一、二值化
1.1 二值化图
二值化图:就是将图像中的像素改成只有两种值,其操作的图像必须是灰度图。


1.2 阈值法
阈值法(Thresholding)是一种图像分割技术,旨在根据像素的灰度值或颜色值将图像分成不同的区域。该方法通过选择一个或多个阈值来决定图像中每个像素的分类,常用于将图像转换为二值图像(即仅包含两种颜色的图像)。在图像处理中的阈值化,通常指的是通过设定一个灰度值阈值,将图像的像素分为两类:前景(感兴趣的区域)和背景。
阈值法的基本原理
-
选择阈值 :选择一个合适的阈值
T,它通常是一个灰度值。图像中的每个像素会根据其灰度值与阈值T的关系进行分类。- 如果像素的灰度值大于
T,则该像素属于前景。 - 如果像素的灰度值小于或等于
T,则该像素属于背景。
公式表示为:
- 如果像素的灰度值大于
-
其中,
I(x, y)表示图像在位置(x, y)处的像素值,f(x, y)是阈值化后的输出。 -
生成二值图像 :通过将每个像素根据设定的阈值
T分类,最终得到一张二值图像,像素值为1(或255)表示前景,像素值为 0(或0)表示背景。
示例:
python
import cv2 # 导入OpenCV库,用于图像处理
import numpy as np # 导入NumPy库,用于数组和矩阵运算
# 读取图片
img = cv2.imread('./flower.png') # 从指定路径加载图片,注意路径需正确
# 转换成灰度图
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 将彩色图片转换为灰度图
# 创建一个与灰度图同样大小的零矩阵,用于存储二值化后的图像
img_binary = np.zeros_like(img_gray)
# 设置阈值
thresh = 127 # 设定一个阈值,用于将灰度图进行二值化处理
# 二值化处理(手动实现)
# 遍历灰度图的每个像素,如果像素值大于阈值,则设为255(白色),否则设为0(黑色)
for i in range(img_gray.shape[0]): # 遍历图片的每一行
for j in range(img_gray.shape[1]): # 遍历图片的每一列
if img_gray[i,j] > thresh:
img_gray[i,j] = 255 # 将大于阈值的像素点设为白色
else:
img_gray[i,j] = 0 # 将小于等于阈值的像素点设为黑色
# 反转二值化处理结果(手动实现),生成另一种二值图像
# 遍历处理后的灰度图,如果像素值小于等于阈值,则设为255(白色),否则设为0(黑色)
# 这一步其实是对上一步的结果进行了反转,使得原本为白色的区域变为黑色,黑色的区域变为白色
for i in range(img_gray.shape[0]): # 遍历图片的每一行
for j in range(img_gray.shape[1]): # 遍历图片的每一列
if img_gray[i,j] <= thresh:
img_binary[i,j] = 255 # 在反转的二值图中,将原本为黑色的区域设为白色
else:
img_binary[i,j] = 0 # 在反转的二值图中,将原本为白色的区域设为黑色
# 显示原始图片、灰度图和两种二值化后的图片
cv2.imshow('img', img) # 显示原始图片
cv2.imshow('img_gray', img_gray) # 显示灰度图
cv2.imshow('img_binary', img_binary) # 显示反转后的二值图
cv2.waitKey(0) # 等待按键事件,按任意键关闭所有窗口例图见1.1
1.3 截断阈值法
截断阈值法(Truncation Thresholding)是阈值法的一种变体,在图像处理中用于限制像素值的范围。与传统的阈值化方法不同,截断阈值法不会将像素值完全二值化为 0 或最大值,而是对像素值进行截断,使其限制在一定的范围内。这意味着只有在特定阈值之上或之下的像素值会被改变,而其他像素值会被保留。
截断阈值法的工作原理
截断阈值法将图像的每个像素值与设定的阈值进行比较:
- 如果像素值大于设定的阈值,则将该像素值设置为该阈值。
- 如果像素值小于或等于设定的阈值,则保持不变。
公式表示为:
其中,I(x, y) 表示原始图像中位置 (x, y) 的像素值,T 是设定的阈值,f(x, y) 是经过截断后的输出图像。
1.4 OTSU阈值法
OTSU 阈值法(Otsu's Thresholding)是一种自动确定图像分割阈值的算法,常用于图像二值化。它通过计算图像的类间方差(或类间方差的最大化)来选择最佳的阈值,从而实现图像的自动分割。
OTSU 阈值法是一种全局阈值法,它适用于灰度直方图具有双峰分布的图像。该方法的关键思想是:选择一个阈值,使得图像分割后的前景和背景之间的类间方差最大,从而提高分割的准确性。
OTSU 阈值法的基本原理
-
类间方差(Between-class variance): 类间方差是衡量前景和背景分割的质量的一个指标。Otsu 算法试图选择一个阈值,使得前景和背景的类间方差最大,从而达到最佳分割效果。
-
计算过程: 假设图像的灰度级从 0 到 255,Otsu 算法的步骤如下:
- 计算图像的灰度直方图:统计图像每个灰度级的像素数量。
- 计算每个灰度级的概率:每个灰度级的概率是该灰度级像素的数量除以图像中所有像素的总数。
- 选择最佳阈值:通过遍历所有可能的灰度阈值,计算每个阈值对应的类间方差,并选择具有最大类间方差的阈值作为分割阈值。
-
具体步骤:
公式:
Otsu 算法通过选择最大类间方差对应的阈值来进行图像分割。
1. 计算每个灰度级的概率分布。
2. 计算前景和背景的平均灰度值。
3. 计算前景和背景的类内方差。
4. 计算类间方差,并寻找使类间方差最大化的阈值。
5. 选择该阈值进行图像分割。
- 类内方差:
其中,p0(t) 和 p1(t) 分别是背景和前景的像素概率,σ0^2(t) 和 σ1^2(t)是背景和前景的方差。
- 类间方差:
其中,μ0(t)\ 和 μ1(t) 是背景和前景的均值。
Otsu 算法通过选择最大类间方差对应的阈值来进行图像分割。
OTSU 阈值法的优点
- 自动化:Otsu 方法不需要用户手动选择阈值,而是通过计算图像的类间方差自动选择最优的阈值。
- 适应性强:适用于具有双峰灰度直方图的图像,能够较好地分离前景和背景。
- 广泛应用:在图像二值化、文档图像处理、物体检测等领域有广泛的应用。
示例:
python
import cv2 # 导入OpenCV库,用于图像处理
# 从指定路径加载图片
img = cv2.imread('./flower.png') # 确保路径正确,加载的图片将存储在img变量中
# 将彩色图片转换为灰度图
# 灰度图只包含亮度信息,不包含颜色信息,处理起来更快,也更容易进行边缘检测等操作
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 使用Otsu's二值化方法对灰度图进行二值化处理
# cv2.threshold函数返回两个值,第一个值是阈值(由Otsu算法自动计算得出),第二个值是二值化后的图像
# 200是初始猜测的阈值(但实际上会被Otsu算法忽略),255是最大值(即白色)
# cv2.THRESH_BINARY表示二值化类型,cv2.THRESH_OTSU表示使用Otsu算法自动计算阈值
ret, img_binary = cv2.threshold(img_gray, 200, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
# 打印Otsu算法计算出的阈值
print(ret) # 这个值是由Otsu算法根据图像的直方图自动计算出来的,用于将图像二值化
# 显示原始图片、灰度图和二值化后的图片
cv2.imshow('img', img) # 显示原始彩色图片
cv2.imshow('img_gray', img_gray) # 显示灰度图
cv2.imshow('img_binary', img_binary) # 显示二值化后的图片,只有黑白两种颜色
# 等待按键事件,按任意键后关闭所有窗口
cv2.waitKey(0)结果同1.1
1.5 自适应二值化
自适应二值化(Adaptive Thresholding)是一种图像二值化方法,适用于光照不均匀的图像。与传统的全局阈值法不同,自适应二值化通过在图像的不同区域计算不同的阈值来处理每个区域。这样,即使图像中的不同部分光照条件不同,也能有效地进行二值化。
自适应二值化的原理
自适应二值化通过局部计算每个像素的阈值来进行二值化。每个像素的阈值是基于其邻域区域(通常是一个小窗口)内的像素值统计量(如平均值或加权平均值)来确定的。这样,可以适应图像中的局部变化。
自适应二值化的步骤:
- 选择邻域区域:为每个像素选择一个小的邻域窗口。
- 计算局部阈值:在该邻域内计算一个统计量,通常是像素值的平均值或加权平均值(例如高斯加权),然后根据该值设定一个阈值。
- 二值化:根据计算出的局部阈值,将当前像素与该阈值比较,决定其是否为前景(通常为 255)或背景(通常为 0)。
常用的自适应二值化算法:
- 均值法(Mean):每个像素的阈值是其邻域内所有像素的平均值。
- 高斯加权法(Gaussian):与均值法类似,但使用高斯加权平均来计算阈值,邻域中心的像素权重较大。
函数原型:
python
cv2.adaptiveThreshold(src, maxValue, adaptiveMethod, thresholdType, blockSize, C)- src:输入图像(灰度图)。
- maxValue:阈值化后的最大值(通常为 255)。
- adaptiveMethod :计算阈值的方法,可以是:
cv2.ADAPTIVE_THRESH_MEAN_C:使用邻域像素的均值来计算阈值。cv2.ADAPTIVE_THRESH_GAUSSIAN_C:使用邻域像素的加权高斯平均值来计算阈值。
- thresholdType :阈值化类型,可以是:
cv2.THRESH_BINARY:将像素值大于阈值的部分设置为maxValue,其余部分设为 0。cv2.THRESH_BINARY_INV:反转,即将像素值大于阈值的部分设为 0,其他部分设为maxValue。
- blockSize:邻域窗口的大小,必须为奇数(如 3, 5, 7 等)。该值决定了在计算每个像素阈值时考虑的邻域大小。
- C:常数,值越大,阈值越大。用于调整邻域计算的结果。
示例:
python
import cv2 # 导入OpenCV库,用于图像处理
# 从指定路径加载图片
img = cv2.imread('./girl.png') # 确保路径正确,加载的图片将存储在img变量中
# 将彩色图片转换为灰度图
# 灰度图只包含亮度信息,不包含颜色信息,处理起来更快,也更容易进行边缘检测等操作
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 使用自适应阈值化方法对灰度图进行处理
# cv2.adaptiveThreshold函数用于自适应阈值化,它根据图像局部区域的像素值来确定阈值
img_adaptive = cv2.adaptiveThreshold(img_gray, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 15, 1)
# 显示原始图片和自适应阈值化后的图片
cv2.imshow('img', img) # 显示原始彩色图片
cv2.imshow('img_adaptive', img_adaptive) # 显示自适应阈值化后的图片,只有黑白两种颜色
# 等待按键事件,按任意键后关闭所有窗口
cv2.waitKey(0)
二、形态学转换
2.1 腐蚀函数
腐蚀(Erosion)是形态学操作中的一种基本技术,用于对图像进行处理,尤其是在二值图像中。腐蚀操作通过"侵蚀"图像中的前景像素(通常是白色,像素值为255),使其变得更小,背景(通常是黑色,像素值为0)扩展,常用于消除小的噪声点或填补小的孔洞。
腐蚀的基本原理
腐蚀操作基于结构元素(kernel)的形态学计算。在腐蚀操作中,结构元素会在图像上滑动,并在每个位置与图像的邻域进行运算。具体来说,对于结构元素中的每个位置,它会检查该位置覆盖的图像区域。如果结构元素的所有像素与图像区域的像素匹配,那么中心像素被保留;否则,中心像素会被腐蚀(设为背景像素值,通常为0)。
腐蚀的效果是:
- 图像中的白色区域(前景)会变小。
- 图像中的黑色区域(背景)会扩展。
- 边缘细节可能会丢失。
数学表达
腐蚀操作的数学表示为:
其中:
- I(x,y)是输入图像。
- S 是结构元素。
- Ierosion(x,y) 是腐蚀后的图像。
这个公式表示,对于结构元素 S 中的每个像素位置 (m,n),它与输入图像的对应位置像素进行比较,并选择最小值。通常,最小值是背景值(0),这就是腐蚀的效果。
函数原型:
python
cv2.erode(src, kernel, iterations=1)- src:输入图像,通常是二值图像。
- kernel:结构元素,用于腐蚀操作。结构元素是一个小的矩阵(通常是 3x3 或 5x5),表示腐蚀操作时的邻域范围。
- iterations:腐蚀操作的次数。默认是 1,表示进行一次腐蚀操作。如果设置为更大的值,会进行多次腐蚀。
示例:
python
import cv2 # 导入OpenCV库,用于图像处理
import numpy as np # 导入NumPy库,虽然在这段代码中未直接使用,但常用于图像处理中的数组操作
# 注意:这里应该使用cv2.IMREAD_GRAYSCALE来确保加载的是灰度图,
# 因为腐蚀操作通常应用于二值化或灰度图像。如果'ball.png'是彩色图像,
# 则此处的img_binary实际上是一个彩色图像,这可能不是您想要的结果。
# 如果要处理二值图像,请确保先对图像进行二值化处理。
img_binary = cv2.imread('ball.png', cv2.IMREAD_GRAYSCALE) # 从指定路径加载灰度图像
# 创建一个结构元素(核),用于腐蚀操作
# 这里使用的是椭圆形结构元素,大小为9x9
# 结构元素的大小和形状会影响腐蚀操作的结果
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (9, 9))
# 使用腐蚀操作处理图像
# 腐蚀操作会"削减"图像中的白色区域(或前景对象)的边界
# 这可以用于去除小的白色噪点、断开连接的对象等
img_erode = cv2.erode(img_binary, kernel)
# 显示原始二值图像和腐蚀后的图像
# 注意:如果img_binary不是真正的二值图像(即只包含0和255的像素值),
# 那么显示时可能会看到灰度级别的差异。但在这里,我们假设它是二值化的。
cv2.imshow('img_binary', img_binary) # 显示原始二值图像
cv2.imshow('img_erode', img_erode) # 显示腐蚀后的图像
# 等待按键事件,按任意键后关闭所有窗口
cv2.waitKey(0)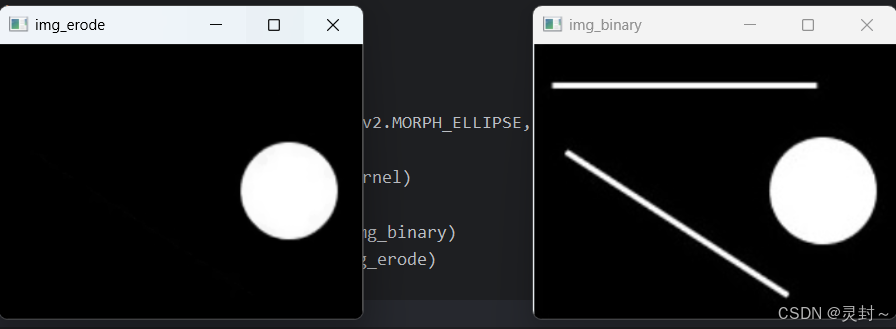
2.2 膨胀函数
膨胀(Dilation)是形态学操作中的一种基本操作,通常用于对图像中的前景(通常为白色像素,值为 255)进行扩展,使其变大。膨胀操作将图像中的白色区域(前景)扩展,同时使图像中的黑色区域(背景)缩小。膨胀操作是腐蚀操作的对立面。
膨胀的基本原理
膨胀操作基于结构元素(kernel)。膨胀时,结构元素会在图像上滑动,并与图像的每个局部区域进行比较。如果结构元素中的任意位置与图像的像素匹配,则中心像素会被设置为前景像素(通常为 255),否则会保持原样。膨胀的效果是:图像中的白色区域变大,黑色区域变小。
数学表达
膨胀操作的数学表达式为:
其中:
- I(x,y) 是输入图像。
- S 是结构元素。
- Idilated(x,y) 是膨胀后的图像。
这个公式表示,对于结构元素 S 中的每个像素位置 (m,n),它与输入图像的对应位置像素进行比较,并选择最大值。通常,最大值是前景值(255),这就是膨胀的效果。
函数原型 :
python
cv2.dilate(src, kernel, iterations=1)- src:输入图像,通常是二值图像。
- kernel:结构元素,用于膨胀操作。结构元素是一个小的矩阵(通常是 3x3 或 5x5),表示膨胀操作时的邻域范围。
- iterations:膨胀操作的次数。默认是 1,表示进行一次膨胀操作。如果设置为更大的值,会进行多次膨胀。
示例:
python
import cv2 # 导入OpenCV库,用于图像处理
# 从指定路径加载图像
# 注意:这里没有指定加载为灰度图像,所以img将是一个彩色图像(BGR格式)
img = cv2.imread("ball.png")
# 创建一个结构元素(核),用于腐蚀和膨胀操作
# 这里使用的是椭圆形结构元素,大小为9x9
# 结构元素的大小和形状会影响腐蚀和膨胀操作的结果
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (9, 9))
# 使用腐蚀操作处理图像
# 腐蚀操作会"削减"图像中的前景对象的边界
# 这可以用于去除小的白色噪点、断开连接的对象等
img_erode = cv2.erode(img, kernel)
# 使用膨胀操作处理腐蚀后的图像
# 膨胀操作会"增长"图像中的前景对象的边界
# 这可以用于填充小的黑色空洞、连接分离的对象等
# 在这里,它可能用于部分恢复由腐蚀操作去除的细节
img_erode_dilate = cv2.dilate(img_erode, kernel)
# 显示原始图像、腐蚀后的图像和腐蚀后膨胀的图像
cv2.imshow("img", img) # 显示原始彩色图像
cv2.imshow("img_erode", img_erode) # 显示腐蚀后的图像,前景对象边界被削减
cv2.imshow("img_erode_dilate", img_erode_dilate) # 显示腐蚀后膨胀的图像,部分恢复前景对象边界
# 等待按键事件,按任意键后关闭所有窗口
cv2.waitKey(0)
三、图像旋转
3.1 仿射变换函数
仿射变换(Affine Transformation)是一种常用的图像变换操作,能够执行平移、旋转、缩放、剪切等几何操作。仿射变换保持图像中的平行线和直线的相对位置不变,但可能改变图像的大小、方向等。通常,仿射变换通过一个 2×3 的变换矩阵来描述。
仿射变换的数学原理
仿射变换可以通过一个 2×3 的矩阵来表示,对于图像中的一个点 (x,y)(x, y)(x,y),经过仿射变换后,新位置为 (x′,y′)(x', y')(x′,y′):
其中:
- a,b,c,d 是仿射变换矩阵的系数,用于控制图像的旋转、缩放、剪切等。
- tx,ty是平移参数。
- x′,y′ 是变换后的坐标,x,yx, yx,y 是原图像的坐标。
仿射变换可以进行:
- 平移(Translation):沿 xxx 和 yyy 方向移动图像。
- 旋转(Rotation):绕原点旋转图像。
- 缩放(Scaling):放大或缩小图像。
- 剪切(Shearing):使图像倾斜。
仿射变换函数(OpenCV)
在 OpenCV 中,仿射变换可以通过以下两个函数实现:
cv2.getAffineTransform():根据原图和目标图像中的三个点来计算仿射变换矩阵。cv2.warpAffine():使用变换矩阵对图像进行仿射变换。
cv2.getAffineTransform() 函数
cv2.getAffineTransform() 用于计算仿射变换矩阵,基于两个三对对应点。
函数原型:
python
cv2.getAffineTransform(srcPoints, dstPoints)- srcPoints:源图像中的三个点的坐标。
- dstPoints:目标图像中的三个点的坐标。
该函数返回一个 2x3 的仿射变换矩阵。
cv2.warpAffine() 函数
cv2.warpAffine() 用于对图像进行仿射变换,接受一个仿射变换矩阵和图像。
函数原型:
python
cv2.warpAffine(src, M, dsize)- src:输入图像。
- M:仿射变换矩阵(2x3)。
- dsize:输出图像的大小 (宽, 高)。
示例:
python
import cv2
import numpy as np
# 读取图像
image = cv2.imread('flower.png')
# 1. 平移变换
# 设置平移矩阵 tx=100, ty=50
M_translation = np.float32([[1, 0, 100], [0, 1, 50]]) # 平移矩阵
rows, cols, _ = image.shape
translated_image = cv2.warpAffine(image, M_translation, (cols, rows))
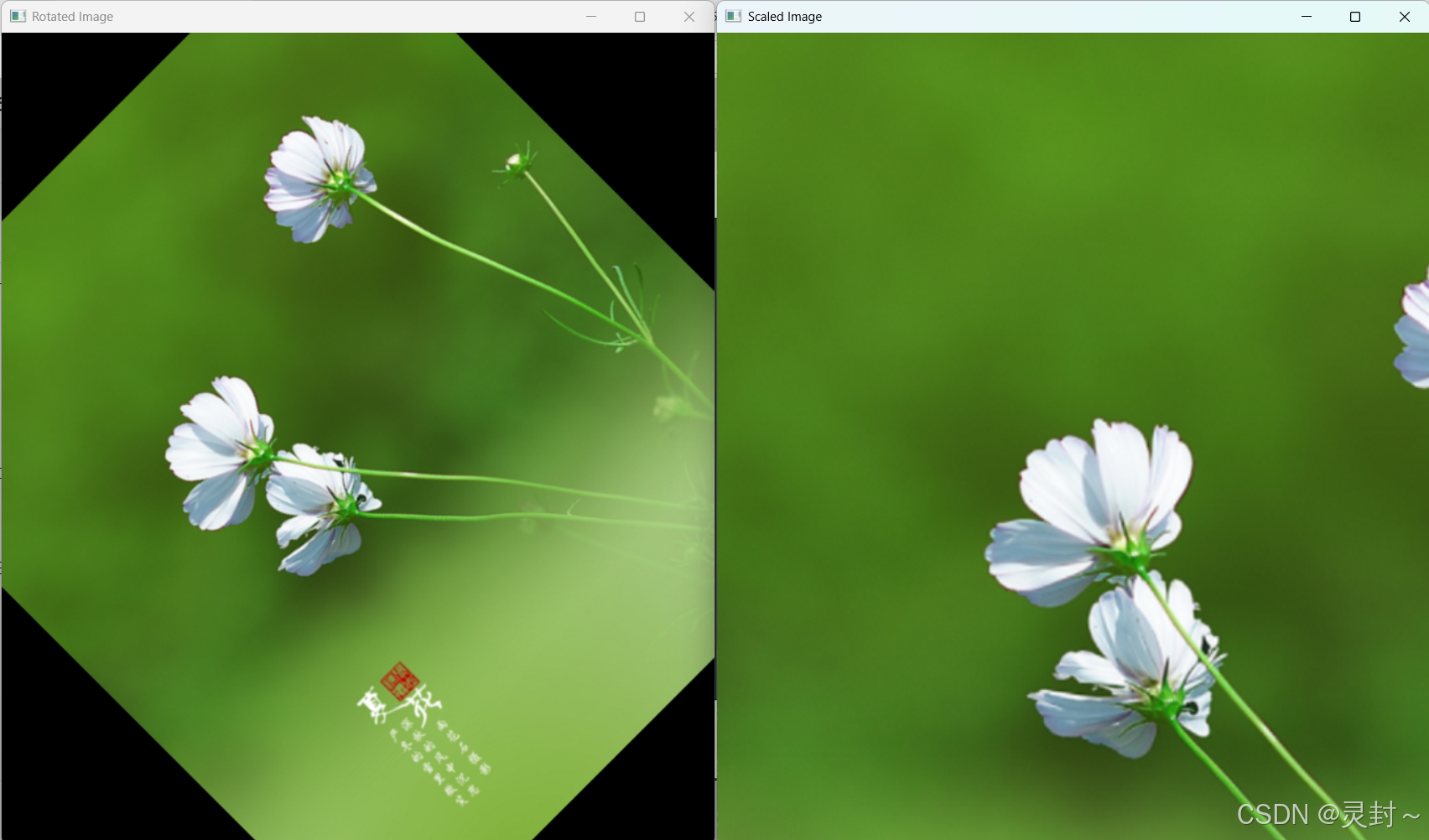
# 2. 旋转变换
# 计算图像中心
center = (cols // 2, rows // 2)
# 生成旋转矩阵,旋转 45 度,不缩放
M_rotation = cv2.getRotationMatrix2D(center, 45, 1)
rotated_image = cv2.warpAffine(image, M_rotation, (cols, rows))
# 3. 缩放变换
M_scaling = np.float32([[1.5, 0, 0], [0, 1.5, 0]]) # 缩放矩阵
scaled_image = cv2.warpAffine(image, M_scaling, (cols, rows))
# 显示结果
cv2.imshow('Original Image', image)
cv2.imshow('Translated Image', translated_image)
cv2.imshow('Rotated Image', rotated_image)
cv2.imshow('Scaled Image', scaled_image)
cv2.waitKey(0)
cv2.destroyAllWindows()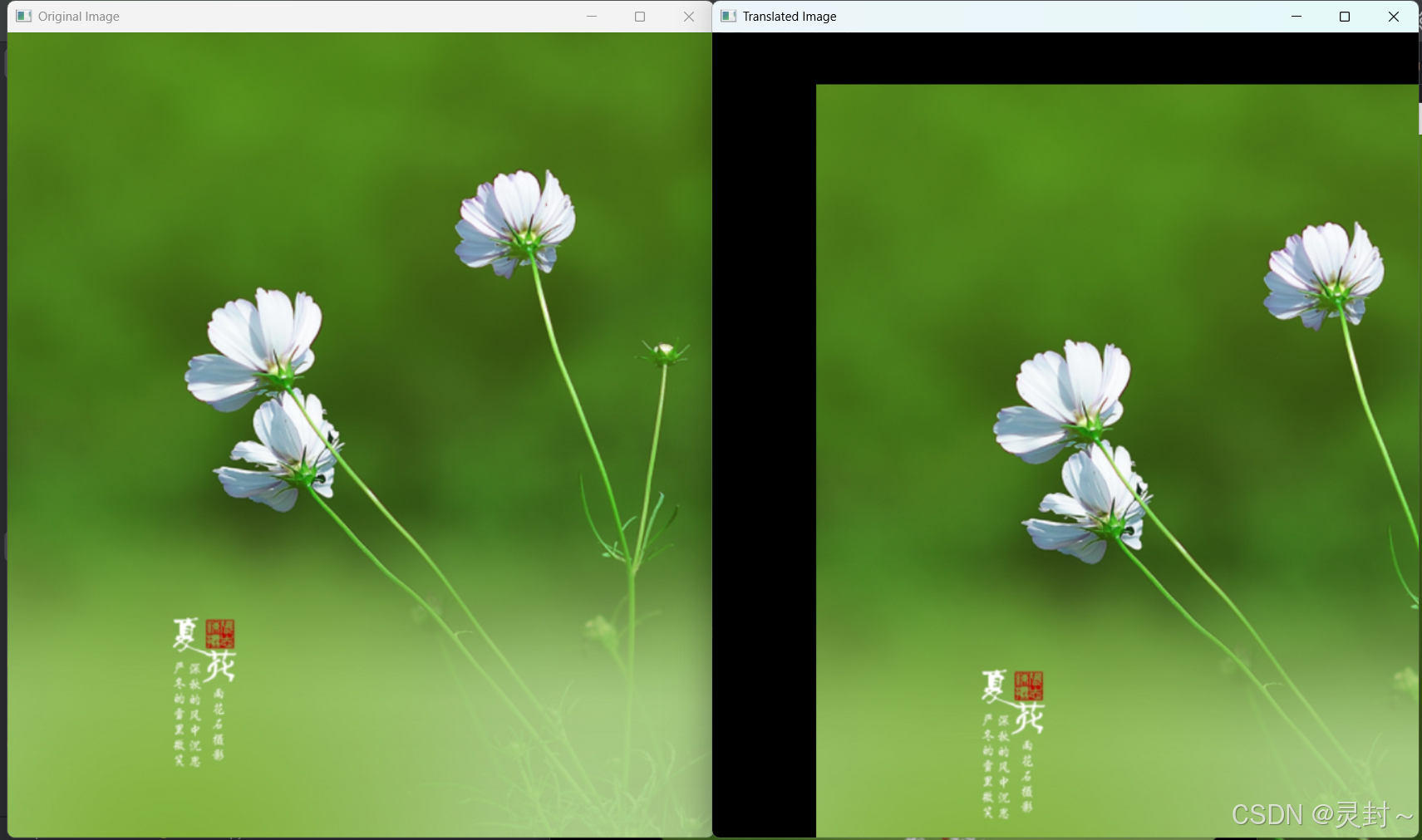
3.2 透视变换函数
透视变换(Perspective Transformation)是一种常见的图像变换,它可以将图像从一个平面投影变换到另一个平面,通常用于修复或改变图像中的视角。这种变换能够模拟从不同角度观看物体的效果,通常用于矫正图像中的透视畸变,例如将倾斜的矩形图像转换为正矩形。
透视变换的数学原理
透视变换通常使用一个 3x3 的矩阵 来表示。该矩阵将二维空间中的点从一个坐标系映射到另一个坐标系。与仿射变换不同,透视变换允许图像进行投影变换,因此它能够模拟从不同视角观察物体的效果。
透视变换的数学公式如下:
其中:
- (x,y) 是输入图像中的点坐标。
- (x′,y′)是变换后的点坐标。
- h1,h2,...,h9 是透视变换矩阵的元素。
- w′是齐次坐标,用于使得变换能够处理无穷远的点。
透视变换可以处理图像的倾斜、旋转、拉伸、缩放等复杂的变换。
透视变换函数(OpenCV)
在 OpenCV 中,透视变换可以通过以下两个主要函数来实现:
cv2.getPerspectiveTransform():根据输入图像和输出图像中的四个对应点计算透视变换矩阵。cv2.warpPerspective():使用计算出的透视变换矩阵对图像进行透视变换。
cv2.getPerspectiveTransform() 函数
cv2.getPerspectiveTransform() 函数计算透视变换矩阵,需要输入两个四点集合:源图像中的四个点和目标图像中的四个点。
函数原型:
python
cv2.getPerspectiveTransform(srcPoints, dstPoints)- srcPoints:源图像中的四个点的坐标。
- dstPoints:目标图像中的四个点的坐标。
返回值是一个 3x3 的透视变换矩阵。
cv2.warpPerspective() 函数
cv2.warpPerspective() 用于应用透视变换矩阵,变换图像。
函数原型:
python
cv2.warpPerspective(src, M, dsize)- src:输入图像。
- M:透视变换矩阵(3x3)。
- dsize :输出图像的大小
(width, height)。
示例:
python
import cv2 # 导入OpenCV库,用于图像处理
import numpy as np # 导入NumPy库,用于进行高效的数值计算
# 读取图片文件,'./card.png'为图片的路径,结果存储在变量img中
img = cv2.imread('./card.png')
# 定义源图像中的四个点,这四个点将用于定义透视变换的源四边形
# 这些点的坐标是手动指定的,需要根据具体的图像内容进行调整
points1 = np.array([[200,100],[700,150],[140,400],[650,460]],dtype=np.float32)
# 定义目标图像中的四个点,这四个点将用于定义透视变换后的目标四边形
# 在这里,目标四边形被设置为图像的整个边界,即图像的四个角
points2 = np.array([[0,0],[img.shape[1],0],[0,img.shape[0]],[img.shape[1],img.shape[0]]],dtype=np.float32)
# 使用cv2.getPerspectiveTransform函数计算透视变换矩阵
# 该函数需要源点和目标点的坐标作为输入,输出一个3x3的变换矩阵
matrix = cv2.getPerspectiveTransform(points1,points2)
# 使用cv2.warpPerspective函数应用透视变换
# 该函数需要原始图像、变换矩阵和输出图像的尺寸作为输入
# 输出图像是应用了透视变换后的图像
img_output = cv2.warpPerspective(img, matrix, (img.shape[1], img.shape[0]))
# 显示原始图像
cv2.imshow('img', img)
# 显示应用了透视变换后的图像
cv2.imshow('img_output', img_output)
# 等待用户按键操作,参数0表示无限等待
cv2.waitKey(0)