我自己的原文哦~https://blog.51cto.com/whaosoft/12316553
#SAFDNet
3D点云物体检测对自动驾驶感知至关重要,如何高效地从稀疏点云数据中学习特征表示是3D点云物体检测面临的一个关键挑战。我们在本文中将会介绍团队发表在NeurIPS 2023的HEDNet和CVPR 2024的SAFDNet,其中HEDNet聚焦于解决现有稀疏卷积神经网络难以捕捉远距离特征间依赖关系的问题,而SAFDNet则是基于HEDNet构建的纯稀疏点云检测器。
前世 - HEDNet
研究背景
主流方法通常将非结构化的点云转换为规则的体素,并使用稀疏卷积神经网络或Transformer来提取特征。大多数现有的稀疏卷积神经网络主要通过堆叠子流形稀疏残差(Submanifold Sparse Residual, SSR)模块构建而来,每个SSR模块包含两个采用小卷积核的子流形稀疏 (Submanifold Sparse, SS) 卷积。然而,子流形稀疏卷积要求输入和输出特征图的稀疏度保持不变,这阻碍了远距离特征间的信息交互,导致模型难以捕捉远距离特征间的依赖关系。一种可能的解决方案是将SSR模块中的子流形稀疏卷积替换为普通稀疏 (Regular Sparse, RS) 卷积。然而,随着网络深度的增加,这会显著降低特征图的稀疏度,导致计算成本大幅增加。一些研究尝试使用基于大卷积核的稀疏卷积神经网络或Transformer来捕获远距离特征间的依赖关系,但这些方法要么没能在检测精度上带来提升,要么需要更高的计算成本。综上,我们仍然缺乏一种能够高效地捕捉远距离特征间依赖关系的方法。
方法介绍
SSR模块和RSR模块
为了提升模型效率,现有的3D点云物体检测器大多采用稀疏卷积来提取特征。稀疏卷积主要包括RS卷积和SS卷积。RS卷积在计算过程中会将稀疏特征扩散到相邻区域,因而会降低特征图的稀疏度。与之相反,SS卷积则保持输入和输出特征图的稀疏度不变。由于降低特征图的稀疏度会显著增加计算成本,在现有方法中RS卷积通常仅用于特征图下采样。另一方面,大多数基于体素的方法通过堆叠SSR模块构来建稀疏卷积神经网络,以提取点云特征。每个SSR模块包含两个SS卷积和一个融合输入和输出特征图的跳跃连接。
图 1(a) 展示了单个SSR模块的结构。图中有效特征 (valid feature) 指非零特征,而空特征 (empty feature) 的值为零,代表该位置原本不包含点云。我们将特征图的稀疏度定义为空特征占据的区域面积与特征图总面积之比。在SSR模块中,输入特征图经过两个SS卷积转换后得到输出特征图,同时输入特征图的信息通过跳跃连接 (Skip conn.) 直接融合到输出特征图中。SS卷积只处理有效特征,以保证SSR模块的输出特征图与输入特征图具有相同的稀疏度。然而,这样的设计阻碍了不连通特征之间的信息交互。例如,顶部特征图中由星号标记的特征点,无法从底部特征图中位于红色虚线框外、由红色三角形标记的三个特征点接收信息,这限制了模型建模远距离特征间依赖关系的能力。
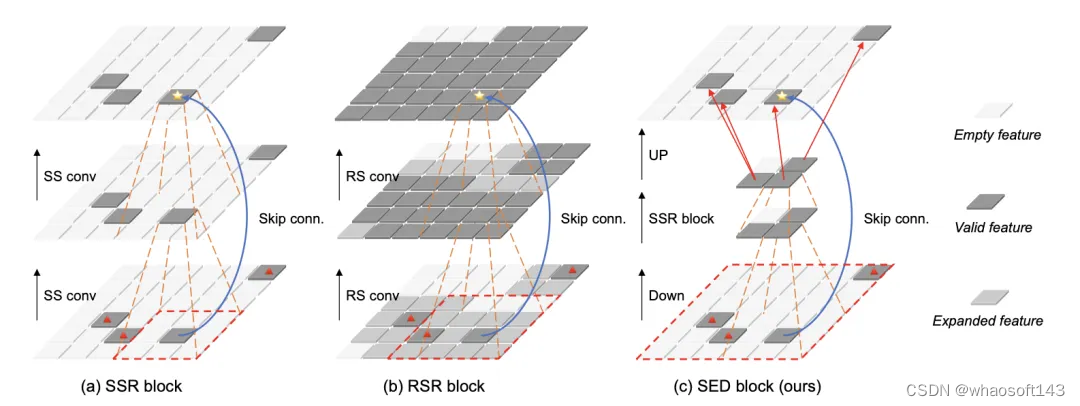
图1 SSR、RSR和SED模块结构比较
对于以上问题,一种可能的解决方案是将SSR模块中的SS卷积替换为RS卷积来捕捉远距离特征间的依赖关系。我们将这种修改后的模块称为普通稀疏残差 (Regular Sparse Residual, RSR) 模块,其结构如图 1(b) 所示。图中,待扩散特征 (expanded feature) 是有效特征邻域内的空特征。RS卷积同时处理有效特征和待扩散特征,其卷积核中心会遍历这些特征区域,这种设计导致输出特征图较输入特征图具有更低的稀疏度。堆叠RS卷积则会更加迅速地降低特征图的稀疏度,进而导致模型效率大幅降低。这也是现有方法通常仅将RS卷积用于特征图下采样的原因。这里把expanded feature翻译成待扩散特征可能有点奇怪,expanded feature是原始论文中的叫法,我们后来认为改成待扩散特征更为合适。
SED模块和DED模块
SED模块的设计目标是克服SSR模块的局限性。SED模块通过特征下采样缩短远距离特征之间的空间距离,同时通过多尺度特征融合恢复丢失的细节信息。图 1(c)展示了一个具有两个特征尺度的SED模块示例。该模块首先采用步长为3的3x3 RS卷积进行特征下采样 (Down)。特征下采样之后,底部特征图中不连通的有效特征被整合进中间特征图中相邻的有效特征内。接着,通过在中间特征图上使用一个SSR模块提取特征,来实现有效特征之间的交互。最后,上采样 (UP) 中间特征图以匹配输入特征图的分辨率。值得注意的是,这里仅上采样特征到输入特征图中有效特征所对应的区域。因此,SED模块可以维持特征图的稀疏度。
图 2(a) 展示了一个具有三个特征尺度的SED模块的具体实现方式。括号中的数字表示对应特征图的分辨率与输入特征图的分辨率之比。SED模块采用了不对称的编解码器结构,它利用编码器提取多尺度特征,并通过解码器逐步融合提取的多尺度特征。SED模块采用RS卷积作为特征下采样层,并采用稀疏反卷积 (Inverse Convolution) 作为特征上采样层。通过使用编解码器结构,SED模块促进了空间中不连通特征之间的信息交互,从而使模型能够捕获远距离特征间的依赖关系。
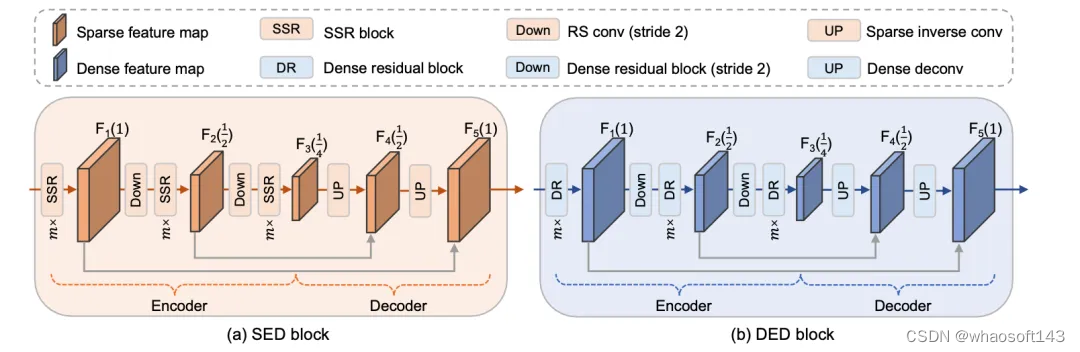
图2 SED和DED模块结构
另一方面,当前主流的3D点云检测器主要依赖于物体中心特征进行预测,但在稀疏卷积神经网络提取的特征图中,物体中心区域可能存在空洞,尤其是在大物体上。为了解决这一问题,我们提出了DED模块,其结构如图 2(b) 所示。DED模块与SED模块具有相同的结构,它将SED模块中的SSR模块替换为密集残差 (Dense Residual, DR) 模块、将用于特征下采样的RS卷积替换为步长为2的DR模块以及将用于特征上采样的稀疏反卷积替换为密集反卷积,其中DR模块与SSR模块具有相同的结构,但由两个密集卷积组成。这些设计使得DED模块能够有效地将稀疏特征向物体中心区域扩散。
HEDNet
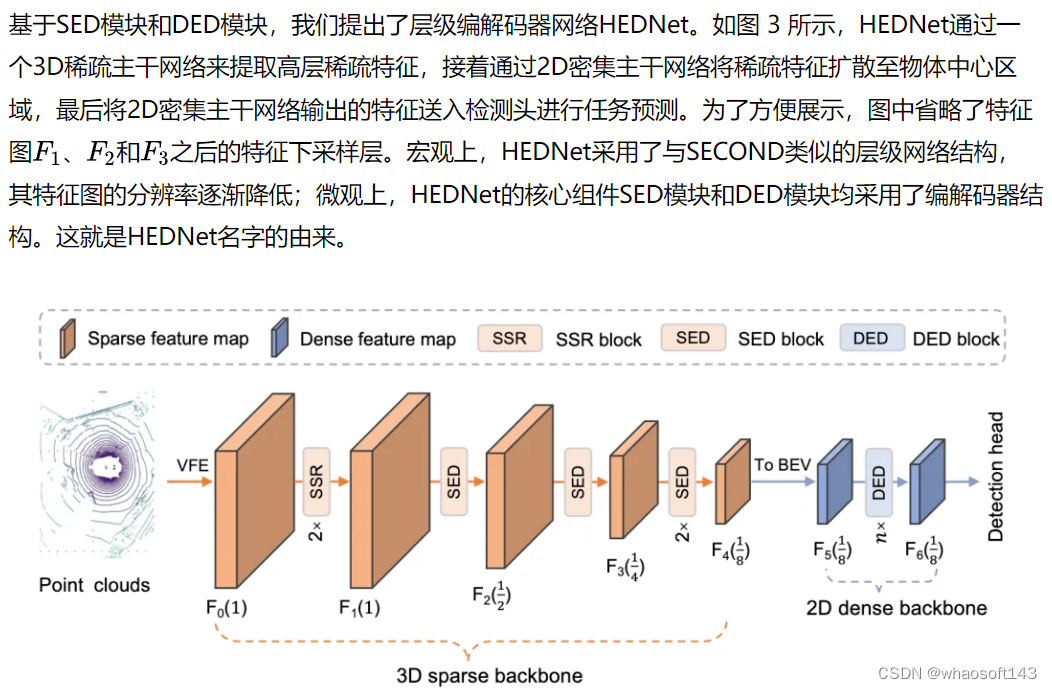
图3 HEDNet整体框架
小彩蛋
我们为什么会想到使用编解码器结构呢?实际上HEDNet是从我们的前序工作 CEDNet: A Cascade Encoder-Decoder Network for Dense Prediction (改名之前叫CFNet) 中启发而来。感兴趣可以去看我们的论文。
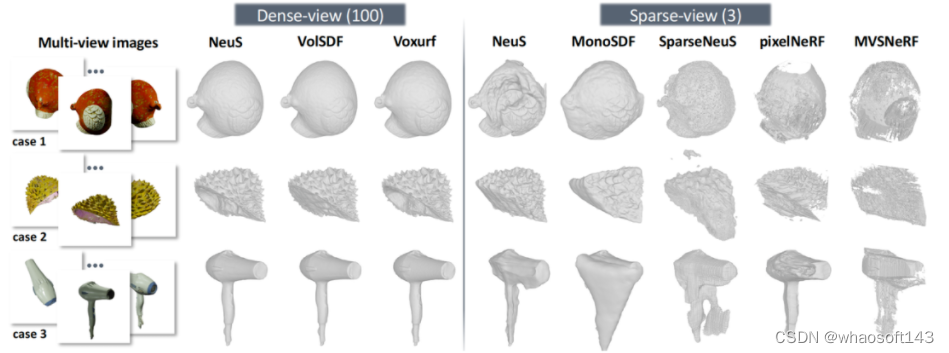
实验结果
我们将HEDNet与此前领先的方法在综合性能上进行了比较,结果如图4所示。与基于大卷积核CNN的LargeKernel3D和基于Transformer的DSVT-Voxel相比,HEDNet在检测精度和模型推断速度上均取得更优的结果。值得一提的是,与此前最先进的方法DSVT相比,HEDNet在取得更高检测准确率的同时,在模型推断速度上提升了50%。更详细的结果请参见我们的论文。
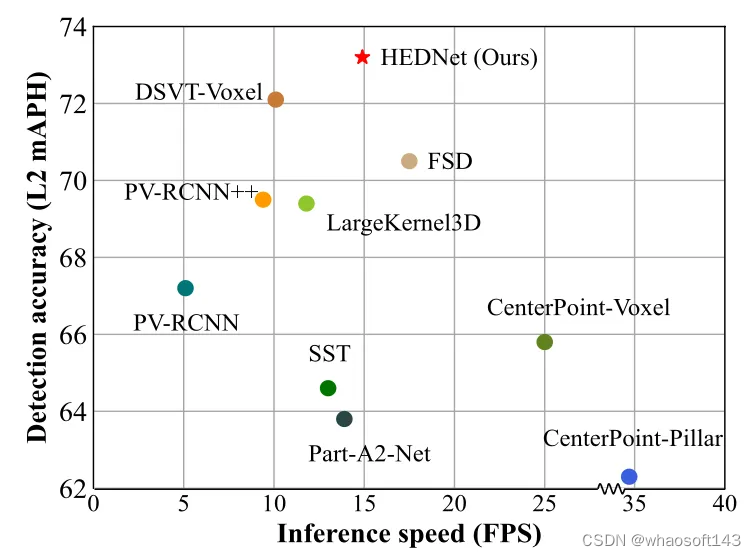
图4 在Waymo Open数据集上的综合性能比较
今生 - SAFDNet
研究背景
基于体素的方法通常将稀疏体素特征转换为密集特征图,接着通过密集卷积神经网络提取特征进行预测。我们将这类检测器称为混合检测器 ,其结构如图 5(a) 所示。这类方法在小范围 (<75米) 检测场景上表现优异,但随着感知范围扩大,使用密集特征图的计算成本急剧增加,限制了它们在大范围(>200米)检测场景中的应用。一个可能的解决方案是通过移除现有混合检测器中的密集特征图来构建纯稀疏检测器 ,但这会导致模型的检测性能明显下降,因为目前大多数混合检测器依赖于物体中心特征进行预测,当使用纯稀疏检测器提取特征时,大物体的中心区域通常是空的,这就是物体中心特征缺失问题。因此,学习适当的物体表征对于构建纯稀疏检测器至关重要。
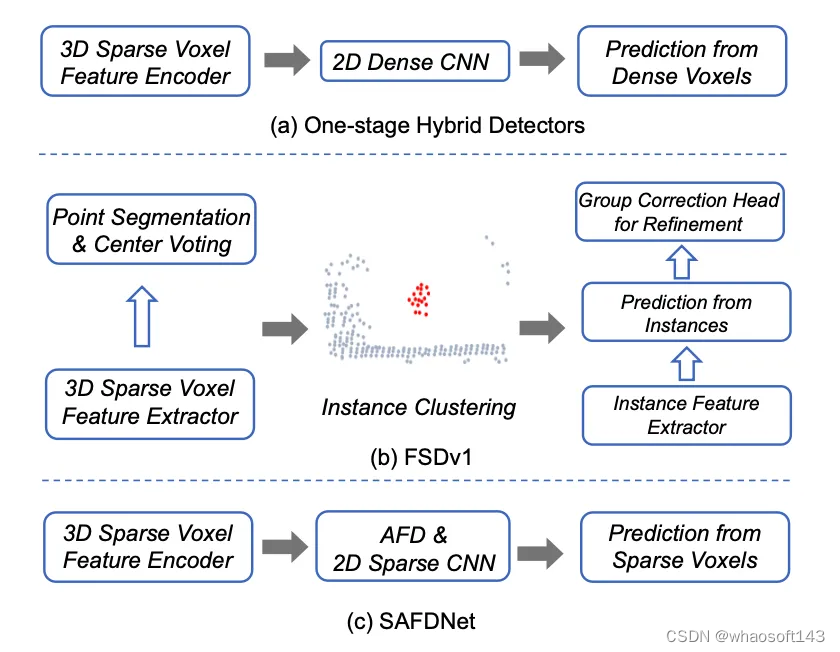
图5 混合检测器、FSDv1和SAFDNet的结构对比
为了解决物体中心特征缺失问题,FSDv1 (图 5(b)) 首先将原始点云分割为前景点和背景点,接着通过中心点投票机制对前景点进行聚类,并从每个聚类中提取实例特征用于初始预测,最后再通过Group Correction Head进一步细化。为了减少手工提取实例特征引入的归纳偏差,FSDv2采用虚拟体素化模块来替换FSDv1中的实例聚类操作。FSD系列方法与CenterPoint等广泛使用的检测框架差异较大,并且引入大量超参数,导致在真实场景中部署这些方法面临挑战。与FSD系列方法不同,VoxelNeXt直接基于距离物体中心最近的体素特征进行预测,但牺牲了检测准确率。
那么我们想要的纯稀疏点云检测器是什么样的呢?首先,结构要简单,这样便于直接部署到实际应用中,一个直观的想法是在目前广泛使用的混合检测器架构如CenterPoint的基础上,做最小的改动来构建纯稀疏检测器;其次,在性能上至少要匹配目前领先的混合检测器,并且能够适用于不同范围的检测场景。
方法介绍
从上述两个要求出发,我们基于HEDNet构建了纯稀疏3D点云物体检测器SAFDNet,其宏观结构如图 5(c) 所示。SAFDNet首先利用稀疏体素特征提取器来提取稀疏点云特征,接着采用自适应特征扩散 (Adaptive Feature Diffusion, AFD)策略和2D稀疏卷积神经网络将稀疏特征扩散到物体中心区域,来解决物体中心特征缺失问题,最后基于稀疏体素特征进行预测。SAFDNet能够仅使用稀疏特征进行高效计算,并且其大部分结构设计和超参数与基准混合检测器保持一致,使其可以轻松适配到实际应用场景,来替换现有的混合检测器。下面介绍SAFDNet的具体结构。
SAFDNet整体框架
图 6 展示了SAFDNet的整体框架。与现有的混合检测器类似,SAFDNet主要由三个部分组成:一个3D稀疏主干网络、一个2D稀疏主干网络和一个稀疏检测头。3D稀疏主干网络用于提取3D稀疏体素特征,并将这些特征转换成2D稀疏BEV特征。3D稀疏主干网络使用了3D-EDB模块来促进远距离特征间的信息交互 (3D-EDB模块就是基于3D稀疏卷积构建的SED模块,下文的2D-EDB模块类似)。2D稀疏主干网络接收3D稀疏主干网络输出的稀疏BEV特征作为输入,它首先对每个体素进行分类,以判断每个体素的几何中心是否落在特定类别的物体边界框内或者是否属于背景区域,接着通过AFD操作与2D-EDB模块,将稀疏特征扩散到物体中心区域。该部分是SAFDNet的核心组件。稀疏检测头基于2D稀疏主干网络输出的稀疏BEV特征进行预测。SAFDNet采用CenterPoint提出的检测头设计,我们对其进行了一些调整以适配稀疏特征,更多细节请参见论文。
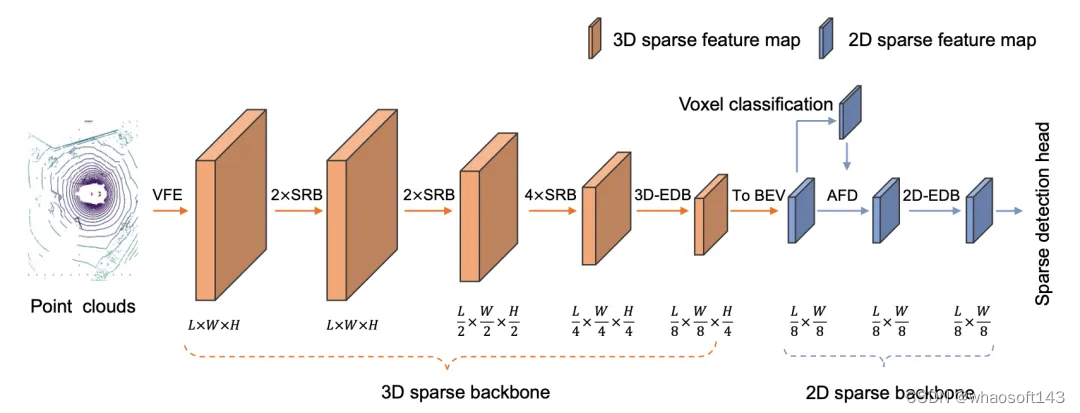
图6 SAFDNet整体框架
自适应特征扩散 (AFD)
由于激光雷达产生的点云主要分布在物体表面,使用纯稀疏检测器提取特征进行预测将面临物体中心特征缺失问题。那么检测器能否在尽可能保持特征稀疏度的同时,提取更接近或者位于物体中心的特征呢?一个直观的想法是将稀疏特征扩散到邻近的体素内。图 6(a)展示了一个稀疏特征图的示例,图中红点表示物体中心,每一个方格代表一个体素,深橙色方格是几何中心落在物体边界框内的非空体素,深蓝色方格是几何中心落在物体边界框外的非空体素,白色方格是空体素。每个非空体素对应一个非空特征。图 7(b) 是通过将图 7(a) 中非空特征均匀扩散到KxK (K取5) 的邻域后得到。扩散得到的非空体素以浅橙色或浅蓝色表示。
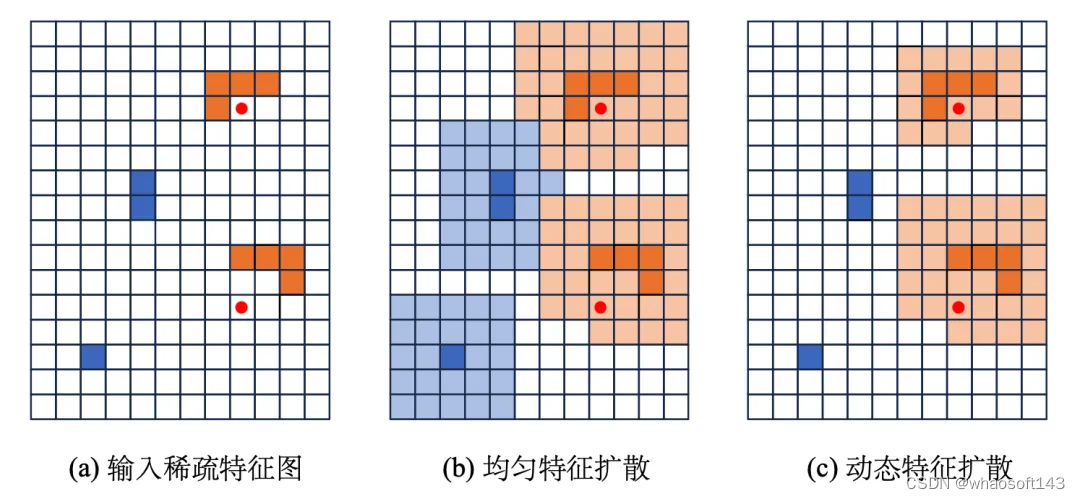
图7 均匀特征扩散和自适应特征扩散示意图
通过分析3D稀疏主干网络输出的稀疏特征图,我们观察到:(a) 少于10%的体素落在物体的边界框内;(b) 小物体通常在其中心体素附近或中心体素上有非空特征。这一观察表明,将所有非空特征扩散到相同大小的领域内可能是不必要的,特别是对于小物体边界框内和背景区域中的体素。因此,我们提出了一种自适应特征扩散策略,该策略根据体素特征的位置动态调整扩散范围。如图 7(c) 所示,该策略通过为大物体边界框内的体素特征分配更大的扩散范围来让这些特征更接近物体中心,同时通过为小物体边界框内和背景区域中的体素特征分配较小的扩散范围来尽可能地维持特征稀疏度。为了实现这一策略,需要进行体素分类(Voxel classification),以判别任意非空体素的几何中心是否在特定类别物体的边界框内或者属于背景区域。关于体素分类的更多细节请参考论文。通过使用自适应特征扩散策略,检测器能够尽可能地保持特征稀疏度,进而受益于稀疏特征的高效计算。
主要实验结果
我们将SAFDNet与之前最好的方法在综合性能上进行了比较,结果如图8所示。在检测范围较小的Waymo Open数据集上,SAFDNet和之前最好的纯稀疏检测器FSDv2以及我们提出的混合检测器HEDNet取得相当的检测准确率,但SAFDNet的推断速度是FSDv2的2倍以及HEDNet的1.2倍。在检测范围较大的Argoverse2数据集上,与纯稀疏检测器FSDv2相比,SAFDNet在指标mAP上提升了2.1%,同时推断速度达到了FSDv2的1.3倍;与混合检测器HEDNet相比,SAFDNet在指标mAP上提升了2.6%,同时推断速度达到了HEDNet的2.1倍。此外,当检测范围较大时,混合检测器HEDNet的显存消耗远大于纯稀疏检测器。综上所述,SAFDNet适用于不同范围的检测场景,且性能出色。

图8 主要实验结果
未来工作
SAFDNet是纯稀疏点云检测器的一种解决方案,那么它是否存在问题呢?实际上,SAFDNet只是我们关于纯稀疏检测器设想的一个中间产物,笔者认为它过于暴力,也不够简洁优雅。敬请期待我们的后续工作!
HEDNet和SAFDNet的代码都已经开源 , 链接: https://github.com/zhanggang001/HEDNet
#OmniObject3D
Award Candidate | 真实高精三维物体数据集OmniObject3D

为了促进真实世界中感知、重建和生成领域的发展,我们提出了 OmniObject3D,一个高质量的大类别真实三维物体数据集。本数据集有三个主要优势:
- 类别丰富:覆盖 200 余个类别的约 6K 个三维物体数据;
- 标注丰富:包括了高精表面网格、点云、多视角渲染图像,和实景采集的视频;
- 真实扫描:专业的扫描设备保证了物体数据的精细形状和真实纹理。
OmniObject3D 是目前学界最大的真实世界三维模型数据集, 为未来的三维视觉研究提供了广阔的空间。利用该数据集,我们探讨了 点云识别、神经渲染、表面重建、三维生成 等多种学术任务的鲁棒性和泛化性,提出了很多有价值的发现,并验证了其从感知、重建、到生成领域的开放应用前景。我们希望 OmniObject3D 以及其对应的 benchmarks 能够为学术研究和工业应用带来新的挑战和机会。作为 CVPR 2023 的投稿,我们收到了 4 位审稿人的 一致满分 评价,并获推 CVPR Award Candidate(top 12 / 9155)。
- Project page: https://omniobject3d.github.io/
- Paper: https://arxiv.org/abs/2301.07525
- Github: https://github.com/omniobject3d/OmniObject3D/tree/main
- Dataset Download: https://opendatalab.com/OpenXD-OmniObject3D-New/download
面向真实 3D 物体的感知、理解、重建与生成是计算机视觉领域一直倍受关注的问题,也在近年来取得了飞速的进展。然而,由于社区中长期缺乏大规模的实采 3D 物体数据库,大部分技术方法仍依赖于 ShapeNet1 等仿真数据集。然而,仿真数据与真实数据之间的外观和分布差距巨大,这大大限制了它们在现实生活中的应用。
为了解决这一困难,近年来也有一些优秀的工作如 CO3D2 等从视频/多视角图片中寻求突破点,并利用 SfM 的方式重建 3D 点云,然而这种方式得到的点云往往难以提供完整、干净、精准的 3D 表面和纹理。因此,社区迫切需要一个大规模且高质量的真实世界 3D 物体扫描数据集,这将有助于推进许多3D视觉任务和下游应用。
数据集特点
OmniObject3D 为每一个物体提供了四种模态信息,包括:带纹理的高精模型、点云、多视角渲染图像、实景拍摄的环绕视频。对于每个拍摄的视频,我们平均抽取了 200 帧,并提供前景掩码和 SfM 重建的相机位姿和稀疏点云。
下游应用
OmniObject3D 为学界带来了广泛的探索空间,在本文中,我们选取了四个下游任务进行评估与分析。
任务一:点云分类鲁棒性(Point Cloud Classification Robustness)
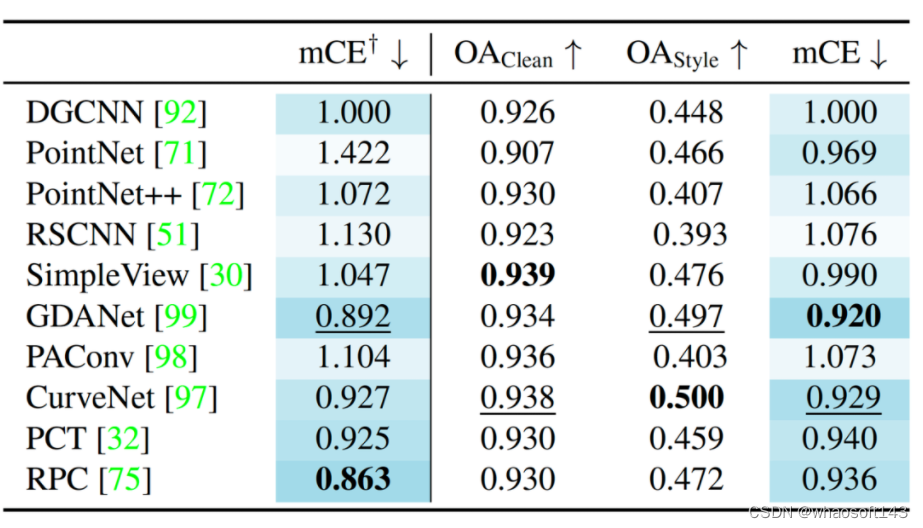
物体点云分类是 3D 感知中最基本的任务之一,在本节中,我们展示了 OmniObject3D 如何通过解耦 out-of-distribution styles & out-of-distribution corruptions 来实现更全面的点云分类的鲁棒性分析。

具体来说,1)CAD 模型与真实扫描模型之间的差异引入了 OOD styles;2)常见点云破坏因子产生了 OOD corruptions。
在之前的研究工作中,含噪的真实物体数据集如 ScanObjectNN6 将两种情况藕合了起来,无法实现解耦分析;主动加入破坏因子的仿真数据集如 ModelNet-C7 则仅仅反映了第二种情况。OmniObject3D 则具备将两种情况解耦分析的要素。
我们对十种最常见的点云分类模型进行了测试,并揭示了其与 ModelNet-C 数据集中结论的异同。在应对这两个挑战时,如何实现一个真正鲁棒的点云感知模型仍需更加深度的探索。
任务二:新视角合成(Novel View Synthesis)
自 NeRF8 提出以来,新视角合成一直是领域内的一个热门方向。我们在 OmniObject3D 上研究了两种赛道下的新视角合成方法:1)利用密集视角图片输入,对单一场景进行优化训练;2)挖掘数据集中不同场景之间的先验,探索类 NeRF 模型的泛化能力。
首先,对于单场景优化的模型,我们观察到基于体素的方法会更加擅长建模高频纹理信息,而基于隐式模型的方法则相对更能抵抗表面凹陷或弱纹理等容易产生几何歧义的情况。数据集中物体多变而复杂的形状和外观为这项任务提供了一个全新的评估基准。

相对于拟合的单个场景的模型,跨场景可泛化框架在本数据集上的表现则更令人期待。网络从很多同类别、甚至跨类别的数据中学习到可以泛化的信息,即可对于一个全新场景的稀疏视角输入做出新视角预测。
实验表明,作为一个几何和纹理信息丰富的数据集,OmniObject3D 有助于促使模型学到对新物体或甚至新类别的泛化能力。
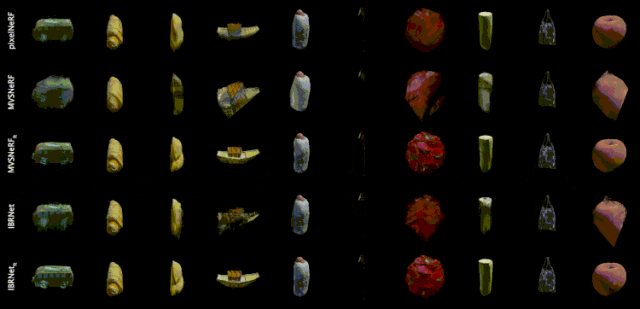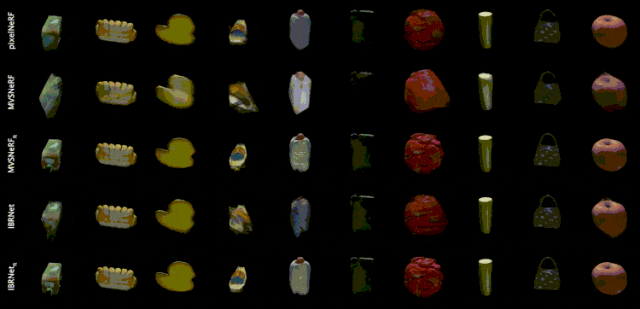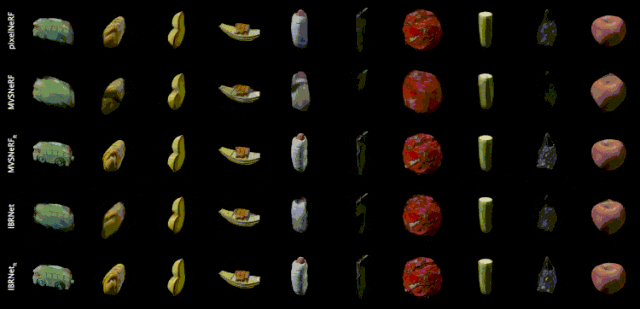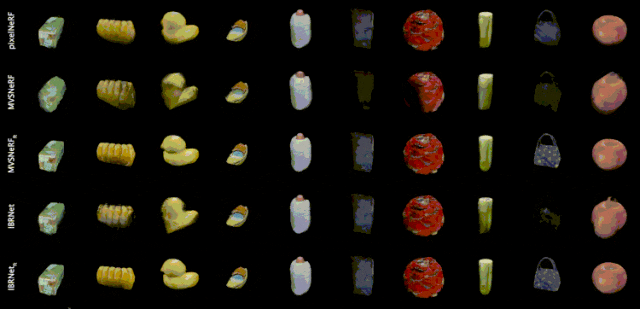
泛化性模型效果示例
任务三:表面重建(Surface Reconstruction)
除了新视角合成外,如果能恢复物体的显式表面,将更加有助于下游应用的开发。同时,我们的数据具备精准且完整的三维表面,能够充分支持表面重建精度的评测需要。
类似的,我们也为表面重建任务设置了两条赛道:1)稠密视角采样下的表面重建;2)稀疏视角采样下的表面重建。
稠密视角下表面重建结果展示了数据集内几何形状的显著多样性。精准的扫描使得我们能够使用 Chamfer Distance 作为重建精度的度量。将类别划分为三个"难度"等级,可以观察到所有方法在不同等级上的结果存在明显的差距。与仅包含 15 个场景的标准 DTU9 基准相比,我们的数据集在这项任务上提供了更全面的评估结果。

稠密视角表面重建示例
稀疏视图表面重建是一个更具挑战性的任务,在所有方法的结果中我们都观察到了明显瑕疵,均未达到能够足实际应用的水平。除了专为稀疏视角表面重建设计的方法外,我们还评估了前面提到的泛化性新视角合成模型的几何恢复能力------数据集提供的精准 3D Ground Truth 在评测中再次发挥了优势,然而他们的表现同样无法令人满意。综上所述,这个问题的探索空间仍然巨大,而 OmniObject3D 为该领域进一步的研究提供了扎实的数据基础。
稠密和稀疏视角表面重建效果示例
任务四:3D 物体生成(3D Object Generation)
除了重建之外,OmniObject3D 还可以用来训练真实 3D 物体的生成模型。我们采用 GET3D10 框架同时生成形状和纹理,并尝试使用单个模型从数据集中同时学习多种类别的生成。

带纹理的 3D 物体生成
通过在隐空间插值,可以观察到生成模型跨类别变化的特性。我们在文章中还着重探讨了由于训练数据不平衡导致的生成语义分布失衡特点,详细请参考论文。

形状和纹理低维隐码插值结果
未来工作
关于数据集本身,我们会致力于不断扩大和更新数据集以满足更广泛的研究需求。除了现有的应用,我们还计划进一步发展其他下游任务,如 2D / 3D 物体检测和 6D 姿态估计等。除了感知和重建任务外,在 AIGC 时代,我们相信OmniObject3D 能够在推动真实感 3D 生成方面发挥至关重要的作用。
#SHERF
输入的一张任意相机角度 3D 人体图片,Ta 就能动啦!
人体神经辐射场的目标是从 2D 人体图片中恢复高质量的 3D 数字人并加以驱动,从而避免耗费大量人力物力去直接获取 3D 人体几何信息。这个方向的探索对于一系列应用场景,比如虚拟现实和辅助现实场景,有着非常大潜在性的影响。
现有人体神经辐射场生成和驱动技术主要可以分为两类。
- 第一类技术利用单目或者多目人体视频去重建和驱动 3D 数字人。这类技术主要是针对特定数字人的建模和驱动,优化耗时大,缺乏泛化到大规模数字人重建上的能力。
- 第二类技术为了提升 3D 数字人重建的效率。提出利用多视角人体图片作为输入去重建人体神经辐射场。
尽管这第二类方法在 3D 人体重建上取得了一定的效果,这类方法往往需要特定相机角度下的多目人体图片作为输入。在现实生活中,我们往往只能获取到任意相机角度下人体的一张图片,给这类技术的应用提出了挑战。
在 ICCV2023 上,南洋理工大学 - 商汤科技联合研究中心 S-Lab 团队提出了基于单张图片的可泛化可驱动人体神经辐射场方法 SHERF。
- 论文地址:https://arxiv.org/abs/2303.12791
- 项目地址:https://skhu101.github.io/SHERF
- 代码开源:https://github.com/skhu101/SHERF
SHERF 可以基于用户输入的一张任意相机角度 3D 人体图片,该角度下相机和人体动作体型(SMPL)参数,以及给定目标输出空间下任意相机参数和人体动作体型(SMPL)参数,重建并驱动该 3D 数字人。本方法旨在利用任意相机角度下人体的一张图片去重建和驱动 3D 人体神经辐射场。
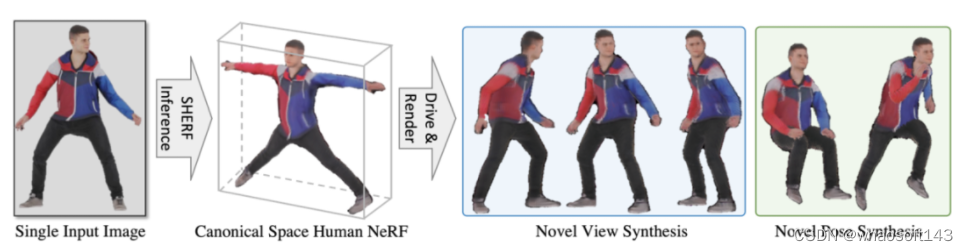
图 1
基本原理
人体神经辐射场重建和驱动主要分为五个步骤(如图 2 所示)。
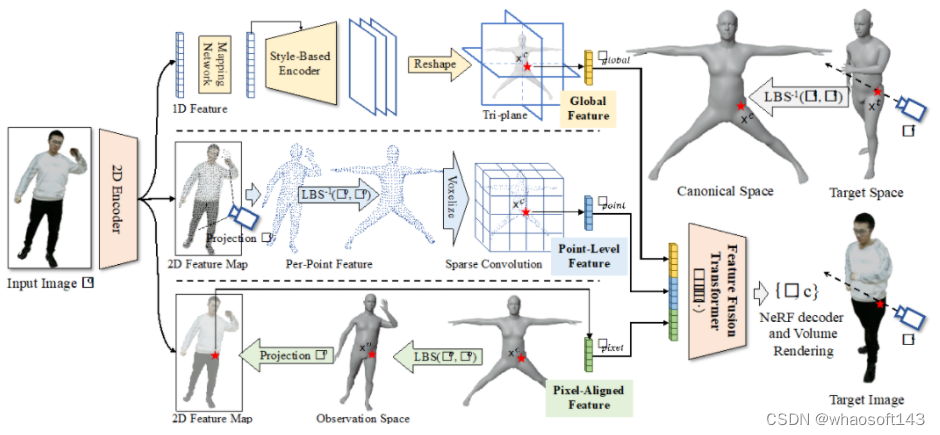
图 2
第一步为**目标空间(target space)到标准空间(canonical space)的坐标转换,**基于用户输入目标输出空间下任意人体动作体型参数和相机外参参数,在目标空间内射出光线,并在光线上采样一系列空间点,利用 SMPL 算法的逆线性蒙皮转换(Inverse Linear Blend Skinning)将目标空间里的空间点转换到标准空间中。
第二步为提取标准空间中 3D 点对应的层级特征(hierarchical feature)。
- **全局特征(global feature)提取:**利用二维编码网络(2D Encoder)从输入图片提取一维特征,并利用映射网络(Mapping Network)和风格编码网络(Style-Based Encoder)进一步将 1D 特征转换为标准空间下的三平面特征(Tri-plane),接下来将标准空间中 3D 点投影到三平面提取相应的全局特征;
- **点级别特征(Point-Level Feature)提取:**首先利用二维编码网络(2D Encoder)从输入图片提取二维特征,并将观测空间(observation space)下 SMPL 的顶点投影到输入图片成像平面上去提取相应特征,紧接着利用 SMPL 算法的逆线性蒙皮转换(Inverse Linear Blend Skinning)将观测空间下 SMPL 的顶点转到标准空间下构建稀疏三维张量,然后利用稀疏卷积得到标准空间中 3D 点的点级别特征;
- **像素级别特征(Pixel-Aligned Feature)提取:**首先利用二维编码网络(2D Encoder)从输入图片提取二维特征,并利用 SMPL 算法的线性蒙皮转换(Linear Blend Skinning)将标准空间中 3D 点转到观测空间下,再投影到输入图片成像平面上去提取相应像素级别特征。
第三步为特征融合(Feature Fusion Transformer), 利用 Transformer 模型将三种不同级别的特征进行融合。第四步为**人体神经辐射场解码生成相应图片信息,**将标准空间中 3D 点坐标,光线方向向量和对应特征输入到人体神经辐射场解码网络中得到 3D 点的体密度和颜色信息,并进一步基于体渲染(Volume Rendering)在目标空间下生成相应像素的颜色值,并得到最终用户输入目标输出空间下任意人体动作体型参数和相机外参参数下的图片。
基于以上步骤,给定目标输出空间下任意人体动作序列(SMPL)参数可以从 2D 图片恢复 3D 数字人并加以驱动。
结果比较
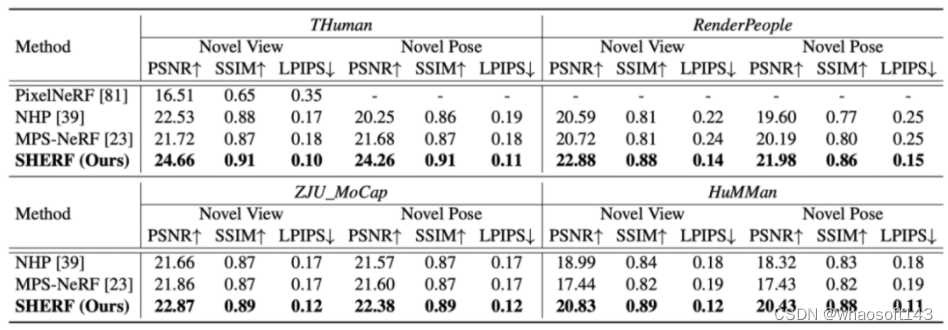
本文在四个人体数据集上人体数据集上进行了实验,分别是 THuman,RenderPeople,ZJU_MoCap,HuMMan。
该研究对比了对比了最先进的可泛化多视角人体图片的人体神经辐射场方法,NHP 和 MPS-NeRF。本文在 peak signal-to-noise ratio (PSNR),structural similarity index (SSIM),以及 Learned Perceptual Image Patch Similarity (LPIPS)进行了比较。如下图所示,本文在所有数据集,所有指标上均大幅超越之前的方案。
SHERF 动态驱动 3D 人体结果如下图所示:

从左到右分别为 input Image、motion seq 1 、motion seq 2
本文同样验证了在 in-the-wild DeepFashion 数据上的泛化和驱动效果,如下图 3 所示,给定任意一张输入图片,本文利用单视角估 SMPL 的先进算法估出 SMPL 和相应相机角度,后利用本文提出的算法对 3D 人体进行驱动。实验结果显示 SHERF 具有较强的泛化性。




从左到右分别为 input Image、motion seq 1 、motion seq 2
应用前景
在游戏电影制作,虚拟现实增强现实或者其他需要数字人建模的场景,用户可以无需专业技能,专业软件,即可通过输入的一张任意相机角度 3D 人体图片,该角度下相机的参数和相应的人体动作体形参数(SMPL),就可以达到重建并驱动该 3D 数字人的目的。
结语
本文提出一种基于单张输入图片可泛化可驱动的人体神经辐射场方法 SHERF。可以承认的是,本文依然存在一定的缺陷。
首先,对于输入图片观测不到一部分人体表面, 渲染出来的结果可以观察到一定的瑕疵,一个解决的办法是建立一种遮挡可知(occlusion-aware)的人体表征。
其次,关于如何补齐输入图片观测不到人体部分依旧是一个很难得问题。本文从重建角度提出 SHERF,只能对观测不到的人体部分给出一个确定性的补齐,对观测不到部分的重建缺乏多样性。一个可行的方案是利用生成模型在观测不到的人体部分生成多样性高质量的 3D 人体效果。
坐着代码已经全部开源,大量基于单张图片生成的数字人结果也已经上传项目主页 感谢大佬~~
#OccNeRF
近年来,3D 占据预测(3D Occupancy Prediction)任务因其独特的优势获得了学界及业界的广泛关注。3D 占据预测通过重建周围环境的 3D 结构为自动驾驶的规划和导航提供详细信息。然而,大多数现有方法依赖 LiDAR 点云生成的标签来监督网络训练。在 OccNeRF 工作中,作者提出了一种自监督的多相机占据预测方法。该方法参数化的占据场(Parameterized Occupancy Fields)解决了室外场景无边界的问题,并重新组织了采样策略,然后通过体渲染(Volume Rendering)来将占用场转换为多相机深度图,最后通过多帧光度一致性(Photometric Error)进行监督。此外,该方法利用预训练的开放词汇语义分割模型(open vocabulary semantic segmentation model)生成 2D 语义标签对模型进行监督,来赋予占据场语义信息。
问题背景
近年来,随着人工智能技术的飞速发展,自动驾驶领域也取得了巨大进展。3D 感知是实现自动驾驶的基础,为后续的规划决策提供必要信息。传统方法中,激光雷达能直接捕获精确的 3D 数据,但传感器成本高且扫描点稀疏,限制了其落地应用。相比之下,基于图像的 3D 感知方法成本低且有效,受到越来越多的关注。多相机 3D 目标检测 在一段时间内是 3D 场景理解任务的主流,但它无法应对现实世界中无限的类别 ,并受到数据长尾分布的影响。
3D 占据预测能很好地弥补这些缺点,它通过多视角输入直接重建周围场景的几何结构。大多数现有方法关注于模型设计与性能优化,依赖 LiDAR 点云生成的标签来监督网络训练,这在基于图像的系统中是不可用的。换言之,我们仍需要利用昂贵的数据采集车来收集训练数据,并浪费大量没有 LiDAR 点云辅助标注的真实数据,这一定程度上限制了 3D 占据预测的发展。因此探索自监督 3D 占据预测是一个非常有价值的方向。
详解OccNeRF算法
Parameterized Occupancy Fields
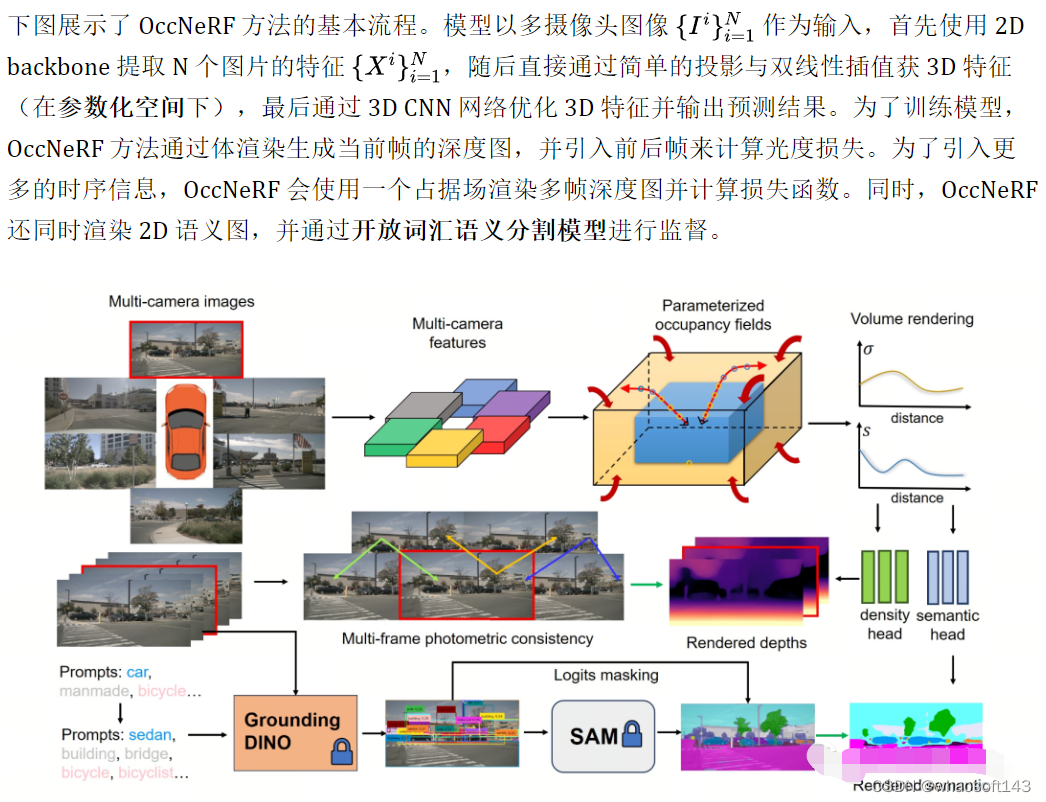
Parameterized Occupancy Fields 的提出是为了解决相机与占据网格之间存在感知范围差距这一问题。理论上来讲,相机可以拍摄到无穷远处的物体,而以往的占据预测模型都只考虑较近的空间(例如 40 m 范围内)。在有监督方法中,模型可以根据监督信号学会忽略远处的物体;而在无监督方法中,若仍然只考虑近处的空间,则图像中存在的大量超出范围的物体将对优化过程产生负面影响。基于此,OccNeRF 采用了 Parameterized Occupancy Fields 来建模范围无限的室外场景。

Multi-frame Depth Estimation
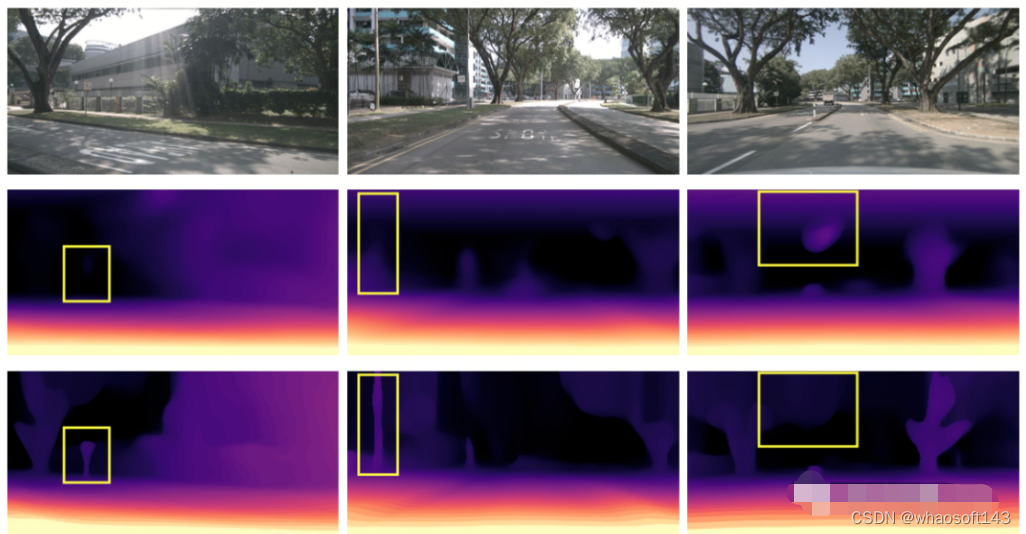
为了实现训练 occupancy 网络,OccNeRF选择利用体渲染将 occupancy 转换为深度图,并通过光度损失函数来监督。渲染深度图时采样策略很重要。在参数化空间中,若直接根据深度或视差均匀采样,都会造成采样点在内部或外部空间分布不均匀,进而影响优化过程。因此,OccNeRF 提出在相机中心离原点较近的前提下,可直接在参数化空间中均匀采样。此外,OccNeRF 在训练时会渲染并监督多帧深度图。
下图直观地展示了使用参数化空间表示占据的优势。(其中第三行使用了参数化空间,第二行没有使用。)
Semantic Label Generation
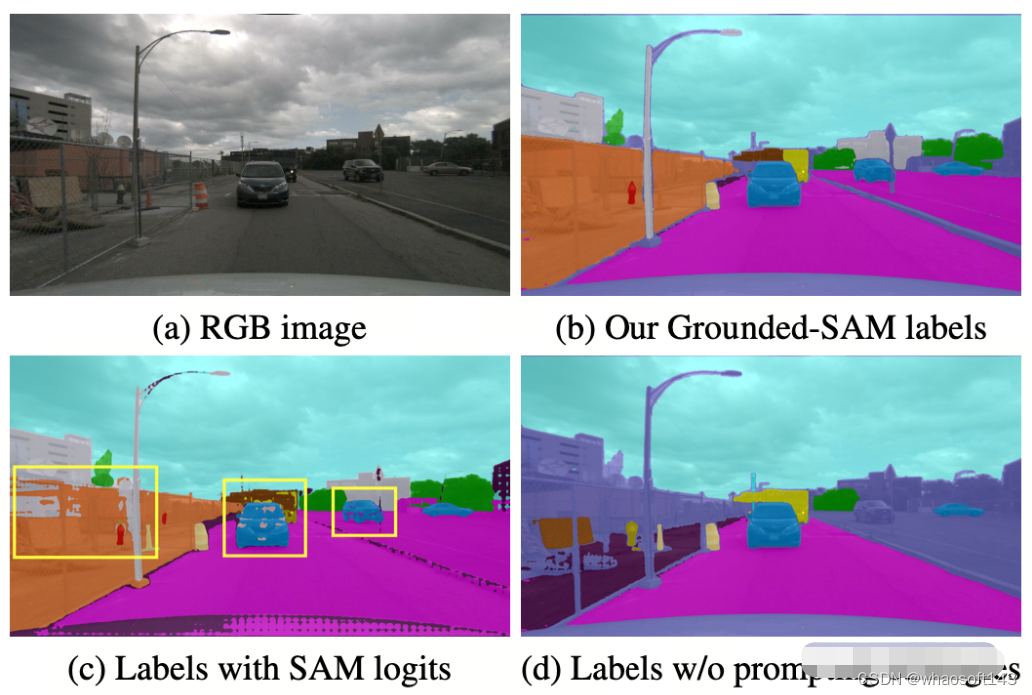
OccNeRF 使用预训练的 GroundedSAM (Grounding DINO + SAM) 生成 2D 语义标签。为了生成高质量的标签,OccNeRF 采用了两个策略,一是提示词优化 ,用精确的描述替换掉 nuScenes 中模糊的类别。OccNeRF中使用了三种策略优化提示词:歧义词替换(car 替换为 sedan)、单词变多词(manmade 替换为 building, billboard and bridge)和额外信息引入(bicycle 替换为 bicycle, bicyclist)。二是根据 Grounding DINO 中检测框的置信度而不是 SAM 给出的逐像素置信度来决定类别。OccNeRF 生成的语义标签效果如下:
OccNeRF实验结果
OccNeRF 在 nuScenes 上进行实验,并主要完成了多视角自监督深度估计和 3D 占据预测任务。
多视角自监督深度估计
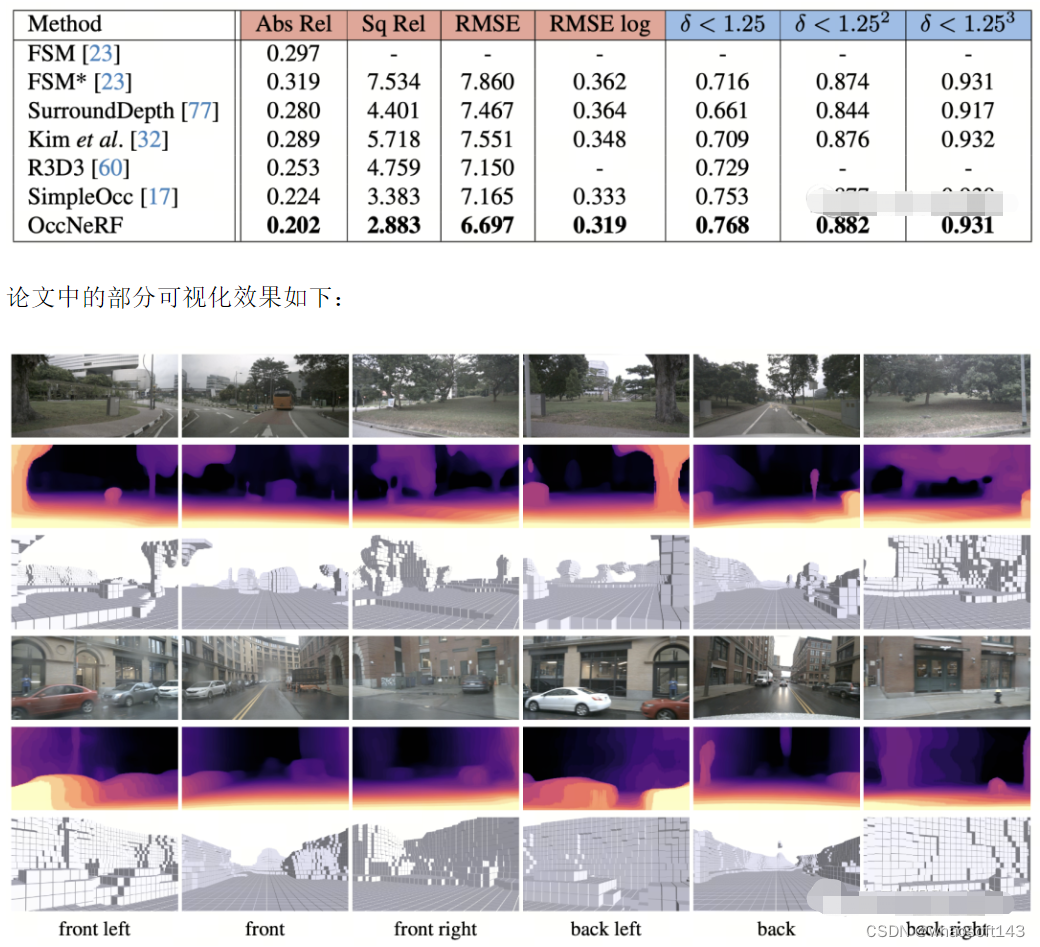
OccNeRF 在 nuScenes 上多视角自监督深度估计性能如下表所示。可以看到基于 3D 建模的 OccNeRF 显著超过了 2D 方法,也超过了 SimpleOcc,很大程度上是由于 OccNeRF 针对室外场景建模了无限的空间范围。
3D 占据预测
OccNeRF 在 nuScenes 上 3D 占据预测性能如下表所示。由于 OccNeRF 完全不使用标注数据,其性能与有监督方法仍有差距。但部分类别(如 drivable surface 与 manmade)已达到与有监督方法可比的性能。

总结
在许多汽车厂商都尝试去掉 LiDAR 传感器的当下,如何利用好成千上万无标注的图像数据,是一个重要的课题。而 OccNeRF 给我们带来了一个很有价值的尝试。
#OctreeOcc
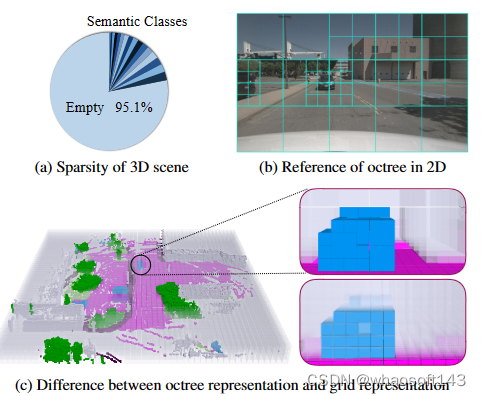
传统方法通常依赖密集、规则的网格表示,这通常会导致过多的计算需求和小对象空间细节的丢失。OctreeOcc是一个无丢失重要信息的3D占用预测框架,它利用八叉树表示自适应地捕获3D中有价值的信息,提供可变的颗粒度来适应不同大小和复杂性的对象形状和语义区域。特别是,结合了图像信息来提高初始八叉树结构的准确性,并设计了一种有效的校正机制来迭代地细化八叉树结构。通过广泛的评估表明,OctreeOcc不仅在占用预测方面超越了最先进的方法,而且与基于密集网格的方法相比,计算开销减少了15%-24%。
OctreeOcc的创新点核心
1.引入了基于多颗粒度八叉树查询的3D占用预测框架OctreeOcc
通过预测八叉树结构为不同区域提供不同的建模颗粒度,在保留空间信息的同时减少了需要建模的体素数量,从而减少了计算开销并保持了预测精度 从图1中可以看出,(a)表明语义类别只占空间的一小部分,建模空区域密集地影响计算效率。(b)和(c)证明了八叉树表示的优越性,我们可以对不同尺度的对象或空间应用不同的粒度,这减少了计算开销,同时保留了空间信息。半透明区域代表空体素
2.开发了语义引导的八叉树初始化模块和迭代结构校正模块
将语义信息作为初始化八叉树结构的前身。随后,我们迭代更新结构,确保与场景更准确地对齐的持续校正
OctreeOcc重点解析
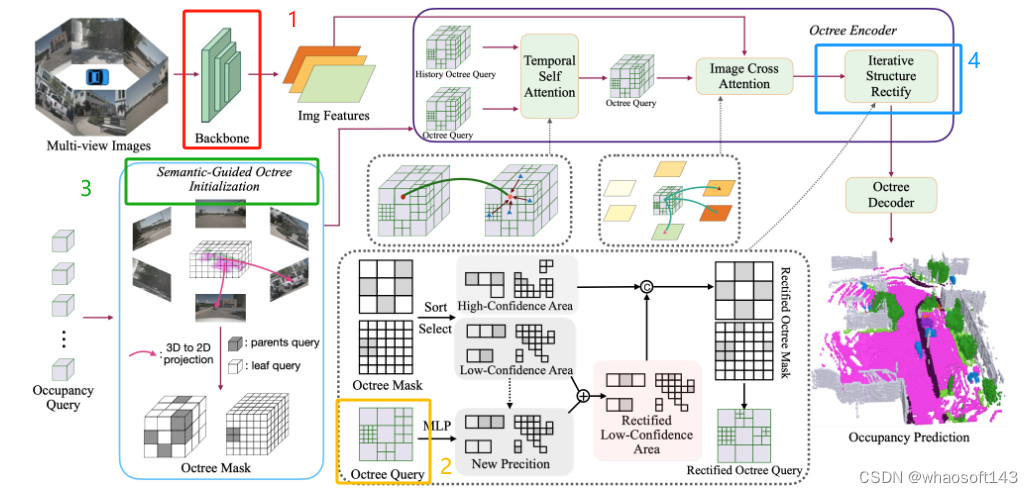
1. 图像特征提取(Image Backbone)
使用ResNet101-DCN作为backbone,从多视角图像中提取多尺度特征,用于后续模块。
2. 密集查询初始化(Dense Query Initialization)
八叉树初始化模块将八叉树转换为稀疏八叉树查询Qoctree:
A:稀疏和多颗粒度的八叉树查询
创建灵活的体素表示,以适应不同尺度的语义区域,通过预测八叉树掩码来启动,这个预测八叉树掩码Mo是获取八叉树结构的关键元素,促进了八叉树到Qoctree的转换:
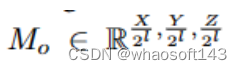
其中L=1,2, . . . , −L 1,八叉树掩码表示每个级别的每个体素分裂成八叉的可能性。这里,L代表八叉树的深度
B:确定八叉树的层次结构
根据查询选择比例α和八叉树掩码Mo,确定八叉树的层次结构,即在每个层级上需要保留或分裂的查询位置。α控制每个层级的分裂程度。
C:将密集查询转换为稀疏和多颗粒度的八叉树查询
在每个层级上,使用平均池化下采样密集查询Q_dense,只保留叶查询(不需要继续分裂的查询)。最终获得八叉树查询Q_octree。
D:将稀疏的Q_octree解码回密集表示Q_dense
通过追踪每个查询的八叉树坐标,可以方便地将稀疏的Q_octree解码回密集表示Q_dense,以匹配场景占用预测的输出形状。
3. 语义导向的八叉树初始化(Semantic-Guided Octree Initialization)
由图像语义驱动的八叉树初始化方法,可以产生更准确的初始八叉树结构
A:图像的语义分割结果(I_seg)
使用UNet对输入多视角图像进行语义分割
B:对采样点Pi的网络中心位置进行投影
对于每个占用查询点,投影到图像分割结果上,根据投影的语义类别设定查询点的分裂概率。例如投影到前景类别时分裂概率为1,采样点pi与其对应的2D参考点(uij,vij)在第j个图像视图上的投影公式为:
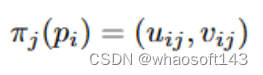
其中πj(pi)表示第j个摄像机视图中位置pi处的第i个采样点的投影
C:为投影到不同语义类别的体素分配了不同的权重
在获得每个体素的初始置信度后,我们将其下采样到不同的八叉树级别以制定初始八叉树掩码,根据掩码,例如选择前20%和60%置信度查询作为父查询,其余为叶查询,构建初始的稀疏八叉树表示
4.八叉树编码器(Octree Encoder)
编码后的八叉树查询为结构优化提供了额外信息,使预测的八叉树结构能够动态调整
A:时空注意力(Spatial-Temporal Attention)
采用高效的可变形注意力 用于图像交叉注意力 (ICA)和时间自我注意力(TSA)
图像交叉注意力ICA:
图像交叉注意力机制旨在增强多尺度图像特征和八叉树查询之间的交互。对于八叉树查询q,我们可以获取其中心的3D坐标(x, y,z)作为参考点
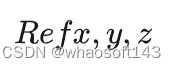
然后我们将3d点投影到图像并执行可变形的注意:
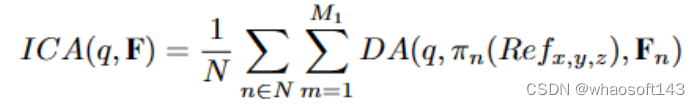
其中N表示相机视图,m索引参考点,M1是每个查询的采样点总数。Fn是第n个相机视图的图像特征,DA代表可变形注意力。
时序自注意力TSA:
给定历史八叉树查询Qt−1,通过自我意识车辆运动将其与当前八叉树查询Qt对齐。为了降低计算成本,采用了与ICA类似的操作。

其中K表示注意力头的数量,M2表示采样点的数量,Wk和Wm是学习权重,Akm表示归一化注意力权重,p+Δpkm表示3D空间中可学习的采样点位置。该特征是通过该位置的体素特征的三线性插值计算的。
B:迭代结构校正(Iterative Structure Rectification
将当前八叉树结构划分为高置信和低置信 区域。对低置信区域,利用编码后的稠密表示预测新结构与原结构融合得到校正后的结构。1.将之前预测的八又树结构划分为高置信区域和低置信区域。高置信区域直接保留不变。
2.对低置信区域先将当前的八叉树查询解码为密集表示,然后在每个八叉树层级上下采样得到密集特征表示。
3.提取低置信区域的密集特征用MLP预测这些区域的新八又树分裂概率。
4.将MLP预测的新概率与原先低置信区域的概率做加权融合,得到校正后的新概率。
5.根据新概率选择置信Top K%的位置作为真正需要分裂的位置生成当前层级的新结构。
6.将新结构与高置信区域直接保留的结构拼接成为当前层级校正后的新结构。
通过这种迭代校正,八叉树结构能够动态调整,从而提高结构预测的准确性,更好地表示场景。
C:损失函数(Loss Function)
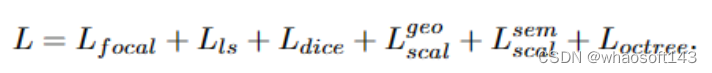
1.Focal Loss (Lfocal):处理类别不平衡的focal loss。2.Lovasz-softmax Loss (Lls): Lovasz hinge loss 的一个变种。3.Dice Loss (Ldice):Dice 系数的损失函数。4.尺度一致性损失(Lgeo_scal, Lsem_scal):监督几何和语义的Prediction不同尺度之间的一致性。5.八叉树损失(Loctree): 用focal loss 监督八叉树结构的预测。
总结
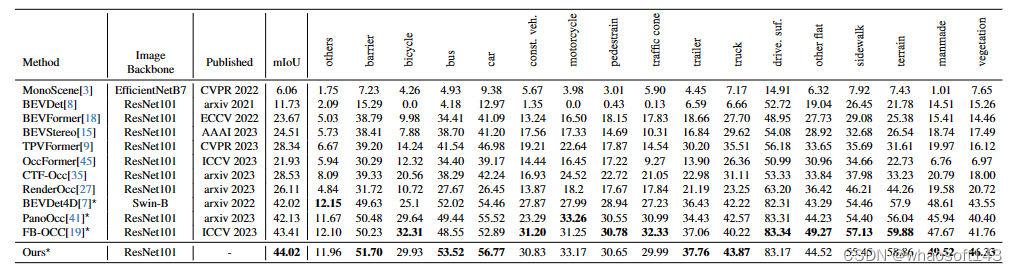
纯视觉的3D占用预测性能对比
八叉树结构校正的图示。左图显示最初预测的八叉树结构,右图描述迭代结构校正模块后的八叉树结构。很明显,预测的八叉树结构在校正模块之后变得更加符合物体的形状
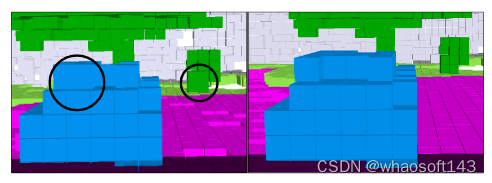
第一行显示输入的多视图图像,而第二行显示PanoOcc、FBOCC、OctreeOcc方法和地面实况的占用预测结果
结论
解决了传统密集网格表示在理解3D场景中的局限性。OctreeOcc对八叉树表示的自适应利用能够捕获具有可变颗粒度的有价值信息, 满足不同大小和复杂性的对象。广泛的实验结果证实了OctreeOcc在3D占用预测中获得最先进性能的能力, 同时同时减少了计算开销。
附录
A:语义引导的八叉树初始化(Semantic-Guided Octree Initialization)
- 使用UNet模型对图像进行语义分割,得到每幅图像的语义分割结果。
- 通过投影occupancy的ground truth到图像平面,为UNet得到图像语义分割的标签进行监督训练。
- 离线生成语义分割结果,以避免训练时对occupancy预测模型的影响。
- 对每一个查询点,投影到生成的语义分割结果图上。如果投影到地面像素(driveable surface等),分裂概率加0.1;如果投影到背景像素,加0.5;如果投影到前景像素,加1.0。
- 通过平均池化生成不同层级的八叉树掩码,即初始八叉树结构。最终构建初始的稀疏、多粒度八叉树表示。
B:迭代结构校正(Iterative Structure Rectification)
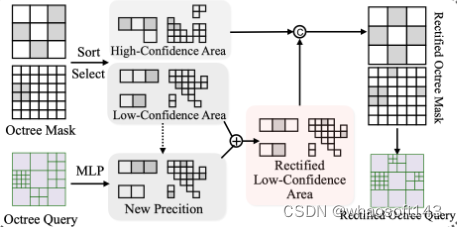
- 在第1层级,直接保留置信度最高的10%预测结构。
- 对于剩下的位置,用2层MLP预测新概率,与原概率按60:40 权重融合得到新概率。
- 按新概率选择置信Top 10%的位置进行分裂,生成第1层级的新结构。
- 在第2层级,直接保留置信Top 30%预测结构。
- 对于其余位置,同样用MLP预测新概率,与原概率50:50 权重融合。
- 按新概率选择Top 30%的位置分裂,生成第2层级的新结构。
总结:通过这种连续校正,八叉树的质量明显提升(mIoU提高约10%),校正了许多不准确的预测。
C:八叉树结构质量探讨(Discussion on Octree Structure Quality)
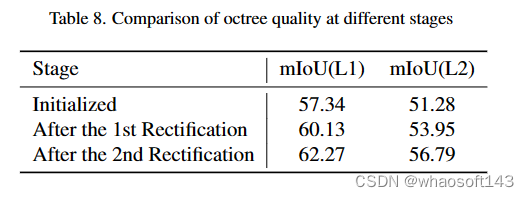
- 初始八叉树结构在第1层级和第2层级的mIoU分别为57.34和51.28。
- 经过第1轮迭代结构校正后,第1层级和第2层级的mIoU分别提高到60.13和53.95。
- 第2轮迭代结构校正后,第1层级和第2层级的mIoU进一步提高到62.27和56.79
可以看出,随着迭代结构校正模块的不断作用,八叉树的质量持续提高,原本不准确的预测被校正,mIoU提高了约10%。这证明了结构迭代校正模块的效果。
总的来说,这部分论证了预测八叉树结构的动态迭代调整和优化,可以持续改进八叉树表示的质量,从而提高下游任务的性能。
D. More Visualization
图14显示了提议的Oc-treeOcc的附加可视化。显然,此方法利用多颗粒度八叉树建模,展示了卓越的性能,特别是在卡车、公共汽车和人造物体的类别中。

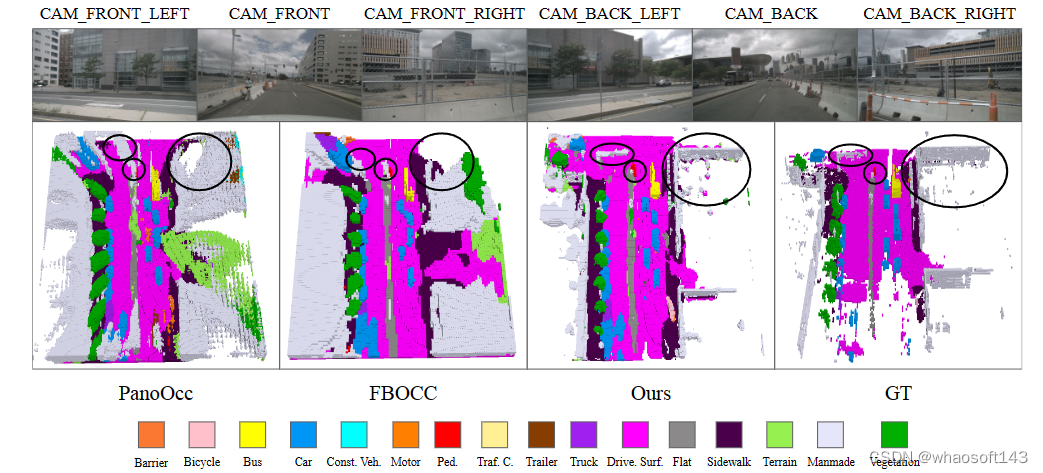
Occ3D-nuScenes验证集的更多可视化。第一行显示输入的多视图图像,而第二行显示PanoOcc、FBOCC、此方法和地面实况的占用预测结果。
#基于深度学习的3D分割综述
搬来个厉害的涉及RGB-D/点云/体素/多目 希望早点有时间能系统的学到用到~~~
3D目标分割是计算机视觉中的一个基本且具有挑战性的问题,在自动驾驶、机器人、增强现实和医学图像分析等领域有着广泛的应用。它受到了计算机视觉、图形和机器学习社区的极大关注。传统上,3D分割是用人工设计的特征和工程方法进行的,这些方法精度较差,也无法推广到大规模数据上。在2D计算机视觉巨大成功的推动下,深度学习技术最近也成为3D分割任务的首选。近年来已涌现出大量相关工作,并且已经在不同的基准数据集上进行了评估。本文全面调研了基于深度学习的3D分割的最新进展,涵盖了150多篇论文。论文总结了最常用的范式,讨论了它们的优缺点,并分析了这些分割方法的对比结果。并在此基础上,提出了未来的研究方向。
如图1第二行所示,3D分割可分为三种类型:语义分割、实例分割和部件分割。

论文的主要贡献如下:
- 本文是第一篇全面涵盖使用不同3D数据表示(包括RGB-D、投影图像、体素、点云、网格和3D视频)进行3D分割的深度学习综述论文;
- 论文对不同类型的3D数据分割方法的相对优缺点进行了深入分析;
- 与现有综述不同,论文专注于专为3D分割设计的深度学习方法,并讨论典型的应用领域;
- 论文对几种公共基准3D数据集上的现有方法进行了全面比较,得出了有趣的结论,并确定了有前景的未来研究方向。
图2显示了论文其余部分的组织方式:
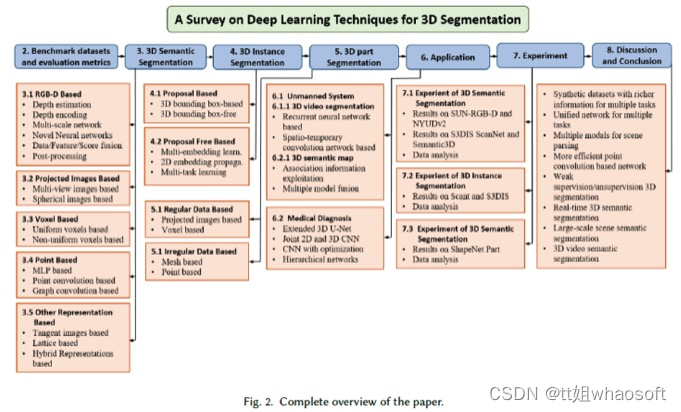
1 基准数据集和评估指标
3D分割数据集
数据集对于使用深度学习训练和测试3D分割算法至关重要。然而,私人收集和标注数据集既麻烦又昂贵,因为它需要领域专业知识、高质量的传感器和处理设备。因此,构建公共数据集是降低成本的理想方法。遵循这种方式对社区有另一个好处,它提供了算法之间的公平比较。表1总结了关于传感器类型、数据大小和格式、场景类别和标注方法的一些最流行和典型的数据集。
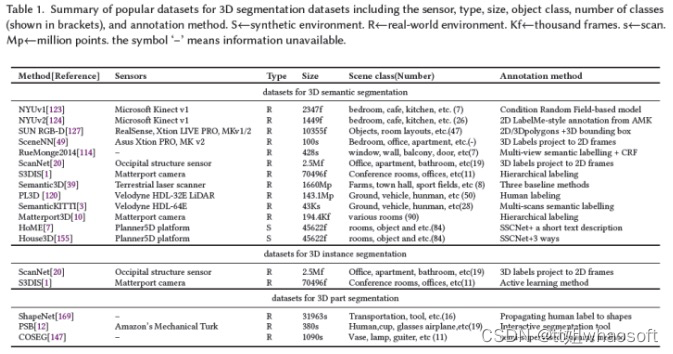
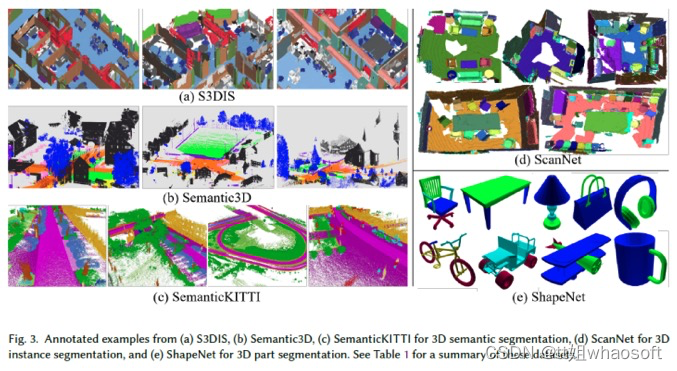
这些数据集是通过不同类型的传感器(包括RGB-D相机123、124、127、49、20、移动激光扫描仪120、3、静态地面扫描仪39和非真实引擎7、155和其他3D扫描仪1、10)用于3D语义分割而获取的。其中,从非真实引擎获得的数据集是合成数据集7155,不需要昂贵的设备或标注时间。这些物体的种类和数量非常丰富。与真实世界数据集相比,合成数据集具有完整的360度3D目标,没有遮挡效果或噪声,真实世界数据集中有噪声且包含遮挡123、124、127、49、20、120、12、3、1、39、10。对于3D实例分割,只有有限的3D数据集,如ScanNet20和S3DIS1。这两个数据集分别包含RGB-D相机或Matterport获得的真实室内场景的扫描数据。对于3D部件分割,普林斯顿分割基准(PSB)12、COSEG147和ShapeNet169是三个最流行的数据集。图3中显示了这些数据集的标注示例:
2 评价指标
不同的评估指标可以评价分割方法的有效性和优越性,包括执行时间、内存占用和准确性。然而,很少有作者提供有关其方法的执行时间和内存占用的详细信息。本文主要介绍精度度量。对于3D语义分割,常用的有Overall Accuracy(OAcc)、mean class Accuracy(mAcc)、mean class Intersection over Union(mIoU)。
OAcc:
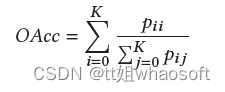
mAcc:

mIoU:
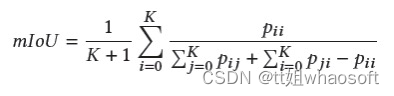
对于3D实例分割,常用的有Average Precision(AP)、mean class Average Precision(mAP)。
AP:
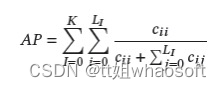
mAP:
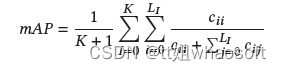
对于3D部件分割,常用的指标是overall average category Intersection over Union(Cat.mIoU)和overall average instance Intersection over Union(Ins.mIoU)。
Cat.mIoU:
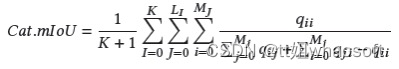
Ins.mIoU:
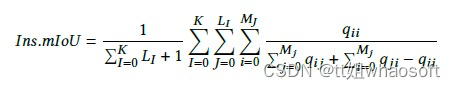
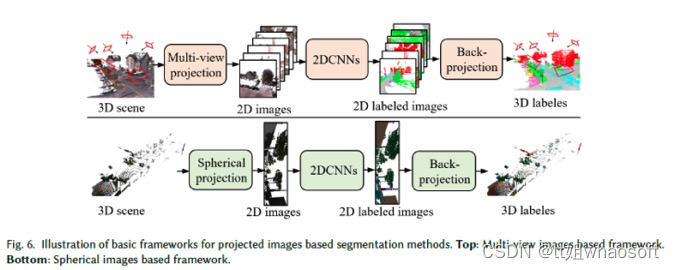
3 3D语义分割
文献中提出了许多关于3D语义分割的深度学习方法。根据使用的数据表示,这些方法可分为五类,即基于RGB-D图像、基于投影图像、基于体素、基于点云和其他表示。基于点云的方法可以根据网络架构进一步分类为基于多层感知器(MLP)的方法、基于点云卷积的方法和基于图卷积的。图4显示了近年来3D语义分割深度学习的里程碑。
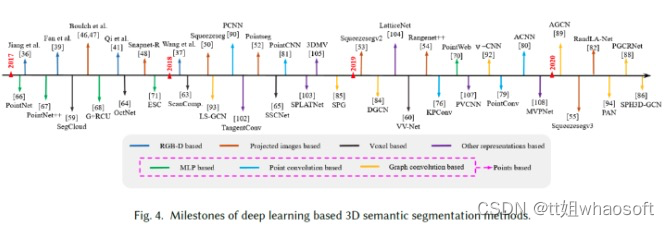
基于RGB-D
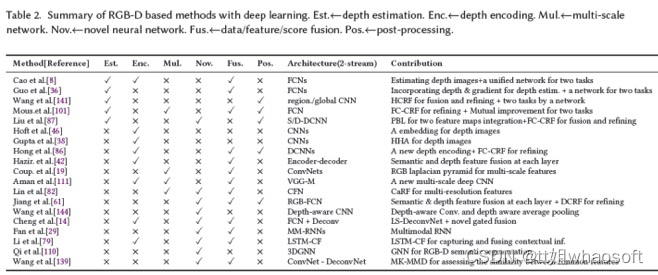
RGB-D图像中的深度图包含关于真实世界的几何信息,这有助于区分前景目标和背景,从而提供提高分割精度的可能。在这一类别中,通常使用经典的双通道网络分别从RGB和深度图像中提取特征。然而框架过于简单,无法提取丰富而精细的特征。为此,研究人员将几个附加模块集成到上述简单的双通道框架中,通过学习对语义分割至关重要的丰富上下文和几何信息来提高性能。这些模块大致可分为六类:多任务学习、深度编码、多尺度网络、新型神经网络结构、数据/特征/得分级融合和后处理(见图5)。表2中总结了基于RGB-D图像的语义分割方法。
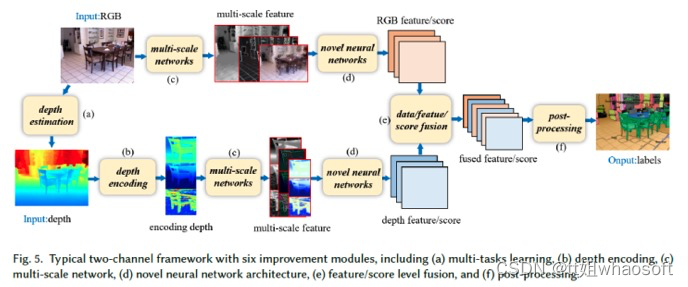
多任务学习:深度估计和语义分割是计算机视觉中两个具有挑战性的基本任务。这些任务也有一定的相关性,因为与不同目标之间的深度变化相比,目标内的深度变化较小。因此,许多研究者选择将深度估计任务和语义分割任务结合起来。从两个任务的关系来看,多任务学习框架主要有两种类型:级联式和并行式。级联式的工作有8、36,级联框架分阶段进行深度估计和语义分割,无法端到端训练。因此,深度估计任务并没有从语义分割任务中获得任何好处。并行式的工作有141、101、87,读者具体可以参考相关论文。
深度编码:传统的2D CNN无法利用原始深度图像的丰富几何特征。另一种方法是将原始深度图像编码为适合2D-CNN的其他表示。Hoft等人46使用定向梯度直方图(HOG)的简化版本来表示RGB-D场景的深度通道。Gupta等人38和Aman等人82根据原始深度图像计算了三个新通道,分别为水平视差、地面高度和重力角(HHA)。Liu等人86指出了HHA的局限性,即某些场景可能没有足够的水平和垂直平面。因此,他们提出了一种新的重力方向检测方法,通过拟合垂直线来学习更好的表示。Hazirbas等人42还认为,HHA表示具有较高的计算成本,并且包含比原始深度图像更少的信息。并提出了一种称为FuseNet的架构,该架构由两个编码器-解码器分支组成,包括一个深度分支和一个RGB分支,且以较低的计算负载直接编码深度信息。
多尺度网络:由多尺度网络学习的上下文信息对于小目标和详细的区域分割是有用的。Couprie等人19使用多尺度卷积网络直接从RGB图像和深度图像中学习特征。Aman等人111提出了一种用于分割的多尺度deep ConvNet,其中VGG16-FC网络的粗预测在scale-2模块中被上采样。然而,这种方法对场景中的杂波很敏感,导致输出误差。Lin等人82利用了这样一个事实:较低场景分辨率区域具有较高的深度,而较高场景分辨率区域则具有较低的深度。他们使用深度图将相应的彩色图像分割成多个场景分辨率区域,并引入context-aware receptive field(CaRF),该感知场专注于特定场景分辨率区域的语义分割。这使得他们的管道成为多尺度网络。
新型神经网络结构:由于CNN的固定网格计算,它们处理和利用几何信息的能力有限。因此,研究人员提出了其他新颖的神经网络架构,以更好地利用几何特征以及RGB和深度图像之间的关系。这些架构可分为四大类:改进2D CNN,相关工作有61、144;逆卷积神经网络(DeconvNets),相关工作有87、139、14;循环神经网络(RNN),相关工作有29、79;图神经网络(GNN),相关工作有110。
数据/特征/得分融合:纹理(RGB通道)和几何(深度通道)信息的最优融合对于准确的语义分割非常重要。融合策略有三种:数据级、特征级和得分级,分别指早期、中期和晚期融合。数据融合最简单的方式是将RGB图像和深度图像concat为4通道输入CNN19中,这种方式比较粗暴,没有充分利用深度和光度通道之间的强相关性。特征融合捕获了这些相关性,相关工作有79、139、42、61。得分级融合通常使用简单的平均策略进行。然而,RGB模型和深度模型对语义分割的贡献是不同的,相关工作有86、14。
后处理:用于RGB-D语义分割的CNN或DCNN的结果通常非常粗糙,导致边缘粗糙和小目标消失。解决这个问题的一个常见方法是将CNN与条件随机场(CRF)耦合。Wang等人141通过分层CRF(HCRF)的联合推断进一步促进了两个通道之间的相互作用。它加强了全局和局部预测之间的协同作用,其中全局用于指导局部预测并减少局部模糊性,局部结果提供了详细的区域结构和边界。Mousavian等人101、Liu等人87和Long等人86采用了全连接CRF(FC-CRF)进行后处理,其中逐像素标记预测联合考虑几何约束,如逐像素法线信息、像素位置、强度和深度,以促进逐像素标记的一致性。类似地,Jiang等人61提出了将深度信息与FC-CRF相结合的密集敏感CRF(DCRF)。
基于投影图像
基于投影图像的语义分割的核心思想是使用2D CNN从3D场景/形状的投影图像中提取特征,然后融合这些特征用于标签预测。与单目图像相比,该范式不仅利用了来自大规模场景的更多语义信息,而且与点云相比,减少了3D场景的数据大小。投影图像主要包括多目图像或球形图像。表3总结了基于投影图像的语义分割方法。
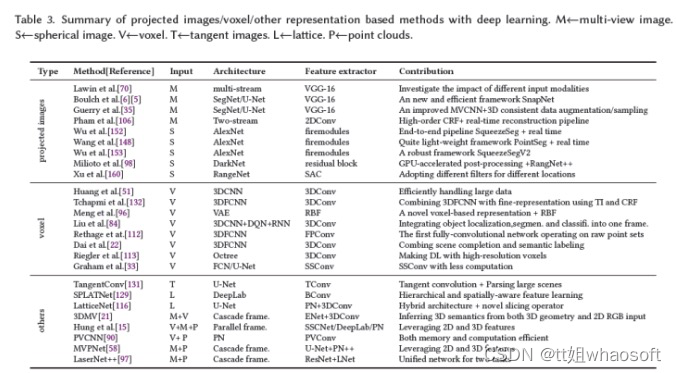
基于多目图像
MV-CNN130使用统一网络将由虚拟相机形成的3D形状的多个视图中的特征组合到单个紧凑的形状描述子中,以获得更好的分类性能。这促使研究人员将同样的想法应用于3D语义分割(见图6)。例如,Lawin等人70将点云投影到多目合成图像中,包括RGB、深度和表面法线图像。将所有多目图像的预测分数融合到单个表示中,并将其反向投影到每个点云中。然而,如果点云的密度较低,图像可能会错误地捕捉到观测结构背后的点云,这使得深度网络误解了多目图像。为此,SnapNet6、5对点云进行预处理,以计算点云特征(如正常或局部噪声)并生成网格,这与点云密度化类似。从网格和点云中,它们通过适当的快照生成RGB和深度图像。然后使用FCN对2D快照进行逐像素标记,并通过高效缓冲将这些标记快速重投影回3D点云。其他相关算法35、106可参考具体论文。
基于球形图像
从3D场景中选择快照并不直接。必须在适当考虑视点数量、视距和虚拟相机角度后拍摄快照,以获得完整场景的最优表示。为了避免这些复杂性,研究人员将整个点云投影到一个球体上(见图6底部)。例如,Wu等人152提出了一个名为SqueezeSeg的端到端管道,其灵感来自SqueezeNet53,用于从球形图像中学习特征,然后由CRF将其细化为循环层。类似地,PointSeg148通过整合特征和通道注意力来扩展SqueezeNet,以学习鲁棒表示。其他相关算法还有153、98、160。
基于体素
与像素类似,体素将3D空间划分为具有特定大小和离散坐标的许多体积网格。与投影图像相比,它包含更多的场景几何信息。3D ShapeNets156和VoxNet94将体积占用网格表示作为用于目标识别的3D CNN的输入,该网络基于体素指导3D语义分割。根据体素大小的统一性,基于体素的方法可分为均匀体素方法和非均匀体素法。表3总结了基于体素的语义分割方法。
均匀体素
3D CNN是用于处理标签预测的统一体素的通用架构。Huang等人51提出了用于粗体素水平预测的3D FCN。他们的方法受到预测之间空间不一致性的限制,并提供了粗略的标记。Tchapmi等人132引入了一种新的网络SEGCloud来产生细粒度预测。其通过三线性插值将从3D FCN获得的粗体素预测上采样到原始3D点云空间分辨率。对于固定分辨率的体素,计算复杂度随场景比例的增加而线性增长。大体素可以降低大规模场景解析的计算成本。Liu等人84介绍了一种称为3DCNN-DQN-RNN的新型网络。与2D语义分割中的滑动窗口一样,该网络在3D-CNN和deep Q-Network(DQN)的控制下,提出了遍历整个数据的眼睛窗口,用于快速定位和分割目标。3D-CNN和残差RNN进一步细化眼睛窗口中的特征。该流水线有效地学习感兴趣区域的关键特征,以较低的计算成本提高大规模场景解析的准确性。其他相关工作112、22、96可以参考论文。
非均匀体素
在固定比例场景中,随着体素分辨率的增加,计算复杂度呈立方增长。然而,体素表示自然是稀疏的,在对稀疏数据应用3D密集卷积时会导致不必要的计算。为了缓解这个问题,OcNet113使用一系列不平衡的八叉树将空间分层划分为非均匀体素。树结构允许内存分配和计算集中于相关的密集体素,而不牺牲分辨率。然而,empty space仍然给OctNet带来计算和内存负担。相比之下,Graham等人33提出了一种新的子流形稀疏卷积(SSC),它不在empty space进行计算,弥补了OcNet的缺陷。
基于点云
点云在3D空间中不规则地散布,缺乏任何标准顺序和平移不变性,这限制了传统2D/3D卷积神经网络的使用。最近,一系列基于点云的语义分割网络被提出。这些方法大致可分为三类:基于多层感知器(MLP)的、基于点云卷积的和基于图卷积。表4总结了这些方法。
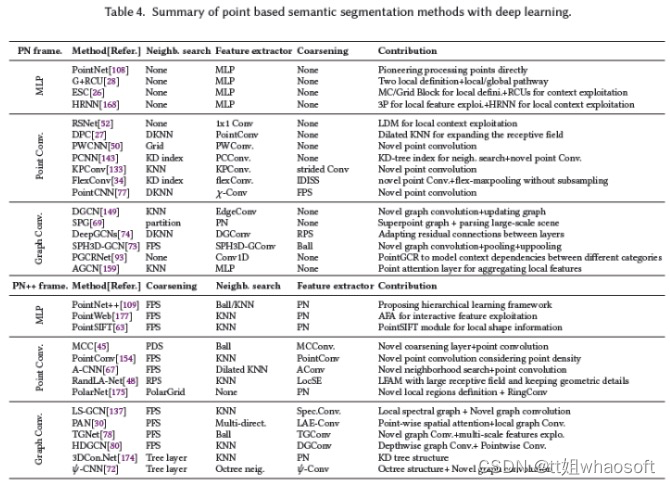
基于MLP
这些方法直接使用MLP学习点云特征。根据其框架,可进一步分为两类:基于PN和基于PN++框架的方法,如图7(a)和(b)所示。
基于PN框架
PointNet108(PN)是一项直接处理点云的开创性工作。它使用共享MLP来挖掘逐点云特征,并采用max-pooling等对称函数来将这些特征聚合到全局特征表示中。由于max-pooling仅捕获全局点云的最大激活,因此PN无法学习利用局部特征。基于PN框架,一些网络开始定义局部区域以增强局部特征学习,并利用递归神经网络(RNN)来增加上下文特征的利用。例如,Engelmann等人28通过KNN聚类和K-means聚类定义局部区域,并使用简化PN提取局部特征。ESC26将全局区域点云划分为多尺度/网格块。连接的(局部)块特征附加到逐点云特征,并通过递归合并单元(RCU)进一步学习全局上下文特征。其他相关算法168可以参考论文。
基于PN++框架
基于PointNet,PointNet++109(PN++)定义了分层学习架构。它使用最远点采样(FPS)对点云进行分层采样,并使用k个最近邻搜索和球搜索对局部区域进行聚类。逐步地,简化的PointNet在多个尺度或多个分辨率下利用局部区域的功能。PN++框架扩展了感受野以共同利用更多的局部特征。受SIFT91的启发,PointSIFT63在采样层之前插入一个PointSIFT模块层,以学习局部形状信息。该模块通过对不同方向的信息进行编码,将每个点云转换为新的形状表示。类似地,PointWeb177在聚类层之后插入自适应特征调整(AFA)模块层,以将点云之间的交互信息嵌入到每个点云中。这些策略增强了学习到的逐点云特征的表示能力。然而,MLP仍然单独处理每个局部点云,并且不注意局部点云之间的几何连接。此外,MLP是有效的,但缺乏捕捉更广泛和更精细的局部特征的复杂性。
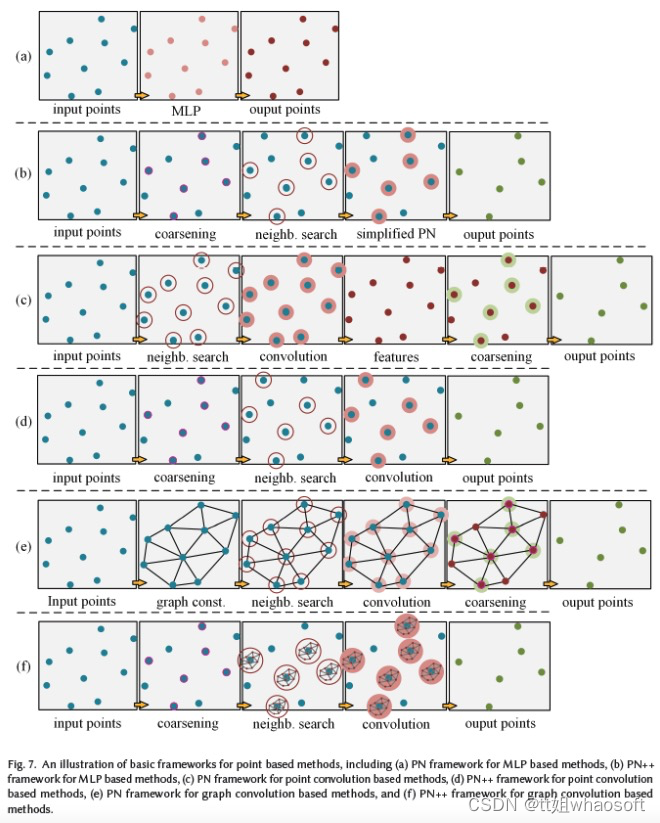
基于点云卷积
基于点云卷积的方法直接对点云进行卷积运算。与基于MLP的分割类似,这些网络也可以细分为基于PN框架的方法和基于PN++框架的方法,如图7(c)、(d)所示。
基于PN
基于PN框架的方法对每个点云的相邻点云进行卷积。例如,RSNet52使用1x1卷积利用逐点云特征,然后将它们传递给local dependency module(LDM),以利用局部上下文特征。但是,它并没有为每个点云定义邻域以了解局部特征。另一方面,PointwiseCNN50按照特定的顺序对点云进行排序,例如XYZ坐标或Morton曲线100,并动态查询最近邻,并将它们放入3x3x3 kernel中,然后使用相同的内核权重进行卷积。DPC27在通过dilated KNN搜索确定邻域点云的每个点云的邻域点云上调整点卷积154。该方法将扩张机制整合到KNN搜索中,以扩大感受野。PCNN143在KD-tree邻域上进行参数化CNN,以学习局部特征。然而,特征图的固定分辨率使得网络难以适应更深层次的架构。其他相关算法133、34、77可以参考具体论文。
基于PN++
基于PN++框架的方法将卷积层作为其关键层。例如,蒙特卡罗卷积近似的一个扩展叫做PointConv154,它考虑了点云密度。使用MLP来近似卷积核的权重函数,并使用inverse density scale来重新加权学习的权重函数。类似地,MCC45通过依赖点云概率密度函数(PDF)将卷积表述为蒙特卡罗积分问题,其中卷积核也由MLP表示。此外,它引入了Possion Disk Sampling(PDS)151来构建点云层次结构,而不是FPS,这提供了一个在感受野中获得最大样本数的机会。A-CNN67通过扩展的KNN定义了一个新的局部环形区域,并将点云投影到切线平面上,以进一步排序局部区域中的相邻点云。然后,对这些表示为闭环阵列的有序邻域进行标准点云卷积。其他相关算法48、175可以参考具体论文。
基于图卷积
基于图卷积的方法对与图结构连接的点云进行卷积。在这里,图的构造(定义)和卷积设计正成为两个主要挑战。PN框架和PN++框架的相同分类也适用于图7(e)和(f)所示的图卷积方法。
基于PN
基于PN框架的方法从全局点云构造图,并对每个点云的邻域点云进行卷积。例如,ECC125是应用空间图形网络从点云提取特征的先驱方法之一。它动态生成edge-conditioned filters,以学习描述点云与其相邻点云之间关系的边缘特征。基于PN架构,DGCN149在每个点云的邻域上实现称为EdgeConv的动态边缘卷积。卷积由简化PN近似。SPG69将点云划分为若干简单的几何形状(称为super-points),并在全局super-points上构建super graph。此外,该网络采用PointNet来嵌入这些点云,并通过门控递归单元(GRU)细化嵌入。其他相关算法74、73、93、159可以参考具体论文。
基于PN++
基于PN++框架的方法对具有图结构的局部点云进行卷积。图是光谱图或空间图。在前一种情况下,LS-GCN137采用了PointNet++的基本架构,使用标准的非参数化傅立叶kernel将MLP替换为谱图卷积,以及一种新的spectral cluster pooling替代max-pooling。然而,从空间域到频谱域的转换需要很高的计算成本。此外,谱图网络通常定义在固定的图结构上,因此无法直接处理具有不同图结构的数据。相关算法可以参考30、78、80、174、72。
基于其他表示
一些方法将原始点云转换为投影图像、体素和点云以外的表示。这种表示的例子包括正切图像131和晶格129、116。在前一种情况下,Tatargenko等人131将每个点云周围的局部曲面投影到一系列2D切线图像,并开发基于切线卷积的U-Net来提取特征。在后一种情况下,SPLATNet129采用Jampani等人56提出的双边卷积层(BCL)将无序点云平滑映射到稀疏网格上。类似地,LatticeNet116使用了一种混合架构,它将获得低级特征的PointNet与探索全局上下文特征的稀疏3D卷积相结合。这些特征嵌入到允许应用标准2D卷积的稀疏网格中。尽管上述方法在3D语义分割方面取得了重大进展,但每种方法都有其自身的缺点。例如,多目图像具有更多的语义信息,但场景的几何信息较少。另一方面,体素具有更多的几何信息,但语义信息较少。为了获得最优性能,一些方法采用混合表示作为输入来学习场景的综合特征。相关算法21、15、90、58、97可以参考具体论文。
4 3D实例分割
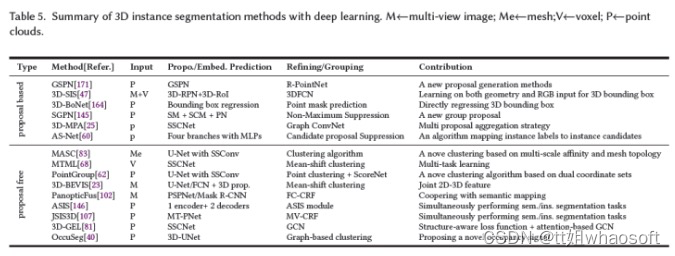
3D实例分割方法另外区分同一类的不同实例。作为场景理解的一项信息量更大的任务,3D实例分割越来越受到研究界的关注。3D实例分割方法大致分为两个方向:基于Proposal和无Proposal。
基于Proposal
基于Proposal的方法首先预测目标Proposal,然后细化它们以生成最终实例mask(见图8),将任务分解为两个主要挑战。因此,从Proposal生成的角度来看,这些方法可以分为基于检测的方法和无检测的方法。
基于检测的方法有时将目标Proposal定义为3D边界框回归问题。3D-SIS47基于3D重建的姿态对齐,将高分辨率RGB图像与体素结合,并通过3D检测主干联合学习颜色和几何特征,以预测3D目标框Proposal。在这些Proposal中,3D mask主干预测最终实例mask。其他相关算法171、164可以参考论文。
无检测方法包括SGPN145,它假定属于同一目标实例的点云应该具有非常相似的特征。因此,它学习相似度矩阵来预测Proposal。这些Proposal通过置信度分数过滤,以生成高度可信的实例Proposal。然而,这种简单的距离相似性度量学习并不能提供信息,并且不能分割同一类的相邻目标。为此,3D-MPA25从投票给同一目标中心的采样和聚类点云特征中学习目标Proposal,然后使用图卷积网络合并Proposal特征,从而实现Proposal之间的更高层次交互,从而优化Proposal特征。AS Net60使用分配模块来分配Proposal候选,然后通过抑制网络消除冗余候选。
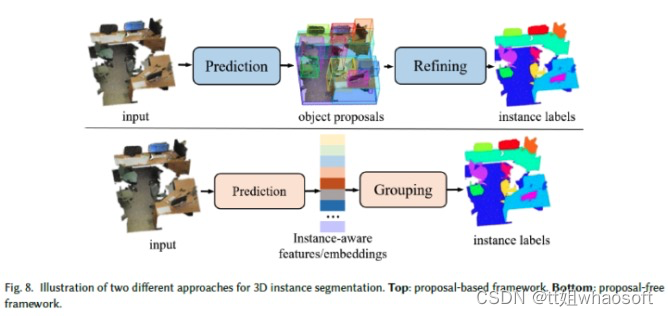
Proposal Free
无Proposal 方法学习每个点云的特征嵌入,然后使用聚类以获得明确的3D实例标签(见图8),将任务分解为两个主要挑战。从嵌入学习的角度来看,这些方法可以大致分为三类:多嵌入学习、2D嵌入传播和多任务学习。
多嵌入学习:MASC83等方法依靠SSCN33的高性能来预测多尺度和语义拓扑上相邻点云之间的相似性嵌入。简单而有效的聚类89适用于基于两种类型的学习嵌入将点云分割为实例。MTML68学习两组特征嵌入,包括每个实例唯一的特征嵌入和定向实例中心的方向嵌入,这提供了更强的聚类能力。类似地,PointGroup62基于原始坐标嵌入空间和偏移的坐标嵌入空间将点云聚类为不同的簇。
2D嵌入传播:这些方法的一个例子是3D-BEVIS23,它通过鸟瞰整个场景来学习2D全局实例嵌入。然后通过DGCN149将学习到的嵌入传播到点云上。另一个例子是PanopticFusion102,它通过2D实例分割网络Mask R-CNN43预测RGB帧的逐像素实例标签。
多任务联合学习:3D语义分割和3D实例分割可以相互影响。例如,具有不同类的目标必须是不同的实例,具有相同实例标签的目标必须为同一类。基于此,ASIS146设计了一个称为ASIS的编码器-解码器网络,以学习语义感知的实例嵌入,从而提高这两个任务的性能。类似地,JSIS3D107使用统一网络即MT-PNet来预测点云的语义标签,并将点云嵌入到高维特征向量中,并进一步提出MV-CRF来联合优化目标类和实例标签。类似地,Liu等人83和3D-GEL81采用SSCN来同时生成语义预测和实例嵌入,然后使用两个GCN来细化实例标签。OccusSeg40使用多任务学习网络来产生occupancy signal和空间嵌入。occupancy signal表示每个体素占用的体素数量。表5总结了3D实例分割方法。
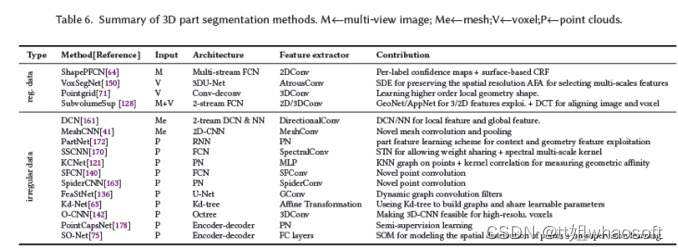
5 3D部件分割
3D部件分割是继实例分割之后的下一个更精细的级别,其目的是标记实例的不同部分。部件分割的管道与语义分割的管道非常相似,只是标签现在是针对单个部件的。因此,一些现有的3D语义分割网络96、33、108、109、174、52、133、50、45、154、77、149、73、159、143、34、72、129、116也可用于部件分割。然而,这些网络并不能完全解决部件分割的困难。例如,具有相同语义标签的各个部件可能具有不同的形状,并且具有相同语义标记的实例的部件数量可能不同。我们将3D部件分割方法细分为两类:基于规则数据的和基于不规则数据的,如下所示。
基于规则数据
规则数据通常包括投影图像64、体素150、71、128。对于投影图像,Kalogerakis等人64从多个视图中获得一组最佳覆盖物体表面的图像,然后使用多视图全卷积网络(FCN)和基于表面的条件随机场(CRF)分别预测和细化部件标签。体素是几何数据的有效表示。然而,像部件分割这样的细粒度任务需要具有更详细结构信息的高分辨率体素,这导致了较高的计算成本。Wang等人150建议VoxSegNet利用有限分辨率的体素中更详细的信息。它们在子采样过程中使用空间密集提取来保持空间分辨率,并使用attention feature aggregation(AFA)模块来自适应地选择尺度特征。其他相关算法71、128可以参考论文。
基于不规则数据
不规则数据表示通常包括网格161、41和点云75、121、170、136、140、172、178。网格提供了3D形状的有效近似,因为它捕捉到了平面、尖锐和复杂的表面形状、表面和拓扑。Xu等人161将人脸法线和人脸距离直方图作为双流框架的输入,并使用CRF优化最终标签。受传统CNN的启发,Hanocka等人41设计了新颖的网格卷积和池化,以对网格边缘进行操作。对于点云,图卷积是最常用的管道。在频谱图领域,SyncSpecCNN170引入了同步频谱CNN来处理不规则数据。特别地,提出了多通道卷积核和参数化膨胀卷积核,分别解决了多尺度分析和形状信息共享问题。在空间图域中,类似于图像的卷积核,KCNet121提出了point-set kernel和nearest-neighbor-graph,以改进PointNet,使其具有高效的局部特征提取结构。其他相关算法140、163、136、65、142、75、172、178可以参考论文。3D部件的相关算法总结如下表所示。
6 3D分割的应用无人驾驶系统
随着激光雷达和深度相机的普及,价格也越来越实惠,它们越来越多地应用于无人驾驶系统,如自动驾驶和移动机器人。这些传感器提供实时3D视频,通常为每秒30帧(fps),作为系统的直接输入,使3D视频语义分割成为理解场景的主要任务。此外,为了更有效地与环境交互,无人系统通常会构建场景的3D语义图。下面回顾基于3D视频的语义分割和3D语义地图构建。
3D视频语义分割
与前文介绍的3D单帧/扫描语义分割方法相比,3D视频(连续帧/扫描)语义分割方法考虑了帧之间连接的时空信息,这在稳健和连续地解析场景方面更为强大。传统的卷积神经网络(CNN)没有被设计成利用帧之间的时间信息。一种常见的策略是自适应RNN(134、24)或时空卷积网络(44、17、122)。
3D语义地图重建
无人系统不仅需要避开障碍物,还需要建立对场景的更深理解,例如目标解析、自我定位等。3D场景重建通常依赖于同时定位和建图系统(SLAM)来获得没有语义信息的3D地图。随后用2D-CNN进行2D语义分割,然后在优化(例如条件随机场)之后将2D标签转移到3D地图以获得3D语义地图165。这种通用管道无法保证复杂、大规模和动态场景中的3D语义地图的高性能。研究人员已经努力使用来自多帧的关联信息(92、95、157、13、66)、多模型融合(59、176)和新的后处理操作来增强鲁棒性。
医疗诊断
2D U-Net115和3D U-Net18通常用于医学图像分割。基于这些基本思想,设计了许多改进的体系结构,主要可分为四类:扩展的3D U-Net(9、173、117)、联合的2D-3D CNN(105、2、138、76)、带优化模块的CNN(99、179、126、104)和分层网络(11、57、118、135、166、167、119)。
7 实验结果
3D语义分割结果
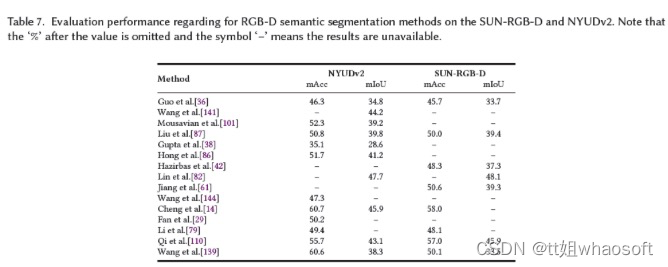
论文报告了基于RGB-D的语义分割方法在SUN-RGB-D127和NYUDv2124数据集上的结果,使用mAcc和mIoU作为评估指标。各种方法的这些结果取自原始论文,如表7所示。下表所示。
论文在S3DIS1(5折和6折交叉验证)、ScanNet20(测试集)、Semantic3D39(缩减的8个子集)和SemanticKITTI3(仅xyz,无RGB)上报告了投影图像/体素/点云/其他表示语义分割方法的结果。使用mAcc、oAcc和mIoU作为评估指标。这些不同方法的结果取自原始论文。表8列出了结果。
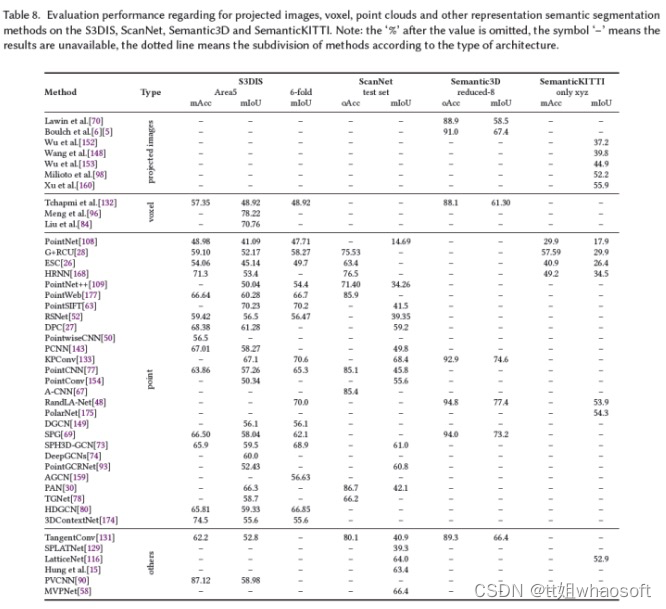
由于本文的主要兴趣是基于点云的语义分割方法,因此重点对这些方法的性能进行详细分析。为了捕获对语义分割性能至关重要的更广泛的上下文特征和更丰富的局部特征,在基本框架上提出了几种专用策略。
- 基础网络是3D分割发展的主要推动力之一。一般来说,有两个主要的基本框架,包括PointNet和PointNet++框架,它们的缺点也指出了改进的方向;
- 自然环境中的物体通常具有各种形状。局部特征可以增强目标的细节分割;
- 3D场景中的目标可以根据与环境中的其他目标的某种关系来定位。已经证明,上下文特征(指目标依赖性)可以提高语义分割的准确性,特别是对于小的和相似的目标。
3D实例分割结果
论文报告了ScanNet20数据集上3D实例分割方法的结果,并选择mAP作为评估指标。这些方法的结果取自ScanNet Benchmark Challenge网站,如表9所示,并在图9中总结。该表和图如下所示:
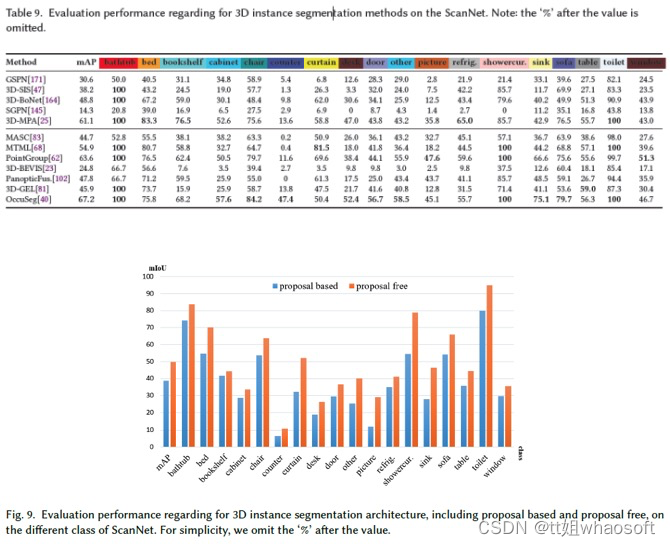
- OccusSeg40具有最先进的性能,在本文调查时,ScanNet数据集的平均精度为67.2%;
- 大多数方法在诸如"浴缸"和"厕所"之类的大规模类上具有更好的分割性能,而在诸如"柜台"、"桌子"和"图片"之类的小规模类上具有较差的分割性能。因此,小目标的实例分割是一个突出的挑战;
- 在所有类的实例分割方面,无Proposal方法比基于提案的方法具有更好的性能,尤其是对于"窗帘"、"其他"、"图片"、"淋浴帘"和"水槽"等小目标;
- 在基于Proposal的方法中,基于2D嵌入传播的方法,包括3D-BEVIS23、PanoticFusion102,与其他基于无提案的方法相比,性能较差。简单的嵌入传播容易产生错误标签。
3D部件分割结果
论文报告了ShapeNet169数据集上3D零件分割方法的结果,并使用了Ins.mIoU作为评估度量。各种方法的这些结果取自原始论文,如表10所示。我们可以看到:
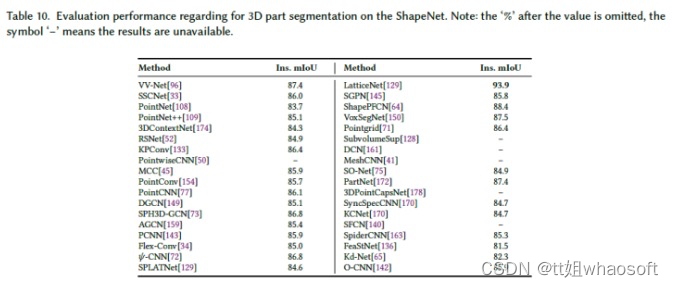
- LatticeNet40具有最先进的性能,在本文调查时,ShapeNet数据集的平均精度为93.9%;
- 所有方法的部件分割性能非常相似。
8 讨论和结论
论文使用深度学习技术,包括3D语义分割、3D实例分割和3D部件分割,对3D分割的最新发展进行了全面综述。论文对每个类别中的各种方法进行了全面的性能比较和优点。近年来,使用深度学习技术的3D分割取得了重大进展。然而,这仅仅是一个开始,重要的发展摆在我们面前。下面,论文提出一些悬而未决的问题,并确定潜在的研究方向。
合成数据集为多个任务提供了更丰富的信息:与真实数据集相比,合成数据集成本低、场景多样,因此在语义分割方面逐渐发挥重要作用7、155。众所周知,训练数据中包含的信息决定了场景解析精度的上限。现有的数据集缺少重要的语义信息,如材料和纹理信息,这对于具有相似颜色或几何信息的分割更为关键。此外,大多数现有数据集通常是为单个任务设计的。目前,只有少数语义分割数据集还包含实例20和场景布局127的标签,以满足多任务目标。
多任务的统一网络:对于一个系统来说,通过各种深度学习网络来完成不同的计算机视觉任务是昂贵且不切实际的。对于场景的基本特征开发,语义分割与一些任务具有很强的一致性,例如深度估计97、85、36、141、1141、87、场景补全22、实例分割146、107、81和目标检测97。这些任务可以相互协作,以提高统一网络中的性能。语义/实例分割可以进一步与部件分割和其他计算机视觉任务相结合,用于联合学习。
场景解析的多种模式:使用多个不同表示的语义分割,例如投影图像、体素和点云,可能实现更高的精度。然而,由于场景信息的限制,如图像的几何信息较少,体素的语义信息较少,单一表示限制了分割精度。多重表示(多模态)将是提高性能的另一种方法21,15,90,58,97。
高效的基于点云卷积的网络:基于点云的语义分割网络正成为当今研究最多的方法。这些方法致力于充分探索逐点云特征和点云/特征之间的连接。然而,他们求助于邻域搜索机制,例如KNN、ball query109和分层框架154,这很容易忽略局部区域之间的低级特征,并进一步增加了全局上下文特征开发的难度。
弱监督和无监督的3D分割:深度学习在3D分割方面取得了显著的成功,但严重依赖于大规模标记的训练样本。弱监督和无监督学习范式被认为是缓解大规模标记数据集要求的替代方法。目前,工作162提出了一个弱监督网络,它只需要对一小部分训练样本进行标记。75、178提出了一种无监督网络,该网络从数据本身生成监督标签。
大规模场景的语义分割**:**大规模场景的语义分割一直是研究的热点。现有方法仅限于极小的3D点云108、69(例如,4096个点云或1x1米块),在没有数据预处理的情况下,无法直接扩展到更大规模的点云(例如,数百万个点云或数百米)。尽管RandLA Net48可以直接处理100万个点,但速度仍然不够,需要进一步研究大规模点云上的有效语义分割问题。
3D视频语义分割:与2D视频语义分割一样,少数作品试图在3D视频上利用4D时空特征(也称为4D点云)17,122。从这些工作中可以看出,时空特征可以帮助提高3D视频或动态3D场景语义分割的鲁棒性。
#FastPillars实时3D
3D检测器的部署是现实世界自动驾驶场景中的主要挑战之一。现有的基于BEV(即鸟瞰图)的检测器支持稀疏卷积(称为SPConv),以加快训练和推理,这为部署(尤其是在设备上应用)带来了困难。在本文中解决了从LiDAR点云中高效检测3D目标的问题,并考虑了部署。为了减少计算负担提出了一种从行业角度来看具有高性能的基于Pillar的3D检测器,称为FastPillars。与以前的方法相比,本文引入了一个更有效的最大和注意力Pillar编码(MAPE)模块,并以重参化的方式重新设计了一个功能强大、轻量级的骨干CRVNet,CRVNet结合了Cross Stage Partial network(CSP),形成了一个紧凑的特征表示框架。大量实验表明,FastPillars在设备速度和性能方面都超过了最先进的3D检测器。具体而言,FastPillars可以通过TensorRT有效部署,在nuScenes测试集上使用64.6 mAP的单个RTX3070Ti GPU获得实时性能(~24FPS)。
使用LiDAR点云的3D目标检测在自动驾驶和机器人领域有着广泛的应用。与RGB图像相比,3D点云对照明变化不太敏感,可以准确地表示场景的几何信息。然而,基于激光雷达的3D目标检测有其自身的挑战。
首先,与规则矩阵的图像不同,点云是不规则和无序的。第二,与密集图像不同,点云是稀疏的,并且在空间上是离散的,尤其是远离自身的点。第三,与2D检测相比,3D目标检测需要估计更高的空间维度信息(例如,3D位置、3D大小、方向),这使其更加复杂。
主流方法之一是直接从原始点云中学习区分表示,而不将其转换为体素网格。在这些方法中,对称函数被用来处理点的无序性。尽管这些方法尽可能保留点云的原始几何信息,但这些方法可能对有效的硬件实现不友好,因为它们通常需要在3D空间中进行点查询/检索(例如,PointNet++)。
基于体素的3D检测器是另一种主流解决方案。在这些方法中,首先将不规则点云转换为排列的网格(即体素),然后使用2D/3D CNN提取特征。在体素化过程之后,由于点云的稀疏性,将生成许多空网格,这将导致巨大的冗余计算开销。
为了提高计算效率,一些方法使用三维稀疏卷积来跳过空网格上的卷积计算。尽管稀疏卷积是有效的,但当转换为ONNX/TensorRT进行部署和网络量化时,它会带来挑战,并阻碍通过这些技术进一步加速。这些技术通常将模型推理速度提高几倍,并广泛用于工业深度学习模型部署,特别是在资源受限的平台上。
目前,设备上部署的流行方法之一是PointPillars。在该方法中,首先将点云转换为Pillar(即,仅在平面中进行体素化),然后使用PointNet学习每个Pillar中的点的特征。然后,应用2D检测器流水线来预测3D边界框。该方法仅采用2D卷积,易于转换为ONNX/TensorRT进行部署,并利用各种精度的网络量化FP32/FP16/Int8,满足不同嵌入式平台的要求。
然而,PointPillars只是利用最大池化操作来聚合一个Pillar中的所有点特征,这会大量减少局部细粒度信息,并降低性能,尤其是对于小目标。此外,基于特征金字塔网络(FPN),PointPillars以1×、2×和4×的步长直接融合多尺度特征,但不同层之间缺乏充分的特征交互。虽然PointPillars在速度上有很大的优势,但其性能仍远远落后于其他方法。
为了提高基于Pillar的方法的性能,提出了PillarNet,它可以在保持实时性的同时实现高性能的3D检测性能。PillarNet使用基于稀疏卷积的编码器网络进行空间特征学习,使用Neck模块进行高级和低级特征融合。
然而,在PillarNet中使用SPConv使得很难通过TensorRT进行量化和部署。具体而言,SPConv将难以量化的3D坐标作为输入。此外,如果想将常用的TensorRT用于量化部署,SPConv不是TensorRT中的内置操作。因此,需要在CUDAC++中编写一个自定义插件,并具有固定形状输入和兼容性降低等几个限制。它还需要考虑融合以实现快速执行,从而使部署过程更加复杂。
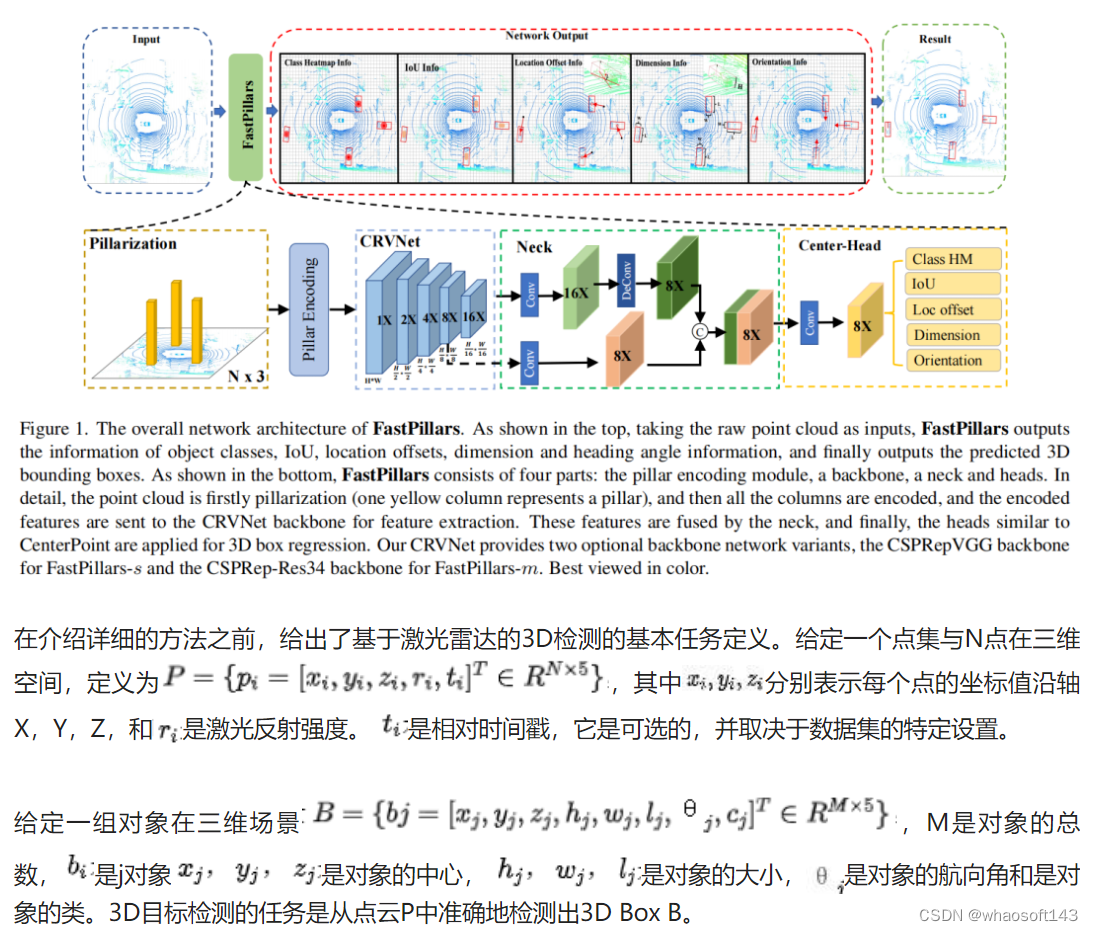
在本文中提出了一种来自LiDAR点云的高效3D目标检测器,称为FastPillars。FastPillars完全基于标准卷积,因此可以在工业应用中轻松部署,并无缝享受TensorRT和网络量化的加速。FastPillars由4个块组成,分别用于Pillar编码、特征提取、特征融合和3D边界框回归。
对于Pillar编码,本文提出了一种简单但有效的最大和注意力Pillar编码(MAPE)模块,该模块几乎无需额外延迟(4ms)即可自动学习局部几何图案。MAPE模块专注地整合了每个Pillar中的重要局部特征,这大大提高了小目标的准确性。
对于特征提取,为了增强模型的表示能力并减少低延迟机载部署的计算负担,设计了一个紧凑高效的骨干网络,名为CRVNet(Cross-Stage Patrial RepVGG style network)。
从CSP结构和重参化的RepVGG网络中汲取灵感,并提出了一个紧凑的网络,同时保持了强大的特征提取能力。此外,在特征融合块中,通过分层地融合来自不同层次和感受野的特征来丰富语义特征。对于回归模块,采用了一个高效的基于中心的Head来分别回归目标的得分、维度、位置、旋转和在联合上的框相交(IOU)信息。
将这些组件组合在一起,作者构建了FastPillars,这是一个完全卷积部署友好的基于柱的3D检测器。对于实时嵌入式应用,所提出的方法在速度和精度之间实现了更好的权衡。此外,大量实验表明FastPillars在nuScenes数据集上实现了最先进的性能。此外,它可以通过TensorRT无缝加速,达到24 FPS的速度。
贡献总结如下:
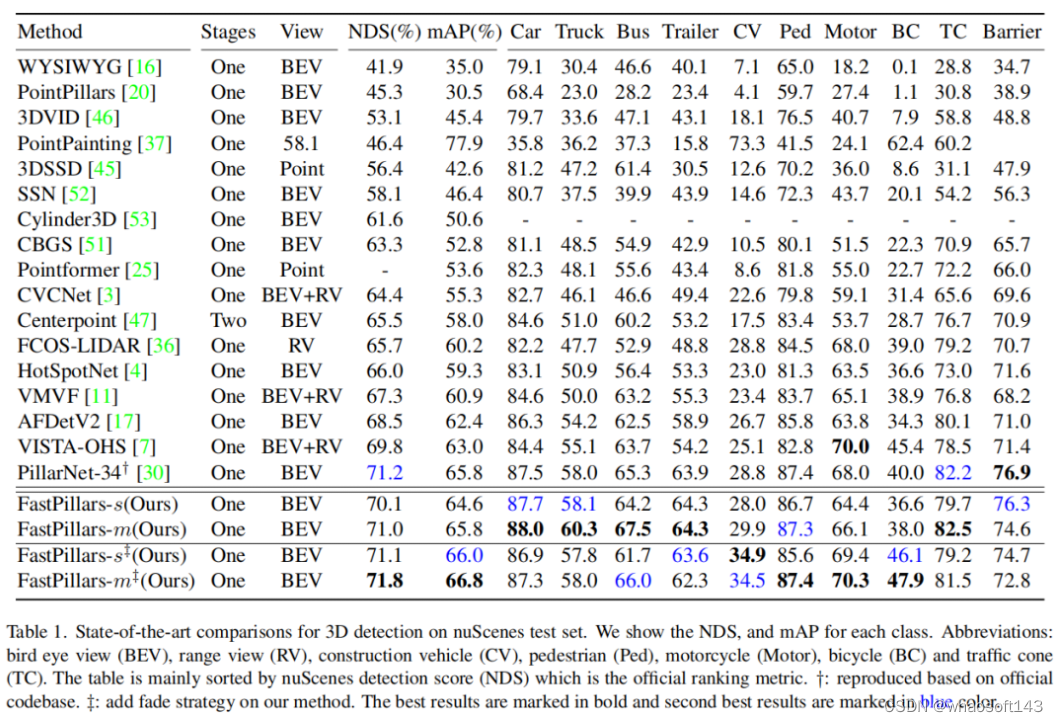
- 提出了一种基于Pillar的单阶段3D检测器,称为FastPillars。所提出的方法是部署友好的,消除了稀疏卷积的需要。作者还提出了FastPillars的两个实例,即FastPillars-s和FastPillars-m,在24 FPS和nes测试集上分别达到64.6 mAP和70.1 NDS,在16 FPS上达到66.0 mAP和71.1 NDS。
- 并提出了一种简单而有效的 Max-and-Attention Pillar Encoding(MAPE)模块。MAPE可以提高每个Pillar特性的表示能力,几乎不需要额外的延迟(只有≈4 ms)。
- 设计了一个紧凑的全卷积主干网络CRVNet,它具有竞争性的特征学习能力和推理速度,而不需要稀疏卷积。同时,还证明了专门为二维图像设计的轻量级网络结构可以很好地处理3D点云的任务,并在性能和速度之间实现了良好的权衡。
- 在nuScenes数据集上的大量实验表明,FastPillars具有优越的效率和准确的检测性能。还提供了一个详细的性能与推理速度分析,以进一步验证方法的优越性。
基于Voxel的三维探测器
基于体素的3D检测器通常将非结构化点云转换为紧凑形状的规则柱/体素网格。这进一步允许通过利用成熟的2D/3D卷积神经网络来学习点特征。
VoxelNet是一项开创性的工作,它对输入点云进行密集体素化,然后利用体素特征提取器(VFE)和3D CNN来学习几何表示。其缺点是由于3D卷积的巨大计算负担,推理速度相对较慢。
为了节省内存成本,SECOND使用3D稀疏卷积来加速训练和推理。这里,稀疏卷积仅对非空体素进行操作,这大大提高了计算和存储效率。SPConv的一个缺点是它对部署不友好,这使得在嵌入式系统上应用它们很困难。
为此,PointPillars被提议将体素进一步简化为Pillar(即,在高度上没有体素化),并利用高度优化的2D卷积,这在低延迟的情况下获得了良好的性能。同时,易于部署的优势使PointPillar成为实践中的主流方法。
之后,提出了CenterPoint,它使用几乎实时且Anchor-Free的管道,实现了最先进的性能。最近,PillarNet项目指向BEV空间,并使用基于"编码器颈部头部"架构的2D SPConv以实时速度提高3D检测性能。由于SPConv的使用,它不可避免地面临着在工业应用中部署的困难,并随着网络量化而进一步加速。
用于对象检测的工业级轻量级网络结构
多年来,YOLO系列一直是轻量级2D检测的事实上的行业标准,其主干设计主要继承了CSPNet的思想。通过在两个单独的分支中处理部分特征以获得更丰富的梯度组合,CSPNet不仅降低了内存和计算成本,而且提高了性能。
最近,RepVGG使用基于重参化的结构设计重构了著名的普通网络VGG。在训练期间,普通的Conv-BN-ReLU被其过度参数化的3分支对应物(即Conv3×3-BN、Conv1×1-BN和Identity BN)所取代,然后是3个分支相加后的ReLU函数。3分支结构实质上有助于网络优化,而重参化在推理时将3个分支相同地转换为一个分支,提高了推理效率。由于这一优势,这一趋势席卷了2D检测器,并在极端速度下表现出高性能,如PPYOLOE、YOLOv6和YOLOv7。
本文方法
在本节中将介绍用于实时基于Pillar的单阶段3D目标检测的FastPillars,这是一个端到端可训练和无spconv的神经网络。如图1所示,本文的网络架构由4个部分组成:Pillar编码模块、用于特征提取的主干、用于特征融合的Neck和用于3D框回归的头部。
Max-and-Attention Pillar Encoding
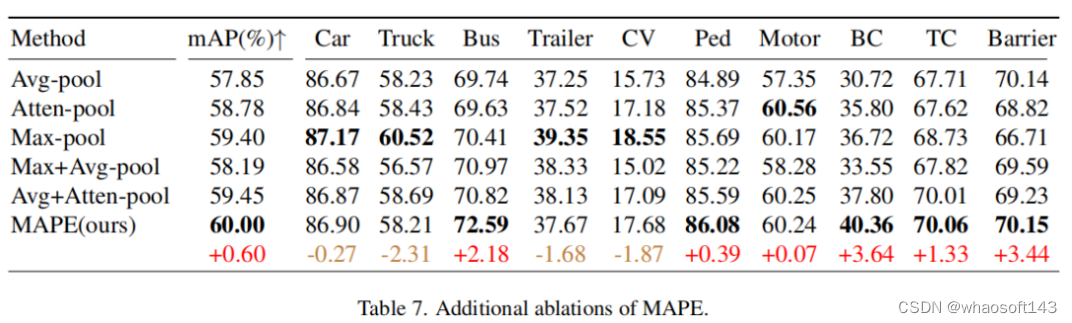
点云体素/Pillar编码对于基于网格的3D检测方法至关重要。开创性的PointPillars积极利用最大池化来聚合每个Pillar中的点特征,以表示相应的Pillar。然而,最大池化操作将导致细粒度信息的丢失,而这些局部几何模式对于基于Pillar的对象非常关键,尤其是对于小目标。
在本文中提出了一种简单但有效的Pillar编码模块,称为最大和注意力Pillar编码(MAPE),它考虑了每个Pillar的局部详细几何信息,计算负担可忽略不计,并有利于BEV中小目标(例如行人等)的性能。同时,MAPE模块的轻量级Pillar编码方法使其非常适合实时嵌入式应用。如图2所示,MAPE模块由3个单元组成:
- 点编码单元
- 最大池化编码单元
- 注意力池化编码单元
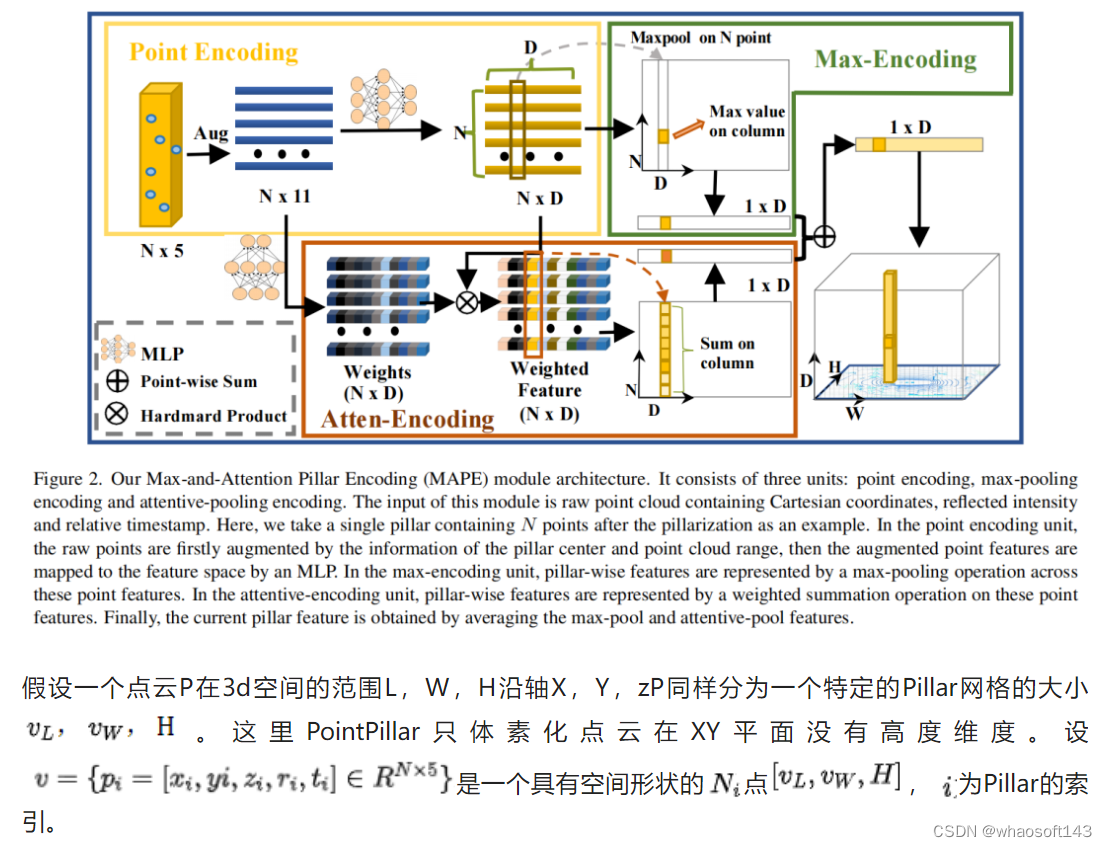


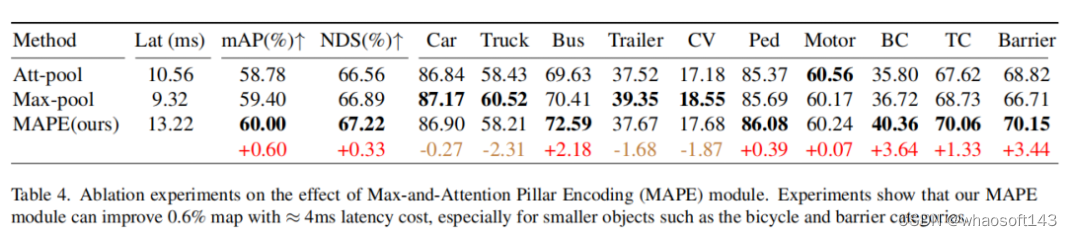
通过结合这两个特性,可以有效地保留更丰富的信息,以增强Pillar的表示。尽管这是一个简单的方法,但MAPE模块显著地影响了小目标的性能,如实验所示。值得注意的是,MAPE模块在nuScenes数据集上提高了大约0.6 mAP性能,只有额外的4ms延迟。
CRVNet Backbone
主干网络的目的是从投影的二维伪图像或三维体素特征中分层提取不同层次的语义特征。之前的工作通常使用稀疏卷积来基于ResNet或VGG 架构提取体素/Pillar 特征。稀疏卷积大大提高了计算效率,因为大多数体素/Pillar 都是空的。
例如,在nuScenes数据集中的单帧点云中,空Pillar 的比例约为90%。然而,在稀疏特征图上直接使用二维卷积会导致过高的计算负担和高延迟,这促使设计一个更紧凑、更有效的骨干网络。
受RepVGG和CSPNet的启发,提出了CRVNet((Cross-Stage-Patrial RepVGG-style Network)。网络的主要组成部分如图3所示。训练阶段的每个模块如图3(a)所示。在推断阶段(图3(b)),每个RepBlock被转换为具有激活函数的3×3卷积层(表示为RepConv)的堆栈。这是因为3×3卷积具有更高的计算密度,并且在大多数设备上效率很高。
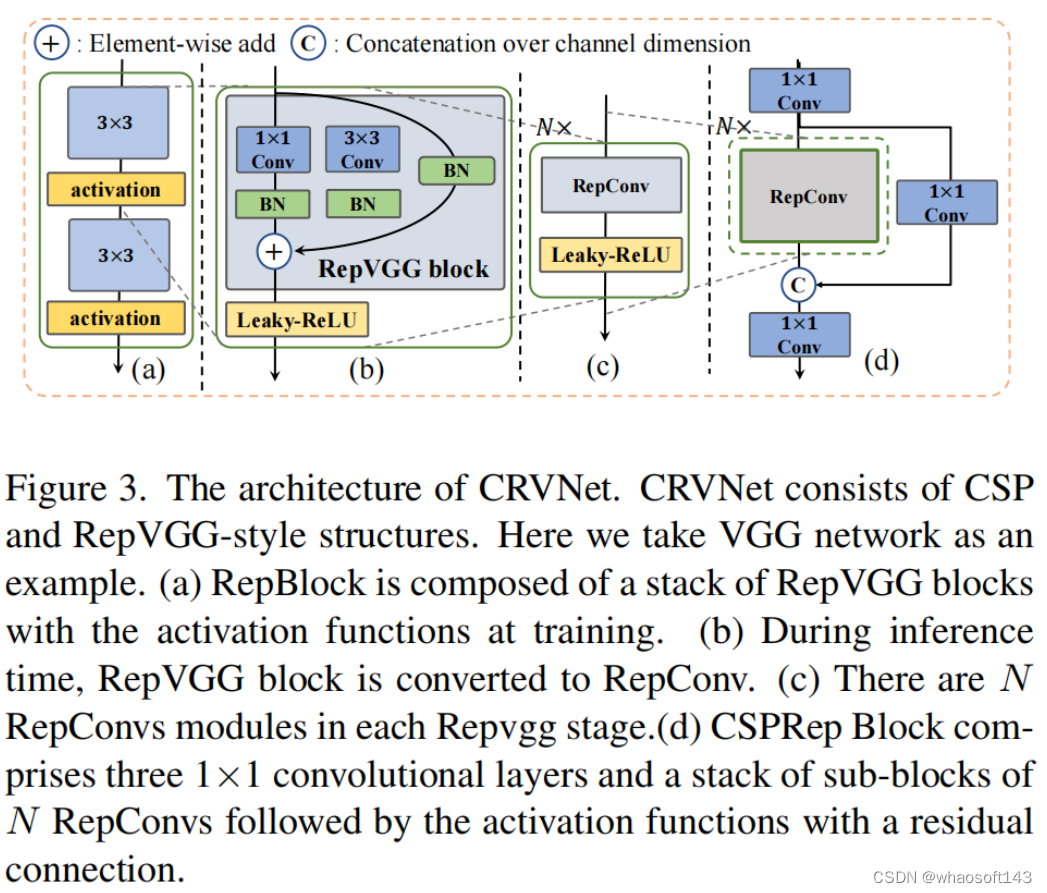
因此,RepBlock骨干网络以优异的特征表示能力显著降低了推断延迟。此外,作者注意到,如果模型容量进一步扩大,单路径网络中的计算成本和参数数量将呈指数增长。因此,进一步将RepBlock与CSP结构结合起来。如图3(d)所示,CSP结构由3个1×1卷积层和原始网络结构组成。
作者在主干网络的每个阶段使用CSP结构,其中每个阶段包含N个RepConv(图3(c))。通过引入CSP结构,整个网络具有更少的参数,并且更加紧凑和高效。值得注意的是,尽管RepBlock和CSP在基于2D图像的任务中被证明是有效的,但它们尚未被充分用于3D点云任务。
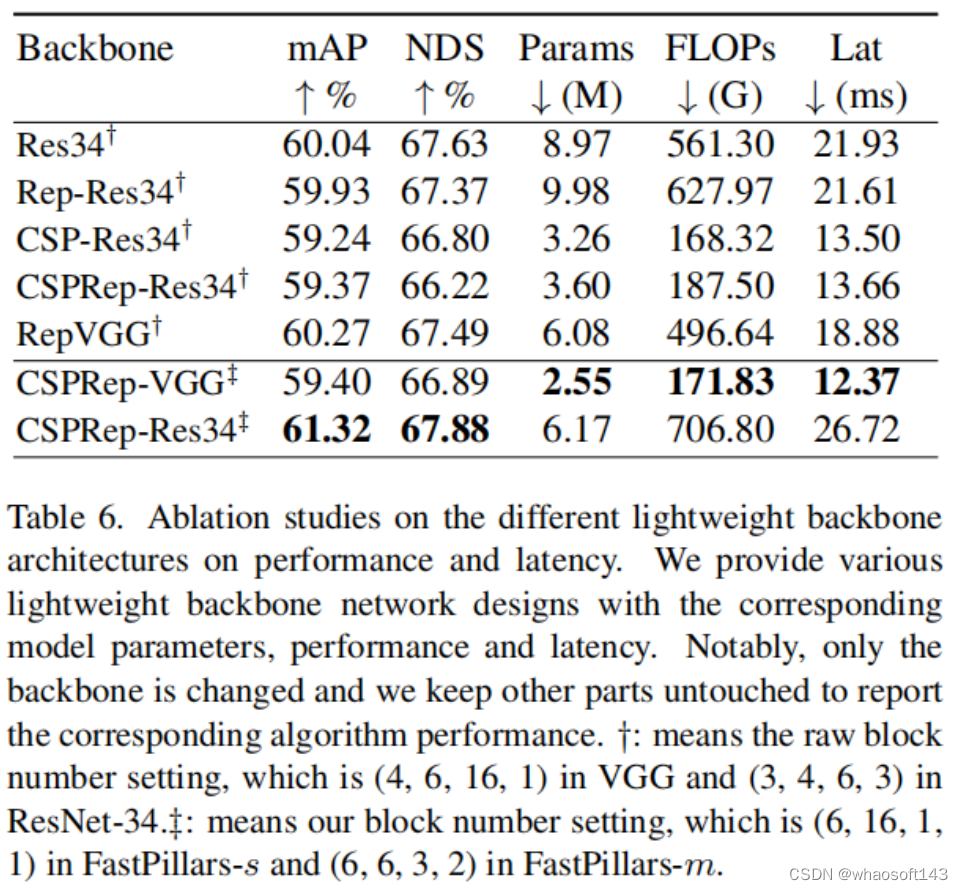
FastPillars-s和FastPillar-m模型分别建立在VGG和ResNet-34网络上。作者发现,最终性能对后期的容量不敏感,但对早期的容量非常敏感,这与FCOS LiDAR中的情况一致。因此,将FastPillers-s中VGG的块数从(4,6,16,1)更改为(6,16,1,1),FastPiller-m中ResNet-34的块数从(3,4,6,3)更改为(6,6,3,2),同时都删除了第一级中的前2×下采样。
Neck and Center-based Heads
在Neck模块中,采用了PillarNet中的丰富Neck设计。Neck模块将特征与来自主干的8×和16×特征图融合,以实现不同空间语义特征的有效交互。作者发现,在这种Neck设计中,级联操作之前的卷积层的数量显著影响最终性能。将在实验中详细讨论这一点。对于回归头,直接遵循3D Center-Track使用其简单但有效的头设计。
此外,还添加了一个IoU分支来预测预测框和GT之间的3D IoU。然后,Afdetv中的IoU-Aware校正函数用于弥补分类和回归预测之间的差距。具体而言,非最大抑制(NMS)后处理的校正置信分数C通过以下公式计算:
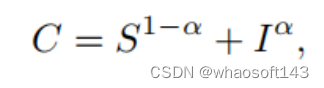
其中,S为预测的分类分数,I为预测的IoU值,α∈0,1为平衡S和I贡献的超参数。
Loss Functions
遵循3D Center-Track来设计损失函数。具体来说,对于分类分支使用Focal Loss作为Heatmap损失。

实 验
消融实验
① Max-and-Attention Pillar Encoding Module
② CSP Ratios Selection
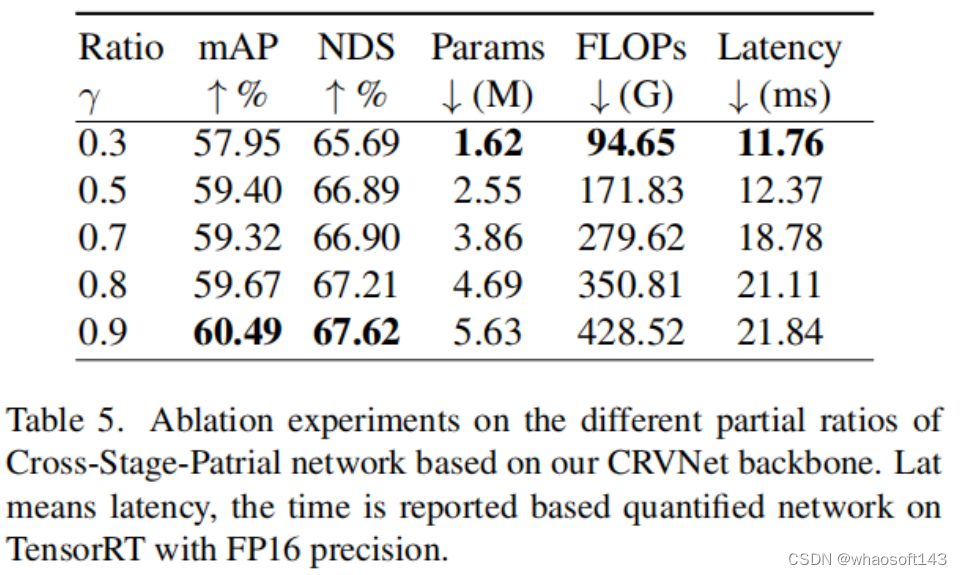
③ Lightweight Backbone Architecture
④ MAPE中不同池化操作的消融实验
SOTA对比
速度对比
可视化
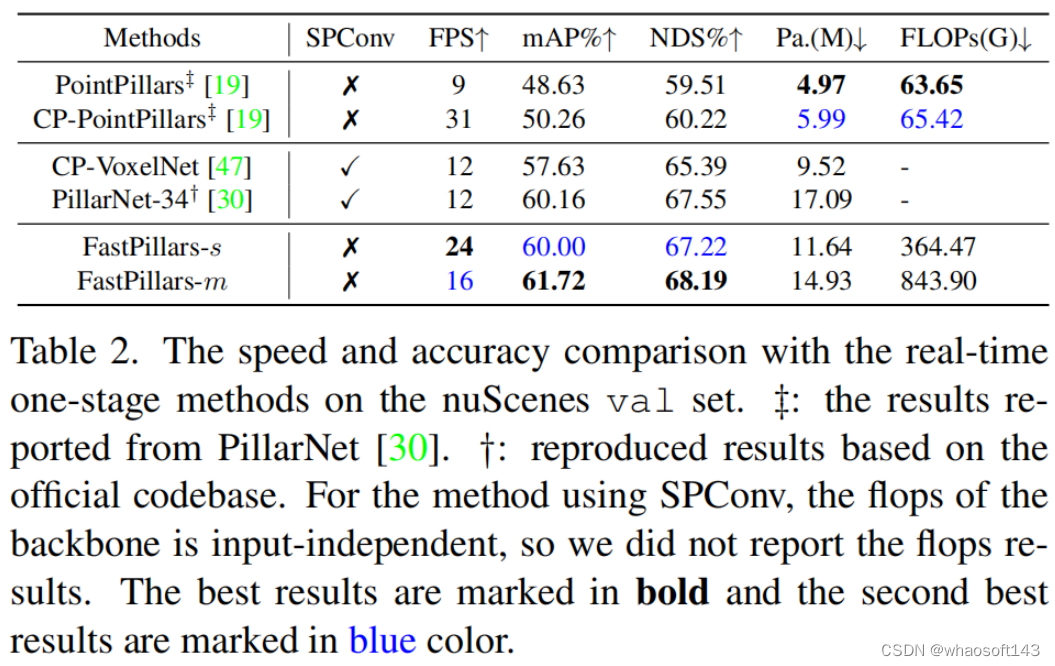
部分可视化结果如图4所示。在这里,基于FastPillars-s模型在场景上的一些具有挑战性的场景中可视化检测结果。正如所看到的,FastPillars可以在各种具有挑战性的环境下可靠地工作。可以清楚地看到,提出的FastPillars能够检测小目标,如行人、障碍和自行车。
#BEV-MAE
本文针对点云预训练问题,提出了BEV-MAE,一种基于掩码模型的LiDAR感知模型预训练策略,在预训练效率和性能上表现出色,可缓解LiDAR感知模型对标记数据的需求。
本文介绍了来自北京大学王选计算机研究所的王勇涛团队与其合作者的研究成果BEV-MAE。针对自动驾驶场景,该篇工作提出了一个高效的LiDAR感知模型预训练策略,可缓解LiDAR感知模型对标记数据的需求,论文已发表在AAAI 2024。
论文标题:BEV-MAE: Bird's Eye View Masked Autoencoders for Point Cloud Pre-training in Autonomous Driving Scenarios
论文:https://arxiv.org/abs/2212.05758
主页:https://github.com/VDIGPKU/BEV-MAE
论文概述
本文提出了BEV-MAE,一种高效的3D点云感知模型预训练算法,可直接使用大量的无标记点云数据对感知模型进行预训练从而降低对点云标记的需求。BEV-MAE首先使用鸟瞰图引导的掩码策略来对3D点云输入进行掩码,该部分被掩盖的点云将被替换为共享的可学习令牌。之后被处理过的点云依次输入到3D编码器和轻量级的解码器中,由轻量级的解码器重建被掩盖的点云并预测被掩盖区域的点云密度。BEV-MAE在自动驾驶感知数据集Waymo上以最低的预训练代价取得了最高的3D目标检测精度提升。同时,基于Transfusion-L检测器,BEV-MAE在自动驾驶感知数据集nuScenes上取得了领先的3D点云目标检测结果。
研究背景
3D目标检测是自动驾驶中最基本的任务之一。近年来,由于标注数据集和数据量的增加,基于激光雷达(LiDAR)的3D目标检测算法取得了显著的成功。然而,现有的基于激光雷达的3D目标检测算法通常采用从头开始训练的范式(training from scratch)。这种范式存在两个显著的缺陷。首先,从头开始训练的范式在很大程度上依赖于大量的标注数据,而对于3D目标检测而言,标注准确的物体包围框和分类标签是需要大量人工参与的,且非常昂贵和耗时的。例如,在KITTI数据集上标注一个物体需要大约114秒。其次,在许多实际应用场景中,自动驾驶车辆在行驶过程中可以生成大量无标注的点云数据,而从头开始训练的范式不能很好地将这部分数据利用起来。
方法部分
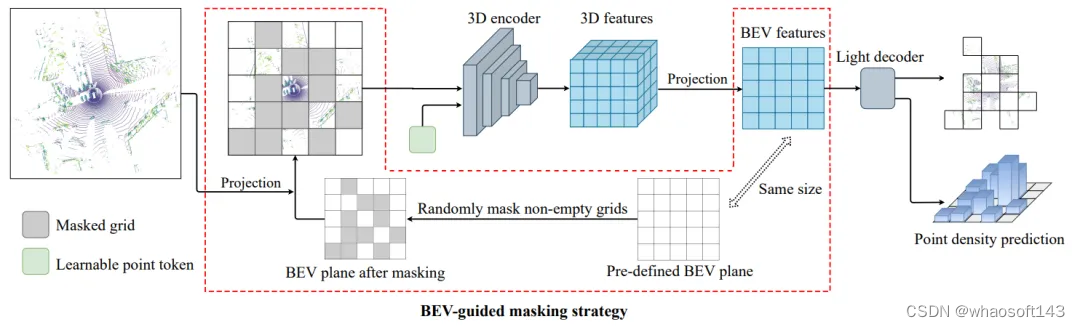
针对该问题,作者研究了一种针对自动驾驶场景的 3D 点云自监督预训练方法,提出了一种名为 BEV-MAE 的鸟瞰图掩码自编码器框架,专门用于预训练自动驾驶场景的 3D 目标检测器。具体流程图如下图所示:

b、共享可学习token
常用的基于体素的3D目标检测器的3D编码器通常由多个稀疏卷积操作组成,而稀疏卷积仅会处理非空体素附近的特征,因此,将掩码后的点云作为输入时,3D编码器的感受野将会变小。为了解决这个问题,作者采用一个共享的可学习令牌替换被掩盖的点云。具体来说,作者使用完整点云的坐标作为稀疏卷积的输入索引,并在第一个稀疏卷积层中用共享的可学习令牌替换被掩码点云的特征,同时保持其他稀疏卷积层不变。所提出的共享可学习令牌的唯一目的是将信息从一个点或体素传递到另一个点或体素,以维持感受野大小不变,而不引入任何额外的信息,包括被掩码点的坐标,来降低重建任务的难度。
c、掩码预测任务
所提出的BEV-MAE由两个任务作为监督,即点云重建和密度预测。对于每个任务,都采用独立的线性层作为预测头来预测结果。
对于点云重建,与之前的工作类似,BEV-MAE通过预测被掩码点云的坐标来重建掩码输入。采用chamfer-distance作为训练损失函数。
对于密度预测,不同于图像、语言和室内点云,自动驾驶场景中室外点云的密度具有随离激光雷达传感器越远而越稀疏的特性。因此,密度可以反映每个点或物体的位置信息。而对于目标检测而言,检测器的定位能力至关重要。因此,点云密度预测任务能够一定程度上指导3D编码器获得更好的定位能力。
具体而言,对于每个被掩码的网格,计算此网格中的点云数量,并通过将点云数量除以其在3D空间中的占用体积来得到对应的密度真值。然后,BEV-MAE使用线性层作为预测头来预测密度。密度预测使用Smooth-L1损失来监督此任务。
实验部分
BEV-MAE主要在两个主流的自动驾驶数据集nuScenes和Waymo上进行实验。
在Waymo上,BEV-MAE以较低的预训练代价,取得了更高的3D目标检测性能提升,如下图所示:
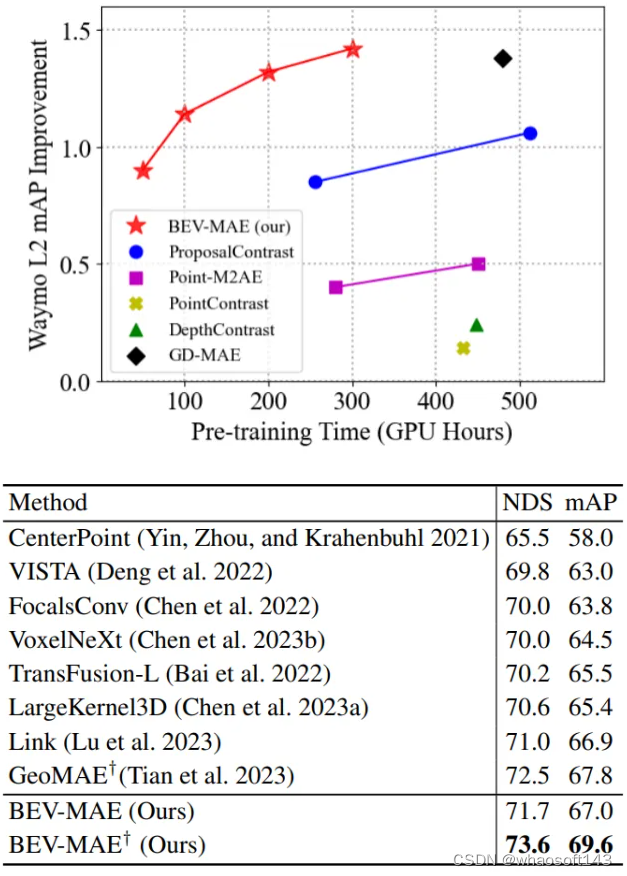
在nuScenes上,以BEV-MAE作为预训练算法,能够进一步提升当前最强点云3D目标检测器的性能。以TransFusion-L作为基础3D检测器,外加BEV-MAE的预训练算法,在nuScenes数据集上取得了先进的单模态点云3D目标检测结果。
结论
本文针对点云预训练问题,提出了BEV-MAE,一种基于掩码模型的LiDAR感知模型预训练策略,在预训练效率和性能上表现出色,可缓解LiDAR感知模型对标记数据的需求。
#3d2fool
本文提出3D Depth Fool (3D²FoO),第一个针对MDE模型的基于3D纹理的对抗攻击。3D²FoO经过优化可生成与汽车模型种类无关的3D对抗纹理,并提高了在恶劣天气条件(如雨、雾)下的鲁棒性。投稿人简介:郑君豪,西安交通大学网络空间安全学院博士一年级学生,导师是沈超老师,主要研究方向为自动驾驶感知安全和对抗攻击。本文介绍西安交通大学网络空间学院先智所提出的针对自动驾驶场景下单目深度估计模型的对抗攻击方法,论文被CVPR2024收录。
Physical 3D Adversarial Attacks against Monocular Depth Estimation in Autonomous Driving
论文:https://arxiv.org/abs/2403.17301
代码:https://github.com/gandolfczjh/3d2fool
摘要

简介
尽管深度神经网络(DNNs)被广泛应用,但是它们容易受到对抗攻击的影响,这也对基于DNNs的MDE模型构成了安全威胁。对抗攻击可以根据应用场景分为两种类型:数字域对抗攻击和物理域对抗攻击。数字域攻击主要是对图像像素添加小的扰动,由于其对物理变化(如打印、天气条件和视角变化)的敏感性,它们很难直接转化到物理世界中。物理域攻击通过在各种物理约束下优化扰动来解决这些限制,并且它们在误导现实世界的自动驾驶系统的感知模型上取得了一定成功(CAMOU1, DAS2, FCA3, DTA4, ACTIVE5)。在物理世界的攻击中,攻击者往往设计一个2D对抗补丁或3D伪装纹理并将其粘贴到目标车辆上,由摄像头捕获,然后将其输入到受害者模型中。2D对抗补丁仅能粘贴在物体表面的局部平面部分,无法在不同的视角和距离上实现对抗效果。相比之下,3D伪装纹理是为了覆盖车辆的整个表面,从而在任何视角下都能获得更好的攻击性能。

图二 (a)现有的2D对抗补丁攻击(APARATE7, SPOO9)和(b)其3D对抗纹理的修改版本未能完全从MDE预测深度图中隐藏车辆,而(c)我们的鲁棒3D对抗性纹理使汽车消失

方法
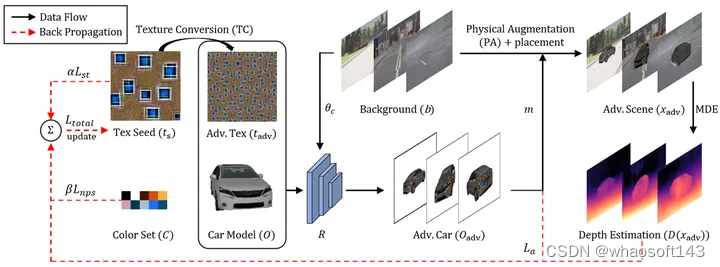
图三 方法框图

实验
实验在Carla 渲染器中完成,用于测评的MDE模型包括:Monodepth210,Depthhints11, Manydepth12,Robustdepth13
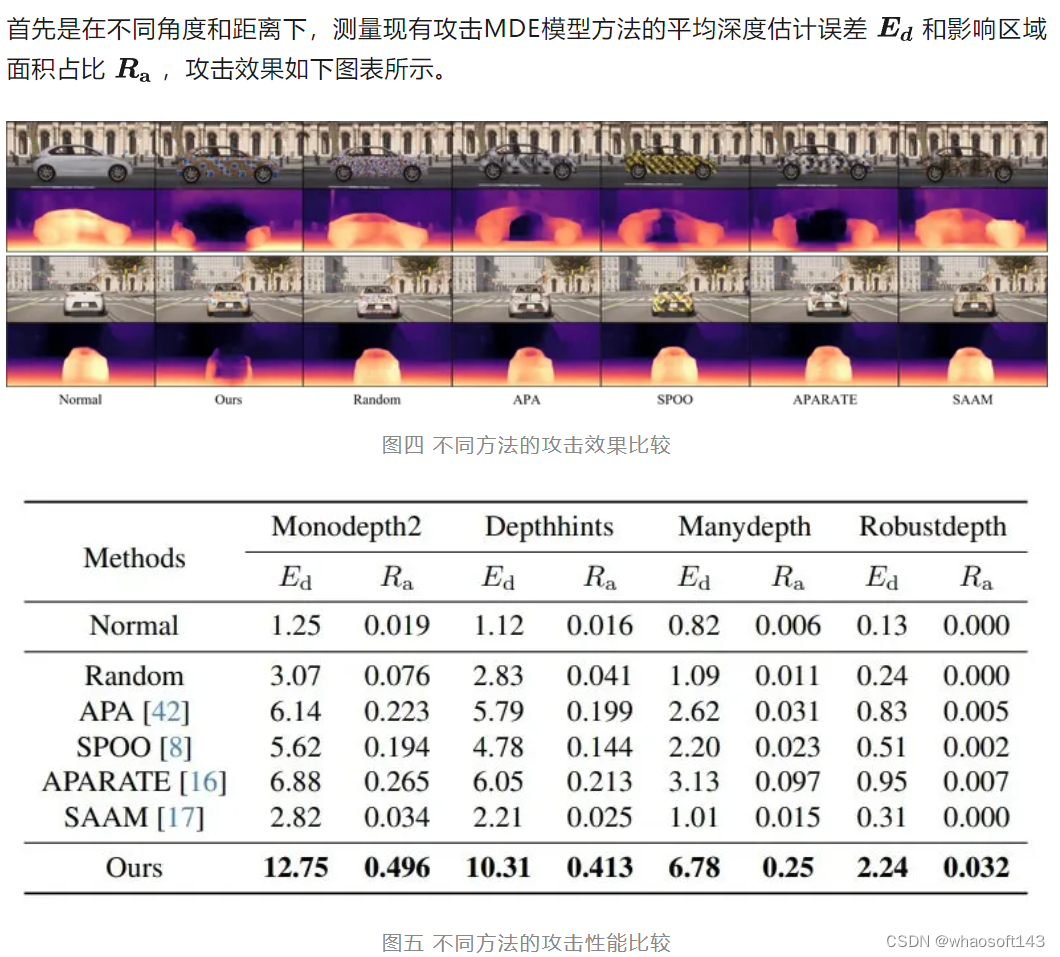
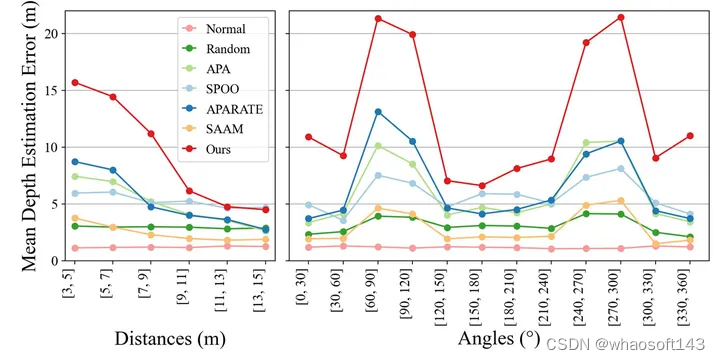
图六 不同方法的攻击性能在不同距离和角度下的比较
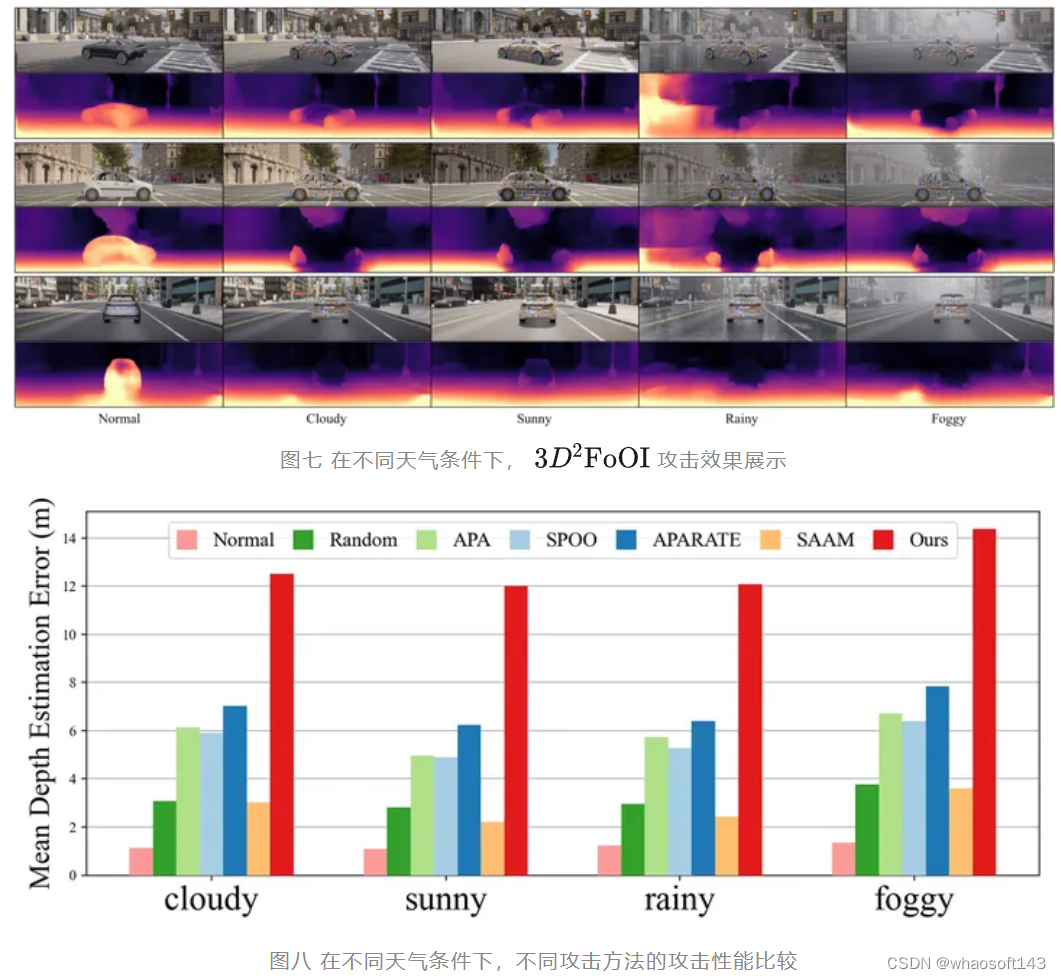
在不同的天气条件下,分别测试各攻击方法对Monodepth210模型的攻击效果,结果如下图表所示。
在不同的目标物体上,如行人、公交、卡车上,分别测试各攻击方法对Monodepth210模型的攻击效果,结果如下图表所示。
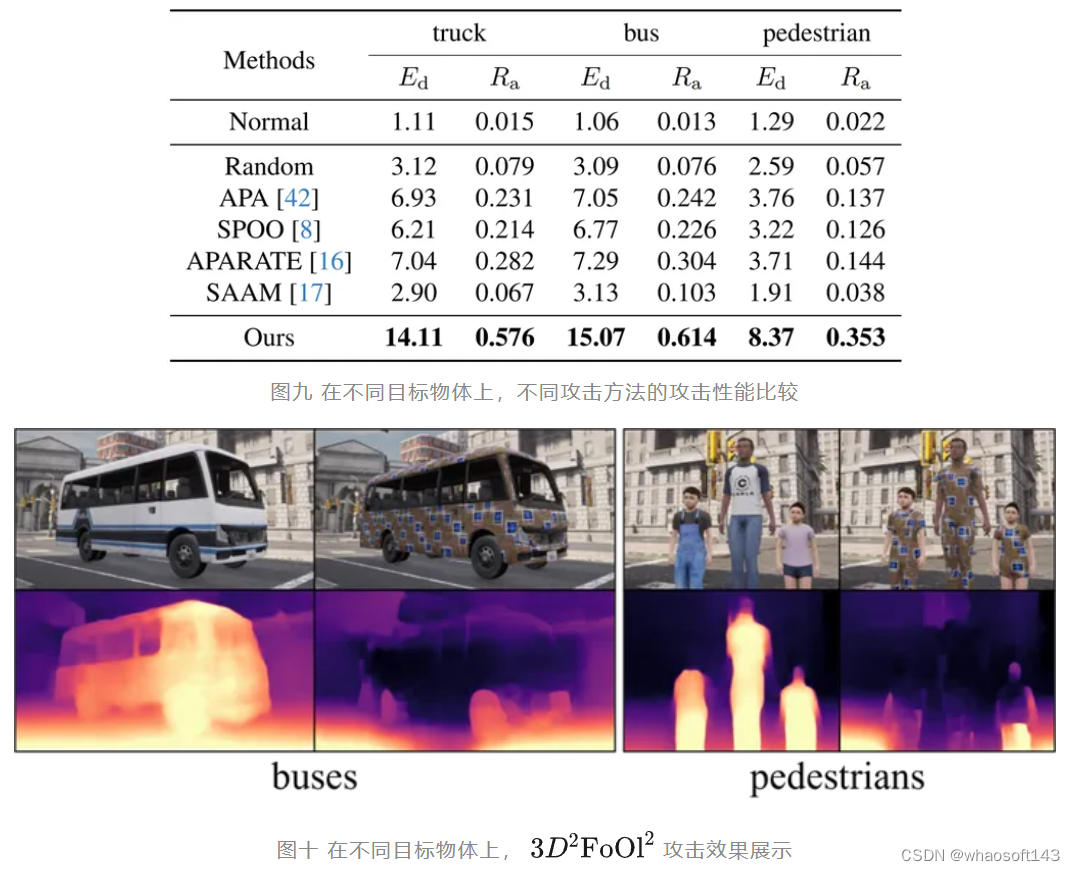
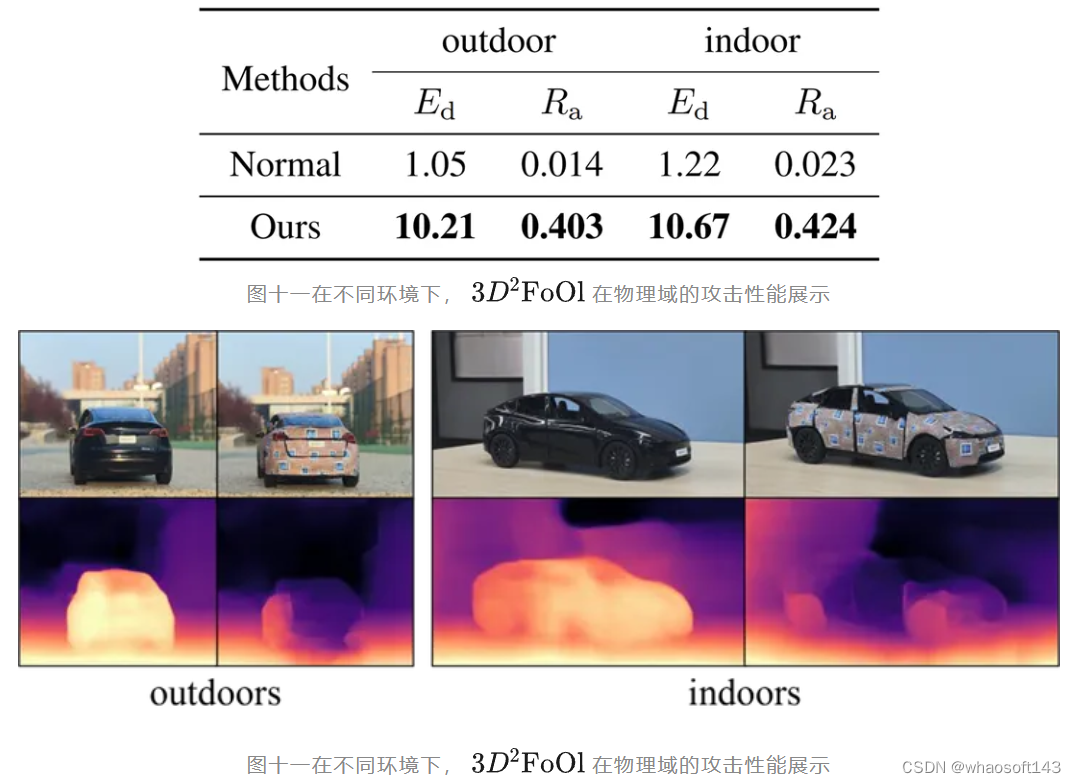
在物理世界的实验测试中,我们将纹理粘贴在汽车模型表面,测试对Monodepth210模型的攻击效果,结果如下图表所示。
#RCBEVDet
本文提出了RCBEVDet,一个基于毫米波雷达和环视相机鸟瞰图(BEV)特征融合的3D目标检测模型架构,在显著提升3D目标检测精度的同时可保持实时的推理速度,且具有较强鲁棒性。本文介绍了来自北京大学王选计算机研究所的王勇涛团队与其合作者的最新研究成果RCBEVDet。针对自动驾驶场景,该篇工作提出了一个基于毫米波雷达和环视相机鸟瞰图(BEV)特征融合的3D目标检测模型架构RCBEVDet,在显著提升3D目标检测精度的同时可保持实时的推理速度,且对模态信号丢失、干扰等情况鲁棒,论文已被CVPR 2024录用。
论文标题:RCBEVDet: Radar-camera Fusion in Bird's Eye View for 3D Object Detection
项目主页/论文链接:https://github.com/VDIGPKU/RCBEVDet
论文概述:
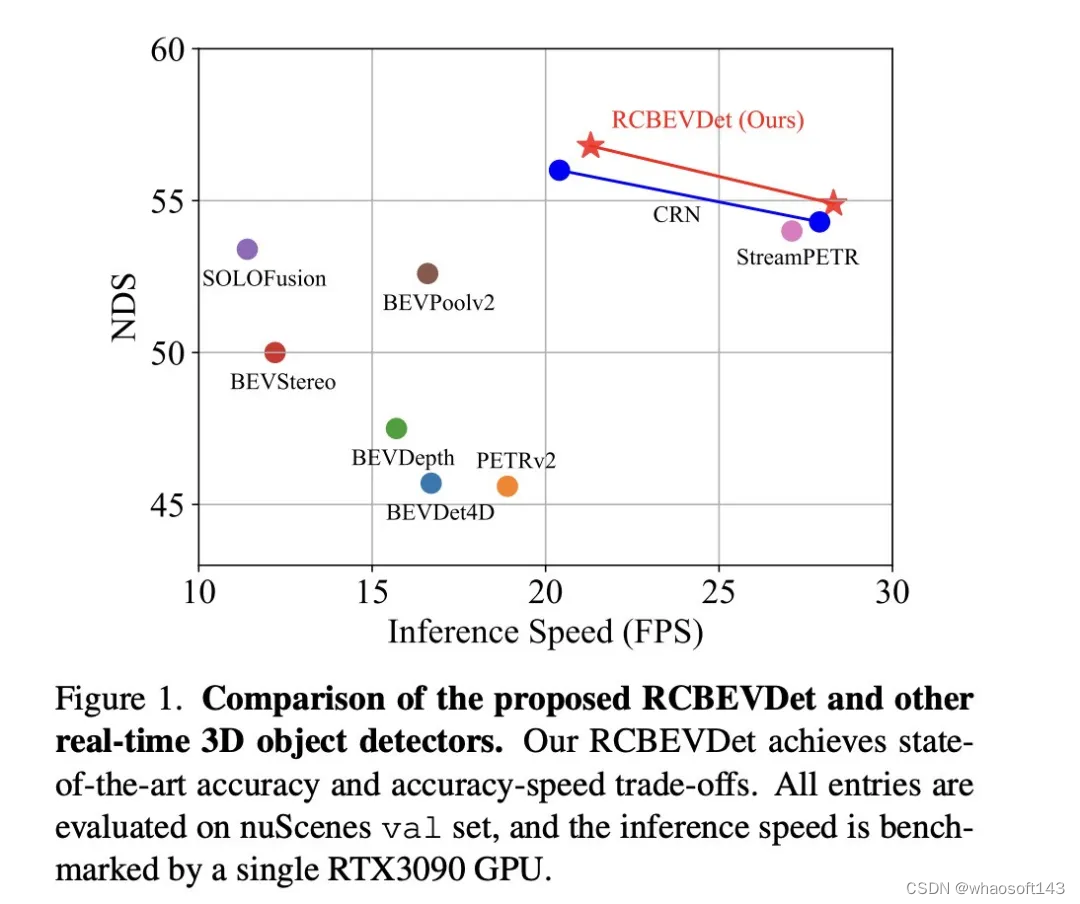
本文提出了一个基于毫米波雷达和环视相机鸟瞰图(BEV)特征融合的3D目标检测模型架构RCBEVDet。该架构针对毫米波雷达的特性设计了一种高效的毫米波雷达主干网络(RadarBEVNet)进行点云鸟瞰图特征提取,提出了一种基于可形变的跨注意力机制进行毫米波雷达特征和环视相机特征融合。该架构对现有主流的环视相机3D检测器具有较强的兼容性,在显著提升3D目标检测精度的同时可保持实时的推理速度,且对模态信号丢失、干扰等情况鲁棒。同时,该架构在自动驾驶感知数据集nuScenes上取得了领先的毫米波雷达-多摄相机3D目标检测精度以及推理速度-精度综合性能。
研究背景:
近期,研究者们关注于使用经济且高效的多视角相机进行自动驾驶场景的3D目标检测。多视角相机能够捕捉物体的颜色和纹理信息,同时提供高分辨率的语义信息。然而,仅依赖单独的多视角相机难以实现高精度且鲁棒的3D目标检测。例如,多视角相机难以提供准确的深度信息,且图像质量受天气和光照的影响较大。为了提升智能驾驶系统的安全性和鲁棒性,智能驾驶车辆通常采用多种模态的传感器获取场景信息进行感知,如环视相机、激光雷达、毫米波雷达等。毫米波雷达是一种经济实惠的常用传感器,能够提供较为准确的深度信息和速度信息,并且能够在各种天气和光照条件下给出高质量毫米波点云。因此,使用毫米波雷达-环视相机多模态组合感知方案具有优秀的感知能力和较高的性价比,受到了现在很多研究人员和车厂的青睐。但是,由于4D毫米波雷达和环视相机模态间的巨大差异,如何融合这两种模态信息高精度且鲁棒地完成智能驾驶感知任务(如3D目标检测)具有非常大的技术挑战性。
论文关注的主要问题是3D目标检测技术在自动驾驶进程中的应用。尽管环视相机技术的发展为3D目标检测提供了高分辨率的语义信息,这种方法因无法精确捕获深度信息和在恶劣天气或低光照条件下的表现不佳等问题而受限。针对这一问题,论文提出了一种结合环视相机和经济型毫米波雷达传感器的多模态3D目标检测新方法------RCBEVDet。
RCBEVDet的核心在于两个关键设计:RadarBEVNet和Cross-Attention Multi-layer Fusion Module(CAMF)。RadarBEVNet旨在有效提取雷达特征,它包括双流雷达主干网络和RCS(雷达截面积)感知的BEV(鸟瞰图)编码器。这样的设计利用点基和变换器基编码器处理雷达点,通过交互更新雷达点特征,同时将雷达特定的RCS特性作为目标大小的先验信息来优化BEV空间的点特征分布。而CAMF模块通过多模态交叉注意力机制解决了雷达点的方位误差问题,实现了雷达和相机的BEV特征图的动态对齐以及通过通道和空间融合层的多模态特征自适应融合。
论文提出的新方法通过以下几点实现对现有问题的解决:
- 高效的雷达特征提取器:通过双流雷达主干和RCS感知的BEV编码器设计,专门针对雷达数据的特性进行优化,解决了使用为激光雷达设计的编码器处理雷达数据的不足。
- 强大的雷达-相机特征融合模块:采用变形的交叉注意力机制,有效处理环视图像和雷达输入之间的空间不对齐问题,提高融合效果。
论文的主要贡献如下:
- 提出了一种新颖的雷达-相机多模态3D目标检测器RCBEVDet,实现了高精度、高效率和强鲁棒性的3D目标检测。
- 设计了针对雷达数据的高效特征提取器RadarBEVNet,通过双流雷达主干和RCS感知BEV编码器,提高了特征提取的效率和准确性。
- 引入了Cross-Attention Multi-layer Fusion模块,通过变形交叉注意力机制实现了雷达和相机特征的精确对齐和高效融合。
- 在nuScenes和VoD数据集上达到了雷达-相机多模态3D目标检测的新的最佳性能,同时在精度和速度之间实现了最佳平衡,并展示了在传感器失效情况下的良好鲁棒性。
方法部分:
作者提出了RCBEVDet,一种基于毫米波雷达和多视角相机鸟瞰图融合的3D感知方法,以实现高精度、高鲁棒性的自动驾驶多模态3D感知。具体架构如下图所示:
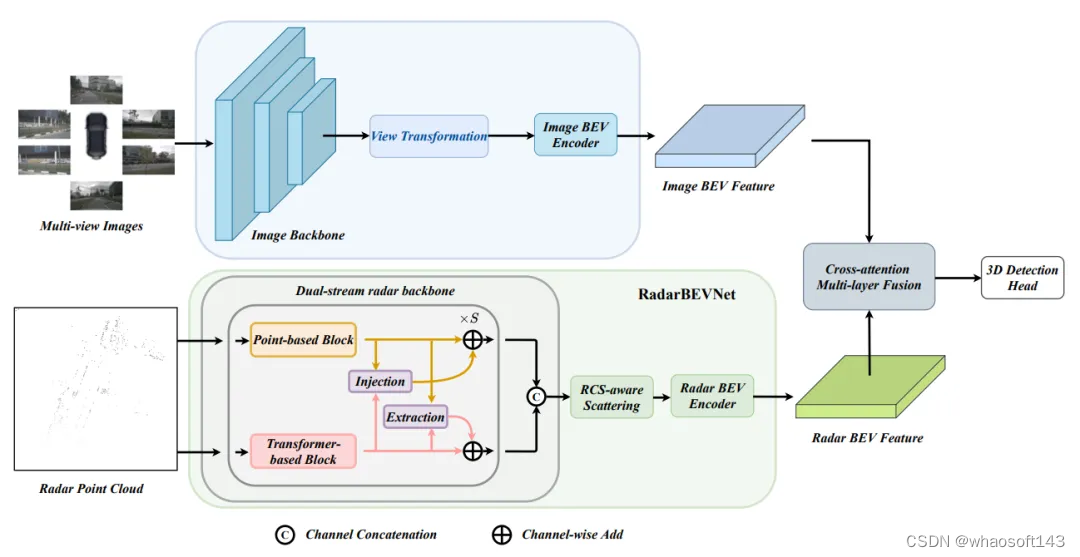
图1 RCBEVDet架构图
RCBEVDet针对毫米波雷达的特性,设计了一种高效的毫米波雷达主干网络(RadarBEVNet),进行点云鸟瞰图特征提取,RadarBEVNet使用两种特征表征方式对毫米波雷达点云进行特征表示,并使用基于雷达反射截面(RCS)的离散方法得到鸟瞰图特征。此外,该方法还提出了一种基于可形变的跨注意力机制进行毫米波雷达特征和多视角相机鸟瞰图特征进行鲁棒和高效的融合,从而提高自动驾驶的3D感知任务的性能和多模态鲁棒性。
1、RadarBEVNet
给定输入的毫米波雷达点云,RadarBEVNet采用point-based和transformer-based两种表征形式对点云进行特征提取,point-based提取器将针对毫米波雷达点云提取局部点云特征,而transformer-based的模块则针对毫米波雷达点云提取全局点云特征。同时两种特征表示通过injection和extraction模块进行特征关联,将局部特征和全局特征进行交互,得到更加全面的毫米波雷达点云特征。
a、两种特征表征方式
两种特征表征的提取器如下图所示:
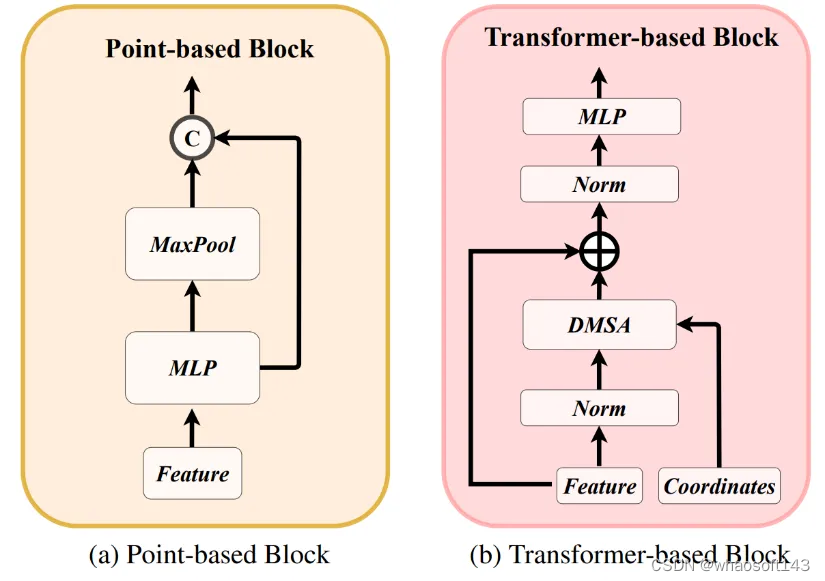
图 2 两种特征表征的提取器

b、injection和extraction模块

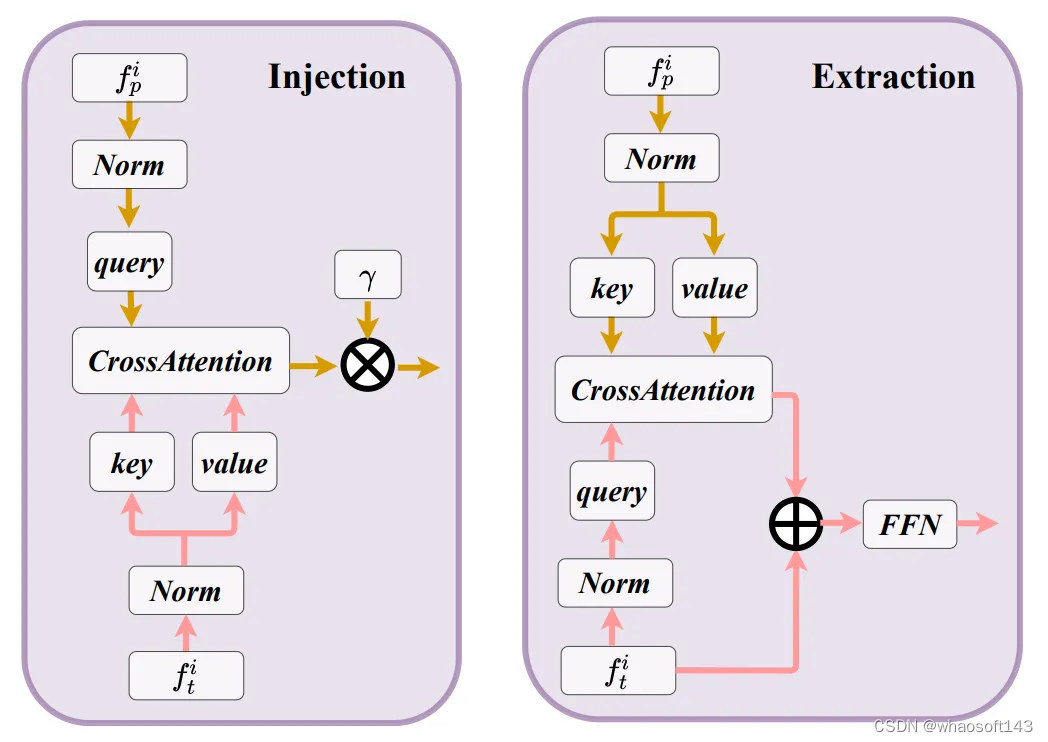
图3 injection和extraction模块架构图
2、基于雷达反射截面(RCS)的离散方法
RCS是毫米波雷达特有的特征,它是用来反映一个物体可检测性的指标。相同条件下(材料、形状),较大的物体会产生较强的毫米波雷达反射响度,从而使毫米波雷达传感器获得较强的雷达反射截面。因此,雷达反射截面能够在一定程度上反映出物体的大小。基于RCS引导的体素离散化操作将雷达反射截面作为物体大小的先验知识,从而能够使得一个毫米波雷达点云被离散化到多个体素栅格上,提高毫米波雷达特征的稠密程度,使后续的特征聚集变得更加简单。如下图所示:
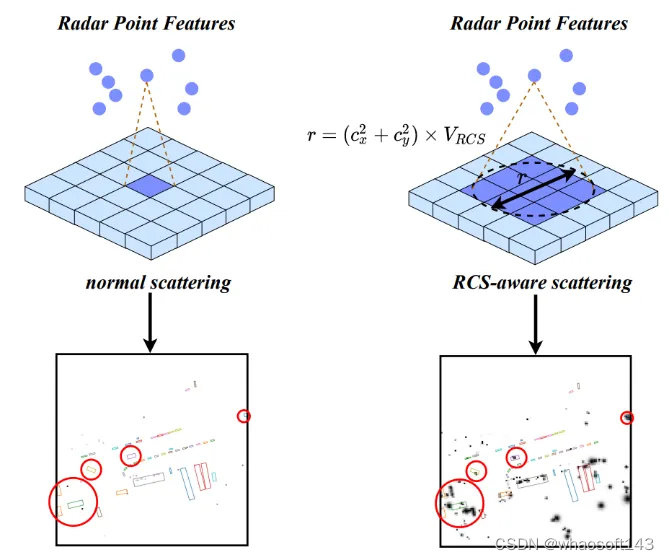
图4 基于RCS的离散方式示意图
3、可形变的跨注意力机制融合模块
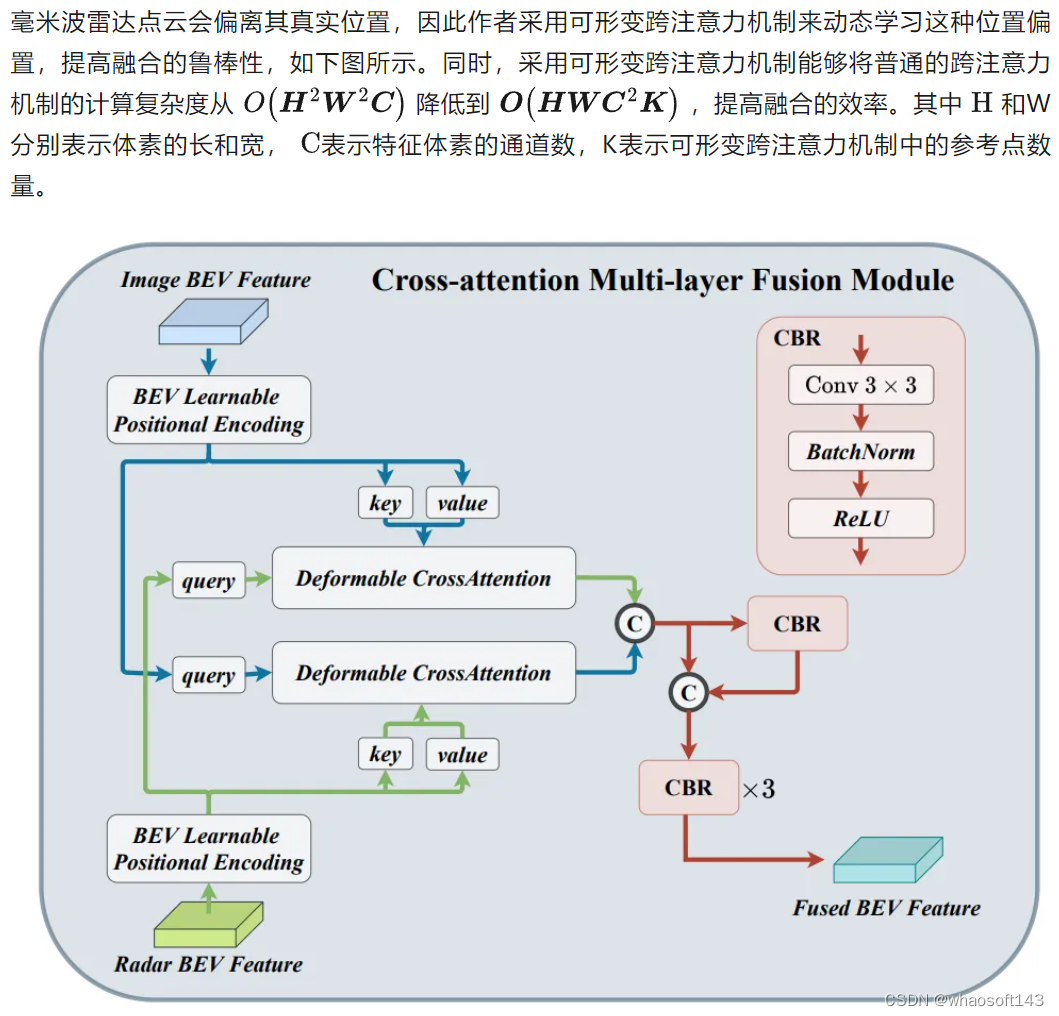
图5 可形变的跨注意力机制融合模块架构图
实验部分:
RCBEVDet主要在多模态自动驾驶数据集nuScenes上进行实验。以BEVDepth为基础模型,RCBEVDet在增加少量推理时延的情况下(仍保证实时推理速度),能够大幅度稳定提升3D检测的性能,同时实现最优的速度-精度权衡,如下所示:
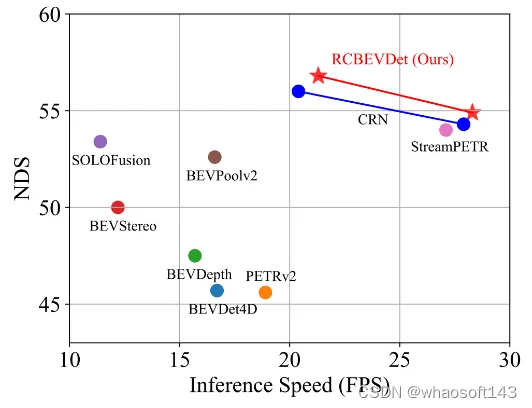
图6 速度-精度权衡图
在nuScenes验证集上,作者验证了RCBEVDet在不同backbone和image size的性能,如下表所示,RCBEVDet在各个设置下相比于之前的方法都有明显提升。
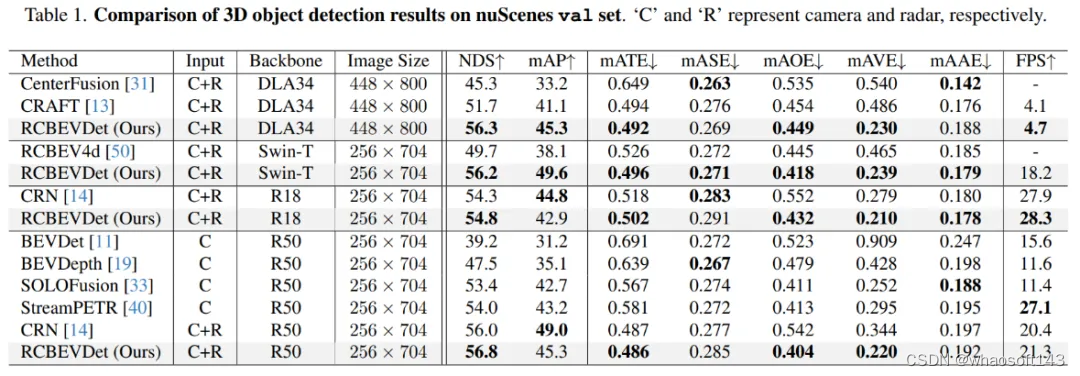
图7 nuScenes验证集结果
在nuScenes测试集上,增加Radar输入后,相比于相机基准模型BEVDepth,RCBEVDet提升了3.4 NDS,实现了63.9 NDS的性能。值得注意的是,RCBEVDet能够非常方便地与现有的其他高精度多视角相机检测器(例如streamPETR)相结合,实现更高精度的3D检测结果。
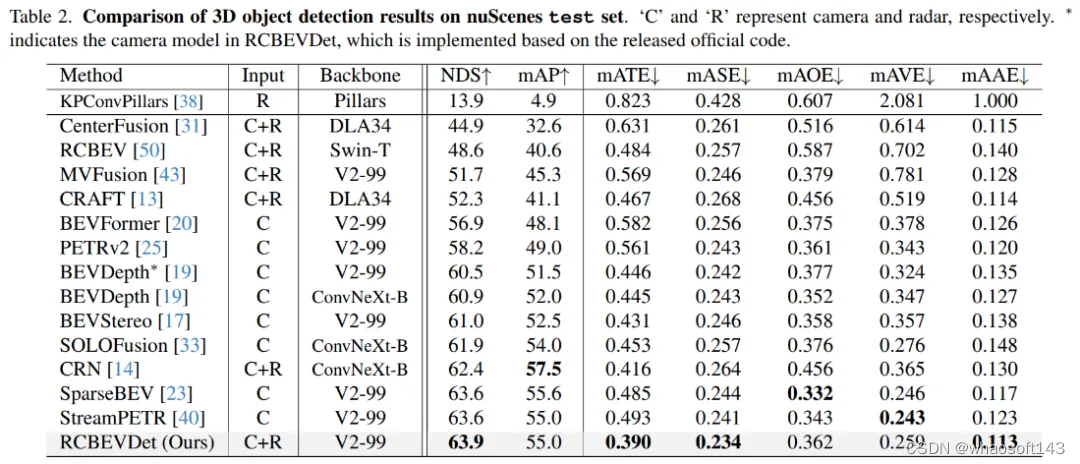
图8 nuScenes测试集结果
此外,作者模拟随机丢失传感器的情况,将部分传感器(相机或者毫米波雷达)的输入设为空,来验证RCBEVDet的鲁棒性,具体结果如下所示
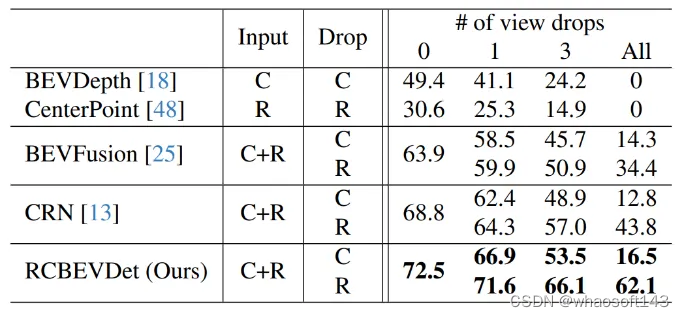
图9 鲁棒性验证
RCBEVDet对相机和毫米波雷达的缺失均表现出较强的鲁棒性。
结论:
本文提出了RCBEVDet,一个基于毫米波雷达和环视相机鸟瞰图(BEV)特征融合的3D目标检测模型架构,在显著提升3D目标检测精度的同时可保持实时的推理速度,且具有较强鲁棒性。
这个消融实验展示了RadarBEVNet在逐步添加主要组件时,对3D目标检测性能的持续改进。从基准模型BEVDepth开始,每一步增加的组件都显著提高了NDS(核心度量标准,反映了检测精度和完整性)和mAP(平均精确度,反映了模型对目标的检测能力)。
- 添加时间信息:通过引入时间信息,NDS和mAP分别提升了4.4和5.4个百分点。这表明时间信息对于提高3D目标检测的准确性和鲁棒性非常有效,可能是因为时间维度提供了额外的动态信息,有助于模型更好地理解场景和目标的动态特性。
- 加入PointPillar+BEVFusion(基于雷达和相机的融合):这一步进一步提升了NDS和mAP,分别增加了1.7和1.8个百分点。这说明通过融合雷达和相机数据,模型能够获取更全面的场景理解,弥补了单一模态数据的局限。
- 引入RadarBEVNet:NDS和mAP分别再次提升2.1和3.0个百分点。RadarBEVNet作为一个高效的雷达特征提取器,优化了雷达数据的处理,提高了特征的质量和有效性,这对于整体检测性能的提升至关重要。
- 添加CAMF(交叉注意力多层融合模块):通过精细的特征对齐和融合,NDS增加了0.7个百分点,mAP稍微提升到45.6,显示出在特征融合方面的有效性。这一步骤的改进虽然不如前几步显著,但依然证明了在多模态融合过程中,精确的特征对齐对于提高检测性能的重要性。
- 加入时间监督:最后,引入时间监督后,NDS微增0.4个百分点至56.8,而mAP略有下降0.3个百分点至45.3。这表明时间监督能进一步提升模型在时间维度的性能,尽管对mAP的贡献可能受到特定实验设置或数据分布的影响而略显限制。
总的来说,这一系列的消融实验清晰地展示了RadarBEVNet中每个主要组件对于提高3D目标检测性能的贡献,从时间信息的引入到复杂的多模态融合策略,每一步都为模型带来了性能上的提升。特别是,对雷达和相机数据的精细处理和融合策略,证明了在复杂的自动驾驶环境中,多模态数据处理的重要性。
讨论
论文提出的RadarBEVNet方法通过融合相机和雷达的多模态数据,有效地提升了3D目标检测的准确性和鲁棒性,尤其在复杂的自动驾驶场景中表现出色。通过引入RadarBEVNet和Cross-Attention Multi-layer Fusion Module(CAMF),RadarBEVNet不仅优化了雷达数据的特征提取过程,还实现了雷达和相机数据之间精准的特征对齐和融合,从而克服了单一传感器数据使用中的局限性,如雷达的方位误差和相机在低光照或恶劣天气条件下的性能下降。
优点方面,RadarBEVNet的主要贡献在于其能够有效处理并利用多模态数据之间的互补信息,提高了检测的准确度和系统的鲁棒性。RadarBEVNet的引入使得雷达数据的处理更为高效,而CAMF模块确保了不同传感器数据之间的有效融合,弥补了各自的不足。此外,RadarBEVNet在实验中展现了在多个数据集上的优异性能,尤其是在自动驾驶中至关重要的兴趣区域内,显示了其在实际应用场景中的潜力。
缺点方面,尽管RadarBEVNet在多模态3D目标检测领域取得了显著成果,但其实现的复杂性也相应增加,可能需要更多的计算资源和处理时间,这在一定程度上限制了其在实时应用场景中的部署。此外,虽然RadarBEVNet在骑行者检测和综合性能上表现优秀,但在特定类别上(如汽车和行人)的性能仍有提升空间,这可能需要进一步的算法优化或更高效的特征融合策略来解决。
总之,RadarBEVNet通过其创新的多模态融合策略,在3D目标检测领域展现了显著的性能优势。尽管存在一些局限性,如计算复杂度较高和在特定检测类别上的性能提升空间,但其在提高自动驾驶系统准确性和鲁棒性方面的潜力不容忽视。未来的工作可以聚焦于优化算法的计算效率和进一步提高其在各类目标检测上的表现,以推动RadarBEVNet在实际自动驾驶应用中的广泛部署。
结论
论文通过融合相机和雷达数据,引入了RadarBEVNet和Cross-Attention Multi-layer Fusion Module(CAMF),在3D目标检测领域展现出显著的性能提升,特别是在自动驾驶的关键场景中表现优异。它有效地利用了多模态数据之间的互补信息,提高了检测准确性和系统的鲁棒性。尽管存在计算复杂度高和在某些类别上性能提升空间的挑战,\ours在推动自动驾驶技术发展,尤其是在提升自动驾驶系统的感知能力方面,展现了巨大的潜力和价值。未来工作可以关注于优化算法效率和进一步提升检测性能,以便更好地适应实时自动驾驶应用的需求。