昇思大模型平台打卡体验活动:项目2基于MindSpore通过GPT实现情感分类
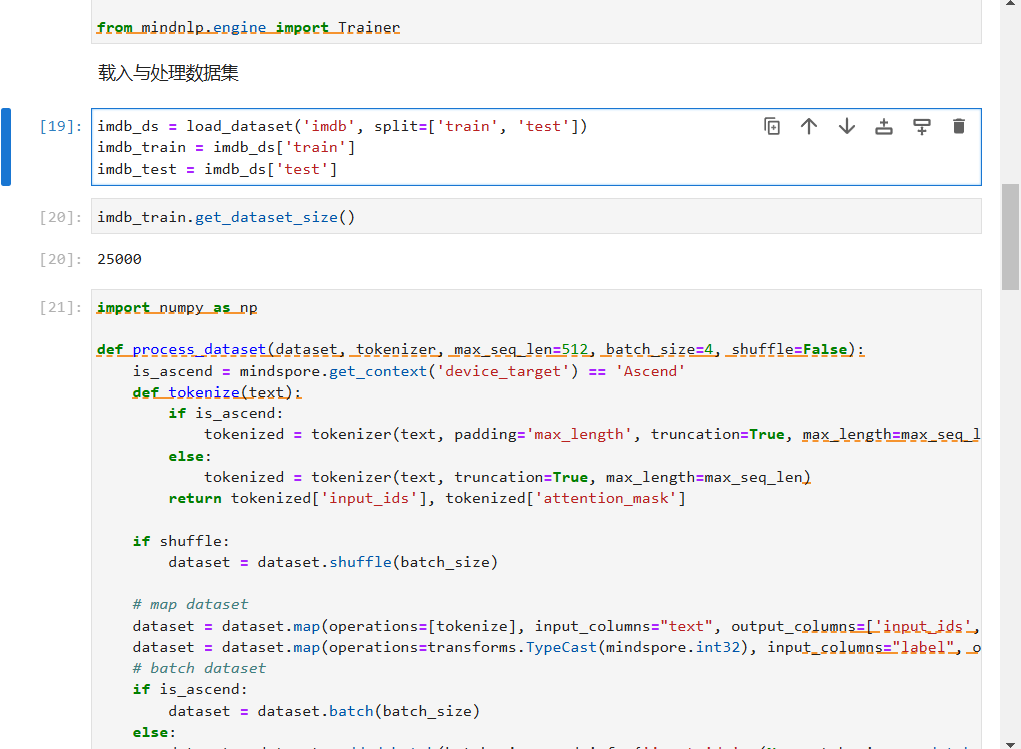
1. 载入与处理数据集
在情感分类任务中,我们使用了IMDB数据集,首先需要对数据进行加载和处理。由于原数据集没有验证集,我们将训练集重新划分为训练集和验证集,以确保训练和验证过程中模型的性能得到充分评估。
2. 加载GPT序列分类模型,设置为二分类
在处理数据后,我们使用了OpenAIGPTForSequenceClassification模型,基于GPT模型进行文本分类。我们将模型设置为二分类任务,适应情感分类问题的需求。
以下是模型的加载与配置:
python
from mindnlp.transformers import OpenAIGPTForSequenceClassification
# 加载GPT模型并设置为二分类
model = OpenAIGPTForSequenceClassification.from_pretrained('openai-gpt', num_labels=2)
# 配置pad_token_id并调整token embedding
model.config.pad_token_id = gpt_tokenizer.pad_token_id
model.resize_token_embeddings(model.config.vocab_size + 3)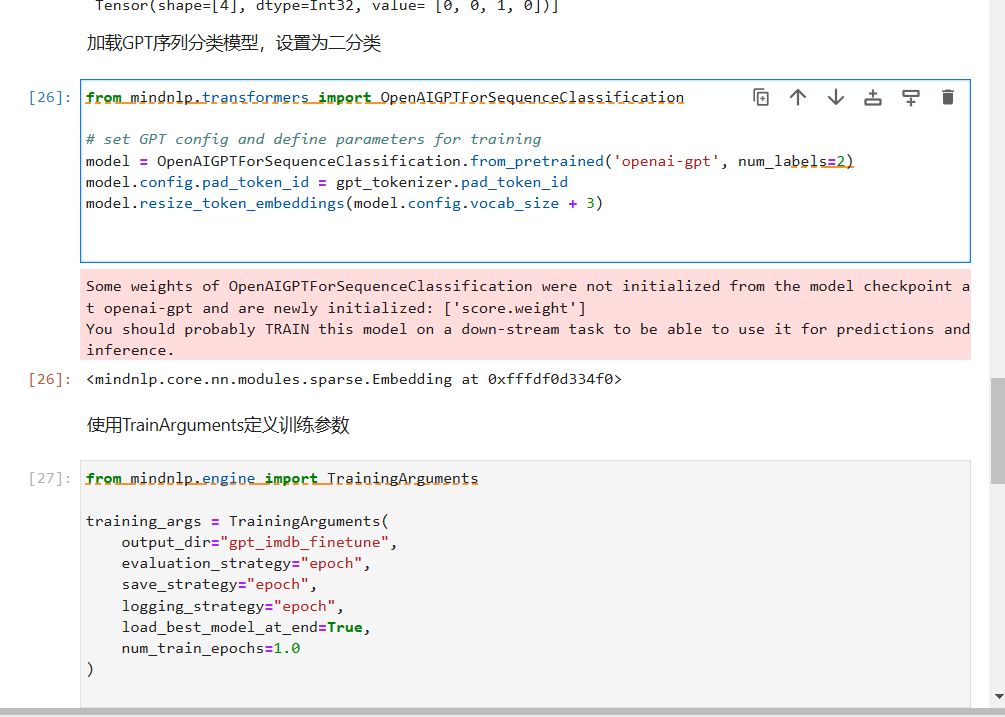
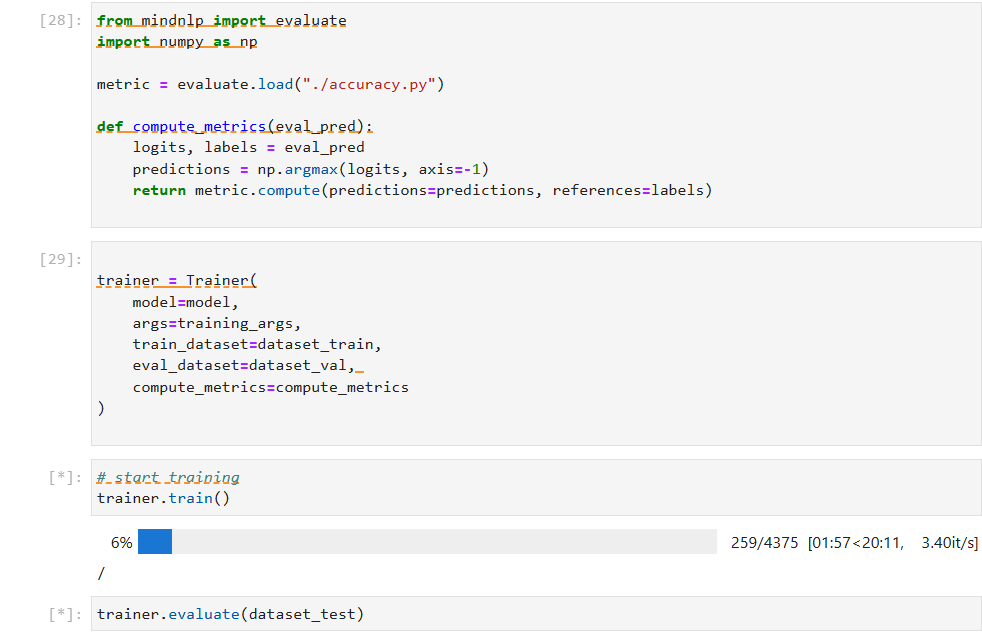
3. 设置训练与评估指标
为了对模型进行训练和评估,我们需要定义适当的训练和评估指标。在此步骤中,我们选择了适用于情感分类任务的标准指标,如准确率(Accuracy)、精确率(Precision)、召回率(Recall)等。
4. 最后的训练和评估结果
经过模型训练和评估后,我们得到了最终的结果。该模型能够有效地对IMDB数据集中的文本进行情感分类,并输出相关的评估指标。
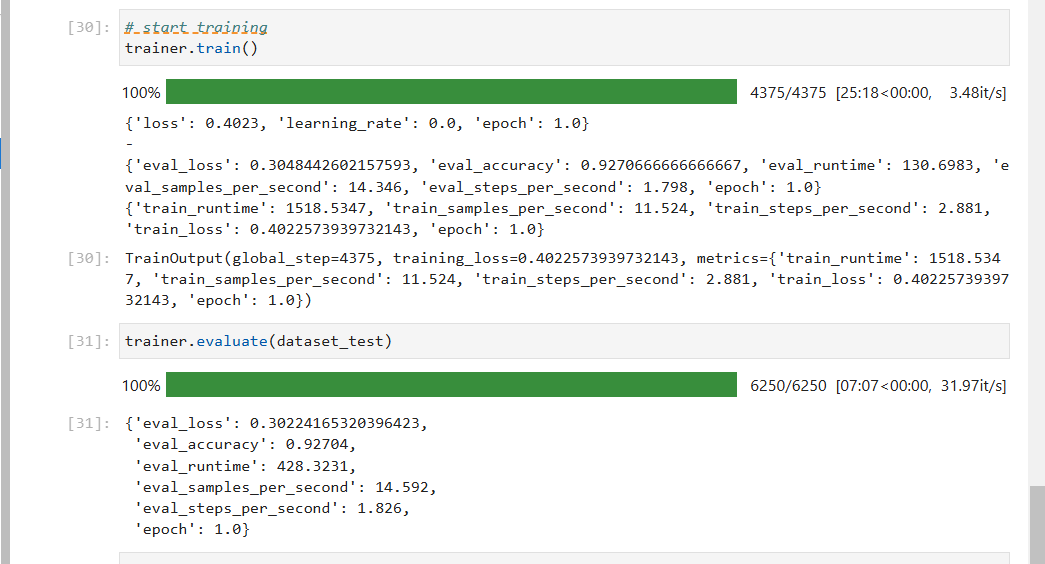
通过上述步骤,我们使用MindSpore平台和GPT模型实现了情感分类任务,能够有效地对文本进行情绪分析,提供情感分类的预测结果。这一过程展示了GPT模型在自然语言处理任务中的应用,尤其是在情感分析方面的表现。