
本文主要分享如何使用 vLLM 实现大模型推理服务。
1. 概述
大模型推理有多种方式比如
- 最基础的 HuggingFace Transformers
- TGI
- vLLM
- Triton + TensorRT-LLM
- ...
其中,热度最高的应该就是 vLLM,性能好的同时使用也非常简单,本文就分享一下如何使用 vLLM 来启动大模型推理服务。
根据 vLLM 官方博客 vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention所说:
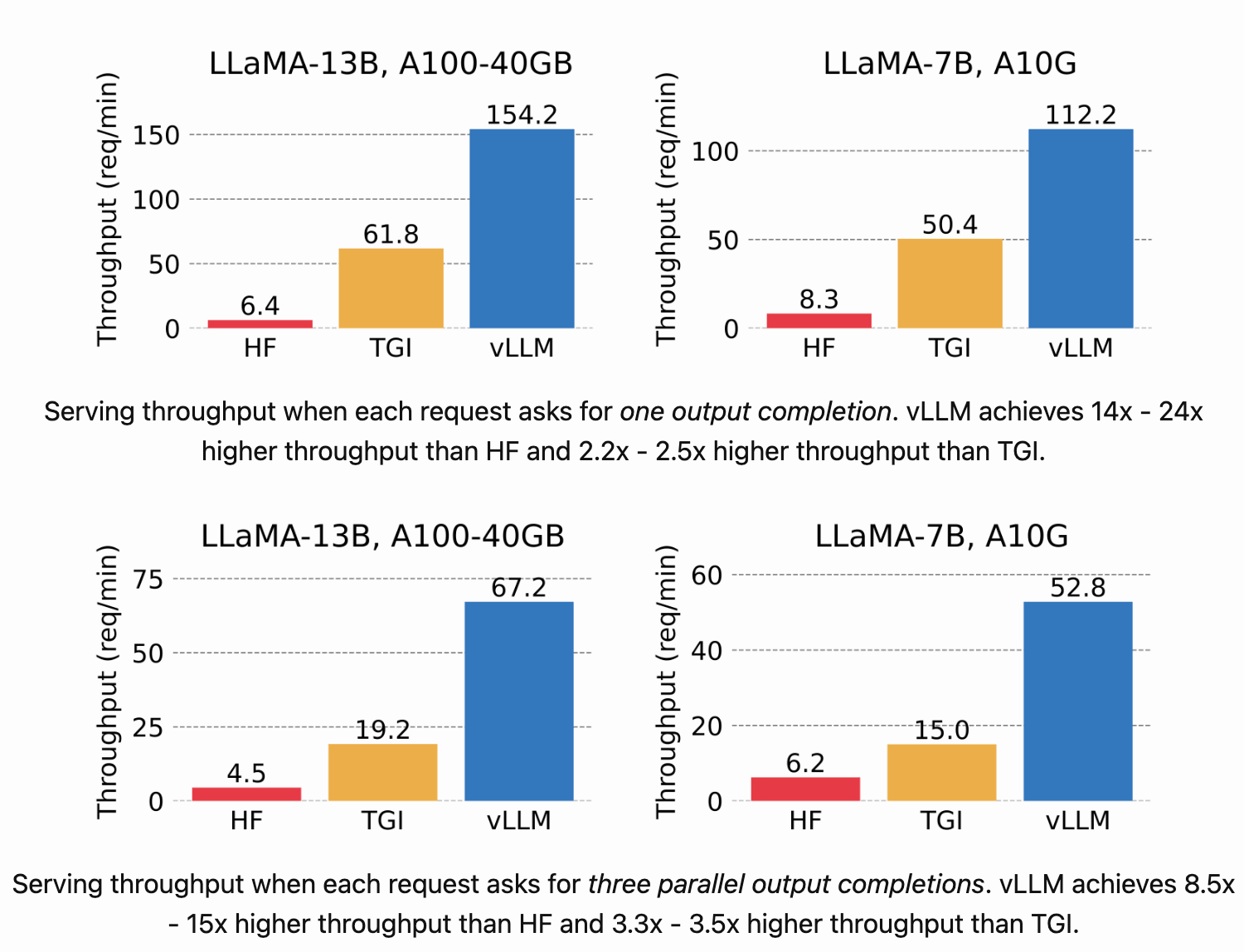
进行了 NVIDIA A10 GPU 上推理 LLaMA-7 B 和 在 NVIDIA A100 GPU(40 GB)上推理 LLaMA-13 B 两个实验,在吞吐量上 vLLM 比最基础的 HuggingFace Transformers 高 24 倍,比 TGI 高 3.5 倍。
2.安装 vLLM
首先要准备一个 GPU 环境,可以参考这篇文章:GPU 环境搭建指南:如何在裸机、Docker、K8s 等环境中使用 GPU
需要保证宿主机上可以正常执行 nvidia-smi 命令,就像这样:
bash
root@test:~# nvidia-smi
Thu Jul 18 10:52:01 2024
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.147.05 Driver Version: 525.147.05 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA A40 Off | 00000000:00:07.0 Off | 0 |
| 0% 45C P0 88W / 300W | 40920MiB / 46068MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 1 NVIDIA A40 Off | 00000000:00:08.0 Off | 0 |
| 0% 47C P0 92W / 300W | 40916MiB / 46068MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 1847616 C tritonserver 480MiB |
| 0 N/A N/A 2553571 C python3 40426MiB |
| 1 N/A N/A 1847616 C tritonserver 476MiB |
| 1 N/A N/A 2109313 C python3 40426MiB |
+-----------------------------------------------------------------------------+安装 conda
为了避免干扰,这里使用 conda 单独创建一个 Python 虚拟环境安装 vLLM。
使用下面的命令可以快速安装最新的 miniconda,也可以去官方下载压缩包,解压并配置到 PATH 变量。
Bash
mkdir -p ~/miniconda3
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda3/miniconda.sh
bash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3
rm -rf ~/miniconda3/miniconda.sh然后初始化
Bash
# 根据使用的不同 shell 选择一个命令执行
~/miniconda3/bin/conda init bash
~/miniconda3/bin/conda init zsh激活
Bash
source ~/.bashrc创建虚拟环境安装 vLLM
创建虚拟环境并激活
Bash
conda create -n vllm_py310 python=3.10
conda activate vllm_py310
# 配置 pip 源
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple/
pip config set install.trusted-host pypi.tuna.tsinghua.edu.cn
# 在虚拟环境中安装 vllm 0.4.2 版本
pip install vllm==0.4.23. 准备模型
一般模型都会发布到 HuggingFace,不过国内网络情况,推荐到 ModelScope 下载。
主流的模型 vLLM 都是支持的,具体列表可以查看官方文档:vllm-supported-models
这里使用 Qwen1.5-1.8B-Chat 进行测试。
使用 git lfs 方式下载:
bash
# 安装并初始化 git-lfs
apt install git-lfs -y
git lfs install
# 下载模型
git lfs clone https://www.modelscope.cn/qwen/Qwen1.5-1.8B-Chat.git完整内容如下:
bash
root@j99cloudvm:~/lixd/models# ls -lhS Qwen1.5-1.8B-Chat/
total 3.5G
-rw-r--r-- 1 root root 3.5G Jul 18 11:20 model.safetensors
-rw-r--r-- 1 root root 6.8M Jul 18 11:08 tokenizer.json
-rw-r--r-- 1 root root 2.7M Jul 18 11:08 vocab.json
-rw-r--r-- 1 root root 1.6M Jul 18 11:08 merges.txt
-rw-r--r-- 1 root root 7.2K Jul 18 11:08 LICENSE
-rw-r--r-- 1 root root 4.2K Jul 18 11:08 README.md
-rw-r--r-- 1 root root 1.3K Jul 18 11:08 tokenizer_config.json
-rw-r--r-- 1 root root 662 Jul 18 11:08 config.json
-rw-r--r-- 1 root root 206 Jul 18 11:08 generation_config.json
-rw-r--r-- 1 root root 51 Jul 18 11:08 configuration.json这个目录包含了一个大模型的相关文件。以下是每个文件的作用简要说明:
model.safetensors:这是大模型的主要文件,包含了模型的权重。tokenizer.json:这个文件包含了分词器(Tokenizer)的配置和词汇表。分词器用于将输入文本转换为模型可以处理的格式,通常是数字 ID。tokenizer_config.json:这个文件包含了分词器的配置选项,如分词器的类型、参数设置等。config.json:这个文件包含了模型的配置参数,定义了模型的结构和训练过程中的一些设置。它通常包括层数、隐藏单元数、激活函数等参数。generation_config.json:这个文件包含了用于生成文本的配置参数,如生成长度、采样策略等。configuration.json:这个文件通常是模型的额外配置文件,可能包含与模型结构或训练过程相关的配置信息。vocab.json:这个文件包含了分词器的词汇表,通常是一个从词汇到 ID 的映射表。分词器使用这个文件来将文本中的单词转换为模型可以处理的 ID。
一般只需要注意权重文件和 tokenizer 即可。
4. 开始推理
启动推理服务
vLLM 支持提供 OpenAI 格式的 API,启动命令如下:
bash
modelpath=/models/Qwen1.5-1.8B-Chat
# 单卡
python3 -m vllm.entrypoints.openai.api_server \
--model $modelpath \
--served-model-name qwen \
--trust-remote-code输出如下
bash
INFO 07-18 06:42:31 llm_engine.py:100] Initializing an LLM engine (v0.4.2) with config: model='/models/Qwen1.5-1.8B-Chat', speculative_config=None, tokenizer='/models/Qwen1.5-1.8B-Chat', skip_tokenizer_init=False, tokenizer_mode=auto, revision=None, tokenizer_revision=None, trust_remote_code=True, dtype=torch.float16, max_seq_len=32768, download_dir=None, load_format=LoadFormat.AUTO, tensor_parallel_size=1, disable_custom_all_reduce=False, quantization=None, enforce_eager=False, kv_cache_dtype=auto, quantization_param_path=None, device_config=cuda, decoding_config=DecodingConfig(guided_decoding_backend='outlines'), seed=0, served_model_name=qwen)
INFO: Started server process [614]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)vLLM 默认监听 8000 端口。
对于多卡则是增加参数 tensor-parallel-size ,将该参数设置为 GPU 数量即可,vLLM 会启动 ray cluster 将模型切分到多个 GPU 上运行,对于大模型很有用。
bash
python3 -m vllm.entrypoints.openai.api_server \
--model $modelpath \
--served-model-name qwen \
--tensor-parallel-size 8 \
--trust-remote-code发送测试请求
直接使用 OpenAI 格式请求
bash
# model 就是前面启动服务时的 served-model-name 参数
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "qwen",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "你是谁?"}
]
}'输出如下:
bash
{"id":"cmpl-07f2f8c70bd44c10bba71d730e6e10a3","object":"chat.completion","created":1721284973,"model":"qwen","choices":[{"index":0,"message":{"role":"assistant","content":"我是来自阿里云的大规模语言模型,我叫通义千问。我是阿里云自主研发的超大规模语言模型,可以回答问题、创作文字,还能表达观点、撰写代码、撰写故事,还能表达观点、撰写代码、撰写故事。我被设计用来帮助用户解答问题、创作文字、表达观点、撰写代码、撰写故事,以及进行其他各种自然语言处理任务。如果您有任何问题或需要帮助,请随时告诉我,我会尽力提供支持。"},"logprobs":null,"finish_reason":"stop","stop_reason":null}],"usage":{"prompt_tokens":22,"total_tokens":121,"completion_tokens":99}}查看 GPU 占用情况,基本跑满了
bash
Thu Jul 18 06:45:32 2024
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.161.08 Driver Version: 535.161.08 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 Tesla T4 On | 00000000:3B:00.0 Off | 0 |
| N/A 59C P0 69W / 70W | 12833MiB / 15360MiB | 84% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
| 1 Tesla T4 On | 00000000:86:00.0 Off | 0 |
| N/A 51C P0 30W / 70W | 4849MiB / 15360MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| 0 N/A N/A 3376627 C python3 12818MiB |
| 1 N/A N/A 1150487 C /usr/bin/python3 4846MiB |
+---------------------------------------------------------------------------------------+5. 小结
本文主要分享如何使用 vLLM 来部署大模型推理服务, 安装好环境后,vLLM 使用非常简单,一条命令即可启动。
bash
modelpath=/models/Qwen1.5-1.8B-Chat
# 单卡
python3 -m vllm.entrypoints.openai.api_server \
--model $modelpath \
--served-model-name qwen \
--trust-remote-code【Kubernetes 系列】 持续更新中,搜索公众号【探索云原生】订阅,阅读更多文章。
