张数据表,一个数据库可以有多张数据库表。
SQL语句
不管哪一个数据库,它的核心都是SQL语句,SQL语句可以理解为数据库标准,不管哪种数据库都要支持。
- sqlite中SQL语句不需要以
.开头,正常输入的内容都会被当成SQL语句解析。 - SQL语句的关键字不区分大小写,但是通常约定俗成会以大写来书写关键字。
- SQL语句在sqlite命令终端以分号结尾,如果未键入
;敲回车,终端会继续等待键入。
创建表
语法
CREATE TABLE database_name.table_name(
column1 datatype PRIMARY KEY,
column2 datatype NOT NULL,
column3 datatype,
.....
columnN datatype,
);PRIMARY KEY表示主键,能唯一确定一条数据表记录,类似与人的身份证,不一定非要有。
NOT NULL的约束表示在表中创建纪录时这些字段不能为 NULL。
如果表不存在,再创建
CREATE TABLE if not exists student(xxx)实例
下面是一个实例,它创建了一个 COMPANY表,ID 作为主键,NOT NULL 的约束表示在表中创建纪录时这些字段不能为 NULL:
CREATE TABLE COMPANY(
ID INTEGER PRIMARY KEY,
NAME TEXT NOT NULL,
AGE INTEGER NOT NULL,
ADDRESS TEXT,
SALARY REAL
);可以使用 sqlite命令中的.tables命令来验证表是否已成功创建,该命令用于列出附加数据库中的所有表。
sqlite>.tables
COMPANY在这里,可以看到我们刚创建的两张表 COMPANY。
可以使用 .schema 命令得到表的完整信息,如下所示:
sqlite> .schema
CREATE TABLE COMPANY(
ID INTEGER PRIMARY KEY,
NAME TEXT NOT NULL,
AGE INTEGER NOT NULL,
ADDRESS TEXT,
SALARY REAL
);删除表
语法
DROP TABLE table_name;实例
sqlite>DROP TABLE COMPANY;插入语句
语法
INSERT INTO TABLE_NAME [(column1, column2, column3,...columnN)]
VALUES (value1, value2, value3,...valueN);以上是对指定列添加值,如果对所有列添加,可以不写列名。但要确保值的顺序与列在表中的顺序一致。
INSERT INTO TABLE_NAME VALUES (value1,value2,value3,...valueN);实例
INSERT INTO COMPANY (ID,NAME,AGE)
VALUES (1, 'Paul', 32);
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (2, 'Allen', 25, 'Texas', 15000.00 );
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (3, 'Teddy', 23, 'Norway', 20000.00 );
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (4, 'Mark', 25, 'Rich-Mond ', 65000.00 );
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (5, 'David', 27, 'Texas', 85000.00 );
INSERT INTO COMPANY (ID,NAME,AGE,ADDRESS,SALARY)
VALUES (6, 'Kim', 22, 'South-Hall', 45000.00 );或者
INSERT INTO COMPANY VALUES (7, 'James', 24, 'Houston', 10000.00 );查询语句
语法
SELECT column1, column2, columnN FROM table_name;如果要查询所有的数据,可以用下面的语句。
SELECT * FROM table_name;实例
可以使用前面的命令先对输出内容做格式化调整。
sqlite>.header on
sqlite>.mode column然后使用查询命令:
SELECT ID, NAME, SALARY FROM COMPANY;运算符
运算符用于指定 SQLite 语句中的条件,并在语句中连接多个条件。运算符分为:
- 算术运算符
- 比较运算符
- 逻辑运算符
- 位运算符
注:此部分作为参考手册,无需记忆,用到时候回来自查即可。
算术运算符
假设变量 a=10,变量 b=20,则:
|-----|-----------------------|----------------|
| 运算符 | 描述 | 实例 |
| + | 加法 - 把运算符两边的值相加 | a + b 将得到 30 |
| - | 减法 - 左操作数减去右操作数 | a - b 将得到 -10 |
| * | 乘法 - 把运算符两边的值相乘 | a * b 将得到 200 |
| / | 除法 - 左操作数除以右操作数 | b / a 将得到 2 |
| % | 取模 - 左操作数除以右操作数后得到的余数 | b % a 将得到 0 |
select 10 + 20;比较运算符
假设变量 a=10,变量 b=20,则:
|------|--------------------------------|----------------|
| 运算符 | 描述 | 实例 |
| == | 检查两个操作数的值是否相等,如果相等则条件为真。 | (a == b) 不为真。 |
| = | 检查两个操作数的值是否相等,如果相等则条件为真。 | (a = b) 不为真。 |
| != | 检查两个操作数的值是否相等,如果不相等则条件为真。 | (a != b) 为真。 |
| <> | 检查两个操作数的值是否相等,如果不相等则条件为真。 | (a <> b) 为真。 |
| > | 检查左操作数的值是否大于右操作数的值,如果是则条件为真。 | (a > b) 不为真。 |
| < | 检查左操作数的值是否小于右操作数的值,如果是则条件为真。 | (a < b) 为真。 |
| >= | 检查左操作数的值是否大于等于右操作数的值,如果是则条件为真。 | (a >= b) 不为真。 |
| <= | 检查左操作数的值是否小于等于右操作数的值,如果是则条件为真。 | (a <= b) 为真。 |
| !< | 检查左操作数的值是否不小于右操作数的值,如果是则条件为真。 | (a !< b) 为假。 |
| !> | 检查左操作数的值是否不大于右操作数的值,如果是则条件为真。 | (a !> b) 为真。 |
select 10==20;逻辑运算符
|---------|-------------------------------------------------------------------|
| 运算符 | 描述 |
| AND | AND 运算符允许在一个 SQL 语句的 WHERE 子句中的多个条件的存在。 |
| BETWEEN | BETWEEN 运算符用于在给定最小值和最大值范围内的一系列值中搜索值。 |
| EXISTS | EXISTS 运算符用于在满足一定条件的指定表中搜索行的存在。 |
| IN | IN 运算符用于把某个值与一系列指定列表的值进行比较。 |
| NOT IN | IN 运算符的对立面,用于把某个值与不在一系列指定列表的值进行比较。 |
| LIKE | LIKE 运算符用于把某个值与使用通配符运算符的相似值进行比较。 |
| GLOB | GLOB 运算符用于把某个值与使用通配符运算符的相似值进行比较。GLOB 与 LIKE 不同之处在于,它是大小写敏感的。 |
| NOT | NOT 运算符是所用的逻辑运算符的对立面。比如 NOT EXISTS、NOT BETWEEN、NOT IN,等等。它是否定运算符。 |
| OR | OR 运算符用于结合一个 SQL 语句的 WHERE 子句中的多个条件。 |
| IS NULL | NULL 运算符用于把某个值与 NULL 值进行比较。 |
| IS | IS 运算符与 = 相似。 |
| IS NOT | IS NOT 运算符与 != 相似。 |
| || | 连接两个不同的字符串,得到一个新的字符串。 |
| UNIQUE | UNIQUE 运算符搜索指定表中的每一行,确保唯一性(无重复)。 |
位运算符
|---|---|--------|--------|
| p | q | p & q | p | q |
| 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 1 |
| 1 | 1 | 1 | 1 |
| 1 | 0 | 0 | 1 |
条件查询
SQLite的 WHERE 子句用于指定从一个表或多个表中获取数据的条件。
如果满足给定的条件,即为真(true)时,则从表中返回特定的值。可以使用 WHERE 子句来过滤记录,只获取需要的记录。
语法
SELECT column1, column2, columnN
FROM table_name
WHERE [condition]可以使用比较或逻辑运算符指定条件,比如 >、<、=、LIKE、NOT,等等。
实例
列出 AGE 大于等于 25 且工资大于等于 65000.00 的所有记录:
SELECT * FROM COMPANY WHERE AGE >= 25 AND SALARY >= 65000;列出 AGE 大于等于 25 或工资大于等于 65000.00 的所有记录:
SELECT * FROM COMPANY WHERE AGE >= 25 OR SALARY >= 65000;下面的 SELECT 语句列出了 AGE 不为 NULL 的所有记录,结果显示所有的记录,意味着没有一个记录的 AGE 等于 NULL
SELECT * FROM COMPANY WHERE AGE IS NOT NULL;下面的 SELECT 语句列出了 AGE 的值为 25 或 27 的所有记录:
SELECT * FROM COMPANY WHERE AGE IN ( 25, 27 );下面的 SELECT 语句列出了 AGE 的值既不是 25 也不是 27 的所有记录:
SELECT * FROM COMPANY WHERE AGE NOT IN ( 25, 27 );下面的 SELECT 语句列出了 AGE 的值在 25 与 27 之间的所有记录:
SELECT * FROM COMPANY WHERE AGE BETWEEN 25 AND 27;数据更新
语法
UPDATE table_name
SET column1 = value1, column2 = value2...., columnN = valueN
WHERE [condition];可以使用 AND 或 OR 运算符来结合 N 个数量的条件。
实例
更新 ID 为 6 的客户地址:
UPDATE COMPANY SET ADDRESS = 'Texas' WHERE ID = 6;修改 COMPANY 表中 ADDRESS 和 SALARY 列的所有值,则不需要使用 WHERE 子句,UPDATE 查询如下:
UPDATE COMPANY SET ADDRESS = 'Texas', SALARY = 20000.00;数据删除
SQLite 的 DELETE 查询用于删除表中已有的记录。可以使用带有 WHERE 子句的 DELETE 查询来删除选定行,否则所有的记录都会被删除。
语法
DELETE FROM table_name
WHERE [condition];可以使用 AND 或 OR 运算符来结合 N 个数量的条件。
实例
删除 ID 为 7 的客户
DELETE FROM COMPANY WHERE ID = 7;想要从 COMPANY 表中删除所有记录,则不需要使用 WHERE 子句
DELETE FROM COMPANY;Like子句
SQLite 的 LIKE 运算符是用来匹配通配符指定模式的文本值。如果搜索表达式与模式表达式匹配,LIKE 运算符将返回真(true),也就是 1。这里有两个通配符与 LIKE 运算符一起使用:
- 百分号 (%)
- 下划线 (_)
百分号(%)代表零个、一个或多个数字或字符。下划线(_)代表一个单一的数字或字符。这些符号可以被组合使用。
语法
SELECT column_list
FROM table_name
WHERE column LIKE 'XXXX%'
or
SELECT column_list
FROM table_name
WHERE column LIKE '%XXXX%'
or
SELECT column_list
FROM table_name
WHERE column LIKE 'XXXX_'
or
SELECT column_list
FROM table_name
WHERE column LIKE '_XXXX'
or
SELECT column_list
FROM table_name
WHERE column LIKE '_XXXX_'您可以使用 AND 或 OR 运算符来结合 N 个数量的条件。在这里,XXXX 可以是任何数字或字符串值。
实例
下面一些实例演示了 带有 '%' 和 '_' 运算符的 LIKE 子句不同的地方:
|---------------------------|------------------------------|
| 语句 | 描述 |
| WHERE SALARY LIKE '200%' | 查找以 200 开头的任意值 |
| WHERE SALARY LIKE '%200%' | 查找任意位置包含 200 的任意值 |
| WHERE SALARY LIKE '00%' | 查找第二位和第三位为 00 的任意值 |
| WHERE SALARY LIKE '2%_%' | 查找以 2 开头,且长度至少为 3 个字符的任意值 |
| WHERE SALARY LIKE '%2' | 查找以 2 结尾的任意值 |
| WHERE SALARY LIKE '_2%3' | 查找第二位为 2,且以 3 结尾的任意值 |
| WHERE SALARY LIKE '2___3' | 查找长度为 5 位数,且以 2 开头以 3 结尾的任意值 |
显示 COMPANY 表中 AGE 以 2 开头的所有记录:
SELECT * FROM COMPANY WHERE AGE LIKE '2%';显示 COMPANY 表中 ADDRESS 文本里包含一个连字符(-)的所有记录:
SELECT * FROM COMPANY WHERE ADDRESS LIKE '%-%';Glob 子句
SQLite 的 GLOB 运算符是用来匹配通配符指定模式的文本值。如果搜索表达式与模式表达式匹配,GLOB 运算符将返回真(true),也就是 1。与 LIKE 运算符不同的是,GLOB 是大小写敏感的,对于下面的通配符,它遵循 UNIX 的语法。
- 星号 (*)
- 问号 (?)
星号(*)代表零个、一个或多个数字或字符。问号(?)代表一个单一的数字或字符。这些符号可以被组合使用。GLOB 使用的通配符和我们后面要学习的Linux命令中用的类似。
语法
SELECT FROM table_name
WHERE column GLOB 'XXXX*'
or
SELECT FROM table_name
WHERE column GLOB '*XXXX*'
or
SELECT FROM table_name
WHERE column GLOB 'XXXX?'
or
SELECT FROM table_name
WHERE column GLOB '?XXXX'
or
SELECT FROM table_name
WHERE column GLOB '?XXXX?'
or
SELECT FROM table_name
WHERE column GLOB '????'实例
下面一些实例演示了 带有 '*' 和 '?' 运算符的 GLOB 子句不同的地方:
|-----------------------------|------------------------------|
| 语句 | 描述 |
| WHERE SALARY GLOB '200*' | 查找以 200 开头的任意值 |
| WHERE SALARY GLOB '*200*' | 查找任意位置包含 200 的任意值 |
| WHERE SALARY GLOB '?00*' | 查找第二位和第三位为 00 的任意值 |
| WHERE SALARY GLOB '2??' | 查找以 2 开头,且长度至少为 3 个字符的任意值 |
| WHERE SALARY GLOB '*2' | 查找以 2 结尾的任意值 |
| WHERE SALARY GLOB '?2*3' | 查找第二位为 2,且以 3 结尾的任意值 |
| WHERE SALARY GLOB '2???3' | 查找长度为 5 位数,且以 2 开头以 3 结尾的任意值 |
显示 COMPANY 表中 AGE 以 2 开头的所有记录
SELECT * FROM COMPANY WHERE AGE GLOB '2*';显示 COMPANY 表中 ADDRESS 文本里包含一个连字符(-)的所有记录:
SELECT * FROM COMPANY WHERE ADDRESS GLOB '*-*';Limit 子句
SQLite 的 LIMIT 子句用于限制由 SELECT 语句返回的数据数量。
基本语法
SELECT column1, column2, columnN
FROM table_name
LIMIT [num]与 OFFSET 子句一起使用时的语法:
SELECT column1, column2, columnN
FROM table_name
LIMIT [no of rows] OFFSET [row num]实例
限制提取的行数:
SELECT * FROM COMPANY LIMIT 6;在某些情况下,可能需要从一个特定的偏移开始提取记录。下面是一个实例,从第三位开始提取 3 个记录:
SELECT * FROM COMPANY LIMIT 3 OFFSET 2;结果排序
SQLite 的 ORDER BY 子句是用来基于一个或多个列按升序或降序顺序排列数据。
语法
SELECT column-list
FROM table_name
[WHERE condition]
[ORDER BY column1, column2, .. columnN] [ASC | DESC];ascend:上升;升高;登高
descend:下来;下去;下降;下斜;下倾;降临;来临
实例
将结果按 SALARY 升序排序
SELECT * FROM COMPANY ORDER BY SALARY ASC;将结果按 NAME 和 SALARY 升序排序:
SELECT * FROM COMPANY ORDER BY NAME, SALARY ASC;将结果按 NAME 降序排序:
SELECT * FROM COMPANY ORDER BY NAME DESC;ORDER BY 后可加2个字段,用英文逗号隔开。当第一个条件相等时,才会用第二个条件去排序。将结果按 SALARY 降序,NAME升序排列:
SELECT * FROM COMPANY ORDER BY SALARY DESC,NAME DESC;结果分组
SQLite 的 GROUP BY 子句用于与 SELECT 语句一起使用,来对相同的数据进行分组。
在 SELECT 语句中,GROUP BY 子句放在 WHERE 子句之后,放在 ORDER BY 子句之前。
语法
SELECT column-list
FROM table_name
WHERE [ conditions ]
GROUP BY column1, column2....columnN
ORDER BY column1, column2....columnN实例
统计所有员工都有地址都有哪些分类。
SELECT ADDRESS FROM COMPANY GROUP BY ADDRESS;统计每个地址的员工数,这里需要一个内置函数count。
SELECT COUNT(ADDRESS),ADDRESS FROM COMPANY GROUP BY ADDRESS ORDER BY COUNT(ID) DESC;