文章目录
- [一. Series](#一. Series)
-
- [1. 创建](#1. 创建)
-
- [① 创建 Series:使用Python列表,元组,字典创建](#① 创建 Series:使用Python列表,元组,字典创建)
- [② 创建Series:通过index参数,指定行索引](#② 创建Series:通过index参数,指定行索引)
- [③ 获取Series:通过loc,从DataFrame中获取](#③ 获取Series:通过loc,从DataFrame中获取)
- [2. Series常用属性](#2. Series常用属性)
-
- [① 获取行索引](#① 获取行索引)
- [② 获取值](#② 获取值)
- [③ 其他属性](#③ 其他属性)
- [3. Series常用方法](#3. Series常用方法)
-
- [① value_counts():返回不同值的条目数量](#① value_counts():返回不同值的条目数量)
- [② count():返回有多少非空值](#② count():返回有多少非空值)
- [③ describe():打印描述信息](#③ describe():打印描述信息)
- [④ info(),head(),tail(),len()](#④ info(),head(),tail(),len())
- [⑤ 其他方法](#⑤ 其他方法)
- [4. Series布尔索引](#4. Series布尔索引)
- [5. Series的运算](#5. Series的运算)
- [二. DataFrame](#二. DataFrame)
-
- [1. 创建](#1. 创建)
-
- [① 创建DataFrame:使用字典创建](#① 创建DataFrame:使用字典创建)
- [② 创建DataFrame:指定列的顺序和行索引](#② 创建DataFrame:指定列的顺序和行索引)
- [2. DataFrame常用属性](#2. DataFrame常用属性)
-
- [① 获取行索引](#① 获取行索引)
- [② 获取值](#② 获取值)
- [③ 其他属性](#③ 其他属性)
- [3. DataFrame常用方法](#3. DataFrame常用方法)
-
- [② count():返回有多少非空值](#② count():返回有多少非空值)
- [③ describe():打印描述信息](#③ describe():打印描述信息)
- [④ info(),head(),tail(),len()](#④ info(),head(),tail(),len())
- [⑤ 其他方法](#⑤ 其他方法)
- [4. DataFrame布尔索引](#4. DataFrame布尔索引)
- [5. DataFrame的运算](#5. DataFrame的运算)
- [6. 给行索引命名](#6. 给行索引命名)
-
- [① 通过set_index()方法设置行索引名字](#① 通过set_index()方法设置行索引名字)
- [② 加载数据的时候,可以通过通过index_col参数,指定使用某一列数据作为行索引](#② 加载数据的时候,可以通过通过index_col参数,指定使用某一列数据作为行索引)
- [③ 通过reset_index()方法可以重置索引](#③ 通过reset_index()方法可以重置索引)
- [8. 修改行名和列名](#8. 修改行名和列名)
-
- [① 获取行名和列名](#① 获取行名和列名)
- [② 通过rename()方法对原有的行索引名和列名进行修改](#② 通过rename()方法对原有的行索引名和列名进行修改)
- [③ 将index 和 columns属性提取出来,修改之后,再赋值回去](#③ 将index 和 columns属性提取出来,修改之后,再赋值回去)
- [9. 添加,删除,插入列](#9. 添加,删除,插入列)
- [三. 导出和导入数据](#三. 导出和导入数据)
- DataFrame和Series是Pandas最基本的两种数据结构
- 在Pandas中,Series是一维容器,Series表示DataFrame的每一列
可以把DataFrame看作由Series对象组成的字典,其中key是列名,值是Series
Series和Python中的列表非常相似,但是它的每个元素的数据类型必须相同
一. Series
1. 创建
① 创建 Series:使用Python列表,元组,字典创建
-
列表创建
pythonimport pandas as pd s = pd.Series(['banana',42]) s0 banana 1 42 dtype: object -
元组创建
pythons = pd.Series(('banana',42)) s0 banana 1 42 dtype: object -
字典创建
pythons = pd.Series({'banana':42}) sbanana 42 dtype: int64
② 创建Series:通过index参数,指定行索引
python
s = pd.Series(['Sailiman','Male'],index=['Name','Gender'])
sName Sailiman
Gender Male
dtype: object③ 获取Series:通过loc,从DataFrame中获取
-
加载csv文件
pythondata = pd.read_csv('data/nobel_prizes.csv') data.head()
-
使用 DataFrame的loc 属性获取数据集里的一行,就会得到一个Series对象
pythonfirst_row = data.loc[0] type(first_row)pandas.core.series.Seriespythonfirst_row
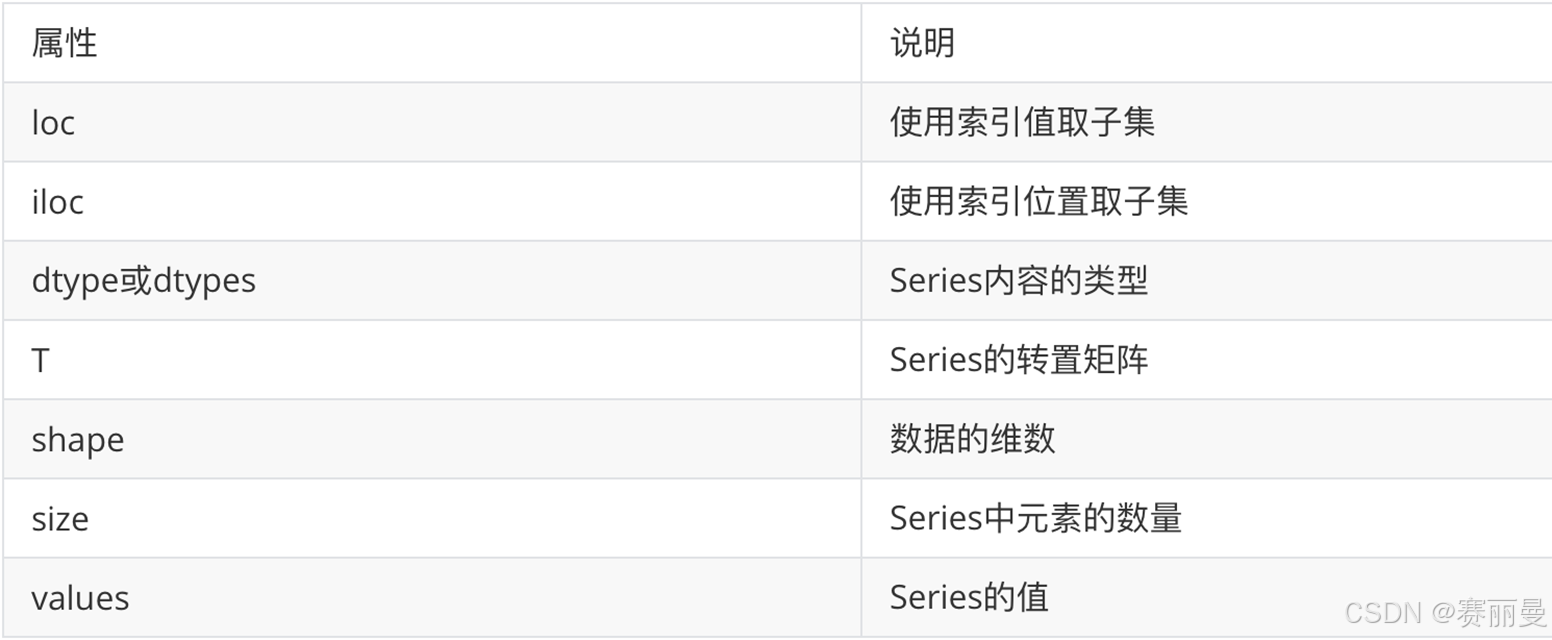
2. Series常用属性
① 获取行索引
python
first_row.index
python
first_row.keys()Index(['year', 'category', 'overallMotivation', 'id', 'firstname', 'surname',
'motivation', 'share'],
dtype='object')② 获取值
python
first_row.valuesarray([2017, 'physics', nan, 941, 'Rainer', 'Weiss',
'"for decisive contributions to the LIGO detector and the observation of gravitational waves"',
2], dtype=object)③ 其他属性
python
print(first_row.loc['year'])#2017
print(first_row.iloc[0])#2017
print(first_row.dtype)#object
print(first_row.dtypes)#object
print(first_row.loc['year'].dtype)#int64
# print(first_row.loc['year'].dtypes)#错
# print(first_row.loc['category'].dtype)#错
print(first_row.shape)#(8,)
print(first_row.size)#8,包括nan
python
print(first_row)
print('********************************')
print(first_row.T)year 2017
category physics
overallMotivation NaN
id 941
firstname Rainer
surname Weiss
motivation "for decisive contributions to the LIGO detect...
share 2
Name: 0, dtype: object
********************************
year 2017
category physics
overallMotivation NaN
id 941
firstname Rainer
surname Weiss
motivation "for decisive contributions to the LIGO detect...
share 2
Name: 0, dtype: object3. Series常用方法
① value_counts():返回不同值的条目数量
python
movie = pd.read_csv('data/movie.csv')
movie.head()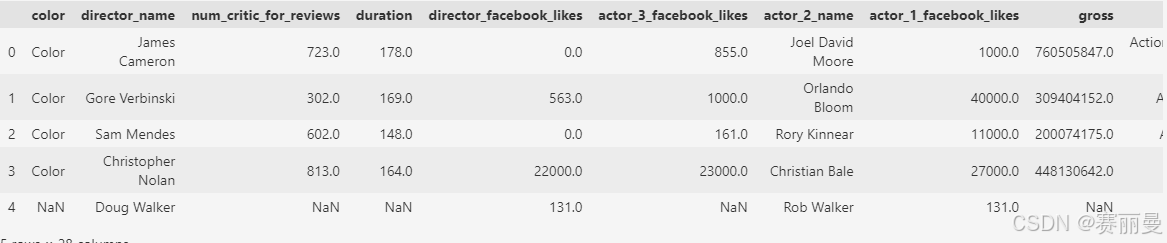
python
director = movie['director_name']
director.value_counts()Steven Spielberg 26
Woody Allen 22
Martin Scorsese 20
Clint Eastwood 20
Ridley Scott 16
..
John Putch 1
Luca Guadagnino 1
Sam Fell 1
Dan Fogelman 1
Daniel Hsia 1
Name: director_name, Length: 2397, dtype: int64② count():返回有多少非空值
python
#非空值数量
print(director.count())
#全部数据数量
print(director.shape)4814
(4916,)③ describe():打印描述信息
python
director.describe()count 4814
unique 2397
top Steven Spielberg
freq 26
Name: director_name, dtype: object
python
actor_1_fb_likes = movie.actor_1_facebook_likes
actor_1_fb_likes.describe()count 4909.000000
mean 6494.488491
std 15106.986884
min 0.000000
25% 607.000000
50% 982.000000
75% 11000.000000
max 640000.000000
Name: actor_1_facebook_likes, dtype: float64④ info(),head(),tail(),len()
python
scientists = pd.read_csv('data/scientists.csv')
scientists.head()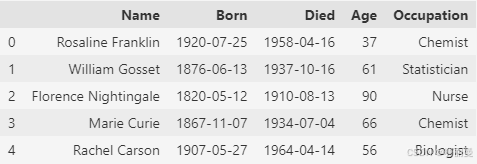
python
ages = scientists['Age']
ages.info()<class 'pandas.core.series.Series'>
RangeIndex: 8 entries, 0 to 7
Series name: Age
Non-Null Count Dtype
-------------- -----
8 non-null int64
dtypes: int64(1)
memory usage: 192.0 bytes
python
ages.head()0 37
1 61
2 90
3 66
4 56
Name: Age, dtype: int64
python
ages.tail()3 66
4 56
5 45
6 41
7 77
Name: Age, dtype: int64
python
#包含nan
len(ages)#8
len(ages+pd.Series([10,20]))#88⑤ 其他方法


python
share = data.share
print(share.mean())
print(share.max())
print(share.min())
print(share.std())1.982665222101842
4
1
0.93249522022446724. Series布尔索引
从Series中获取满足某些条件的数据,可以使用布尔索引
python
scientists = pd.read_csv('data/scientists.csv')
scientists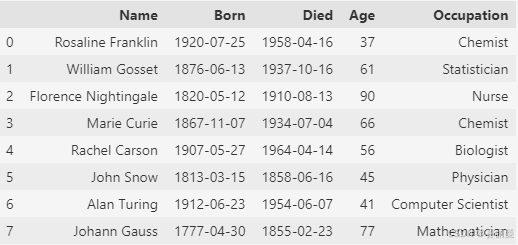
-
手动创建布尔值列表
pythonages = scientists['Age'] ages bool_values = [False,True, False, True, False,True, False, True] ages[bool_values]1 61 3 66 5 45 7 77 Name: Age, dtype: int64 -
筛选年龄大于平均年龄的科学家
pythonages>ages.mean()0 False 1 True 2 True 3 True 4 False 5 False 6 False 7 True Name: Age, dtype: boolpythonages[ages>ages.mean()]1 61 2 90 3 66 7 77 Name: Age, dtype: int64
5. Series的运算
-
Series和数值型变量计算时,变量会与Series中的每个元素逐一进行计算
pythonages+1000 137 1 161 2 190 3 166 4 156 5 145 6 141 7 177 Name: Age, dtype: int64 -
Series和数值型变量计算时,变量会与Series中的每个元素逐一进行计算
pythonages*20 74 1 122 2 180 3 132 4 112 5 90 6 82 7 154 Name: Age, dtype: int64 -
两个Series之间计算,如果Series元素个数相同,则将两个Series对应元素进行计算
pythonages+ages0 74 1 122 2 180 3 132 4 112 5 90 6 82 7 154 Name: Age, dtype: int64 -
元素个数不同的Series之间进行计算,会根据索引进行. 索引不同的元素最终计算的结果会填充成缺失值,用NaN表示
pythonages+pd.Series([10,20])0 47.0 1 81.0 2 NaN 3 NaN 4 NaN 5 NaN 6 NaN 7 NaN dtype: float64 -
Series之间进行计算时,数据会尽可能依据索引标签进行相互计算
pythonrev_ages = ages.sort_index(ascending=False) print(rev_ages)7 77 6 41 5 45 4 56 3 66 2 90 1 61 0 37 Name: Age, dtype: int64pythonages+rev_ages0 74 1 122 2 180 3 132 4 112 5 90 6 82 7 154 Name: Age, dtype: int64
二. DataFrame
1. 创建
① 创建DataFrame:使用字典创建
python
name_list = pd.DataFrame(
{
"name": ["Alice", "Bob", "Charlie", "David", "Edith"],
"age": [25, 30, 35, 40, 45],
"gender": ["F", "M", "M", "M", "F"],
}
)
name_list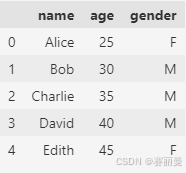
② 创建DataFrame:指定列的顺序和行索引
python
name_list = pd.DataFrame(data={'Occupation':['teacher','IT'],'Age':[28,36]},columns=['Age','Occupation'],index=['Tom','Jerry'])
name_list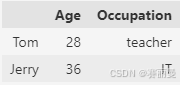
2. DataFrame常用属性
python
scientists = pd.read_csv('data/scientists.csv')
scientists.head()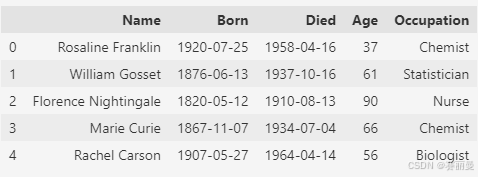
① 获取行索引
python
scientists.indexRangeIndex(start=0, stop=8, step=1)
python
scientists.keys()#列名sIndex(['Name', 'Born', 'Died', 'Age', 'Occupation'], dtype='object')② 获取值
python
movie.valuesarray([['Rosaline Franklin', '1920-07-25', '1958-04-16', 37, 'Chemist'],
['William Gosset', '1876-06-13', '1937-10-16', 61, 'Statistician'],
['Florence Nightingale', '1820-05-12', '1910-08-13', 90, 'Nurse'],
['Marie Curie', '1867-11-07', '1934-07-04', 66, 'Chemist'],
['Rachel Carson', '1907-05-27', '1964-04-14', 56, 'Biologist'],
['John Snow', '1813-03-15', '1858-06-16', 45, 'Physician'],
['Alan Turing', '1912-06-23', '1954-06-07', 41,
'Computer Scientist'],
['Johann Gauss', '1777-04-30', '1855-02-23', 77, 'Mathematician']],
dtype=object)③ 其他属性
python
print(scientists.loc[0])
print("****************")
print(scientists.iloc[0])Name Rosaline Franklin
Born 1920-07-25
Died 1958-04-16
Age 37
Occupation Chemist
Name: 0, dtype: object
****************
Name Rosaline Franklin
Born 1920-07-25
Died 1958-04-16
Age 37
Occupation Chemist
Name: 0, dtype: object
python
print(scientists.dtypes)Name object
Born object
Died object
Age int64
Occupation object
dtype: object
python
print(scientists.shape)
print(scientists.size)#包括nan(8, 5)
40
python
scientists.T
3. DataFrame常用方法
② count():返回有多少非空值
python
movie = pd.read_csv('data/movie.csv')
movie.head()
python
movie.count()color 4897
director_name 4814
num_critic_for_reviews 4867
duration 4901
director_facebook_likes 4814
actor_3_facebook_likes 4893
actor_2_name 4903
actor_1_facebook_likes 4909
gross 4054
genres 4916
actor_1_name 4909
movie_title 4916
num_voted_users 4916
cast_total_facebook_likes 4916
actor_3_name 4893
facenumber_in_poster 4903
plot_keywords 4764
movie_imdb_link 4916
num_user_for_reviews 4895
language 4904
country 4911
content_rating 4616
budget 4432
title_year 4810
actor_2_facebook_likes 4903
imdb_score 4916
aspect_ratio 4590
movie_facebook_likes 4916
dtype: int64
python
movie.shape(4916, 28)③ describe():打印描述信息
python
movie.describe()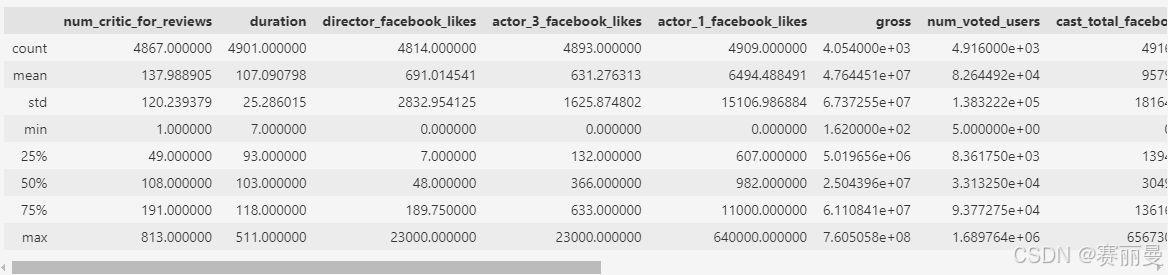
④ info(),head(),tail(),len()
python
movie.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4916 entries, 0 to 4915
Data columns (total 28 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 color 4897 non-null object
1 director_name 4814 non-null object
2 num_critic_for_reviews 4867 non-null float64
3 duration 4901 non-null float64
4 director_facebook_likes 4814 non-null float64
5 actor_3_facebook_likes 4893 non-null float64
6 actor_2_name 4903 non-null object
7 actor_1_facebook_likes 4909 non-null float64
8 gross 4054 non-null float64
9 genres 4916 non-null object
10 actor_1_name 4909 non-null object
11 movie_title 4916 non-null object
12 num_voted_users 4916 non-null int64
13 cast_total_facebook_likes 4916 non-null int64
14 actor_3_name 4893 non-null object
15 facenumber_in_poster 4903 non-null float64
16 plot_keywords 4764 non-null object
17 movie_imdb_link 4916 non-null object
18 num_user_for_reviews 4895 non-null float64
19 language 4904 non-null object
20 country 4911 non-null object
21 content_rating 4616 non-null object
22 budget 4432 non-null float64
23 title_year 4810 non-null float64
24 actor_2_facebook_likes 4903 non-null float64
25 imdb_score 4916 non-null float64
26 aspect_ratio 4590 non-null float64
27 movie_facebook_likes 4916 non-null int64
dtypes: float64(13), int64(3), object(12)
memory usage: 1.1+ MB
python
ages = scientists['Age']
ages.info()<class 'pandas.core.series.Series'>
RangeIndex: 8 entries, 0 to 7
Series name: Age
Non-Null Count Dtype
-------------- -----
8 non-null int64
dtypes: int64(1)
memory usage: 192.0 bytes
python
movie.head()
python
movie.tail()
python
print(movie.ndim)
print(len(movie))
print(movie.size)
print(movie.shape)
print("***************")
print(movie.count())2
4916
137648
(4916, 28)
***************
color 4897
director_name 4814
num_critic_for_reviews 4867
duration 4901
director_facebook_likes 4814
actor_3_facebook_likes 4893
actor_2_name 4903
actor_1_facebook_likes 4909
gross 4054
genres 4916
actor_1_name 4909
movie_title 4916
num_voted_users 4916
cast_total_facebook_likes 4916
actor_3_name 4893
facenumber_in_poster 4903
plot_keywords 4764
movie_imdb_link 4916
num_user_for_reviews 4895
language 4904
...
imdb_score 4916
aspect_ratio 4590
movie_facebook_likes 4916
dtype: int64⑤ 其他方法
python
# print(movie.mean())
print(movie.max())
# print(movie.min())
# print(movie.std())num_critic_for_reviews 813.0
duration 511.0
director_facebook_likes 23000.0
actor_3_facebook_likes 23000.0
actor_1_facebook_likes 640000.0
gross 760505847.0
genres Western
movie_title Æon Flux
num_voted_users 1689764
cast_total_facebook_likes 656730
facenumber_in_poster 43.0
movie_imdb_link http://www.imdb.com/title/tt5574490/?ref_=fn_t...
num_user_for_reviews 5060.0
budget 4200000000.0
title_year 2016.0
actor_2_facebook_likes 137000.0
imdb_score 9.5
aspect_ratio 16.0
movie_facebook_likes 349000
dtype: object
C:\Users\cong\AppData\Local\Temp\ipykernel_4880\1514917175.py:2: FutureWarning: The default value of numeric_only in DataFrame.max is deprecated. In a future version, it will default to False. In addition, specifying 'numeric_only=None' is deprecated. Select only valid columns or specify the value of numeric_only to silence this warning.
print(movie.max())4. DataFrame布尔索引
同Series一样,DataFrame也可以使用布尔索引获取数据子集。
-
使用布尔索引获取部分数据行
pythonmovie[movie['duration']>movie['duration'].mean()] movie[movie.duration>movie.duration.mean()]
-
可以传入布尔值的列表,来获取部分数据,True所对应的数据会被保留
pythonmovie.head()[[True,True,False,True,False]]
5. DataFrame的运算
python
scientists = pd.read_csv('data/scientists.csv')
scientists.head()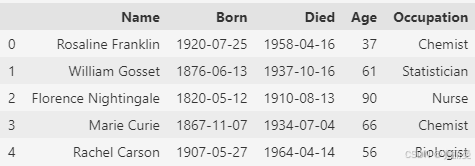
- 当DataFrame和数值进行运算时,DataFrame中的每一个元素会分别和数值进行运算
python
scientists*2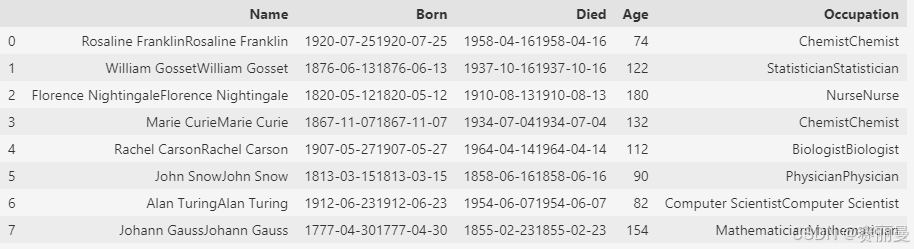
- 两个DataFrame之间进行计算,会根据索引进行对应计算
python
scientists+scientists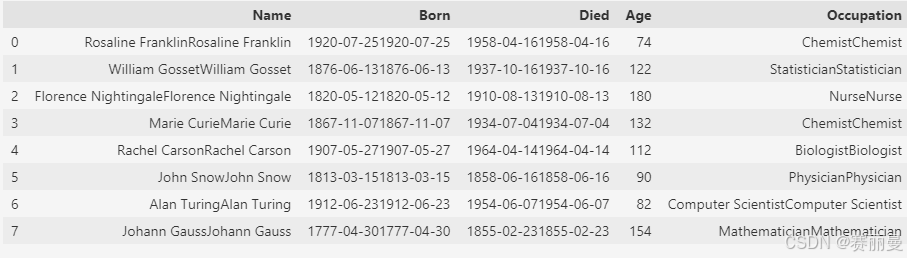
- 两个DataFrame会根据索引进行计算,索引不匹配的会返回NaN
python
half = scientists[:4]
half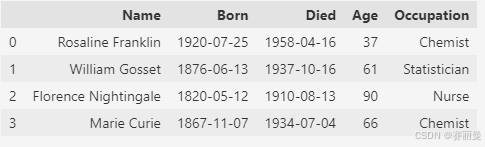
python
scientists+half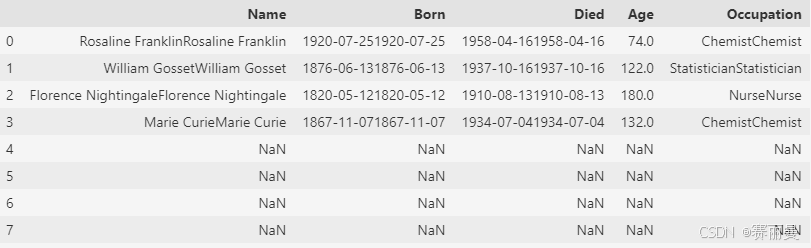
6. 给行索引命名
加载数据文件时,如果不指定行索引,Pandas会自动加上从0开始的索引
python
movie = pd.read_csv('data/movie.csv')
movie.head()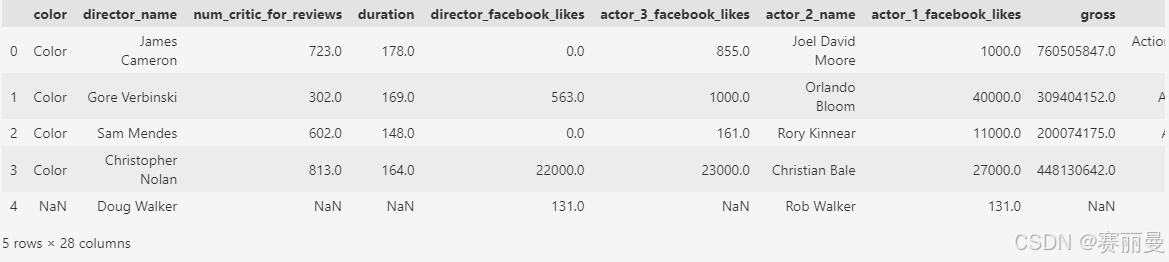
① 通过set_index()方法设置行索引名字
python
movie2 = movie.set_index('movie_title')
movie2.head()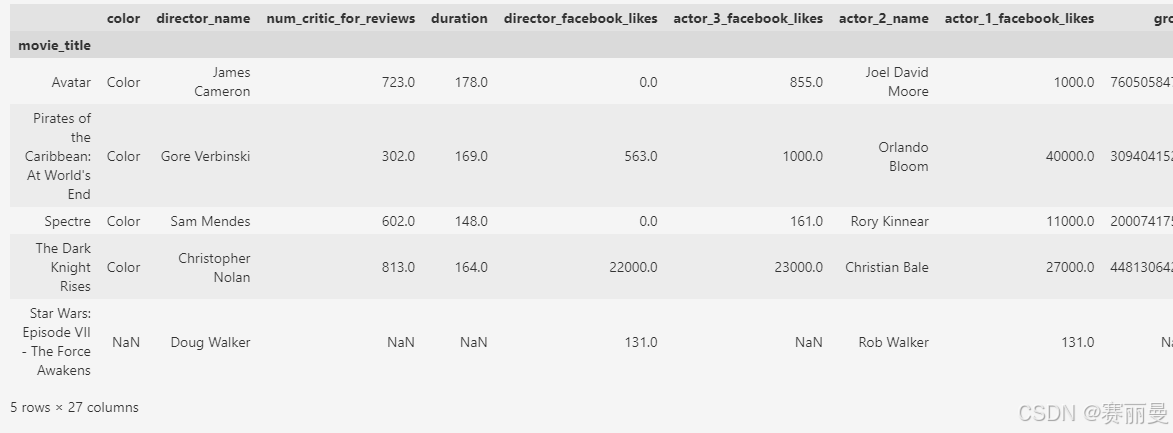
② 加载数据的时候,可以通过通过index_col参数,指定使用某一列数据作为行索引
python
movie3 = pd.read_csv('data/movie.csv',index_col="movie_title")
movie3.head()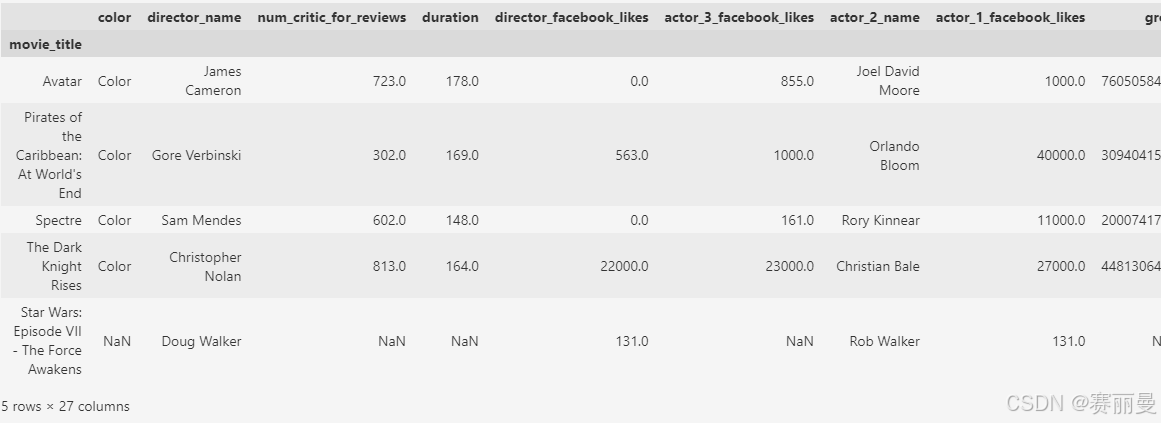
③ 通过reset_index()方法可以重置索引
python
movie4 = movie3.reset_index()
movie4.head()
8. 修改行名和列名
① 获取行名和列名
python
movie = pd.read_csv('data/movie.csv',index_col='movie_title')
movie.head()
python
movie.index[:5]Index(['Avatar', 'Pirates of the Caribbean: At World's End', 'Spectre',
'The Dark Knight Rises', 'Star Wars: Episode VII - The Force Awakens'],
dtype='object', name='movie_title')
python
movie.columns[:5]Index(['color', 'director_name', 'num_critic_for_reviews', 'duration',
'director_facebook_likes'],
dtype='object')② 通过rename()方法对原有的行索引名和列名进行修改
python
idx_rename={'Avatar':'Avatar_ID','Spectre':'Spectre_ID'}
col_rename = {'color':'color_ID'}
movie.rename(index=idx_rename,columns=col_rename).head()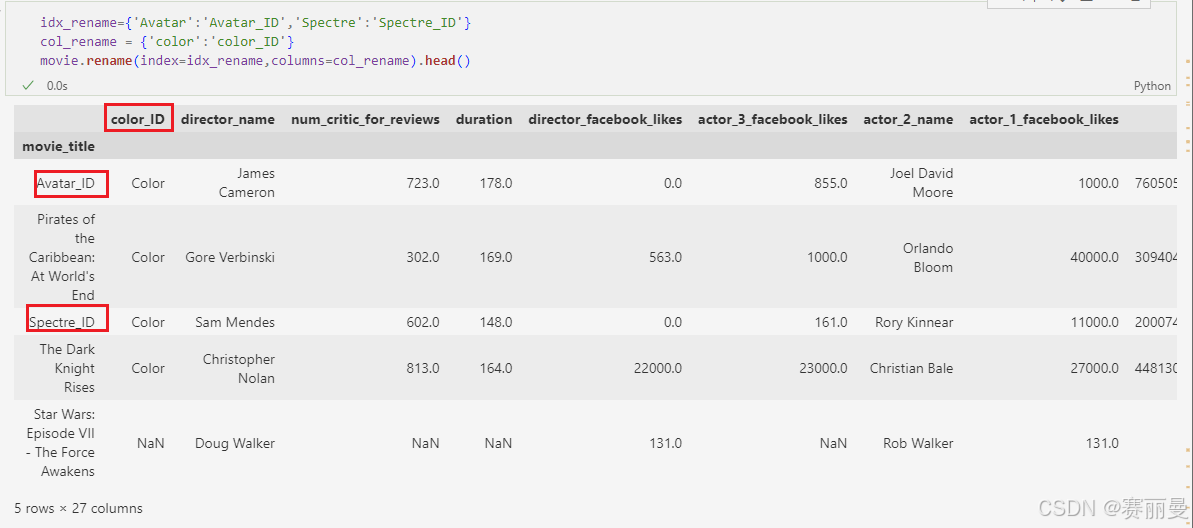
③ 将index 和 columns属性提取出来,修改之后,再赋值回去
python
index = movie.index
columns = movie.columns
index_list = index.tolist()
columns_list = columns.tolist()
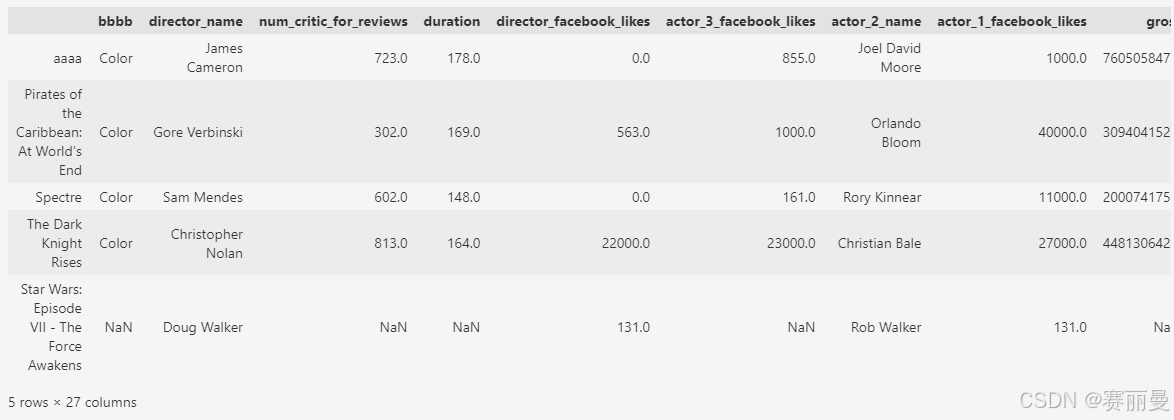
index_list[0] = 'aaaa'
columns_list[0] = 'bbbb'
movie.index = index_list
movie.columns = columns_list
movie.head()