在人工智能(AI)领域,长上下文生成与检索(RAG) 已成为提升自然语言处理(NLP)模型性能的关键技术之一。随着数据规模与应用场景的不断扩展,如何高效地处理海量上下文信息,成为研究与应用的热点话题。本文将深入探讨OpenAI最新发布的O1-preview 和O1-mini 模型在长上下文RAG任务中的表现,比较其与行业内其他SOTA(State-of-the-Art)模型如GPT-4o 和Google Gemini 1.5的性能差异,并提供实用的优化建议,助力开发者在构建LLM(大型语言模型)应用时实现更高效、更精准的性能表现。

引言:长上下文RAG的重要性
在现代AI应用中,大型语言模型(LLM) 已广泛应用于文本生成、问答系统、内容总结等多个领域。然而,随着应用场景的复杂性和数据量的急剧增加,传统的短上下文处理能力已难以满足需求。长上下文RAG(Retrieve and Generate) 技术通过在生成过程中引入检索机制,使模型能够处理更大规模的上下文信息,从而显著提升了回答的准确性与相关性。
【CodeMoss】集成13个种AI模型(GPT4、o1等)、支持Open API调用、自定义助手、文件上传等强大功能,助您提升工作效率! >>> - CodeMoss & ChatGPT-AI中文版
>>> https://pc.aihao123.cn/index.html#/page/login?invite=1141439&fromChannel=CodeMoss_1212RAG
OpenAI O1模型概述
OpenAI的O1模型 是最新发布的SOTA模型之一,分为 O1-preview 和 O1-mini 两个版本。O1模型在2023年10月发布后,凭借其卓越的长上下文处理能力,迅速在行业内崭露头角。与之前的GPT-4o模型相比,O1模型在多个长上下文RAG基准测试中表现更为出色,尤其是在处理超过百万级词元的超长文本时展现出了显著优势。
O1-mini 版本在性能上几乎与GPT-4o持平,而 O1-preview 则在一些特定任务中超越了GPT-4o,显示出其强大的泛化能力和适应性。这两款模型不仅在标准数据集上的表现优异,还在诸如Databricks DocsQA和FinanceBench等内部数据集上展现了卓越的性能。
O1模型在长上下文RAG基准测试中的表现
为了全面评估O1模型在长上下文RAG任务中的性能,我们将其在多个数据集上的表现进行详尽分析,包括Databricks DocsQA 、FinanceBench 和 Natural Questions (NQ)。
在Databricks DocsQA数据集上的表现
Databricks DocsQA 是一个内部数据集,专注于文档问答任务,涵盖了技术文档的复杂结构与多样化内容。在此数据集上,O1-preview和O1-mini模型在所有上下文长度下的表现显著优于GPT-4o和Google Gemini模型。具体而言:
- O1-preview 模型在2k至200万词元的上下文长度范围内,回答的正确性和相关性均稳步提升,尤其在长上下文下表现尤为突出。
- O1-mini 版本在处理超长上下文时,准确率接近GPT-4o,但在某些任务中超越了GPT-4o,显示出其高效的上下文处理能力。
图2.1展示了不同模型在Databricks DocsQA数据集上的RAG性能对比,可以明显看出O1模型的优势。

在FinanceBench数据集上的表现
FinanceBench 数据集专注于金融领域的问答任务,涉及大量专业术语与复杂的金融逻辑。在此数据集上,O1模型同样表现优异:
- O1-preview 和 O1-mini 在所有上下文长度下,尤其是在8k及以上,准确率均显著高于GPT-4o和Gemini模型。
- 尤其是在16k甚至更长的上下文长度下,O1模型能够保持较高的回答质量,展示出其在处理金融数据复杂性方面的优势。
图2.2展示了O1模型在FinanceBench数据集上的长上下文RAG性能,进一步验证了其卓越表现。

在Natural Questions (NQ)数据集上的表现
Natural Questions (NQ) 是一个标准的学术基准测试数据集,涵盖了广泛的常识性问题。在NQ数据集上,O1模型的表现总体优异,但在短上下文长度(2k词元)下存在一定的性能下降:
- 在短篇幅上下文中,如果检索到的文档中信息不足,O1模型倾向于回答"信息不可用",而无法基于自身知识进行补充回答。
- 尽管如此,在更长的上下文环境下,O1模型依然保持了较高的回答正确性,接近甚至超越了GPT-4o。
这种在短上下文下的性能下降主要源于检索文档的相关性不足,导致模型无法充分发挥其生成能力。
与Google Gemini 1.5模型的对比
Google Gemini 1.5 模型是目前市场上另一款领先的长上下文RAG模型,拥有Pro 和 Flash 两个版本。在多个基准测试中,Gemini 1.5展示出了其独特的优势,尤其是在处理超长上下文时的稳定性。
Gemini 1.5在超长上下文下的稳定性
尽管在128k词元以下的整体答案正确性低于O1和GPT-4o模型,Gemini 1.5 在处理高达200万词元的超长上下文时,表现出了惊人的稳定性。具体表现如下:
- 一致性:在超长上下文下,Gemini 1.5模型能维持一致的回答质量,而不会像其他模型那样在上下文长度增加时出现性能波动。
- 资源优化:尽管处理超长文本可能带来较高的计算成本,Gemini 1.5通过优化算法,有效控制了资源消耗,使其在长文档处理上具有成本效益。
图2.1展示了Gemini 1.5在NQ数据集上的长上下文RAG性能,显示其在大规模文本处理中依然能够保持高水平的回答正确性。

成本与开发便捷性的权衡
对于开发者而言,选择合适的模型不仅要考虑性能,还需权衡成本与开发便捷性。Gemini 1.5在长上下文处理上的优势意味着在某些应用场景下,可以跳过传统的检索步骤,直接将整个数据集输入模型进行处理。然而,这种做法可能带来较高的计算成本与资源消耗,但为开发人员提供了更简化的开发体验,适合对开发效率有较高要求的项目。
通过对比分析,我们可以得出:
- O1模型 在中短上下文下表现优异,适合需要高准确性和相关性的应用场景。
- Gemini 1.5 则更适合处理超长上下文且对成本有一定容忍度的项目,提供了一种简化的RAG工作流方案。
LLM在长上下文RAG中的失败模式分析
尽管大型语言模型在长上下文RAG任务中展现了强大的能力,但在实际应用中,仍然存在多种失败模式。理解这些失败模式有助于开发者在构建应用时采取相应的优化措施,提升系统的整体性能与稳定性。
OpenAI O1-preview与O1-mini的失败模式
在对O1模型的失败案例进行分析时,我们发现其主要失误类别包括:
- 重复内容(repeated_content):模型生成回答时出现重复的无意义词组或字符,影响回答的可读性与信息量。
- 随机内容(random_content):生成的回答与上下文内容无关,缺乏逻辑性和语法合理性。
- 未遵循指令(fail_follow_inst):未按照问题要求生成回答,如在要求基于上下文回答时,模型尝试进行总结。
- 空响应(empty_resp):模型未生成任何回答,返回空字符串。
- 错误答案(wrong_answer):尽管遵循了指令,模型提供了错误的答案。
- 拒绝回答(refusal):模型因不确定性或其他原因拒绝回答问题。
- 因API过滤导致的任务失败:由于安全过滤规则,模型未生成回答。
O1-preview 和 O1-mini 在处理不同上下文长度时,特别是在推理步骤的词元长度不可预测时,可能会因上下文过长而返回空响应。此外,在NQ数据集中,短上下文下的性能下降表现为模型简单地回答"信息不可用",即便在一些情况下存在支持回答的oracle文档,模型仍未能提供正确答案。
下面两个图分别展示了O1-preview在Databricks DocsQA和NQ数据集上的失败分析,可以看出不同数据集和上下文长度对模型表现的影响。


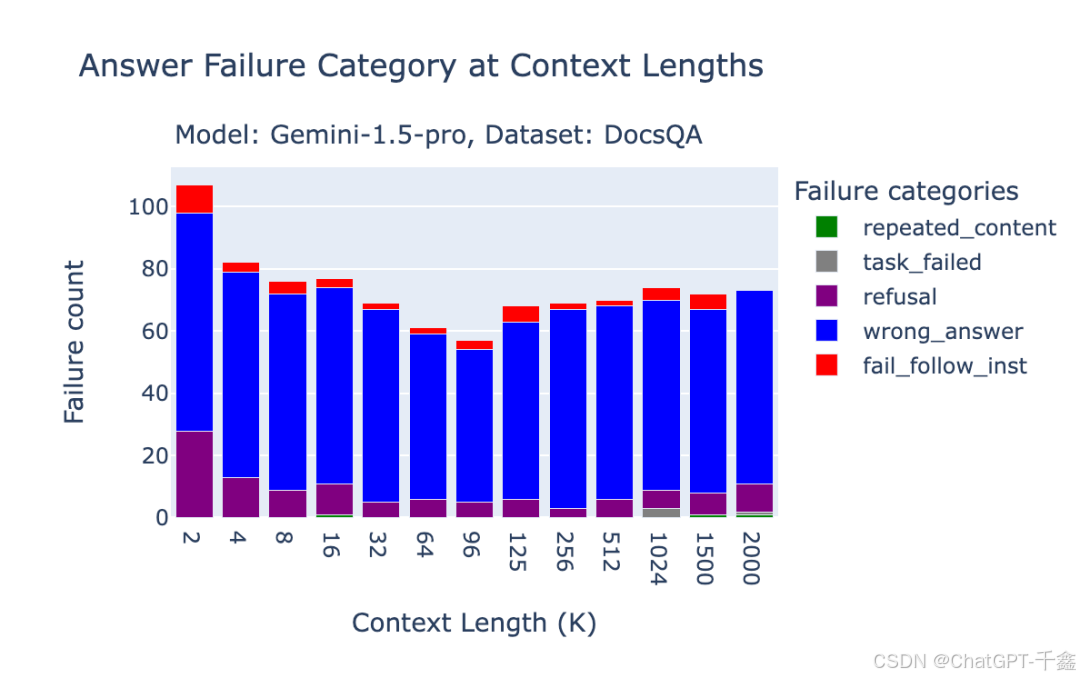
Google Gemini 1.5 Pro与Flash的失败模式
Gemini 1.5 模型的失败模式分析显示,其主要问题在于:
- 主题敏感性:生成API对提示内容的主题高度敏感,尤其在NQ基准测试中,由于提示内容被过滤,导致了大量任务失败。
- 拒绝回答:在FinanceBench数据集中,模型经常因为检索不到相关信息而拒绝回答,尤其在短上下文(2k词元)下,96.2%的"拒绝"情况发生在缺失oracle文档时。
- BlockedPromptException错误:由于提示内容被API过滤,导致生成任务失败,这类错误在NQ基准测试中较为普遍。
图3.3至图3.5展示了Gemini 1.5 Pro在不同数据集上的失败模式分布,可以明显看出在不同上下文长度和数据集环境下,模型表现出的特有问题。
优化长上下文RAG性能的策略
针对上述模型的表现与失败模式,开发者可以采取以下策略优化长上下文RAG的性能,提升应用的整体效果。
选择合适的模型与上下文长度
根据具体应用需求选择最合适的模型与上下文长度,是提升RAG性能的第一步。
- 中短上下文应用 :对于需要高准确性和相关性的应用,如技术文档问答、金融报告分析,推荐使用OpenAI O1-preview 或 O1-mini,在2k至16k词元的上下文长度下表现优异。
- 超长上下文应用 :对于需要处理超过200万词元的超长文本,如大型文档解析、综合报告生成,Google Gemini 1.5 是更合适的选择,其在超长上下文下保持了相对稳定的性能。

改进检索步骤以提升性能
检索步骤在RAG流程中扮演着至关重要的角色,改进检索算法和策略,可以有效提升模型的回答质量。
- 增强检索相关性:通过优化检索算法,确保检索到的文档与问题高度相关,减少模型生成随机或错误回答的概率。
- 动态上下文调整 :根据问题的复杂性和上下文的相关性,动态调整输入的上下文长度,确保模型在不同任务中都能获得足够的信息支持。
处理模型的失败模式
针对模型在不同场景下的失败模式,采取相应的预防和修正措施,能够显著提高系统的稳定性和用户体验。
- 内容过滤与指令优化:在设计提示内容时,避免触发模型的拒绝回答机制,采用更加明确和具体的指令,减少因安全过滤导致的任务失败。
- 多模型协同:结合多种模型的优势,采用多模型协同策略,如在短上下文下优先使用O1模型,在超长上下文下切换至Gemini模型,最大化每种模型的优点。
- 错误监控与反馈机制:建立完善的错误监控系统,实时检测并记录模型的失败情况,采用反馈机制不断优化提示内容和模型选择策略。
更多人在看
【OpenAI】(一)获取OpenAI API Key的多种方式全攻略:从入门到精通,再到详解教程!!
【VScode】(二)VSCode中的智能AI-GPT编程利器,全面揭秘CodeMoss & ChatGPT中文版
结论:未来的发展与展望
随着AI技术的不断进步,长上下文RAG在各种应用场景中的重要性日益凸显。OpenAI O1模型 的发布,展示了其在处理长上下文任务上的强大能力,超越了之前的GPT-4o模型,为行业树立了新的标杆。同时,Google Gemini 1.5 在超长上下文处理上的独特优势,也为开发者提供了更多选择,特别是在需要处理海量文本数据的应用中,Gemini 1.5 的优势尤为明显。