案例---通过Shell脚本定时采集数据到HDFS
掌握HDFS的Shell操作,能够完成案例-通过Shell脚本定时采集数据到HDFS
在实际的开发环境中,服务器每天都会产生大量的日志文件,这些日志文件会记录服务器的运行状态。当服务器宕机时,可以从日志文件中查找服务器宕机原因,从而尽快让服务器恢复正常运行。通过一个案例演示如何通过Shell脚本周期性的将Hadoop的日志文件上传到HDFS。
目录
1.创建Shell脚本
在虚拟机Hadoop1的/export/data目录下执行vi uploadHDFS.sh命令,在该文件中实现上传Hadoop日志文件到HDFS的代码。
#!/bin/bash
export HADOOP_HOME=/export/servers/hadoop-3.3.0 #
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
hadoop_log_dir=/export/servers/hadoop-3.3.0/logs/
log_toupload_dir=/export/data/logs/toupload/
date=`date +%Y_%m_%d_%H_%M` ' ' " "
hdfs_dir=/hadoop_log/$date/
if [ -d $log_toupload_dir ];
then
echo "$log_toupload_dir exits"
else
mkdir -p $log_toupload_dir
fi
ls $hadoop_log_dir | while read fileName
do
if [[ $fileName == *.log ]];
then
echo "moving hadoop log to $log_toupload_dir"
cp $hadoop_log_dir/*.log $log_toupload_dir
scp root@hadoop2:$hadoop_log_dir/*.log $log_toupload_dir
scp root@hadoop3:$hadoop_log_dir/*.log $log_toupload_dir
echo "moving hadoop log willDoing"
break
fi
done
echo "create $hdfs_dir"
hdfs dfs -mkdir -p $hdfs_dir
ls $log_toupload_dir | while read fileName
do
echo "upload hadoop log $fileName to $hdfs_dir"
hdfs dfs -put $log_toupload_dir$fileName $hdfs_dir
echo "upload hadoop log $fileName willDoing"
done
echo "delete $log_toupload_dir log"
rm -fr $log_toupload_dir


2.执行Shell脚本
进入到虚拟机Hadoop1的/export/data/目录下,确保Hadoop集群处于启动状态下,执行sh uploadHDFS.sh命令运行Shell脚本文件uploadHDFS.sh。
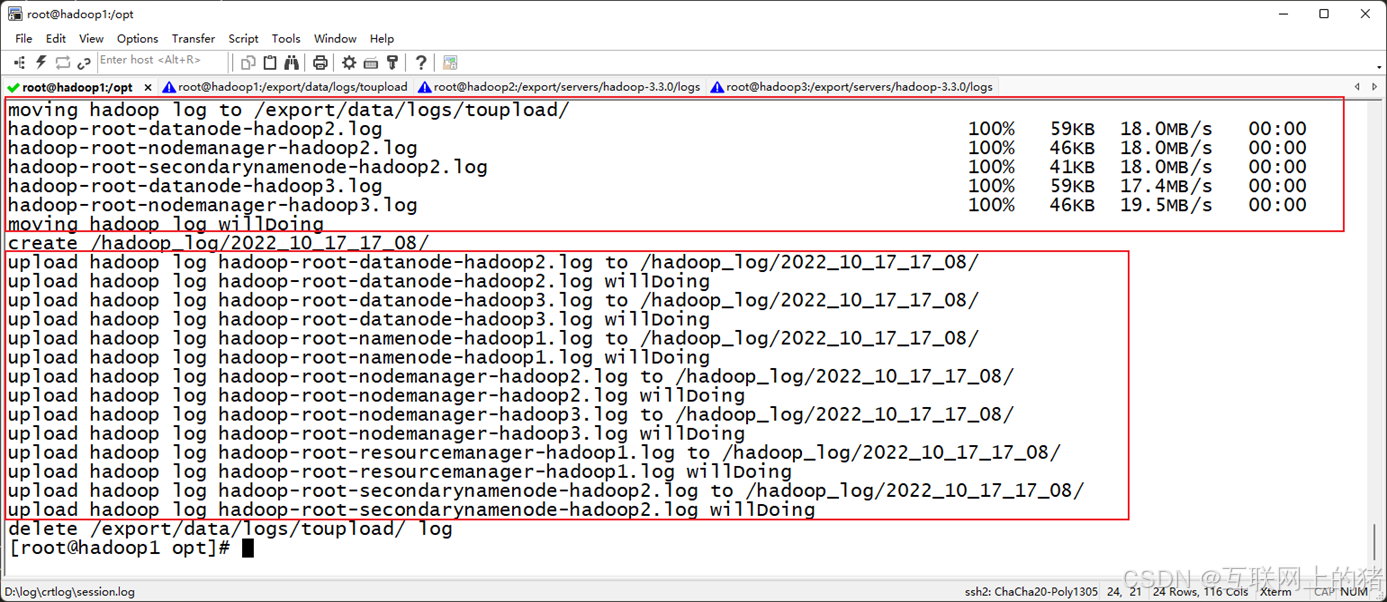
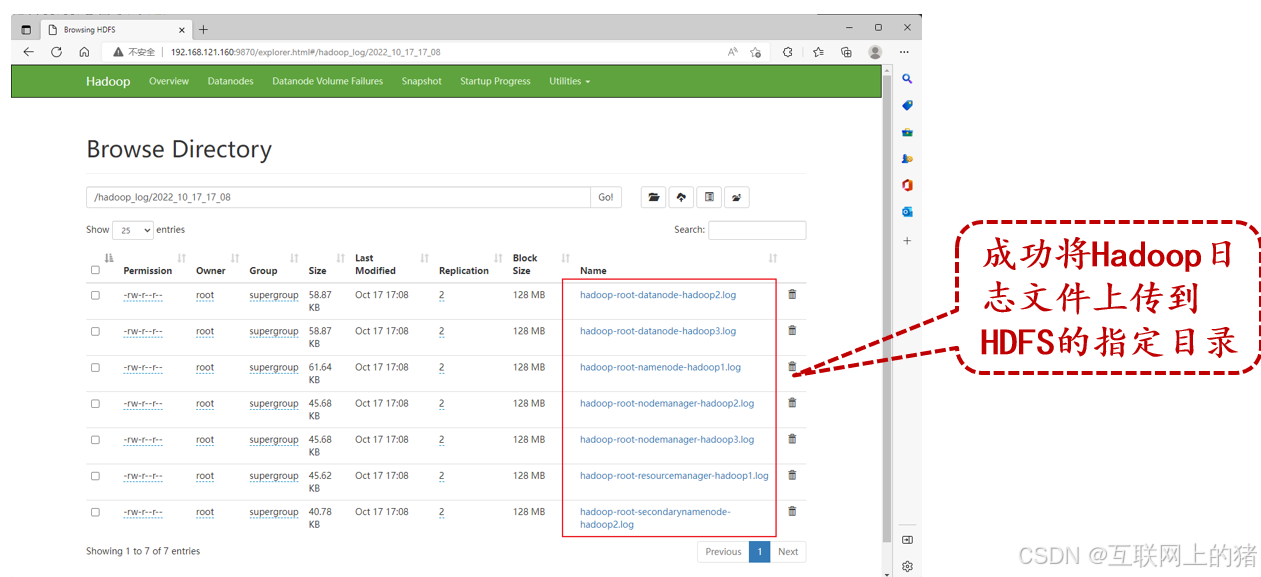
3.验证Hadoop日志文件是否上传成功
在本地计算机的浏览器中打开HDFS的Web UI,查看HDFS的/hadoop_log/2022_10_17_17_08/目录中是否存在Hadoop日志文件。
4.定时执行Shell脚本
1)检查是否安装Crontab
在虚拟机Hadoop1执行rpm -qa | grep crontab命令检查是否安装Crontab。
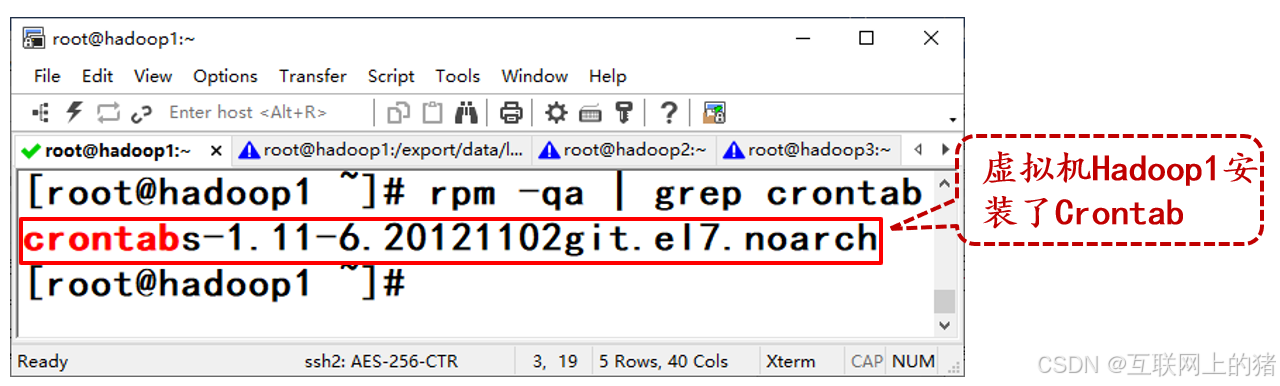
若没有显示Crontab的版本信息,可以先安装Crontab。
yum -y install vixie-cron
yum -y install crontabs
2)启动Crontab服务
使用Crontab时,必须保证Crontab服务处于运行状态。启动Crontab服务的命令如下。
service crond start

3)添加可执行权限
进入虚拟机Hadoop1的/export/data/目录,为Shell脚本文件uploadHDFS.sh添加可执行权限。
chmod 777 uploadHDFS.sh
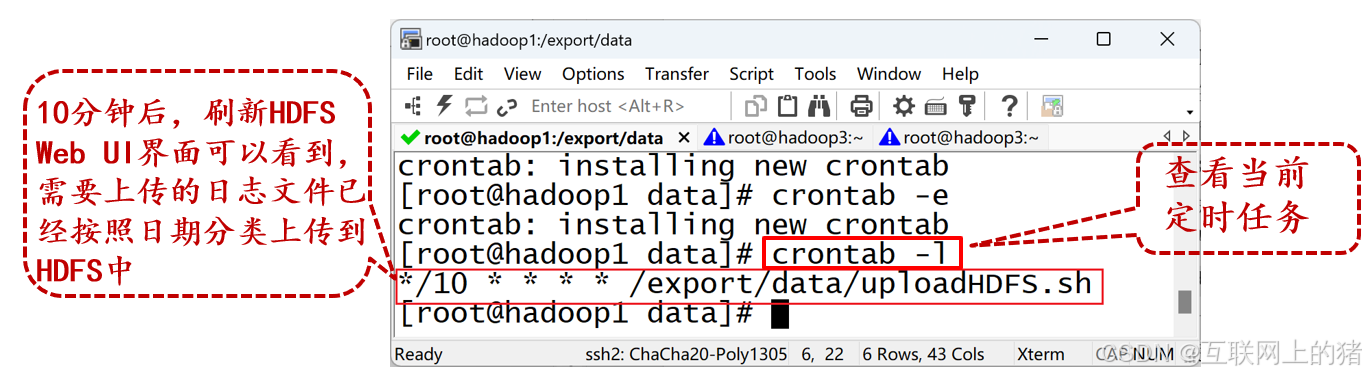
4)配置定时任务
在虚拟机Hadoop1执行crontab -e命令编辑Crontab文件,配置定时任务,在Crontab文件添加如下内容。
*/10 * * * * /export/data/uploadHDFS.sh
5.Crontab表达式
*/10 * * * * /export/data/uploadHDFS.sh
| 字符 | 含义 | 示例 |
|---|---|---|
| * | 表示匹配域的任意值 | 在分这个域使用 *,即表示每分钟都会触发事件。 |
| ? | 表示匹配域的任意值,但只能用在日期和星期两个域,因为这两个域会相互影响。 | 要在每月的 20 号触发调度,不管每个月的 20 号是星期几,则只能使用如下写法:13 13 15 20 * ?。其中,因为日期域已经指定了 20 号,最后一位星期域只能用 ?,不能使用 *。如果最后一位使用 *,则表示不管星期几都会触发,与日期域的 20 号相斥,此时表达式不正确。 |
| - | 表示起止范围 | 在分这个域使用 5-20,表示从 5 分到 20 分钟每分钟触发一次。 |
| / | 表示起始时间开始触发,然后每隔固定时间触发一次 | 在分这个域使用 5/20,表示在第 5 分钟触发一次,之后每 20 分钟触发一次,即 5、 25、45 等分别触发一次。 |
| , | 表示列出枚举值 | 在分这个域使用 5,20,则意味着在 5 和 20 分每分钟触发一次。 |
| L | 表示最后,只能出现在日和星期两个域 | 在星期这个域使用 5L,意味着在最后的一个星期四触发。 |
| W | 表示有效工作日(周一到周五),只能出现在日这个域,系统将在离指定日期最近的有效工作日触发事件。 | 在日这个域使用 5W,如果 5 号是星期六,则将在最近的工作日星期五,即 4 号触发。如果 5 号是星期天,则在 6 号(周一)触发;如果 5 号为工作日,则就在 5 号触发。另外,W 的最近寻找不会跨过月份。 |
| LW | 这两个字符可以连用,表示在某个月最后一个工作日,即最后一个星期五。 | |
| # | 表示每个月第几个星期几,只能出现在星期这个域 | 在星期这个域使用 4#2,表示某月的第二个星期三,4 表示星期三,2 表示第二个。 |