🍛循环神经网络(RNN)概述
循环神经网络(Recurrent Neural Network, RNN)是一种能够处理时序数据或序列数据的深度学习模型。不同于传统的前馈神经网络,RNN具有内存单元,能够捕捉序列中前后信息之间的依赖关系。RNN在自然语言处理、语音识别、时间序列预测等领域中具有广泛的应用。
RNN的核心思想是通过循环结构使网络能够记住前一个时刻的信息。每一个时间步,输入不仅依赖于当前的输入数据,还依赖于前一时刻的状态,从而使得RNN能够处理时序信息。
🍛循环神经网络的基本单元
RNN的基本单元由以下部分组成:
- 输入(Input):在每个时间步,输入当前时刻的数据。
- 隐藏状态(Hidden State):每个时间步都有一个隐藏状态,代表对当前输入及前一时刻信息的记忆。
- 输出(Output):根据当前输入和隐藏状态生成输出。
在数学上,RNN的计算可以表示为以下公式:
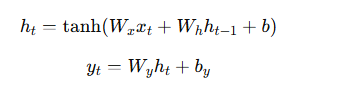
🍛循环神经网络的网络结构
RNN的网络结构可以分为以下几种类型:
- 单层RNN:最简单的RNN结构,只包括一个隐藏层。
- 多层RNN(堆叠RNN):通过堆叠多个RNN层,增加模型的复杂性和表达能力。
- 双向RNN(BiRNN):双向RNN同时考虑了从前往后和从后往前的时序信息,能够获得更加丰富的上下文信息。
- 深度循环神经网络(DRNN):通过增加网络的深度(堆叠多个RNN层)来提高模型的表示能力。
🍛长短时记忆网络(LSTM)
传统的RNN在处理长序列数据时存在梯度消失和梯度爆炸的问题,长短时记忆网络(LSTM)通过引入门控机制来解决这一问题。
LSTM通过使用三个门(输入门、遗忘门和输出门)来控制信息的流动。LSTM的更新过程如下:
- 遗忘门:决定忘记多少旧的信息。
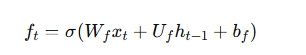
输入门:决定当前时刻的输入信息有多少更新到记忆单元。
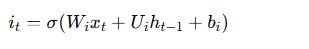
输出门:决定记忆单元的多少信息输出到当前的隐藏状态。
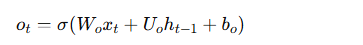
记忆更新:根据遗忘门和输入门更新记忆单元的状态。
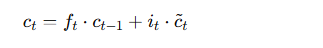
🍛双向循环神经网络(BiRNN)和深度循环神经网络(DRNN)
- 双向RNN(BiRNN):为了捕捉从前到后的信息,双向RNN通过在两个方向上运行两个独立的RNN来获取完整的上下文信息。通过这种结构,BiRNN能够更好地处理具有复杂依赖关系的时序数据。
公式如下:
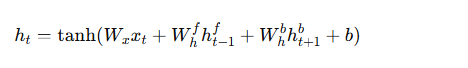
深度循环神经网络(DRNN):通过堆叠多个RNN层,形成深度结构,DRNN能够捕捉更高层次的特征和时序依赖。多层的RNN允许网络从更抽象的层次进行学习。
🍛序列标注与应用
RNN在序列标注任务中的应用非常广泛,尤其是在自然语言处理(NLP)领域。常见的任务包括:
- 命名实体识别(NER):识别文本中的人物、地点、组织等实体。
- 词性标注(POS Tagging):标注每个单词的词性(如名词、动词等)。
- 语音识别:将语音信号转化为文字。
- 情感分析:分析文本的情感倾向。
通过在RNN的输出层使用Softmax激活函数,可以实现多分类任务,如对每个时间步的输入数据进行分类。
🍛代码实现与示例
以下是一个简单的基于PyTorch的RNN模型实现,用于文本分类任务,代码仅供参考
import torch
import torch.nn as nn
import torch.optim as optim
# 定义RNN模型
class RNNModel(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(RNNModel, self).__init__()
self.rnn = nn.RNN(input_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
# x: 输入的序列数据
out, _ = self.rnn(x) # 获取RNN的输出
out = out[:, -1, :] # 只取最后一个时间步的输出
out = self.fc(out)
return out
# 参数设置
input_size = 10 # 输入特征的维度
hidden_size = 50 # 隐藏层的维度
output_size = 2 # 输出的类别数(例如,二分类问题)
# 创建模型
model = RNNModel(input_size, hidden_size, output_size)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 示例输入数据
inputs = torch.randn(32, 5, input_size) # 32个样本,每个样本有5个时间步,输入特征维度为10
labels = torch.randint(0, 2, (32,)) # 随机生成标签,2类
# 训练过程
outputs = model(inputs)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"Loss: {loss.item()}")🍛实战(IMDB影评数据集)
环境准备
pip install torch torchvision torchaudio torchtext完整源码
代码仅供参考
import torch
import torch.nn as nn
import torch.optim as optim
import torchtext
from torchtext.datasets import IMDB
from torchtext.data import Field, BucketIterator
# 数据预处理
TEXT = Field(sequential=True, tokenize='spacy', include_lengths=True)
LABEL = Field(sequential=False, use_vocab=True, is_target=True)
# 下载IMDB数据集
train_data, test_data = IMDB.splits(TEXT, LABEL)
# 构建词汇表并用预训练的GloVe词向量初始化
TEXT.build_vocab(train_data, vectors='glove.6B.100d', min_freq=10)
LABEL.build_vocab(train_data)
# 创建训练和测试数据迭代器
train_iterator, test_iterator = BucketIterator.splits(
(train_data, test_data),
batch_size=64,
device=torch.device('cuda' if torch.cuda.is_available() else 'cpu'),
sort_within_batch=True,
sort_key=lambda x: len(x.text)
)
# 定义RNN模型
class RNNModel(nn.Module):
def __init__(self, input_dim, embedding_dim, hidden_dim, output_dim, n_layers, dropout):
super(RNNModel, self).__init__()
self.embedding = nn.Embedding(input_dim, embedding_dim)
self.rnn = nn.RNN(embedding_dim, hidden_dim, num_layers=n_layers, dropout=dropout, batch_first=True)
self.fc = nn.Linear(hidden_dim, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, text, text_lengths):
embedded = self.embedding(text)
packed_embedded = nn.utils.rnn.pack_padded_sequence(embedded, text_lengths, batch_first=True, enforce_sorted=False)
packed_output, hidden = self.rnn(packed_embedded)
output = self.dropout(hidden[-1])
return self.fc(output)
# 超参数设置
input_dim = len(TEXT.vocab)
embedding_dim = 100
hidden_dim = 256
output_dim = len(LABEL.vocab)
n_layers = 2
dropout = 0.5
# 初始化模型、损失函数和优化器
model = RNNModel(input_dim, embedding_dim, hidden_dim, output_dim, n_layers, dropout)
optimizer = optim.Adam(model.parameters())
criterion = nn.CrossEntropyLoss()
# 将模型和数据转移到GPU(如果可用)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = model.to(device)
criterion = criterion.to(device)
# 训练模型
def train(model, iterator, optimizer, criterion):
model.train()
epoch_loss = 0
epoch_acc = 0
for batch in iterator:
text, text_lengths = batch.text
labels = batch.label
optimizer.zero_grad()
# 预测
predictions = model(text, text_lengths).squeeze(1)
# 计算损失和准确率
loss = criterion(predictions, labels)
acc = binary_accuracy(predictions, labels)
# 反向传播
loss.backward()
optimizer.step()
epoch_loss += loss.item()
epoch_acc += acc.item()
return epoch_loss / len(iterator), epoch_acc / len(iterator)
# 计算二分类准确率
def binary_accuracy(predictions, labels):
preds = torch.argmax(predictions, dim=1)
correct = (preds == labels).float()
return correct.sum() / len(correct)
# 测试模型
def evaluate(model, iterator, criterion):
model.eval()
epoch_loss = 0
epoch_acc = 0
with torch.no_grad():
for batch in iterator:
text, text_lengths = batch.text
labels = batch.label
predictions = model(text, text_lengths).squeeze(1)
loss = criterion(predictions, labels)
acc = binary_accuracy(predictions, labels)
epoch_loss += loss.item()
epoch_acc += acc.item()
return epoch_loss / len(iterator), epoch_acc / len(iterator)
# 训练过程
N_EPOCHS = 5
for epoch in range(N_EPOCHS):
train_loss, train_acc = train(model, train_iterator, optimizer, criterion)
test_loss, test_acc = evaluate(model, test_iterator, criterion)
print(f'Epoch {epoch+1}/{N_EPOCHS}')
print(f'Train Loss: {train_loss:.3f} | Train Acc: {train_acc*100:.2f}%')
print(f'Test Loss: {test_loss:.3f} | Test Acc: {test_acc*100:.2f}%')-
数据预处理:
- 我们使用了torchtext库来下载和处理IMDB影评数据集。
- 通过
Field定义了文本和标签的预处理方法。tokenize='spacy'表示使用Spacy库进行分词。 build_vocab方法用来建立词汇表,并加载GloVe预训练词向量。
-
模型定义:
-
RNNModel
类定义了一个基础的循环神经网络模型。它包含:
- 一个嵌入层(Embedding),将词汇映射为向量。
- 一个RNN层,处理序列数据。
- 一个全连接层,将隐藏状态映射为最终的输出(情感分类)。
-
我们在RNN层中使用了
pack_padded_sequence来处理不同长度的序列。
-
-
训练和评估:
- 训练和评估函数
train和evaluate分别用于训练和评估模型。 - 使用
Adam优化器和CrossEntropyLoss损失函数进行训练。
- 训练和评估函数
-
准确率计算:
binary_accuracy函数计算预测结果的准确率,适用于二分类问题。
模型评估
模型会输出每个epoch的训练损失和准确率,以及测试损失和准确率,具体结果可以参考下图
注意:en_core_web_sm模型配置下载
🍛总结
循环神经网络(RNN)及其变种如LSTM、BiRNN和DRNN在处理时序数据和序列标注任务中表现出色。尽管RNN存在梯度消失问题,但通过改进的结构(如LSTM和GRU)和双向结构,我们可以更好地捕捉时序数据中的长期依赖。随着深度学习技术的不断进步,RNN及其变种将在更多的实际应用中展现出强大的性能
🍛参考文献
Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural Computation, 9(8), 1735-1780.
结果可以参考下图
注意:en_core_web_sm模型配置下载
🍛总结
循环神经网络(RNN)及其变种如LSTM、BiRNN和DRNN在处理时序数据和序列标注任务中表现出色。尽管RNN存在梯度消失问题,但通过改进的结构(如LSTM和GRU)和双向结构,我们可以更好地捕捉时序数据中的长期依赖。随着深度学习技术的不断进步,RNN及其变种将在更多的实际应用中展现出强大的性能
🍛参考文献
Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural Computation, 9(8), 1735-1780.
Graves, A., & Schmidhuber, J. (2005). Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural Networks, 18(5-6), 602-610.
