引入
在云原生技术飞速发展的当下,Kubernetes(简称 K8s)凭借其强大的容器编排与管理能力,已成为企业构建现代化应用架构的核心基石。然而,随着集群规模的不断扩大、业务负载的日益复杂,集群的稳定性、性能瓶颈以及故障排查等问题愈发凸显 ------ 节点资源使用率骤升、Pod 异常重启、服务链路中断等突发状况,往往会给业务带来不可估量的损失。此时,一套实时、精准、可视化且具备告警能力的监控方案,就成为保障 K8s 集群平稳运行的 "生命线"。
传统监控工具(如 Zabbix、Nagios)在云原生场景下逐渐暴露出适配性不足的问题:要么难以高效采集容器化环境下的动态指标,要么缺乏灵活的可视化配置,要么告警机制无法与云原生生态深度融合。而在众多云原生监控方案中,Prometheus+Grafana+Alertmanager的组合凭借其开源、可扩展、高度定制化的特性,成为了业界公认的 "黄金搭档"------Prometheus 负责指标的采集与存储,Grafana 将枯燥的数据转化为直观易懂的可视化面板,Alertmanager 则精准捕捉异常指标并及时推送告警信息。三者协同工作,不仅能覆盖 K8s 集群从节点、Pod、服务到应用的全维度监控需求,更能通过灵活的配置满足不同企业的个性化场景,真正实现 "监控无死角、告警精准化、问题可追溯"。
一、组件介绍
1.1 Prometheus
Prometheus是一个开源的系统监控和警报工具,最初是在SoundCloud上构建的。Prometheus于2016年加入CNCF(云原生计算基金会),成为继Kubernetes之后的第二个托管项目。2018年8月9日,CNCF 宣布开放源代码监控工具 Prometheus 已从孵化状态进入毕业状态。
1.2 cAdvisor
Cadvisor是Google开源的一款用来检测、分析、展示单节点的一个容器性能指标和资源监控的可视化工具(也可以监控本机,针对单台物理机),监控包括容器的内存使用率、CPU使用率、网络IO、磁盘IO及文件系统使用情况,利用Linux的Cgroup获取容器及本机的资源使用信息。同时提供了一个Web界面用于查看容器的实时运行状态。
1.3 kube-state-metrics
kube-state-metrics关注于获取k8s各种资源的最新状态,如 deployment 或者 daemonset是从 api-server 中获取 cpu、内存使用率这种监控指标,他当前的核心M作用是:为HPAkubectI等组件提供决策指标支持。
1.4 Grafana
Grafana 是一个监控仪表系统,它是由GrafanaLabs 公司开源的的一个系统监测工具。Grafana支持许多不同的数据源,每个数据源都有一个特定的查询编辑器,它就可以帮助生成各种可视化仪表,同时它还有报警功能,可以在系统出现问题时发出通知。
1.5 Alertmanager
Alertmanager主要用于接收Prometheus发送的告警信息,它支持丰富的告警通知渠道,而且很容易做到告警信息进行去重,降噪,分组,策略路由,是一款前卫的告警通知系统。
1.6 应有的架构
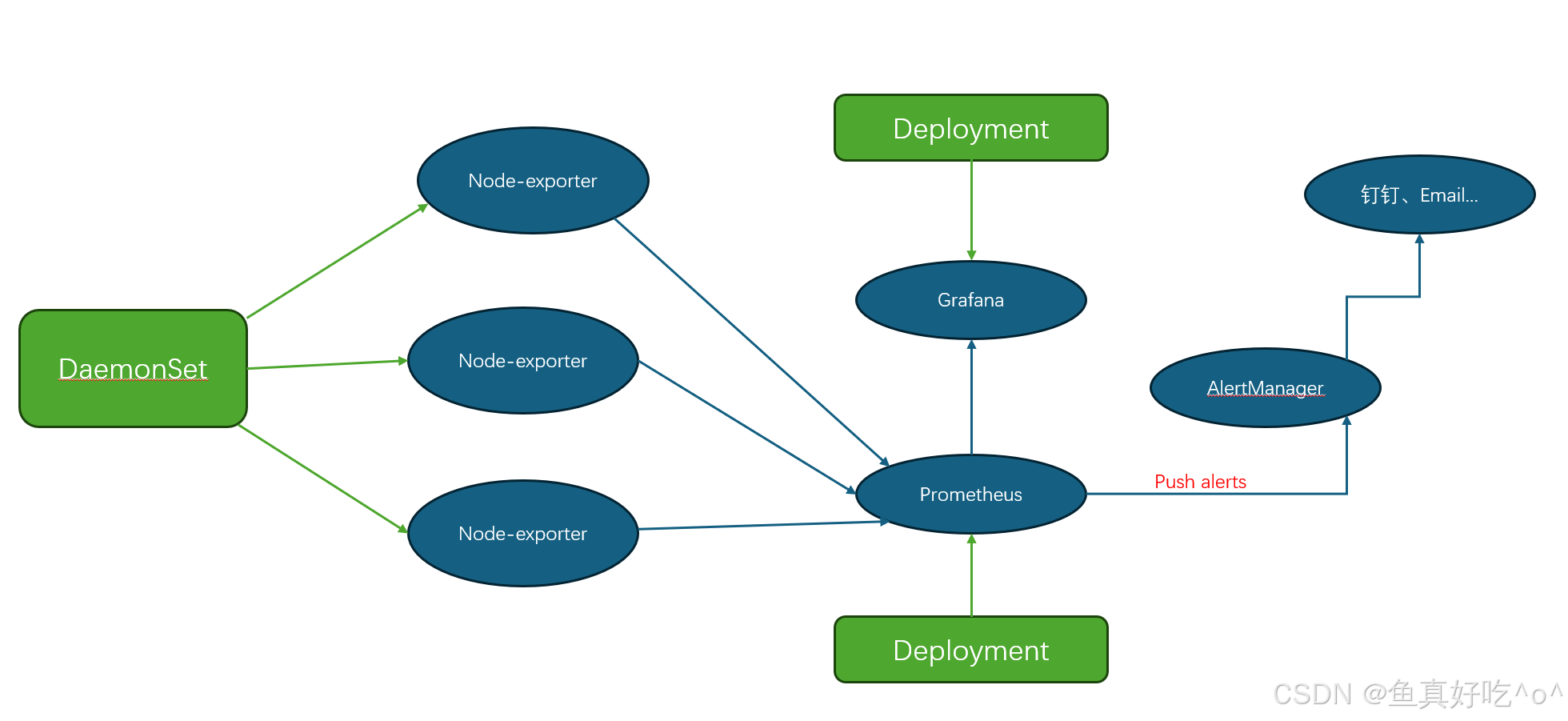
1.7 官方架构图
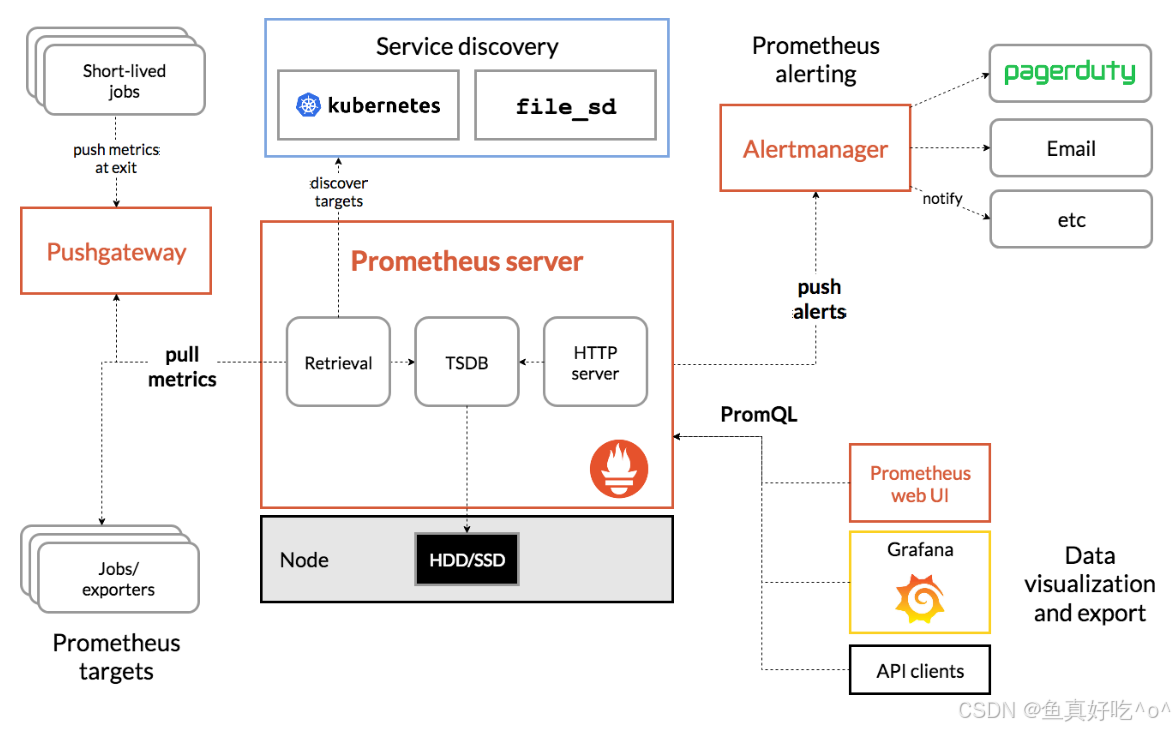
二、部署监控系统
2.1 部署Prometheus
创建资源隔离名称空间
bash
[root@k8s-master ~/kube-prometheus]# kubectl create ns minitor
[root@k8s-master ~/kube-prometheus]# kubectl get ns monitor
NAME STATUS AGE
monitor Active 3d16h创建Prometheus configMap文件
prometheus-configmap.yaml
bash
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: monitor
data:
prometheus.yml: |
global:
scrape_interval: 15s
evaluation_interval: 15s
alerting:
alertmanagers:
- static_configs:
- targets:
- alertmanager-svc.monitor.svc.cluster.local:9093
scheme: http
timeout: 20s
rule_files:
- /etc/prometheus/rules/*.yml
scrape_configs:
- job_name: 'prometheus'
kubernetes_sd_configs:
- role: endpoints
namespaces:
names: [monitor]
relabel_configs:
- source_labels: [__meta_kubernetes_service_name]
regex: prometheus-svc
action: keep
- source_labels: [__meta_kubernetes_endpoint_port_name]
regex: web
action: keep
- job_name: 'coredns'
kubernetes_sd_configs:
- role: endpoints
namespaces:
names: [kube-system]
relabel_configs:
- source_labels: [__meta_kubernetes_service_name]
regex: kube-dns
action: keep
- source_labels: [__meta_kubernetes_endpoint_port_name]
regex: metrics
action: keep
- job_name: 'kube-apiserver'
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: false
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: endpoints
namespaces:
names: [default, kube-system]
relabel_configs:
- source_labels: [__meta_kubernetes_service_name]
regex: kubernetes
action: keep
- source_labels: [__meta_kubernetes_endpoint_port_name]
regex: https
action: keep
- job_name: 'node-exporter'
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
regex: '(.*):10250'
replacement: '${1}:9100'
target_label: __address__
action: replace
- job_name: 'cadvisor'
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
insecure_skip_verify: true
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
relabel_configs:
- action: replace
target_label: __metrics_path__
replacement: /metrics/cadvisor
- job_name: 'kube-state-metrics'
kubernetes_sd_configs:
- role: endpoints
namespaces:
names: [monitor]
relabel_configs:
- source_labels: [__meta_kubernetes_service_name]
regex: kube-state-metrics
action: keep
- source_labels: [__meta_kubernetes_endpoint_port_name]
regex: kube-state-metrics
action: keep创建Prometheus业务pod
prometheus.yaml
bash
[root@k8s-master ~/kube-prometheus]# cat prometheus.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: prometheus
namespace: monitor
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus
rules:
- apiGroups:
- ""
resources:
- nodes
- services
- endpoints
- pods
- nodes/proxy
- nodes/proxy
verbs:
- get
- list
- watch
- apiGroups:
- "extenstions"
resources:
- ingresses
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- configmaps
- nodes/metrics
verbs:
- get
- nonResourceURLs:
- /metrics
verbs:
- get
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: prometheus
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus
subjects:
- kind: ServiceAccount
name: prometheus
namespace: monitor
---
apiVersion: v1
kind: Service
metadata:
name: prometheus-svc
namespace: monitor
labels:
app: prometheus
annotations:
prometheus_io_scrape: "true"
spec:
selector:
app: prometheus
type: NodePort
ports:
- name: web
nodePort: 32224
port: 9090
targetPort: http
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: prometheus-ingress
namespace: monitor
spec:
ingressClassName: nginx
rules:
- host: www.myprometheus.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: prometheus-svc
port:
number: 9090
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: prometheus-pvc
namespace: monitor
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 2Gi
storageClassName: nfs-csi
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus
namespace: monitor
labels:
app: prometheus
spec:
selector:
matchLabels:
app: prometheus
replicas: 1
template:
metadata:
labels:
app: prometheus
spec:
serviceAccountName: prometheus
initContainers:
- name: "change-permission-of-directory"
image: swr.cn-north-4.myhuaweicloud.com/ddn-k8s/quay.io/prometheus/busybox:latest
command: ["/bin/sh"]
args: ["-c","chown -R 65534:65534 /prometheus"]
securityContext:
privileged: true
volumeMounts:
- mountPath: "/etc/prometheus"
name: config-volume
- mountPath: "/prometheus"
name: data
containers:
- image: swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/prom/prometheus:latest
name: prometheus
args:
- "--config.file=/etc/prometheus/prometheus.yml"
- "--storage.tsdb.path=/prometheus"
- "--web.enable-lifecycle"
- "--web.console.libraries=/usr/share/prometheus/console_libraries"
- "--web.console.templates=/usr/share/prometheus/consoles"
ports:
- containerPort: 9090
name: http
volumeMounts:
- mountPath: "/etc/prometheus"
name: config-volume
- mountPath: "/prometheus"
name: data
- mountPath: "/etc/prometheus/rules"
name: rules-volume
resources:
requests:
cpu: 100m
memory: 512Mi
limits:
cpu: 100m
memory: 512Mi
volumes:
- name: data
persistentVolumeClaim:
claimName: prometheus-pvc
- configMap:
name: prometheus-config
name: config-volume
- name: rules-volume
configMap:
name: prometheus-rules2.2 部署node-exporter
node-exportet-daemonset.yaml
bash
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-exporter
namespace: monitor
labels:
app: node-exporter
spec:
selector:
matchLabels:
app: node-exporter
template:
metadata:
labels:
app: node-exporter
spec:
hostPID: true
hostIPC: true
hostNetwork: true
nodeSelector:
kubernetes.io/os: linux
containers:
- name: node-exporter
image: docker.io/prom/node-exporter:latest
imagePullPolicy: IfNotPresent
args:
- --web.listen-address=$(HOSTIP):9100
- --path.procfs=/host/proc
- --path.sysfs=/host/sys
- --path.rootfs=/host/root
- --collector.filesystem.ignored-mount-points=^/(dev|proc|sys|var/lib/docker/.+)($|/)
- --collector.filesystem.ignored-fs-types=^(autofs|binfmt_misc|cgroup|configfs|debugfs|devpts|devtmpfs|fusectl|hugetlbfs|mqueue|overlay|proc|procfs|pstore|rpc_pipefs|securityfs|sysfs|tracefs)$
ports:
- containerPort: 9100
env:
- name: HOSTIP
valueFrom:
fieldRef:
fieldPath: status.hostIP
resources:
requests:
cpu: 150m
memory: 180Mi
limits:
cpu: 150m
memory: 180Mi
securityContext:
runAsNonRoot: true
runAsUser: 65534
volumeMounts:
- name: proc
mountPath: /host/proc
- name: sys
mountPath: /host/sys
- name: root
mountPath: /host/root
mountPropagation: HostToContainer
readOnly: true
tolerations:
- operator: "Exists"
volumes:
- name: proc
hostPath:
path: /proc
- name: dev
hostPath:
path: /dev
- name: sys
hostPath:
path: /sys
- name: root
hostPath:
path: /创建node-exporter-svc
node-exportet-svc.yaml
bash
apiVersion: v1
kind: Service
metadata:
name: node-exporter
namespace: monitor
labels:
app: node-exporter
spec:
selector:
app: node-exporter
ports:
- name: metrics
port: 9100
targetPort: 9100
clusterIP: None2.3 部署kube-state-metrics
kube-state-metrics.yaml
bash
apiVersion: v1
kind: ServiceAccount
metadata:
name: kube-state-metrics
namespace: monitor
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: kube-state-metrics
rules:
- apiGroups: [""]
resources: ["nodes", "pods", "services", "resourcequotas", "replicationcontrollers", "limitranges", "persistentvolumeclaims", "persistentvolumes", "namespaces", "endpoints"]
verbs: ["list", "watch"]
- apiGroups: ["extensions"]
resources: ["daemonsets", "deployments", "replicasets"]
verbs: ["list", "watch"]
- apiGroups: ["apps"]
resources: ["statefulsets"]
verbs: ["list", "watch"]
- apiGroups: ["batch"]
resources: ["cronjobs", "jobs"]
verbs: ["list", "watch"]
- apiGroups: ["autoscaling"]
resources: ["horizontalpodautoscalers"]
verbs: ["list", "watch"]
- apiGroups: ["networking.k8s.io"]
resources: ["ingresses"]
verbs: ["list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: kube-state-metrics
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: kube-state-metrics
subjects:
- kind: ServiceAccount
name: kube-state-metrics
namespace: monitor
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: kube-state-metrics
namespace: monitor
spec:
replicas: 1
selector:
matchLabels:
app: kube-state-metrics
template:
metadata:
labels:
app: kube-state-metrics
spec:
serviceAccountName: kube-state-metrics
containers:
- name: kube-state-metrics
image: swr.cn-north-4.myhuaweicloud.com/ddn-k8s/registry.k8s.io/kube-state-metrics/kube-state-metrics:v2.9.2
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8080
---
apiVersion: v1
kind: Service
metadata:
annotations:
prometheus.io/scrape: 'true'
name: kube-state-metrics
namespace: monitor
labels:
app: kube-state-metrics
spec:
ports:
- name: kube-state-metrics
port: 8080
protocol: TCP
selector:
app: kube-state-metrics2.4 部署Grafana
参考我的日志收集模块文章,使用HELM部署Grafana,因为建议监控和日志放在同一个Grafana去展示更方便,但是要保证,Grafana做了持久化数据存储和多副本高可用。
Alloy+Loki+Minio+Grafana云原生K8S日志收集方案-CSDN博客
2.5 部署metrics.server
官网地址:https://github.com/kubernetes-sigs/metrics-server
bash
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
k8s-app: metrics-server
rbac.authorization.k8s.io/aggregate-to-admin: "true"
rbac.authorization.k8s.io/aggregate-to-edit: "true"
rbac.authorization.k8s.io/aggregate-to-view: "true"
name: system:aggregated-metrics-reader
rules:
- apiGroups:
- metrics.k8s.io
resources:
- pods
- nodes
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
k8s-app: metrics-server
name: system:metrics-server
rules:
- apiGroups:
- ""
resources:
- nodes/metrics
verbs:
- get
- apiGroups:
- ""
resources:
- pods
- nodes
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
labels:
k8s-app: metrics-server
name: metrics-server-auth-reader
namespace: kube-system
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: extension-apiserver-authentication-reader
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
k8s-app: metrics-server
name: metrics-server:system:auth-delegator
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:auth-delegator
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
k8s-app: metrics-server
name: system:metrics-server
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:metrics-server
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: v1
kind: Service
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
spec:
ports:
- appProtocol: https
name: https
port: 443
protocol: TCP
targetPort: https
selector:
k8s-app: metrics-server
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
spec:
replicas: 2
selector:
matchLabels:
k8s-app: metrics-server
strategy:
rollingUpdate:
maxUnavailable: 1
template:
metadata:
labels:
k8s-app: metrics-server
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchLabels:
k8s-app: metrics-server
namespaces:
- kube-system
topologyKey: kubernetes.io/hostname
containers:
- args:
- --kubelet-insecure-tls
- --cert-dir=/tmp
- --secure-port=10250
- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
- --kubelet-use-node-status-port
- --metric-resolution=15s
image: registry.k8s.io/metrics-server/metrics-server:v0.8.0
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 3
httpGet:
path: /livez
port: https
scheme: HTTPS
periodSeconds: 10
name: metrics-server
ports:
- containerPort: 10250
name: https
protocol: TCP
readinessProbe:
failureThreshold: 3
httpGet:
path: /readyz
port: https
scheme: HTTPS
initialDelaySeconds: 20
periodSeconds: 10
resources:
requests:
cpu: 100m
memory: 200Mi
securityContext:
allowPrivilegeEscalation: false
capabilities:
drop:
- ALL
readOnlyRootFilesystem: true
runAsNonRoot: true
runAsUser: 1000
seccompProfile:
type: RuntimeDefault
volumeMounts:
- mountPath: /tmp
name: tmp-dir
nodeSelector:
kubernetes.io/os: linux
priorityClassName: system-cluster-critical
serviceAccountName: metrics-server
volumes:
- emptyDir: {}
name: tmp-dir
---
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
spec:
minAvailable: 1
selector:
matchLabels:
k8s-app: metrics-server
---
apiVersion: apiregistration.k8s.io/v1
kind: APIService
metadata:
labels:
k8s-app: metrics-server
name: v1beta1.metrics.k8s.io
spec:
group: metrics.k8s.io
groupPriorityMinimum: 100
insecureSkipTLSVerify: true
service:
name: metrics-server
namespace: kube-system
version: v1beta1
versionPriority: 1002.6 部署DingtalkWebhook
新建钉钉群聊机器人
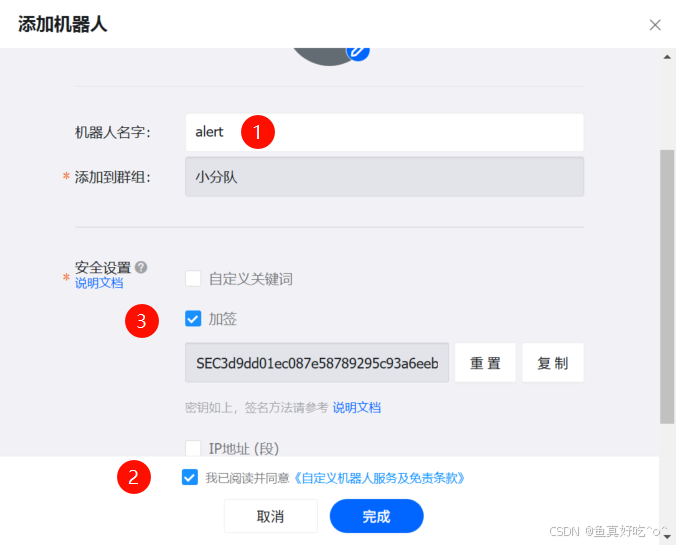
点击完成之后可以看到机器人已经出现在群聊了,后续只需要保存机器人的两个内容
Webhook的地址:https://oapi.dingtalk.com/robot/send?access_token=XXXXX
加签的Secert: SECb734299dffb1cf51cXXXX
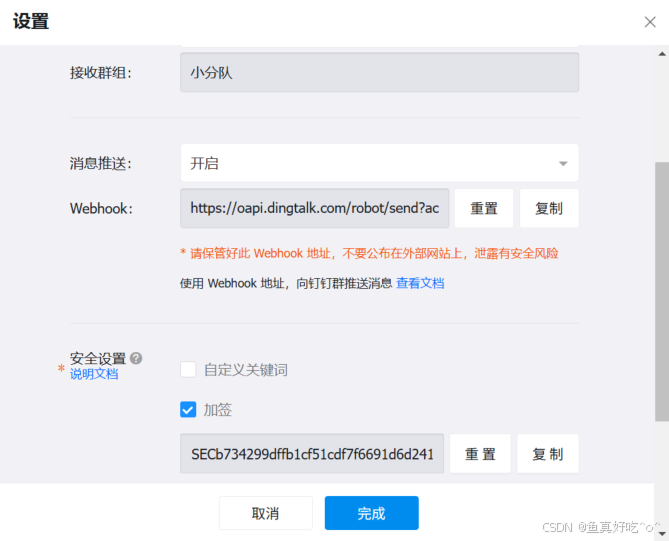
保存信息即可。
创建dingtalk-webhook.yaml资源清单将复制的内容填写到configMap.data.webhook1.url和secret下,注意,要换成自己的信息哦。
bash
[root@k8s-master ~/kube-prometheus]# cat dingtalk-webhook.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: dingtalk-webhook-config
namespace: monitor
data:
config.yml: |
targets:
webhook1:
url: https://oapi.dingtalk.com/robot/send?access_token=XXXXXX
secret: SECb7342XXXXXX
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: dingtalk-webhook
namespace: monitor
labels:
app: dingtalk-webhook
spec:
replicas: 1
selector:
matchLabels:
app: dingtalk-webhook
template:
metadata:
labels:
app: dingtalk-webhook
spec:
containers:
- name: dingtalk-webhook
image: timonwong/prometheus-webhook-dingtalk:v2.1.0
imagePullPolicy: IfNotPresent
args:
- --config.file=/etc/dingtalk/config.yml
ports:
- name: http
containerPort: 8060
volumeMounts:
- name: config
mountPath: /etc/dingtalk
resources:
requests:
cpu: 50m
memory: 100Mi
limits:
cpu: 100m
memory: 200Mi
volumes:
- name: config
configMap:
name: dingtalk-webhook-config
---
apiVersion: v1
kind: Service
metadata:
name: dingtalk-webhook-svc
namespace: monitor
spec:
selector:
app: dingtalk-webhook
ports:
- name: http
port: 8060
targetPort: http2.7 部署Alertmanager
alertmanager.yaml
bash
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: alertmanager-pvc
namespace: monitor
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 2Gi
storageClassName: nfs-csi
---
apiVersion: v1
kind: ConfigMap
metadata:
name: alertmanager-config
namespace: monitor
data:
alertmanager.yml: |
global:
resolve_timeout: 5m
route:
group_by: ['alertname', 'namespace']
group_wait: 30s
group_interval: 5m
repeat_interval: 4h
receiver: dingtalk
routes:
- receiver: dingtalk
continue: false
receivers:
- name: dingtalk
webhook_configs:
- url: http://dingtalk-webhook-svc.monitor.svc.cluster.local:8060/dingtalk/webhook1/send
send_resolved: true
max_alerts: 0
http_config: {}
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: alertmanager
namespace: monitor
labels:
app: alertmanager
spec:
replicas: 1
selector:
matchLabels:
app: alertmanager
template:
metadata:
labels:
app: alertmanager
spec:
containers:
- name: alertmanager
image: prom/alertmanager:latest
imagePullPolicy: IfNotPresent
args:
- '--config.file=/etc/alertmanager/alertmanager.yml'
- '--storage.path=/alertmanager'
- '--web.listen-address=:9093'
ports:
- containerPort: 9093
name: http
volumeMounts:
- name: config
mountPath: /etc/alertmanager
- name: data
mountPath: /alertmanager
resources:
requests:
cpu: 100m
memory: 256Mi
limits:
cpu: 200m
memory: 512Mi
volumes:
- name: config
configMap:
name: alertmanager-config
- name: data
persistentVolumeClaim:
claimName: alertmanager-pvc
---
apiVersion: v1
kind: Service
metadata:
name: alertmanager-svc
namespace: monitor
labels:
app: alertmanager
spec:
selector:
app: alertmanager
ports:
- name: http
port: 9093
targetPort: http
type: NodePort编写告警规则
alert-rules.yaml
bash
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-rules
namespace: monitor
data:
k8s-rules.yml: |
groups:
- name: kubernetes-system
rules:
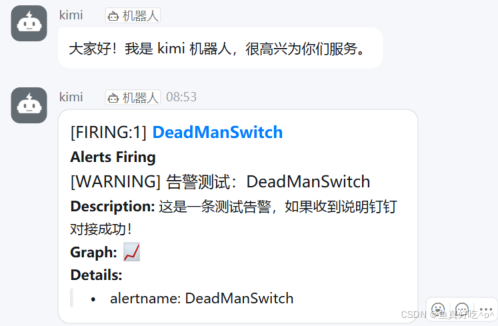
# 测试用 DeadManSwitch(永远触发,用于验证钉钉是否收到)
- alert: DeadManSwitch
expr: vector(1)
for: 0m
labels:
severity: warning
annotations:
summary: "告警测试:DeadManSwitch"
description: "这是一条测试告警,如果收到说明钉钉对接成功!"
- alert: NodeDown
expr: up{job="node-exporter"} == 0
for: 2m
labels:
severity: critical
annotations:
summary: "节点 {{ $labels.instance }} 已宕机"
description: "节点 {{ $labels.instance }} 超过 2 分钟没有上报 metrics"依次执行
bash
[root@k8s-master ~/kube-prometheus]# kubectl apply -f prometheus-configmap.yaml
[root@k8s-master ~/kube-prometheus]# kubectl apply -f prometheus.yaml
[root@k8s-master ~/kube-prometheus]# kubectl apply -f node-exportet-daemonset.yaml
[root@k8s-master ~/kube-prometheus]# kubectl apply -f node-exportet-svc.yaml
[root@k8s-master ~/kube-prometheus]# kubectl apply -f kube-state-metrics.yaml
### 注意Grafana可以根据我的提示使用HELM部署
[root@k8s-master ~/kube-prometheus]# kubectl apply -f high-availability-1.21+.yaml
[root@k8s-master ~/kube-prometheus]# kubectl apply -f dingtalk-webhook.yaml
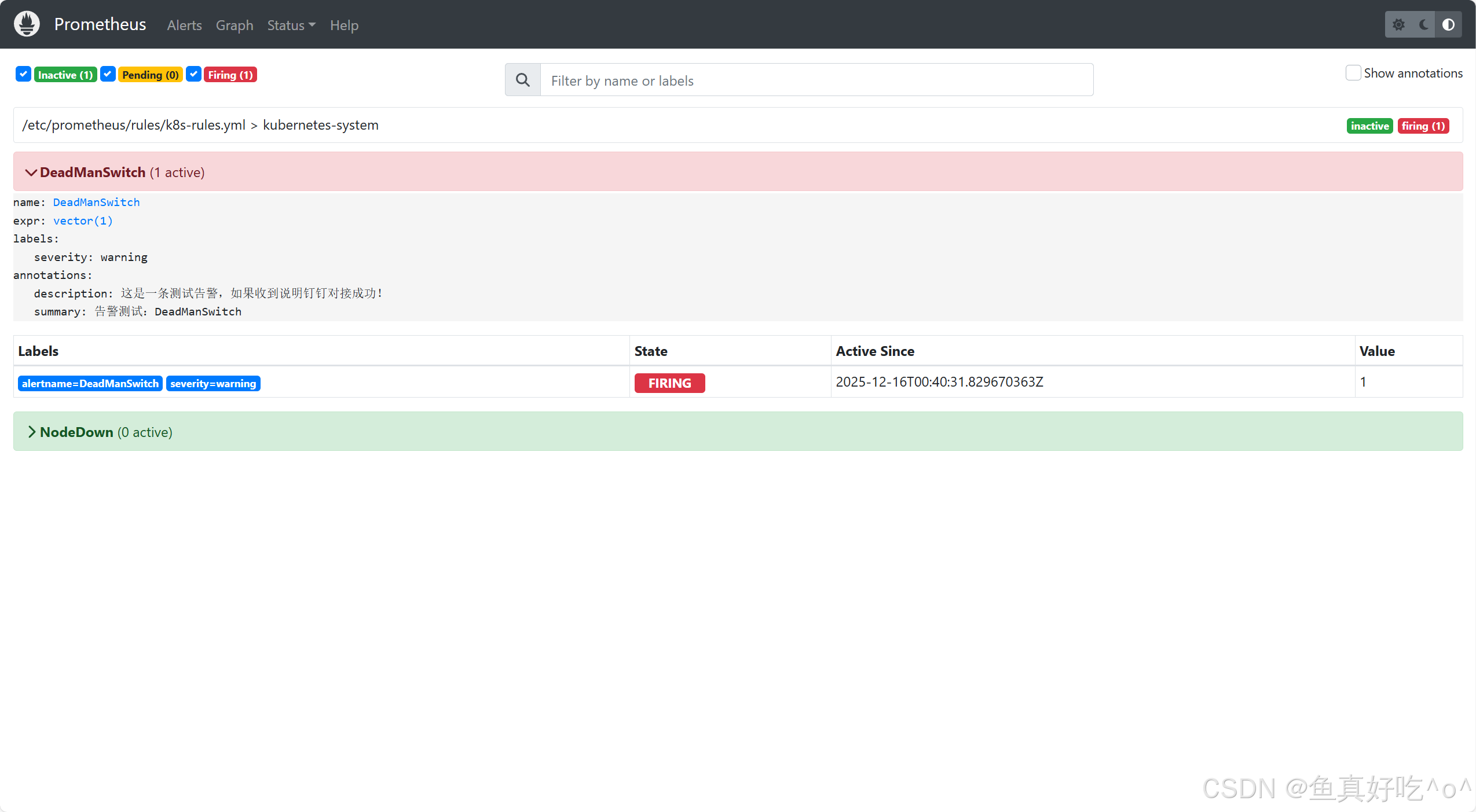
[root@k8s-master ~/kube-prometheus]# kubectl apply -f alert-rules.yaml
[root@k8s-master ~/kube-prometheus]# kubectl apply -f alertmanager.yaml三、查看资源并验证
bash
[root@k8s-master ~/kube-prometheus]# kubectl get po,svc -n monitor
NAME READY STATUS RESTARTS AGE
pod/alertmanager-64cd88c6bf-zlzq6 1/1 Running 0 48m
pod/dingtalk-webhook-5dbd768bf-chqvn 1/1 Running 0 48m
pod/kube-state-metrics-6db447664-7btct 1/1 Running 1 (61m ago) 15h
pod/node-exporter-fpbwb 1/1 Running 1 (61m ago) 15h
pod/node-exporter-hqc6d 1/1 Running 1 (61m ago) 15h
pod/node-exporter-szt7q 1/1 Running 1 (61m ago) 15h
pod/prometheus-cf4b7697b-4g7x2 1/1 Running 1 (61m ago) 15h
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/alertmanager-svc NodePort 10.98.214.23 <none> 9093:31351/TCP 15h
service/dingtalk-webhook-svc ClusterIP 10.98.94.120 <none> 8060/TCP 15h
service/kube-state-metrics ClusterIP 10.111.72.112 <none> 8080/TCP 15h
service/node-exporter ClusterIP None <none> 9100/TCP 15h
service/prometheus-svc NodePort 10.98.192.148 <none> 9090:32224/TCP 15h
bash
[root@k8s-master ~/kube-prometheus]# kubectl top nodes
NAME CPU(cores) CPU(%) MEMORY(bytes) MEMORY(%)
k8s-master 278m 6% 2383Mi 56%
k8s-node1 131m 3% 2348Mi 44%
k8s-node2 101m 2% 2811Mi 52%
[root@k8s-master ~/kube-prometheus]# kubectl top pod -n monitor
NAME CPU(cores) MEMORY(bytes)
alertmanager-64cd88c6bf-zlzq6 2m 12Mi
dingtalk-webhook-5dbd768bf-chqvn 0m 22Mi
kube-state-metrics-6db447664-7btct 1m 18Mi
node-exporter-fpbwb 2m 14Mi
node-exporter-hqc6d 2m 9Mi
node-exporter-szt7q 2m 27Mi
prometheus-cf4b7697b-4g7x2 10m 281Mi
[root@k8s-master ~/kube-prometheus]# kubectl top pod -n monitoring
NAME CPU(cores) MEMORY(bytes)
alloy-j2sp8 20m 208Mi
alloy-kntn4 18m 167Mi
alloy-pffnr 16m 194Mi
grafana-858cf85796-znkrr 6m 103Mi
loki-0 20m 261Mi
loki-canary-4f685 2m 44Mi
loki-canary-hd7t2 2m 11Mi
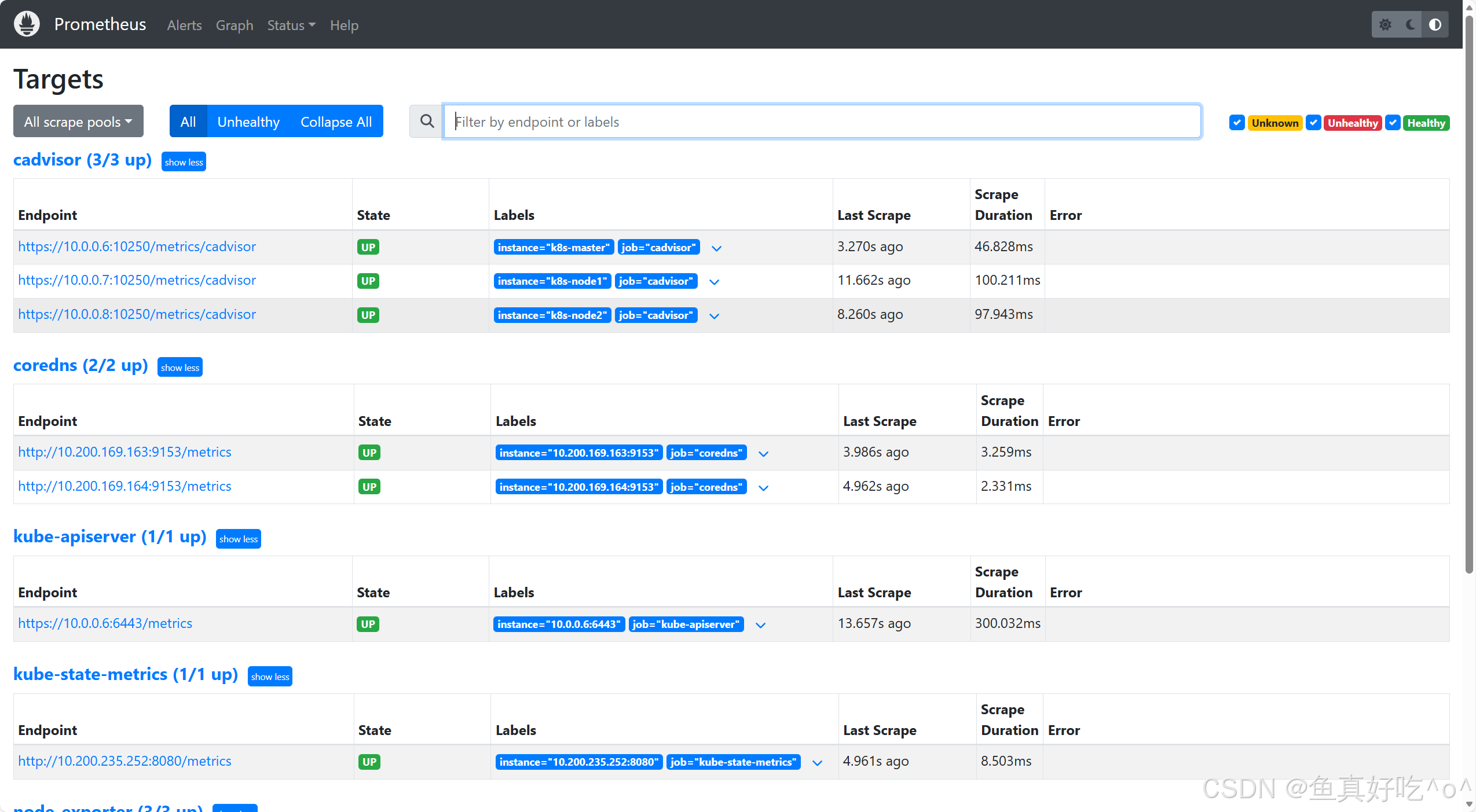
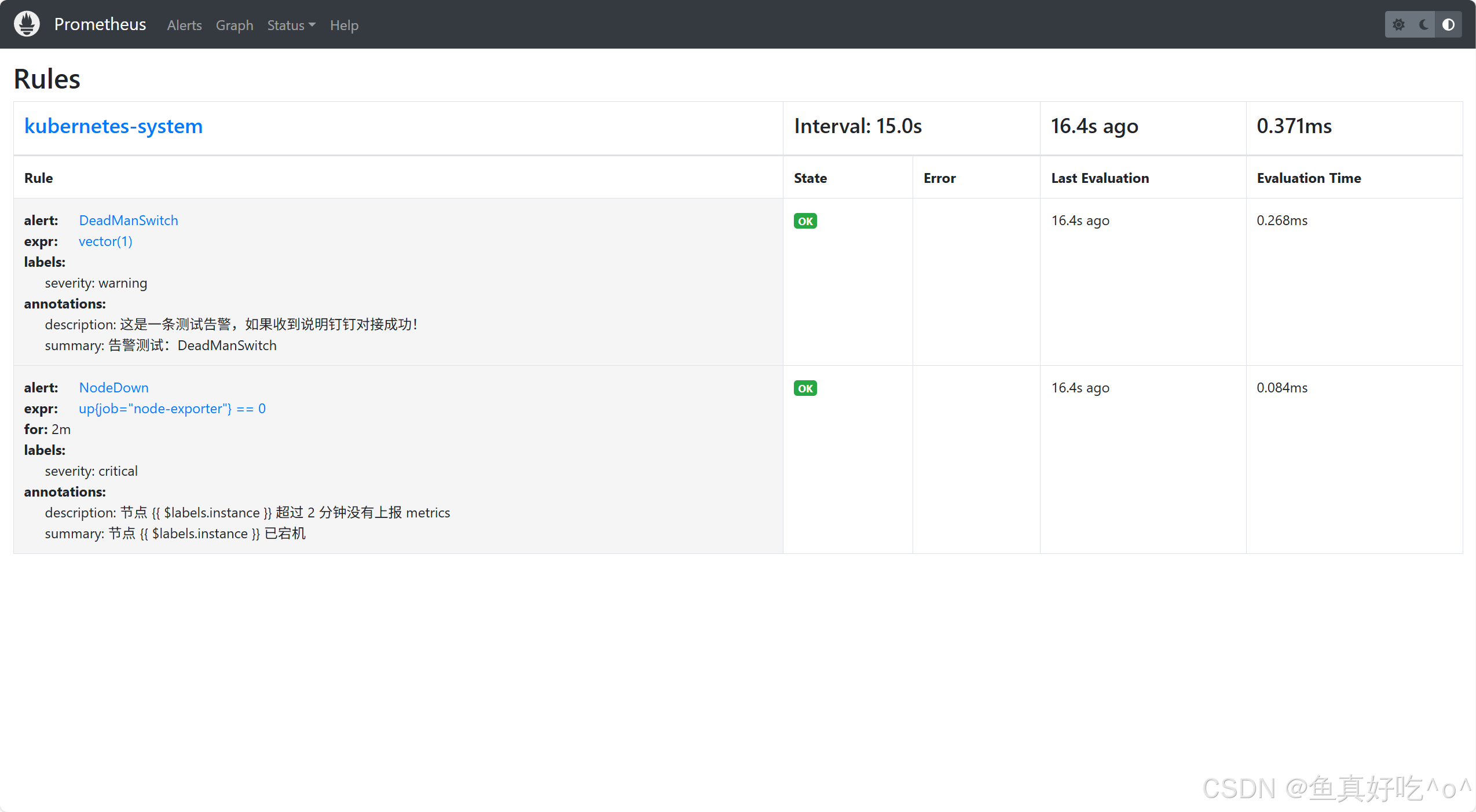
loki-canary-pjcl9 2m 20Mi 3.1 访问Prometheus的UI界面
IP和端口注意换成自己的IP和NodePort端口
3.2 访问Grafana的UI界面
bash
[root@k8s-master ~/kube-prometheus]# kubectl get ingress -n monitoring
NAME CLASS HOSTS ADDRESS PORTS AGE
ingress-http-grafana nginx www.mygrafana.com 10.0.0.150 80 4d17h
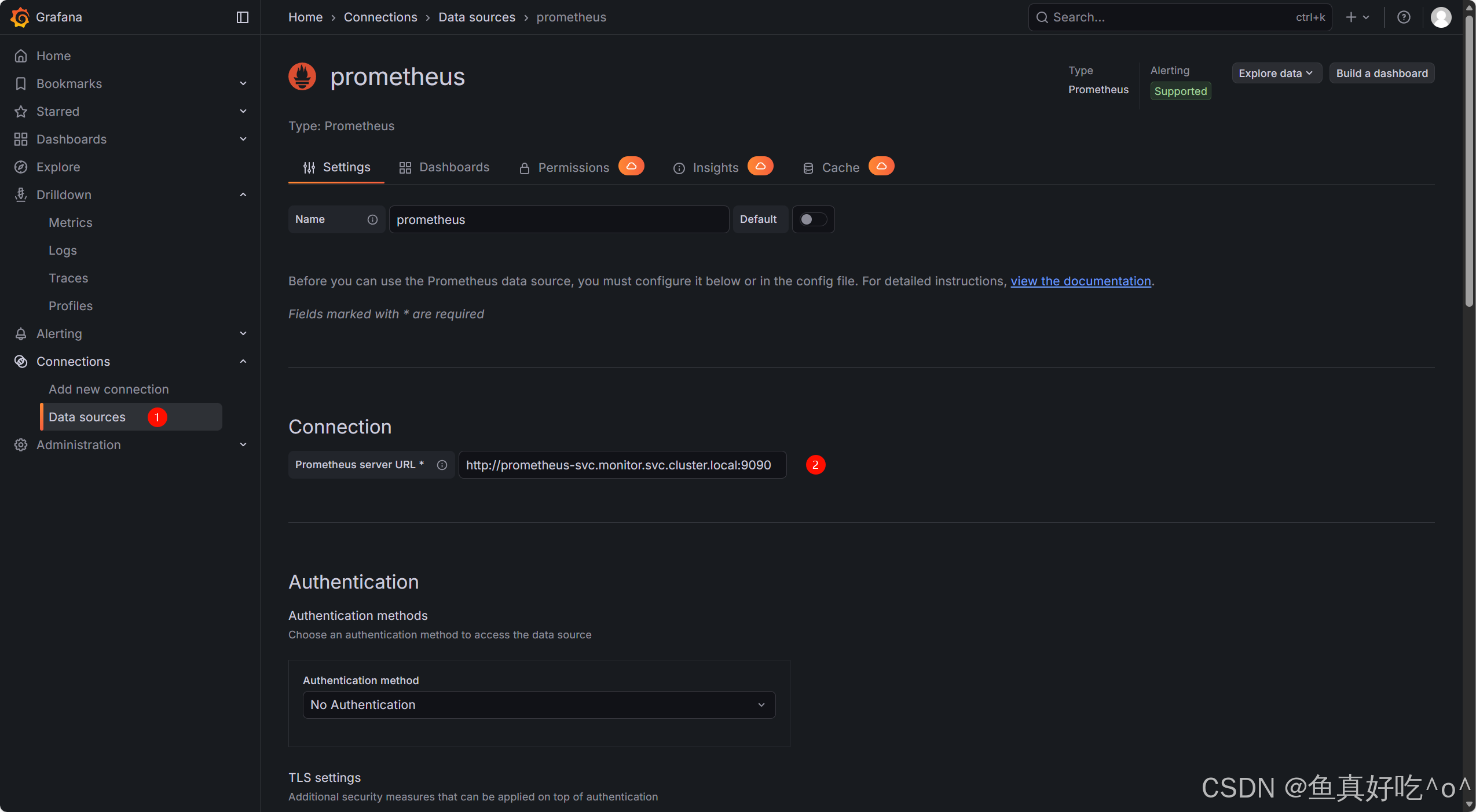
添加数据源为Prometheus
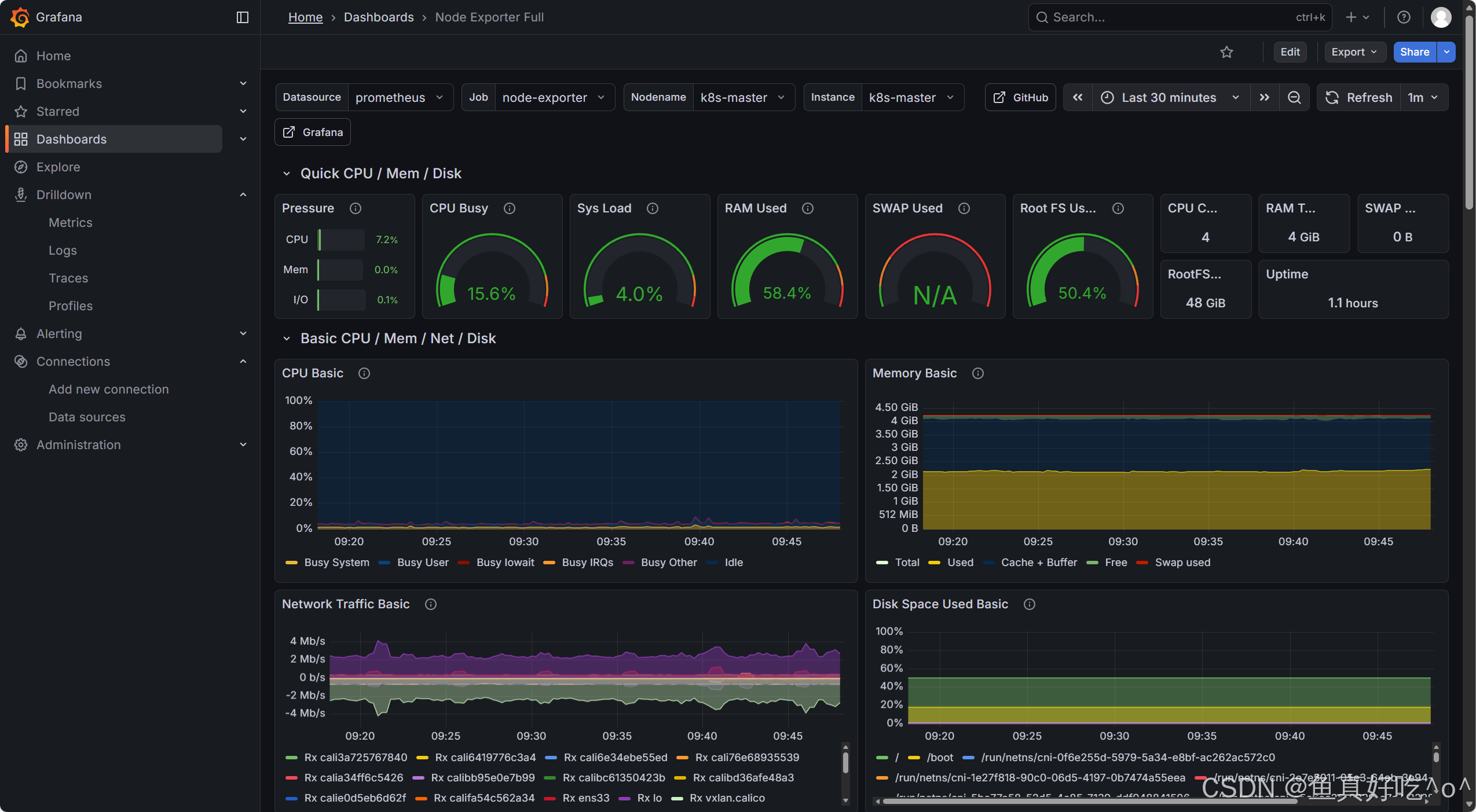
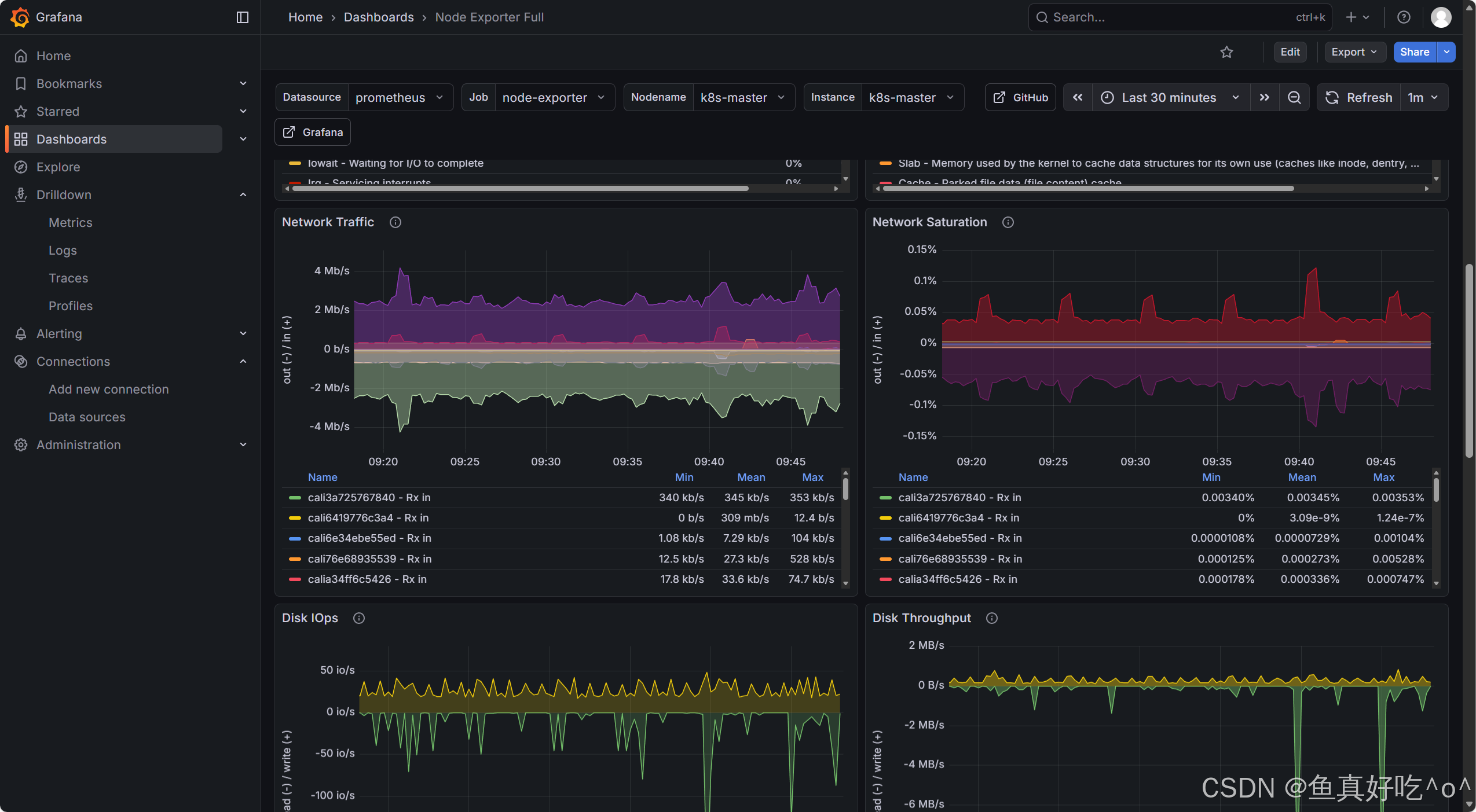
导入模板ID1860
3.3 访问Alertmanager的UI界面
3.4 查看钉钉机器人推送的告警
四、一些说明
4.1 Node-exporter
node_exporter就是抓取用于采集服务器节点的各种运行指标,目前node_exporter支持几乎所有常见的监控点,比如 conntrack, cpu, diskstats, filesystem, loadavg, meminfo, netstat等,详细的监控点列表可以参考其https://github.com/prometheus/node_exporter
4.2 Prometheus的configMap
在 Kubernetes 下,Promethues 通过与 Kubernetes API 集成,目前主要支持5中服务发现模式,分别是: Node、Service、Pod、Endpoints、Ingress
通过指定kubernetes_sd_configs 的模式为 node,Prometheus 就会自动从Kubernetes 中发现所有的 node节点并作为当前job 监控的目标实例,发现的节点/metrics 接口是默认的kubelet 的HTTP接口
Prometheus 去发现 Node 模式的服务的时候,访问的端口默认是10250,而现在该端口下面已经没有了 /metrics 指标数据了,现在kubelet 只读的数据接口统一通过10255端口进行暴露了,所以我们应该去替换掉这里的端口,但是我们是要替换成10255端口吗?不是的,因为我们是要去配置上面通过node-exporter抓取到的节点指标数据,而我们上面是不是指定了hostNetwork=true,所以在每个节点上就会绑定一个端口9100,所以我们应该将这里的10250替换成9100
这里我们就需要使用到 Prometheus 提供的 relabel_configs 中的 replace 能力了, relabel 可以在Prometheus 采集数据之前,通过Target 实例的 Metadata 信息,动态重新写入 Label 的值。除此之外,我们还能根据Target 实例的 Metadata 信息选择是否采集或者忽略该Target 实例
添加了一个 action 为 labelmap,正则表达式是__meta_kubernetes_node_1abe1_(.+) 的配置,这里的意思就是表达式中匹配都的数据也添加到指标数据的Label标签中去。
4.3 cAdvisor
容器监控我们自然会想到cAdvisor,我们前面也说过cAdvisor 已经内置在了kubelet 组件之中,所以我们不需要单独去安装,cAdvisor的数据路径为/api/v1/nodes/<node>/proxy/metrics,同样我们这里使用 node的服务发现模式,因为每一个节点下面都有kubelet.
4.4 metrics.server
从 Kubernetes v1.8开始,资源使用情况的监控可以通过 Metrics API 的形式获取,例如容器 CPU 和内存使用率。这些度量可以由用户直接访问(例如,通过使用kubectl top 命令),或者由集群中的控制器(例如,Horizontal Pod Autoscaler) 使用来进行决策,具体的组件为 Metrics Server,用来替换之前的 heapster, heapster 从 1.11 开始逐渐被废弃。
Metrics-Server是集群核心监控数据的聚合器。通俗地说,它存储了集群中各节点的监控数据,并且提供了 API 以供分析和使用。 Metrics-Server 作为一个 Deployment 对象默认部署在 Kubernetes 集群中。不过准确地说, 它是 Deployment, Service, ClusterRole,ClusterRoleBinding, APIService,RoleBinding等资源对象的综合体。
4.5 彩蛋
另一种operator监控方案可以查看我的博文。
基于 Operator 部署 Prometheus 实现 K8S 监控_operator安装prometheus-CSDN博客
五、总结
Prometheus 的监控逻辑遵循 "主动拉取 + 时序存储 + 按需查询" 的核心模式,具体流程如下:
- 指标采集:Prometheus Server 通过配置的 "目标地址"(如 K8s 节点的 Node Exporter、应用的自定义 Exporter),以 HTTP 协议主动拉取(Pull) 指标数据;对于短生命周期任务(如临时 Pod),则通过 PushGateway 接收其主动推送(Push) 的指标。
- 时序存储:采集到的指标数据(包含指标名、标签、时间戳、数值)被存储到 Prometheus 内置的时序数据库(TSDB)中,支持按时间范围高效查询。
- 指标查询:通过 PromQL(Prometheus 查询语言),用户可按需筛选、聚合指标数据(如 "查询近 1 小时节点 CPU 使用率超过 80% 的实例"),并对接 Grafana 生成可视化面板。
- 告警触发:Prometheus Server 持续检查指标是否满足预设告警规则(如 "Pod 内存使用率持续 5 分钟超过 90%"),当规则触发时,将告警信息发送至 Alertmanager。
- 告警处理:Alertmanager 接收告警后,通过去重、分组、路由(如 "节点告警发送给运维组,应用告警发送给开发组"),最终以邮件、钉钉、Slack 等方式通知相关人员。
在 Kubernetes 集群管理愈发复杂的云原生时代,"Prometheus+Grafana+Alertmanager" 组合成功解决了传统监控工具在动态容器环境中的适配难题,构建起一套 "采集 - 存储 - 可视化 - 告警" 全链路闭环的监控体系。从实践价值来看,这套方案不仅凭借 Prometheus 的时序指标采集能力覆盖节点、Pod、应用等全维度数据,更通过 Grafana 的灵活可视化让运维人员快速定位性能瓶颈,再结合 Alertmanager 的精准告警机制提前规避故障风险,真正实现了 K8s 集群 "可观测、可预警、可追溯" 的运维目标。