本笔记使用的Vitis HLS版本为2022.2,在windows11下运行,仿真part为xcku15p_CIV-ffva1156-2LV-e,主要根据教程:跟Xilinx SAE 学HLS系列视频讲座-高亚军进行学习
从这一篇开始正式进入HLS对C++代码的优化笔记
学习笔记:《FPGA学习笔记》索引
FPGA学习笔记#1 HLS简介及相关概念
FPGA学习笔记#2 基本组件------CLB、SLICE、LUT、MUX、进位链、DRAM、存储单元、BRAM
FPGA学习笔记#3 Vitis HLS编程规范、数据类型、基本运算
FPGA学习笔记#4 Vitis HLS 入门的第一个工程
FPGA学习笔记#5 Vitis HLS For循环的优化(1)
FPGA学习笔记#6 Vitis HLS For循环的优化(2)
FPGA学习笔记#7 Vitis HLS 数组优化和函数优化
FPGA学习笔记#8 Vitis HLS优化总结和案例程序的优化
目录
- 1.循环优化中的基本参数
- [2.PIPELINE & UNROLL](#2.PIPELINE & UNROLL)
- 2.1.PIPELINE
- 2.2.UNROLL
- 3.LOOP_MERGE
1.循环优化中的基本参数
以如下程序为例,top.h:
cpp
#include <ap_int.h>
#define N 3
#define XW 8
#define BW 16
typedef ap_int<XW> dx_t;
typedef ap_int<BW> db_t;
typedef ap_int<BW+1> do_t;
void func(dx_t xin[N], dx_t a, db_t b, db_t c, do_t yo[N]);top.cpp:
cpp
#include "top.h"
void func(dx_t xin[N], dx_t a, db_t b, db_t c, do_t yo[N])
{
int i = 0;
loop:
for (i = 0; i < N; i++)
{
yo[i] = a * xin[i] + b + c;
}
}从本篇开始,top函数更改为通用的func,这样只改其中的逻辑和参数就行,记得第一次运行要在设置中更改Top函数,更改方式请参考上一篇笔记。
从程序代码出发,对loop标签下的for循环进行分析,可以得到其全过程时序如下,其中每个属性的含义:
1 clock cycle:一个基本操作需要一个时钟周期
Loop Trip Count:循环次数,N==3,所以为3
Loop Iteration Latency:一轮循环执行所需时间
Loop Iteration Interval(Loop II):两轮循环相隔的时间,这里和循环执行时间相等的原因:
1.HLS识别到循环次数为常数,省略了对变量i的操作,如果N是变量则这个时间会相应增加。
2.在编程中并未让其流水线操作或展开(UNROLL),否则这个时间会减少或直接为0。
Loop Latency:循环总执行时间,等于Loop Iteration Latency * Loop Trip Count
Function Latency:函数的执行时间,这里应该是Rd a,b,c,这三个变量传进来之后不再改变,读一次就行
Function Initial Interval(II):两轮函数的执行间隔,这里应该放在Rd之前,函数放在一个循环内时:
1.如果函数执行结束到下一轮该函数执行之间有操作的话,这一时间会增加
2.如果对循环和函数进行优化,函数可能并发执行(多个函数实例,间隔为0)、流水线执行(间隔减小)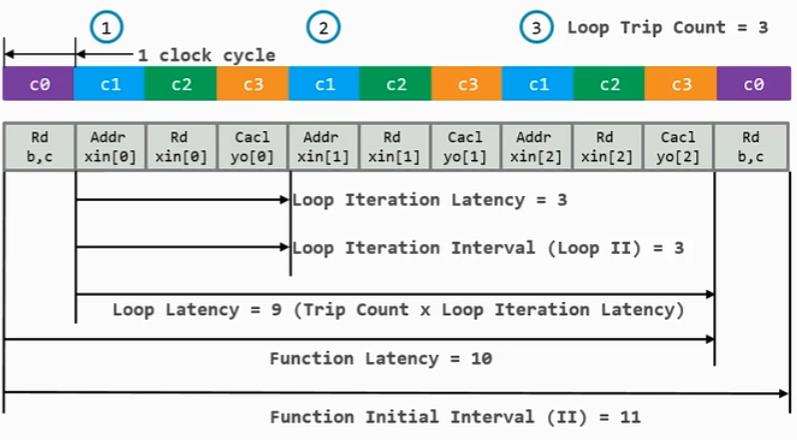
2.PIPELINE & UNROLL
2.1.PIPELINE
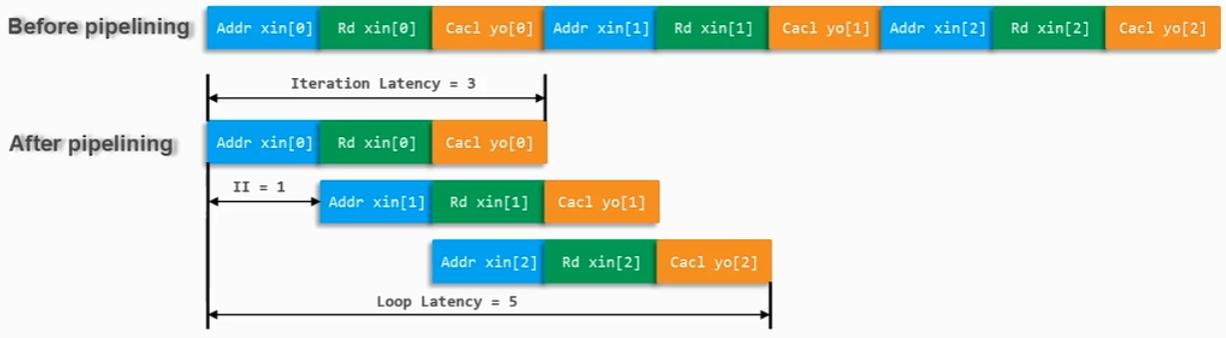
For循环最常见也是最常用的优化就是PIPELINE,可以右键Directive中循环的标签进行添加(所有循环都应添加标签,便于进行优化和DEBUG),也可以在循环的左大括号下一行添加#pragma HLS PIPELINE:
cpp
loop:
for (int i = 0; i < N; i++)
{
#pragma HLS PIPELINE
/* 函数体 */
}添加PIPELINE后,第一节提到的Loop Iteration Interval (Loop II)循环迭代间隔就变为了1,因为3次循环间没有数据依赖,所以间隔为一个cycle,循环耗时从9减少到5:
2.2.UNROLL
UNROLL会将循环全部展开,如循环次数为3,则将原本1组电路进行3次运算更改为3组电路分别进行1次计算,通过消耗N倍资源换取N倍效率,其添加方法与PIPELINE相同:
cpp
#pragma HLS UNROLL
有时,循环的次数实在过多,全部展开会用光板子的资源,那么我们可以将其部分展开,使用UNROLL的参数factor进行配置,如factor=3时,会将循环展开为3组电路,消耗3倍资源换取3倍效率:
cpp
// factor为复制份数(消耗资源倍数)
#pragma HLS UNROLL factor=3我们之前提到过,将C++原本的数据类型换为HLS的任意精度数据类型可以增加资源利用率,那么我们复制了这么多循环,for()中i的类型是否要考虑更换呢?事实上,vitis会考虑i的最大值,也就是N,来对其实际占用的空间进行资源优化,int i = 0;和ap_int<4> i = 0;实际没有区别,如果i<N的N是变量,那么N的数据类型是很重要的,这一点在以后会讲到。
3.LOOP_MERGE
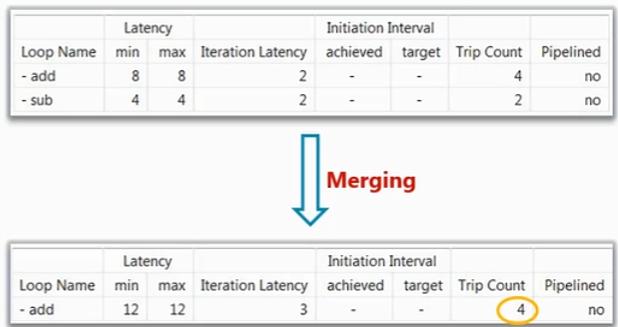
考虑如下图中的情况,add循环和sub循环都用到了ai和bi,并且循环上限都为N,从硬件设计的角度上讲,这两个循环完全可以合并,如右图中的逻辑:

在这里我们引入loop region的概念,它实际上就是对一段大括号括起的代码块声明的标签,在这里用作LOOP_MERGE的作用域。
然后我们对loop region添加LOOP_MERGE约束,与for添加约束的逻辑相同,通过图形界面Directive右键添加,或者在代码块第一行编写#pragma HLS LOOP_MERGE,就可以实现两个循环的并发执行:
cpp
void func(data_t a[N], data_t b[N], data_t c[N], data_t d[N])
{
int i;
loop_region:
{
#pragma HLS LOOP_MERGE
add:
for (i = 0; i < N; i++)
{
c[i] = a[i] + b[i];
}
sub:
for (i = 0; i < N; i++)
{
d[i] = a[i] - b[i];
}
}
}这样不仅能提高效率,并且在代码编写的过程中可以更好的区分逻辑,让代码有更好的可读性和可维护性。
如果两个循环的边界不同,如下图:

合并时将根据更大的循环决定循环次数,这没有问题,较少的那个循环之后就不会获取这个循环模块的sub输出了。
需要注意的是,如果两个(或多个)循环的循环上限有常量也有变量,那么LOOP_MERGE会报错:
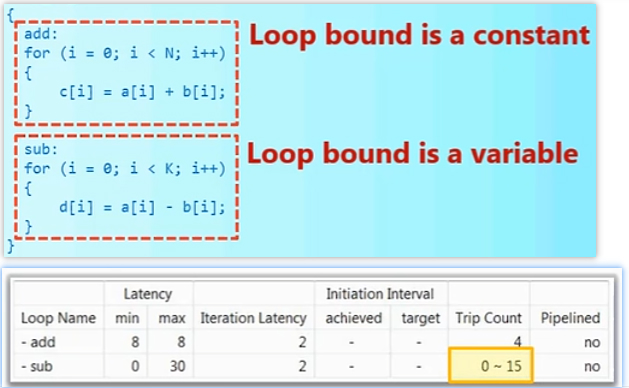
而如果循环上限有2个及以上的变量,那么即便变量的范围相同,LOOP_MERGE也会报错:

如何避免这样的问题?如果编程者可以通过设计,预先确定多个变量中哪个变量最小,那么就可以LOOP_MERGE最小变量次数的循环,然后在loop region外执行剩余的循环,如下是能确定K<=J的情况:

下一篇笔记将对For循环的DATAFLOW、嵌套和其他优化进行介绍。