1st author
paper: [2406.06592 Improve Mathematical Reasoning in Language Models by Automated Process Supervision](https://arxiv.org/abs/2406.06592)
5. 总结 (结果先行)
论文提出了一种名为 OmegaPRM 的新颖的、基于蒙特卡洛树搜索 (MCTS) 的算法,用于全自动、高效地收集大规模、高质量的过程监督数据,以训练过程奖励模型 (PRM) 来提升大型语言模型 (LLM) 的数学推理能力。
贡献:
- 高效性: 通过巧妙结合 MCTS 的探索机制和二分查找的快速错误定位能力,显著提高了过程监督数据的收集效率,相比传统暴力蒙特卡洛方法有约75倍的提升。
- 数据质量 : MCTS 的设计使其能够系统性地探索推理空间,平衡正负样本,并通过特定的价值函数 Q ( s , r ) Q(s,r) Q(s,r) 优先挖掘对PRM训练更有价值的"难负例"。
- 自动化与成本效益: 整个数据收集和PRM训练过程无需人工干预,大幅降低了获取过程监督数据的成本。
局限性与展望:
- 自动化标注的噪声: 尽管实验效果显著,但自动化标注过程不可避免地会引入一些噪声 (假阳性和假阴性标签)。未来可以研究噪声对 PRM 性能的具体影响,以及如何进一步降低或利用这些噪声。
- 依赖 (问题, 正确答案) 对: 当前的 OmegaPRM 仍然需要预先存在的 (问题, 黄金答案) 对来判断 rollout 的最终正确性。这限制了其在没有标准答案的开放式任务上的直接应用。
- 未来工作可以探索将自动化标注与少量高质量人工标注相结合的策略,以及如何将此类方法推广到更广泛的、缺乏明确答案的复杂推理任务中。

1. 思想
大规模语言模型 (LLM) 在解决复杂的多步数学推理问题时仍面临挑战。传统的结果监督 (Outcome Supervision) ,例如使用结果奖励模型 (ORM) 判断最终答案的正确性,对于长推理链而言,其信号过于稀疏,无法有效指导中间步骤的推理。过程监督 (Process Supervision) 通过对推理过程中的每一步进行评估和奖励,提供了更细粒度的反馈,已被证明在提升复杂推理能力方面更有效。然而,获取高质量的过程监督数据通常依赖昂贵的人工标注,或效率低下的暴力蒙特卡洛估计,这限制了其大规模应用。
论文旨在解决自动化、高效地收集高质量过程监督数据的难题,进而训练出更强大的过程奖励模型 (PRM),以提升 LLM 的数学推理性能。
核心思路分为以下几个层面:
- 自动化过程数据标注 : 提出一种名为 OmegaPRM 的新型蒙特卡洛树搜索 (MCTS) 算法,用于自动化地为推理步骤生成正确性标签。
- MCTS 核心机制 :
- 高效错误定位 : OmegaPRM 内部采用二分查找策略,在思维链 (CoT) 中快速定位第一个错误步骤。
- 数据质量与平衡 : MCTS 框架通过系统性的搜索与评估,能够有效地探索推理路径,并平衡正负样本,同时侧重于收集"有价值"的错误样本 (即模型易错但应能正确识别的步骤)。
- PRM 训练: 利用 OmegaPRM 收集到的大量 <(问题, 部分解路径), 步骤正确性> 标注数据,训练一个 PRM。
- 推理增强 : 将训练好的 PRM 与加权自洽性 (weighted self-consistency) 解码策略结合,在推理时选择最优的解题路径。
2. 方法
2.1 过程监督 vs. 结果监督
- 结果奖励模型 (ORM) : 给定一个问题 q q q 和一个完整的模型生成解答 x x x,ORM 输出一个概率 p = ORM ( q , x ) p = \text{ORM}(q, x) p=ORM(q,x),表示该解答 x x x 中最终答案的正确性。
- 过程奖励模型 (PRM) : 给定一个问题 q q q、到第 t − 1 t-1 t−1 步的部分解 x 1 : t − 1 x_{1:t-1} x1:t−1,以及当前第 t t t 步的推理 x t x_t xt,PRM 输出一个概率 p t = PRM ( q , x 1 : t − 1 , x t ) p_t = \text{PRM}(q, x_{1:t-1}, x_t) pt=PRM(q,x1:t−1,xt),表示步骤 x t x_t xt 在当前上下文中的正确性。
- x 1 : t − 1 = x 1 , . . . , x t − 1 x_{1:t-1} = x_1, ..., x_{t-1} x1:t−1=x1,...,xt−1: 解答的前 t − 1 t-1 t−1 个步骤。
- x t x_t xt: 当前的第 t t t 个推理步骤。
- PRM 会对 解题过程中的每一个中间步骤 的正确性进行打分,从而提供更细致的反馈。
2.2 基于蒙特卡洛的自动化过程标注
为了训练 PRM,需要为大量的 <(问题 q q q, 部分解路径 x 1 : t − 1 x_{1:t-1} x1:t−1), 当前步骤 x t x_t xt> 数据对,标注 x t x_t xt 的正确性。论文采用蒙特卡洛方法自动完成此标注。
-
核心思想 : 从一个部分解 x 1 : t x_{1:t} x1:t (即 x 1 : t − 1 x_{1:t-1} x1:t−1 加上 x t x_t xt) 出发,使用一个"补全器"策略 (可以是另一个 LLM,或当前正在优化的 LLM 本身) 生成 k k k 条完整的解路径 (称为 rollouts)。
-
步骤正确性估计 ( C t C_t Ct) :
C t = MonteCarlo ( q , x 1 : t ) = 从第 t 步之后继续推演能得到正确最终答案的 rollout 数量 从第 t 步之后继续推演的总 rollout 数量 C_t = \text{MonteCarlo}(q, x_{1:t}) = \frac{\text{从第 } t \text{ 步之后继续推演能得到正确最终答案的 rollout 数量}}{\text{从第 } t \text{ 步之后继续推演的总 rollout 数量}} Ct=MonteCarlo(q,x1:t)=从第 t 步之后继续推演的总 rollout 数量从第 t 步之后继续推演能得到正确最终答案的 rollout 数量- 这里的假设是:在逻辑推理场景下,只要这 k k k 条 rollout 中至少有一条 能够推导出正确 的最终答案,就认为 部分解 x 1 : t x_{1:t} x1:t 及其之前的所有 步骤是正确的。
-
二分查找定位首个错误:
- 目标:对于一个完整的、答案错误的解题路径,高效地找到其中第一个错误的推理步骤。
- 方法:
- 给定一个包含 M M M 个步骤的完整解路径 S = s 1 , s 2 , . . . , s M S = s_1, s_2, ..., s_M S=s1,s2,...,sM。
- 选择中间步骤 s m s_m sm ( m = ⌊ M / 2 ⌋ m = \lfloor M/2 \rfloor m=⌊M/2⌋) 作为切分点。
- 从部分解 S 1 : m = s 1 , . . . , s m S_{1:m} = s_1, ..., s_m S1:m=s1,...,sm 出发,进行 k k k 次 rollout。计算其正确性估计 C m C_m Cm。
- 如果 C m > 0 C_m > 0 Cm>0 (即至少有一个 rollout 得到了正确答案),则说明 S 1 : m S_{1:m} S1:m 是正确的,第一个错误必然在 S m + 1 : M S_{m+1:M} Sm+1:M 中。继续在后半段查找。
- 如果 C m = 0 C_m = 0 Cm=0 (即所有 k k k 个 rollout 都得到了错误答案),则说明第一个错误很可能在 S 1 : m S_{1:m} S1:m 中 (或 s m s_m sm 本身就是第一个错误)。继续在前半段查找。
- 通过迭代此二分过程,可以将定位首个错误的复杂度从暴力检查每一步的 O ( k M ) O(kM) O(kM) 降低到 O ( k log M ) O(k \log M) O(klogM) 。其中 M M M 是解的总步数, k k k 是每次估计的 rollout 次数。
2.3 OmegaPRM:基于蒙特卡洛树搜索 (MCTS) 的数据收集
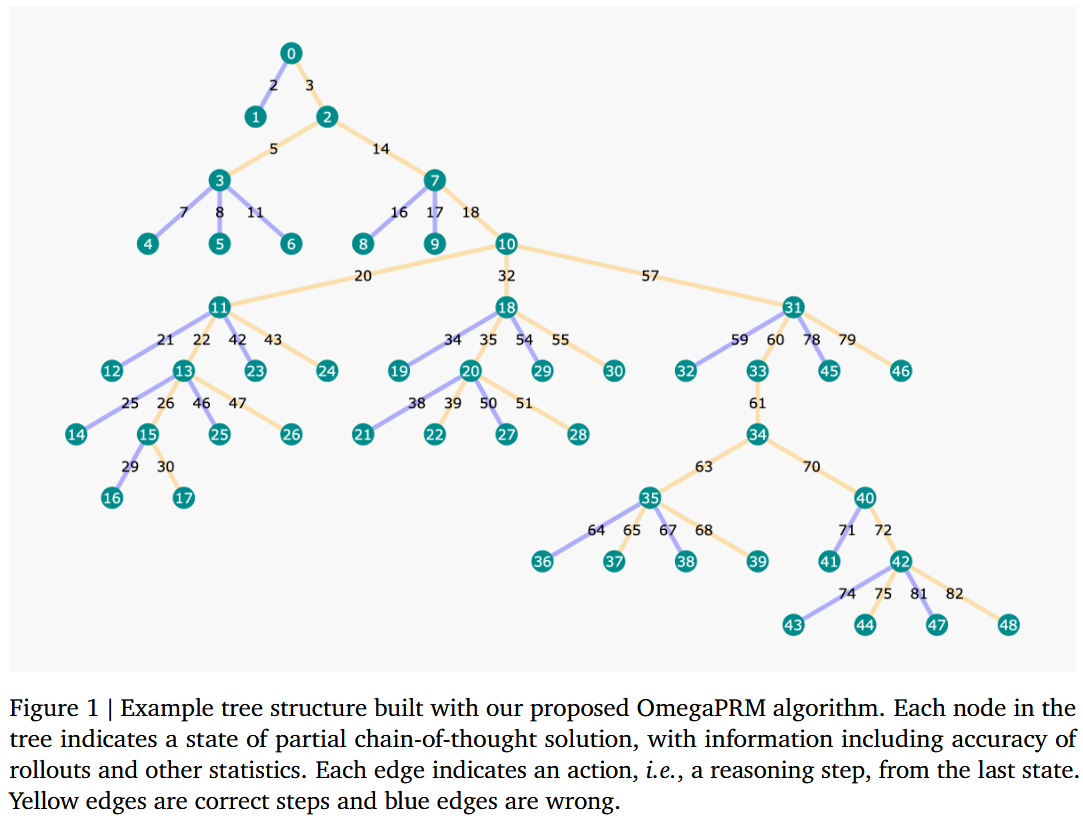
尽管二分查找提高了标注单个错误路径的效率,但每次查找后,生成的 rollout 信息就被丢弃了。为了更系统地收集大量高质量的过程数据,并复用计算资源 ,论文提出了 OmegaPRM 算法,它将上述蒙特卡洛标注方法嵌入到 MCTS 框架中。
- 树结构 :
- 节点 s s s : 代表一个状态,包含原始问题 q q q、当前已经生成的前缀解 x 1 : t x_{1:t} x1:t,以及从该状态出发的所有历史 rollouts { ( s , r i ) } 1 N \{(s, r_i)\}_1^N {(s,ri)}1N。
- 边 ( s , a ) (s,a) (s,a) : 代表一个动作,即从状态 s s s (对应部分解 x 1 : t x_{1:t} x1:t) 出发,执行一个或多个推理步骤 a a a,到达新的状态 s ′ s' s′。
- 每个节点 s s s 存储一组统计量: { N ( s ) , MC ( s ) , Q ( s , r ) } \{N(s), \text{MC}(s), Q(s,r)\} {N(s),MC(s),Q(s,r)}。
- N ( s ) N(s) N(s): 节点 s s s (状态 s s s) 的访问次数。
- MC ( s ) \text{MC}(s) MC(s): 节点 s s s 所代表的部分解 x 1 : t x_{1:t} x1:t 的蒙特卡洛正确性估计值 C t C_t Ct。
- Q ( s , r ) = α 1 − MC ( s ) ⋅ β len ( r ) L Q(s,r) = \alpha^{1-\text{MC}(s)} \cdot \beta^{\frac{\text{len}(r)}{L}} Q(s,r)=α1−MC(s)⋅βLlen(r) : 状态-rollout 价值函数,用于指导 MCTS 中的选择阶段。
- α , β ∈ ( 0 , 1 ] \alpha, \beta \in (0,1] α,β∈(0,1] 和 L > 0 L > 0 L>0 是超参数。
- len ( r ) \text{len}(r) len(r) 是 rollout r r r 的长度 (以 token 数量计)。
- α 1 − MC ( s ) \alpha^{1-\text{MC}(s)} α1−MC(s) 项:当 MC ( s ) \text{MC}(s) MC(s) 趋近于 1 (即状态 s s s 被认为是高度正确的) 时,该项值也趋近于 α 0 = 1 \alpha^0=1 α0=1。
- β len ( r ) L \beta^{\frac{\text{len}(r)}{L}} βLlen(r) 项:对过长的 rollout 进行惩罚 (因为 β < 1 \beta < 1 β<1)。
- Q ( s , r ) Q(s,r) Q(s,r) 的设计旨在优先探索那些"被认为是正确的状态"( MC ( s ) \text{MC}(s) MC(s) 高)但其某个具体 rollout r r r 却导向了错误最终答案的情况。这样的样本对于训练 PRM 识别"迷惑性"错误至关重要。
- OmegaPRM 迭代过程 :
-
选择 (Select):
- 算法维护一个当前所有待探索的 rollout 池,这些 rollout 通常来自 0 < MC ( s i ) < 1 0 < \text{MC}(s_i) < 1 0<MC(si)<1 的状态 (即不完全确定其正确性的中间推理状态)。
- 从池中选择一个 ( s , r ) (s,r) (s,r) 对(即一个状态 s s s 及其对应的一条历史 rollout r r r)进行深入探索。选择的依据是最大化 Q ( s , r ) + U ( s ) Q(s,r) + U(s) Q(s,r)+U(s)。
- U ( s ) = c p u c t ∑ j N ( s j ) 1 + N ( s ) U(s) = c_{puct} \frac{\sqrt{\sum_j N(s_j)}}{1+N(s)} U(s)=cpuct1+N(s)∑jN(sj) 。这是上信赖界 (UCB) 算法的一个变种,称为 PUCT (Polynomial Upper Confidence Trees)。
- c p u c t c_{puct} cpuct 是一个常数,用于平衡探索与利用。
- ∑ j N ( s j ) \sum_j N(s_j) ∑jN(sj) 原文中指树中所有已访问节点 s j s_j sj 的访问次数总和的平方根,这用于鼓励探索访问次数较少的节点。
- 目标是选择最有价值的 rollout 进行分析,而不是随机选择或平均分配资源。
-
二分搜索 (Binary Search):
- 对在"选择"阶段选中的 rollout ( s , r ) (s,r) (s,r),执行 2.2 节中描述的二分查找算法,以高效定位该 rollout 路径中的第一个错误步骤。
- 在二分查找过程中,所有在第一个错误步骤之前的、作为划分点的中间部分解,如果它们尚未存在于MCTS树中,则会作为新的状态节点被添加到树中。这些新节点对应的边(即从父节点到它们的推理步骤)的正确性也随之确定(若在该错误点前则为正确,错误点本身为错误)。
-
维护/扩展 (Maintain/Expand & Backup-like):
- 当一个 rollout ( s , r ) (s,r) (s,r) 被选择并进行二分搜索后,节点 s s s 的访问次数 N ( s ) N(s) N(s) 会增加。
- 对于二分搜索过程中新生成的 rollout (例如,从某个中间点 m m m 出发进行的 k k k 次新rollout),会计算它们对应的 MC ( s m ) \text{MC}(s_m) MC(sm) 值,并更新或初始化相关的 Q ( s m , r ′ ) Q(s_m, r') Q(sm,r′) 值。
- 这个阶段类似于传统 MCTS 中的"扩展"和"回溯更新"阶段,但更简化,因为主要更新的是直接从二分搜索中获得的统计信息,而非严格的从叶节点到根节点的递归更新。
-
树构建 (Tree Construction): 重复执行"选择"、"二分搜索"、"维护"这三个步骤,直到达到预设的搜索迭代次数限制,或者候选 rollout 池为空。
-
2.4 PRM 训练
当 OmegaPRM 构建的 MCTS 树达到一定规模后,树中的每条边 (代表一个推理步骤) 及其通过上述过程得到的正确性标注,就可以作为训练 PRM 的数据。
-
训练数据形式: 每个样本是一个元组 < ( q , x 1 : t − 1 ) , x t , y ^ t > <(q, x_{1:t-1}), x_t, \hat{y}_t> <(q,x1:t−1),xt,y^t>。
- ( q , x 1 : t − 1 ) (q, x_{1:t-1}) (q,x1:t−1): 问题和到 t − 1 t-1 t−1 步的部分解。
- x t x_t xt: 第 t t t 步的推理。
- y ^ t \hat{y}_t y^t: 步骤 x t x_t xt 的正确性标签,通常是 MC ( s ′ ) \text{MC}(s') MC(s′),其中 s ′ s' s′ 是执行 x t x_t xt 后到达的状态。
-
损失函数: 论文主要采用逐点软标签 (pointwise soft label) 的交叉熵损失。
L pointwise = ∑ i ( y ^ i log y i + ( 1 − y ^ i ) log ( 1 − y i ) ) \mathcal{L}_{\text{pointwise}} = \sum_i (\hat{y}_i \log y_i + (1-\hat{y}_i)\log(1-y_i)) Lpointwise=i∑(y^ilogyi+(1−y^i)log(1−yi))- y ^ i \hat{y}_i y^i: 第 i i i 个训练样本中,对应步骤的 (软) 正确性标签,即 MC ( s ′ ) \text{MC}(s') MC(s′) 值。
- y i = PRM ( ( q , x 1 : t − 1 ) , x t ) y_i = \text{PRM}((q, x_{1:t-1}), x_t) yi=PRM((q,x1:t−1),xt): PRM 模型对该步骤正确性的预测概率。
-
其他可选的训练目标包括:
- 逐点硬标签 : y ^ i = 1 MC ( s ′ ) \> 0 \hat{y}_i = \mathbf{1}\\text{MC}(s') \> 0 y^i=1MC(s′)\>0,即如果蒙特卡洛估计大于0则为1,否则为0。
- 配对损失 (Pairwise Loss): 类似于 RLHF 中训练奖励模型的方法,比较同一前缀下的两个不同后续步骤,PRM 需要预测哪个更优。采用 Bradley-Terry 模型进行建模。
实验结果表明,使用 pointwise soft label 进行训练的效果最佳。
3. 优势
- 全自动化过程监督数据收集: 完全无需昂贵且耗时的人工标注,也避免了对每个步骤都进行暴力蒙特卡洛估计的低效。
- 显著提升的标注效率 : 结合了 MCTS 的系统性探索和二分查找的快速错误定位,在相同的计算预算下,OmegaPRM 收集数据的效率比传统的暴力蒙特卡洛方法高出约 75 倍。
- 更高质量的数据 :
- MCTS 的选择策略 (特别是 Q ( s , r ) Q(s,r) Q(s,r) 的设计) 倾向于挖掘那些模型容易出错的"难负例" (hard negative examples),即模型认为可能是正确的步骤 ( MC ( s ) \text{MC}(s) MC(s) 较高),但实际后续会导致错误。这有助于训练出判别能力更强的 PRM。
- MCTS 框架有助于在探索过程中自然地平衡正负样本的比例。
- 步骤切分的灵活性: 不同于一些依赖固定规则 (如按换行符) 切分步骤的方法,OmegaPRM 中 MCTS 的"动作" (即推理步骤) 可以是任意长度的 token 序列,这由二分查找的切分点动态决定,更具灵活性。
- 无需人工干预的端到端流程: 从数据收集到 PRM 训练,整个流程可以自动化进行,具有良好的可扩展性。
4. 实验
4.1 实验设置
- 数据集 :
- MATH: 包含 12K 训练样本,测试时使用其官方 5K 测试集中的一个 500 题代表性子集 (MATH500)。
- GSM8K: 小学数学应用题数据集。
- 基础语言模型 :
- Gemini Pro: 经过数学指令微调的版本 (在 MATH 测试集上约 51% 准确率)。
- Gemma2 27B: 使用其预训练检查点,配合 4-shot CoT 提示。
- PRM 训练: PRM 模型均从相应基础模型的预训练检查点开始训练。
- OmegaPRM 数据生成 :
- 在 MATH 训练集的每个问题上,MCTS 搜索上限为 100 次迭代。
- 最终收集了超过 150 万个带有过程监督标签的推理步骤。
- 为减少噪声,过滤掉 了对于当前模型而言 "太难" (如32次rollout全错)或 "太简单" (32次rollout全对)的问题。
- 每次蒙特卡洛正确性估计使用 k = 8 k=8 k=8 条 rollouts。
- OmegaPRM 超参数: Q ( s , r ) Q(s,r) Q(s,r) 中 α = 0.5 , β = 0.9 , L = 500 \alpha=0.5, \beta=0.9, L=500 α=0.5,β=0.9,L=500; U ( s ) U(s) U(s) 中 c p u c t = 0.125 c_{puct}=0.125 cpuct=0.125。
- 对比方法 (用于 PRM 训练数据来源) :
- PRM800K (Lightman et al., 2023): 包含约 800K 人工标注的过程监督数据。
- Math-Shepherd (Wang et al., 2024a): 一种自动化的过程数据收集方法,但未使用 MCTS,更接近暴力蒙特卡洛。
- Math-Shepherd (our impl): 论文作者基于 Math-Shepherd 思想复现的暴力蒙特卡洛数据收集方法。
- 评估方式 :
- 使用训练好的 PRM,结合加权多数投票 (weighted majority voting) 进行最终答案选择。具体地,一条完整解路径的最终得分被计算为其所有中间步骤 PRM 得分的乘积。
- 生成 N N N (例如 N = 64 N=64 N=64) 条候选解路径,PRM 从中选出得分最高的路径,并报告其最终答案的准确率。
4.2 主要结果
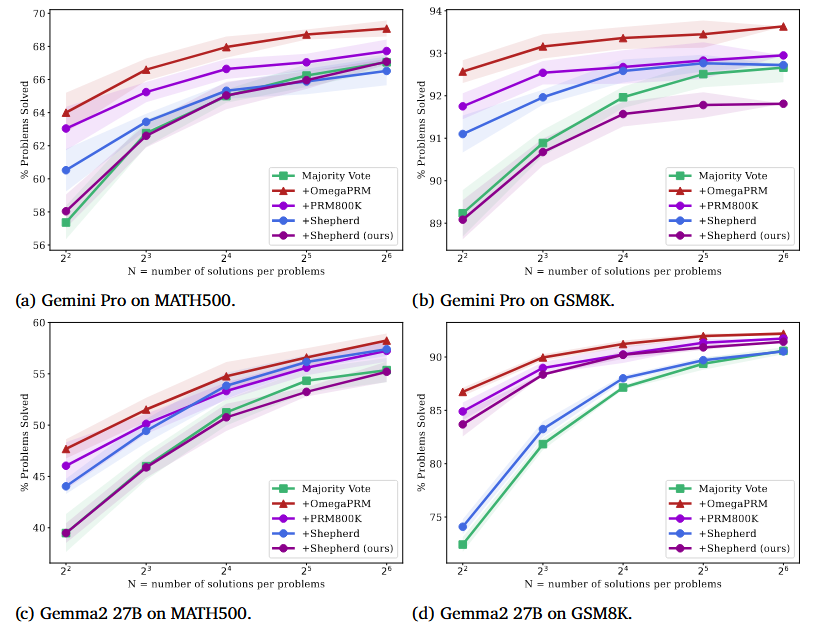
-
性能提升:
- OmegaPRM 训练的 PRM 在所有测试的 LLM 和数据集上均一致且显著地优于其他过程监督数据训练的 PRM。
- 对于 Gemini Pro:
- MATH500: 准确率从基线模型的 51% 提升到 69.4% (使用 OmegaPRM)。
- GSM8K: 准确率从基线模型的 86.4% 提升到 93.6% (使用 OmegaPRM)。
- 对于 Gemma2 27B:
- MATH500: 准确率从基线模型的 42.3% 提升到 58.2% (使用 OmegaPRM)。
- GSM8K: 准确率从基线模型的 74.0% 提升到 92.2% (使用 OmegaPRM)。
- 一个有趣的发现 : 随着用于多数投票的候选解路径数量 ( N N N) 增加,其他 PRM (如基于 PRM800K 或 Math-Shepherd 数据训练的) 的性能逐渐收敛到朴素多数投票的水平。相比之下,基于 OmegaPRM 训练的 PRM 始终能维持一个明显的性能优势,这表明 OmegaPRM 学习到了更有效的路径选择策略。
-
步骤长度分布:
- OmegaPRM 产生的推理步骤长度分布与人工设计的 PRM800K 数据集中的步骤长度分布相似。这表明 OmegaPRM 采用的灵活步骤切分策略 (基于二分查找的动态切分) 是合理的,能够生成语义上连贯的步骤。
-
训练目标比较:
- 在 PRM 训练时,使用不同的损失函数目标,其在验证集上的步骤分类准确率如下:
- 逐点软标签 (Pointwise Soft Label, MC ( s ) \text{MC}(s) MC(s) 作为标签): 70.1%
- 配对损失 (Pairwise Loss): 64.2%
- 逐点硬标签 (Pointwise Hard Label, 1 MC ( s ) \> 0 \mathbf{1}\\text{MC}(s)\>0 1MC(s)\>0 作为标签): 63.3%
- 这验证了论文主体实验中使用逐点软标签的合理性。
- 在 PRM 训练时,使用不同的损失函数目标,其在验证集上的步骤分类准确率如下:
-
算法效率:
- 在相同的计算预算下,OmegaPRM 能够生成约 1500 万个过程监督数据点,而传统的暴力蒙特卡洛方法 (Math-Shepherd our impl) 只能生成约 20 万个数据点。OmegaPRM 的数据收集效率提升了约 75 倍。实践中,作者对 OmegaPRM 生成的数据进行了下采样至 150 万用于 PRM 训练。