前言
在上一篇文章《使用SpringAI快速实现离线/本地大模型应用》中,记录了如何使用SpringAI 来调用我们的本地大模型,如何快速搭建一个本地大模型系统,并演示本地大模型的智能对话、图片理解、文生图等功能。
但在前文中,我们把SpringAI 只是当作了一个大模型的搬运工,它并没有和我们的具体业务 系统联系起来。
也就是,它并没有解决前文中提到的以下问题:"然而在许多领域,由于大模型的数据没有采集到更细化的信息,亦或者出于安全原因某些数据不能对外公开,这时使用离线大模型来实现信息的生成与检索则变得非常重要。"
在本文中,将介绍如何使用Spring AI 中的RAG 技术,让大模型 (LLM)为我们的私有业务系统体现出具体价值。
目标:我们的大模型=(公有大模型+我们的私有业务系统知识)
RAG介绍
RAG,即Retrieval-augmented Generation ,检索增强生成。它是大模型 和信息检索技术的结合技术。
百度百科上的解释为:当模型需要生成文本或者回答问题时,它会先从一个庞大的文档集合中检索出相关的信息,然后利用这些检索到的信息来指导文本的生成,从而提高预测的质量和准确性。
按成功人士的话来讲,则为:"让大模型为行业赋能"。
RAG的工作流程可参考SpringAI中的这张图:

即:在用户向大模型检索某个信息时,会携带关于所需要检索的背景知识,这样以让大模型可以参考已有知识来进行应答。
SpringAI中实现RAG
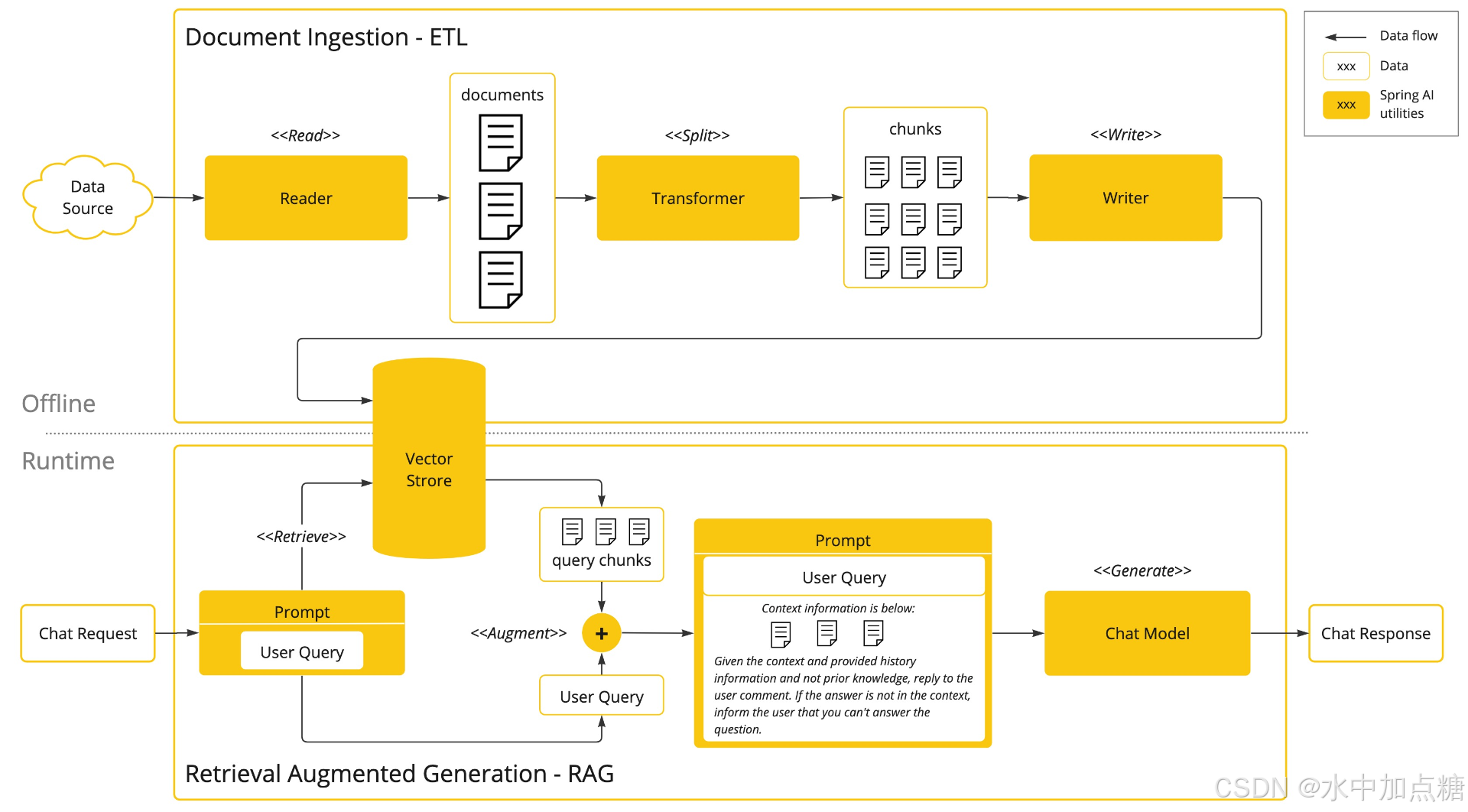
通过前面的介绍,我们已经对RAG有了一定的了解,通过它可以让大模型更加智能。RAG它没有具体的实现方式,在SpringAI 中实现一个RAG 我们一般遵循SpringAI的规范实现它就行。
此部分可参考:SpringAI-AI/Concepts/Retrieval Augmented Generation
The approach involves a batch processing style programming model, where the job reads unstructured data from your documents, transforms it, and then writes it into a vector database. At a high level, this is an ETL (Extract, Transform and Load) pipeline. The vector database is used in the retrieval part of RAG technique.
如上所述,RAG 的实现流程更像是一个ETL 工作流,并运用向量数据库实现对业务数据的存储与检索。下面用具体例子来说明。
ETL Pipeline(数据预加载)

ETL------Extract, Transform, and Load ,数据的提取、转换、加载流。
在SpringAI中,它对ETL的具体实现进行了一系列的封装,并对E、T、L中的每个阶段依次提供了接口类,分别为DocumentReader、DocumentTransformer、DocumentWriter。同时还提供了相关的依赖包,我们实现时根据需要按需导入。
下面以加载项目中一个名为1.pdf的PDF文档为例,看一下SpringAI中实现ETL的具体代码:
java
@Component
public class RagWorker {
private final VectorStore vectorStore;
private final Resource pdfResource;
public RagWorker(VectorStore vectorStore,
@Value("classpath:/rag/1.pdf") Resource pdfResource) {
this.vectorStore = vectorStore;
this.pdfResource = pdfResource;
}
@PostConstruct
public void init() {
//Extract
TikaDocumentReader tikaDocumentReader = new TikaDocumentReader(pdfResource);
TokenTextSplitter tokenTextSplitter = new TokenTextSplitter();
//Transform, and Load
vectorStore.add(tokenTextSplitter.apply(tikaDocumentReader.get()));
}
}以上代码中实现了从对PDF文档的读取,到TOKEN的切分与转换为向量,再到最终存入向量数据库的全部过程。
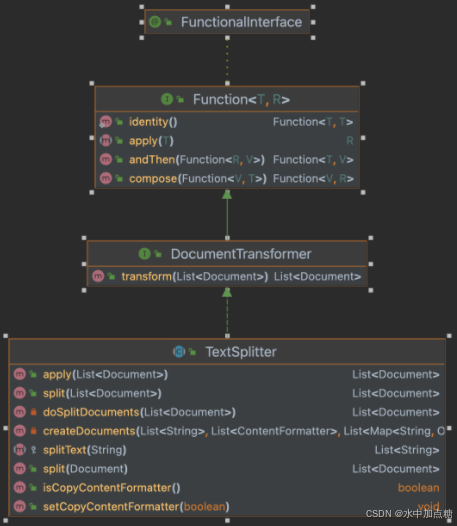
其中的TokenTextSplitter为Transformer的一个具体实现,类图如下:
其中涉及到的依赖为:
xml
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-tika-document-reader</artifactId>
</dependency>向量数据库与embedding模型
SpringAI中提供了VectorStore 接口类,它代表各向量数据库的抽象接口。SimpleVectorStore为SpringAI所提供的内存map向量数据库实现,仅在数据量极少和代码验证时适用。
vectorStore.add方法会调用嵌入模型的embed方法 ,将数据转换为向量。
代码片段如下:
java
@Override
public void add(List<Document> documents) {
VectorStoreObservationContext observationContext = this
.createObservationContextBuilder(VectorStoreObservationContext.Operation.ADD.value())
.build();
VectorStoreObservationDocumentation.AI_VECTOR_STORE
.observation(this.customObservationConvention, DEFAULT_OBSERVATION_CONVENTION, () -> observationContext,
this.observationRegistry)
.observe(() -> this.doAdd(documents));
}
@Override
public void doAdd(List<Document> documents) {
for (Document document : documents) {
logger.info("Calling EmbeddingModel for document id = {}", document.getId());
float[] embedding = this.embeddingModel.embed(document);
document.setEmbedding(embedding);
this.store.put(document.getId(), document);
}
}SpringAI中的默认ollama嵌入模型为mxbai-embed-large,使用前记得先进行拉取
ollama pull mxbai-embed-large
如需要修改SpringAI中调用的ollama嵌入模型,可通过项目的配置文件进行修改,application.properties:
spring.ai.ollama.embedding.model=rjmalagon/gte-qwen2-1.5b-instruct-embed-f16:latest
如这里修改为了中文支持度更好的qwen嵌入模型
ollama pull rjmalagon/gte-qwen2-1.5b-instruct-embed-f16
写段JAVA代码试下从向量数据库中查询某个关键字
java
@GetMapping("/ai/vectorStoreSearch")
public Map<String, String> getSystem(@RequestParam(value = "message", defaultValue = "Tell me a joke") String message) {
List<Document> similarDocuments = this.vectorStore.similaritySearch(message);
String documents = similarDocuments.stream().map(Document::getContent)
.collect(Collectors.joining(System.lineSeparator()));
return Map.of("result", documents);
}调用试一下:
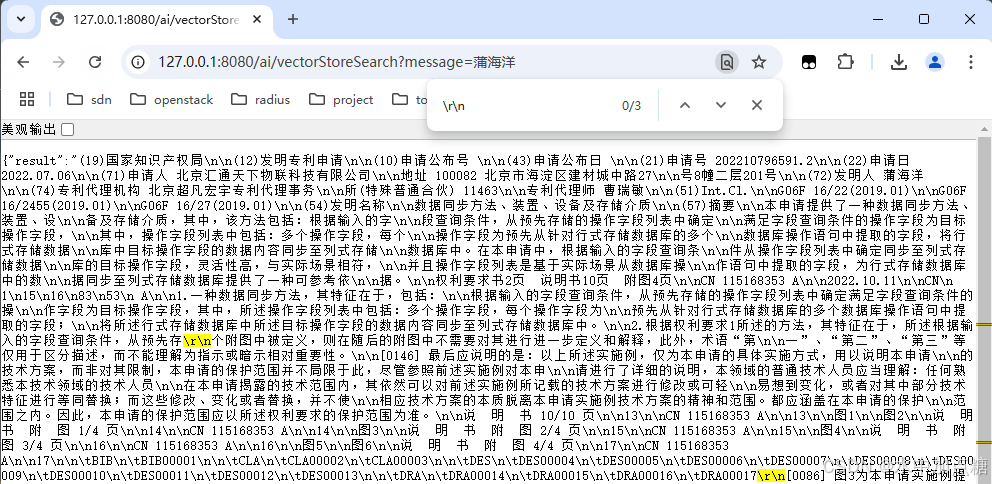
其中\r\n为代码中的System.lineSeparator(),它默认会返回与被搜索关键字最相似的4段文本
RAG实现示例
如上所述,在SpringAI项目中实现一个完整的RAG功能需要包含完整的ETL流程,并携带prompt 的上下文向大模型 提交问题,这些步骤看似冗长但好在有SpingAI的完美封装,实现起来非常简单。
在项目中新建一个字符串模板 文件,如service.st,内容如下:
你是一个信息查询助手,你的名字为"haiyangAI"。您的回复将简短明了,但仍然具有信息量和帮助性。
今天日期是{current_date}。
参考信息:
{documents}对话时的主要代码如下:
java
private static void submitPromptListener(String chatId, MessageInput.SubmitEvent e, ChatService chatService, VerticalLayout messageList) {
var question = e.getValue();
var userMessage = new MarkdownMessage(question, "You", Color.AVATAR_PRESETS[6]);
var assistantMessage = new MarkdownMessage("haiyangAI", Color.AVATAR_PRESETS[0]);
messageList.add(userMessage, assistantMessage);
chatService.chat(chatId, question)
.map(res -> Optional.ofNullable(res.getResult().getOutput().getContent()).orElse(""))
.subscribe(assistantMessage::appendMarkdownAsync);
}
public Flux<ChatResponse> chat(String chatId, String message) {
Message systemMessage = promptManagementService.getSystemMessage(chatId, message);
UserMessage userMessage = new UserMessage(message);
promptManagementService.addMessage(chatId, userMessage);
logger.debug("Chatting with chatId: {} and message: {}", chatId, message);
Prompt prompt = new Prompt(List.of(systemMessage, userMessage));
logger.info("prompt: {}", prompt);
return chatModel.stream(prompt);
}
public PromptManagementService(@Value("classpath:/rag/service.st") Resource systemPrompt, VectorStore vectorStore) {
this.systemPrompt = systemPrompt;
this.vectorStore = vectorStore;
this.messageAggregations = new ConcurrentHashMap<>();
}
public Message getSystemMessage(String chatId, String message) {
// Retrieve related documents to query
List<Document> similarDocuments = this.vectorStore.similaritySearch(SearchRequest.query(message).withTopK(2));
String documents = similarDocuments.stream().map(Document::getContent)
.collect(Collectors.joining(System.lineSeparator()));
Map<String, Object> prepareHistory = Map.of(
"documents", documents,
"current_date", java.time.LocalDate.now()
);
return new SystemPromptTemplate(this.systemPrompt).createMessage(prepareHistory);
}其主要流程为:
- 根据用户的输入prompt从向量数据库 (vectorStore)中查询出与prompt最接近的本地文本,topK(2)代表返回2条
- 拼接
classpath:/rag/service.st将本地向量数据库 返回的topK文档到模板文件中,形成SystemPrompt - 将SystemPrompt和用户输入的UserMessage 作为消息列表传递给大模型,以让大模型根据SystemPrompt 中的内容为背景知识来应答用户的输入
之后再用测试界面试一下效果,提问:蒲海洋在2022年7月申请了什么专利?

自定义的AI根据上下文背景 准确进行了回复,其参考的信息来源于1.pdf 文档

上面代码写得有点长,也可以使用SpringAI 提供的Advisors API进一步简化,写个http示例接口:
java
@GetMapping(value = "/ai/generateStream2", produces = MediaType.TEXT_EVENT_STREAM_VALUE + ";charset=UTF-8")
public Flux<ServerSentEvent<String>> generateStream2(@RequestParam(value = "message", defaultValue = "Tell me a joke") String message) {
String promptContext = """
你是一个信息查询助手,你的名字为"haiyangAI"。您的回复将简短明了,但仍然具有信息量和帮助性。
今天日期是{current_date}。
参考信息:{question_answer_context}
""";
return ChatClient.create(chatModel)
.prompt()
.user(message)
.advisors(new QuestionAnswerAdvisor(vectorStore, SearchRequest.defaults().withTopK(2), promptContext))
.user(b -> b.param("current_date", LocalDate.now().toString()))
.stream()
.content()
.map(resp -> ServerSentEvent.builder(resp)
.event("generation").build());
}其中的question_answer_context 占位符为QuestionAnswerAdvisor查询向量数据库自动填充的内容。
可见源码org.springframework.ai.chat.client.advisor#before方法:
java
private AdvisedRequest before(AdvisedRequest request) {
HashMap<String, Object> context = new HashMap(request.adviseContext());
String var10000 = request.userText();
String advisedUserText = var10000 + System.lineSeparator() + this.userTextAdvise;
String query = (new PromptTemplate(request.userText(), request.userParams())).render();
SearchRequest searchRequestToUse = SearchRequest.from(this.searchRequest).withQuery(query).withFilterExpression(this.doGetFilterExpression(context));
List<Document> documents = this.vectorStore.similaritySearch(searchRequestToUse);
context.put("qa_retrieved_documents", documents);
String documentContext = (String)documents.stream().map(Content::getContent).collect(Collectors.joining(System.lineSeparator()));
Map<String, Object> advisedUserParams = new HashMap(request.userParams());
advisedUserParams.put("question_answer_context", documentContext);
AdvisedRequest advisedRequest = AdvisedRequest.from(request).withUserText(advisedUserText).withUserParams(advisedUserParams).withAdviseContext(context).build();
return advisedRequest;
}验证一下:
http://127.0.0.1:8080/ai/generateStream2?message=蒲海洋在2022年7月申请了什么专利

可以看出应答效果与前面手动代码效果一样 ,即:QuestionAnswerAdvisor 可以简化手动查库 和填充上下文的代码,强得可怕。
Function Calling实时查询
在SpringAI 中除了可以使用向量数据库 进行上下文知识 提供外,还提供了另外一种与RAG 类似的功能------Function Calling API。
Function Calling工作流程
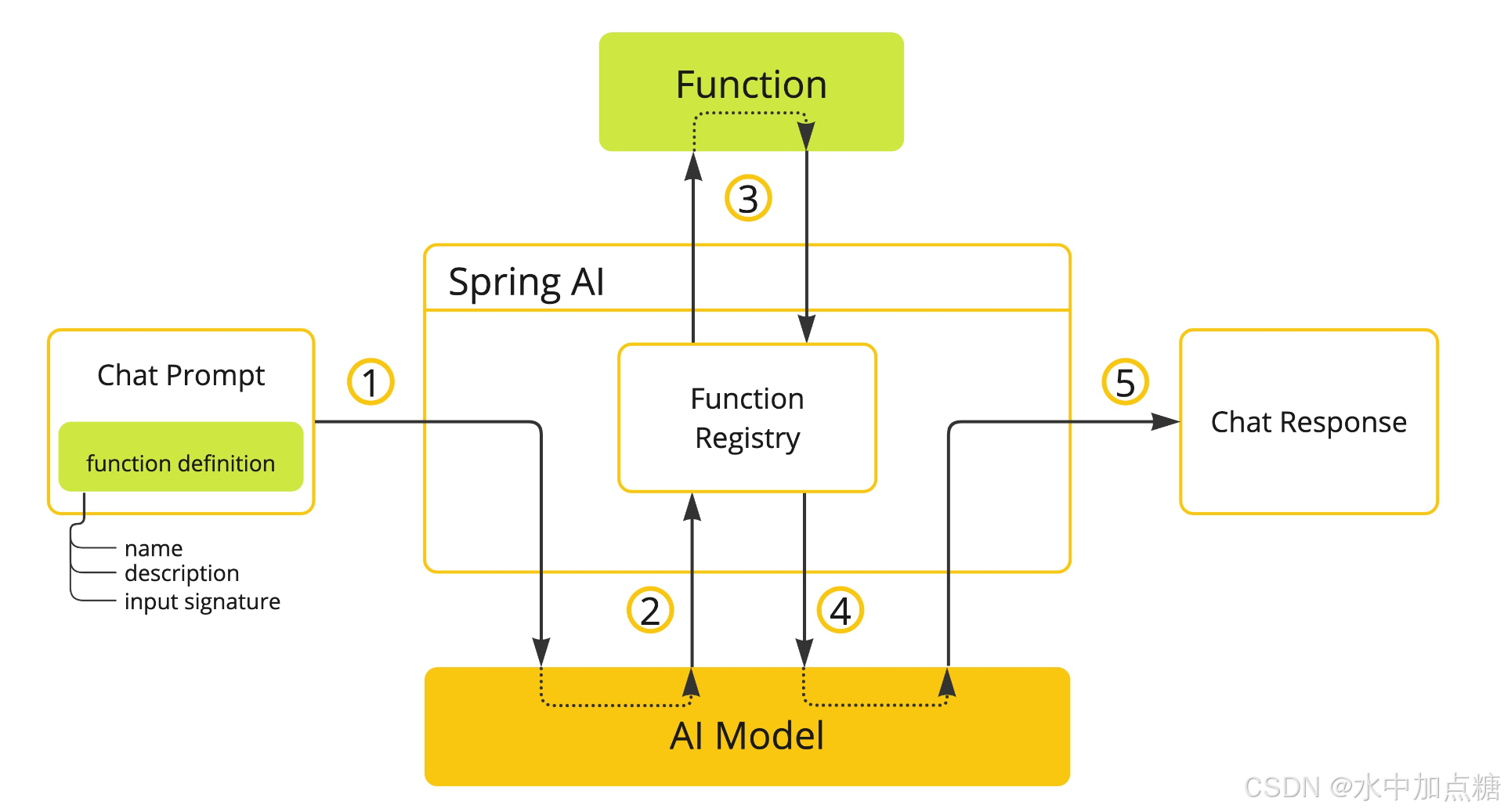
Function Calling的工作流程如上图,它的工作流程可以理解为是一个回调。
举个问天气预报的例子。
问题:"今天成都天气怎么样?"
其中的 "今天" 和 "成都" 分别代表两个变量:时间 和 地点
在SpringAI 框架中要实现这类部分变量的特定问题,则可以使用function calling来实现。
具体工作流程如下:
- 首先定义一个description ,设置问题描述("获取某个地方某天的天气" ),并绑定一个回调方法用来查询某个地方的某天的天气信息
- 当用户的输入 被提交到大模型后,大模型判断用户的输入是否符合 是否符合descprition所描述 的问题,
如满足,则由大模型提取出关键参数:"今天" 和 "成都",并调用这个description的回调函数 - 由本地的业务系统 得到今天 和成都 这两个实参,去查询本地业务系统中的天气信息,并将对应的天气信息再次提交给大模型
- 大模型再次收到业务系统关于 "成都今天的天气信息" 后,组织语言返回最终的分析结果
Function Calling快速实现
这里以ollama 本地大模型(参考ollama-chat-functions),写段代码理解下。
假设要实现的行业为 "AI+地铁" ,要做一个地铁AI问答系统 ,以实现某站点线路查询 的场景,解决类似:"天府三街有哪些地铁线路?" 这类的问题。
写个工具类,用来处理地铁站问题的回调,示例代码:
java
@Configuration
public class SubwayTools {
private static final Logger logger = LoggerFactory.getLogger(SubwayTools.class);
public record SubwayStationDetailsRequest(String stationName) {
}
@JsonInclude(JsonInclude.Include.NON_NULL)
public record SubwayStationDetails(String stationName,
Integer totalSubwayLine,
List<String> subwayLineNameList) {
}
@Bean
@Description("获取所在位置的地铁线路")
public Function<SubwayStationDetailsRequest, SubwayStationDetails> getSubwayStationDetails() {
return request -> {
try {
return findSubwayStationDetails(request.stationName());
} catch (Exception e) {
logger.warn("Booking details: {}", NestedExceptionUtils.getMostSpecificCause(e).getMessage());
return new SubwayStationDetails(request.stationName(), 0, null);
}
};
}
/**
* 获取某个地点的地铁线路
*
* @param stationName stationName
*/
private SubwayStationDetails findSubwayStationDetails(String stationName) {
//mock数据
if (stationName.contains("天府三街")) {
return new SubwayStationDetails(stationName, 1, List.of("地铁1号线"));
} else if (stationName.contains("三岔")) {
return new SubwayStationDetails(stationName, 2, List.of("地铁18号线", "地铁19号线"));
} else if (stationName.contains("西博城")) {
return new SubwayStationDetails(stationName, 3, List.of("地铁1号线", "地铁6号线", "地铁18号线"));
} else if (stationName.contains("海洋公园")) {
return new SubwayStationDetails(stationName, 3, List.of("地铁1号线", "地铁18号线", "地铁16号线"));
} else {
return null;
}
}
}在上面的代码中使用Description注解 的方式向Spring框架 中注入了一个名为getSubwayStationDetails 的function call ,并定义了用来接收大模型解析参数的Request类SubwayStationDetailsRequest,用来回复大模型的Response(上下文)类SubwayStationDetails,并使用mock 的方式模拟了几个地点的地铁线路。
有了上面@Configuration注解的自动装配后,我们就可以调用上面的Function了。写段代码验证下:
java
public Flux<ChatResponse> chatWithCallback(String chatId, String message) {
UserMessage userMessage = new UserMessage(message);
ChatResponse response = chatModel.call(new Prompt(userMessage, OllamaOptions.builder().withFunction("getSubwayStationDetails").build()));
return Flux.just(response);
}使用call调用时传入function的名称为getSubwayStationDetails,测试效果如下:

注意看,最后一个示例中我们问: "海洋公园有哪些地铁线路?" ,它回答到: "海洋公园有3条地铁线路,分别是地铁1号线、地铁18号线和地铁16号线。"
虽然答案不符合实际,但它这样回答是正确的,因为在function函数中我们mock的数据就是这样的。
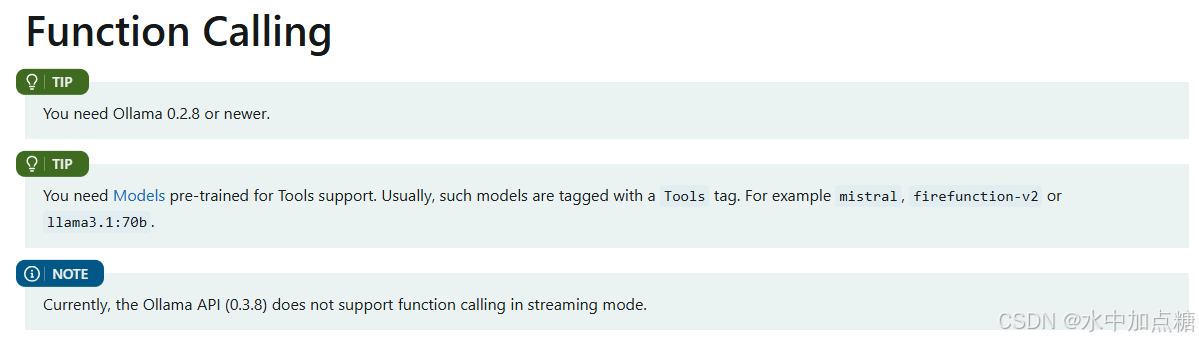
另外,需要注意的是:如果使用ollama作为大模型,要使用function calling 功能,需要使用支持Tools的模型。
如我这里使用的是国内的千问2.5
ollama run qwen2.5
spring.ai.ollama.chat.options.model=qwen2.5:latest
总结
使用SpringAI内置的RAG 和Function Calling 功能可以快速实现 一个针对私有业务领域的本地大模型系统。
- RAG 主要涉及到ETL Pipeline、embedding model、向量数据库的知识点,处理过程有点像装饰器设计模式,在向大模型提交prompt前修饰原问题的上下文背景。
- Function Calling 对于实时信息查询 的场景比较适用,通过对大模型的2次调用 与业务系统api的反馈 让大模型获取出上下文背景。
相信通过前文《使用SpringAI快速实现离线/本地大模型应用》的内容,再结合本文中介绍的RAG 和Function Calling 技术,我们可以很方便地用SpringAI 来实现一个面向自己的业务领域的本地(离线)大模型系统了。