第二章 HDFS
为什么需要分布式存储
数据量太大,单机存储能力有上限,需要靠数量来解决问题
数量的提升带来的是网络传输、磁盘读写、CPU、内存等各方面的综合提升。
分布式组合在一起可以达到1+1>2的效果
分布式的基础架构分析
大数据体系中,分布式的调度主要有2类架构模式:
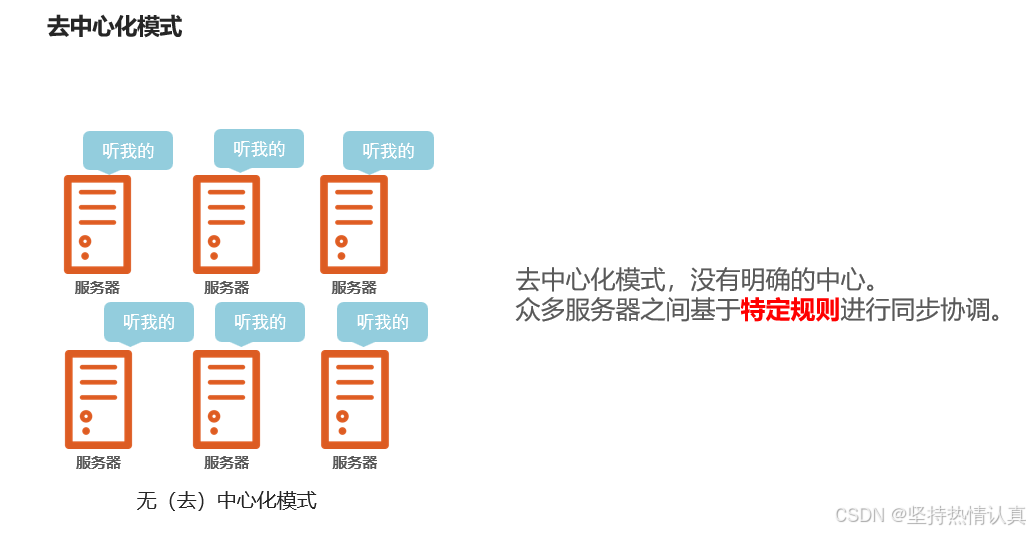
去中心化模式
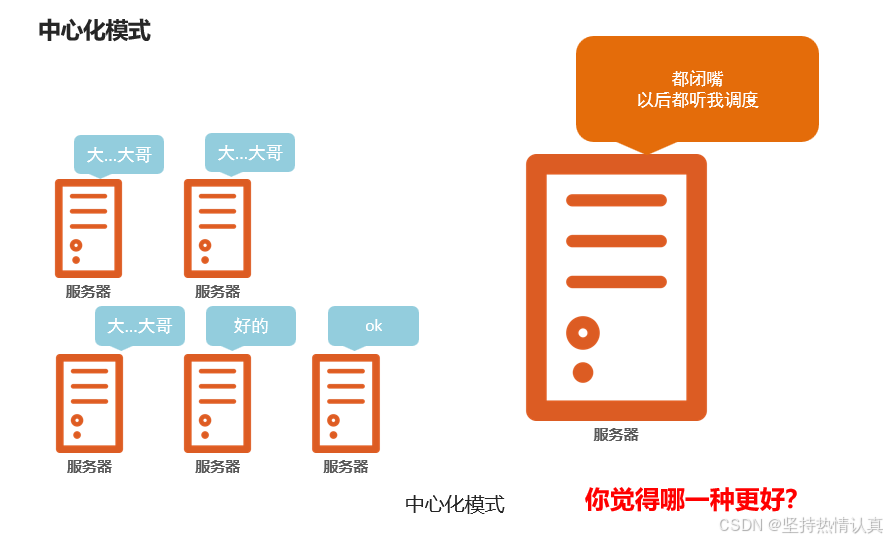
中心化模式
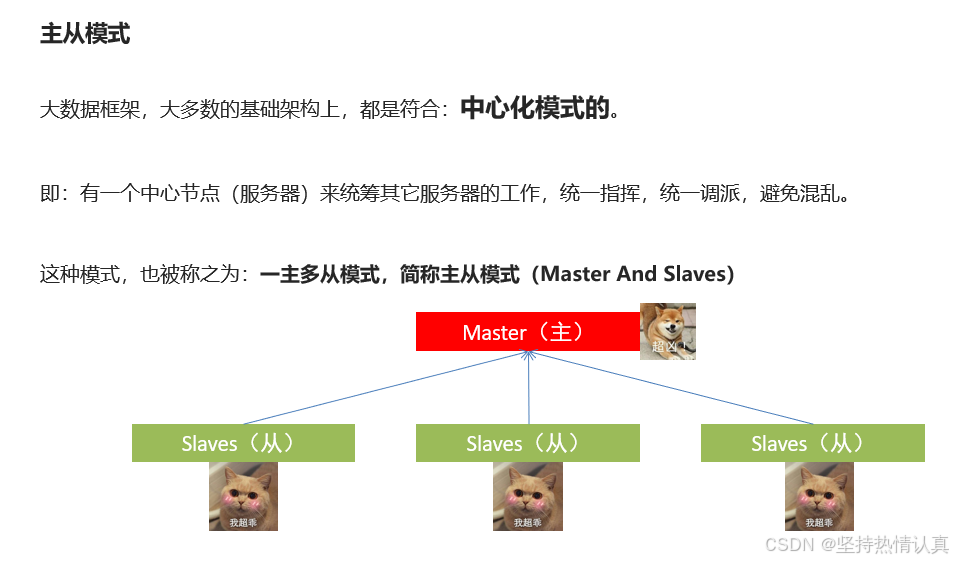
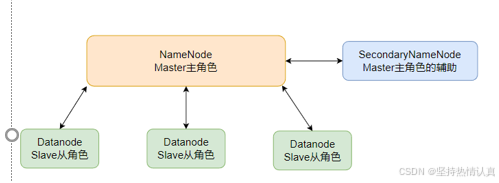
主从模式(Master-Slaves)就是中心化模式,表示有一个主节点来作为管理者,管理协调下属一批从节点工作。
Hadoop是哪种模式
主从模式(中心化模式)的架构
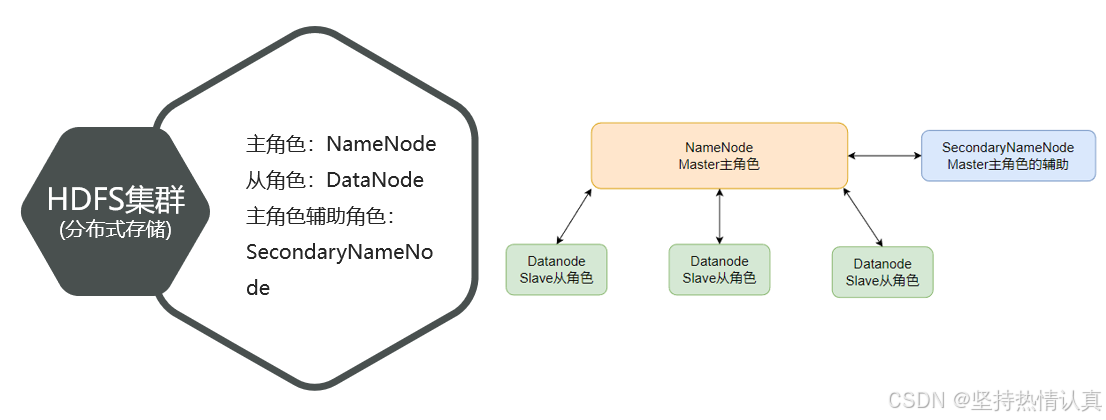
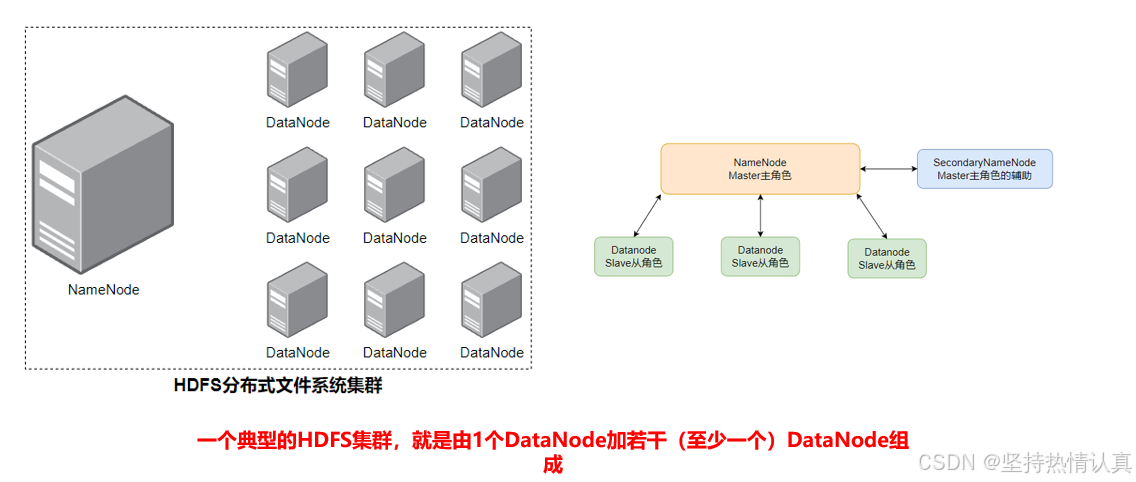
HDFS的基础架构

总结
- 什么是HDFS?
HDFS全称:Hadoop Distributed File System
是Hadoop三大组件(HDFS、MapReduce、YARN)之一
可在多台服务器上构建集群,提供分布式数据存储能力
- HDFS中的架构角色有哪些?
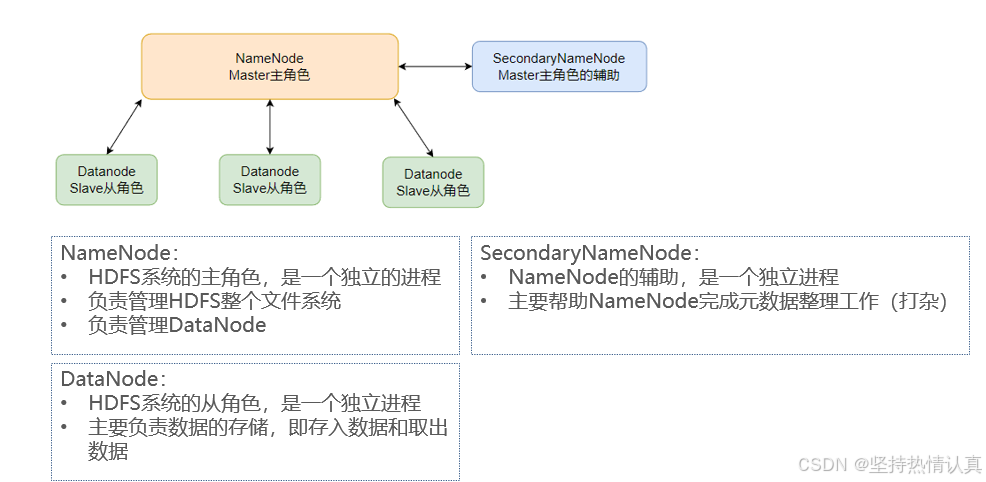
NameNode:主角色,管理HDFS集群和DataNode角色
DataNode:从角色,负责数据的存储
SecondaryNameNode:辅助角色,协助NameNode整理元数据
HDFS集群环境部署
VMWare虚拟机中环境部署
下载
网址(很慢需要魔法)
也可以使用清华的镜像网站
清华大学开源软件镜像站 | Tsinghua Open Source Mirror
部署

服务规划

在doop1里面进行如下工作
- 上传Hadoop安装包到doop1中
2.解压缩安装包到/export/server/中
tar -zxvf hadoop-3.4.0.tar.gz -C /export/server3.构建软链接
先进入到/export/server文件夹里面
cd /export/server在此文件夹里面构建软链接
ln -s /export/server/hadoop-3.4.0 hadoop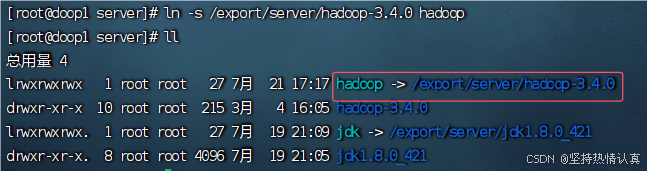
-
进入hadoop安装包内
cd hadoop

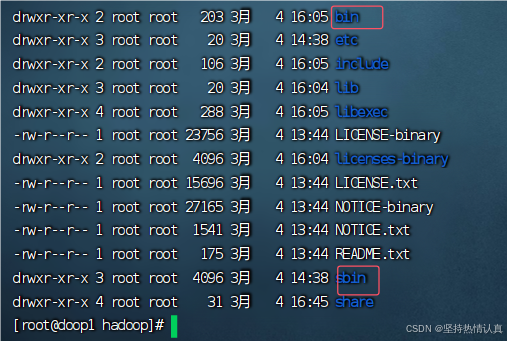
各个文件夹含义如下(标红三个重要)
•bin,存放Hadoop的各类程序(命令)
•etc,存放Hadoop的配置文件
•include,C语言的一些头文件
•lib,存放Linux系统的动态链接库(.so文件)
•libexec,存放配置Hadoop系统的脚本文件(.sh和.cmd)
•licenses-binary,存放许可证文件
•sbin,管理员程序(super bin)
share,存放二进制源码(Java jar包)
修改配置文件,应用自定义设置
配置HDFS集群,我们主要涉及到如下文件的修改:
•workers: 配置从节点(DataNode)有哪些
•hadoop-env.sh: 配置Hadoop的相关环境变量
•core-site.xml: Hadoop核心配置文件
•hdfs-site.xml: HDFS核心配置文件
这些文件均存在与$HADOOP_HOME/etc/hadoop文件夹中。
$HADOOP_HOME是后续我们要设置的环境变量,其指代Hadoop安装文件夹即/export/server/hadoop
配置workers文件(配置从节点(DataNode)有哪些)
进入到hadoop安装文件夹下 的配置文件夹etc下 的hadoop文件
cd etc/hadoop
编辑workers文件
vim workers删除内置的localhost(按两下dd)
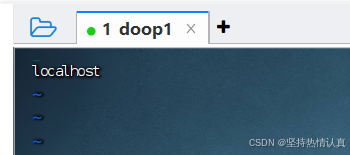
填入如下内容

配置hadoop-env.sh文件( 配置Hadoop的相关环境变量)
vim hadoop-env.sh
export JAVA_HOME=/export/server/jdk
export HADOOP_HOME=/export/server/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOOP_LOG_DIR=$HADOOP_HOME/logs配置core-site.xml文件
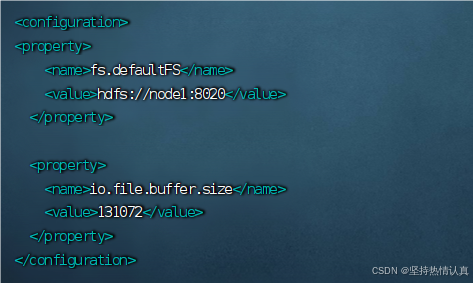
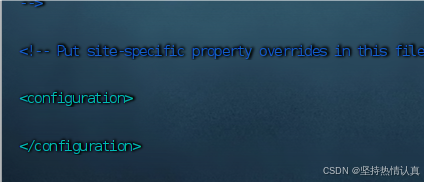
在文件中填入如下内容
<property>
<name>fs.defaultFS</name>
<value>hdfs://doop1:8020</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>用vim编辑器打开core-site.xml文件,shift+g到文件末尾可以看到两个configuration,把内容粘贴到中间
含义
•key:fs.defaultFS
•含义:HDFS文件系统的网络通讯路径
•值:hdfs://node1:8020
•协议为hdfs://
•namenode为node1
•namenode通讯端口为8020
•key:io.file.buffer.size
•含义:io操作文件缓冲区大小
值:131072 bit
•hdfs://node1:8020为整个HDFS内部的通讯地址,应用协议为hdfs://(Hadoop内置协议)
•表明DataNode将和node1的8020端口通讯,node1是NameNode所在机器
•此配置固定了node1必须启动NameNode进程
配置hdfs-site.xml文件
在文件中填入如下内容
<property>
<name>dfs.datanode.data.dir.perm</name>
<value>700</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/nn</value>
</property>
<property>
<name>dfs.namenode.hosts</name>
<value>doop1,doop2,doop3</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/dn</value>
</property>用vim编辑器打开hdfs-site.xml文件,shift+g到文件末尾可以看到两个configuration,把内容粘贴到中间
ctrl+f向下翻页
ctrl+b向上翻页
含义
•key:dfs.datanode.data.dir.perm
•含义:hdfs文件系统,默认创建的文件权限设置
•值:700,即:rwx------
•key:dfs.namenode.name.dir
•含义:NameNode元数据的存储位置
•值:/data/nn,在node1节点的/data/nn目录下
•
•key:dfs.namenode.hosts
•含义:NameNode允许哪几个节点的DataNode连接(即允许加入集群)
•值:node1、node2、node3,这三台服务器被授权
•key:dfs.blocksize
•含义:hdfs默认块大小
•值:268435456(256MB)
•
•key:dfs.namenode.handler.count
•含义:namenode处理的并发线程数
•值:100,以100个并行度处理文件系统的管理任务
•
•key:dfs.datanode.data.dir
•含义:从节点DataNode的数据存储目录
•值:/data/dn,即数据存放在node1、node2、node3,三台机器的/data/dn内
准备数据目录
 •namenode数据存放在node1的/data/nn
•namenode数据存放在node1的/data/nn
•datanode数据存放在node1、node2、node3的/data/dn
所以应该
•在node1节点:
•mkdir -p /data/nn
•mkdir -p /data/dn
•在node2和node3节点:
mkdir -p /data/dn
分发hadoop文件夹
从node1将hadoop安装文件夹远程复制到node2、node3
在node1执行如下命令
这里复制的时候把之前配置好的配置文件也都复制过来了,所以前面配置文件出错了,后面doop2和doop3的配置文件也会出错
cd /export/server
scp -r hadoop-3.4.0 doop2:`pwd`/
scp -r hadoop-3.4.0 doop3:`pwd`
•在node2执行,为hadoop配置软链接
在node2执行如下命令
ln -s /export/server/hadoop-3.4.0 hadoop
•在node3执行,为hadoop配置软链接
在node3执行如下命令
ln -s /export/server/hadoop-3.4.0 hadoop
配置环境变量
为了方便我们操作Hadoop,可以将Hadoop的一些脚本、程序配置到PATH中,方便后续使用。
在Hadoop文件夹中的bin、sbin两个文件夹内有许多的脚本和程序,现在来配置一下环境变量
- vim /etc/profile
在/etc/profile文件底部追加如下内容
export HADOOP_HOME=/export/server/hadoop
export PATH=PATH:HADOOP_HOME/bin:$HADOOP_HOME/sbin
- 在node2和node3配置同样的环境变量
授权hadoop用户
为了确保安全,hadoop系统不以root用户启动,我们以普通用户hadoop来启动整个Hadoop服务
所以,现在需要对文件权限进行授权。
把hadoop文件夹的所属用户和用户组都修改为Hadoop
以root身份,在三台服务器上均执行
chown -R hadoop:hadoop /data
chown -R hadoop:hadoop /export
-R:对文件夹内全部内容应用相同的用户和用户组
格式化整个文件系统
前期准备全部完成,现在对整个文件系统执行初始化
•格式化namenode
确保以hadoop用户执行
su - hadoop
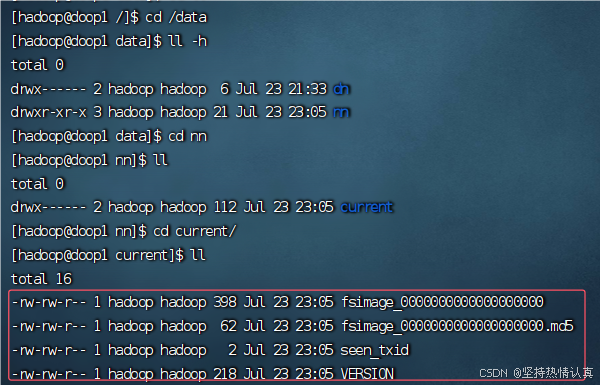
格式化namenode
hadoop namenode -format
成功了有数据了
•启动
一键启动hdfs集群
一键关闭hdfs集群
jps查看有没有启动成功

如果遇到命令未找到的错误,表明环境变量未配置好,可以以绝对路径执行
/export/server/hadoop/sbin/start-dfs.sh
/export/server/hadoop/sbin/stop-dfs.sh
查看 HDFS WEBUI
启动完成后,可以在浏览器打开:
http://doop1:9870,即可查看到hdfs文件系统的管理网页。
三个都亮了就OK了
如果没有亮的话
可以先把/data和/export/server/hadoop/logs文件夹删除了重新创建试一下

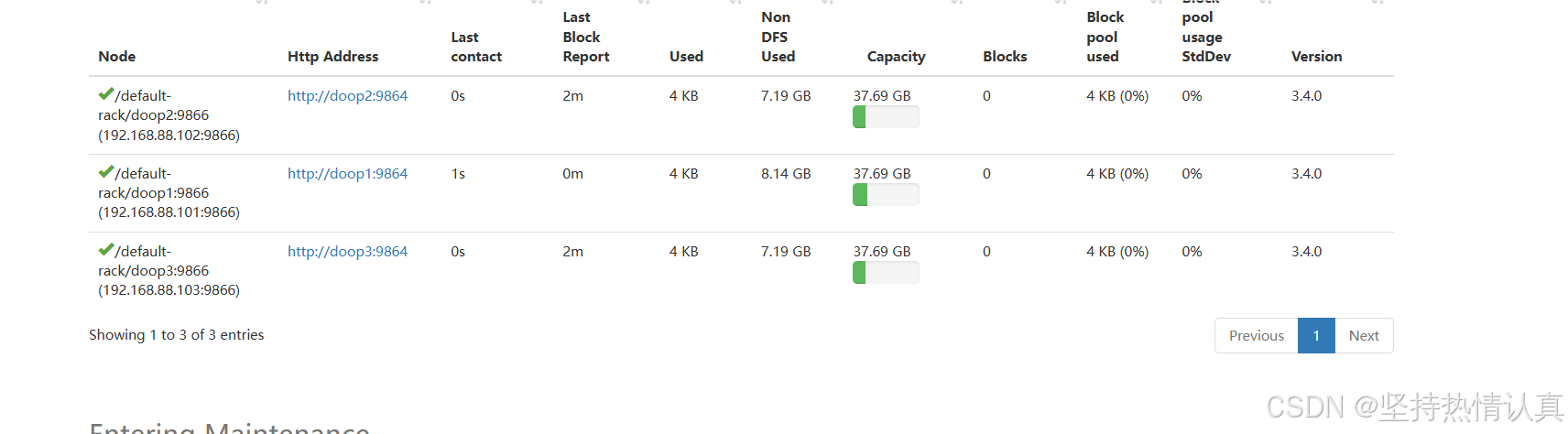
常见出错原因
start-dfs.sh脚本会:
在当前机器启动SecondaryNameNode,并根据core-site.xml文件的记录启动namenode
根据workers文件的记录,启动各个机器的datanode
1.是否遗漏了前置准备章节的相关操作?
ssh授权(允许hadoop用户免密登录doop1,doop2,doop3)
2.是否遗漏的将文件夹(Hadoop安装文件夹、/data数据文件夹)chown授权到hadoop用户这一操作
以hadoop用户启动集群的时候会报错文件无法写入,没有权限(permission denied),也有可能看起来正常,这时候可以去日志文件里面找到错误
解决办法
把日志文件夹logs和data数据文件里面的内容都清空,然后重新授权
rm rf /export/server/hadoop/logs/*
rm rf /data/nn/*; rm rf /data/dn/*
chown -R hadoop:hadoop /data
chown -R hadoop:hadoop /export
3.是否遗忘了格式化hadoop这一步(hadoopnamenode -format)
未格式化会导致doop1的namenode无法正常启动
4.是否是以root用户格式化的hadoop
z在写入文件内容的时候,又会把文件权限全部重新赋给root,以hadoop启动的时候就又没有权限了
5.是否以root启动过hadoop,后续以hadoop用户启动出错
只要用root操作过一个,相关的目录权限又归为root了,以hadoop执行的时候就会出错
6.是否确认workers文件内,配置了node1、node2、node3三个节点
datanode无法正常启动
7.是否在/etc/profile内配置了HADOOP_HOME环境变量,并将HADOOP_HOME/bin和HADOOP_HOME/sbin加入PATH变量
命令会找不到
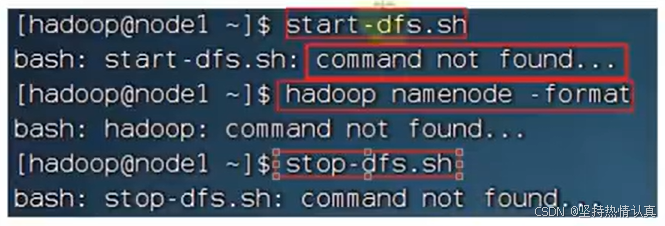
没有配置好环境变量,导致
/export/server/hadoop/bin/hadoop
/export/server/hadoop/sbin/start-dfs.sh &/export/server/hadoop/sbin/stop-dfs.sh
这些命令或脚本无法直接执行
8.是否遗忘了软链接,但环境变量的配置的HADOOP_HOME确是:/export/server/hadoop
hadoop这个文件根本不存在,什么也找不到
9.是否确认配置文件内容的准确(一个字符都不错),并确保三台机器的配置文件均0K

云服务器中部署
HDFS集群启停命令
一键启停
Hadoop HDFS组件内置了HDFS集群的一键启停脚本。
•$HADOOP_HOME/sbin/start-dfs.sh,一键启动HDFS集群
执行原理:
•在执行此脚本的机器上,启动SecondaryNameNode
•读取core-site.xml内容(fs.defaultFS项),确认NameNode所在机器,启动NameNode
•读取workers内容,确认DataNode所在机器,启动全部DataNode
•$HADOOP_HOME/sbin/stop-dfs.sh,一键关闭HDFS集群
执行原理:
•在执行此脚本的机器上,关闭SecondaryNameNode
•读取core-site.xml内容(fs.defaultFS项),确认NameNode所在机器,关闭NameNode
•读取workers内容,确认DataNode所在机器,关闭全部NameNode
单进程启停
除了一键启停外,也可以单独控制进程的启停。
- $HADOOP_HOME/sbin/hadoop-daemon.sh,此脚本可以单独控制所在机器的进程的启停
用法:hadoop-daemon.sh (start|status|stop) (namenode|secondarynamenode|datanode)
- $HADOOP_HOME/bin/hdfs,此程序也可以用以单独控制所在机器的进程的启停
用法:hdfs --daemon (start|status|stop) (namenode|secondarynamenode|datanode)
文件系统的操作命令
HDFS 文件系统基本信息
HDFS作为分布式存储的文件系统,有其对数据的路径表达方式。
•HDFS同Linux系统一样,均是以/作为根目录的组织形式
如何区分呢?
•Linux:file:///
•HDFS:hdfs://namenode:port/
如上路径:
•Linux:file:///usr/local/hello.txt
•HDFS:hdfs://node1:8020/usr/local/hello.txt
协议头file:/// 或 hdfs://node1:8020/可以省略
•需要提供Linux路径的参数,会自动识别为file://
•需要提供HDFS路径的参数,会自动识别为hdfs://
除非你明确需要写或不写会有BUG,否则一般不用写协议头
两套命令体系
关于HDFS文件系统的操作命令,Hadoop提供了2套命令体系
两者在文件系统操作上,用法完全一致,用哪个都可以
某些特殊操作需要选择hadoop命令或hdfs命令,讲到的时候具体分析
•hadoop命令(老版本用法),用法:hadoop fs generic options
•hdfs命令(新版本用法),用法:hdfs dfs generic options
创建文件夹
•hadoop fs -mkdir -p <path> ...
•hdfs dfs -mkdir -p <path> ...
path 为待创建的目录
-p选项的行为与Linux mkdir -p一致,它会沿着路径创建父目录。
例子
hadoop fs -mkdir -p /itcast/bigdata
hdfs fs -mkdir -p /itheima/hadoop
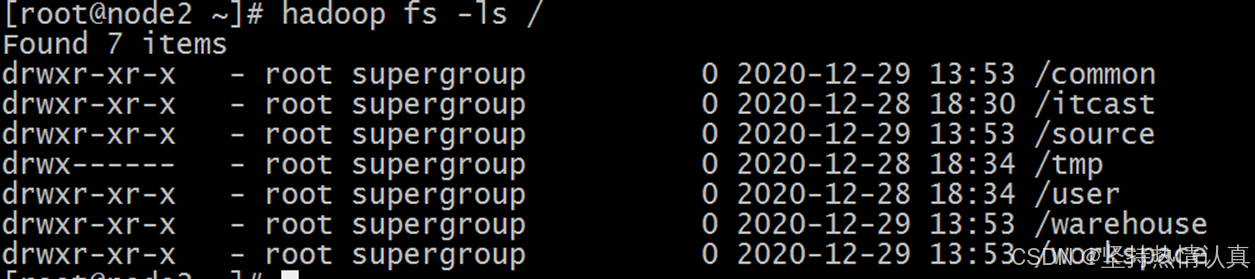
查看指定目录下的内容
hadoop fs -ls -h -R \
•hdfs dfs -ls -h -R \
path 指定目录路径
-h 人性化显示文件size
-R 递归查看指定目录及其子目录
例子
上传文件到HDFS指定目录下(上传Linux文件到HDFS)
hadoop fs -put -f -p <localsrc> ... <dst>
hdfs dfs -put -f -p <localsrc> ... <dst>
-f 覆盖目标文件(已存在下)
-p 保留访问和修改时间,所有权和权限。
localsrc 本地文件系统(客户端所在机器(Linux))
dst 目标文件系统(HDFS)
例子
hadoop fs -put words.txt /itcast
hdfs dfs -put file:///etc/profile hdfs://node1:8020/itcast
查看HDFS文件内容
hadoop fs -cat <src> ...
hdfs dfs -cat <src> ...
读取指定文件全部内容,显示在标准输出控制台。
例子
hadoop fs -cat /itcast/words.txt
hdfs dfs -cat /itcast/profile
读取大文件可以使用管道符配合more(Linux中对内容进行翻页的命令,按下空格进行翻页)
hadoop fs -cat <src> | more
hdfs dfs -cat <src> | more
下载HDFS文件(下载HDFS文件到Linux)
hadoop fs -get -f -p <src> ... <localdst>
hdfs dfs -get -f -p <src> ... <localdst>
下载文件到本地文件系统指定目录,localdst必须是目录
-f 覆盖目标文件(已存在下)
-p 保留访问和修改时间,所有权和权限。
例子
rm -rf *删除当前目录的全部内容
上传/test.txt文件到当前目录, .代表当前目录
hdfs dfs -get /test.txt .
拷贝HDFS文件
hadoop fs -cp -f <src> ... <dst>
hdfs dfs -cp -f <src> ... <dst>
-f 覆盖目标文件(已存在下)
<src>:复制的文件的位置
<dst>:要复制到的位置
这两个位置都是HDFS的位置
例子
把/test.txt文件复制到/home/下
hdfs dfs -cp /test.txt /home/
cp命令还有改名的功能
把/test.txt文件复制到/home目录下,并且改名为abc.txt
hdfs dfs -cp /test.txt /home/abc.txt
追加数据到HDFS文件中
hdfs文件只支持追加或者删除,不像Linux可以使用编辑器修改
hadoop fs -appendToFile <localsrc> ... <dst>
hdfs dfs -appendToFile <localsrc> ... <dst>
将所有给定本地文件的内容追加到给定dst文件。
dst如果文件不存在,将创建该文件。
如果<localSrc>为-,则输入为从标准输入中读取
例子
把2.txt和3.txt的内容追加到/1.txt中
hadoop fs -appendToFile 2.txt 3.txt /1.txt
HDFS数据移动操作
hadoop fs -mv <src> ... <dst>
hdfs dfs -mv <src> ... <dst>
移动文件到指定文件夹下
可以使用该命令移动数据,重命名文件的名称
用来的目录下文件就不见了,文件到了新的目录下,同时具有改名的效果
例子
具有改名的效果
把/tets2.txt移动到目录/klj下,并且改名为abc.txt
hadoop fs mv /test2.txt /klj/abc .txt
HDFS数据删除操作
hadoop fs -rm -r -skipTrash URI URI ...
hdfs dfs -rm -r -skipTrash URI URI ...
删除指定路径的文件或文件夹
-r:用来删除文件夹
-skipTrash 跳过回收站,直接删除
配置回收站
回收站功能默认关闭,如果要开启需要在core-site.xml内配置:
#表示文件在回收站的保留时间为1440分钟,即一天
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
#表示每120分钟检查一次回收站里面有没有保留期限到期的文件
<property>
<name>fs.trash.checkpoint.interval</name>
<value>120</value>
</property>无需重启集群,在哪个机器配置的,在哪个机器执行命令就生效。
回收站默认位置在:/user/用户名(hadoop)/.Trash
这个时候删除文件就会提示,文件被移动到了回收站的默认位置 /usr/hadoop/.Trash/Current

在回收站里面可以找到

Hadoop官方文档(查找其他命令)
地址
Apache Hadoop 3.3.4 -- Overview
HDFS WEB浏览
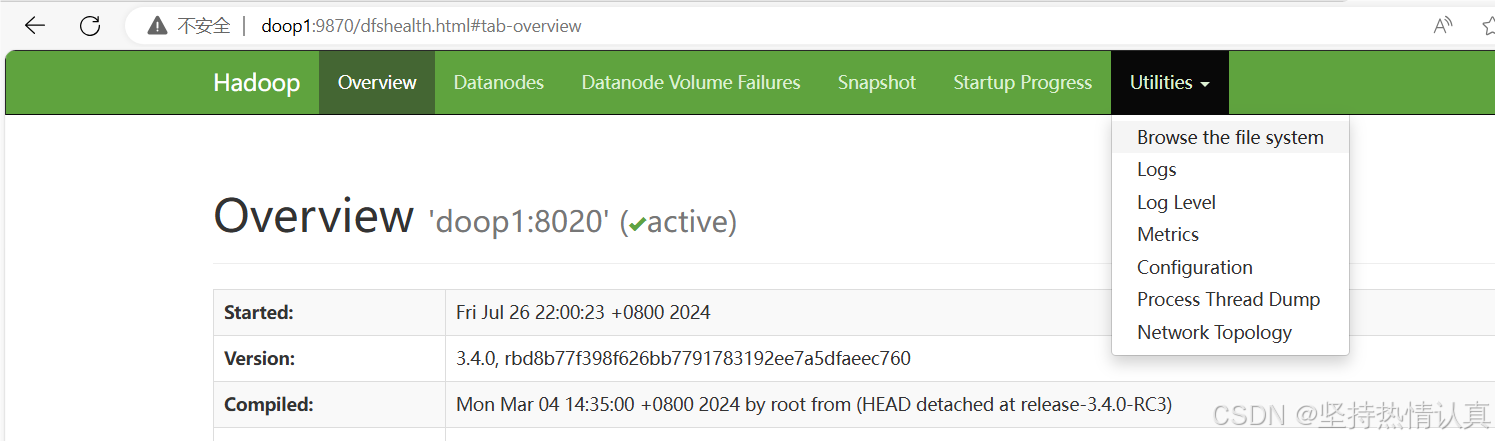
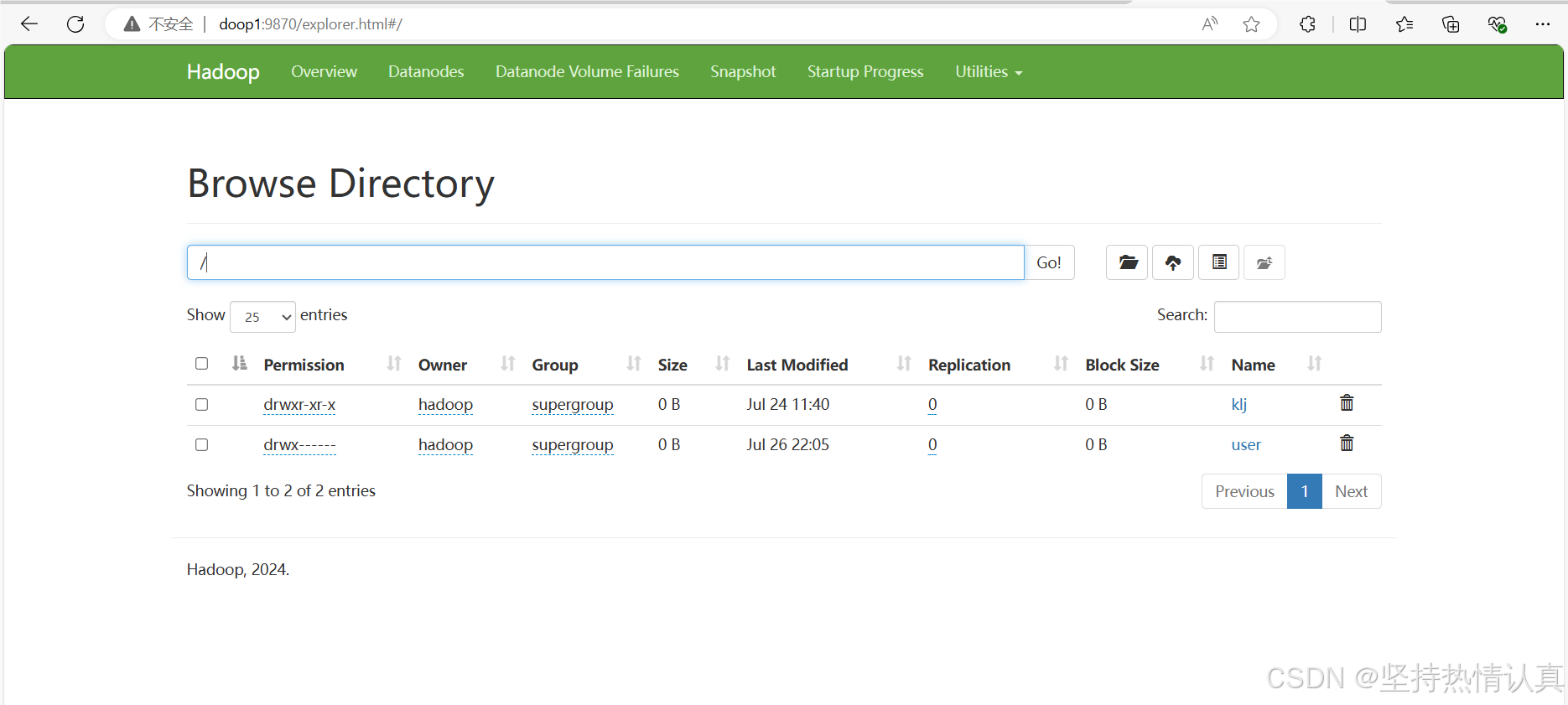
使用WEB浏览操作文件系统,一般会遇到权限问题

这是因为WEB浏览器中是以匿名用户(dr.who)登陆的,其只有只读权限,多数操作是做不了的。
如果需要以特权用户在浏览器中进行操作,需要配置如下内容到core-site.xml并重启集群
<property>
<name>hadoop.http.staticuser.user</name>
<value>hadoop</value>
</property>但是,不推荐这样做
•HDFS WEBUI,只读权限挺好的,简单浏览即可
•如果给与高权限,会有很大的安全问题,造成数据泄露或丢失
HDFS Shell命令权限不足问题解决
Permission denied: user=root, access=WRiTE, inode="/":hadoop:supergroup:drwxr-xr-x
这种类似的问题,是因为操作没有权限

HDFS中,也是有权限控制的,其控制逻辑和Linux文件系统的完全一致。
但是不同的是,Superuser不同(超级用户不同)
Linux的超级用户是root
HDFS文件系统的超级用户:是启动namenode的用户(也就是hadoop用户)
所以在HDFS中,要以hadoop用户登录才有权限,在Linux中权限比hadoop高的root登录也是没有权限的(强龙压不过地头蛇)
修改权限
在HDFS中,可以使用和Linux一样的授权语句,即:chown和chmod
修改所属用户和组:
hadoop fs -chown -R root:root /xxx.txt
hdf$ dfsf-chown -R root:root /xxx.txt
修改权限
hadoop fs -chmod -R 777 /xxx.txt
hdfs dfs -chmod -R 777 /xxx.txt
HDFS客户端-- Jetbrians产品插件
在Jetbrains的产品中,均可以安装插件,其中:Big Data Tools插件可以帮助我们方便的操作HDFS,比如
•IntelliJ IDEA(Java IDE)
•PyCharm(Python IDE)
•DataGrip(SQL IDE)
均可以支持Bigdata Tool插件。
如果有使用以上几款IDE,就可以安装此插件进行HDFS操作。
下载安装
在pycharm,datagrip和idea中任何一款中都可以安装使用
配置Windows
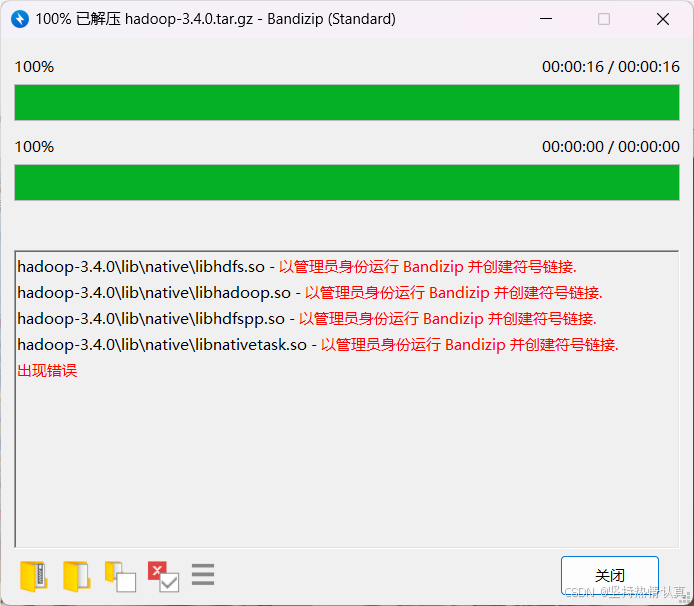
1.解压hadoop安装包到windows某一个位置(如E盘)
出现错误不用担心,是因为里面存在一些Linux的软链接,Windows不支持,但是不影响使用
2.设置HADOOP_HOME环境变量指向刚刚解压hadoop的位置
3.下载
hadoop.dll
winutils/hadoop-3.0.0/bin/hadoop.dll at master · steveloughran/winutils · GitHub
winutils.exe
winutils/hadoop-3.0.0/bin/winutils.exe at master · steveloughran/winutils · GitHub
4.将hadoop.dll和winutils.exe放入HADOOP_HOME/bin中
配置Big Data Tools插件
注意要启动集群以后再进行后面的操作
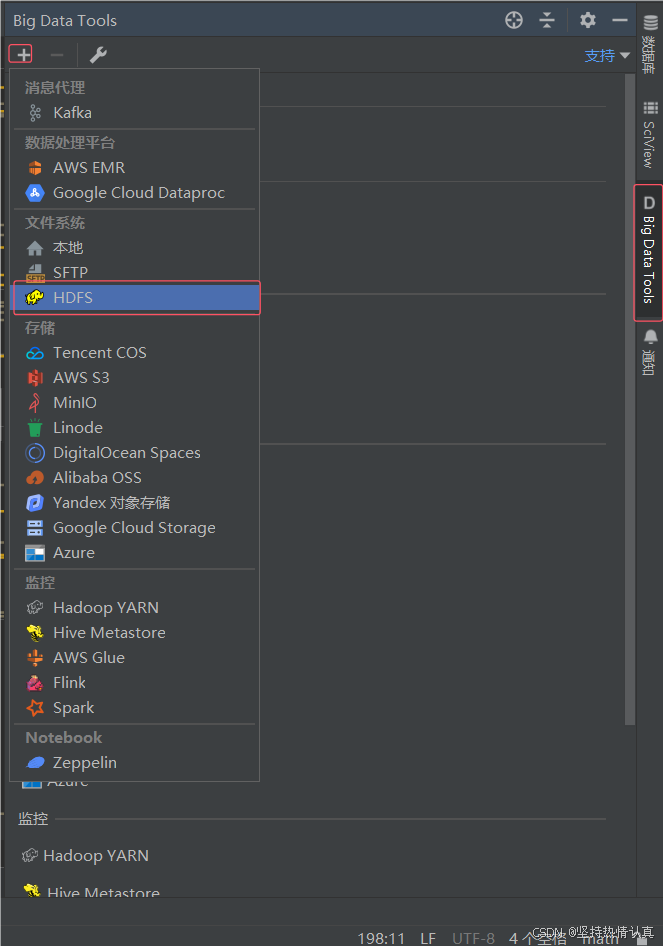
测试连接失败报错环境变量可能是环境变量没有生效,可以重启电脑再次尝试
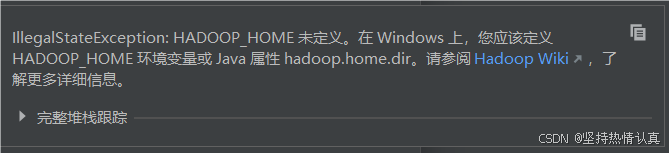
测试连接成功就可以了
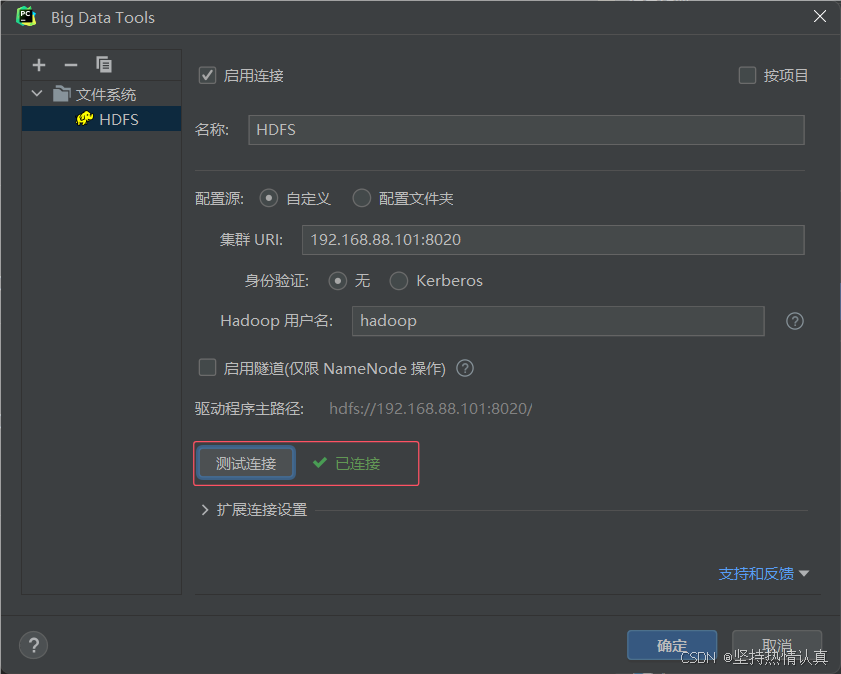
这个时候HDFS的文件目录就以图形化的形式展现了,可以上传和下载文件
HDFS客户端--NFS
HDFS提供了基于NFS(Network File System)的插件,可以对外提供NFS网关,供其它系统挂载使用。
NFS 网关支持 NFSv3,并允许将 HDFS 作为客户机本地文件系统的一部分挂载,现在支持:
•上传、下载、删除、追加内容
配置NFS
配置HDFS需要配置如下内容:
core-site.xml,新增配置项 以及 hdfs-site.xml,新增配置项
开启portmap、nfs3两个新进程
在doop1进行如下操作
-
在core-site.xml 内新增如下两项
hadoop.proxyuser.hadoop.groups * hadoop.proxyuser.hadoop.hosts *
•项目: hadoop.proxyuser.hadoop.groups 值:*
允许hadoop用户代理任何其它用户组
•项目:hadoop.proxyuser.hadoop.hosts 值:*
允许代理任意服务器的请求
-
在hdfs-site.xml中新增如下项
nfs.superuser hadoop nfs.dump.dir /tmp/.hdfs-nfs nfs.exports.allowed.hosts 192.168.88.1 rw
•nfs.suerpser:NFS操作HDFS系统,所使用的超级用户(hdfs的启动用户为超级用户)
•nfs.dump.dir:NFS接收数据上传时使用的临时目录
•nfs.exports.allowed.hosts:NFS允许连接的客户端IP和权限,rw表示允许读写权限,IP整体或部分可以以*代替
看以看到上面配置的IP是VMnet8的IP地址
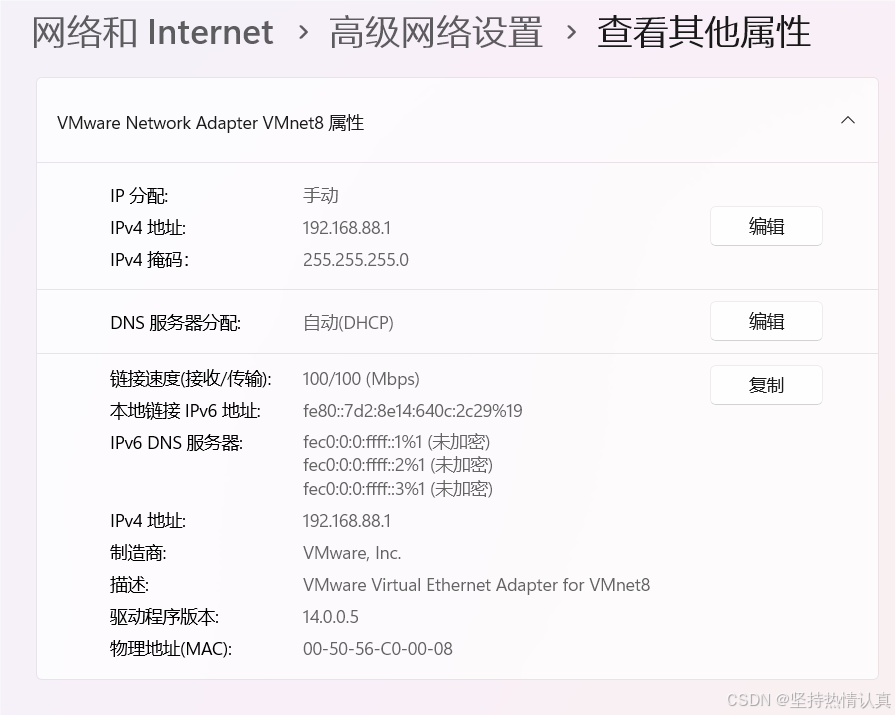
我们其实不是直连虚拟机的,而是通过VMnet8中转了一下
-
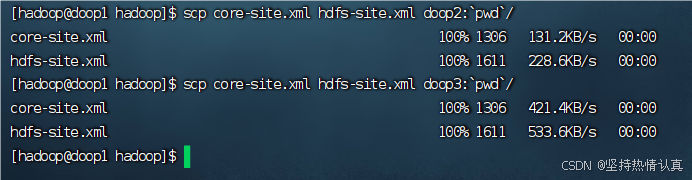
将配置好的core-site.xml和hdfs-site.xml分发到node2和node3
scp core-site.xml hdfs-site.xml doop2:
pwd/scp core-site.xml hdfs-site.xml doop3:
pwd/
-
重启Hadoop HDFS集群(先stop-dfs.sh,后start-dfs.sh)
-
停止系统的NFS相关进程(使用root用户,hadoop是普通用户做不了)
a. systemctl stop nfs; systemctl disable nfs 关闭系统nfs并关闭其开机自启
b. yum remove -y rpcbind 卸载系统自带rpcbind
-
启动portmap(HDFS自带的rpcbind功能)(必须以root执行):hdfs --daemon start portmap
-
启动nfs(HDFS自带的nfs功能)(必须以hadoop用户执行):hdfs --daemon start nfs3
检查NFS是否正常
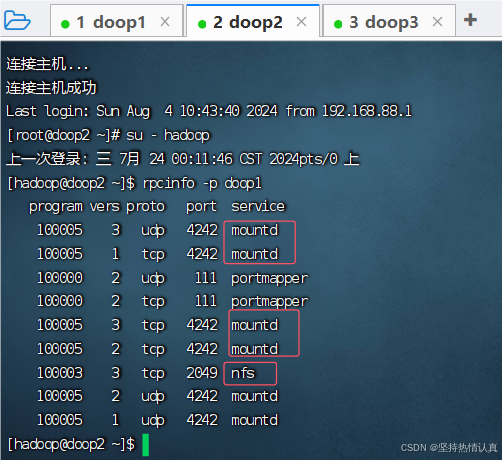
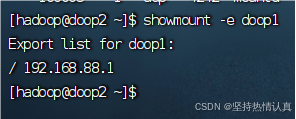
以下操作在doop2或doop3执行(因为doop1卸载了rpcbind,缺少了必要的2个命令)
执行:rpcinfo -p doop1,有mountd和nfs出现
执行:showmount -e doop1,可以看到 / 192.168.88.1
在Windows挂在HDFS文件系统
只有专业版的Windows系统才有,家庭版的没有
后面再学
第二章-12-可选HDFS客户端-NFS挂载到Windows本地_哔哩哔哩_bilibili
HDFS存储原理
问题1:文件大小不一,不利于统一管理
解决:设定统一的管理单位, block 块
Block块,HDFS最小存储单位
每个256MB(可以修改)
问题2: 如果丢失或损坏了某个 Block 块呢?
通过多个副本(备份)解决
每个 Block 块都有 2 个(可修改)备份
每个块都有 2 个备份在 其它服务器 上 (不放在同一个服务器上,服务器坏了什么用也没有)


指定上传文件的副本数和查看副本命令
在前面我们了解了HDFS文件系统的数据安全,是依靠多个副本来确保的。
如何设置默认文件上传到HDFS中拥有的副本数量呢?可以在hdfs-site.xml中配置如下属性:
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
这个属性默认是3,一般情况下,我们无需主动配置(除非需要设置非3的数值)
如果需要自定义这个属性,请修改每一台服务器的hdfs-site.xml文件,并设置此属性
•除了配置文件外,我们还可以在上传文件的时候,临时决定被上传文件以多少个副本存储。
hadoop fs -D dfs.replication=2 -put test.txt /tmp/
-D:表示自己指定一些配置项,后面的dfs.replication=2就是自己指定的配置项
如上命令,就可以在上传test.txt的时候,临时设置其副本数为2
•对于已经存在HDFS的文件,修改dfs.replication属性不会生效,如果要修改已存在文件可以通过命令
hadoop fs -setrep -R 2 path
如上命令,指定path的内容将会被修改为2个副本存储。
-R选项可选,使用-R表示对子目录也生效。
同时,我们可以使用hdfs提供的fsck命令来检查文件的副本数
hdfs fsck path -files \[-blocks \[-locations]]
fsck可以检查指定路径是否正常
•-files可以列出路径内的文件状态
•-files -blocks 输出文件块报告(有几个块,多少副本)
•-files -blocks -locations 输出每一个block的详情


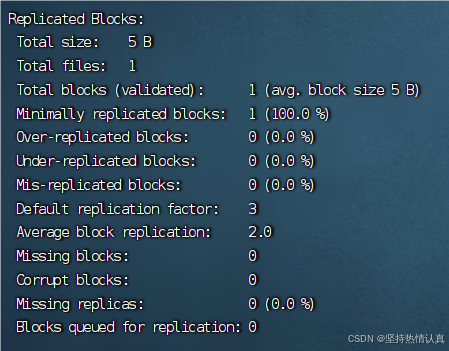
对于块(block),hdfs默认设置为256MB一个,也就是1GB文件会被划分为4个block存储。
块大小可以通过参数:
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
<description>设置HDFS块大小,单位是b</description>
</property>
如上,设置为256MB
NameNode元数据
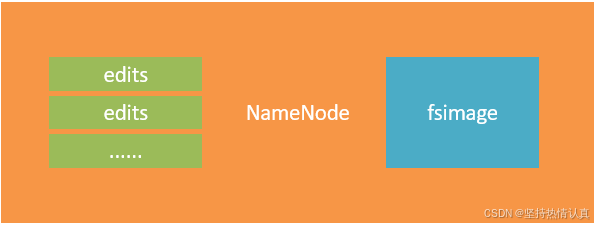
**edits文件(**记录每次操作)
在hdfs中,文件是被划分了一堆堆的block块,那如果文件很大、以及文件很多,Hadoop是如何记录和整理文件和block块的关系呢?
答案就在于NameNode,
NameNode基于一批edits和一个fsimage文件的配合
完成整个文件系统的管理和维护


问题在于,当用户想要查看某文件内容
如:/tmp/data/test.txt
就需要在全部的edits中搜索
(还需要按顺序从头到尾,避免后期改名或删除)
效率非常低
需要合并edits文件,得到最终的结果,只查看最终的状态
**FSImage文件(**记录某一个时间节点前的当前文件系统全部文件的状态和信息)
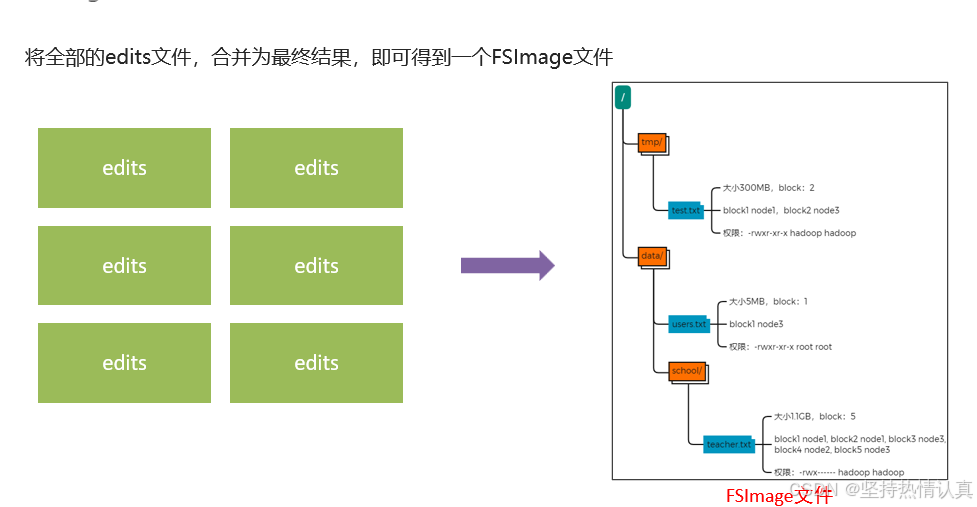
NameNode基于edits和FSImage的配合,完成整个文件系统文件的管理。
-
每次对HDFS的操作,均被edits文件记录
-
edits达到大小上线后,开启新的edits记录
-
定期进行edits的合并操作
•如当前没有fsimage文件, 将全部edits合并为第一个fsimage
•如当前已存在fsimage文件,将全部edits和已存在的fsimage进行合并,形成新的fsimage
元数据合并控制参数
对于元数据的合并,是一个定时过程,基于:
•dfs.namenode.checkpoint.period,默认3600(秒)即1小时
•dfs.namenode.checkpoint.txns,默认1000000,即100W次事务
只要有一个达到条件就执行。
检查是否达到条件,默认60秒检查一次,基于:
•dfs.namenode.checkpoint.check.period,默认60(秒),来决定
SecondaryNameNode 的作用
SecondaryNameNode会通过http从NameNode拉取数据(edits和fsimage)
然后合并完成后提供给NameNode使用。
HDFS数据的读写流程
写入流程
-
客户端向NameNode发起请求
-
NameNode审核权限、剩余空间后,满足条件允许写入,并告知客户端写入的DataNode地址
-
客户端向指定的DataNode发送数据包
-
被写入数据的DataNode同时完成数据副本的复制工作,将其接收的数据分发给其它DataNode
-
如上图,DataNode1复制给DataNode2,然后基于DataNode2复制给Datanode3和DataNode4
-
写入完成客户端通知NameNode,NameNode做元数据记录工作
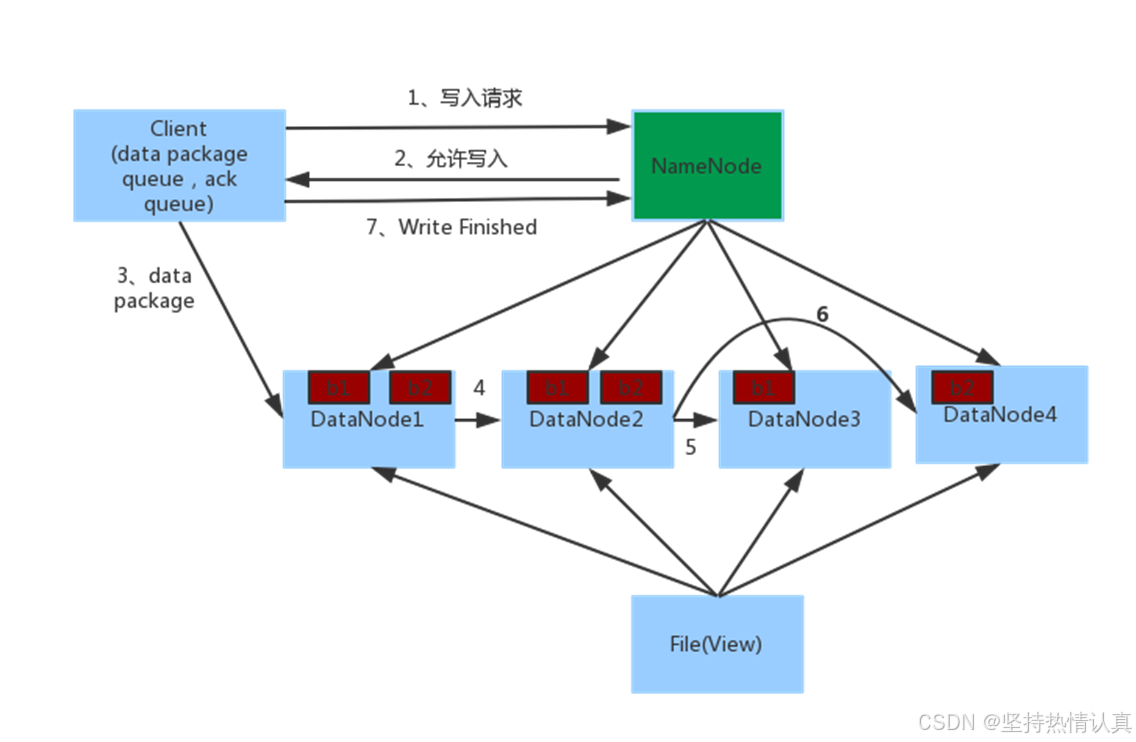
关键信息点:
•NameNode不负责数据写入,只负责元数据记录和权限审批
•客户端直接向1台DataNode写数据,这个DataNode一般是离客户端最近(网络距离)的那一个
•数据块副本的复制工作,由DataNode之间自行完成(构建一个PipLine,按顺序复制分发,如图1给2, 2给3和4)
数据读取流程
1、客户端向NameNode申请读取某文件
2、 NameNode判断客户端权限等细节后,允许读取,并返回此文件的block列表
3、客户端拿到block列表后自行寻找DataNode读取即可
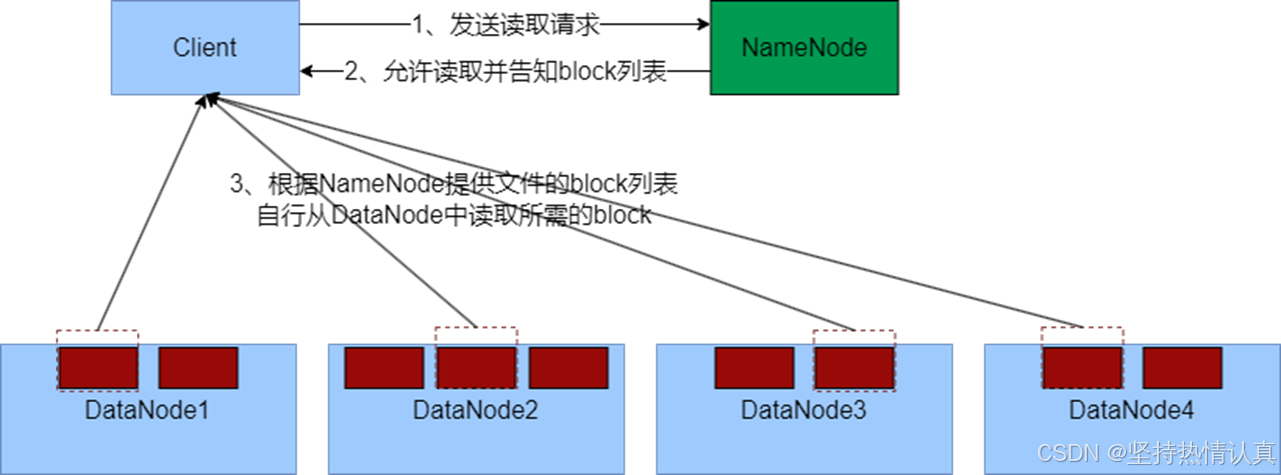
关键点:
1、数据同样不通过NameNode提供
2、NameNode提供的block列表,会基于网络距离计算尽量提供离客户端最近的
这是因为1个block有3份,会尽量找离客户端最近的那一份让其读取
1、对于客户端读取HDFS数据的流程中,一定要知道
不论读、还是写,NameNode都不经手数据,均是客户端和DataNode直接通讯
不然对NameNode压力太大
2、写入和读取的流程,简单来说就是:
•NameNode做授权判断(是否能写、是否能读)
•客户端直连DataNode进行写入(由DataNode自己完成副本复制)、客户端直连DataNode进行block读取
•写入,客户端会被分配找离自己最近的DataNode写数据
•读取,客户端拿到的block列表,会是网络距离最近的一份
3、网络距离
•最近的距离就是在同一台机器
•其次就是同一个局域网(交换机)
•再其次就是跨越交换机
•再其次就是跨越数据中心
HDFS内置网络距离计算算法,可以通过IP地址、路由表来推断网络距离