文章目录
- [一、Hugging Face介绍](#一、Hugging Face介绍)
- 二、加载并使用预训练模型
-
- [2.1 查找预训练模型](#2.1 查找预训练模型)
- [2.2 实际案例](#2.2 实际案例)
-
- [2.2.1 调取预训练模型](#2.2.1 调取预训练模型)
- [2.2.2 如何在具体的推理任务中使用预训练模型?](#2.2.2 如何在具体的推理任务中使用预训练模型?)
- [2.3 如何在训练前就判定好哪些模型适用于实际任务?](#2.3 如何在训练前就判定好哪些模型适用于实际任务?)
- 三、词嵌入工具与词嵌入模型
-
- [3.1 调用分词器,循环对每个句子进行分词](#3.1 调用分词器,循环对每个句子进行分词)
- [3.2 调用分词器,批量处理数据](#3.2 调用分词器,批量处理数据)
- [3.3 建立好词汇表后,有哪些功能可以调用?](#3.3 建立好词汇表后,有哪些功能可以调用?)
- 四、全流程自动化的Pipelines工具
一、Hugging Face介绍
随着人工智能领域的发展,模型的体量逐渐增长、数据的体量逐渐增长、在实践中应用复杂的人工智能算法的需求日益增加,越来越多的开发者会倾向于直接使用经过预训练和封装的成熟NLP算法,而非自行构建复杂的transformers或tokernizer架构。Huggingface正是把握住了这一需求的变化,开发了封装层次极高、调用简单、节约算力、且训练流程清晰明确的Transformers库,这个库提供了一系列与人工智能相关的预训练模型,如BERT、GPT、T5等,这些模型都是建立在原始Transformer架构基础之上,并对其进行了扩展和优化,以适用于各种各样的NLP任务。与最初由Google提出的Transformer模型相比,Hugging Face的Transformers库提供了更为丰富、易于使用且经过精心优化的模型选择,同时支持跨多种编程语言和平台。
注:打开hugging face 需要使用魔法工具,梯子一类的。
二、加载并使用预训练模型
2.1 查找预训练模型
在首页中,选择模型有两种方法,一种是下图所示的:在Models中选择下载量最大的模型(一般下载量大说明训练效果比较好),还有一种是可以在Tasks中选择适合某种任务的模型。
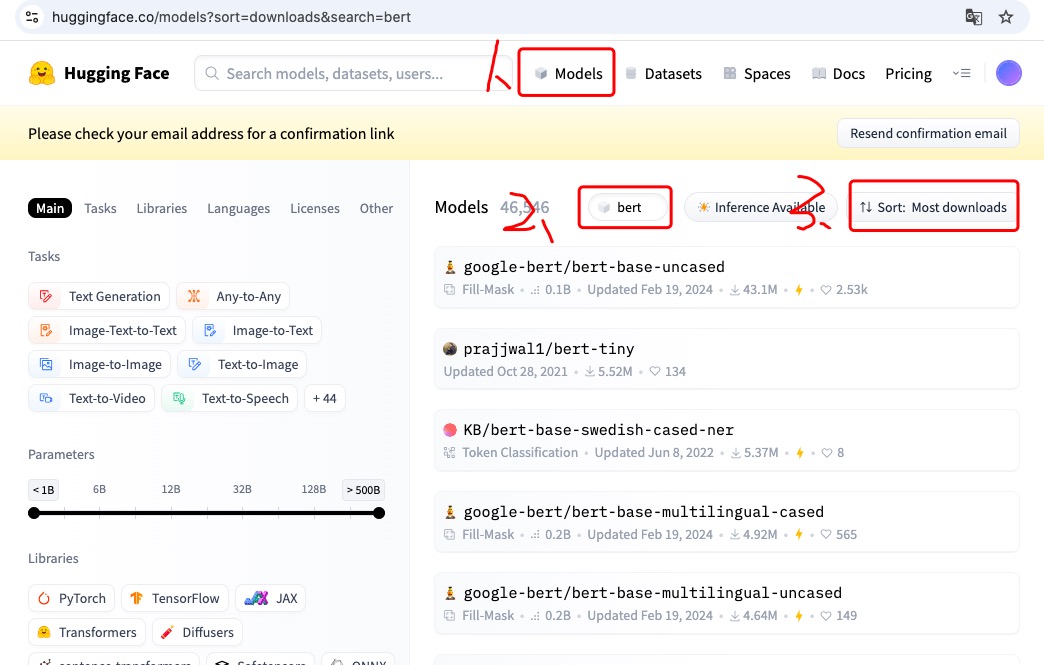
点击下载量最大的模型页面

然后映入眼帘的就是这个模型的Model Card
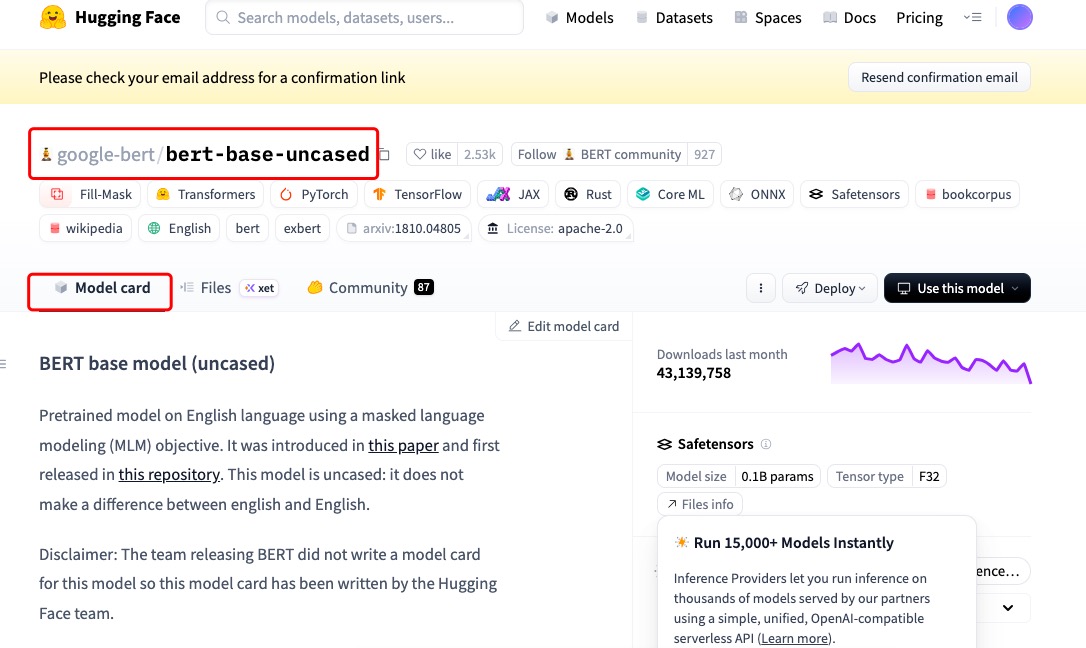
这里一般都有模型调用的方法,一般往下翻就可以找得到,如果没有代码,有的会提供github链接,点击链接跳转到README页面也有模型调用代码。
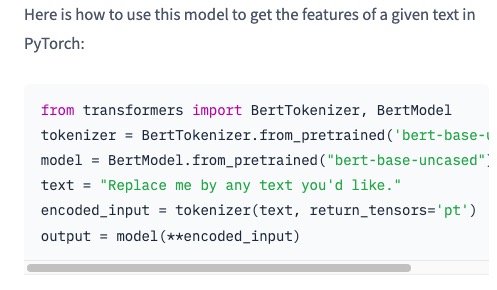
在from_pretrained引入预训练模型的时候,模型的名称是可以换的,在本次案例中,我们引入的是'bert-based-chinese'(专用于中文文本的训练)
需要注意的逻辑是:当我们从Bert中引入预训练好的模型时,我们可以通过查字典的方式,来查询每个单词在已经训练好的词嵌入矩阵中的词向量,当只要经过bert模型,就可以得到包含当前文本语义关系的新的词向量。案例如下:
python
from transformers import BertTokenizer, BertModel
import torch
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
model = BertModel.from_pretrained('bert-base-chinese')
text = "猫追老鼠"
encoded_input = tokenizer(text, return_tensors='pt')
input_ids = encoded_input['input_ids']
print("=== 三个重要概念的对比 ===")
# 1. 静态词嵌入矩阵 (训练好的查找表)
print("1. 静态词嵌入矩阵:")
word_embeddings = model.embeddings.word_embeddings
print(f" Shape: {word_embeddings.weight.shape}")
print(f" 含义: 21128个token每个都有固定的768维向量")
# 2. 初始词嵌入 (静态查找结果)
print("\n2. 初始词嵌入 (从词嵌入矩阵查找):")
initial_embeddings = word_embeddings(input_ids)
print(f" Shape: {initial_embeddings.shape}")
print(f" 示例 - '猫'的初始向量:")
print(f" Token ID: {tokenizer.encode('猫')[1:-1][0]}")
print(f" 这个向量是固定的,与上下文无关")
# 3. BERT最终输出 (上下文相关表示)
print("\n3. BERT输出last_hidden_state:")
with torch.no_grad():
output = model(**encoded_input)
print(f" Shape: {output.last_hidden_state.shape}")
print(f" 示例 - '猫'的上下文向量:")
print(f" 这个向量考虑了'追老鼠'的上下文")
# 对比两者的差异
print("\n=== 关键区别 ===")
print("初始嵌入 vs BERT输出的区别:")
# 计算差异
difference = torch.norm(initial_embeddings - output.last_hidden_state)
print(f"两者之间的欧式距离: {difference.item():.4f}")
print("这个差异越大,说明BERT对原始嵌入的改变越大")
'''
=== 三个重要概念的对比 ===
1. 静态词嵌入矩阵:
Shape: torch.Size([21128, 768])
含义: 21128个token每个都有固定的768维向量
2. 初始词嵌入 (从词嵌入矩阵查找):
Shape: torch.Size([1, 6, 768])
示例 - '猫'的初始向量:
Token ID: 4344
这个向量是固定的,与上下文无关
3. BERT输出last_hidden_state:
Shape: torch.Size([1, 6, 768])
示例 - '猫'的上下文向量:
这个向量考虑了'追老鼠'的上下文
=== 关键区别 ===
初始嵌入 vs BERT输出的区别:
两者之间的欧式距离: 53.3272
这个差异越大,说明BERT对原始嵌入的改变越大
'''如果遇到模型下载不成功报"网络错误"或者Model Card中没有模型调用的代码提示,可以到files里面下载模型的所有代码,然后在本地的Pycharm中新建project就可以跑通了。
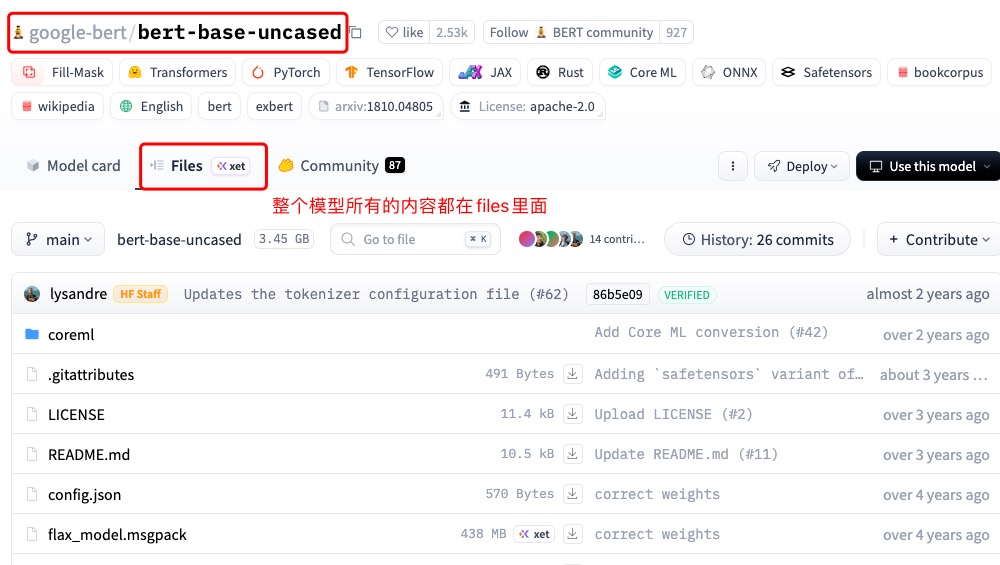
2.2 实际案例
2.2.1 调取预训练模型
python
from transformers import BertTokenizer, BertModel
# 从本地目录加载
model_path = "./bert-base-chinese" # 确保这个目录下有下载的文件
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
model = BertModel.from_pretrained('bert-base-chinese')
text = "虽然今天下雨了,但我拿到了心仪的offer,因此非常开心!"
#将text输入分词和编码模型
encoded_input = tokenizer(text, return_tensors='pt')
#将编码好的文字输入给预训练好的bert
output = model(**encoded_input)
#查看output
print(output)
output的结构如下所示:
BaseModelOutputWithPoolingAndCrossAttentions(
last_hidden_state=tensor([[[...]]]),
pooler_output=tensor([[...]]),
hidden_states=None, # 或包含所有层的输出(如果设置了output_hidden_states=True)
attentions=None # 或包含注意力权重(如果设置了output_attentions=True)
)这里的确已经输出了bert的结果,然而预训练的 BERT 模型(如 BertModel)并没有直接针对具体的任务(如句子分类)进行训练。预训练模型只是通过在大规模文本上进行无监督学习,掌握了语言的基本结构和语义关系。但是,BERT 模型本身并不知道具体的分类标签,也没有针对分类任务进行过训练。
2.2.2 如何在具体的推理任务中使用预训练模型?
在加载预训练模型的时候,如果跑不通就直接到huggingface上搜索该模型,将其files中的内容下载到本地,调用本地的目录在获取预训练模型。
python
from transformers import BertTokenizer, BertModel
from torch import nn as nn
import torch
# 从本地目录加载
model_path = "./bert-base-chinese" # 确保这个目录下有下载的文件
#加载Bert模型和分词器
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
model = BertModel.from_pretrained('bert-base-chinese')
# 定义句子分类器
class BertSentenceClassifier(nn.Module):
def __init__(self, bert_model, num_classes):
super(BertSentenceClassifier, self).__init__()
self.bert = bert_model
self.classifier = nn.Linear(bert_model.config.hidden_size, num_classes)
def forward(self, input_ids, attention_mask):
# 获取BERT的输出
outputs = self.bert(input_ids=input_ids, attention_mask=attention_mask)
# 获取[CLS] token的表示
pooler_output = outputs.pooler_output
# 将其输入到分类器中
logits = self.classifier(pooler_output)
return logits
# 示例文本
text = "虽然今天下雨了,但我拿到了心仪的offer,因此非常开心!"
# 将文本转化为BERT的输入格式
encoded_input = tokenizer(text, return_tensors='pt')
# 初始化分类器,假设我们有两个分类标签(如:积极和消极)
classifier = BertSentenceClassifier(model, num_classes=2)
# 获取分类结果
logits = classifier(encoded_input['input_ids'], encoded_input['attention_mask'])
# 将logits转换为概率(如果需要)
probabilities = torch.softmax(logits, dim=1)
# 打印分类结果
print("Logits:", logits)
print("Probabilities:", probabilities)
#Logits: tensor([[-0.3707, 0.1022]], grad_fn=<AddmmBackward0>)
#Probabilities: tensor([[0.3839, 0.6161]], grad_fn=<SoftmaxBackward0>)输出为1的概率为0.6161,句子被判断为"积极"。
2.3 如何在训练前就判定好哪些模型适用于实际任务?
从task入手,假如当前的任务是分类,我们就从tasks里面找就好了
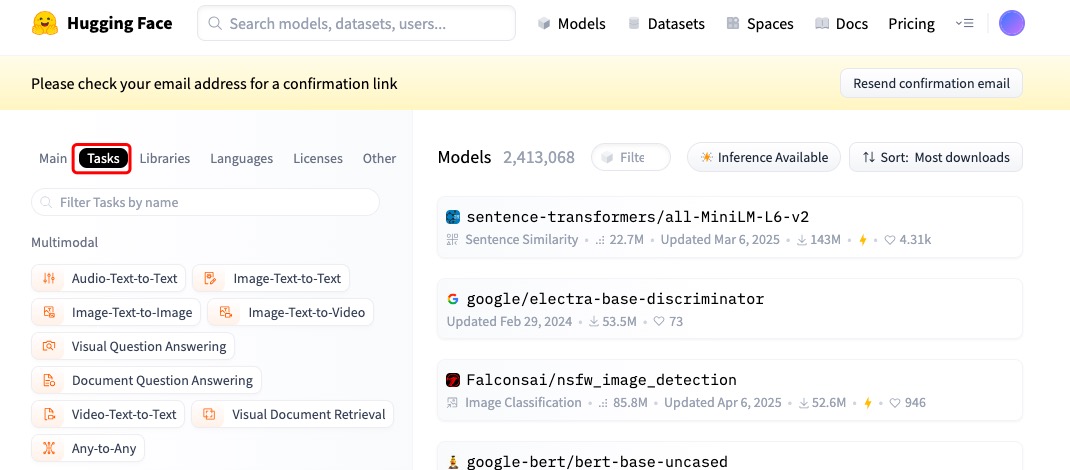
如果是单词分类,锁定Token Classification,如果是为了给一个句子进行分类,就选Text Classfication
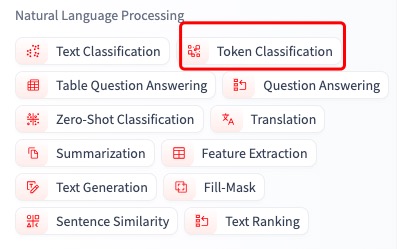
然后在当前筛选中继续查找bert模型,依旧是找下载量最高的模型,或者是其他更合适的模型,实在不会选用下deepseek
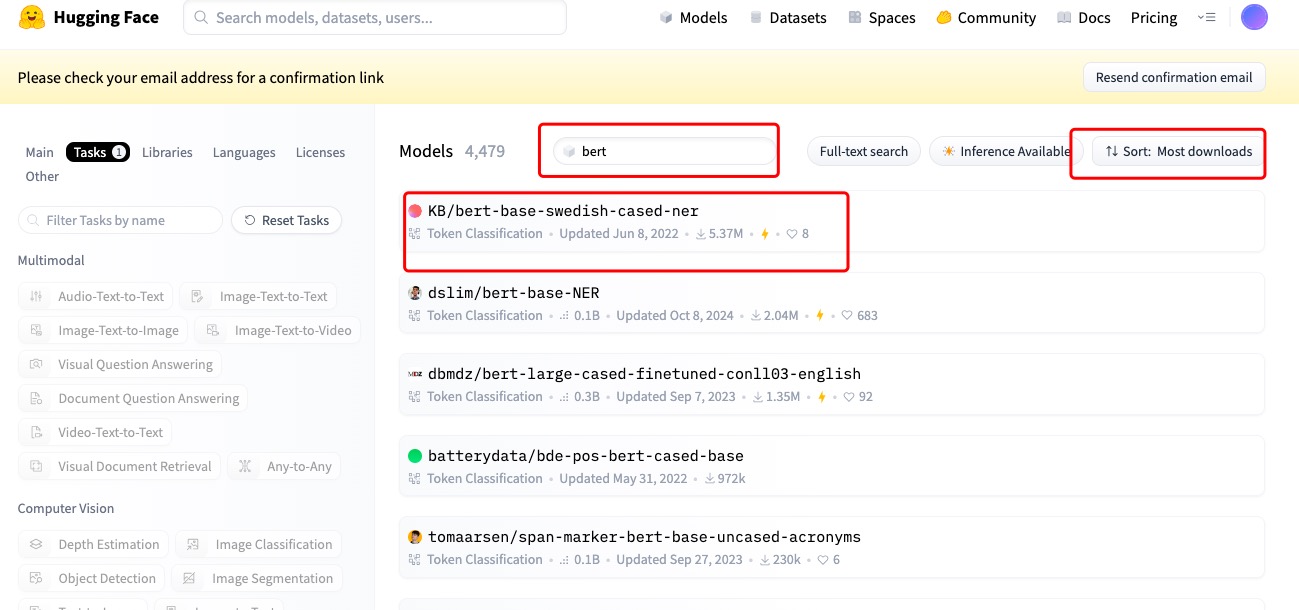
有的模型在Use model里点击transforms就可以直接找到模型调用的代码
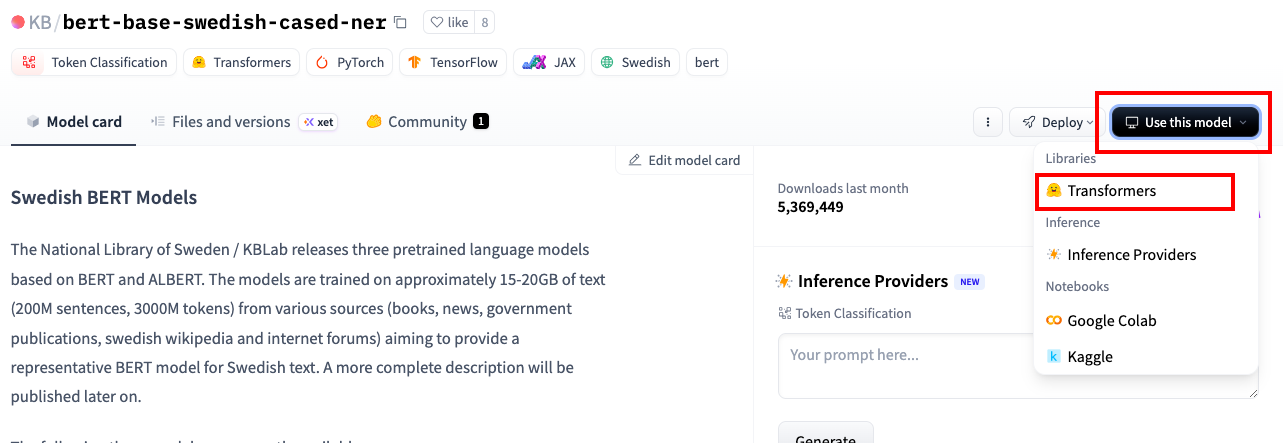
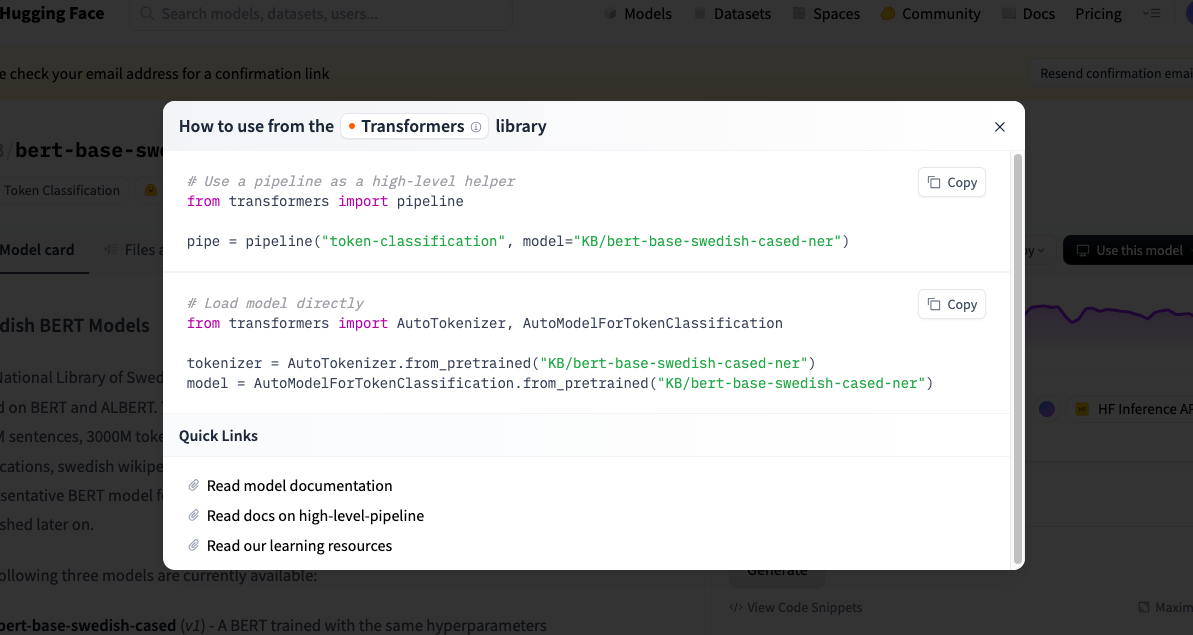
调用模型的代码为:
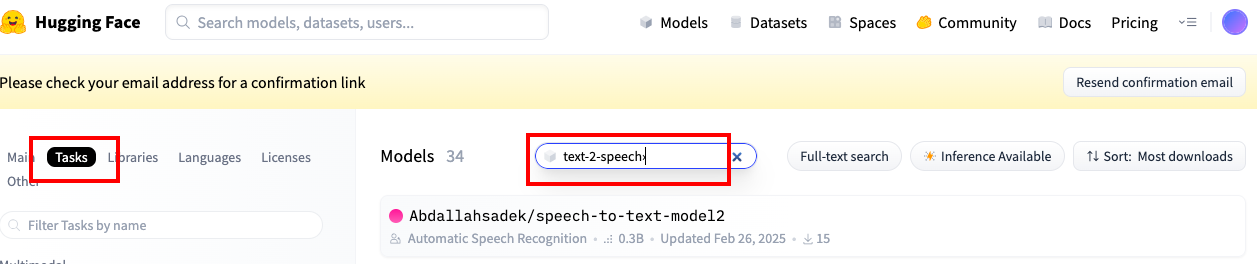
如果task是比较冷门的,可以直接在首页搜索,如下图所示:
三、词嵌入工具与词嵌入模型
词嵌入(Word Embedding)是自然语言处理(NLP)中的一种技术,用于将文本中的词汇或子词转换为低维向量表示。词嵌入的核心思想是将文本数据转化为模型可以理解和处理的数字表示,这种表示保留了词汇之间的语义关系。
在 Hugging Face 的 Transformers 库中,词嵌入工具主要负责以下任务:
将离散的文本数据映射为连续的向量表示:
-
自然语言中的词汇是离散的符号,例如"猫"或"狗",这些符号本身并没有数量上的意义。通过词嵌入工具,词汇会被映射到一个低维的向量空间中,这些向量保留了语义信息。例如,语义相似的词汇会在向量空间中彼此靠近。
-
初始化模型输入: 在使用深度学习模型(如 Transformer 模型)进行任务时,文本输入首先会通过分词器(Tokenizer)被分解成 token(子词或词汇),接着这些 token 会被映射到相应的词嵌入向量中。这个过程是模型理解输入文本的第一步。
-
词嵌入向量不仅保留了词汇的语义信息,还为模型提供了丰富的上下文信息,使得模型可以在更高的层次上处理文本数据。
提供丰富的语义和上下文表示:通过词嵌入,模型能够捕捉到词汇之间的复杂关系,例如同义词、反义词、类比等。对于 Transformer
模型而言,这些向量表示是后续处理的基础,模型通过多层的注意力机制来进一步处理和理解这些向量表示。
3.1 调用分词器,循环对每个句子进行分词
python
from transformers import AutoTokenizer
PATH = r"HuggingfaceModels/"
# 加载预训练的BERT分词器
tokenizer = AutoTokenizer.from_pretrained(os.path.join(PATH,'bert-base-chinese'))
# 读取数据
file_path = r"DLdata/cnews_train_sampled_2000.txt"
# 读取数据
data = read_file(file_path)
# 对每个文本进行分词
for text in data:
#将文本输入tokenizer,直接分词
tokens = tokenizer.tokenize(text)
#分完词后,直接使用convert_tokens_to_ids进行token编码
token_ids = tokenizer.convert_tokens_to_ids(tokens)
print(f"Original Text: {text} \n\n")
print(f"Tokens: {tokens[:100]} \n\n")
print(f"Token IDs: {token_ids[:100]}")
break3.2 调用分词器,批量处理数据
python
# 批量处理多个文本
encoded_inputs = tokenizer(filtered_data, padding=True, truncation=True, return_tensors='pt')3.3 建立好词汇表后,有哪些功能可以调用?
python
encoded_inputs['input_ids'] #编辑好的seq
encoded_inputs['attention_mask'] #掩码在批量处理文本后,除了 input_ids 和 attention_mask,tokenizer 返回的对象中还可以包含其他多个有用的张量或指标,这些数据都可以直接用于模型的输入或分析。以下是一些常见的输出以及它们的功能:
-
input_ids:这是最基础的输出,表示每个 token 的 ID,直接对应于模型词汇表中的索引。示例:101, 你好, 102
可能会映射为 101, 12895, 102。
-
attention_mask:表示哪些 token 是实际输入内容,哪些是填充(padding)内容。1 表示实际内容,0 表示填充。用于告诉模型忽略填充部分的影响,确保模型仅关注实际内容。示例:1, 1, 1, 0, 0 表示前 3 个 token 是实际内容,后 2 个是填充。
-
token_type_ids(或 segment_ids)主要用于区分 BERT中的不同句子(或段落)。在句子对(如问答、自然语言推理)任务中,token_type_ids 用于区分两个句子。一般情况下,第一句的token 标记为 0,第二句的 token 标记为 1。示例:0, 0, 0, 1, 1, 1 表示前 3 个 token属于第一句话,后 3 个 token 属于第二句话。token_type_ids对于句子对任务(如问答、自然语言推理)非常重要。
-
special_tokens_mask用于标记哪些 token 是特殊符号,例如 CLS, SEP, PAD 等。这些token 在某些任务中可能需要特别处理。示例:1, 0, 0, 1, 0, 0,1,表示位置 1、4 和 7是特殊符号。special_tokens_mask 在处理包含特殊符号的文本时有用。
-
offset_mapping:主要用于精确映射原始文本和 token 之间的位置关系。对于每个 token,offset_mapping返回一个 (start, end) 元组,指示该 token在原始文本中的起止位置。这在命名实体识别(NER)等任务中非常有用。示例:(0, 1), (1, 2), (2, 4) 表示第一个token 对应于原始文本的第 0 到 1 个字符,依此类推。offset_mapping特别适用于精确文本对齐任务,如命名实体识别(NER)。
-
overflowing_tokens:当输入文本过长而被截断时,这个字段会返回被截断的 token。这在需要处理被截断部分的任务中很有用。overflowing_tokens 和 num_truncated_tokens 用于处理超长文本输入时的分析。
-
num_truncated_tokens:表示由于输入文本过长而被截断的 token数量。这个信息可以帮助你了解文本在被截断时损失了多少内容。
-
length:表示每个输入序列的实际长度(不包含填充部分)。这个信息在分析输入序列的长度分布时非常有用。
四、全流程自动化的Pipelines工具
Hugging Face 的 pipeline 功能是一个非常强大且易于使用的高层次 API,它允许用户通过简单的接口来访问和使用预训练的 Transformer 模型。pipeline 将复杂的预处理、模型调用和后处理步骤封装在一起,使得用户可以轻松地应用深度学习模型来完成各种自然语言处理(NLP)和计算机视觉任务,而不需要深入了解模型的底层细节。
使用pipelines能够完成的任务如下所示:
| 任务名称 | 任务描述 |
|---|---|
| sentiment-analysis | 用于文本情感分类的任务 |
| text-generation | 文本生成任务,如自动写作或补全文本。 |
| ner | 识别文本中的实体(如人名、地点、组织)。 |
| question-answering | 针对给定文本的问题回答任务。 |
| fill-mask | 填充文本中的掩码(mask)词汇的任务。 |
| summarization | 自动文本摘要生成任务。 |
| translation_xx_to_yy | 翻译任务,xx 和 yy 表示不同的语言代码。 |
| text2text-generation | 将文本转换为另一种形式或语言的任务。 |
| zero-shot-classification | 不带训练的直接分类任务,可以为文本分配多个标签。 |
| conversational | 对话模型,根据对话的历史回应新的对话输入。 |
| feature-extraction | 提取文本的特征向量。 |
| text-classification | 文本分类,也被称为主题分类。 |
| token-classification | 分词层面的分类,如词性标注。 |
| table-question-answering | 对结构化表格数据进行问题回答的任务。 |
| translation | 自动翻译任务,通常需要指定源语言和目标语言。 |
| automatic-speech-recognition | 自动语音识别,将语音转录为文本。 |
| image-classification | 图像分类任务。 |
| object-detection | 在图像中识别多个物体及其位置。 |
| text-to-speech | 文本转语音任务。 |
python
from transformers import pipeline, set_seed
#创建一个pipeline,自动加载预训练模型和相应的预处理
generator = pipeline('task-generation', model='gpt2')
set_seed(42)
generator("hello GPT", max_length=30, num_return_sequences=5)
[{'generated_text': 'Hello gpt!: what i do. that will help. I know i was here for a week but, you bet. I mean'},
{'generated_text': 'Hello gpt! ˥\u3101 ˥\u3102ㄅ ˥ㄈㄇ'},
{'generated_text': 'Hello gpt!!!!!!!!!'},
{'generated_text': 'Hello gpt!\n\nWe can now update the Google Chrome API, a simple feature that was missing from the prior versions.\n\n'},
{'generated_text': 'Hello gpt!"\n\n(I really should probably make a post on the Internet about how to read a website.)\n'}]可以在hugging face 的Docs中找到Transformers,进去搜索pipeline,同样可以看到针对不同任务pipelien代码。
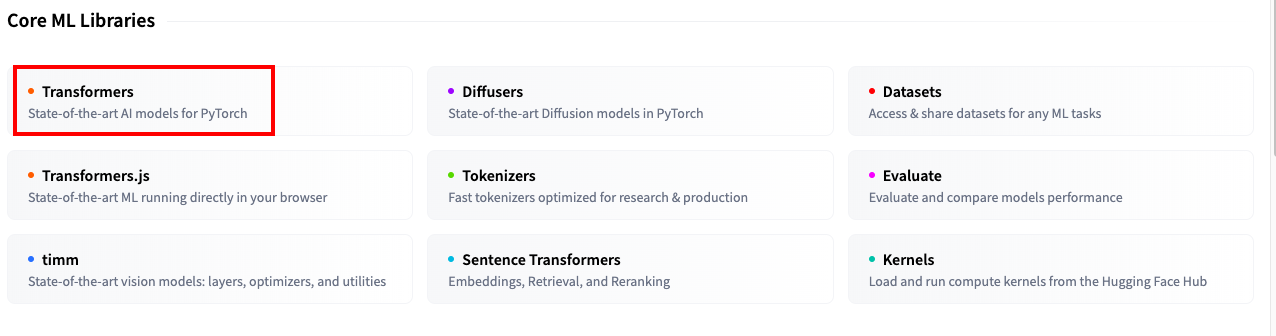
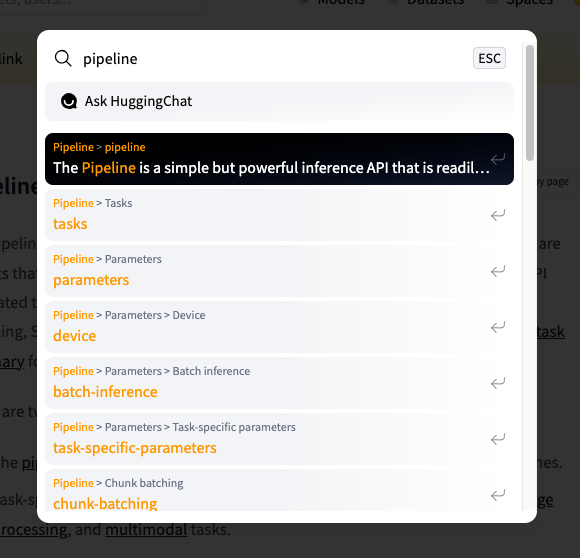
进去之后就会看到各种各样的使用方法介绍,非常全面:
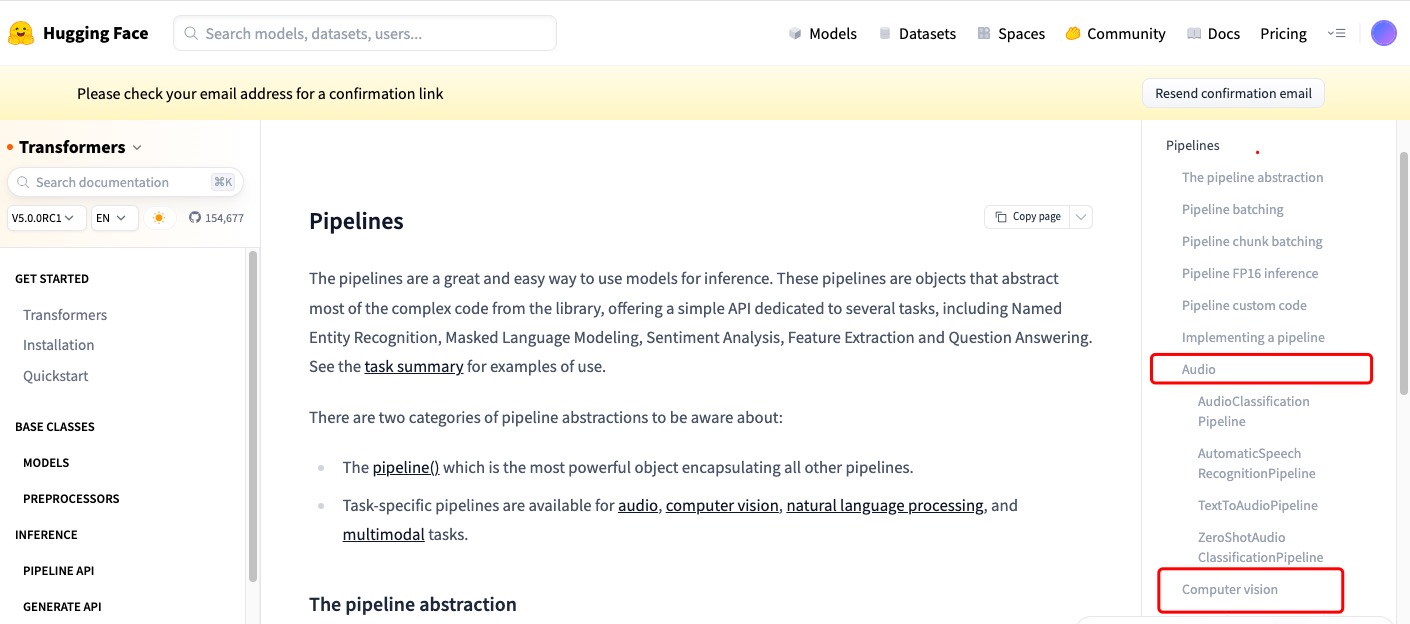 在页面的右侧有目录,针对语音、视频等不同格式的数据集有哪些不同的任务,针对不同的任务的代码调用,都有详细的介绍。
在页面的右侧有目录,针对语音、视频等不同格式的数据集有哪些不同的任务,针对不同的任务的代码调用,都有详细的介绍。
缺陷:如果效果不好,没有办法对pipelines的模型进行微调,只能退到最底层来修改。