文章目录
- 一、物理分区
- 二、Sink
-
- [1、JDBC Connector(JDBC连接器)](#1、JDBC Connector(JDBC连接器))
- [2、Kafka Connector(Kafka连接器)](#2、Kafka Connector(Kafka连接器))
- 3、自定义Sink
一、物理分区
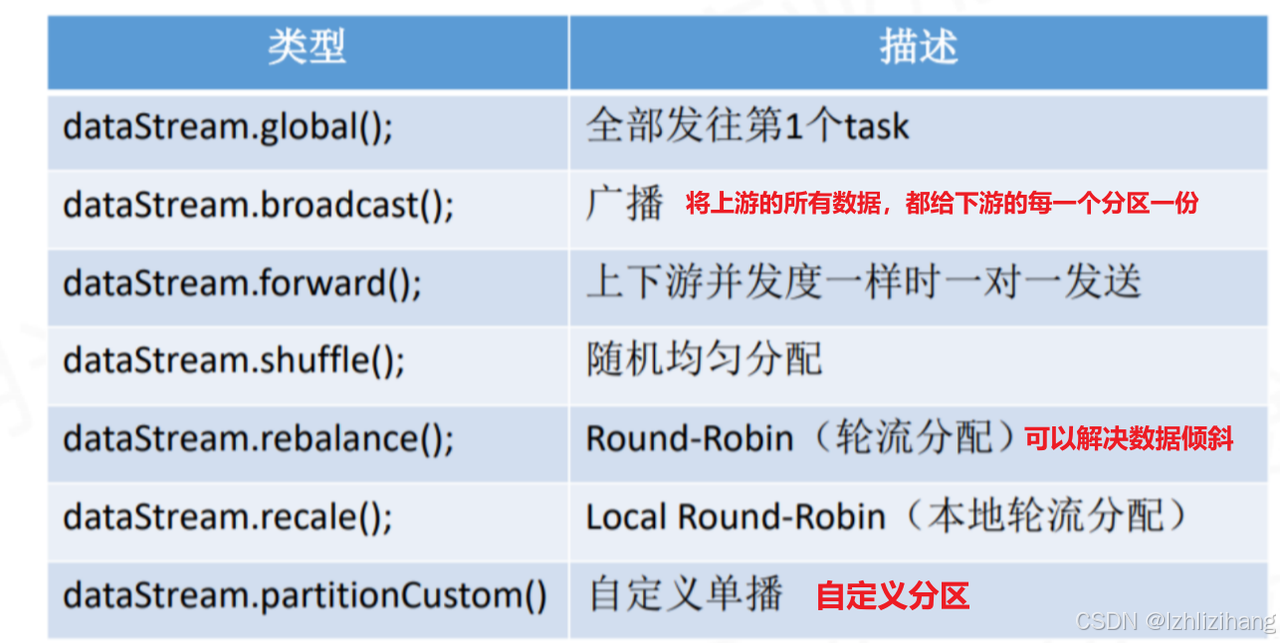
1、自定义分区+重分区(解决数据倾斜)
重分区能够解决数据倾斜
java
package com.bigdata.transformation;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.Partitioner;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
// 自定义分区
class MyPartitioner implements Partitioner<Long>{
@Override
public int partition(Long key, int numPartitions) {
// 小于等于10000的放到1分区,否则放到2分区
if (key <= 10000){
return 0;
}
return 1;
}
}
public class CustomPartition {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
env.setParallelism(2);
DataStreamSource<Long> dataStreamSource = env.fromSequence(1, 15000);
// 自定义分区API
DataStream<Long> dataStream = dataStreamSource.partitionCustom(new MyPartitioner(), new KeySelector<Long, Long>() {
@Override
public Long getKey(Long value) throws Exception {
return value;
}
});
// 查看每个分区的数据量
dataStream.map(new RichMapFunction<Long, Tuple2<Integer,Integer>>() {
@Override
public Tuple2<Integer, Integer> map(Long aLong) throws Exception {
int partitions = getRuntimeContext().getIndexOfThisSubtask();
return Tuple2.of(partitions,1);
}
}).keyBy(new KeySelector<Tuple2<Integer, Integer>, Integer>() {
@Override
public Integer getKey(Tuple2<Integer, Integer> integerIntegerTuple2) throws Exception {
return integerIntegerTuple2.f0;
}
}).sum(1).print("前:");
// 打印自定义分区结果
// dataStream.print();
// 进行重分区
DataStream<Long> rebalance = dataStream.rebalance();
//查看重分区每个分区的数据量
rebalance.map(new RichMapFunction<Long, Tuple2<Integer,Integer>>() {
@Override
public Tuple2<Integer, Integer> map(Long aLong) throws Exception {
int partitions = getRuntimeContext().getIndexOfThisSubtask();
return Tuple2.of(partitions,1);
}
}).keyBy(new KeySelector<Tuple2<Integer, Integer>, Integer>() {
@Override
public Integer getKey(Tuple2<Integer, Integer> integerIntegerTuple2) throws Exception {
return integerIntegerTuple2.f0;
}
}).sum(1).print("后:");
env.execute("自定义分区+重分区(解决数据倾斜)");
}
}二、Sink
有print、writerAsText(以文本格式输出)、Connectors(连接器)
1、JDBC Connector(JDBC连接器)
导包:
java
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.25</version>
</dependency>代码演示:
java
package com.bigdata.sink;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.connector.jdbc.JdbcConnectionOptions;
import org.apache.flink.connector.jdbc.JdbcSink;
import org.apache.flink.connector.jdbc.JdbcStatementBuilder;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.api.common.RuntimeExecutionMode;
import java.sql.PreparedStatement;
import java.sql.SQLException;
/**
@基本功能:
@program:FlinkDemo
@author: hang
@create:2024-11-22 15:55:54
**/
@Data
@NoArgsConstructor
@AllArgsConstructor
class Student {
private int id;
private String name;
private int age;
}
public class JdbcConnector {
public static void main(String[] args) throws Exception {
//1. env-准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//2. source-加载数据
DataStreamSource<Student> studentDataStreamSource = env.fromElements(
new Student(1, "zhanngsan", 18),
new Student(2, "lisi", 19),
new Student(3, "wangwu", 20)
);
//3. transformation-数据处理转换
//4. sink-数据输出
JdbcConnectionOptions jdbcConnectionOptions = new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withDriverName("com.mysql.cj.jdbc.Driver")
.withUrl("jdbc:mysql://localhost:3306/mydb01")
.withUsername("root")
.withPassword("123456").build();
studentDataStreamSource.addSink(JdbcSink.sink(
"insert into student values (?,?,?)",
new JdbcStatementBuilder<Student>() {
@Override
public void accept(PreparedStatement preparedStatement, Student student) throws SQLException {
preparedStatement.setInt(1,student.getId());
preparedStatement.setString(2,student.getName());
preparedStatement.setInt(3,student.getAge());
}
},
jdbcConnectionOptions
// 假如是流的方式可以设置两条插入一次
//JdbcExecutionOptions.builder().withBatchSize(2).build(),jdbcConnectionOptions
));
//5. execute-执行
env.execute();
}
}2、Kafka Connector(Kafka连接器)
需求:从Kafka的topic1中消费日志数据,并做实时ETL,将状态为success的数据写入到Kafka的topic2中
java
package com.bigdata.sink;
import org.apache.flink.api.common.functions.FilterFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
import java.util.Properties;
/**
@基本功能:
@program:FlinkDemo
@author: hang
@create:2024-11-22 16:38:58
**/
public class KafkaConnector {
public static void main(String[] args) throws Exception {
//1. env-准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//2. source-加载数据
Properties properties = new Properties();
properties.setProperty("bootstrap.servers","node01:9092");
properties.setProperty("group.id", "g1");
FlinkKafkaConsumer<String> kafkaConsumer = new FlinkKafkaConsumer<>("topic1", new SimpleStringSchema(), properties);
DataStreamSource<String> dataStreamSource = env.addSource(kafkaConsumer);
//3. transformation-数据处理转换
SingleOutputStreamOperator<String> success = dataStreamSource.filter(new FilterFunction<String>() {
@Override
public boolean filter(String s) throws Exception {
return s.contains("success");
}
});
//4. sink-数据输出
FlinkKafkaProducer<String> kafkaProducer = new FlinkKafkaProducer<>("topic2", new SimpleStringSchema(), properties);
success.addSink(kafkaProducer);
//5. execute-执行
env.execute();
}}
3、自定义Sink
模拟jdbcSink的实现
jdbcSink官方已经提供过了,此处仅仅是模拟它的实现,从而学习如何自定义sink
java
package com.bigdata.sink;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSink;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
class MyJdbcSink extends RichSinkFunction<Student>{
Connection conn = null;
PreparedStatement statement = null;
@Override
public void open(Configuration parameters) throws Exception {
// 注册驱动(安转驱动) 此时这句话可以省略 如果书写的话,mysql8.0 带 cj
Class.forName("com.mysql.cj.jdbc.Driver");
// 获取数据库连接对象 Connection
conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/mydb01","root","123456");
// 执行sql语句
statement = conn.prepareStatement("insert into student values (?,?,?)");
}
@Override
public void close() throws Exception {
// 释放资源
statement.close();
conn.close();
}
@Override
public void invoke(Student student, Context context) throws Exception {
statement.setInt(1,student.getId());
statement.setString(2,student.getName());
statement.setInt(3,student.getAge());
statement.execute();
}
}
public class jdbcCustomSink {
public static void main(String[] args) throws Exception {
//1. env-准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
//2. source-加载数据
DataStreamSource<Student> studentDataStreamSource = env.fromElements(
new Student(4, "zhaoliu", 18),
new Student(5, "qianqi", 19),
new Student(6, "wuba", 20)
);
//3. transformation-数据处理转换
//4. sink-数据输出
DataStreamSink<Student> studentDataStreamSink = studentDataStreamSource.addSink(new MyJdbcSink());
//5. execute-执行
env.execute();
}
}