大家好,大语言模型(LLMs)对自然语言处理(NLP)的影响是非常深远的,不仅提高了任务效率,还催生出新能力,推动了模型架构和训练方法的创新。尽管如此强大,但LLMs也有局限,有时需要针对特定任务进行特别优化。通过对LLMs进行微调,可以大幅提升模型的性能,同时降低训练成本,获得更贴近实际应用的上下文结果。
1.LLM微调
LLM微调就是对预训练的大型语言模型进行针对性的再训练,使其更适应特定领域的任务。这一过程能大幅提高模型的适用性,同时减少数据和计算资源的消耗。
微调的主要步骤包括:
-
选择模型:挑选与任务需求相匹配的预训练模型。
-
收集数据:准备一个与任务相关的、结构化的数据集。
-
数据预处理:对数据集进行清洗、划分,并确保其与模型兼容。
-
执行微调:在特定数据集上调整模型,使其更符合任务需求。
-
任务适应:调整模型参数,使其更好地理解和处理特定任务。
LLM微调适用于需要精准理解和流畅表达的NLP任务,如情感分析、命名实体识别等,能充分发挥预训练模型的潜力,适应专业领域的需求。
2.微调方法
LLM主要有两种方法:
-
全微调:通过训练模型响应特定指令来提升其在多任务上的表现,需要更新所有模型权重,对资源要求较高。
-
参数高效微调(PEFT):只更新部分模型参数,减少资源消耗,避免遗忘已学知识,适合多任务处理。LoRA和QLoRA是PEFT中常用的有效技术。
3.LoRa微调
LoRa是一种微调技术,它不改变大语言模型(LLM)的所有权重,而是通过调整两个小矩阵来近似整个权重矩阵,形成LoRa适配器。这样,原始LLM保持不变,而适配器体积小,通常只有几MB。
在实际使用中,LoRa适配器与原始LLM一起工作,多个适配器可以共享一个LLM,减少了内存需求。
4.QLoRA技术简述
QLoRA是LoRA的内存优化版,通过将适配器权重量化为4位,进一步减少内存和存储需求。虽然精度有所降低,但效果与LoRA相当。
本教程将展示如何用QLoRA在单个GPU上微调LLM,步骤如下:
4.1 准备Jupyter Notebook
这里将用Kaggle笔记本演示,你也可以使用其他Jupyter环境。Kaggle每周提供免费GPU时间,足够我们使用。打开新笔记本,设置好标题,连接到运行环境,并选择GPU P100作为加速器。
此外,用HuggingFace库来下载和训练模型,需要访问令牌,已注册用户可以在设置中获取。
4.2 安装所需库
安装以下库以进行实验:
python
!pip install -q -U bitsandbytes transformers peft accelerate datasets scipy einops evaluate trl rouge_score这些库的主要功能包括:
-
Bitsandbytes:优化CUDA函数,加速模型运行。
-
transformers:提供预训练模型和训练工具。
-
peft:支持参数高效微调。
-
accelerate:简化多设备训练代码。
-
datasets:方便访问多种数据集。
-
einops:简化张量操作。
接下来,导入所需库:
python
from datasets import load_dataset
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
HfArgumentParser,
AutoTokenizer,
TrainingArguments,
Trainer,
GenerationConfig
)
from tqdm import tqdm
from trl import SFTTrainer
import torch
import time
import pandas as pd
import numpy as np
from huggingface_hub import interpreter_login
interpreter_login()本文不使用Weights and Biases跟踪训练指标,如需使用,请自行设置环境变量:
python
import os
# 禁用Weights and Biases
os.environ['WANDB_DISABLED']="true"4.3 加载数据集
使用HuggingFace的DialogSum数据集来微调模型,这个数据集包含一万多个对话及其摘要和主题。也可以用其他数据集来尝试。
加载数据集的代码如下:
python
huggingface_dataset_name = "neil-code/dialogsum-test"
dataset = load_dataset(huggingface_dataset_name)加载数据集后,就可以查看数据集,了解其中包含的内容:
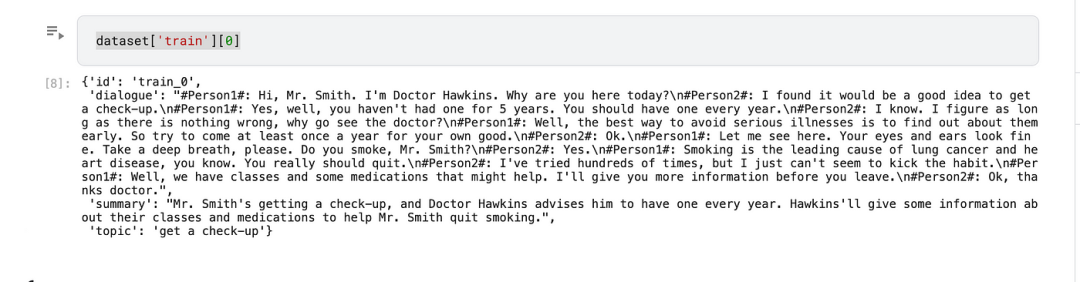
数据集中每条记录包括:对话文本、对话摘要、对话主题、唯一ID。
4.4 设置Bitsandbytes配置
在加载模型之前,需要设置一个配置类来指定量化的方式。这里使用BitsAndBytesConfig,以4位格式加载模型,这样可以显著减少内存使用,但会牺牲一些准确性。
python
import torch
compute_dtype = torch.float16
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type='nf4',
bnb_4bit_compute_dtype=compute_dtype,
bnb_4bit_use_double_quant=False,
)4.5 加载预训练模型
微软新开源的Phi-2模型参数达27亿,性能领先。这里用它进行微调,从HuggingFace以4位量化方式加载。
python
model_name='microsoft/phi-2'
device_map = {"": 0}
original_model = AutoModelForCausalLM.from_pretrained(model_name,
device_map=device_map,
quantization_config=bnb_config,
trust_remote_code=True,
use_auth_token=True)4.6 配置标记器
为了在训练时节省内存,现在来设置标记器:
python
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True, padding_side="left", add_eos_token=True, add_bos_token=True, use_fast=False)
tokenizer.pad_token = tokenizer.eos_token4.7 零样本推理测试
用一些样本输入来测试刚才加载的模型性能:
python
from transformers import set_seed
set_seed(42) # 确保结果可复现
# 选取测试集中的一个样本
prompt = dataset['test'][10]['dialogue']
summary = dataset['test'][10]['summary']
# 构造输入格式
formatted_prompt = f"Instruct: Summarize the following conversation.\n{prompt}\nOutput:\n"
# 生成摘要
res = gen(original_model, formatted_prompt, 100)
output = res[0].split('Output:\n')[1]
# 显示结果
print("-" * 100)
print(f'INPUT PROMPT:\n{formatted_prompt}')
print("-" * 100)
print(f'BASELINE HUMAN SUMMARY:\n{summary}')
print("-" * 100)
print(f'MODEL GENERATION - ZERO SHOT:\n{output}')
测试结果显示,尽管模型在对话摘要任务上仍有提升空间,但其已能从文本中提取关键信息,表明微调能进一步提升性能。
4.8 数据预处理
在微调模型之前,不能直接使用原始数据集,需要将数据集中的提示转换成模型能够理解的格式。
为了使数据集适配微调流程,这里编写辅助函数来格式化输入数据集。具体来说,就是将对话摘要(即提示-响应对)转换成大型语言模型(LLM)能够识别的明确指令。
python
def create_prompt_formats(sample):
"""
格式化样本的各种字段('instruction', 'output')
然后使用两个换行符将它们连接起来
:param sample: 样本字典
"""
INTRO_BLURB = "以下是描述任务的指令。写一个适当完成请求的响应。"
INSTRUCTION_KEY = "### 指令:总结以下对话。"
RESPONSE_KEY = "### 输出:"
END_KEY = "### 结束"
blurb = f"\n{INTRO_BLURB}"
instruction = f"{INSTRUCTION_KEY}"
input_context = f"{sample['dialogue']}" if sample["dialogue"] else None
response = f"{RESPONSE_KEY}\n{sample['summary']}"
end = f"{END_KEY}"
parts = [part for part in [blurb, instruction, input_context, response, end] if part]
formatted_prompt = "\n\n".join(parts)
sample["text"] = formatted_prompt
return sample上述函数负责将输入数据转换成提示格式。
接下来,用模型的分词器对这些提示进行处理,将其转换成标记化的形式。我们的目标是生成长度统一的输入序列,这样做有助于微调语言模型,因为它能提升处理效率并降低计算成本。同时,还得确保这些序列的长度不超过模型允许的最大标记数。
python
from functools import partial
# 来源 https://github.com/databrickslabs/dolly/blob/master/training/trainer.py
def get_max_length(model):
conf = model.config
max_length = None
for length_setting in ["n_positions", "max_position_embeddings", "seq_length"]:
max_length = getattr(model.config, length_setting, None)
if max_length:
print(f"找到最大长度:{max_length}")
break
if not max_length:
max_length = 1024
print(f"使用默认最大长度:{max_length}")
return max_length
def preprocess_batch(batch, tokenizer, max_length):
"""
分批标记化
"""
return tokenizer(
batch["text"],
max_length=max_length,
truncation=True,
)
# 来源 https://github.com/databrickslabs/dolly/blob/master/training/trainer.py
def preprocess_dataset(tokenizer: AutoTokenizer, max_length: int, seed, dataset):
"""格式化并标记化,使其准备好进行训练
:param tokenizer (AutoTokenizer): 模型分词器
:param max_length (int): 分词器发出的最大标记数
"""
# 为每个样本添加提示
print("预处理数据集...")
dataset = dataset.map(create_prompt_formats)#, batched=True)
# 对每个批次的数据集应用预处理并移除 'instruction', 'context', 'response', 'category' 字段
_preprocessing_function = partial(preprocess_batch, max_length=max_length, tokenizer=tokenizer)
dataset = dataset.map(
_preprocessing_function,
batched=True,
remove_columns=['id', 'topic', 'dialogue', 'summary'],
)
# 过滤掉输入_ids超过最大长度的样本
dataset = dataset.filter(lambda sample: len(sample["input_ids"]) < max_length)
# 随机打乱数据集
dataset = dataset.shuffle(seed=seed)
return dataset通过这些函数的处理,数据集已经准备好进行微调了。
python
## 数据集预处理
max_length = get_max_length(original_model)
print(max_length)
train_dataset = preprocess_dataset(tokenizer, max_length,seed, dataset['train'])
eval_dataset = preprocess_dataset(tokenizer, max_length,seed, dataset['validation'])4.9 准备模型进行QLoRA训练
使用PEFT库中的prepare_model_for_kbit_training方法来准备模型。
通过这个方法,对原始模型original_model进行初始化,设置好必要的配置,以便进行QLoRA训练。
4.10 设置PEFT进行微调
接下来,配置LoRA参数,以便对基础模型进行微调。
python
from peft import LoraConfig, get_peft_model
config = LoraConfig(
r=32, # 定义适配器的秩
lora_alpha=32, # 学习权重的缩放因子
target_modules=[
'q_proj', 'k_proj', 'v_proj', 'dense'
],
bias="none",
lora_dropout=0.05, # 防止过拟合
task_type="CAUSAL_LM", # 任务类型
)
# 启用梯度检查点减少内存消耗
original_model.gradient_checkpointing_enable()
# 获取配置好的PEFT模型
peft_model = get_peft_model(original_model, config)这里的r(秩)参数控制适配器的复杂度,影响模型的表达能力和计算成本。lora_alpha参数用于调整学习权重,影响LoRA激活的强度。配置完成后,可以通过辅助函数查看模型的可训练参数数量。
python
print(print_number_of_trainable_model_parameters(peft_model))
4.11 训练PEFT适配器
设置训练参数,并初始化训练器:
python
import transformers
from transformers import TrainingArguments, Trainer, DataCollatorForLanguageModeling
# 设置训练参数
output_dir = f'./peft-dialogue-summary-training-{str(int(time.time()))}'
peft_training_args = TrainingArguments(
output_dir=output_dir,
warmup_steps=1,
per_device_train_batch_size=1,
gradient_accumulation_steps=4,
max_steps=1000,
learning_rate=2e-4,
optim="paged_adamw_8bit",
logging_steps=25,
logging_dir="./logs",
save_strategy="steps",
save_steps=25,
evaluation_strategy="steps",
eval_steps=25,
do_eval=True,
gradient_checkpointing=True,
report_to="none",
overwrite_output_dir=True,
group_by_length=True,
)
# 禁用缓存,准备训练器
peft_model.config.use_cache = False
peft_trainer = Trainer(
model=peft_model,
args=peft_training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False),
)计划进行1000步训练,这个数字对于我们的特定数据集应该是合适的。不过,可能需要根据实际情况调整这个数值,训练时间会根据超参数的不同而有所差异。
python
peft_trainer.train()训练完成后,准备一个用于推理的模型。给原始的Phi-2模型添加一个适配器,并设置为不可训练状态,因为我们只打算用它来做推理。
python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
base_model_id = "microsoft/phi-2"
base_model = AutoModelForCausalLM.from_pretrained(base_model_id)
eval_tokenizer = AutoTokenizer.from_pretrained(base_model_id, add_bos_token=True)
eval_tokenizer.pad_token = eval_tokenizer.eos_token
from peft import PeftModel
ft_model = PeftModel.from_pretrained(
base_model,
"/kaggle/working/peft-dialogue-summary-training-1705417060/checkpoint-1000",
torch_dtype=torch.float16,
is_trainable=False
)微调是一个需要反复试验的过程。我们可能需要根据验证集和测试集的表现来调整模型结构、超参数或训练数据,以提升模型性能。
4.12 定性评估模型(人工评估)
使用PEFT模型对同一个输入进行推理,以评估其性能:
python
from transformers import set_seed
set_seed(seed)
# 选择测试集中的一个对话样本
index = 5
dialogue = dataset['test'][index]['dialogue']
summary = dataset['test'][index]['summary']
# 构建推理提示
prompt = f"Instruct: Summarize the following conversation.\n{dialogue}\nOutput:\n"
# 使用PEFT模型生成摘要
peft_model_res = gen(ft_model, prompt, 100)
peft_model_output = peft_model_res[0].split('Output:\n')[1]
prefix, _, _ = peft_model_output.partition('###')
# 打印结果
dash_line = '-' * 100
print(dash_line)
print(f'输入提示:\n{prompt}')
print(dash_line)
print(f'人工摘要:\n{summary}\n')
print(dash_line)
print(f'PEFT模型输出:\n{prefix}')这段代码将展示PEFT模型相对于人类基线摘要的表现。通过比较模型输出和人类生成的摘要,可以定性地评估PEFT模型的性能。

4.13 定量评估模型(使用ROUGE指标)
ROUGE(Recall-Oriented Understudy for Gisting Evaluation)是一种评估自动摘要和机器翻译软件的工具,它通过比较机器生成的摘要与人工生成的参考摘要来衡量效果,能有效反映微调后摘要质量的整体提升。
通过ROUGE指标来定量评估模型生成的摘要,以下是评估过程:
python
from transformers import AutoModelForCausalLM
import pandas as pd
import evaluate
import numpy as np
# 加载模型和数据
original_model = AutoModelForCausalLM.from_pretrained(base_model_id, device_map='auto')
dialogues = dataset['test'][0:10]['dialogue']
human_baseline_summaries = dataset['test'][0:10]['summary']
# 初始化摘要列表
original_model_summaries = []
peft_model_summaries = []
# 生成摘要并评估
for idx, dialogue in enumerate(dialogues):
prompt = f"Instruct: Summarize the following conversation.\n{dialogue}\nOutput:\n"
original_model_res = gen(original_model, prompt, 100)
original_model_text_output = original_model_res[0].split('Output:\n')[1]
peft_model_res = gen(ft_model, prompt, 100)
peft_model_output = peft_model_res[0].split('Output:\n')[1]
peft_model_text_output, _, _ = peft_model_output.partition('###')
original_model_summaries.append(original_model_text_output)
peft_model_summaries.append(peft_model_text_output)
# 将结果存入DataFrame
df = pd.DataFrame(list(zip(human_baseline_summaries, original_model_summaries, peft_model_summaries)),
columns=['human_baseline_summaries', 'original_model_summaries', 'peft_model_summaries'])
# 计算ROUGE指标
rouge = evaluate.load('rouge')
original_model_results = rouge.compute(predictions=original_model_summaries, references=human_baseline_summaries)
peft_model_results = rouge.compute(predictions=peft_model_summaries, references=human_baseline_summaries)
# 打印结果
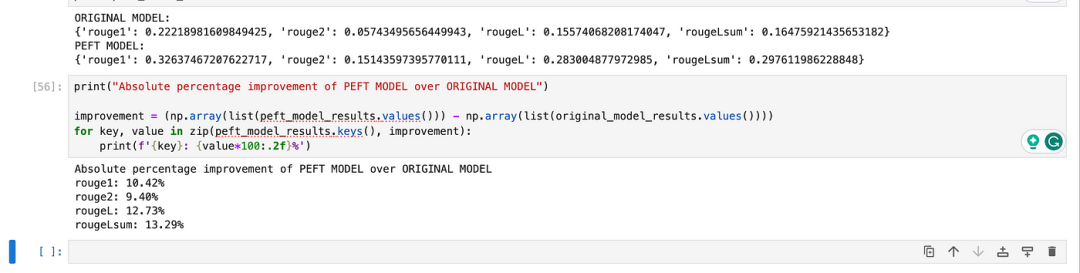
print('原始模型ROUGE指标:')
print(original_model_results)
print('PEFT模型ROUGE指标:')
print(peft_model_results)
# 计算提升百分比
improvement = (np.array(list(peft_model_results.values())) - np.array(list(original_model_results.values())))
for key, value in zip(peft_model_results.keys(), improvement):
print(f'{key}提升: {value*100:.2f}%')通过ROUGE指标,可以看到PEFT模型相较于原始模型在摘要质量上的显著提升。
微调大型语言模型(LLM)已成为寻求优化运营流程必不可少的步骤。虽然LLM的初始训练赋予了广泛的语言理解能力,但微调过程将这些模型细化为能够处理特定主题并提供更准确结果的专用工具。为不同任务、行业或数据集定制LLM扩展了这些模型的能力,确保了它们在不断变化的数字环境中的相关性和价值。展望未来,LLM的持续探索和创新,加上精细的微调方法,有望推进更智能、更高效、更具情境意识的人工智能系统的发展。