数据:
# 线性回归
import torch
import numpy as np
import matplotlib.pyplot as plt
# 随机种子,确保每次运行结果一致
torch.manual_seed(42)
# 生成训练数据
X = torch.randn(100, 3) # 100 个样本,每个样本 3 个特征
true_w = torch.tensor([2.0, 3.0, 4.5] ) # 假设真实权重
true_b = 4.0 # 偏置项
Y = X @ true_w + true_b + torch.randn(100) * 0.2 # 加入一些噪声
# 打印部分数据
print(X[:5])
print(Y[:5])模型:
import torch.nn as nn
# 定义线性回归模型
class LinearRegressionModel(nn.Module):
def __init__(self):
super(LinearRegressionModel, self).__init__()
# 定义一个线性层,输入为2个特征,输出为1个预测值
self.linear = nn.Linear(3, 1) # 输入维度2,输出维度1
def forward(self, x):
return self.linear(x) # 前向传播,返回预测结果
# 创建模型实例
model = LinearRegressionModel()
# 损失函数(均方误差)
criterion = nn.MSELoss()
# 优化器(使用 SGD 或 Adam)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01) # 学习率设置为0.01训练:
# 训练模型
num_epochs = 1000 # 训练 1000 轮
for epoch in range(num_epochs):
model.train() # 设置模型为训练模式
# 前向传播
predictions = model(X) # 模型输出预测值
loss = criterion(predictions.squeeze(), Y) # 计算损失(注意预测值需要压缩为1D)
# 反向传播
optimizer.zero_grad() # 清空之前的梯度
loss.backward() # 计算梯度
optimizer.step() # 更新模型参数
# 打印损失
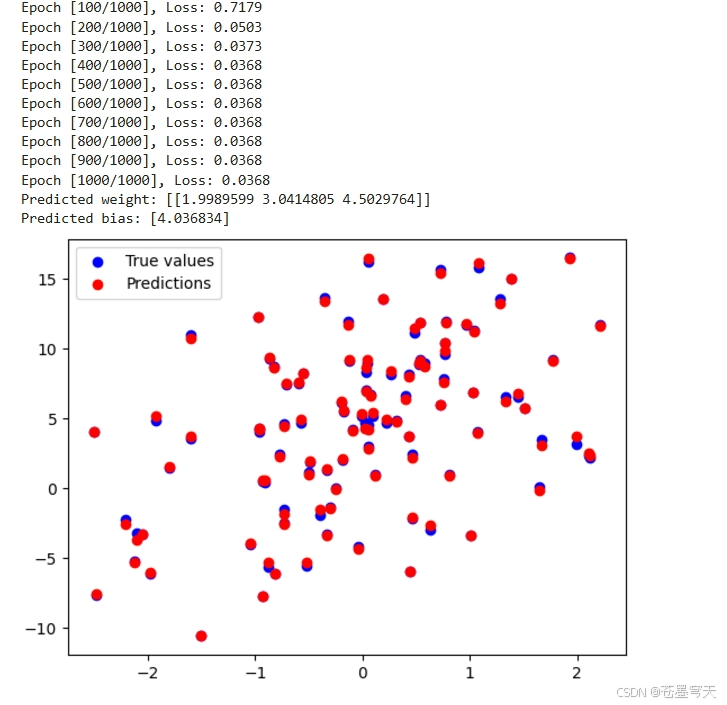
if (epoch + 1) % 100 == 0:
print(f'Epoch [{epoch + 1}/1000], Loss: {loss.item():.4f}')
# 查看训练后的权重和偏置
print(f'Predicted weight: {model.linear.weight.data.numpy()}')
print(f'Predicted bias: {model.linear.bias.data.numpy()}')
# 在新数据上做预测
with torch.no_grad(): # 评估时不需要计算梯度
predictions = model(X)
# 可视化预测与实际值
plt.scatter(X[:, 0], Y, color='blue', label='True values')
plt.scatter(X[:, 0], predictions, color='red', label='Predictions')
plt.legend()
plt.show()