《------往期经典推荐------》
二、机器学习实战专栏【链接】 ,已更新31期,欢迎关注,持续更新中~~
三、深度学习【Pytorch】专栏【链接】
四、【Stable Diffusion绘画系列】专栏【链接】
五、YOLOv8改进专栏【链接】,持续更新中~~
六、YOLO性能对比专栏【链接】,持续更新中~
《------正文------》
目录
- 引言
- 目标检测模型分类
- 1.单阶段与双阶段检测:
- [2. 基于锚点与无锚点检测](#2. 基于锚点与无锚点检测)
- [3. 基于CNN与基于Transformer的检测器](#3. 基于CNN与基于Transformer的检测器)
- 基于transformer主干的对象检测模型
- 5.轴对齐(水平)与旋转边界框:
引言
目标检测是计算机视觉的基本任务之一。文章将深入比较关键的目标检测模型,探索它们在各种检测任务中的独特方法、优势和挑战。
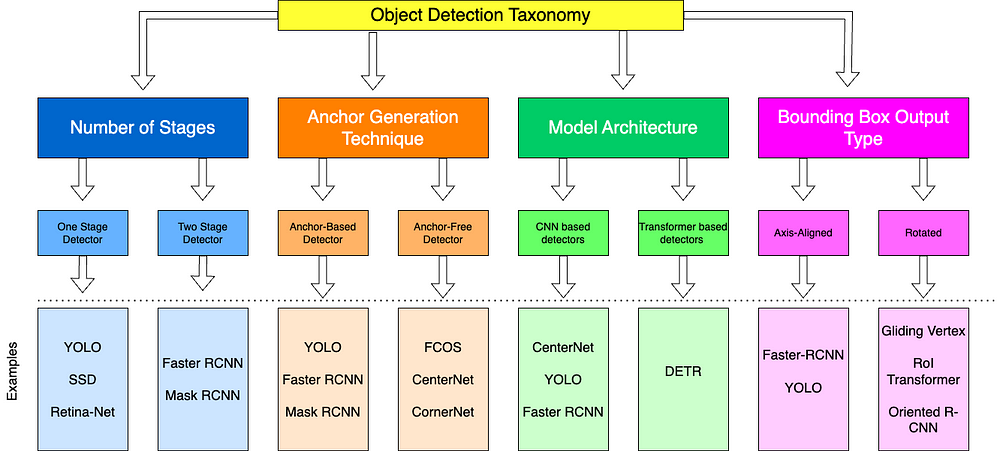
目标检测模型分类
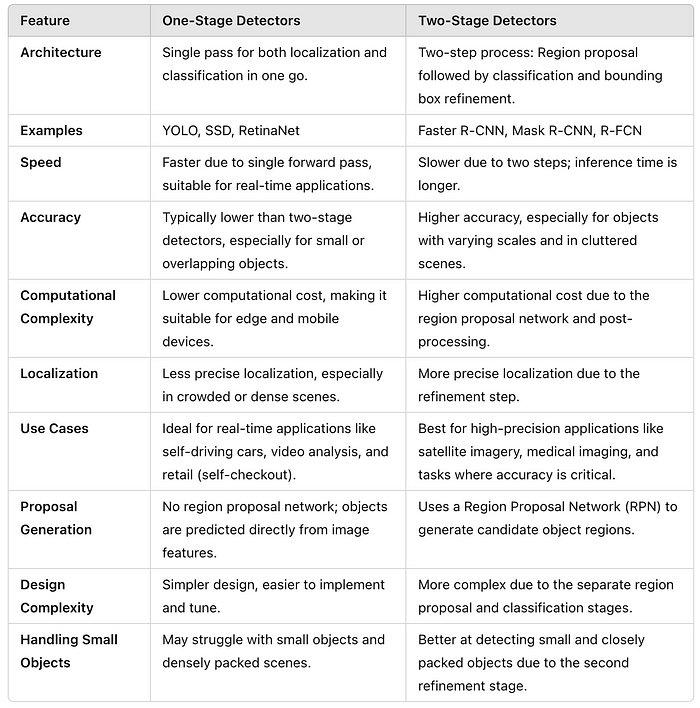
1.单阶段与双阶段检测:
- 单阶段检测(例如,YOLO、SSD)在单次通过中执行对象检测,优先考虑速度和效率,使其成为实时应用的理想选择。
- 双阶段检测(例如,更快的R-CNN)使用两步过程进行区域建议,然后进行分类,专注于准确性,这对复杂或密集的场景特别有益。
2.基于锚点或无锚点检测器:
- 基于锚点的检测器(例如,SSD、YOLOv8)依赖于不同比例和长宽比的预定义边界框(锚点),这些边界框提供了强大的性能,但需要调整。
- 无锚检测器(例如,FCOS、CenterNet、YOLOX)直接预测对象位置,无需使用预定义的锚点,简化了架构,提高了跨不同数据集的适应性。
3.基于CNN与基于Transformer的检测器:
- 基于CNN的检测器利用卷积层有效地捕获局部空间模式。
- 基于Transformer的检测器(例如,DETR)利用自注意机制来捕捉图像中远处对象之间的全局上下文和关系。它们可以很好地扩展大型数据集,但计算成本更高。
4.轴对齐与旋转边界框:
- 轴对齐框与图像轴对齐,提供计算简单性,但难以处理旋转对象和密集场景。
- 旋转的边界框旋转以适应对象的方向,从而提高了有角度对象的精度,但代价是增加了计算复杂性。
1.单阶段与双阶段检测:
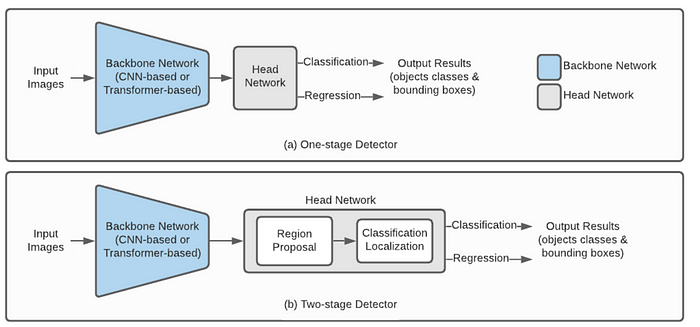
单阶段与双阶段检测的主要区别 :
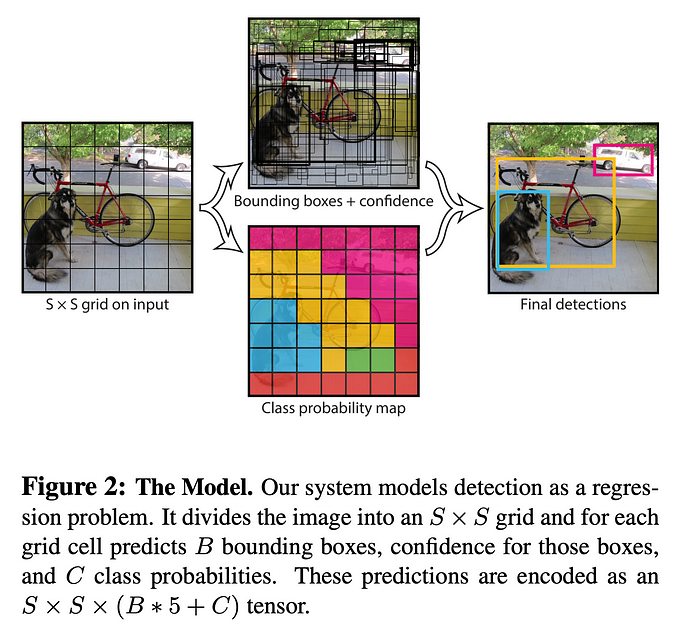
单阶段检测,也称为单次 检测,在网络的单个前向传递中执行定位和分类。这些模型旨在通过消除区域建议阶段来平衡速度和准确性。单级检测器将图像分割成更小的图像。图像被分割成尺寸为S×S的正方形网格。例如,下图显示了YOLO的模型设计
两阶段检测器分为两个不同的步骤:生成区域建议,然后对这些建议区域进行分类和细化。这些方法的重点是通过在分类之前细化潜在的对象区域来产生高度准确的结果。
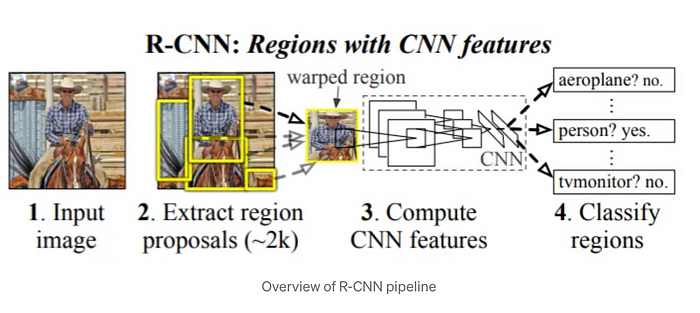
2. 基于锚点与无锚点检测
基于锚点与无锚点检测的主要区别:
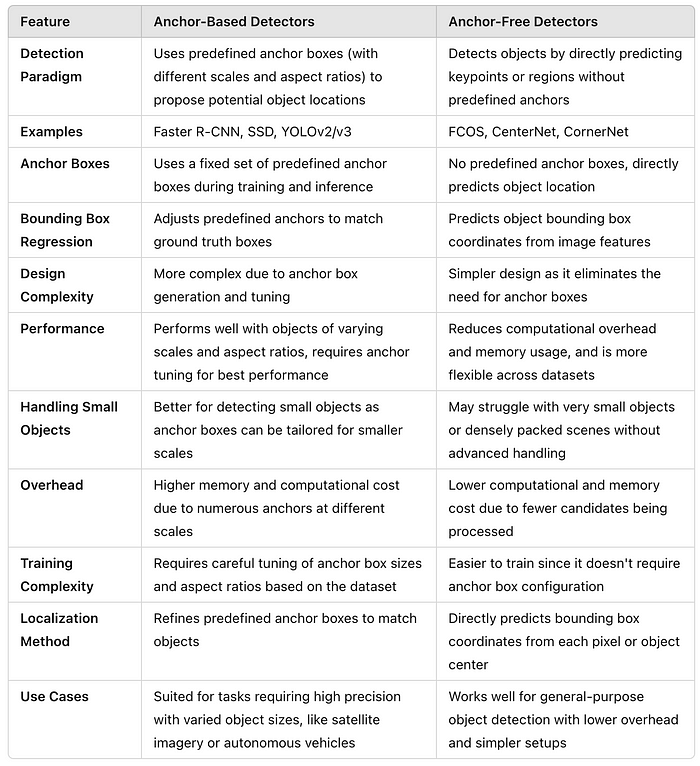
1.基于锚点的物体检测器
这些方法使用预定义的框,称为锚,在不同的尺度和长宽比,以提出潜在的对象区域。然后,网络在训练过程中调整锚点,以更好地适应地面实况对象。
模型特点:
- 预定义锚点: 锚点是基于数据集中对象大小和纵横比的先验知识设计的。
- 边界框回归: 模型在训练过程中调整锚点的位置和大小,以匹配地面实况框。
- 复杂性: 需要调整锚尺寸和纵横比,这可能使设计更加复杂。
- 性能: 通常可以很好地处理不同的对象比例和长宽比,但对于大型或非常小的对象可能会遇到困难。
优点:
- 由于使用了锚点,更好地检测不同大小和形状的物体。
- 由于预先定义的锚点,通常收敛速度更快,更稳定。
缺点:
- 需要调整锚框,这可能是特定于锚的,并且很耗时。
- 由于大量锚点,内存使用率更高
示例如下:
- Faster R-CNN
- YOLO(You Only Look Once)
- SSD(单次发射多盒探测器)
2.无锚式物体检测器
这些模型消除了对预定义的锚框的需要,并直接预测对象的中心或角。
产品特点:
- 直接定位: 预测关键点(例如,对象中心、角),而不依赖于预定义的锚。
- 更简单的设计: 无需设计或调整锚大小,使模型更简单,并可能在数据集之间更灵活。
- 边界框预测: 通常预测对象的中心及其高度和宽度,或对象角的位置。
优点:
- 更简单的架构,超参数更少(无锚调优)。
- 由于减少了计算开销(需要处理的框更少),可能更快地进行推理。
- 更适合检测不同大小和尺度的物体,而无需预定义的假设。
缺点:
- 有时对于小对象或极端长宽比不太准确,因为该方法需要从较少的线索中推断这些特征。
- 可能需要更多的数据增强或复杂的损失函数,以匹配基于锚点的方法的性能。
示例如下:
- CenterNet
- FCOS(全卷积一级目标检测)
- CornerNet
下面是一个比较表,总结了FCOS 、CornerNet 和CenterNet之间的差异:
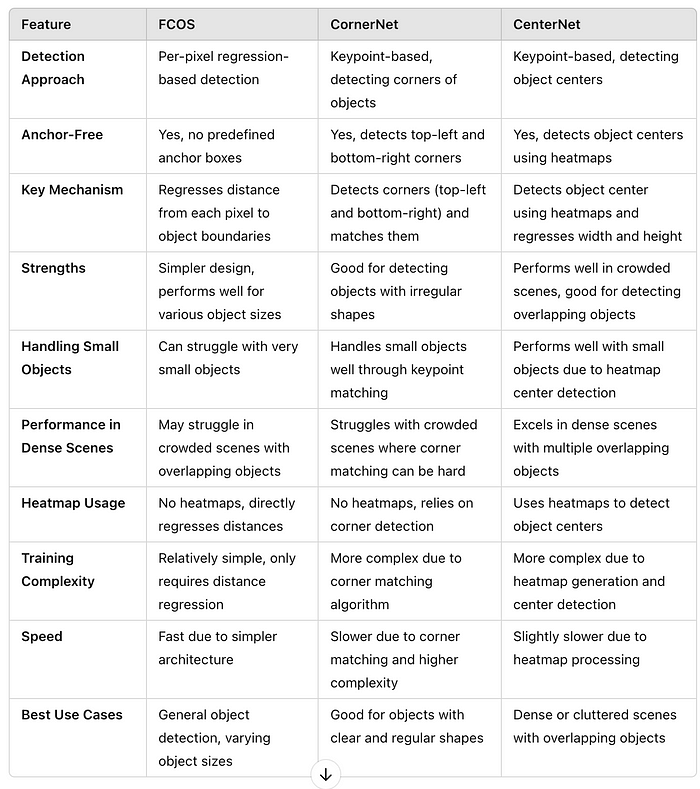
3. 基于CNN与基于Transformer的检测器
基于CNN与基于Transformer的检测器的主要区别:
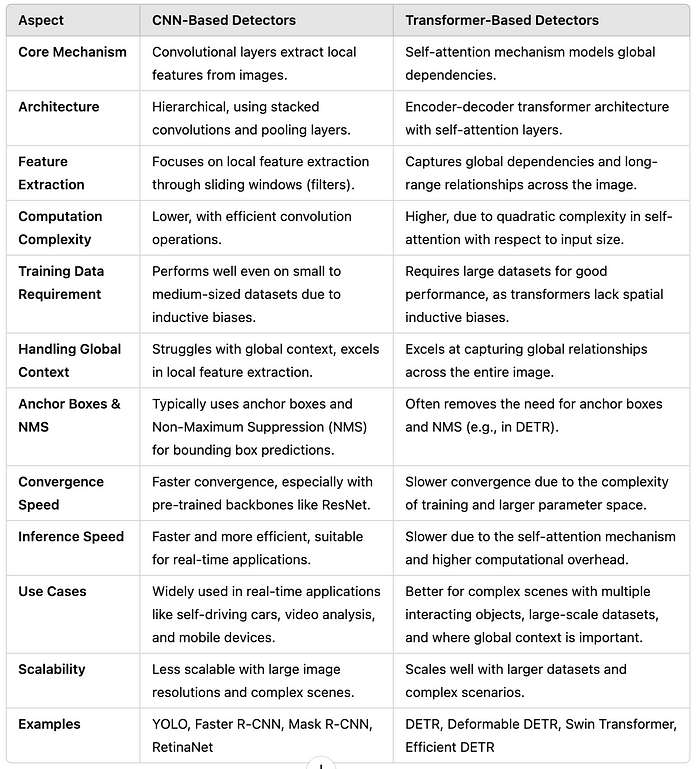
DETR系列
概览:
作用 :DETR模型系列代表了一个完整的对象检测框架,其中整个检测过程(包括特征提取,对象检测和边界框预测)都是使用transformers完成的。DETR消除了对区域建议网络、锚框或非最大抑制的需要。
体系结构:
- DETR模型使用Transformer编码器-解码器结构。编码器处理图像特征,解码器预测一组固定的边界框和对象类。
- DETR将特征提取、对象分类和边界框预测集成到一个端到端的Transformer模型中。
DETR变体:
- DETR(DetectionTransformer):
- 最初的DETR引入了使用变压器端到端进行对象检测的概念,从而消除了对传统锚盒和NMS的需求。
2.可变形DETR:
- 通过使用可变形注意力提高DETR的效率,使模型能够专注于图像的相关部分并降低计算成本。
主要特点:
- 端到端对象检测:DETR模型执行对象检测,而不需要区域建议,锚框或非最大抑制(NMS)等后处理步骤。输出由模型直接预测为一组对象。
- 二分匹配损失:DETR使用独特的匹配过程,使用匈牙利算法将预测的边界框分配给地面实况对象,确保每个对象只被检测一次。
- 检测的自我注意力:DETR模型利用自我注意力机制来建模不同对象和图像部分之间的关系,从而在复杂场景中实现更准确的检测。
优点:
- 简化的检测管道:DETR消除了对锚框、区域建议和NMS等组件的需求,使检测过程更加简化。
- 用于对象检测的全局上下文:与Transformer主干类似,DETR模型捕获全局依赖性,这对于在杂乱或复杂场景中检测对象是有益的。
- 直接预测:边界框直接预测,而不依赖于区域建议或固定锚点。
缺点:
- 收敛速度慢:由于Transformer架构的复杂性,与传统的对象检测模型相比,DETR模型需要更长的训练时间。
- 更高的计算成本:在整个检测管道中使用transformer增加了计算开销,使得DETR模型比基于CNN的检测器更加资源密集。
基于transformer主干的对象检测模型
概述:
角色 :基于transformer的主干用作对象检测模型中的特征提取器。这些模型不依赖于像ResNet或EfficientNet这样的卷积网络(CNN),而是使用transformers来提取图像特征,这些特征稍后将用于对象检测任务。
体系结构:
- 这些骨干通过使用transformers来捕获图像中的长距离依赖关系来取代CNN。Transformer层通常应用于图像补丁或token,这允许它们对图像中不同区域之间的关系进行建模。
- 常见的模型包括ViT(Vision Transformer)和Swin Transformer。
关键示例:
Vision Transformer(ViT):
- 将图像视为一系列面片,并使用Transformer对全局关系进行建模。
Swin Transformer:
- 一个分层的Transformer,在非重叠窗口上运行,使其计算效率更高,更适合下游对象检测任务。
主要特点:
- 特征提取:主要作用是提供图像表示,这些图像表示可以馈送到下游对象检测头,如Faster R-CNN,Mask R-CNN或YOLO。
- 全局上下文:通过利用自注意机制,基于transformer的主干捕获图像不同部分之间的全局依赖关系,允许比传统CNN更多的上下文特征提取。
- 分层设计 :一些主干,如Swin Transformer,提供多尺度特征提取,类似于CNN中的特征金字塔,这有利于检测各种尺度的对象。
优点:
- 更好的全局上下文:变形金刚天生适合捕捉图像中的全局关系,使其成为具有复杂对象交互的场景的理想选择。
- 可扩展性:基于transformer的主干可以很好地扩展更大的数据集和更高的计算资源,并且它们往往在更大的模型和更多的数据中表现得更好。
缺点:
- 更高的计算成本:基于transformer的主干在计算上是昂贵的,特别是对于高分辨率图像。
- 训练数据要求:这些模型需要大量的标记数据才能表现良好,因为它们缺乏CNN的归纳偏差。

5.轴对齐(水平)与旋转边界框:

轴对齐(水平)与旋转边界框模型对比:
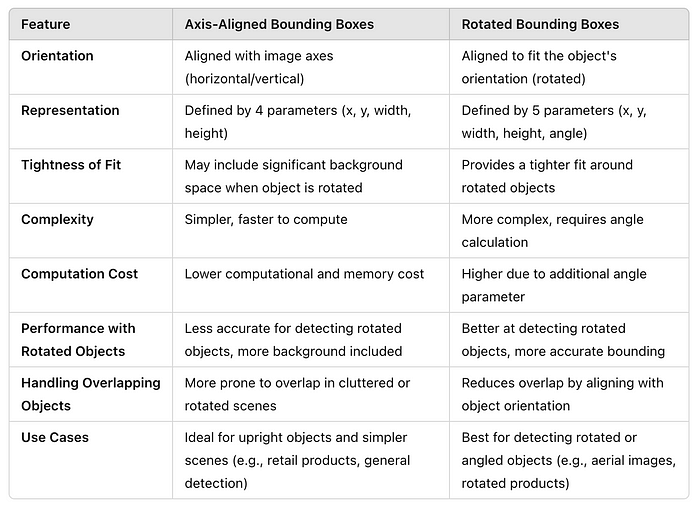
轴对齐的边界框
定义:
轴对齐边界框(AABB)是边界框的传统形式,其中框的边缘平行于图像的坐标轴(即,水平和垂直)。每个框由其左上角和右下角定义。
产品特点:
- 与图像轴对齐:边界框始终与图像的水平轴和垂直轴对齐,而与内部对象的方向无关。
- 更简单的表示:由四个值表示:左上角的坐标,宽度和高度(或者左上角和右下角)。
优点:
- 简单性:易于计算和快速处理,使其广泛用于YOLO和SSD等实时系统。
- 效率:与旋转边界框相比,计算复杂度更低,因为模型不需要考虑方向。
- 适用于一般对象:适用于对象大致直立或没有显著旋转的情况。
缺点:
- 对旋转对象的拟合差:如果对象旋转,则轴对齐的框将具有大量空白空间,导致定位不准确(例如,斜向停放的汽车将导致比所需大的盒子)。
- 密集场景不精确:在多个对象靠近或处于不同角度的场景中,轴对齐的框可能会明显重叠,从而难以区分对象。
旋转边界框
定义:
旋转边界框(也称为定向或旋转框)允许边界框的任意方向以更好地适应对象。这些框可以旋转以与图像中对象的方向对齐。
产品特点:
- 与对象对齐:边界框与对象的方向对齐,最大限度地减少空白空间并更好地封装对象。
- 更复杂的表示:通常由五个值表示:框的中心坐标、宽度、高度和旋转角度(相对于水平轴)。
优点:
- 更好地适合旋转对象:旋转边界框为处于某个角度的对象提供更紧密的适合,减少了空白空间的数量并提高了定位的精度。
- 在密集场景中改进检测:通过将盒子与对象的方向对齐,旋转的盒子减少了附近对象之间的重叠,并有助于更清楚地区分它们。
缺点:
- 更高的计算复杂度:计算和处理旋转的边界框需要更多的计算(例如,计算旋转角度和执行交并(IoU)计算变得更加复杂)。
- 训练更复杂:训练模型来预测边界框和旋转角度比预测轴对齐的框更具挑战性。
- 边缘情况:如果未经适当训练,处理小角度或边缘情况的对象可能会引入噪音或错误。
使用案例:
- 地理空间应用:在卫星图像或航空摄影中,建筑物、船舶或道路等物体通常以任意角度出现,因此旋转框对于准确定位至关重要。
- 文本检测:在文本旋转的情况下(例如,街道标志、带有倾斜文本的文档),旋转的边界框对于准确检测和分割文本区域至关重要。
在选择轴对齐 和旋转边界框 时,决定在很大程度上取决于对象的性质和它们所在的场景。轴对齐框 更简单,计算效率更高,并且在对象直立并始终与图像轴对齐的情况下工作良好。然而,对于以任意角度旋转或放置的对象,例如在航拍图像、密集的零售车或杂乱的环境中,旋转的边界框提供了更紧密的配合,减少了不必要的背景空间,并最大限度地减少了与其他对象的重叠。虽然旋转的边界框为有角度的对象提供了更好的准确性和定位,但由于额外的旋转角度参数,它们具有更高的计算成本和复杂性。 因此,决策应基于增加的精度是否证明额外的计算开销是合理的。

好了,这篇文章就介绍到这里,喜欢的小伙伴感谢给点个赞和关注,更多精彩内容持续更新~~
关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!