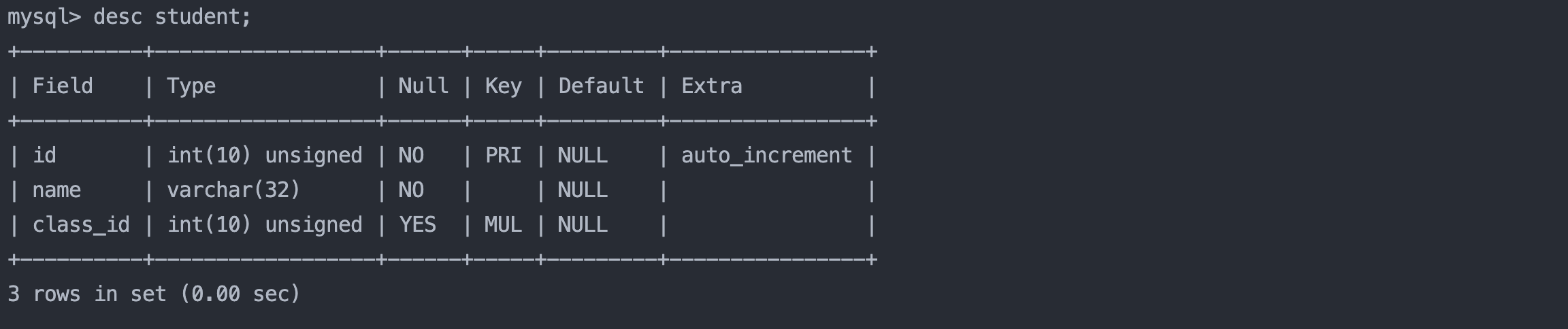
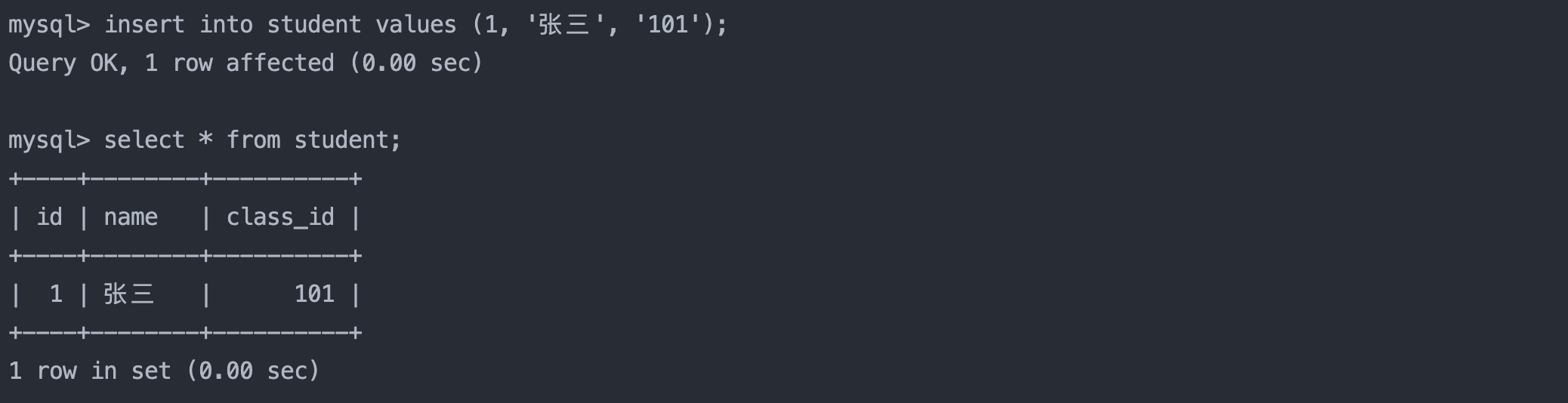
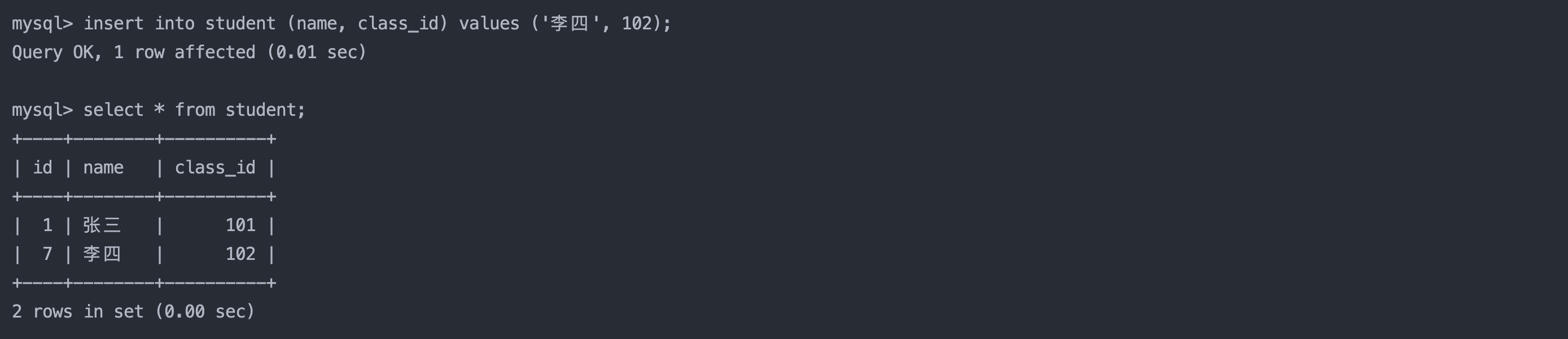
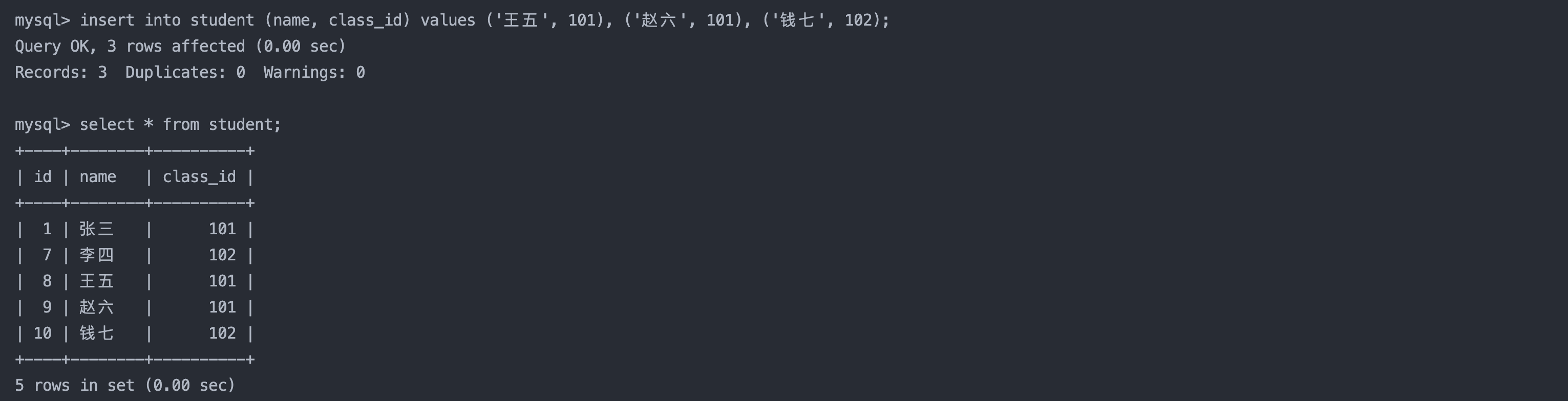
select name, english from result_exam where english < 60;
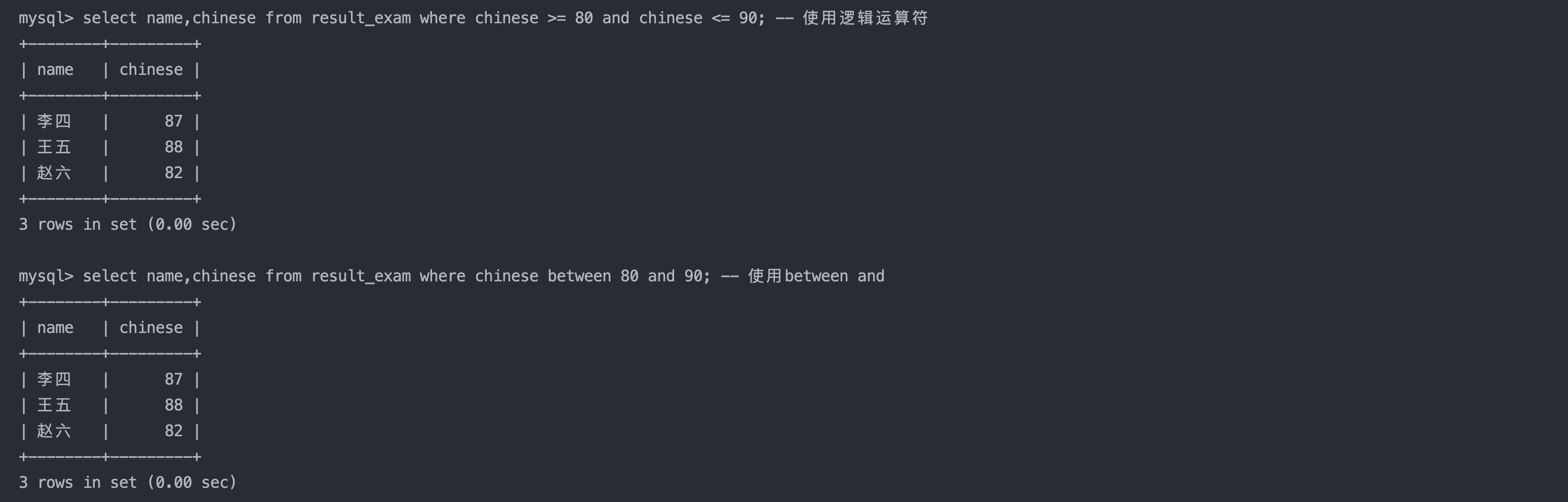
2. 语文成绩在 80, 90 分的同学及语文成绩
sql复制代码
select name,chinese from result_exam where chinese >= 80 and chinese <= 90; -- 使用逻辑运算符
select name,chinese from result_exam where chinese between 80 and 90; -- 使用between and
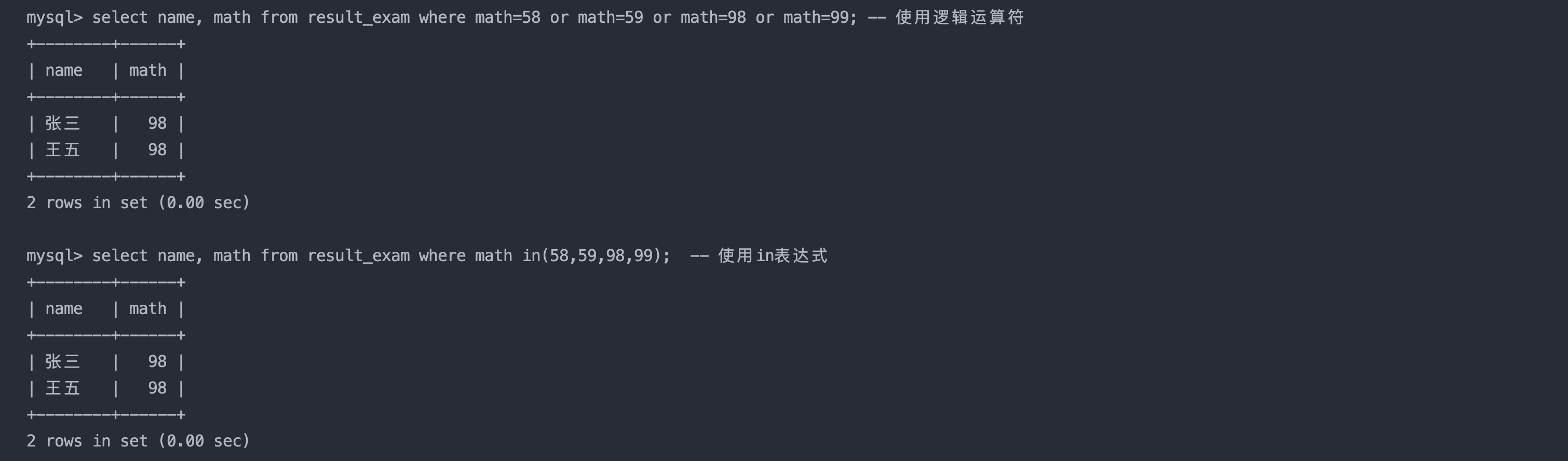
3. 数学成绩是 58 或者 59 或者 98 或者 99 分的同学及数学成绩
sql复制代码
select name, math from result_exam where math=58 or math=59 or math=98 or math=99; -- 使用逻辑运算符
select name, math from result_exam where math in(58,59,98,99); -- 使用in表达式
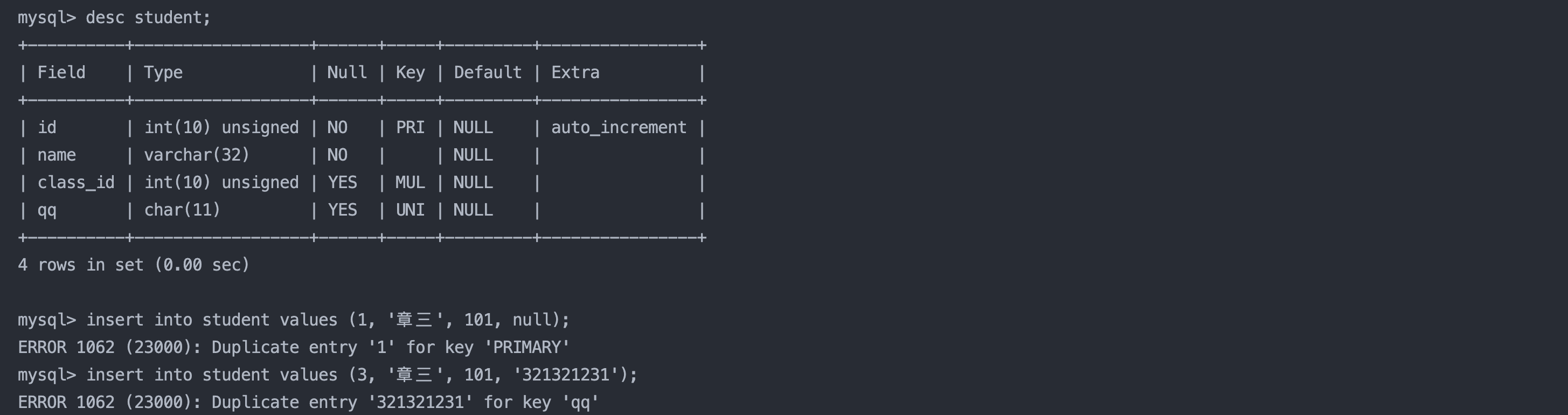
4. 姓张的同学 及 张某同学
sql复制代码
select * from result_exam where name like '张%'; -- % 匹配任意多个(包括 0 个)任意字符
select * from result_exam where name like '张_'; -- _ 匹配1个任意字符
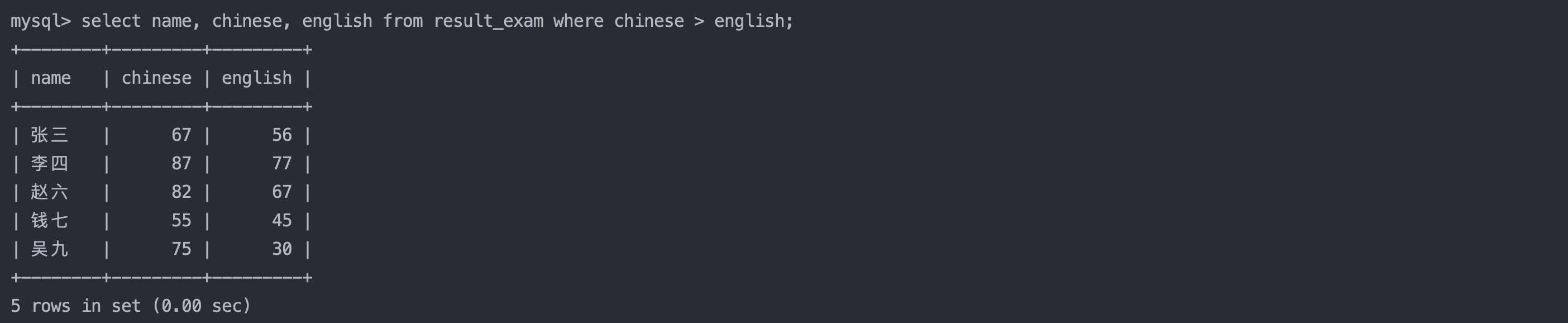
5. 语文成绩好于英语成绩的同学
sql复制代码
select name, chinese, english from result_exam where chinese > english;
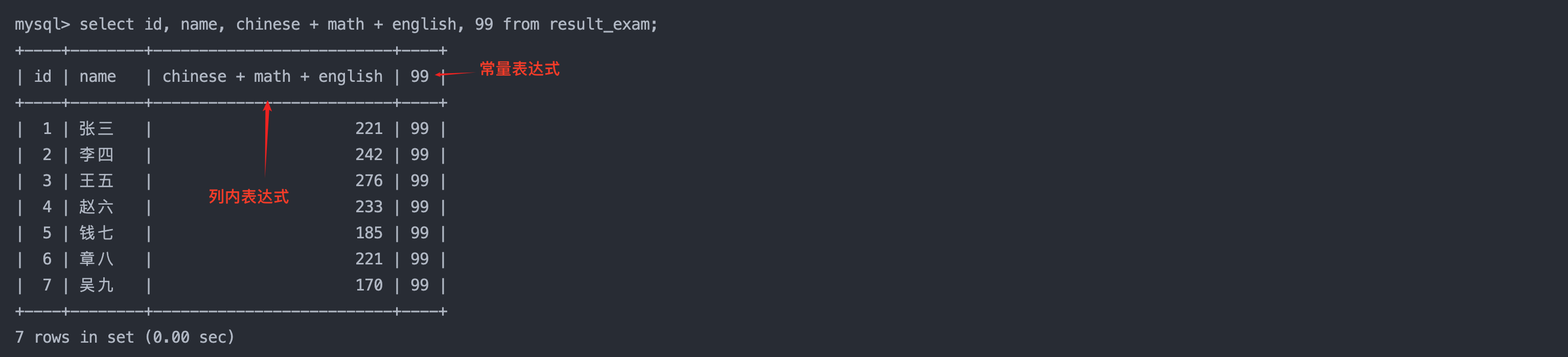
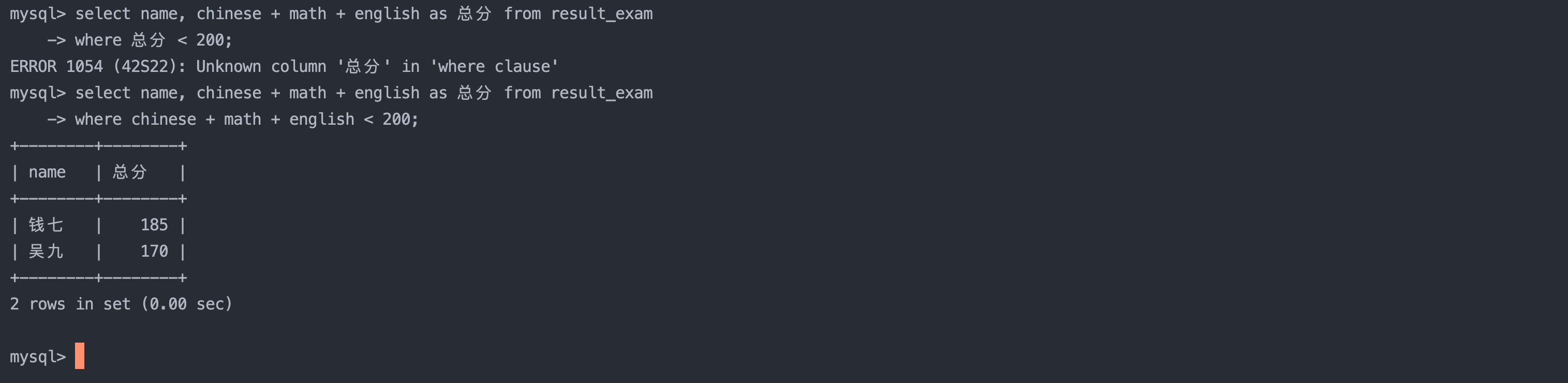
6. 总分在 200 分以下的同学
sql复制代码
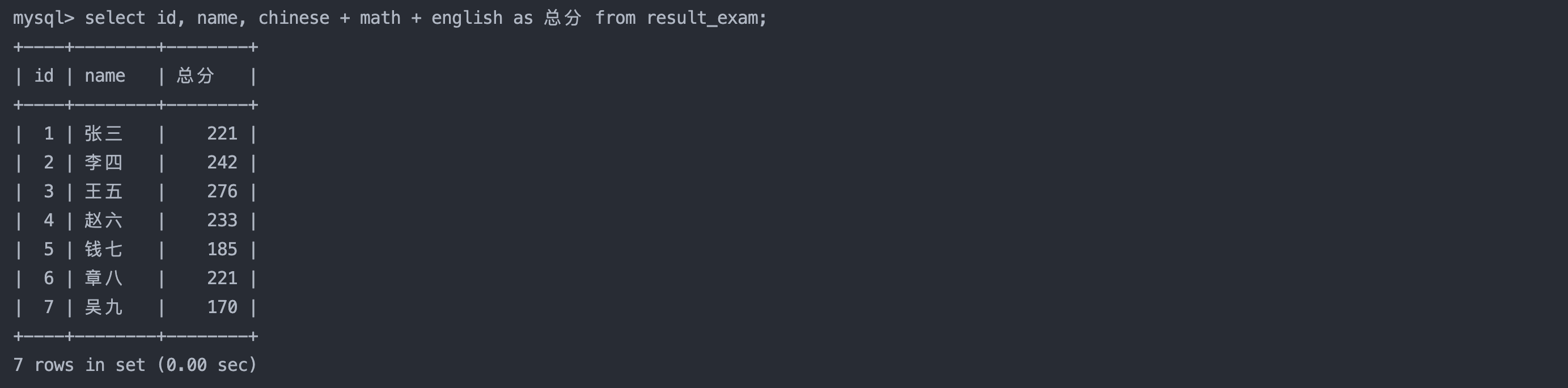
select name, chinese + math + english as 总分 from result_exam
where chinese + math + english < 200;
-- 注意,这里不能在where子句中使用select的重命名,因为查询语句中是先执行where子句,此时还没有重命名
7. 语文成绩 > 80 并且不姓张的同学
sql复制代码
select name, chinese from result_exam where chinese > 80 and name not like '张%';
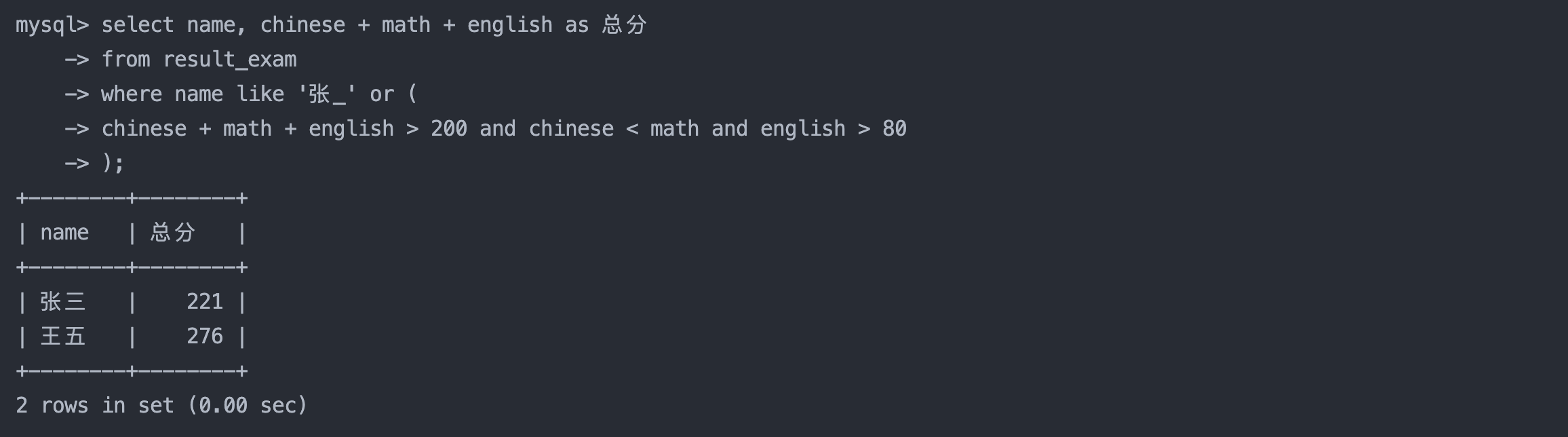
8. 张某同学,否则要求总成绩 > 200 并且 语文成绩 < 数学成绩 并且 英语成绩 > 80
sql复制代码
select name, chinese + math + english as 总分
from result_exam
where name like '张_' or (
chinese + math + english > 200 and chinese < math and english > 80
);
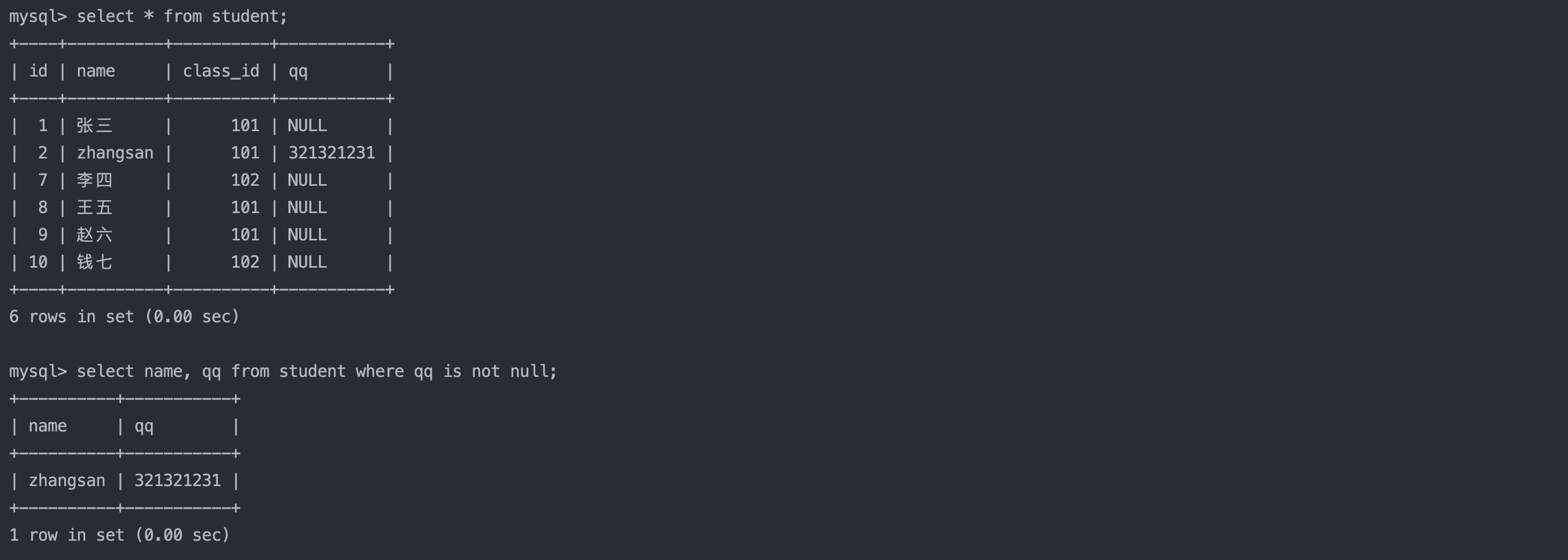
9. NULL查询
sql复制代码
select name, qq from student where qq is not null;
在最开始我们说到where的比较运算符中有NULL安全 和NULL不安全之分,这里我们演示一下
2.3 结果排序
sql复制代码
select ... from table_name [where ...]
order by column [asc|desc], [...];
-- asc 为升序(从小到大) -- desc 为降序(从大到小) -- 默认为 ASC
注意:没有 ORDER BY 子句的查询,返回的顺序是未定义的,永远不要依赖这个顺序
案例:
1. 同学及数学成绩,按数学成绩升序显示
sql复制代码
select name, math from result_exam order by math;
2. 同学及 qq 号,按 qq 号排序显示
sql复制代码
select name, qq from student order by qq;
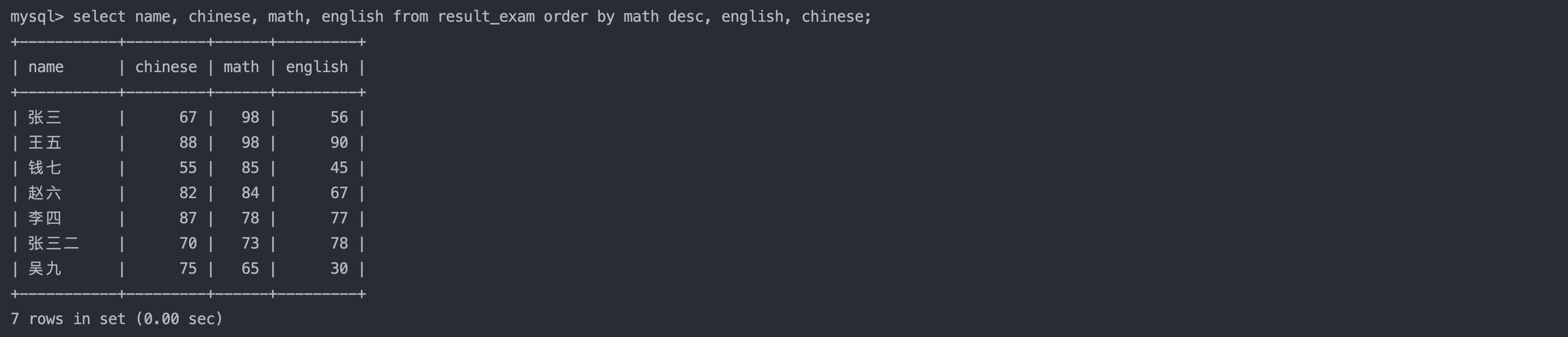
3. 查询同学各门成绩,依次按 数学降序,英语升序,语文升序的方式显示
sql复制代码
select name, chinese, math, english from result_exam order by math desc, english, chinese;
-- order by的排序顺序可以有多个排序规则,按照先后顺序排序,执行排序
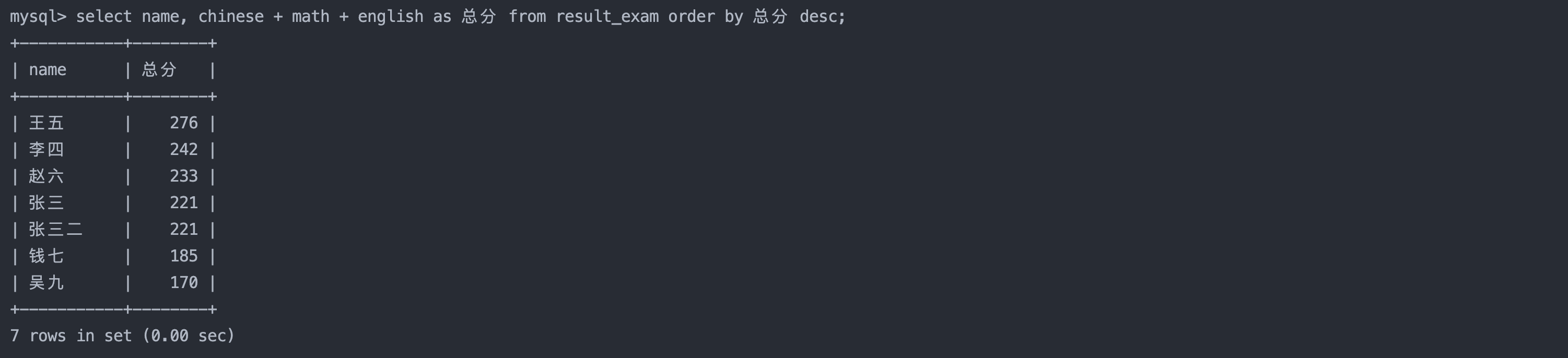
4. 查询同学及总分,由高到低
sql复制代码
select name, chinese + math + english as 总分 from result_exam order by 总分 desc;
-- 在order by的时候可以使用 select 语句的地方重命名的表达式,因为order by的执行本质上是将select查询到的内容进行排序,所以是先执行select再执行order by
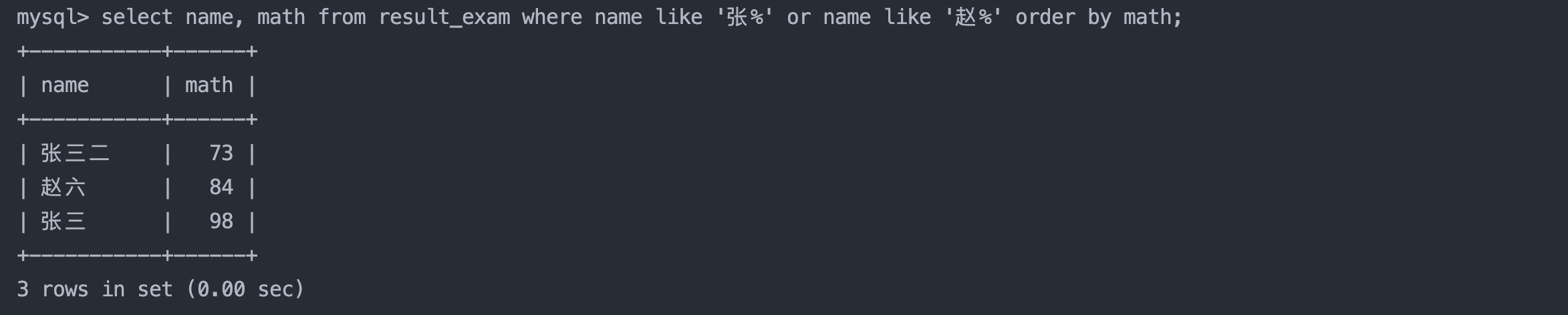
5. 查询姓张的同学或者姓赵的同学数学成绩,结果按数学成绩由高到低显示
sql复制代码
select name, math from result_exam where name like '张%' or name like '赵%' order by math;
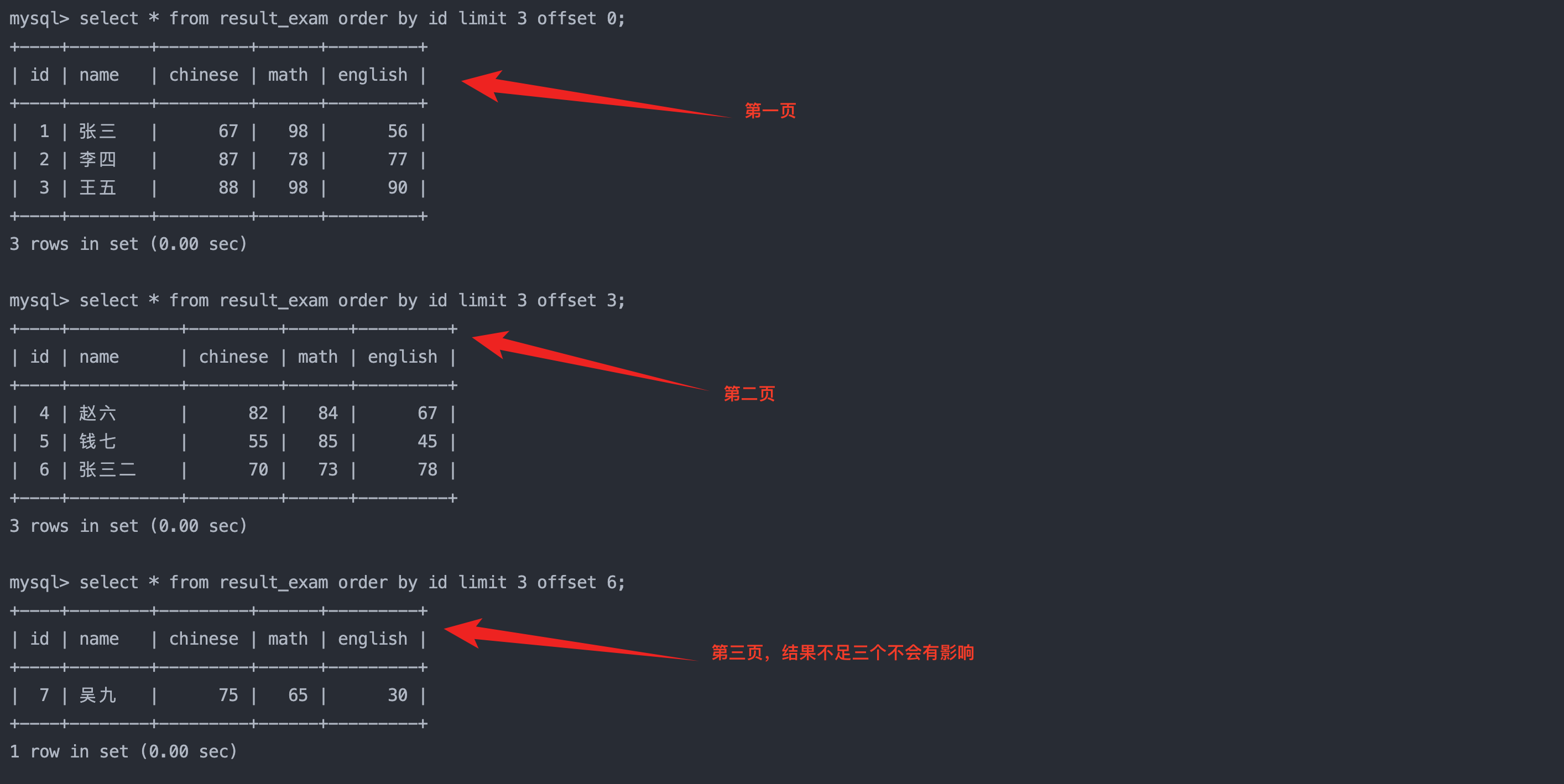
2.4 筛选分页结果
语法:
sql复制代码
-- 起始下标为 0
-- 从 0 开始,筛选 n 条结果
select ... from table_name [where ...] [order by ...] limit n;
-- 从 s 开始,筛选 n 条结果
select ... from table_name [where ...] [order by ...] limit s, n;
-- 从 s 开始,筛选 n 条结果,比第二种用法更明确,建议使用
select ... from table_name [WHERE ...] [order by ...] limit n offset s;
select * from result_exam order by id limit 3 offset 0;
select * from result_exam order by id limit 3 offset 3;
select * from result_exam order by id limit 3 offset 6;
3. 修改数据(Update)
语法:
sql复制代码
update table_name set column = expr [, column = expr ...]
[where ...] [order by ...] [limit ...]
案例:
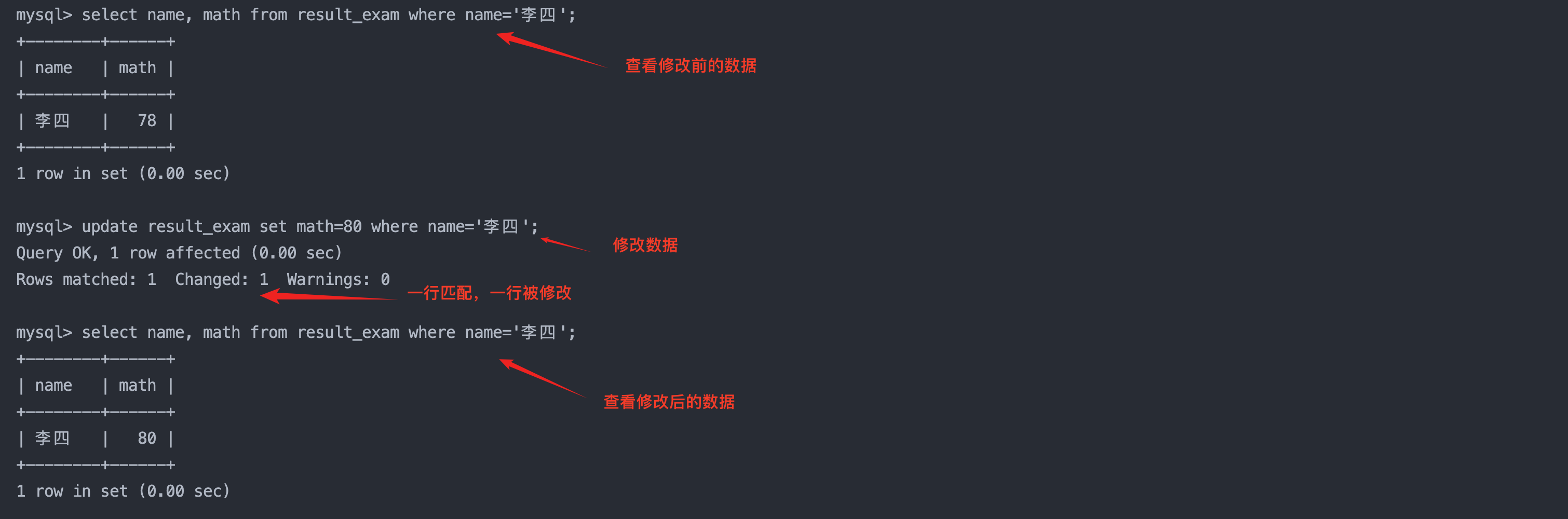
1. 将李四的数学成绩变更为80分
sql复制代码
update result_exam set math = 80 where name = '李四';
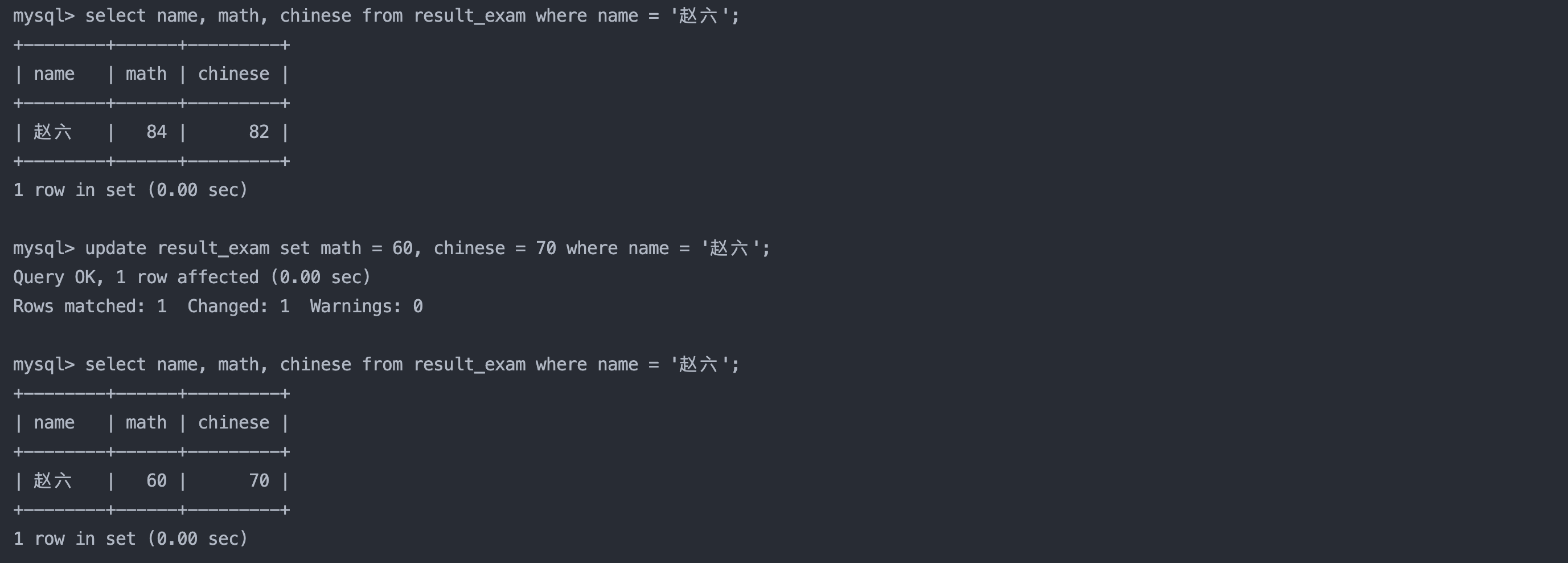
2. 将赵六同学的数学成绩变更为 60 分,语文成绩变更为 70 分
sql复制代码
update result_exam set math = 60, chinese = 70 where name = '赵六';
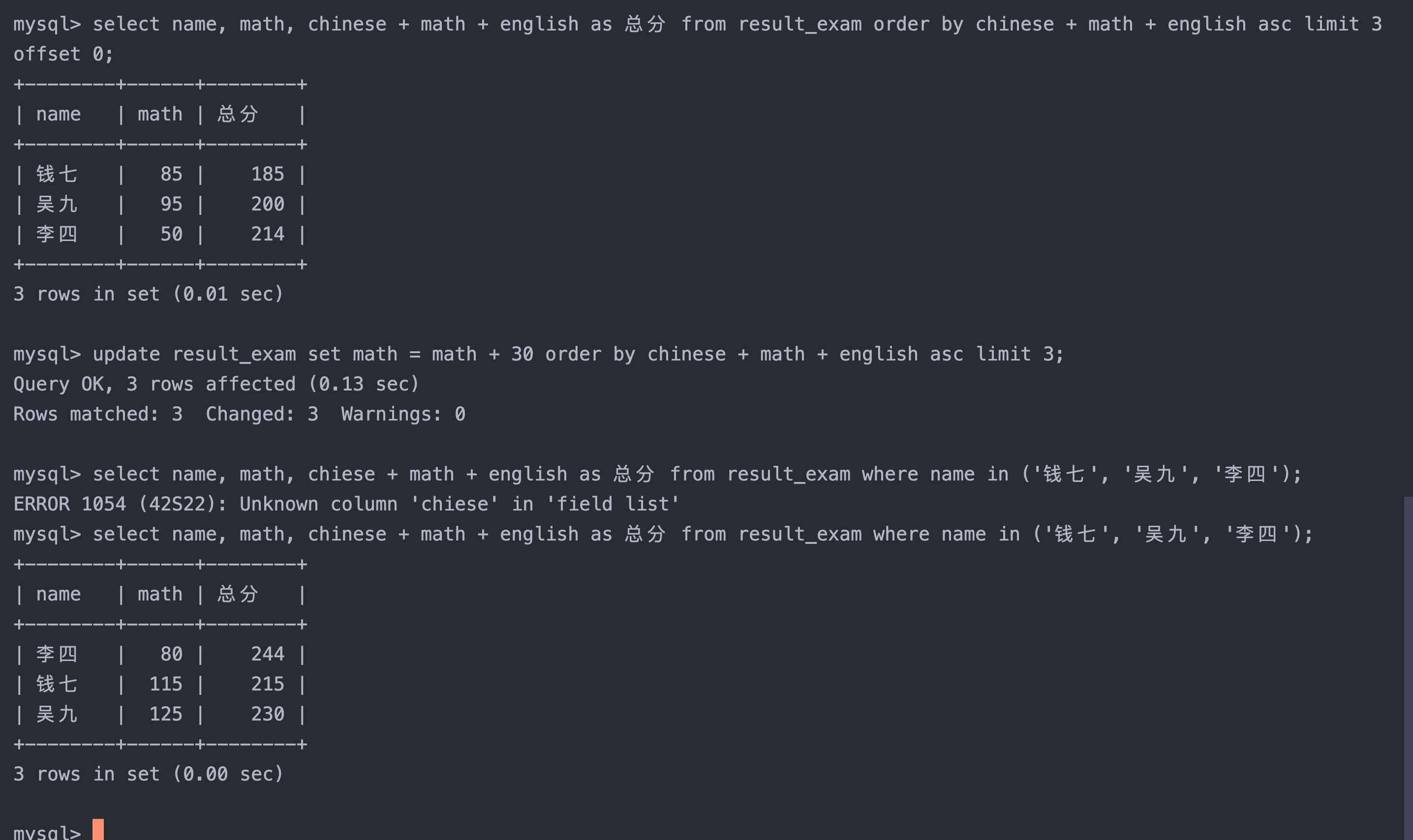
3. 将总成绩倒数前三的 3 位同学的数学成绩加上 30 分
sql复制代码
select name, math, chinese + math + english as 总分 from result_exam order by chinese + math + english asc limit 3 offset 0; -- 查看数据
update result_exam set math = math + 30 order by chinese + math + english asc limit 3; -- 修改指定数据
select name, math, chinese + math + english as 总分 from result_exam where name in ('钱七', '吴九', '李四'); -- 查看之前修改的数据
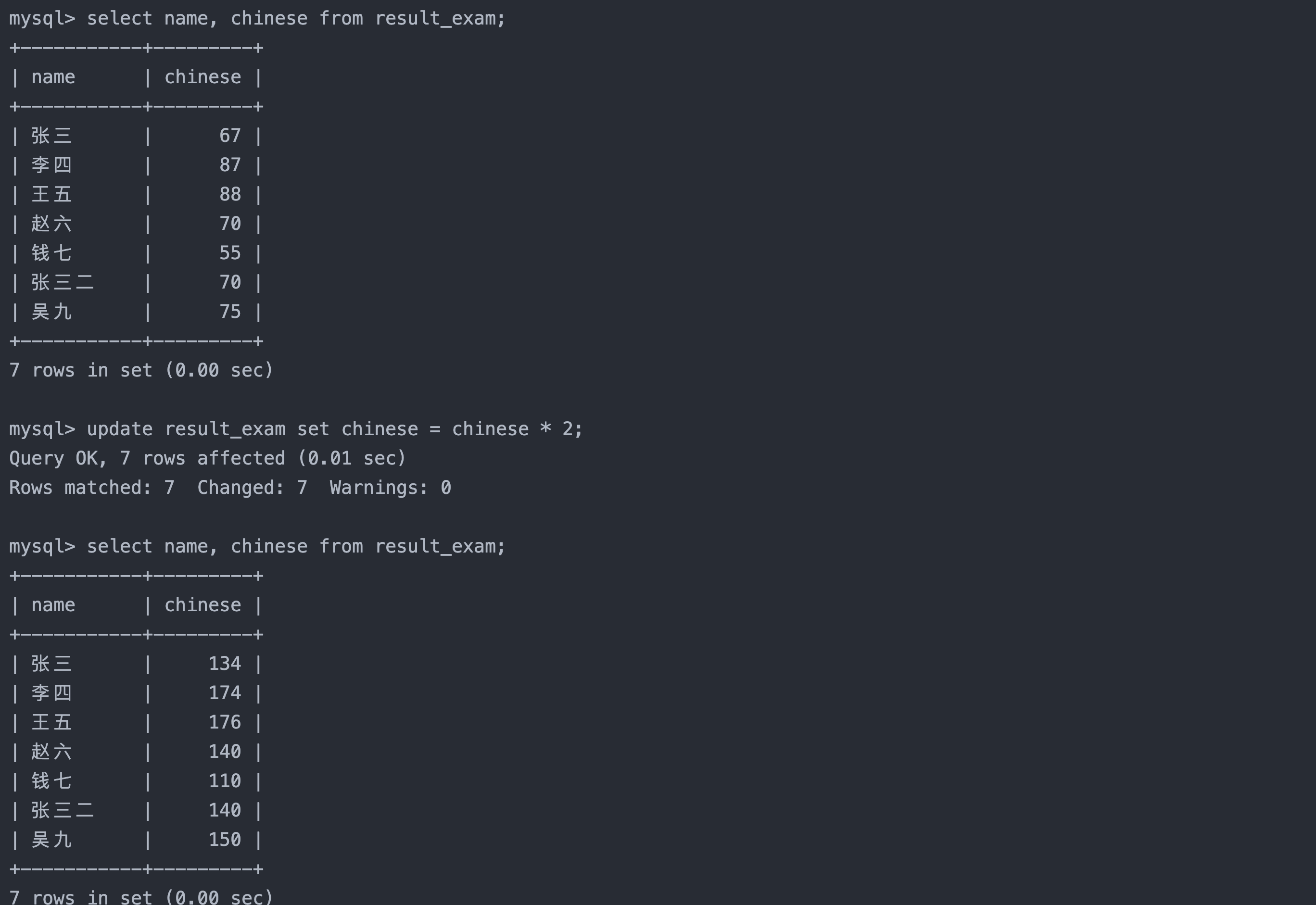
4. 将所有同学的语文成绩更新为原来的2倍
sql复制代码
select name, chinese from result_exam; -- 查看全表
update result_exam set chinese = chinese * 2; -- 没有限制则更新全表
select name, chinese from result_exam; -- 查看更新后的数据
4. 删除数据(delete)
4.1 删除数据
语法:
sql复制代码
delete from table_name [where ...] [order by ...] [limit ...]
案例:
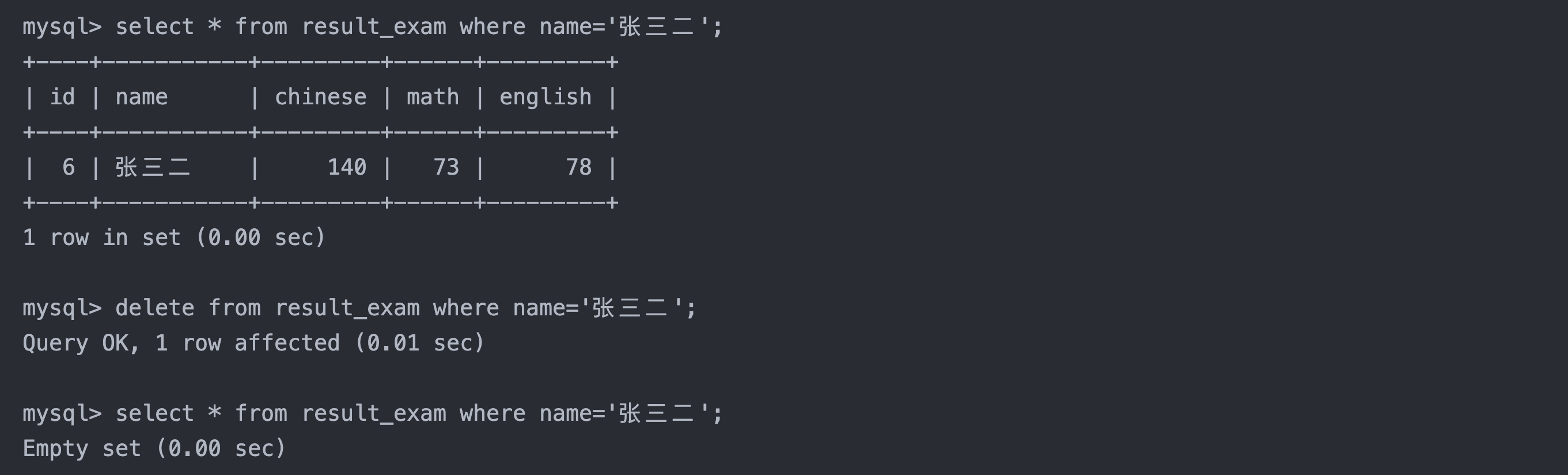
1. 删除张三二的成绩
sql复制代码
select * from result_exam where name='张三二';
delete from result_exam where name='张三二';
select * from result_exam where name='张三二';
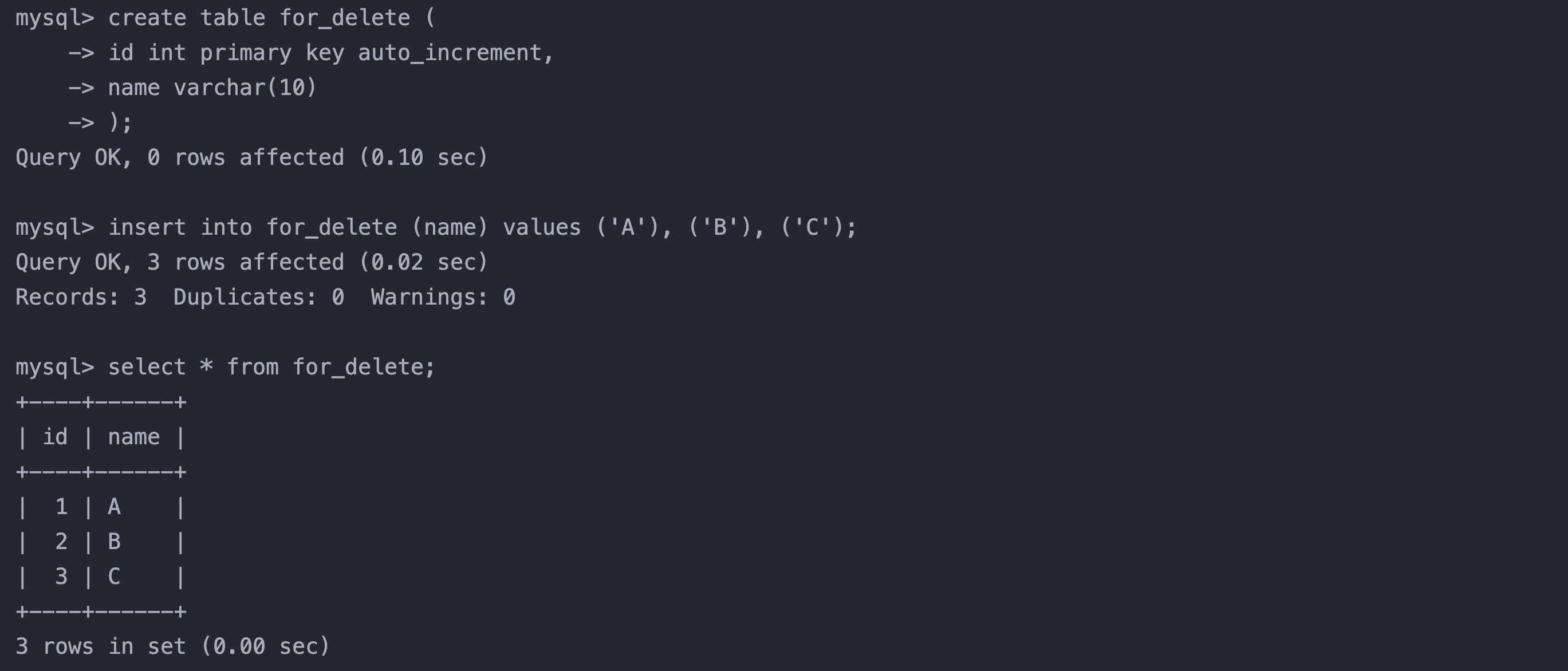
2. 删除整张表
sql复制代码
-- 准备测试表
create table for_delete (
id int primary key auto_increment,
name varchar(10)
);
-- 插入表数据
insert into for_delete (name) values ('A'), ('B'), ('C');
-- 查看插入的数据
select * from for_delete;
-- 删除表
delete from for_delete;
-- 查看删除之后的结果
select * from for_delete;
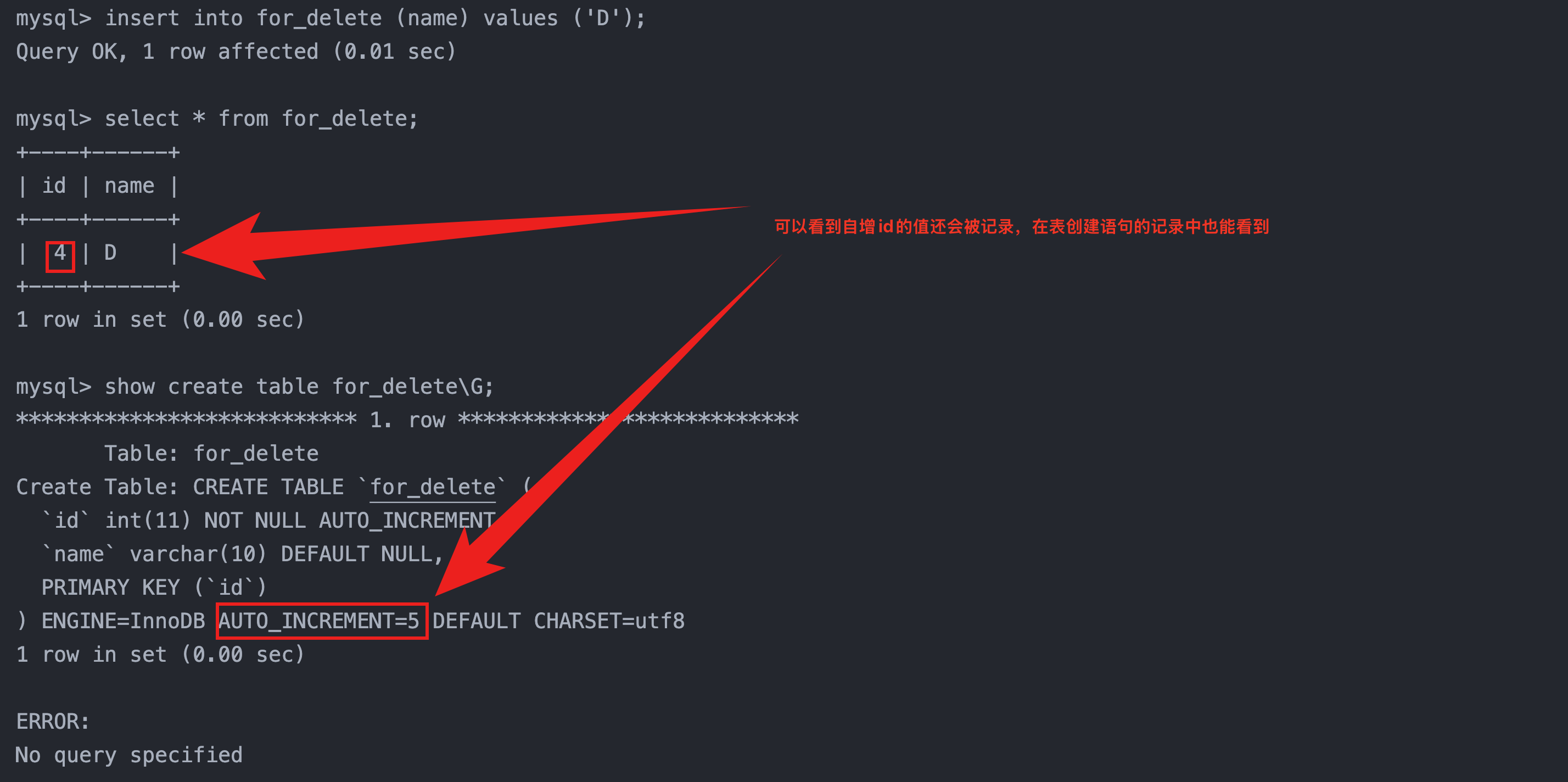
4.2 截断表
语法:
sql复制代码
truncate [table] table_name
注意:这个操作慎用,原因如下
只能对整表操作,不能像 delete 一样针对部分数据操作;
实际上 MySQL 不对数据操作,所以比 delete 更快,但是truncate在删除数据的时候,并不经过真正的事物,所以无法回滚
会重置 auto_increment 项
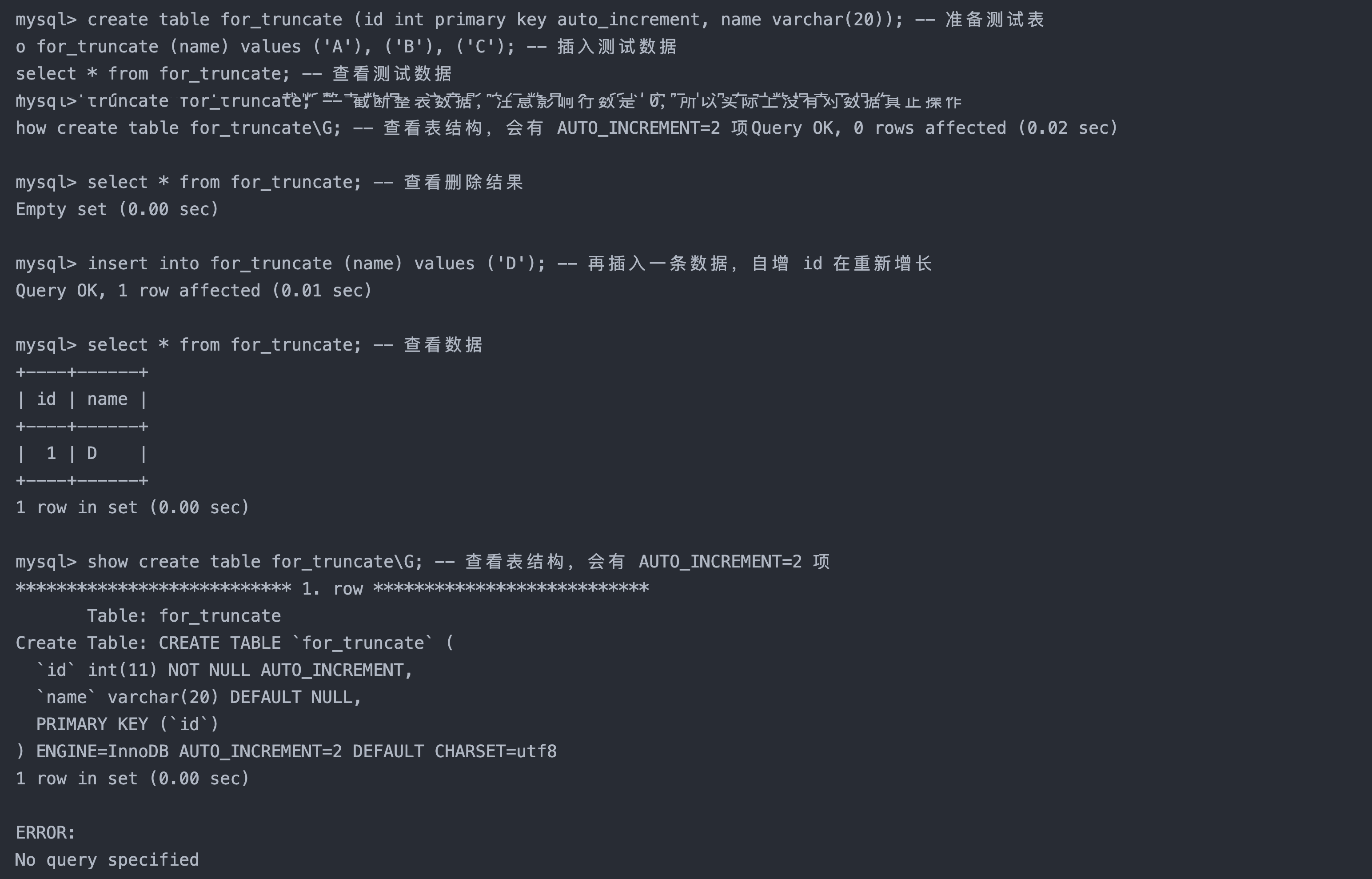
案例:
sql复制代码
create table for_truncate (id int primary key auto_increment, name varchar(20)); -- 准备测试表
insert into for_truncate (name) values ('A'), ('B'), ('C'); -- 插入测试数据
select * from for_truncate; -- 查看测试数据
truncate for_truncate; -- 截断整表数据,注意影响行数是 0,所以实际上没有对数据真正操作
select * from for_truncate; -- 查看删除结果
insert into for_truncate (name) values ('D'); -- 再插入一条数据,自增 id 在重新增长
select * from for_truncate; -- 查看数据
show create table for_truncate\G; -- 查看表结构,会有 AUTO_INCREMENT=2 项
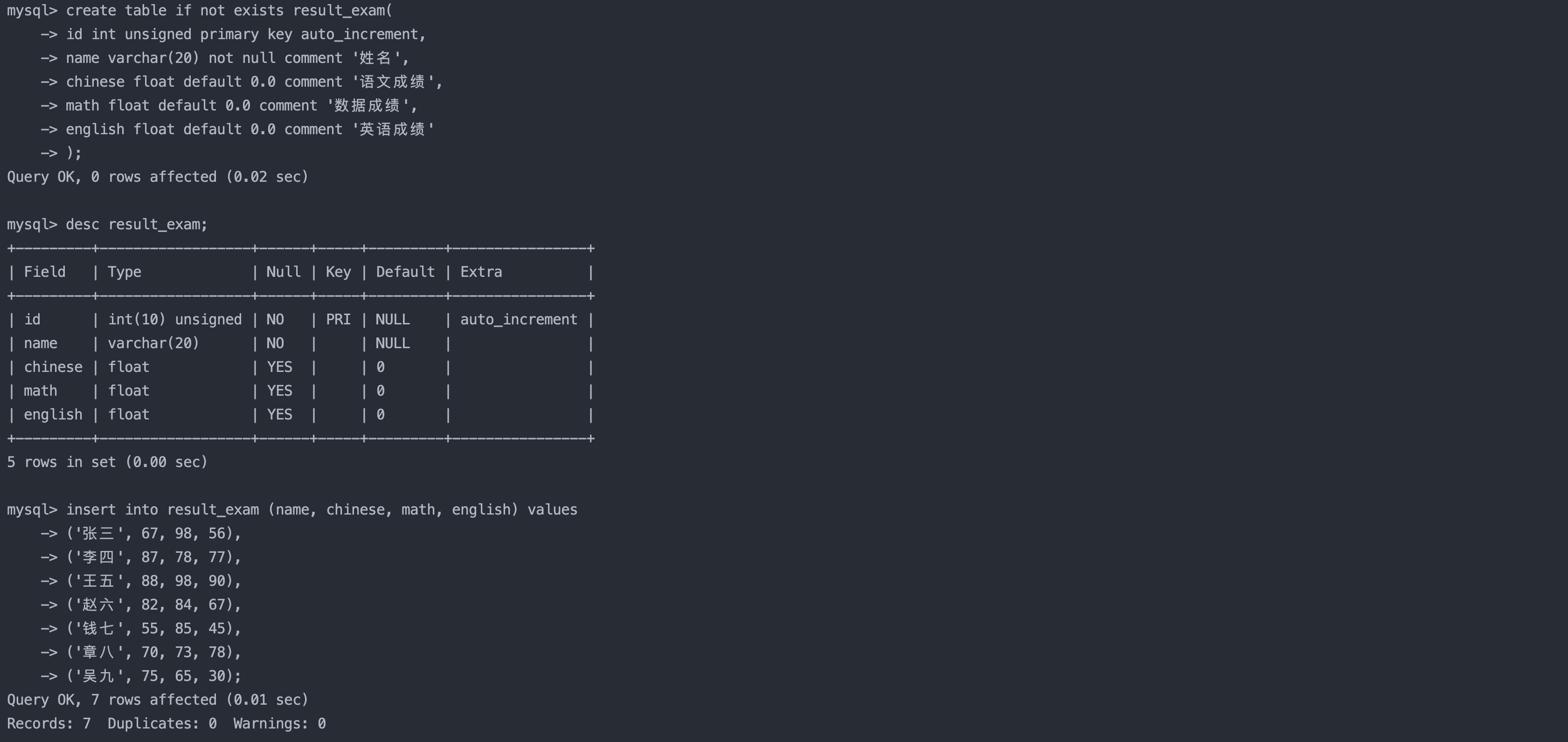
5. 插入查询的结果
案例:
sql复制代码
insert into table_name [(column [, column ...])]
select ...
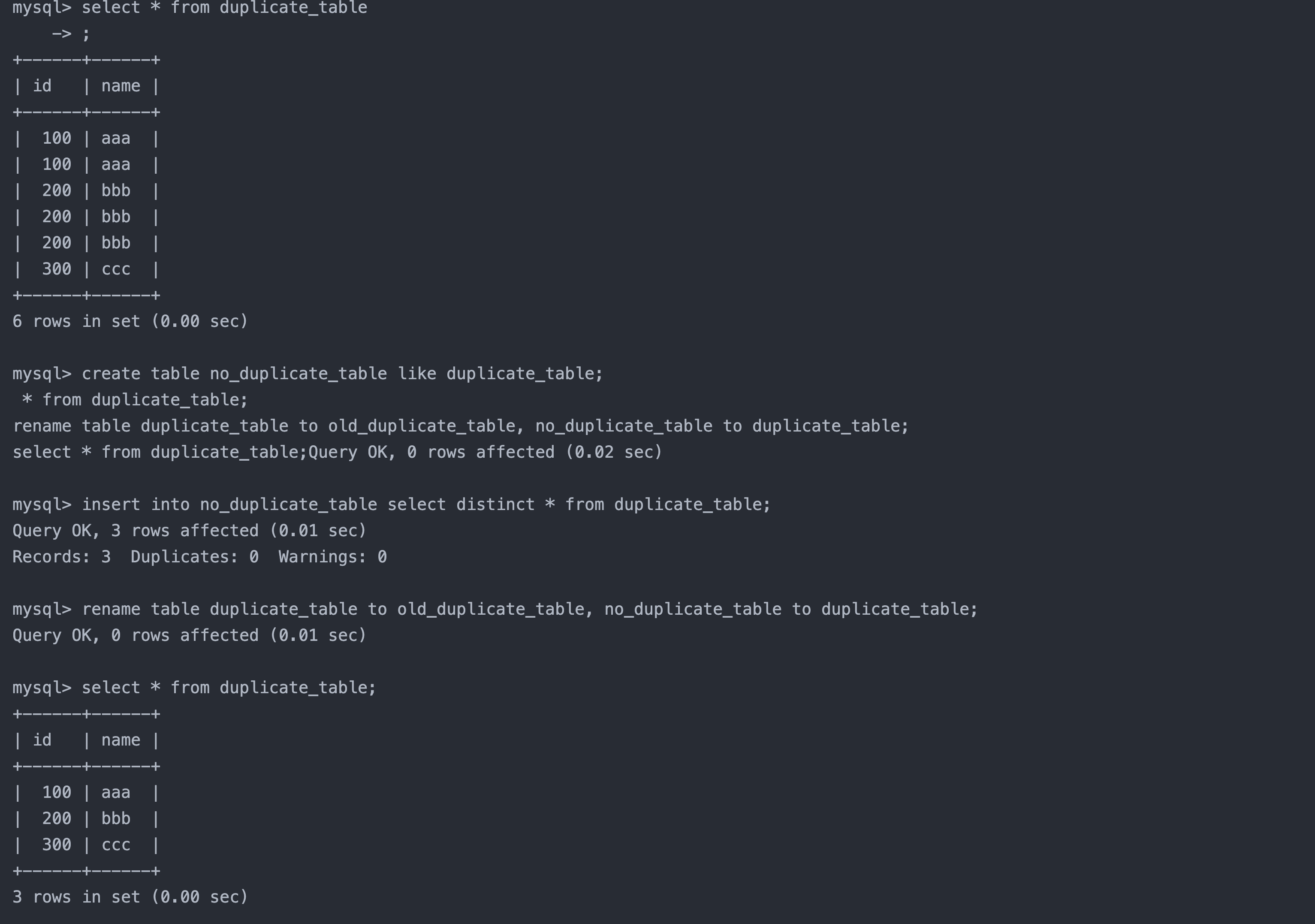
案例:删除表中的的重复复记录,重复的数据只能有一份
sql复制代码
create table duplicate_table (id int, name varchar(20)); -- 创建原数据表
-- 插入测试数据
insert into duplicate_table values (100,'aaa'), (100, 'aaa'), (200,'bbb'), (200,'bbb'), (200,'bbb'), (300,'ccc');
处理思路:
创建一张空表 no_duplicate_table,结构和 duplicate_table 一样
将 duplicate_table 的去重数据插入到 no_duplicate_table
通过重命名表,实现原子的去重操作
查看最终结果
代码:
sql复制代码
create table no_duplicate_table like duplicate_table;
insert into no_duplicate_table select distinct * from duplicate_table;
rename table duplicate_table to old_duplicate_table, no_duplicate_table to duplicate_table;
select * from duplicate_table;
6. 分组与聚合统计
6.1 聚合统计
函数
说明
count(distinct expr)
返回查询到的数据的 数量
sum(distinct expr)
返回查询到的数据的 总和,不是数字没有意义
avg(distinct expr)
返回查询到的数据的 平均值,不是数字没有意义
max(distinct expr)
返回查询到的数据的 最大值,不是数字没有意义
min(distinct expr)
返回查询到的数据的 最小值,不是数字没有意义
案例:
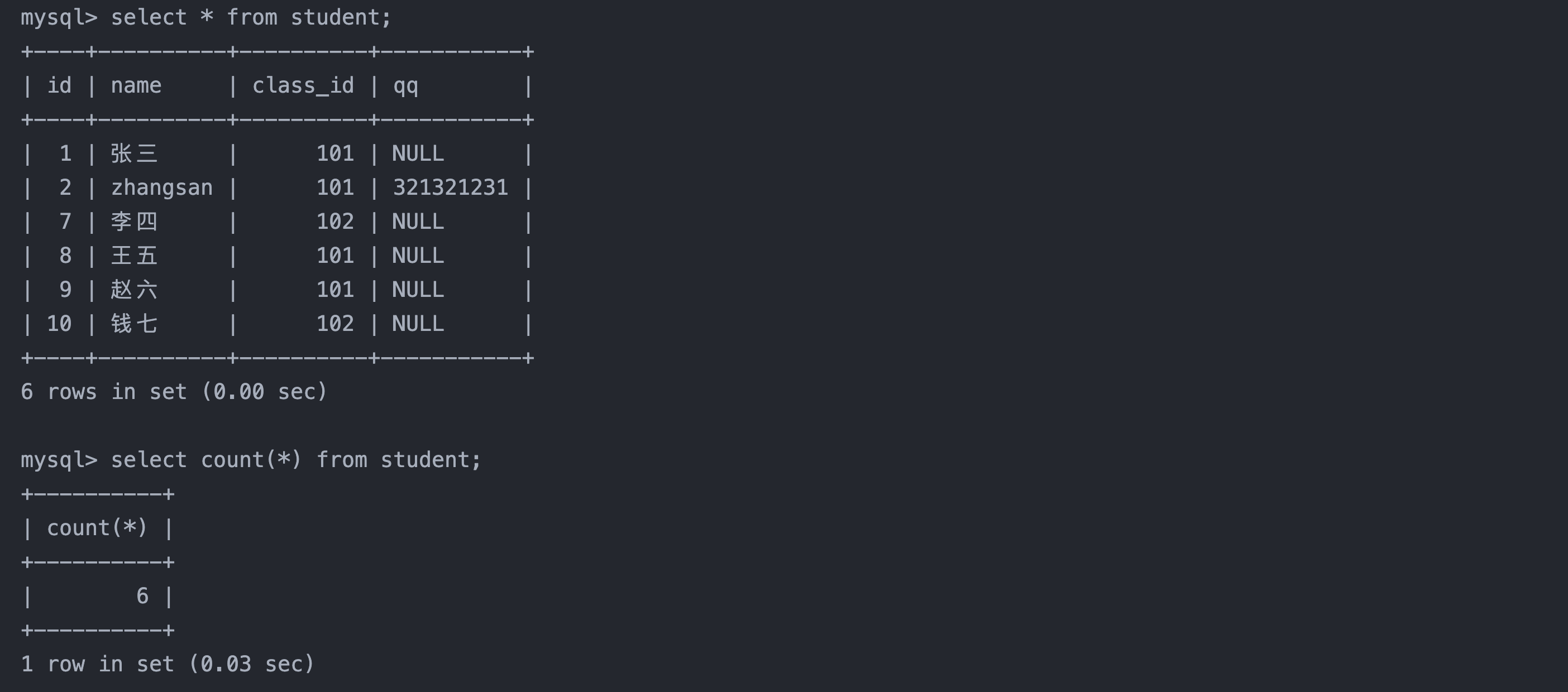
1. 统计班级共有多少同学
sql复制代码
select count(*) from student;
2. 统计班级收集的 qq 号有多少
sql复制代码
select count(qq) from student; -- NULL不计入结果
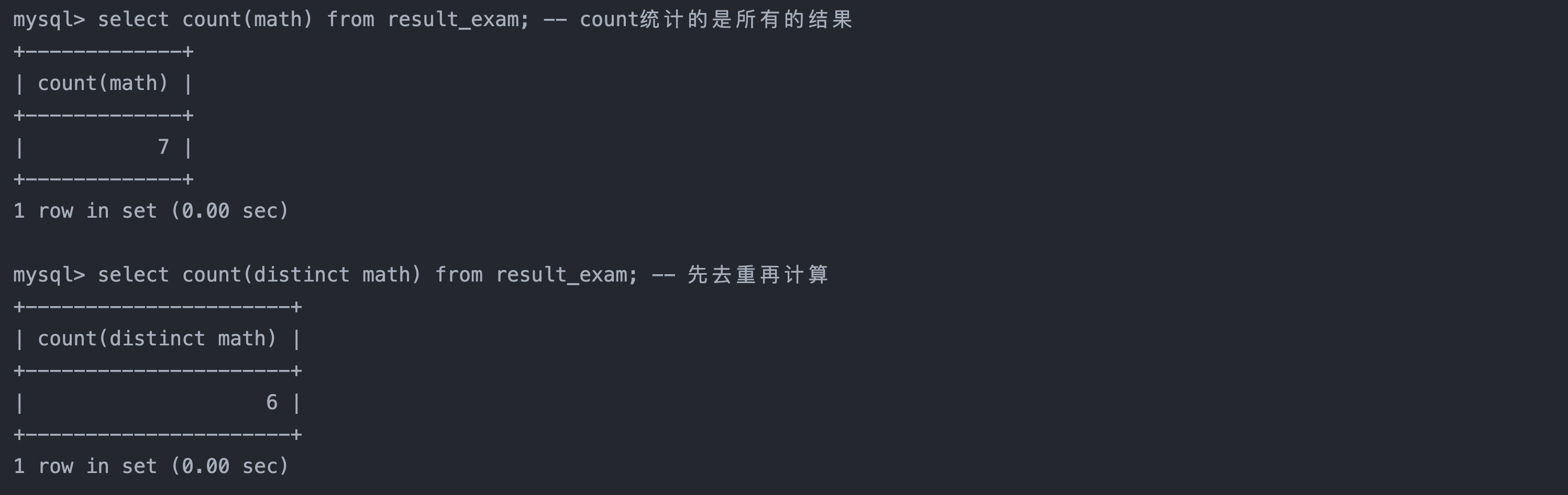
3. 统计本次考试的数学成绩分数个数
sql复制代码
select count(math) from result_exam; -- count统计的是所有的结果
select count(distinct math) from result_exam; -- 先去重再计算
4. 统计数学成绩总分
sql复制代码
select sum(math) from result_exam;
5. 统计平均总分
sql复制代码
select avg(chinese + math + english) as 平均总分 from result_exam;
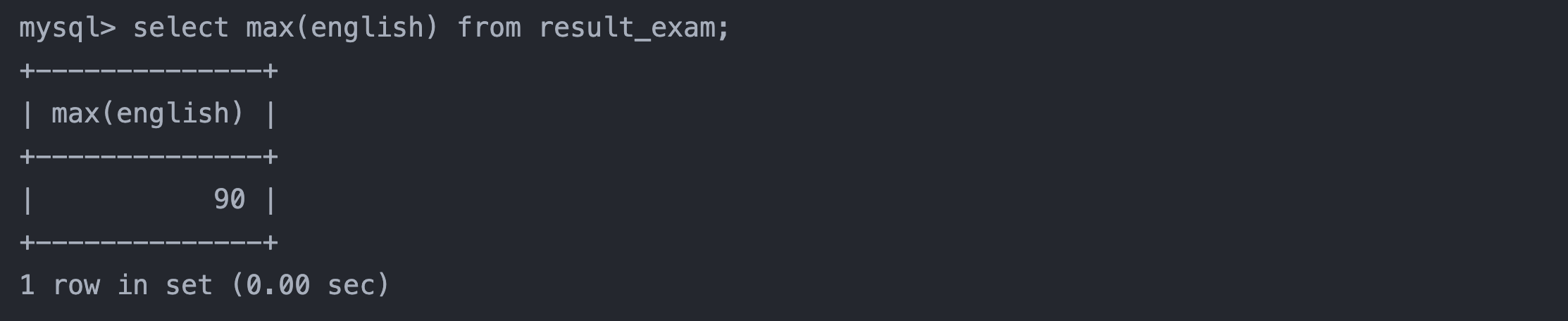
6. 返回英语最高分
sql复制代码
select max(english) from result_exam;
7. 返回 > 70 分以上的数学最低分
sql复制代码
select min(math) from result_exam where math > 70;
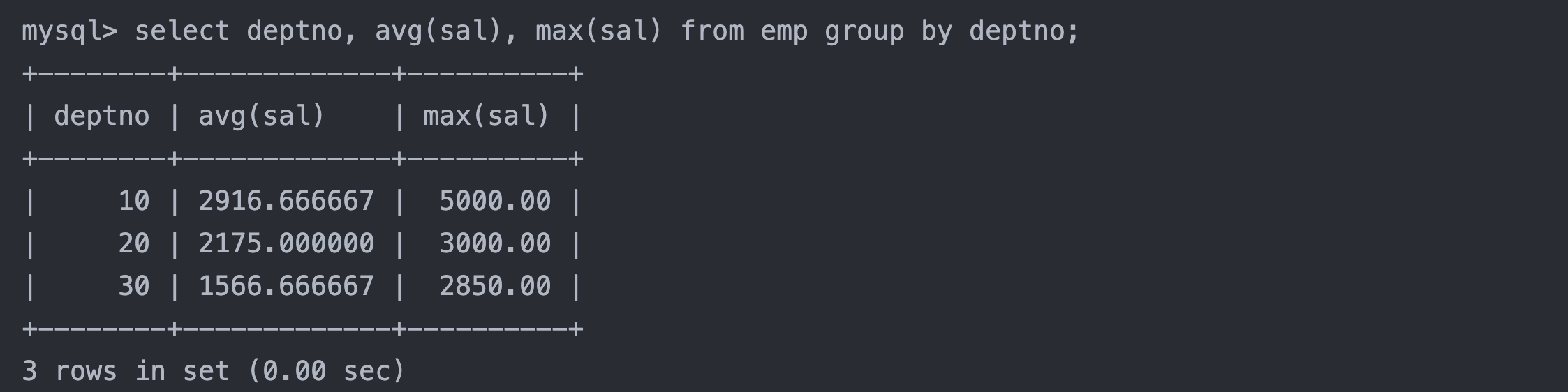
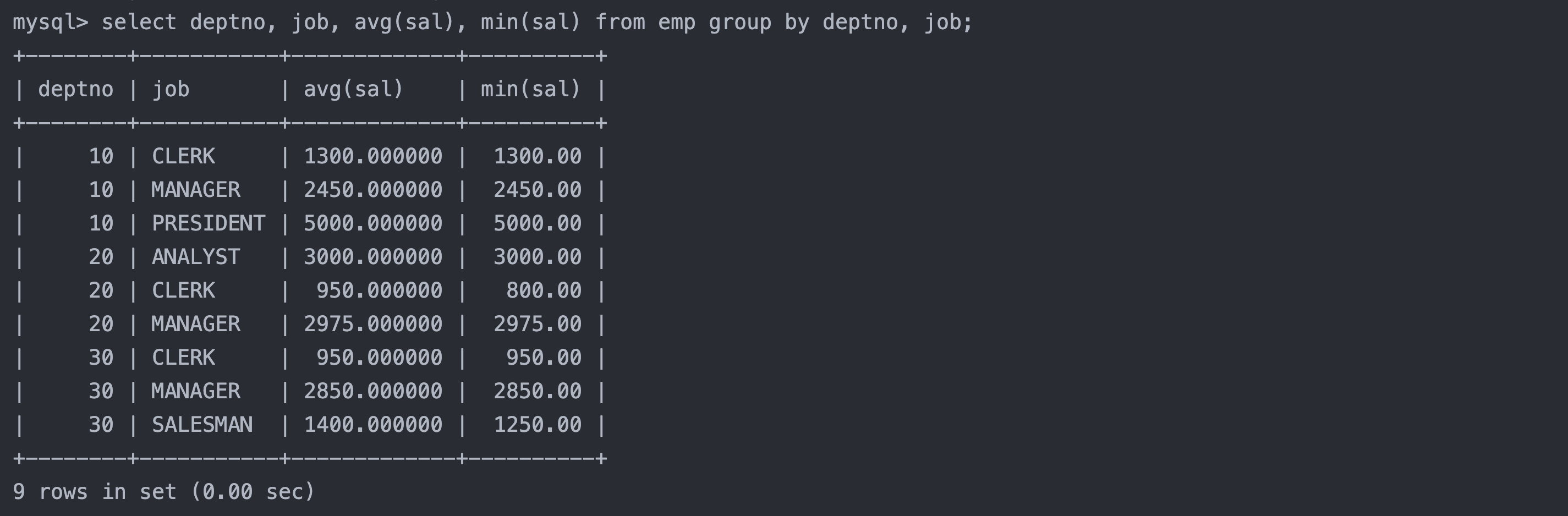
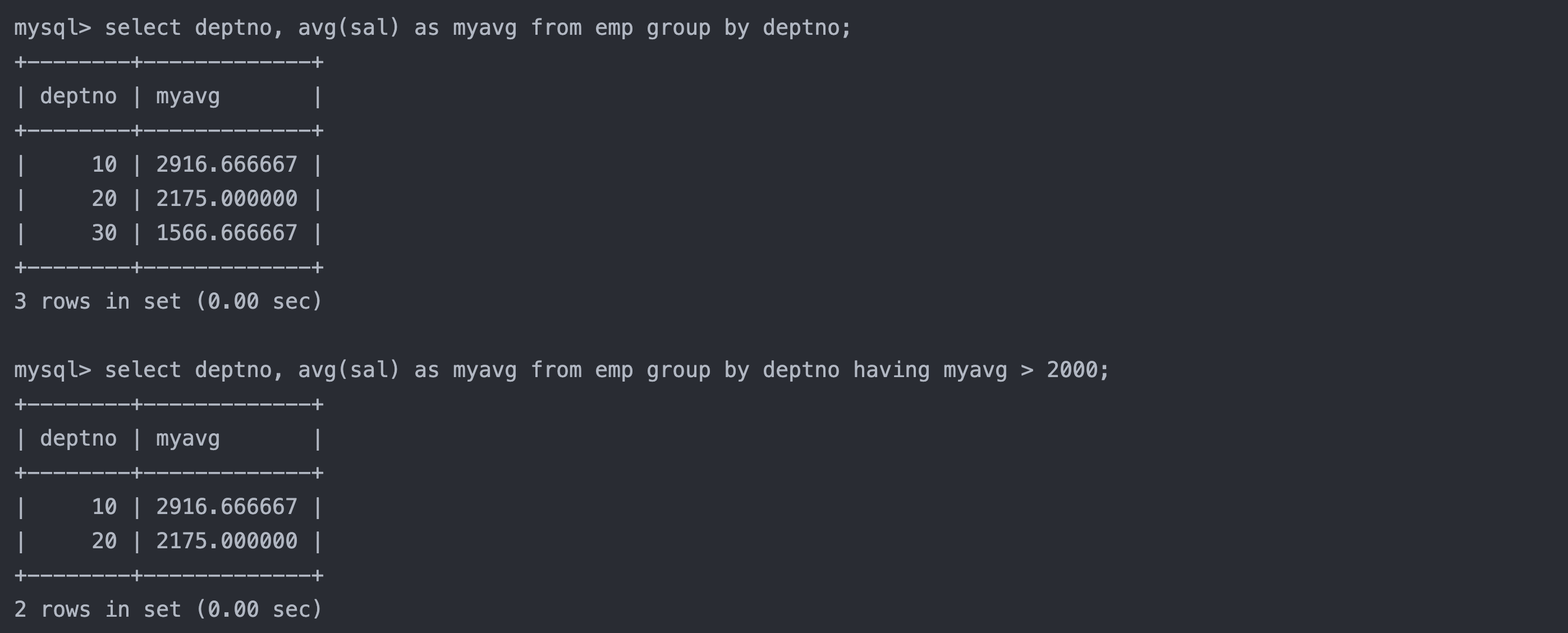
6.2 group by子句分组
在select中使用group by 子句可以对指定列进行分组查询
sql复制代码
select column1, column2, .. from table group by column;