通过Java API演示如何操作HDFS分布式文件系统的文件和目录。
目录
- 1.配置案例环境
-
- [1)打开IntelliJ IDEA](#1)打开IntelliJ IDEA)
- 2)新建Maven项目
- 3)配置Maven项目
- 4)配置项目名称和存储目录
- 2.添加Maven库依赖
- 3.获取客户端对象
- 4.上传文件到HDFS
- 5.从HDFS下载文件
- 6.目录操作
- 7.查看文件中的目录信息
- 8.运行HDFS_CURD类
- 9.查看HDFS下载到本地文件系统的文件
- 10.查看HDFS的目录
1.配置案例环境
1)打开IntelliJ IDEA
打开IntelliJ IDEA开发工具,进入到Welcome to IntelliJ IDEA窗口。

2)新建Maven项目
在New Project对话框,选择创建项目的类型为Maven项目。
3)配置Maven项目
在New Project对话框,对创建的Maven项目进行配置。

4)配置项目名称和存储目录
在New Project对话框,分别指定项目名称和项目存储目录。

2.添加Maven库依赖
在pom.xml文件中,添加Maven库依赖。
bash
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.0</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>

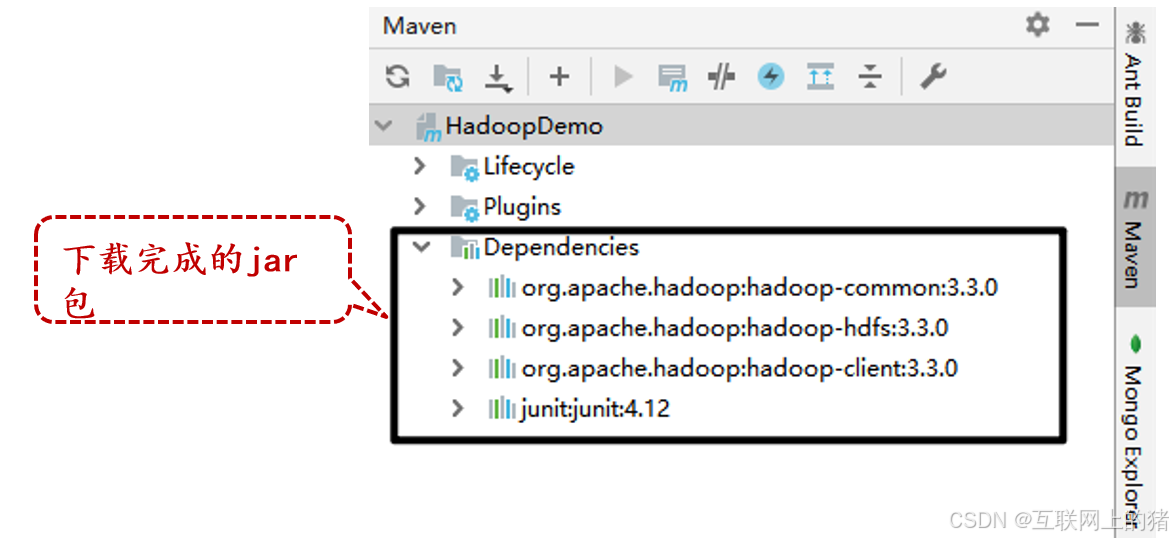
单击IntelliJ IDEA开发工具右侧的"Maven"→"Dependencies"按钮,即可查看到相关的jar包。
3.获取客户端对象
在HadoopDemo项目中创建cn.itcast.hdfsdemo包,在该包下创建HDFS_CURD类,构建HDFS的客户端实例。
第一步:创建init()方法
java
public void init() { } 第二步:指定HDFS配置信息
java
Configuration conf = new Configuration(); 第三步:指定HDFS中NameNode节点的通信地址,连接HDFS
java
conf.set("fs.defaultFS", "hdfs://hadoop1:9000");第四步:指定具有操作HDFS权限的用户root。
java
System.setProperty("HADOOP_USER_NAME", "root");第五步:调用FileSystem类的get()方法获取conf对象指定的配置信息,并创建操作HDFS的对象fs。
java
fs = FileSystem.get(conf); 4.上传文件到HDFS
在HDFS_CURD类中添加方法testAddFileToHdfs(),用于将本地文件系统中,D:\upload\路径下的文件test.txt上传到HDFS的/testFile目录,且该目录必须存在。
java
@Test
public void testAddFileToHdfs() throws IOException {
Path src = new Path("D:\\upload\\test.txt");
Path dst = new Path("/testFile");
fs.copyFromLocalFile(src, dst);
fs.close();
}
在HDFS_CURD类中添加方法testDownloadFileToLocal(),用于将HDFS中/testFile目录下的文件test.txt下载到本地文件系统的D:\downloadFile路径。
5.从HDFS下载文件
在HDFS_CURD类中添加方法testDownloadFileToLocal(),用于将HDFS中/testFile目录下的文件test.txt下载到本地文件系统的D:\downloadFile路径。
java
@Test
public void testDownloadFileToLocal() throws IllegalArgumentException,IOException {
fs.copyToLocalFile(
new Path("/testFile/test.txt"),
new Path("D:\\downloadFile"));
}
6.目录操作
在HDFS_CURD类中添加方法testMkdirAndDeleteAndRename(),用于对HDFS的目录进行操作,包括创建目录、重命名目录和删除目录。
java
@Test
public void testMkdirAndDeleteAndRename() throws Exception {
fs.mkdirs(new Path("/a/b/c"));
fs.mkdirs(new Path("/a2/b2/c2"));
fs.rename(new Path("/a"), new Path("/a3"));
fs.delete(new Path("/a2"), true);
}
7.查看文件中的目录信息
在HDFS_CURD类中添加方法testListFiles(),用户获取/car目录中所有文件的信息包括文件名、文件大小、文件权限等。在/car目录中包含文件car_prices.csv和子目录/other,并且在子目录中包含文件car_prices1.csv和car_prices2.csv。
第一步: 创建testListFiles() 方法。
java
public void testListFiles() {}第二步:递归获取/car目录下文件的信息。
java
RemoteIterator<LocatedFileStatus> listFiles =fs.listFiles(new Path("/car"), true);第三步:获取每个文件的名称、副本数、权限、大小和Block所在服务器的主机名。
java
while (listFiles.hasNext()) {
LocatedFileStatus fileStatus = listFiles.next();
System.out.println("文件名:" + fileStatus.getPath().getName());
System.out.println("文件的副本数:" + fileStatus.getReplication());
System.out.println("文件的权限:" + fileStatus.getPermission());
System.out.println("文件大小:" + fileStatus.getLen() + "字节");
BlockLocation[] blockLocations =fileStatus.getBlockLocations();
for (BlockLocation bl : blockLocations) {
String[] hosts = bl.getHosts();
System.out.println("文件的Block所在虚拟机的主机名:");
for (String host : hosts) {
System.out.println(host);
}
System.out.println("----------------------------");
}如果此时你报了: java.io.FileNotFoundException: java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset. -see https://wiki.apache.org/hadoop/WindowsProblems的错误,说明,你没有在Windows中配置Hadoop的运行环境,详细解决方案请看https://blog.csdn.net/2301_76901778/article/details/144332904?spm=1001.2014.3001.5501
8.运行HDFS_CURD类
选中HDFS_CURD类,右键选择"Run HDFS_CURD"选项运行。

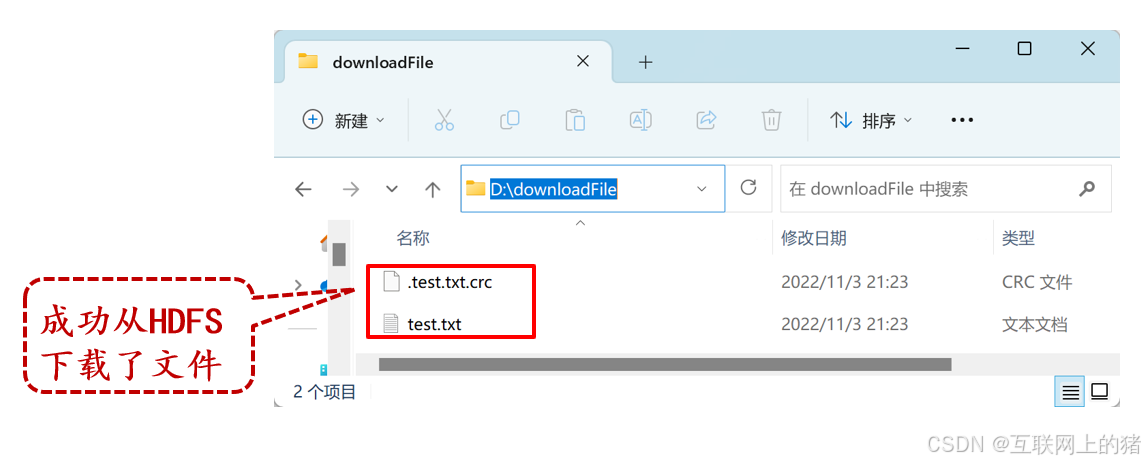
9.查看HDFS下载到本地文件系统的文件
在本地文件系统的D:\downloadFile路径查看从HDFS的/testFile目录下载的文件。
10.查看HDFS的目录
在虚拟机Hadoop1执行命令查看HDFS根目录的内容,以及查看/testFile目录的内容。
