POCC一般题干都是又臭又长哦,所以我觉得应该要先看下题目问啥子,那我们再相应的找所需要的信息点(精准定位)。而且有的时候又会夹带私货考一些别的基础知识对吧,可以单拎出来做(408老头很爱干这事)
题型分类
一、数据与表示
二、Cache/虚存(请求分页)
三、指令与CPU
四、汇编语言
五、数据通路
2009
IO方式(中断、DMA)


数据通路


数据通路(Data Path)_cpu内部数据通路包括-CSDN博客
先分析一波题干,发现也没讲啥要注意的就是MDRin和MDRinE的区别,但这个其实看图也能看出来。

那发现是不是这题答案不唯一啊,因为没有规定R0,R1的顺序所以说无论先1后0还是先0后1都是可以的。
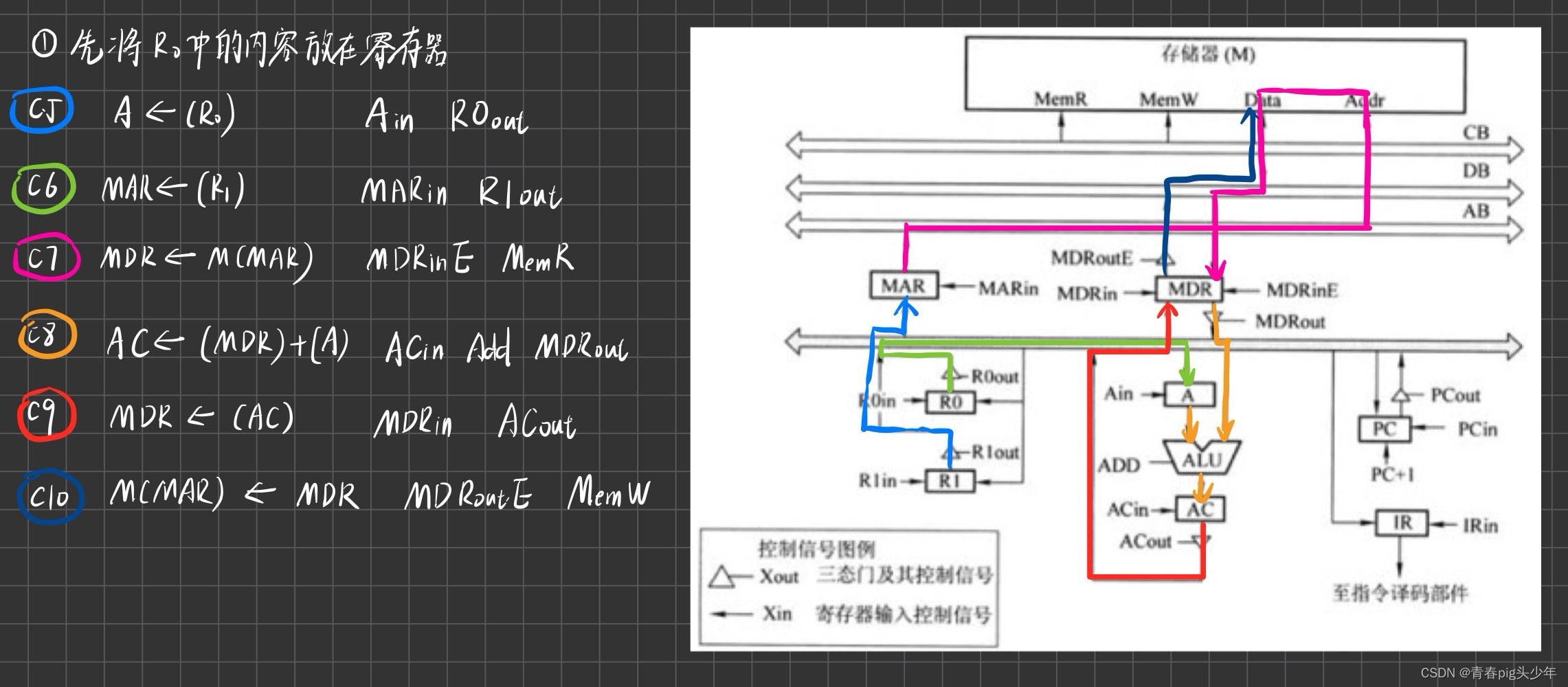
画完这个图了,其实就发现这个是不是还可以再优化一下啊,因为C5和C7即使一块运行也不冲突呀,那这样不就省下了一个时钟周期嘛。(当然题目并没有要求最少时钟周期完成蛤)而且再次提醒到我们ALU是不能放东西的,所以直接丢到AC中。但别完了ALU中的Add。
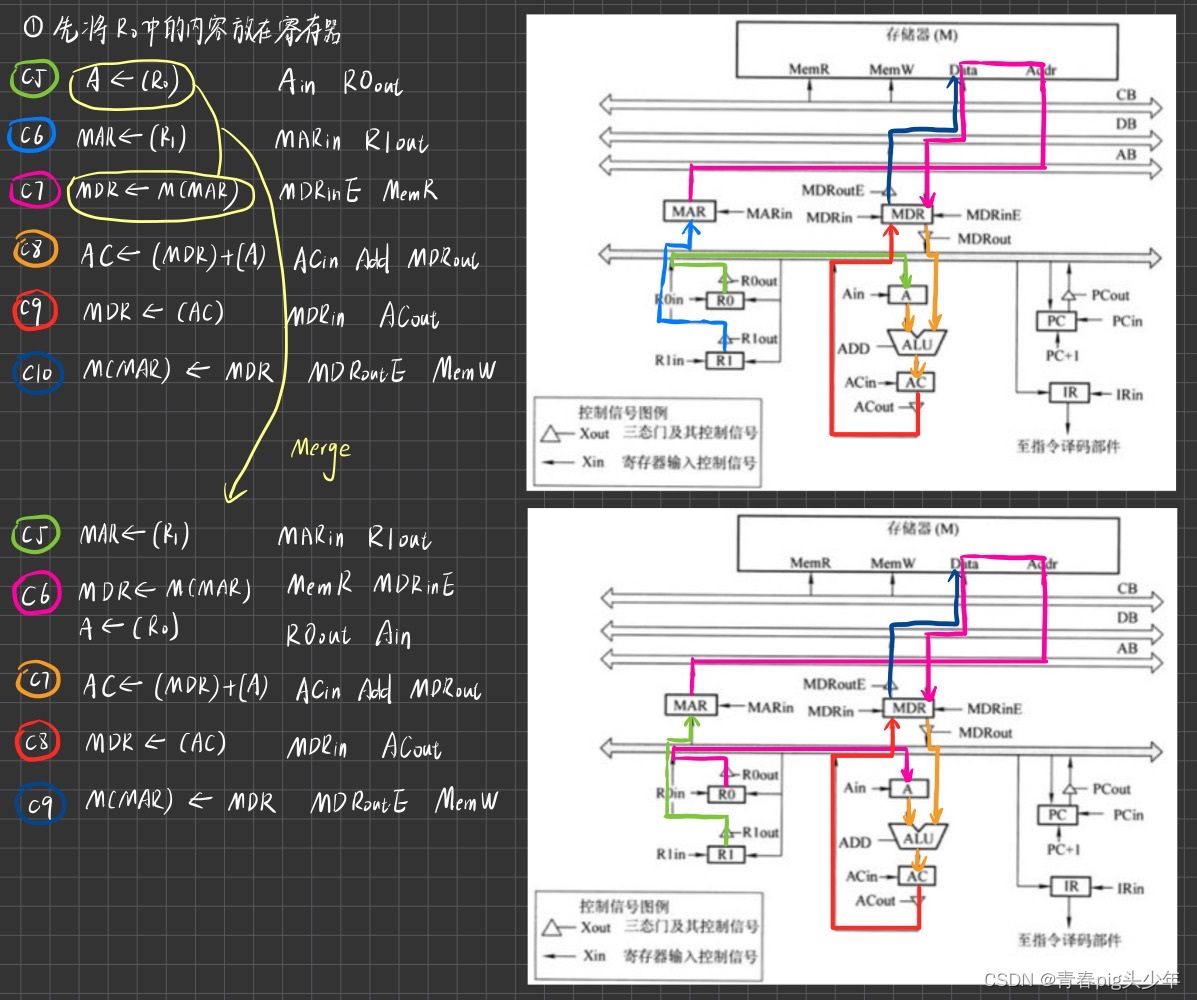
我们再看第二种情况。
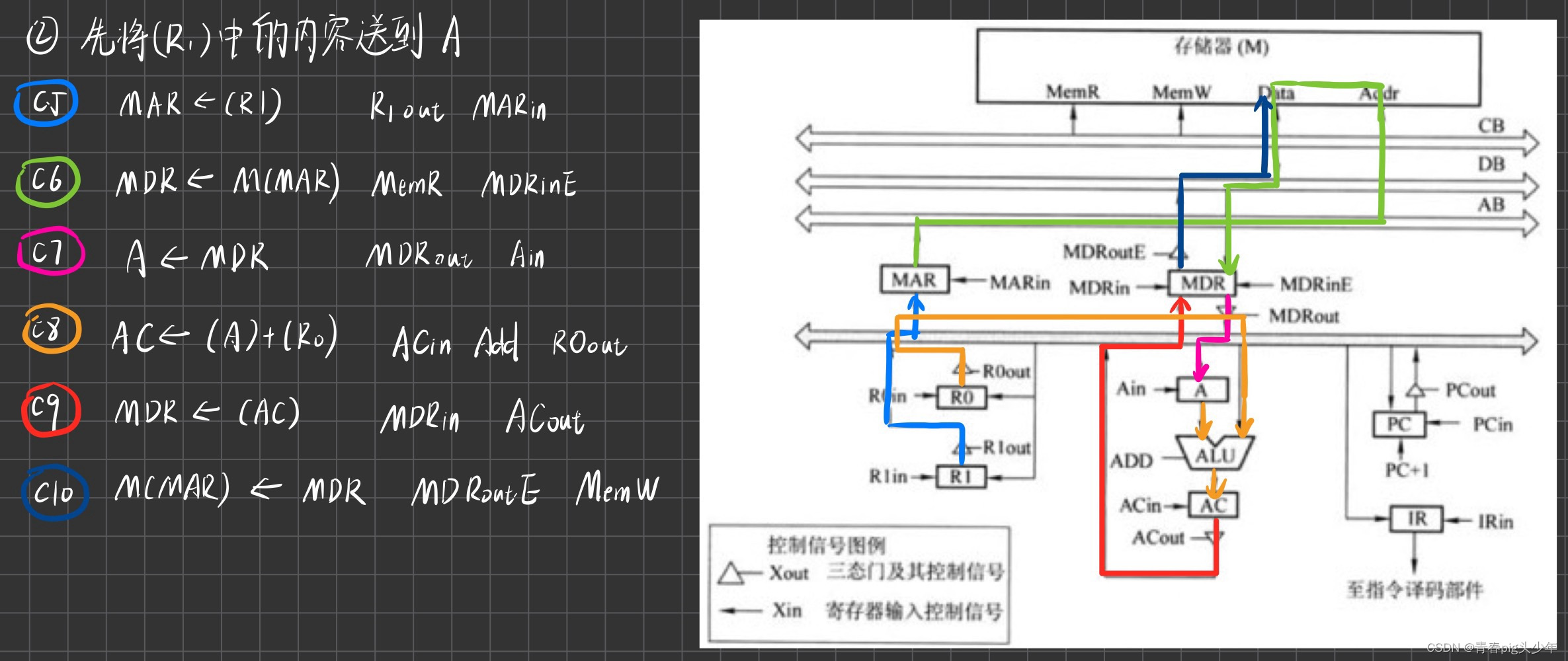
是不是发现了,考察的就还是指令的数据流啊。
2010
指令(指令格式、指令寻址)

 注:2)中直接将偏移量看作0,反正PC能表示的范围也就是总范围了。尤其3)这种串串串的真的要把数据都表示出来看一下,不然很容易混乱。然后就是认真看题目是什么要求照着做就没问题(尤其是(R5)+到底是啥这类讯息要把握好)
注:2)中直接将偏移量看作0,反正PC能表示的范围也就是总范围了。尤其3)这种串串串的真的要把数据都表示出来看一下,不然很容易混乱。然后就是认真看题目是什么要求照着做就没问题(尤其是(R5)+到底是啥这类讯息要把握好)
Cache(总容量、主存的映射方式、命中率)
3)程序A和程序B的数据访问命中率各是多少?哪个程序的执行时间更短?
分析 :这种题目就是算蛤(前提是概念清晰,就好比Cache总容量到底算的是什么?直接映射的行号到底咋算?行优先和列优先有什么不同?Cache和MM之间的交换单位呀?)

故执行程序A比B要快得多。
2011
数据的表示和运算(补码加减)
带符号整数运算语句的执行结果会发生溢出?
分析:
- 咱大眼一看就看到不停地再bb叨什么寄存器里头呀,那应该就是真值和机器数的转换。还有什么无符号数和带符号数之类的,那我们学这个不就是转换嘛,左移右移、判断溢出什么的。
- 8位字长:那就是无论是什么类型的int、unsigned int(哪怕是long及之上的,也是按8位来存低8位)因为寄存器只有8位。
- 一定回答问题要题干要求哦(eg:十六进制表示、十进制表示......)
- 类型强制转换时也并不会改变机器数,只是换了个解释方式。
- m和x就是一样的依托01段对吧,只是一个是带符号数,另一个是无符号数。
- 那再看k1与z1本质上是不是都是那两坨东西进行减法运算,只不过其结果一个是无符号数,一个是带符号数嘛。
- 像题目里面这个什么什么值就是说求真值啦。


3)能。n位加法器实现的是模2^n无符号整数加法运算。
对于无符号整数a和b,a+b可以直接用加法器实现,而a-b可用a加b的补数实现,即a-b=a+-b(mod2^n),所以n位无符号整数加/减运算都可在n位加法器中实现。
由于带符号整数用补码表示,补码加/减运算公式为a+b补=a补+b补(mod2^n),a-b补=a补+-b补(mod2^n),所以n位带符号整数加/减运算都可在n位加法器中实现。
4)带符号整数加/减运算的溢出判断规则为:若加法器的两个输入端(加法)的符号相同且不同于输出端(和)的符号,则结果溢出,或加法器完成加法操作时,若次高位的进位和最高位的进位不同,则结果溢出。
最后一条语句执行时会发生溢出。因为10000110+11110110=(1)01111100,括弧中为加法器的进位,根据上述溢出判断规则,可知结果溢出。或因为2个带符号整数均为负数,它们相加之后,结果小于8位二进制所能表示的最小负数。
注:
- 无符号数转带符号数的过程
- 怎么区分真值和机器数
- 同号相减,异号相加不会溢出
- 二进制减法如何借位
- 补码化简
Cache
TLB

分析:这题也给我们了一个小提醒,要分的清楚这些个地址都是在什么场景中生效的!!!有无Cache引入时地址是怎么划分的?主存和Cache之间传送的单位是什么?内存和外存呢?

3)虚拟地址001C60H的前12位为虚页号,即001H,查看001H处的页表项,其对应的有效位为1,故虚拟地址001C60H所在的页面在主存中。页表001H处的页框号为04H,与页内偏移(虚拟地址后12位)拼接成物理地址为04C60H物理地址04C60H=00000100110001100000B,主存块只能映射到Cache的第3行(即第011B行),由于该行的有效位=1,标记(值为105H)04CH(物理地址高12位),故不命中。
4)由于TLB采用四路组相联,故TLB被分为8/4=2个组,因此虚页号中高11位为TLB标记、最低1位为TLB组号。虚拟地址024BACH=000000100100101110101100B,虚页号为000000100100B,TLB标记为00000010010B(即012H), TLB组号为0B, 因此,该虚拟地址所对应物理页面只可能映射到TLB的第0组。组0中存在有效位=1、标记=012H的项,因此访问TLB命中,即虚拟地址024BACH所在的页面在主存中。
2012
IO方式(DMA)
性能指标(MIPS、带宽)
Cache(命中率)

 注:
注:
- 单位转换!!!
- n体低位交叉存储方式就是一次性能够读n个体
流水线




2013
性能指标(时钟周期)
流水线
Cache


指令



注:按字节编址到底是怎么算的要注意一下。
2014
流水线



注:但其实即使没有三个是时钟周期的阻塞,I1和I5也不会数据相关了(详情见上图)
Cache(数据区容量、命中率)



注:
- 区分清楚Cache总容量和数据容量,还有这是指令Cache
- 为什么TLB会多一次呢,因为还要考虑到第一次访问数组A时,会先查一次TLB,然后产生缺页,处理完缺页中断后,会重新访问A0,此时又查TLB
2015
数据通路


注:

指令



2016
IO方式(中断)


Cache
TLB



注:主存块号=标记+Cache行号
(3)Cache缺失带来的开销小,而处理缺页的开销大。因为缺页处理需要访问磁盘,而Cache缺失只要访问主存。
(4)因为采用直写策略时需要同时写快速存储器和慢速存储器,而写磁盘比写主存慢很多,所以,在Cache-主存层次,Cache可以采用直写策略,而在主存一外存(磁盘)层次,修改页面内容时总是采用回写策略。
2017
数据的表示(int和float类型的转换、IEEE754)


汇编



2018
IO方式(程序查询、中断、DMA)


Cache(总容量、映射方式)
TLB(映射方式)



注:

2019
汇编



Cache(地址结构)


2020
补码乘法

(1)编译器可以将乘法运算转换为一个循环代码段,在循环代码段中通过比较、加法、移位等指令实现乘法运算。
(2)控制逻辑的作用为:控制循环次数,控制加法和移位操作。
(3)a)最长,c)最短。
- 对于 a),需要用循环代码段(即软件)实现乘法操作,因而需反复执行很多条指令,而每条指令都需要取指 令、译码、取数、执行并保存结果,所以执行时间很长;
- 对于 b)和 c),都只要用一条乘法指令实现乘法 操作,不过,b)中的乘法指令需要多个时钟周期才能完成,而 c)中的乘法指令可以在一个时钟周期内完成, 所以 c)执行时间最短。
(4)当 n=32、x=2^31-1、y=2 时,带符号整数和无符号整数乘法指令得到的 64 位乘积都为 0000 0000 FFFF FFFEH。函数 imul 的结果溢出,而函数 umul 结果不溢出。对于无符号整数乘法,若乘积高 n 位全为 0, 则不溢出,否则溢出。
注:无符号的溢出判断和有符号的溢出判断是否一样呢?
Cache

(1)主存块大小为 64B=2^6 字节,故主存地址低 6 位为块内地址,Cache 组数为 32KB/(64B×8) = 64=2^6 , 故主存地址中间 6 位为 Cache 组号,主存地址中高 32-6-6=20 位为标记,采用 8 路组相联映射,故每行中 LRU 位占 3 位(log2路数),采用直写方式,故没有修改位。
(2)因为数组 s 的起始地址最后 6 位全为 0,故 s 位于一个主存块开始处(小细节,万一老头就使坏呢),占 1024×4B/64B=64 个主存块; 执行程序段过程中,每个主存块中的 64B/4B=16 个数组元素依次读、写 1 次,因而对于每个主存块,总是第一次访问缺失,以后每次命中。
综上,数组 s 的数据 Cache 访问缺失次数为 64 次。(可以考虑一下这里算命中率是多少呢?)
(3) 0001 0003H = 0000 0000 0000 0001 0000 000000 000011B,根据主存地址划分可知,组索引为 0,故 该地址所在主存块被映射到指令 Cache 第 0 组;因为 Cache 初始为空(刚刚开始一定不命中),所有Cache 行的有效位均为 0,所以 Cache 访问缺失。此时,将该主存块取出后存入指令 Cache 第 0 组的任意一行,并将主存地址高 20 位 (00010H)填入该行标记字段,设置有效位,修改 LRU 位,最后根据块内地址 000011B 从该行中取出相应内容。
注:Cache缺失处理过程
2021
指令


1)
- ALU的宽度为16位,ALU的宽度即ALU运算对象的宽度,通常与字长相同。
- 地址线为20位,按字节编址,可寻址主存空间大小为2^20字节(或1MB)。
- 指令寄存器有16位,和单条指令长度相同。
- MAR有20位,和地址线位数相同。
- MDR有8位,和数据线宽度相同。
2)tips:不能忽略掉R型用掉的000000
- R型格式的操作码有4位,最多有2^4(16)种操作。
- I型和J型格式的操作码有6位,因为它们的操作码部分重叠,所以共享这6位的操作码空间,且前6位全0的编码已被R型格式占用,因此I和J型格式最多有2-1=63种操作。
- 从R型和I型格式的寄存器编号部分可知,只用2位对寄存器编码,因此通用寄存器最多有4个。
3)
- 指令01B2H=0000000110110010B为一条R型指令,操作码0010表示带符号整数减法指令,其功能为R3←R1-R2。
- 执行指令01B2H后,R3=B052H-0008H=B04AH, 结果未溢出。
- 指令01B3H=0000000110110011B,操作码0011表示带符号整数乘法指令,执行指令01B3H后,R3=R1×R2=B052H×0008H=8290H,结果溢出。
4)在进行指令的跳转时,可能向前跳转,也可能向后跳转,偏移量是一个带符号整数,因此在地址计算时,应对imm进行符号扩展。
5)无条件转移指令可以采用J型格式,将target部分写入PC的低10位,完成跳转。
TLB(映射方式、替换算法)

注:对于本题的TLB,需要采用处理Cache的方式求解。

1)按字节编址,页面大小为4KB=2^12B,页内地址为12位。虚拟地址中高30-12=18位表示虚页号,虚拟地址中低12位表示页内地址。
2)TLB采用2路组相联方式,共8=2^3组,用3位来标记组号。虚拟地址(或虚页号)中高18-3=15位为TLB标记,虚拟地址中随后3位(或虚页号中低3位)为TLB组号。
3)虚页号4对应的TLB表项被替换。因为虚页号与TLB组号的映射关系为TLB组号=虚页号modTLB组数=虚页号mod8,因此,虚页号10,12,16,7,26,4,12,20映射到的TLB组号依次为2,4,0,7,2,4,4,4。TLB采用2路组相联方式,从上述映射到的TLB组号序列可以看出,只有映射到4号组的虚页号数量大于2,相应虚页号依次是12,4,12和20。根据LRU替换策略,当访问第20页时,虚页号4对应的TLB表项被替换出来。
4)虚拟地址位数增加到32位时,虚页号增加了32---30=2位,使得每个TLB表项中的标记字段增加2位,因此,每个TLB表项的位数增加2位。
2022
数据通路
43.(15 分)某 CPU 中部分数据通路如题图所示,其中,GPRs 为通用寄存器组;FR 为标志寄存器,用于存放 ALU 产生的标志信息;带箭头虚线表示控制信号,如控制信号 Read、Write 分别表示主存读、主存写,MDRin 表示内部总线上数据写入 MDR,MDRout 表示 MDR 的内容送内部总线。
请回答下列问题。
1)设 ALU 的输入端 A、B 及输出端 F 的最高位分别为 A15、B15,及 F15,FR 中的符号标志和溢出标志分别为 SF 和 OF,则 SF 的逻辑表达式是什么? A 加 B、A 减 B 时 OF 的逻辑表达式分别是什么?要求逻辑表达式的输入变量为 A15、B15 及 F15
2)为什么要设置暂存器 Y 和 Z?
3)若 GPRs 的输入端 rs、rd 分别为所读、写的通用寄存器的编号,则 GPRs 中最多有多少个通用寄存器?rs 和 rd 来自图中的哪个寄存器?已知 GPRs 内部有一个地址译码器和一个多路选择器, rd 应连接地址译码器还是多路选择器?
4)取指令阶段(不考虑 PC 增量操作) 的控制信号序列是什么? 若从发出主存读命令到主存读出数据并传送到 MDR 共需 5 个时钟周期,则取指令阶段至少需要几个时钟周期?
5)图中控制信号由什么部件产生?图中哪些寄存器的输出信号会连到该部件的输入端?


磁盘
DMA
- 假设某磁盘驱动器中有 4 个双面盘片,每个盘面有 20000 个磁道,每个磁道有 500 个 扇区,每个扇区可记录 512 字节的数据,盘片转速为 7200r/m(转/分)。平均寻道时间为 5ms。请回答下列问题。
1)每个扇区包含数据及其地址信息,地址信息分为 3 个字段。这 3 个子段的名称各是什么?对于该磁盘,各字段至少占多少位?
2)一个扇区的平均访问时间约为多少?
3)若采用周期挪用 DMA 方式进行磁盘与主机之间的数据传送,磁盘控制器中的数据缓冲区大小 为 64 位,则在一个扇区读写过程中,DMA 控制器向 CPU 发送了多少次总线请求?若 CPU 检测到 DMA 控制器的总线请求信号时也需要访问主存,则 DMA 控制器是否可以获得总线使用权?为什么?

2023
Cache


汇编
- 某C语言程序段在计算机M上的部分机器级代码如下,数组a的定义为"int a2464",每个机器级代码行中依次包含指今序号、虚拟地址、机器指令和汇编指令。
1) 第20条指令的虚拟地址是什么?
2)第2条指令jmp的操作码是EBH,它的转移目标地址是00401084h。第7条指令jge的操作码是7DH,它的转移目标地址是004010bch。这两条指令分别采用什么寻址方式?请给出ip指令的转移目标地址计算过程
3)第19条指令,实现了aij<-10。该指令的源操作数采用什么寻址方式?已知edx存放j的值,ecx存放的是什么?该系统采用大端还是小端存储?
4)第一次取第19条指令时, 是否发生缺页?为什么?

2024
指令1

请回答下列问题
1)计算机M最多有多少个通用寄存器?为什么shamt字段占5位?
2)执行add指令时,控制信号ALUBsrc的取值应该是什么?若rs1和rs2寄存器内容分别8765 4321H和9876 5432H,则add指令执行后,ALU输出端F、OF和CF的结果分别是什么?若设add指令处理的是无符号整数,则应根据哪个标志判断是否溢出
3)执行slli指令时,控制信号Ext的取值可以是0也可以是1,为什么?
4)执行lw指令时,控制信号Ext、ALUctr的取值分别是什么?
5)若一条指令的机器码是A040 A103H,则该指令一定是lw指令,为什么?若执行该指令时,R01H=FFFF A2D0H,则读取数据的存储地址是多少?


指令2
44.对于题43中的计算机M,C语言程序P包含的语句"sum+=ai;",在M中对应的指令序列S如下:
已知变量i,sum和数组都为int型,通用寄存器r1-r5的编号为01H-05H。请回答下列问题。
1)根据指令序列s中每条指令的功能,写出存放数组的首地址、变参i和sum的通用寄存器编号
2)已知M为小端方式,计算机采用页式存储管理方式。页大小为4KB。若执行到指令序列s中第1条指令时,i=5且r1和r3的内容分别为0000 1332H和0013 DFF0H。从地址0013 DFF0H开始存储单元,内容如题44图所示。则执行"sum+=ai;"语句后。ai的地址、ai和sum的机器数分别是什么(用十六进制表示)?ai所在页的页号是多少?在此次执行中,数据组至少存放在几页中?
3)指令"slli4 r4,r2,2"的机器码是什么(用十六进制表示)?若数组a改为short类型,则指令序列存到S中slli指令的汇编形式应是什么?


