Dubbo的负载均衡及高性能RPC调用
Dubbo 的负载均衡策略
负载均衡策略就是当某个服务压力比较大的时候,这时候部署多个节点同时提供相同的服务
当服务消费者来消费的时候,可以从这多个节点中选择一个节点进行消费,这个选择的过程,就是 负载均衡
Dubbo 提供了多种负载均衡策略:
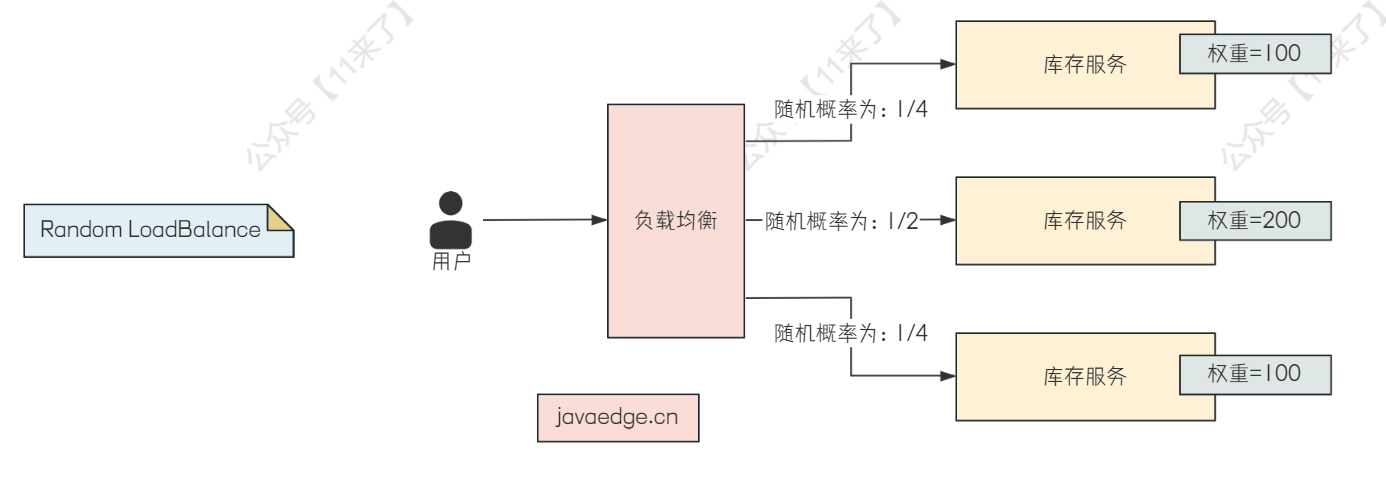
Random LoadBalance
基于权重的随机负载均衡策略,为 Dubbo 的 默认策略
特点就是:根据每个服务的权重来设置它的随机概率,如下图
RoundRobin LoadBalance
基于权重的轮询负载均衡策略,一般不使用该策略
因为轮询的话有一个比较致命的问题,如果其中有一台机器处理请求的速度比较慢,那么当一个请求被转发到很慢的机器上之后,很久都没有处理完,会导致其他请求也会被转发到这个机器上,导致该机器上堆积很多请求,更加处理不过来了
LeastActive LoadBalance
最少活跃负载均衡策略,也就是看哪台机器上活跃的请求比较少
Dubbo 对活跃数的定义:当服务收到一个请求,活跃数 +1,当 Dubbo 处理完一个请求,活跃数 -1
Dubbo 就认为谁的活跃数越少,谁的处理速度就越快,性能也越好,这样的话,我就优先把请求给活跃数少的服务提供者处理
- 如果活跃的请求数量较少,说明该机器的性能是比较高的,有请求的话优先给该机器处理
- 如果活跃的请求数量较多,说明该机器的处理速度较慢,请求分给该机器的话可能会造成请求堆积
ConsistentHash LoadBalance
一致性 Hash 负载均衡策略
可以保证相同参数的请求总是发到同一提供者,当某一台提供者机器宕机时,原本发往该提供者的请求,将基于虚拟节点平摊给其他提供者,这样就不会引起剧烈变动。
基于注解配置负载均衡策略
java
@Reference(loadbalance = "roundrobin")
HelloService helloService;Dubbo 的高性能 RPC 调用
Dubbo 的高性能 RPC 调用离不开它的序列化协议、通信协议,那么接下来就从这两方面来介绍
Dubbo 的序列化协议
Dubbo 中支持多种序列化协议,在 Dubbo3.2 版本之前使用 Hessian2 作为默认的序列化方式,在 Dubbo3.2 版本之后使用 FastJSON2 作为默认的序列化方式
Hessian、Hessian2
在 Dubbo3.2 版本之前使用
Hessian2作为默认的序列化方式
Hessian 序列化是一种支持动态类型、跨语言、基于对象传输的网络协议
Dubbo 中使用的 Hessian2 是阿里基于 Hessian 所做的升级版本
相比 Hessian1,Hessian2中增加了压缩编码,其序列化二进制流大小是 Java 序列化的50%,序列化耗时是 Java 序列化的30%,反序列化耗时是 Java 序列化的20%
相比于 Java 序列化,Hessian2 无论是从 序列化速度 还是 序列化后的体积 上都存在非常大的优势!
配置启用:
yml
# application.yml (Spring Boot)
dubbo:
protocol:
serialization: hessian2FastJSON、FastJSON2
在 Dubbo3.2 版本之后使用
FastJSON2作为默认的序列化方式(FastJSON2 仅在 Dubbo > 3.1.0 版本支持)
FastJSON 是阿里开源的高性能 JSON 解析库
FastJSON 的特点就是 快 !
但是 FastJSON 中存在一些安全漏洞,因此 FastJSON2 对其进行升级,在 性能 和 安全性 上都有所提升!
FastJSON2 使用方式:
引入依赖:
引入依赖:
xml
<dependencies>
<dependency>
<groupId>com.alibaba.fastjson2</groupId>
<artifactId>fastjson2</artifactId>
<version>2.0.23</version>
</dependency>
</dependencies>配置启用:
yaml
# application.yml (Spring Boot)
dubbo:
protocol:
serialization: fastjson2Protobuf
全称 Google Protocol Buffer,简称 Protobuf,由 Google 公司开发
Protocol Buffers 是一种轻便高效的 结构化 数据存储格式 (和 json、xml 文件类似),可以用于结构化数据串行化、或者说序列化,非常适合用于做 数据存储 或者 RPC 数据交换
Protocol 相比于 xml、json 来说,体积更小,解析更快
- 应用场景:
就比如现在有一个 Java 项目和 Go 项目之间要相互通信,两个模块之间对于数据的定义可能是不同的,并且 Java 语言和 Go 也是不兼容的,比如你要传输一个 User 类,在 Java 和 Go 中的定义肯定是不一样的
那么怎么来传输呢?
通过 Protobuf 来定义一个 User 数据对象(假设定义在 user.proto 文件),这个数据对象在 Java 和 Go 中都需要使用, 那么在 Java 中根据 user.proto 文件生成 Java 中的类对象,在 Go 中根据 user.proto 文件生成 Go 中的类对象 ,即可完成不同语言项目之间的通信
并且 Protobuf 在 序列化方面 也有很大的优势,可以很大程度上减小序列化后的体积,比如 proto 文件定义 User 类如下:
protobuf
message User {
string uid = 1;
string username = 2;
}那么一般在序列化传输数据的时候,需要传输数据的 key 和 value
而使用了 Protobuf 之后,在序列化的时候,不需要传输数据的 key 了,因为 key 已经在 proto 文件中定义了,只需要传输 value,因此 序列化后的数据体积减小很多!
- 配置启用:
yaml
# application.yml (Spring Boot)
dubbo:
protocol:
serialization: protobufAvro
Avro 是一种远程过程调用和数据序列化框架,使用 JSON 来定义数据类型和通讯协议,使用压缩二进制格式来序列化数据,它主要用于Hadoop,是 Hadoop 持久化数据的一种序列化格式
其他序列化协议
还有其他很多序列化协议,如 FST、Gson、Kryo、MessagePack,这里就不一一介绍了
获取更多干货内容,记得关注我哦。
本文由博客一文多发平台 OpenWrite 发布!