Golang超详细入门教程
部分图片可能加载不出来,所以这里我上传到了自己的个人网站上也可以查看:http://dahua.bloggo.chat/testimonials/490.html
一、数据类型转换
- C语言中数据可以隐式转换或显示转换, 但是Go语言中数据只能显示转换
- 格式: 数据类型(需要转换的数据)
- 注意点: 和C语言一样数据可以从大类型转换为小类型, 也可以从小类型转换为大类型. 但是大类型转换为小类型可能会丢失精度
Go语言中不能通过 数据类型(变量)的格式将数值类型转换为字符串, 也不能通过 数据类型(变量)的格式将字符串转换为数值类型
go
package main
import "fmt"
func main() {
var num1 int32 = 65
// 可以将整型强制转换, 但是会按照ASCII码表来转换
// 但是不推荐这样使用
var str1 string = string(num1)
fmt.Println(str1)
var num2 float32 = 3.14
// 不能将其它基本类型强制转换为字符串类型
var str2 string = string(num2)
fmt.Println(str2)
var str3 string = "97"
// 不能强制转换, cannot convert str2 (type string) to type int
var num3 int = int(str3)
fmt.Println(num3)
}其它类型转字符串类型 strconv.FormatXxx()
go
package main
import (
"fmt"
"strconv"
)
func main() {
// 字符串转换成字符切片
slice := []byte("hello") // 强制类型转换 string-->[]byte
fmt.Println(slice) // [104 101 108 108 111]
// 字符切片转换成字符串
slice2 := []byte{'h', 'e', 'l', 'l', 'o', 97}
fmt.Println(string(slice2)) // helloa 强制类型转换 []byte-->string
// strconv.FormatXXX() 其他类型转换成字符串
str1 := strconv.FormatBool(true) // bool-->string
fmt.Println(str1) // true
fmt.Println(strconv.FormatInt(123, 10)) // 123 int-->string 10表示十进制
fmt.Println(strconv.Itoa(123)) // 123 十进制int-->string
fmt.Println(strconv.FormatFloat(3.14, 'f', 6, 64)) // 3.140000 float-->string 6:保留6位 64:float64
}字符串类型转其它类型 strconv.ParseXxx()
go
package main
import (
"fmt"
"strconv"
)
func main() {
// strconv.ParseXXX() 字符串转换成其他类型
// strconv.ParseBool() string-->bool
b, err_info := strconv.ParseBool("false")
if err_info != nil { // 如果有错误信息
fmt.Println("类型转换出错")
} else {
fmt.Println(b) // false
}
// strconv.ParseInt() string-->int64
val, err_info := strconv.ParseInt("11011001", 2, 64) // 2:二进制 64:int64
fmt.Println(val) // 217
// strconv.ParseFloat() string-->float64
val2, err_info := strconv.ParseFloat("3.1415", 64) // 64:float64
fmt.Println(val2) // 3.1415
// strconv.Atoi() string-->十进制int
val3, _ := strconv.Atoi("123")
fmt.Println(val3) // 123
}二、常量
- 在常量组中, 如果上一行常量有初始值,但是下一行没有初始值, 那么下一行的值就是上一行的值
- 定义的局部变量或者导入的包没有被使用, 那么编译器会报错,无法编译运行
- 但是定义的常量没有被使用,编译器不会报错, 可以编译运行
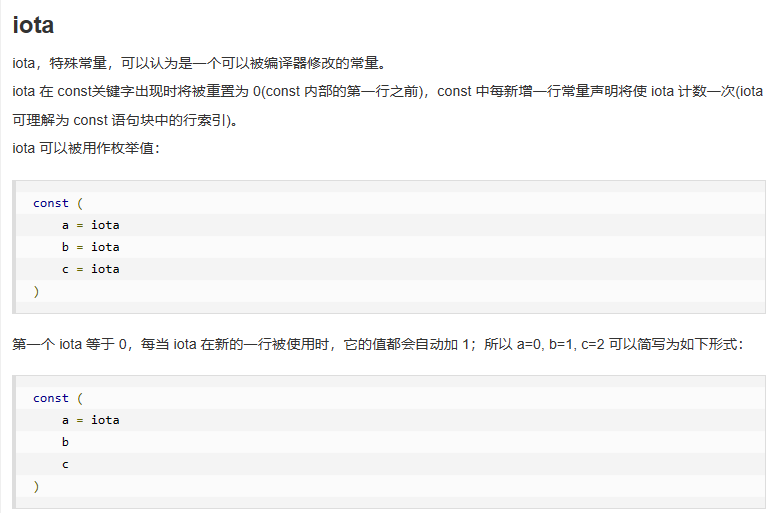
go
package main
import "fmt"
func main() {
const (
a = iota //0
b //1
c //2
d = "ha" //独立值,iota += 1
e //"ha" iota += 1
f = 100 //iota +=1
g //100 iota +=1
h = iota //7,恢复计数
i //8
)
fmt.Println(a, b, c, d, e, f, g, h, i)
}
0 1 2 ha ha 100 100 7 8三、输入输出函数
1.输出函数
func Printf(format string, a ...interface{}) (n int, err error)
- Go语言Printf函数其它特性,如宽度、标志、精度、长度、转移符号等,和C语言一样.
- Go语言中输出某一个值,很少使用%d%f等, 一般都使用%v即可
- 输出复合类型时会自动生成对应格式后再输出
- 除此之外**,Go语言还增加了%v控制符,用于打印所有类型数据**
- 除此之外**,Go语言还增加了%T控制符, 用于输出值的类型**
- 值得注意的是,输出十进制只能通过%d,不能像C语言一样通过%i
- 除了和C语言一样,可以通过%o、%x输出八进制和十六进制外,还可以直接通过%b输出二进制
- 和C语言用法几乎一模一样, 只不过新增了一些格式化符号
func Println(a ...interface{}) (n int, err error)
- 输出之后会在结尾处添加换行
- 传入多个参数时, 会自动在相邻参数之间添加空格
- 传入符合类型数据时, 会自动生成对应格式后再输出
- 采用默认格式将其参数格式化并写入标准输出
func Print(a ...interface{}) (n int, err error)
- 输出之后不会在结尾处添加换行
- 传入多个参数时, 只有两个相邻的参数都不是字符串,才会在相邻参数之间添加空格
- 传入符合类型数据时, 会自动生成对应格式后再输出
- 和Println几乎一样
以下三个函数和Printf/Println/Print函数一样, 只不过上面三个函数是输出到标准输出, 而下面三个函数可以通过w指定输出到什么地方
func Fprintf(w io.Writer, format string, a ...interface{}) (n int, err error)
func Fprintln(w io.Writer, a ...interface{}) (n int, err error)
func Fprint(w io.Writer, a ...interface{}) (n int, err error)
go
package main
import (
"fmt"
"net/http"
"os"
)
func main() {
// os.Stdout 写入到标准输出
name := "lnj"
age := 33
// 第一个参数: 指定输出到什么地方
// 第二个参数: 指定格式控制字符串
// 第三个参数: 指定要输出的数据
fmt.Fprintf(os.Stdout, "name = %s, age = %d\n", name, age)
// http.ResponseWriter 写入到网络响应
http.HandleFunc("/", func(writer http.ResponseWriter, request *http.Request) {
fmt.Fprintf(writer, "name = %s, age = %d\n", name, age)
})
http.ListenAndServe(":8888", nil)
}以下三个函数和Printf/Println/Print函数一样, 只不过上面三个函数是输出到标准输出, 而下面三个函数不会输出,而是将字符串返回给我们
func Sprintf(format string, a ...interface{}) string
func Sprint(a ...interface{}) string
func Sprintln(a ...interface{}) string
go
package main
import (
"fmt"
)
func main() {
name := "lnj"
age := 33
// 按照指定的格式生成字符串
str := fmt.Sprintf("name = %s, age = %d\n", name, age)
// 输出生成的字符串
fmt.Println(str)
}2.输入函数
func Scanf(format string, a ...interface{}) (n int, err error)
func Scan(a ...interface{}) (n int, err error)
func Scanln(a ...interface{}) (n int, err error)
以下三个函数和Scan/Scanln/Scanf函数一样, 只不过上面三个函数是从标准输入读取数据, 而下面三个函数可以通过r指定从哪读取数据
func Fscanf(r io.Reader, format string, a ...interface{}) (n int, err error)
func Fscanln(r io.Reader, a ...interface{}) (n int, err error)
func Fscan(r io.Reader, a ...interface{}) (n int, err error)
go
package main
import (
"fmt"
"os"
"strings"
)
func main() {
var num1 int
var num2 int
// 第一个参数: 指定从哪读取数据
// 第二个参数: 指定格式控制字符串
// 第三个参数: 指定要输出的数据
fmt.Fscanf(os.Stdin, "%d%d", &num1, &num2)
fmt.Println(num1, num2)
s := strings.NewReader("lnj 33")
var name string
var age int
// 从指定字符串中扫描出想要的数据
// 注意:
fmt.Fscanf(s, "%s%d", &name, &age)
fmt.Println("name =", name, "age =", age)
}以下三个函数和Scan/Scanln/Scanf函数一样, 只不过上面三个函数是从标准输入读取数据, 而下面三个函数是从字符串中读取数据
func Sscan(str string, a ...interface{}) (n int, err error)
func Sscanf(str string, format string, a ...interface{}) (n int, err error)
func Sscanln(str string, a ...interface{}) (n int, err error)
go
package main
import "fmt"
func main() {
str := "lnj 33"
var name string
var age int
//fmt.Sscanf(str, "%s %d",&name, &age)
//fmt.Sscanln(str,&name, &age)
fmt.Sscan(str, &name, &age)
fmt.Println("name =", name, "age =", age)
}四、命令行参数
1.go命令行操作指令
go version 查看当前安装的go版本
go env 查看当前go的环境变量
go fmt 格式化代码,会将指定文件中凌乱的代码按照go语言规范格式化
go run 命令文件 编译并运行go程序
go build 编译检查
1. 对于非命令文件只会执行编译检查, 不会产生任何文件
2. 对于命令文件除了编译检查外,还会在当前目录下生成一个可执行文件
3. 对应只想编译某个文件, 可以在命令后面指定文件名称go build 文件名称go install 安装程序
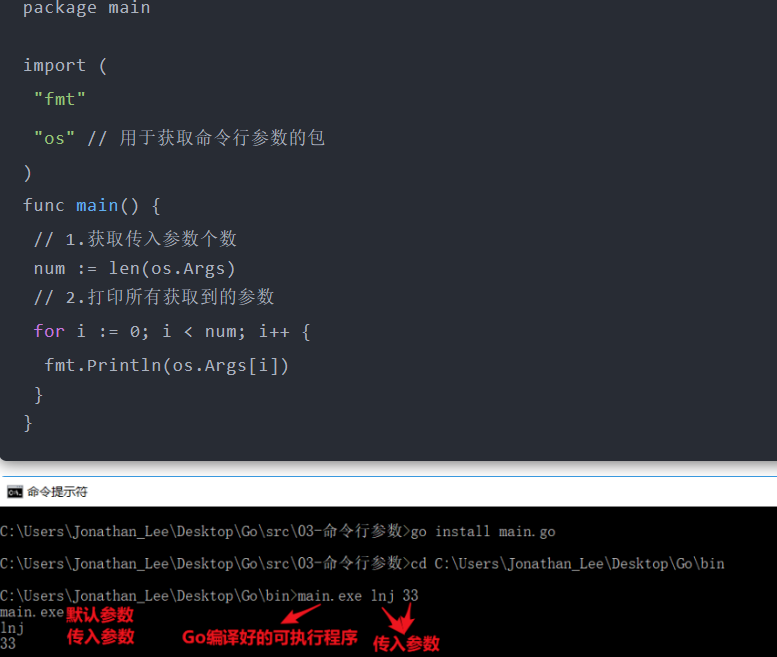
2.通过os包获取命令行参数
简单介绍:Go语言的 os 包中提供了操作系统函数的接口,是一个比较重要的包。 顾名思义,os 包的作用主要是在服务器上进行系统的基本操作,如文件操作、目录操作、执行命令、信号与中断、进程、系统状态等等。
- Go语言中main函数没有形参, 所以不能直接通过main函数获取命令行参数
- 想要获取命令行参数必须导入os包, 通过os包的Args获取
- 注意点: 无论外界传入的是什么类型, 我们拿到的都是字符串类型
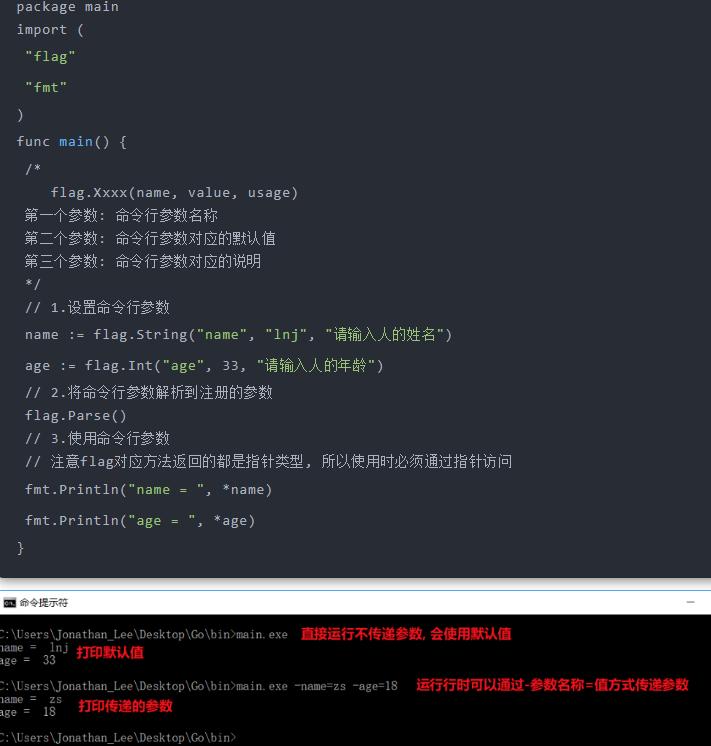
3.通过flag包获取命令行参数
第一种:
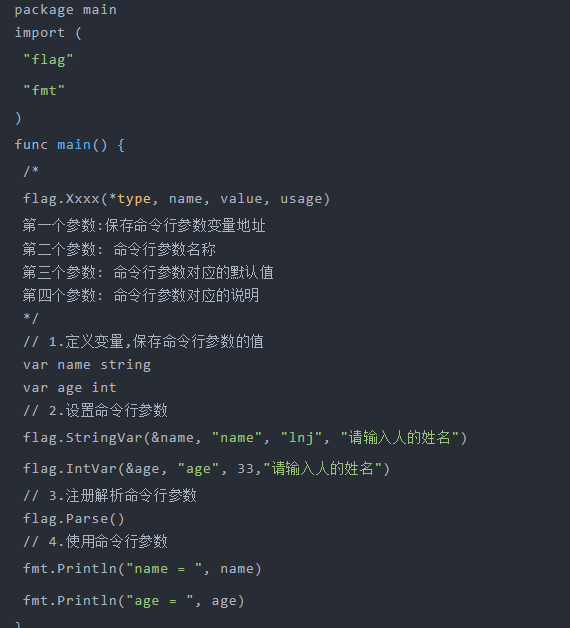
第二种:
4.os包和flag包的对比
通过os包获取命令行参数
- 如果用户没有传递参数会报错
- 需要严格按照代码中的顺序传递参数, 否则会造成数据混乱
- 不能指定参数的名称
- 获取到的数据都是字符串类型
通过flag包获取命令行参数
- 如果用户没有传递参数不会报错
- 不需要严格按照代码中的顺序传递参数, 不会造成数据混乱
- 可以指定参数的名称
- 获取到的数据是我们自己指定的类型
五、流程控制
1.选择语句(if...)
1. 条件表达式的值必须是布尔类型(**Go语言中没有非零即真的概念**)
2. 条件表达式前面可以添加初始化语句
3. 不需要编写圆括号
4. 左大括号必须和条件语句在同一行- 值得一提的是Go语言中没有C语言中的三目运算符, 所以C语言中三目能干的在Go语言中都只能通过if else的形式来完成
2.选择结构(switch...case)
1. 和if一样,表达式前面**可以添加初始化语句**
2. 和if一样,不需要编写圆括号
3. 和if一样,左大括号必须和表达式在同一行
4. case表达式的值不一定要是常量, 甚至可以不用传递
5. 一个case后面**可以有多个表达式**, 满足其中一个就算匹配
6. case后面不需要添加break
7. 可以在case语句块最后添加fallthrough,实现case穿透
8. case后面定义变量不需要添加{}明确范围
go
package main
import "fmt"
func main() {
//第一种
switch num := 3; num {
case 1, 2, 3, 4, 5:
fmt.Println("工作日")
case 6, 7:
fmt.Println("非工作日")
default:
fmt.Println("Other...")
}
//第二种
//case后面不用编写break, 不会出现case穿透问题
//如果想让case穿透,必须在case语句块最后添加fallthrough关键
switch num := 1; num {
case 1:
fallthrough
case 2:
fallthrough
case 3:
fallthrough
case 4:
fallthrough
case 5:
fmt.Println("工作日")
fallthrough
case 6:
fmt.Println("结束")
case 7:
fmt.Println("非工作日")
default:
fmt.Println("Other...")
}
}3.循环结构(for )
除了实现基本的循环结构以外,Go语言还实现了一种高级for循环for...range循环,for...range循环可以快速完成对字符串 、数组 、slice 、map 、channel 遍历。
格式:for 索引, 值 := range 被遍历数据{ content }
go
package main
import "fmt"
func main() {
// 1.定义一个数组
arr := [3]int{1, 3, 5}
// 2.快速遍历数组
// i用于保存当前遍历到数组的索引
// v用于保存当前遍历到数组的值
for i, v := range arr {
fmt.Println(i, v)
}
}
0 1
1 3
2 54.四大跳转
return、break、continue、goto
六、函数
1.值传递和引用传递
- Go语言中值类型有: int系列、float系列、bool、string、数组、结构体
- 值类型通常在栈中分配存储空间
- 值类型作为函数参数传递, 是拷贝传递
- 在函数体内修改值类型参数, 不会影响到函数外的值
- Go语言中引用类型有: 指针、slice、map、channel
- 引用类型通常在堆中分配存储空间
- 引用类型作为函数参数传递,是引用传递
- 在函数体内修改引用类型参数,会影响到函数外的值
- slice是一个24Byte的结构体。
- map和channel都是8Byte的指针。
- slice、map、channel使用的是浅拷贝,形参实参会通过指针共享数据,所以会相互影响。但是golang对这三个结构体做了封装,从广义上来定义引用的话(通过别名去修改原数据),那这三个数据类型也属于引用类型。
2.匿名函数
匿名函数也是函数的一种, 它的格式和普通函数一模一样,只不过没有名字而已。
匿名函数可以定义在函数外(全局匿名函数),也可以定义在函数内(局部匿名函数), Go语言中的普通函数不能嵌套定义, 但是可以通过匿名函数来实现函数的嵌套定义。
- 全局匿名函数
一般情况下我们很少使用全局匿名函数, 大多数情况都是使用局部匿名函数, 匿名函数可以直接调用、保存到变量、作为参数或者返回值。
- 匿名函数应用场景
- 当某个函数只需要被调用一次时, 可以使用匿名函数
- 需要执行一些不确定的操作时,可以使用匿名函数
3.闭包(特殊的匿名函数)
- 只要闭包还在使用外界的变量, 那么外界的变量就会一直存在
- 闭包中使用的变量和外界的变量是同一个变量, 所以可以闭包中可以修改外界变量
- 也就是说只要匿名函数中用到了外界的变量, 那么这个匿名函数就是一个闭包
4.延迟调用
- Go语言中没有提供其它面向对象语言的析构函数, 但是Go语言提供了defer语句用于实现其它面向对象语言析构函数的功能。
- defer语句常用于释放资源、解除锁定以及错误处理等。
- 无论你在什么地方注册defer语句,它都会在所属函数执行完毕之后才会执行, 并且如果注册了多个defer语句,那么它们会按照后进先出的原则执行。
使用建议:
一个函数中,有多个条件分支使用 return 结束函数运行的情况下,同时有资源打开需要关闭的情况下,建议使用 defer,在资源打开后直接使用 defer 注册关闭该资源的代码,这样可以避免忘记关闭资源操作。例如打开一个文件,然后读取内容,内容转换处理,然后关闭文件。这个流程就可以改成 打开文件、延迟关闭文件、读取内容、内容转换处理 。
defer 不要在循环 中使用,也不要对命名返回值变量操作 ,否则会出现很难理解的意外结果。defer 使用的位置如果不正确,会有可能导致宕机(panic),所以有错误检查的语句的,最好放在错误检查语句之后。
5.init 函数
- golang里面有两个保留的函数:
- init函数(能够应用于所有的package)
注:init函数用于处理当前文件的初始化操作, 在使用某个文件时的一些准备工作应该放到这里。
- main函数(只能应用于package main)
- 这两个函数在定义时不能有任何的参数和返回值。
- go程序会自动调用init()和main(),所以你不能在任何地方调用这两个函数。
- package main必须包含一个main函数, 但是每个package中的init函数都是可选的。
- 一个package里面可以写任意多个init函数,但这无论是对于可读性还是以后的可维护性来说,我们都强烈建议用户在一个package中每个文件只写一个init函数。

go
package main
import "fmt"
const constValue = 998 // 1
var gloalVarValue int = abc() // 2
func init() { // 3
fmt.Println("执行main包中main.go中init函数")
}
func main() { // 4
fmt.Println("执行main包中main.go中main函数")
}
func abc() int {
fmt.Println("执行main包中全局变量初始化")
return 998
}
执行main包中全局变量初始化
执行main包中main.go中init函数
执行main包中main.go中main函数七、数组和切片
1.数组
go
var a1 [3]int = [3]int{1, 3, 5}
var a2 [3]int = [3]int{8}
var a3 = [3]int{0: 8, 2: 9}
var a4 [3]int
fmt.Println(a1, a2, a3, a4)
[1 3 5] [8 0 0] [8 0 9] [0 0 0]
go
arr := [...]int{1, 3, 5}
// 传统for循环遍历
for i := 0; i < len(arr); i++ {
fmt.Println(i, arr[i])
}
0 1
1 3
2 5
// for...range循环遍历
for i, v := range arr {
fmt.Println(i, v)
}
0 1
1 3
2 52.切片
- 在实际开发中我们可能事先不能确定数组的长度, 为了解决这类问题Go语言中推出了一种新的数据类型切片。
- 切片可以简单的理解为长度可以变化的数组, 但是Go语言中的切片本质上是一个结构体。
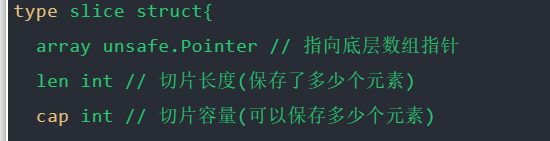
切片的使用
go
sce := make([]int, 3, 5)
sce = append(sce, 1, 2, 3, 4, 5, 6)
fmt.Println(sce)
//首部添加元素, ... 可变参数
sce = append([]int{110, 120}, sce...)
fmt.Println(sce)
//中间添加元素
sce = append(sce[:2], append([]int{123, 456}, sce[2:]...)...)
fmt.Println(sce)
//copy(目标切片, 源切片),
sce1 := make([]int, 10)
copy(sce1, sce)
fmt.Println(sce1)
//删除 3 个 0
sce = append(sce[:4], sce[7:]...)
fmt.Println(sce)
[0 0 0 1 2 3 4 5 6]
[110 120 0 0 0 1 2 3 4 5 6]
[110 120 123 456 0 0 0 1 2 3 4 5 6]
[110 120 123 456 0 0 0 1 2 3]
[110 120 123 456 1 2 3 4 5 6]关于Go切片,看这篇就够了
切片的注意点
7. golang之切片的使用注意事项和细节讨论_风落不归处的博客-CSDN博客
八、字典与结构体
1.map(字典,映射)
- 只要是可以做==、!=判断的数据类型都可以作为key(数值类型、字符串、数组、指针、结构体、接口)。
- map的key的数据类型不能是:slice、map、function。
- map和切片一样容量都不是固定的, 当容量不足时底层会自动扩容。
- 切片是用来存储一组相同类型的数据的, map也是用来存储一组相同类型的数据的。
- 在切片中我们可以通过索引获取对应的元素, 在map中我们可以通过key获取对应的元素。
- 切片的索引是系统自动生成的,从0开始递增. map中的key需要我们自己指定
- 创建map的三种方式
go
package main
import "fmt"
func main() {
//map格式:var dic map[key数据类型]value数据类型
//方式一: 通过Go提供的语法糖快速创建
dict := map[string]string{"name": "lnj", "age": "1", "gender": "male"}
fmt.Println(dict) // map[name:lnj age:33 gender:male]
//方式二:通过make函数创建make(类型, 容量)
var dict1 = make(map[string]string, 3)
dict1["name"] = "lnj"
dict1["age"] = "2"
dict1["gender"] = "male"
fmt.Println(dict1) // map[age:33 gender:male name:lnj]
//方式三:通过make函数创建make(类型)
var dict2 = make(map[string]string)
dict2["name"] = "lnj"
dict2["age"] = "3"
dict2["gender"] = "male"
fmt.Println(dict2) // map[age:33 gender:male name:lnj]
// 注意:map声明后不能直接使用, 只有通过make或语法糖创建之后才会开辟空间,才能使用
var dict3 map[string]string
dict3["name"] = "lnj" // 编译报错
dict3["age"] = "33"
dict3["gender"] = "male"
fmt.Println(dict3)- map的增删改查
go
package main
import "fmt"
func main() {
//增加: 当map中没有指定的key时就会自动增加
var dict = make(map[string]string)
fmt.Println("增加前:", dict) // map[]
dict["name"] = "lnj"
fmt.Println("增加后:", dict) // map[name:lnj]
//修改: 当map中有指定的key时就会自动修改
var dict1 = map[string]string{"name": "lnj"}
fmt.Println("修改前:", dict1) // map[name:lnj]
dict1["name"] = "zs"
fmt.Println("修改后:", dict1) // map[name:zs]
//删除: 可以通过Go语言内置delete函数删除指定元素
var dict2 = map[string]string{"name": "lnj", "age": "33", "gender": "male"}
fmt.Println("删除前:", dict2) // map[name:lnj age:33 gender:male]
// 第一个参数: 被操作的字典
// 第二个参数: 需要删除元素对应的key
delete(dict2, "name")
fmt.Println("删除后:", dict2) // map[age:33 gender:male]
//查询: 通过ok-idiom模式判断指定键值对是否存储
var dict3 = map[string]string{"name": "lnj", "age": "33", "gender": "male"}
//value, ok := dict["age"]
//if(ok){
// fmt.Println("有age这个key,值为", value)
//}else{
// fmt.Println("没有age这个key,值为", value)
//}
if value, ok := dict3["age"]; ok {
fmt.Println("有age这个key,值为", value)
}
//遍历
//注意: map和数组以及切片不同,map中存储的数据是无序的, 所以多次打印输出的顺序可能不同
var dict4 = map[string]string{"name": "lnj", "age": "33", "gender": "male"}
for key, value := range dict4 {
fmt.Println(key, value)
}
}2.结构体
go
package main
import "fmt"
func main() { //创建结构体变量的两种方式
//第一种方式
type Student struct {
name string
age int
}
var stu1 = Student{"lnj", 33} // 完全初始化
fmt.Println(stu1)
// 部分初始化必须通过 属性名称: 方式指定要初始化的属性
var stu2 = Student{name: "lnj"} // 部分初始化
fmt.Println(stu2)
//第二种方式
// 注意: 这里不用写type和结构体类型名称
var stu = struct {
name string
age int
}{
name: "lnj",
age: 33,
}
fmt.Println(stu)
}结构体变量 以及 指针的定义方法。
1.直接定义结构体变量
type Person struct {
Name string
Age int
Gender string
}
func main() {
var p Person
p.Name = "Bob"
p.Age = 20
p.Gender = "Male"
fmt.Println§
}
在上面的示例中,我们直接通过var定义了一个Person类型的变量p,然后使用点操作符来设置其字段的值。
2.使用字面量定义结构体变量
在Go语言中,可以使用结构体字面量来定义结构体变量:
func main() {
p := Person{Name: "Bob", Age: 20, Gender: "Male"}
fmt.Println§
}
使用结构体字面量的好处是可以直接在定义变量时就设置其字段的值,更加简洁易懂。
3.定义结构体指针变量
如果我们需要在函数之间传递结构体变量或在函数内部修改结构体字段的值,一种常见的方式是定义结构体指针变量:
func main() {
var p Person
p = &Person{Name: "Bob", Age: 20, Gender: "Male"}
fmt.Println§
}
在上面的示例中,我们使用&符号获取结构体字面量的内存地址赋值给指针变量p,从而定义了一个结构体指针变量。此后,我们可以使用指针操作符 来访问和修改其字段的值。
4.使用new函数动态分配结构体
Go语言还提供了一个new函数,用于在堆上动态分配一个新的结构体变量,并返回一个指向其内存地址的指针:
func main() {
p := new(Person)
p.Name = "Bob"
p.Age = 20
p.Gender = "Male"
fmt.Println§
}
在上面的示例中,我们使用new函数来动态分配一个Person类型的变量,并通过点操作符来设置其字段的值。需要注意的是,new函数返回的是一个指向已分配内存的指针,因此当使用它来定义一个新的变量时,需要使用指针类型来接收返回值。
go
package main
import "fmt"
type Teacher struct{}
func (tea Teacher) Action() string {
return "我是老师"
}
func main() {
//2.
t := Teacher{}
fmt.Println(t.Action())
//3.
var p *Teacher = &Teacher{}
fmt.Println(p.Action())
//4.
s := new(Teacher)
fmt.Println(s.Action())
}九、接口
Go 语言中的接口是隐式实现的,也就是说,如果一个类型实现了一个接口定义的所有方法,那么它就自动地实现了该接口。因此,我们可以通过将接口作为参数来实现对不同类型的调用,从而实现多态。
go
package main
import "fmt"
// 1.定义一个接口
type usber interface {
start()
stop()
}
// 2.实现接口中的所有方法
type Computer struct {
name string
model string
}
func (cm Computer) start() {
fmt.Println("启动电脑")
}
func (cm Computer) stop() {
fmt.Println("关闭电脑")
}
type Phone struct {
name string
model string
}
func (p Phone) start() {
fmt.Println("启动手机")
}
func (p Phone) stop() {
fmt.Println("关闭手机")
}
// 3.使用接口定义的方法
func working(u usber) {
u.start()
u.stop()
}
func main() {
cm := Computer{"戴尔", "F1234"}
working(cm) // 启动电脑 关闭电脑
p := Phone{"华为", "M10"}
working(p) // 启动手机 关闭手机
}注意点:
1、接口中只能有方法的声明不能有方法的实现
2、接口中只能有方法不能有字段
3、只有实现了接口中所有的方法, 才算实现了接口, 才能用该接口类型接收
4、和结构体一样,接口中也可以嵌入接口
5、和结构体一样,接口中嵌入接口时不能嵌入自己
6、接口中嵌入接口时不能出现相同的方法名称
7、空接口类型可以接收任意类型数据
8、使用接口类型和类型转换
- 利用ok-idiom模式将接口类型还原为原始类型,s.(Person)这种格式我们称之为: 类型断言。
- 通过 type switch将接口类型还原为原始类型,注意: type switch不支持fallthrought。
go
package main
import "fmt"
type studier interface {
read()
}
type Person struct {
name string
age int
}
func (p Person) read() {
fmt.Println(p.name, "正在学习")
}
func main() {
var s studier
s = Person{"lnj", 33}
// s.name = "zs" // 报错, 由于s是接口类型, 所以不能访问属性
// 2.定义一个结构体类型变量
//var p Person
// 不能用强制类型转换方式将接口类型转换为原始类型
//p = Person(s) // 报错
// 2.利用ok-idiom模式将接口类型还原为原始类型
// s.(Person)这种格式我们称之为: 类型断言
if p, ok := s.(Person); ok {
p.name = "zs"
fmt.Println(p)
}
// 2.通过 type switch将接口类型还原为原始类型
// 注意: type switch不支持fallthrought
switch p := s.(type) {
case Person:
p.name = "zs3"
fmt.Println(p) // {zs 33}
default:
fmt.Println("不是Person类型")
}
}对接口的相关补充:
在 Go 语言中,使用接口不一定要定义结构体,我们可以定义任意类型的变量实现相应的接口方法,只要该变量实现了接口中定义的所有方法即可。
而泛型则是一种通用的编程思想,它可以让我们编写一个可以适用于多种不同类型的代码。在 Go 语言中,虽然没有官方支持的泛型实现,但是我们可以使用 interface{} 类型实现类似泛型的功能。因为 interface{} 类型可以表示任意类型的变量,所以我们可以将不同类型的值传入同一个函数或方法中,并在运行时使用类型断言来判断其类型并进行相应的操作。这样可以达到类似泛型的效果,但是需要更多的类型判断和类型转换操作。
go
package main
import "fmt"
func add(a, b interface{}) (interface{}, interface{}, interface{}) {
//在golang中不支持运算符重载,因此需要判断类型
switch a.(type) {
case int:
return a.(int), b.(int), a.(int) + b.(int)
case float64:
return a.(float64), b.(float64), a.(float64) + b.(float64)
default:
return nil, nil, a.(string) + " " + b.(string)
}
}
func main() {
a := 1
b := 2
c := 2.5
d := 3.7
x, y, z := add(a, b)
fmt.Printf("%v + %v = %v\n", x, y, z)
x, y, z = add(c, d)
fmt.Printf("%v + %v = %v\n", x, y, z)
_, _, z = add("hello", "world")
fmt.Printf("Invalid operation: %v + + %v = %v\n", "hello", "world", z)
}
// 1 + 2 = 3
// 2.5 + 3.7 = 6.2
// Invalid operation: hello + + world = hello world
go
package main
import "fmt"
type Adder interface {
Add(x, y interface{}) (interface{}, interface{}, interface{})
}
type IntAdder struct {
}
func (i IntAdder) Add(x, y interface{}) (interface{}, interface{}, interface{}) {
return x.(int), y.(int), x.(int) + y.(int)
}
type FloatAdder struct{}
func (f FloatAdder) Add(x, y interface{}) (interface{}, interface{}, interface{}) {
return x.(float64), y.(float64), x.(float64) + y.(float64)
}
func main() {
var a Adder
a = IntAdder{}
x, y, z := a.Add(1, 2)
fmt.Printf("%v + %v = %v\n", x, y, z)
a = FloatAdder{}
x, y, z = a.Add(2.5, 3.7)
fmt.Printf("%v + %v = %v\n", x, y, z)
}
go
package main
import "fmt"
type Animal interface {
Speak() string
}
type Cat struct{}
func (c Cat) Speak() string {
return "Meow!"
}
type Dog struct{}
func (d Dog) Speak() string {
return "Woof!"
}
func main() {
cat := Cat{}
dog := Dog{}
animals := []Animal{cat, dog}
for _, animal := range animals {
fmt.Println(animal.Speak())
}
}
Meow!
Woof!十、sort接口
go语言sort.interface{}排序模式
Go语言中的sort包提供了对切片排序的函数和方法 ,但是需要开发者自己提供排序的方法。因为在不同的场景下,可能需要根据不同的字段来排序,比如按照整数大小、字符串长度、时间先后顺序等等;同时也可能需要自定义比较函数的规则,例如升序还是降序。
在sort包中,开发者需要实现一个Less方法来定义排序的规则。这个方法接受两个参数,即要比较的两个元素,返回一个bool类型的值表明哪个元素应该排在前面。例如:
go
package main
import (
"fmt"
"sort"
)
type Person struct {
Name string
Age int
}
type ByAge []Person
func (a ByAge) Len() int { return len(a) }
func (a ByAge) Swap(i, j int) { a[i], a[j] = a[j], a[i] }
func (a ByAge) Less(i, j int) bool { return a[i].Age > a[j].Age }
func main() {
people := []Person{
{"Alice", 25},
{"Bob", 30},
{"Carol", 20},
{"David", 35},
}
sort.Sort(ByAge(people))
fmt.Println(people)
}十一、面向对象
封装性
- 封装性就是隐藏实现细节,仅对外公开接口类是数据与功能的封装,数据就是成员变量,功能就是方法- 为什么要封装?
- 不封装的缺点:当一个类把自己的成员变量暴露给外部的时候,那么该类就失去对该成员变量的管理权,别人可以任意的修改你的成员变量
- 封装就是将数据隐藏起来,只能用此类的方法才可以读取或者设置数据,不可被外部任意修改是面向对象设计本质(将变化隔离)。这样降低了数据被误用的可能 (提高安全性和灵活性)封装原则
- 将不需要对外提供的内容都隐藏起来,把属性都隐藏,提供公共的方法对其访问
继承性
- Go语言认为虽然继承能够提升代码的复用性, 但是会让代码腐烂, 并增加代码的复杂度.
- 所以go语言坚持了〃组合优于继承〃的原则, Go语言中所谓的继承其实是利用组合实现的(匿名结构体属性)
go
package main
import "fmt"
type Person struct {
name string
age int
}
type Student struct {
Person // 学生继承了人的特性
score int
}
type Teacher struct {
Person // 所谓的组合
Title string
}
func main() {
s := Student{Person{"lnj", 18}, 99}
//fmt.Println(s.Person.name)
fmt.Println(s.name) // 两种方式都能访问
//fmt.Println(s.Person.age)
fmt.Println(s.age) // 两种方式都能访问
fmt.Println(s.score)
}- 在Go语言中子类不仅仅能够继承父类的属性, 还能够继承父类的方法
go
package main
import "fmt"
type Person struct {
name string
age int
}
// 父类方法
func (p Person) say() {
fmt.Println("name is ", p.name, "age is ", p.age)
}
type Student struct {
Person
score float32
}
func main() {
stu := Student{Person{"zs", 18}, 59.9}
stu.say()
}- 如果子类有和父类同名的方法, 那么我们称之为方法重写
go
package main
import "fmt"
type Person struct {
name string
age int
}
// 父类方法
func (p Person) say() {
fmt.Println("name is ", p.name, "age is ", p.age)
}
type Student struct {
Person
score float32
}
// 子类方法
func (s Student) say() {
fmt.Println("name is ", s.name, "age is ", s.age, "score is ", s.score)
}
func main() {
stu := Student{Person{"zs", 18}, 59.9}
// 和属性一样, 访问时采用就近原则
stu.say()
// 和属性一样, 方法同名时可以通过指定父类名称的方式, 访问父类方法
stu.Person.say()
}- 无论是属性继承还是方法继承, 都只能子类访问父类, 不能父类访问子类
多态性
- 多态的主要好处就是简化了编程接口。它允许在类和类之间重用一些习惯性的命名,而不用为每一个新的方法命名一个新名字。这样,编程接口就是一些抽象的行为的集合,从而和实现接口的类 区分开来。
- 多态也使得代码可以分散在不同的对象中而不用试图在一个方法中考虑到所有可能的对象。这样使得您的代码扩展性和复用性更好一些。当一个新的情景出现时,您无须对现有的代码进行改动,而只需要增加一个新的类和新的同名方法。
go
package main
import "fmt"
// 1.定义接口
type Animal interface {
Eat()
}
type Dog struct {
name string
age int
}
// 2.实现接口方法
func (d Dog) Eat() {
fmt.Println(d.name, "正在吃东西")
}
type Cat struct {
name string
age int
}
// 2.实现接口方法
func (c Cat) Eat() {
fmt.Println(c.name, "正在吃东西")
}
// 3.对象特有方法
func (c Cat) Special() {
fmt.Println(c.name, "特有方法")
}
func main() {
// 1.利用接口类型保存实现了所有接口方法的对象
var a Animal
a = Dog{"旺财", 18}
// 2.利用接口类型调用对象中实现的方法
a.Eat()
a = Cat{"喵喵", 18}
a.Eat()
// 3.利用接口类型调用对象特有的方法
//a.Special() // 接口类型只能调用接口中声明的方法, 不能调用对象特有方法
if cat, ok := a.(Cat); ok {
cat.Special() // 只有对象本身才能调用对象的特有方法
}
}
旺财 正在吃东西
喵喵 正在吃东西
喵喵 特有方法十二、异常处理
1.打印异常信息
- 方式一: 通过fmt包中的Errorf函数创建错误信息, 然后打印
- 方式二: 通过errors包中的New函数创建错误信息,然后打印
go
package main
import (
"errors"
"fmt"
)
func div(a, b int) (res int, err error) {
if b == 0 {
// 一旦传入的除数为0, 就会返回error信息
err = errors.New("除数不能为0")
} else {
res = a / b
}
return
}
func main() {
res, err := div(10, 5)
//res, err := div(10, 0)
if err != nil {
fmt.Println(err) // 除数不能为0
} else {
fmt.Println(res) // 2
}
}2.中断程序
注意:除非是不可恢复性、导致系统无法正常工作的错误, 否则不建议使用panic
3.恢复程序
- 在Go语言中我们可以通过defer和recover来实现panic异常的捕获, 让程序继续执行
十三、字符串与正则表达式
1.字符串
- 获取字符串长度 len(string)
- 注意: Go语言编码方式是UTF-8,在UTF-8中一个汉字占3个字节
- 如果字符串中包含中文, 又想精确的计算字符串中字符的个数而不是占用的字节, 那么必须先将字符串转换为rune类型数组
- Go语言中 byte 用于保存字符, rune 用于保存汉字

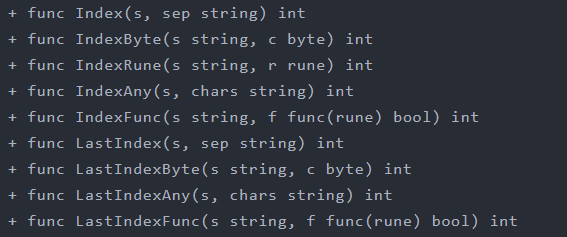
- 查找子串在字符串中出现的位置
go
package main
import (
"fmt"
"strings"
)
func main() {
// 查找`字符`在字符串中第一次出现的位置, 找不到返回-1
res := strings.IndexByte("hello 李南江", 'l')
fmt.Println(res) // 2
// 查找`汉字`OR`字符`在字符串中第一次出现的位置, 找不到返回-1
res = strings.IndexRune("hello 李南江", '李')
fmt.Println(res) // 6
res = strings.IndexRune("hello 李南江", 'l')
fmt.Println(res) // 2
// 查找`汉字`OR`字符`中任意一个在字符串中第一次出现的位置, 找不到返回-1
res = strings.IndexAny("hello 李南江", "wml")
fmt.Println(res) // 2
// 会把wmhl拆开逐个查找, w、m、h、l只要任意一个被找到, 立刻停止查找
res = strings.IndexAny("hello 李南江", "wmhl")
fmt.Println(res) // 0
// 查找`子串`在字符串第一次出现的位置, 找不到返回-1
res = strings.Index("hello 李南江", "llo")
fmt.Println(res) // 2
// 会把lle当做一个整体去查找, 而不是拆开
res = strings.Index("hello 李南江", "lle")
fmt.Println(res) // -1
// 可以查找字符也可以查找汉字
res = strings.Index("hello 李南江", "李")
fmt.Println(res) // 6
// 会将字符串先转换为[]rune, 然后遍历rune切片逐个取出传给自定义函数
// 只要函数返回true,代表符合我们的需求, 既立即停止查找
res = strings.IndexFunc("hello 李南江", custom)
fmt.Println(res) // 4
// 倒序查找`子串`在字符串第一次出现的位置, 找不到返回-1
res = strings.LastIndex("hello 李南江", "l")
fmt.Println(res) // 3
}
func custom(r rune) bool {
fmt.Printf("被调用了, 当前传入的是%c\n", r)
if r == 'o' {
return true
}
return false
}- 判断字符串中是否包含子串

go
package main
import (
"fmt"
"strings"
)
func main() {
// 查找`子串`在字符串中是否存在, 存在返回true, 不存在返回false
// 底层实现就是调用strings.Index函数
res := strings.Contains("hello 李南江", "llo")
fmt.Println(res) // true
// 查找`汉字`OR`字符`在字符串中是否存在, 存在返回true, 不存在返回false
// 底层实现就是调用strings.IndexRune函数
res = strings.ContainsRune("hello 李南江", 'l')
fmt.Println(res) // true
res = strings.ContainsRune("hello 李南江", '李')
fmt.Println(res) // true
// 查找`汉字`OR`字符`中任意一个在字符串中是否存在, 存在返回true, 不存在返回false
// 底层实现就是调用strings.IndexAny函数
res = strings.ContainsAny("hello 李南江", "wmhl")
fmt.Println(res) // true
// 判断字符串是否已某个字符串开头
res = strings.HasPrefix("lnj-book.avi", "nj")
fmt.Println(res) // false
// 判断字符串是否已某个字符串结尾
res = strings.HasSuffix("lnj-book.avi", ".avi")
fmt.Println(res) // true
}- 字符串比较

go
package main
import (
"fmt"
"strings"
)
func main() {
// 比较两个字符串大小, 会逐个字符地进行比较ASCII值
// 第一个参数 > 第二个参数 返回 1
// 第一个参数 < 第二个参数 返回 -1
// 第一个参数 == 第二个参数 返回 0
res := strings.Compare("bcd", "abc")
fmt.Println(res) // 1
res = strings.Compare("bcd", "bdc")
fmt.Println(res) // -1
res = strings.Compare("bcd", "bcd")
fmt.Println(res) // 0
// 判断两个字符串是否相等, 可以判断字符和中文
// 判断时会忽略大小写进行判断
res2 := strings.EqualFold("abc", "def")
fmt.Println(res2) // false
res2 = strings.EqualFold("abc", "abc")
fmt.Println(res2) // true
res2 = strings.EqualFold("abc", "ABC")
fmt.Println(res2) // true
res2 = strings.EqualFold("李南江", "李南江")
fmt.Println(res2) // true
}- 字符串转换
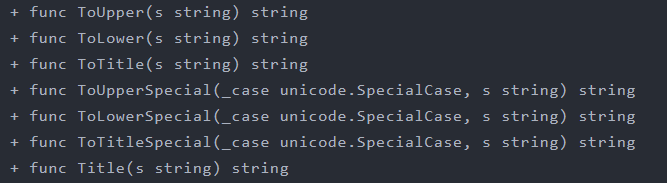
go
package main
import (
"fmt"
"strings"
)
func main() {
// 将字符串转换为小写
res := strings.ToLower("ABC")
fmt.Println(res) // abc
// 将字符串转换为大写
res = strings.ToUpper("abc")
fmt.Println(res) // ABC
// 将字符串转换为标题格式, 大部分`字符`标题格式就是大写
res = strings.ToTitle("hello world")
fmt.Println(res) // HELLO WORLD
// 将单词首字母变为大写, 其它字符不变
// 单词之间用空格OR特殊字符隔开
res = strings.Title("hello world")
fmt.Println(res) // Hello World
}- 字符串拆合
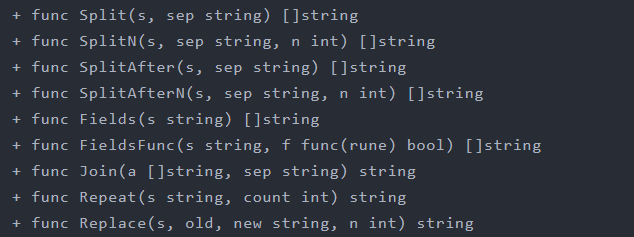
go
package main
import (
"fmt"
"strings"
)
func main() {
// 按照指定字符串切割原字符串
// 用,切割字符串
arr1 := strings.Split("a,b,c", ",")
fmt.Println(arr1) // [a b c]
arr2 := strings.Split("ambmc", "m")
fmt.Println(arr2) // [a b c]
// 按照指定字符串切割原字符串, 并且指定切割为几份
// 如果最后一个参数为0, 那么会范围一个空数组
arr3 := strings.SplitN("a,b,c", ",", 2)
fmt.Println(arr3) // [a b,c]
arr4 := strings.SplitN("a,b,c", ",", 0)
fmt.Println(arr4) // []
// 按照指定字符串切割原字符串, 切割时包含指定字符串
arr5 := strings.SplitAfter("a,b,c", ",")
fmt.Println(arr5) // [a, b, c]
// 按照指定字符串切割原字符串, 切割时包含指定字符串, 并且指定切割为几份
arr6 := strings.SplitAfterN("a,b,c", ",", 2)
fmt.Println(arr6) // [a, b,c]
// 按照空格切割字符串, 多个空格会合并为一个空格处理
arr7 := strings.Fields("a b c d")
fmt.Println(arr7) // [a b c d]
// 将字符串转换成切片传递给函数之后由函数决定如何切割
// 类似于IndexFunc
arr8 := strings.FieldsFunc("a,b,c", custom)
fmt.Println(arr8) // [a b c]
// 将字符串切片按照指定连接符号转换为字符串
sce := []string{"aa", "bb", "cc"}
str1 := strings.Join(sce, "-")
fmt.Println(str1) // aa-bb-cc
// 返回count个s串联的指定字符串
str2 := strings.Repeat("abc", 2)
fmt.Println(str2) // abcabc
// 第一个参数: 需要替换的字符串
// 第二个参数: 旧字符串
// 第三个参数: 新字符串
// 第四个参数: 用新字符串 替换 多少个旧字符串
// 注意点: 传入-1代表只要有旧字符串就替换
// 注意点: 替换之后会生成新字符串, 原字符串不会受到影响
str3 := "abcdefabcdefabc"
str4 := strings.Replace(str3, "abc", "mmm", -1)
fmt.Println(str3) // abcdefabcdefabc
fmt.Println(str4) // mmmdefmmmdefmmm
}
func custom(r rune) bool {
fmt.Printf("被调用了, 当前传入的是%c\n", r)
if r == ',' {
return true
}
return false
}- 字符串清理
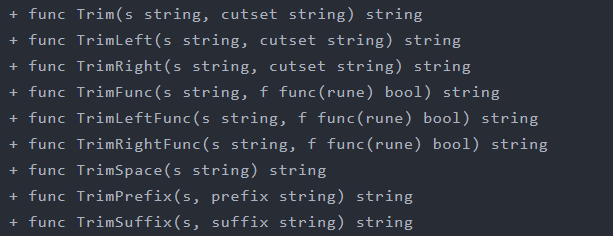
go
package main
import (
"fmt"
"strings"
)
func main() {
// 去除字符串两端指定字符
str1 := strings.Trim("!!!abc!!!def!!!", "!")
fmt.Println(str1) // abc!!!def
// 去除字符串左端指定字符
str2 := strings.TrimLeft("!!!abc!!!def!!!", "!")
fmt.Println(str2) // abc!!!def!!!
// 去除字符串右端指定字符
str3 := strings.TrimRight("!!!abc!!!def!!!", "!")
fmt.Println(str3) // !!!abc!!!def
// // 去除字符串两端空格
str4 := strings.TrimSpace(" abc!!!def ")
fmt.Println(str4) // abc!!!def
// 按照方法定义规则,去除字符串两端符合规则内容
str5 := strings.TrimFunc("!!!abc!!!def!!!", custom)
fmt.Println(str5) // abc!!!def
// 按照方法定义规则,去除字符串左端符合规则内容
str6 := strings.TrimLeftFunc("!!!abc!!!def!!!", custom)
fmt.Println(str6) // abc!!!def!!!
// 按照方法定义规则,去除字符串右端符合规则内容
str7 := strings.TrimRightFunc("!!!abc!!!def!!!", custom)
fmt.Println(str7) // !!!abc!!!def
// 取出字符串开头的指定字符串
str8 := strings.TrimPrefix("lnj-book.avi", "lnj-")
fmt.Println(str8) // book.avi
// 取出字符串结尾的指定字符串
str9 := strings.TrimSuffix("lnj-book.avi", ".avi")
fmt.Println(str9) // lnj-book
}
func custom(r rune) bool {
fmt.Println(r)
if r == ',' {
return true
}
return false
}2.正则表达式
- Go语言中正则表达式使用步骤
- 1.创建一个正则表达式匹配规则对象
- 2.利用正则表达式匹配规则对象匹配指定字符串
go
package main
import (
"fmt"
"regexp"
)
func main() {
// 创建一个正则表达式匹配规则对象
// reg := regexp.MustCompile(规则字符串)
// 利用正则表达式匹配规则对象匹配指定字符串
// 会将所有匹配到的数据放到一个字符串切片中返回
// 如果没有匹配到数据会返回nil
// res := reg.FindAllString(需要匹配的字符串, 匹配多少个)
str := "Hello 李南江 1232"
reg := regexp.MustCompile("2")
res := reg.FindAllString(str, -1)
fmt.Println(res) // [2 2]
res = reg.FindAllString(str, 1)
fmt.Println(res) // [2]
}- 匹配电话号码
go
package main
import (
"fmt"
"regexp"
)
func main() {
res2 := findPhoneNumber("13554499311")
fmt.Println(res2) // true
res2 = findPhoneNumber("03554499311")
fmt.Println(res2) // false
res2 = findPhoneNumber("1355449931")
fmt.Println(res2) // false
}
func findPhoneNumber(str string) bool {
// 创建一个正则表达式匹配规则对象
reg := regexp.MustCompile("^1[1-9]{10}")
// 利用正则表达式匹配规则对象匹配指定字符串
res := reg.FindAllString(str, -1)
fmt.Println(res)
if res == nil {
return false
}
return true
}- 匹配Email
go
package main
import (
"fmt"
"regexp"
)
func main() {
res1 := findEmail("123@qq.com")
fmt.Println(res1) // true
res2 := findEmail("ab?de@qq.com")
fmt.Println(res2) // false
res3 := findEmail("123@qqcom")
fmt.Println(res3) // false
}
func findEmail(str string) bool {
reg := regexp.MustCompile("^[a-zA-Z0-9_]+@[a-zA-Z0-9]+\\.[a-zA-Z0-9]+")
res := reg.FindAllString(str, -1)
if res == nil {
return false
}
return true
}3.时间和日期函数
- 获取当前时间
- 获取年月日时分秒
- 格式化时间
go
package main
import (
"fmt"
"time"
)
func main() {
//1.
var t1 time.Time = time.Now()
// 2018-09-27 17:25:11.653198 +0800 CST m=+0.009759201
fmt.Println(t1)
//2.
var t time.Time = time.Now()
fmt.Println(t.Year())
fmt.Println(t.Month())
fmt.Println(t.Day())
fmt.Println(t.Hour())
fmt.Println(t.Minute())
fmt.Println(t.Second())
//3.
var t3 time.Time = time.Now()
fmt.Printf("当前的时间是: %d-%d-%d %d:%d:%d\n", t3.Year(),
t3.Month(), t3.Day(), t3.Hour(), t3.Minute(), t3.Second())
var dateStr = fmt.Sprintf("%d-%d-%d %d:%d:%d", t3.Year(),
t3.Month(), t3.Day(), t3.Hour(), t3.Minute(), t3.Second())
fmt.Println("当前的时间是:", dateStr)
//4.
var t4 time.Time = time.Now()
// 2006/01/02 15:04:05这个字符串是Go语言规定的, 各个数字都是固定的
// 字符串中的各个数字可以只有组合, 这样就能按照需求返回格式化好的时间
str1 := t4.Format("2006/01/02 15:04:05")
fmt.Println(str1)
str2 := t4.Format("2006/01/02")
fmt.Println(str2)
str3 := t4.Format("15:04:05")
fmt.Println(str3)
}- 时间常量
- 一般用于指定时间单位, 和休眠函数配合使用
- 例如: 100毫秒, 100 *time.Millisecond

- 获取当前时间戳
- Unix秒
- UnixNano纳秒
- 一般用于配合随机函数使用, 作为随机函数随机种子
十四、操作文件
1.文件的打开与关闭
- Open函数
- func Open(name string) (file *File, err error)
- Open打开一个文件用于读取
- Close函数
- func (f *File) Close() error
- Close关闭文件f
2.文件读取
- Read函数(不带缓冲区去读)
- func (f *File) Read(b \[\]byte) (n int, err error)
- Read方法从f中读取最多len(b)字节数据并写入b
go
package main
import (
"fmt"
"os"
)
func main() {
// 1.打开一个文件
// 注意: 文件不存在不会创建, 会报错
// 注意: 通过Open打开只能读取, 不能写入
fp, err := os.Open("E:/Go/1.txt")
if err != nil {
fmt.Println(err)
} else {
fmt.Println(fp)
}
// 2.关闭一个文件
defer func() {
err = fp.Close()
if err != nil {
fmt.Println(err)
}
}()
//3.读取指定指定字节个数据
//注意点: \n也会被读取进来
buf := make([]byte, 50)
count, err := fp.Read(buf)
if err != nil {
fmt.Println(err)
} else {
fmt.Println(count)
fmt.Println(string(buf))
}
// 4.读取文件中所有内容, 直到文件末尾为止
// buf := make([]byte, 10)
// for {
// count, err := fp.Read(buf)
// // 注意: 这行代码要放到判断EOF之前, 否则会出现少读一行情况
// fmt.Print(string(buf[:count]))
// if err == io.EOF {
// break
// }
// }
}- ReadBytes和ReadString函数(带缓冲区去读)
- func (b *Reader) ReadBytes(delim byte) (line \[\]byte, err error)
- ReadBytes读取直到第一次遇到delim字节
- func (b *Reader) ReadString(delim byte) (line string, err error)
- ReadString读取直到第一次遇到delim字节
go
package main
import (
"bufio"
"fmt"
"os"
)
func main() {
// 1.打开一个文件
// 注意: 文件不存在不会创建, 会报错
// 注意: 通过Open打开只能读取, 不能写入
fp, err := os.Open("E:/Go/1.txt")
if err != nil {
fmt.Println(err)
} else {
fmt.Println(fp)
}
// 2.关闭一个文件
defer func() {
err = fp.Close()
if err != nil {
fmt.Println(err)
}
}()
// 3.读取一行数据
// 创建读取缓冲区, 默认大小4096
r := bufio.NewReader(fp)
buf, err := r.ReadBytes('\n')
//buf, err := r.ReadString('\n')
if err != nil {
fmt.Println(err)
} else {
fmt.Println(string(buf))
}
// 4.读取文件中所有内容, 直到文件末尾为止
// r := bufio.NewReader(fp)
// for {
// //buf, err := r.ReadBytes('\n')
// buf, err := r.ReadString('\n')
// fmt.Print(string(buf))
// if err == io.EOF {
// break
// }
// }
}3.文件的创建和写入
- Create函数
- func Create(name string) (file *File, err error)
- Create采用模式0666(任何人都可读写,不可执行)创建一个名为name的文件
- 如果文件存在会覆盖原有文件
- Write函数
- func (f *File) Write(b \[\]byte) (n int, err error)
- 将指定字节数组写入到文件中
- WriteString函数
- func (f *File) WriteString(s string) (ret int, err error)
- 将指定字符串写入到文件中

十五、并发编程
1.并发编程基本概念
- 什么是串行?
- "串行"(Serial)是一种数据传输方式,指的是数据以位一次一个的方式进行发送和接收。比如说,一个8位的字节,将通过8次单独的脉冲来交换,数据一位位按顺序串行传输,这就是串行传输。串行传输的优势是可以通过简单的数据线来实现,节省了成本,并且能跨越较长的距离。但其缺点是数据传输速度相对较慢。
- 在计算机中, 同一时刻, 只能有一条指令, 在一个CPU上执行, 后面的指令必须等到前面指令执行完才能执行, 就是串行
- 什么是并行?
- "并行"(Parallel)是一种数据传输方式,指多个数据位同时通过多条通道或数据线进行传输。假设你有一个8位的字节,你可以同时在8条通道上发送这8位,大大提高了数据传输的速度。这就是并行数据传输。这种方式相对于串行方式,利用的是空间换取时间,通过增加传输线实现了高速数据传输。然而并行传输也有其缺点: 首先,它需要更多的物理线路,这就增加了布线的复杂性和成本;其次,由于电磁干扰的原因,当距离较远时可能会导致数据出错,因此并行数据传输通常被限制在短距离,例如在电脑内部或者局部网络中使用。
- 在计算机中, 同一时刻, 有多条指令, 在多个CPU上执行, 就是并行
- 什么是并发?
- "并发"是指一个时间段内,两个或更多的任务在单个处理器上交替进行。尽管任务的执行可能会一种重叠的行为,但是在任何给定的时刻,处理器只执行一个任务。例如,在某些操作系统中,我们可以同时打开多个应用程序,这些应用程序都在运行,看起来是同时运行,但实际上是由于计算机的高速操作和任务切换,让我们感觉它们都在同时运行。
- 并发是伪并行, 就好比银行只有1个窗口, 有3个人要办事, 那么没轮到后面的人时, 后面的人可以用拖鞋先排队, 去吃个早餐,买个东西啥的, 感觉差不多要到自己时再回来办事
- 在计算机中, _同一时刻, 只能有一条指令, 在一个CPU上执行, 但是CPU会快速的在多条指令之间轮询执行_就是并发
- 什么是程序?
- 程序是指将编译型语言编写好的代码通过编译工具编译之后存储在硬盘上的一个二进制文件, 会占用磁盘空间, 但不会占用系统资源
- 例如我们通过C++编写了一个聊天程序, 然后通过C++编译器将编写好的代码编译成一个二进制的文件, 那么这个二进制的文件就是一个程序
- 什么是进程?
- 进程是指程序在操作系统中的一次执行过程, 是系统进行资源分配和调度的基本单位
- 程序可以在系统中开启多个进程互不影响
- 所以程序和进程的关系是1:N, 所以多个进程的空间是独立的
- 什么是线程?
- 线程是指进程中的一个执行实例, 是程序执行的最小单元, 它是比进程更小的能独立运行的基本单位
- 一个进程中至少有一个线程, 这个线程我们称之为主线程
- 一个进程中除了主线程以外, 我们还可以创建和销毁多个线程
- 什么是协程?
- "协程"(Coroutine)则是一种计算机程序的组件,可以更方便地用来进行多任务处理,尤其是在I/O密集和事件驱动的程序中。协程的特性在于它允许多个进入点和挂起、恢复等操作。协程与线程非常相似,但是协程是完全在用户空间中实现的,所以更轻量级,切换的开销较小,并且协程的调度完全由用户来控制,这使得它在一些特殊的应用场景(例如异步I/O、事件循环等)能够得到更好的性能。
2.Go并发
- Go在语言级别支持协程(多数语言在语法层面并不直接支持协程), 叫做goroutine。
- 人们把Go语言称之为21世纪的C语言. 第一是因为Go语言设计简单, 第二是因为21世纪最重要的就是并行程序设计.而Go从语言层面就支持并发和并行。
go
package main
import (
"fmt"
"time"
)
func sing() {
for i := 0; i < 10; i++ {
fmt.Println("我在唱歌")
time.Sleep(time.Millisecond)
}
}
func dance() {
for i := 0; i < 10; i++ {
fmt.Println("我在跳舞---")
time.Sleep(time.Millisecond)
}
}
func main() {
// 串行: 必须先唱完歌才能跳舞
//sing()
//dance()
// 并行: 可以边唱歌, 边跳舞
// 注意点: 主线程不能死, 否则程序就退出了
go sing() // 开启一个协程
go dance() // 开启一个协程
}- runtime包中常用的函数
- Gosched:使当前go程放弃处理器,以让其它go程运行。
go
package main
import (
"fmt"
"runtime"
)
func main() {
go func(s string) {
for i := 0; i < 2; i++ {
fmt.Println(s)
}
}("hhhh")
// 主协程
for i := 0; i < 2; i++ {
runtime.Gosched() //主协程释放CPU时间片,此时上面的协程得以执行
fmt.Println("main") //CPU时间片回来后继续执行
}
}- Goexit: 终止调用它的go程, 其它go程不会受影响。
go
package main
import (
"fmt"
"runtime"
"time"
)
func main() {
go func() {
defer fmt.Println("A.defer")
func() {
defer fmt.Println("B.defer")
runtime.Goexit() // 结束当前协程
defer fmt.Println("C.defer")
fmt.Println("B")
}()
fmt.Println("A")
}()
time.Sleep(time.Second) //睡一会儿,不让主协程很快结束
}【Go】并发编程之runtime包及其常用方法_runtime.goos_想变厉害的大白菜的博客-CSDN博客
3.高并发的核心工具:协程
1、 线程是系统分配CPU资源的单位。协程本身并不能占有CPU或者内存资源。
2、runtime中与协程有关的主要有3个结构体:G代表协程,M代表线程,P代表处理器
3、窃取式协程调度的关键是P结构体,P结构体持有了一个线程本地队列,存放需要被调度的协程。相比全局队列, 本地队列的锁冲突情况大大降低了。
4、抢占式调度解决了协程饥饿问题。由于种种原因,协程切换的时机不容易获得,导致很多协程长时间无法调用。 抢占式调度主动释放协程,使得协程饥饿的情况大大降低了。
十六、多线程同步
- 互斥锁
- 互斥锁的本质是当一个goroutine访问的时候, 其它goroutine都不能访问。
- 这样就能实现资源同步, 但是在避免资源竞争的同时也降低了程序的并发性能. 程序由原来的并发执行变成了串行。
- 案例:
- 有一个打印函数, 用于逐个打印字符串中的字符, 有两个人都开启了goroutine去打印。
- 如果没有添加互斥锁, 那么两个人都有机会输出自己的内容。
- 如果添加了互斥锁, 那么会先输出某一个的, 输出完毕之后再输出另外一个人的。
go
package main
import (
"fmt"
"sync"
"time"
)
// 创建一把互斥锁
var lock sync.Mutex
func printer(str string) {
// 让先来的人拿到锁, 把当前函数锁住, 其它人都无法执行
// 上厕所关门
lock.Lock()
for _, v := range str {
fmt.Printf("%c", v)
time.Sleep(time.Millisecond * 500)
}
// 先来的人执行完毕之后, 把锁释放掉, 让其它人可以继续使用当前函数
// 上厕所开门
lock.Unlock()
}
func person1() {
printer("hello")
}
func person2() {
printer("world")
}
func main() {
go person1()
go person2()
for {
}
}go语言多线程学习笔记------互斥锁_go 线程锁_浅see_you的博客-CSDN博客
十七、管道
为了保持主线程不挂掉, 我们都会在最后写上一个死循环或者写上一个定时器来实现等待goroutine执行完毕。
上述实现并发的代码中为了解决生产者消费者资源同步问题, 我们利用加锁来解决, 但是这仅仅是一对一的情况, 如果是一对多或者多对多, 上述代码还是会出现问题。
综上所述, 企业开发中需要一种更牛X的技术来解决上述问题, 那就是管道(Channel)。
管道的本质是一个队列(先进先出)。
管道的线程是安全的,也就是自带锁定功能。
声明:var 变量名 chan 类型
初始化:mych:=make(chan 类型,容量)
channel和切片、字典一样,必须make后才能使用,也都是应用类型。
注意点:
- 管道中只能存放声明的数据类型, 不能存放其它数据类型。
- 管道中如果已经没有数据, 再取就会报错。
- 如果管道中数据已满, 再写入就会报错。
管道的关闭和遍历
go
package main
import "fmt"
func main() {
// 1.创建一个管道
mych := make(chan int, 3)
// 2.往管道中存入数据
mych <- 666
mych <- 777
mych <- 888
// 3.遍历管道
//for i:=0; i<len(mych); i++{
// fmt.Println(<-mych) // 这种的输出结果不正确,因为长度在一直变化
//}
// 3.写入完数据之后先关闭管道
// 注意点: 管道关闭之后只能读不能写
close(mych)
//mych<- 999 // 报错
// 4.遍历管道
// 利用for range遍历, 必须先关闭管道, 否则会报错(造成死锁)
//for value := range mych{
// fmt.Println(value)
//}
// close主要用途:
// 在企业开发中我们可能不确定管道有还没有有数据, 所以我们可能一直获取
// 但是我们可以通过ok-idiom模式判断管道是否关闭, 如果关闭会返回false给ok(前提是已经关闭的channel)
for {
if num, ok := <-mych; ok {
fmt.Println(num)
} else {
break
}
}
fmt.Println("数据读取完毕")
}Channel阻塞现象
- 单独在主线程中操作管道, 写满了会报错, 没有数据去获取也会报错。
- 只要在协程中操作管道过, 写满了就会阻塞, 没有就数据去获取也会阻塞。
无缓冲Channel和有缓冲Channel
- 有缓冲管道具备异步的能力(写几个读一个或读几个)
- 无缓冲管道具备同步的能力(写一个读一个)
单向管道和双向管道
- 默认情况下所有管道都是双向了(可读可写)
- 但是在企业开发中, 我们经常需要用到将一个管道作为参数传递
- 在传递的过程中希望对方只能单向使用, 要么只能写,要么只能读
- 双向管道
- var myCh chan int = make(chan int, 0)
- 单向管道
- var myCh chan<- int = make(chan<- int, 0)
- var myCh <-chan int = make(<-chan int, 0)
- 注意点:
- 双向管道可以自动转换为任意一种单向管道。
- 单向管道不能转换为双向管道。
go
package main
import "fmt"
func main() {
// 1.定义一个双向管道
var myCh chan int = make(chan int, 5)
// 2.将双向管道转换单向管道
var myCh2 chan<- int
myCh2 = myCh
fmt.Println(myCh2)
var myCh3 <-chan int
myCh3 = myCh
fmt.Println(myCh3)
// 3.双向管道,可读可写
myCh <- 1
myCh <- 2
myCh <- 3
fmt.Println(<-myCh)
// 3.只写管道,只能写, 不能读
// myCh2<-666
// fmt.Println(<-myCh2)
// 4.指读管道, 只能读,不能写
fmt.Println(<-myCh3)
//myCh3<-666
// 注意点: 管道之间赋值是地址传递, 以上三个管道底层指向相同容器
}十八、定时器
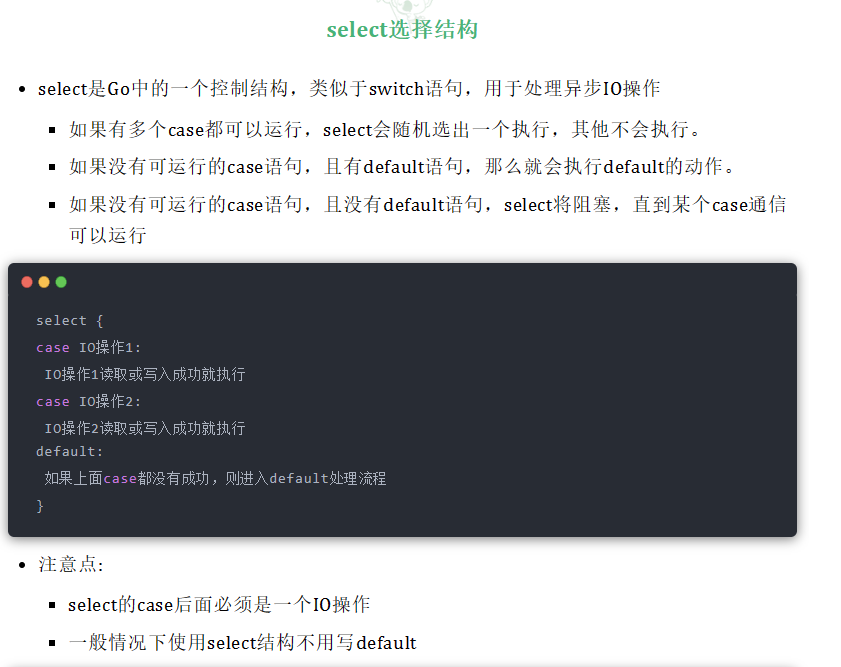
go
package main
import (
"fmt"
"time"
)
func main() {
ch := make(chan int)
timeout := make(chan bool)
// 启动一个 Goroutine 执行操作
go func() {
time.Sleep(2 * time.Second)
ch <- 42
}()
// 使用 select 语句进行超时控制
select {
case result := <-ch:
fmt.Println("接收到结果:", result)
case <-timeout:
fmt.Println("超时")
}
}select应用场景
- 实现多路监听。
- 实现超时处理。

go
package main
import (
"fmt"
"time"
)
func main() {
start := time.Now()
fmt.Println("开始时间", start)
timer := time.NewTimer(time.Second * 3)//定时
fmt.Println("读取之前代码被执行")
end := <-timer.C // 系统写入数据之前会阻塞
fmt.Println("读取之后代码被执行")
fmt.Println("结束时间", end)
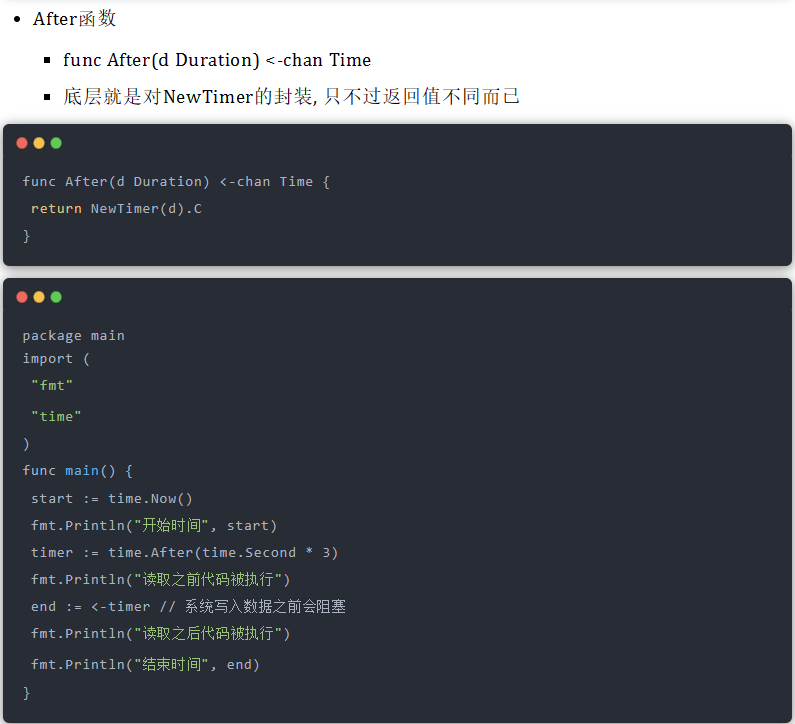
}
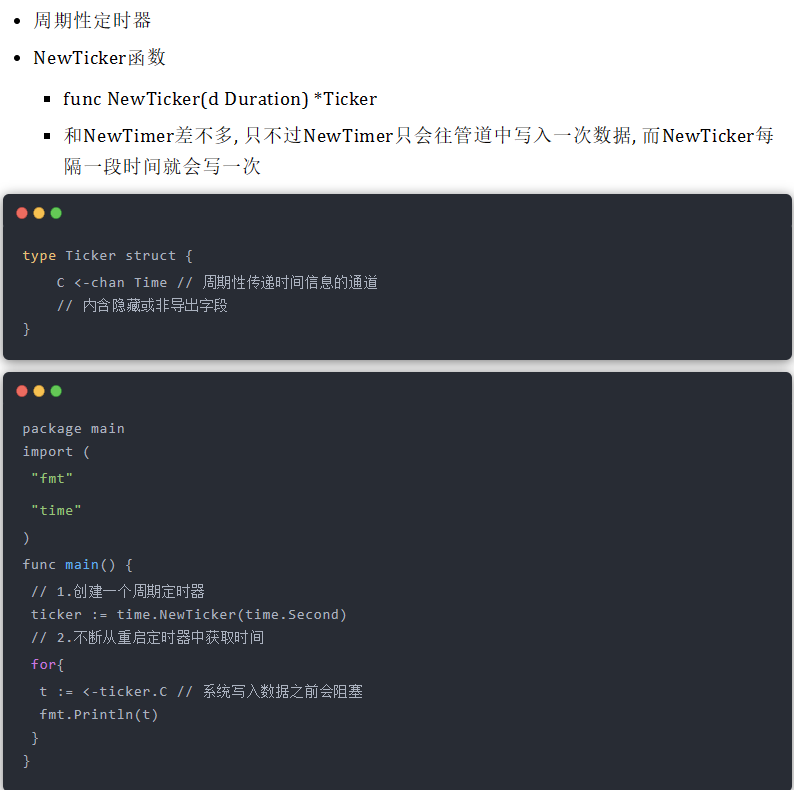
十九、指针操作
go
package main
import "fmt"
func main() {
//数组指针,指向数组的指针
var n = [3]int{1, 2, 3}
var p *[3]int = &n
//指针数组,数组成员的类型是指针
var q = [3]*int{&n[0], &n[1], &n[2]}
fmt.Println("指针数组...")
for i, v := range q {
fmt.Println(i, v, *v)
}
fmt.Println("数组指针...")
for i, v := range p {
fmt.Println(i, &v, v)
}
}
指针数组...
0 0xc0000aa060 1
1 0xc0000aa068 2
2 0xc0000aa070 3
数组指针...
0 0xc0000a6058 1
1 0xc0000a6058 2
2 0xc0000a6058 3数组指针中的地址是相同的,因为它们指向同一个数组的起始位置。而指针数组中的每个元素是独立的指针,它们存储了不同的地址。
go
package main
import "fmt"
func main() {
// 1.定义一个切片
var sce []int = []int{1, 3, 5}
// 2.打印切片的地址
// 切片变量中保存的地址, 也就是指向的那个数组的地址 sce = 0xc0420620a0
fmt.Printf("sce = %p\n", sce)
fmt.Println(sce) // [1 3 5]
// 切片变量自己的地址, &sce = 0xc04205e3e0
fmt.Printf("&sce = %p\n", &sce)
fmt.Println(&sce) // &[1 3 5]
// 3.定义一个指向切片的指针
var p *[]int
// 因为必须类型一致才能赋值, 所以将切片变量自己的地址给了指针
p = &sce
// 4.打印指针保存的地址
// 直接打印p打印出来的是保存的切片变量的地址 p = 0xc04205e3e0
fmt.Printf("p = %p\n", p)
fmt.Println(p) // &[1 3 5]
// 打印*p打印出来的是切片变量保存的地址, 也就是数组的地址 *p = 0xc0420620a0
fmt.Printf("*p = %p\n", *p)
fmt.Println(*p) // [1 3 5]
// 5.修改切片的值
// 通过*p找到切片变量指向的存储空间(数组), 然后修改数组中保存的数据
(*p)[1] = 666
fmt.Println(sce[1])
}

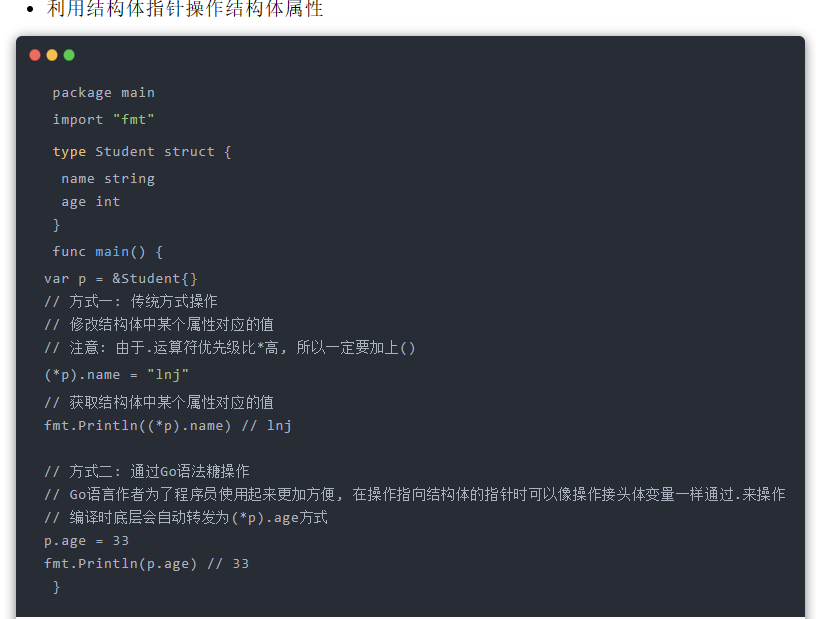
**结构体指针表示指向结构体实例的指针。**它是指向结构体在内存中分配的位置的引用。可以使用 new 关键字或 &运算符创建结构体指针。
type Person struct {
Name string
Age int
}
var p *Person = new(Person) // 使用 new 关键字创建结构体指针
p.Name = "John Doe"
p.Age = 30
**指针结构体是指包含指向其他类型的指针的结构体。**也就是说,指针结构体的字段是指向其他类型的指针。指针结构体自身不是指针类型,而是一个结构体类型。
type Person struct {
Name *string
Age *int
}
name := "John Doe"
age := 30
p := Person{
Name: &name,
Age: &age,
}
注意上述示例中,Name 和 Age 字段都是指向字符串和整数的指针。
因此,结构体指针和指针结构体在概念上有所区别。结构体指针指向结构体实例本身,而指针结构体的字段是指向其他类型的指针。
当使用结构体指针时,可以直接通过指针访问和修改结构体的字段。而在指针结构体中,需要通过解引用指针来访问和修改字段值。
总结起来:结构体指针指向结构体对象,而指针结构体包含指向其他类型的指针。它们在用途和操作上有所不同,尽管有时可以使用类似的语法。