主要介绍Pytorch分布式训练代码以及原理以及一些简易的Demo代码
模型并行 是指将一个模型的不同部分(如层或子模块)分配到不同的设备上运行。它通常用于非常大的模型,这些模型无法完整地放入单个设备的内存中。在模型并行中,数据会顺序通过各个层,即一层处理完所有数据之后再传递给下一层。这意味着,在任何时刻,只有当前正在处理的数据位于相应的设备上。
graph LR A输入数据 --> Blayer_0 B --> Clayer_1 C --> Dlayer_2 D --> E输出数据
流水线并行 是一种特殊的模型并行形式,它不仅拆分模型的不同层,还将输入数据流分为多个微批次(micro-batches)。这样可以实现多批次数据的同时处理,提高了设备利用率和训练效率。比如\(t_0\)时刻再\(layer_0\)处理\(data_0\)在\(t_1\)时刻会有\(layer_0\)处理\(data_1\)并且\(layer_1\)处理\(data_0\)
graph LR subgraph 时间点 t0 AInput data_0 --> Blayer_0 end subgraph 时间点 t1 B --> Clayer_1 DInput data_1 --> B end subgraph 时间点 t2 C --> Elayer_2 B --> Flayer_1 end subgraph 时间点 t3 E --> GOutput data_0 F --> Hlayer_2 end
数据并行 是最常用的分布式训练策略之一,它通过复制整个模型到多个设备上来实现。每个设备处理一小批数据,并在每次迭代结束时同步梯度。这种方法简单且易于实现,适用于大多数情况。
graph LR A输入数据 --> B{Split} B --> Cdevice_0: model_copy_0 B --> Ddevice_1: model_copy_1 B --> Edevice_2: model_copy_2 C --> FAll-Reduce D --> F E --> F F --> GUpdated Model
张量并行 是一种更精细的并行策略,将矩阵运算中\(x,A\)拆分,并分配到不同的设备上。这使得单个层可以在多个设备上并行执行,从而提高了训练速度。根据拆分的方式不同,可以分为列并行(Column-wise Parallelism)和行并行(Row-wise Parallelism)等。
graph LR A输入张量 X --> B{Split} B --> Cdevice_0: W_0\^T B --> Ddevice_1: W_1\^T C --> Elocal_output_0 D --> Flocal_output_1 E --> G{All-Gather/All-Reduce} F --> G G --> H最终输出
1、并行训练
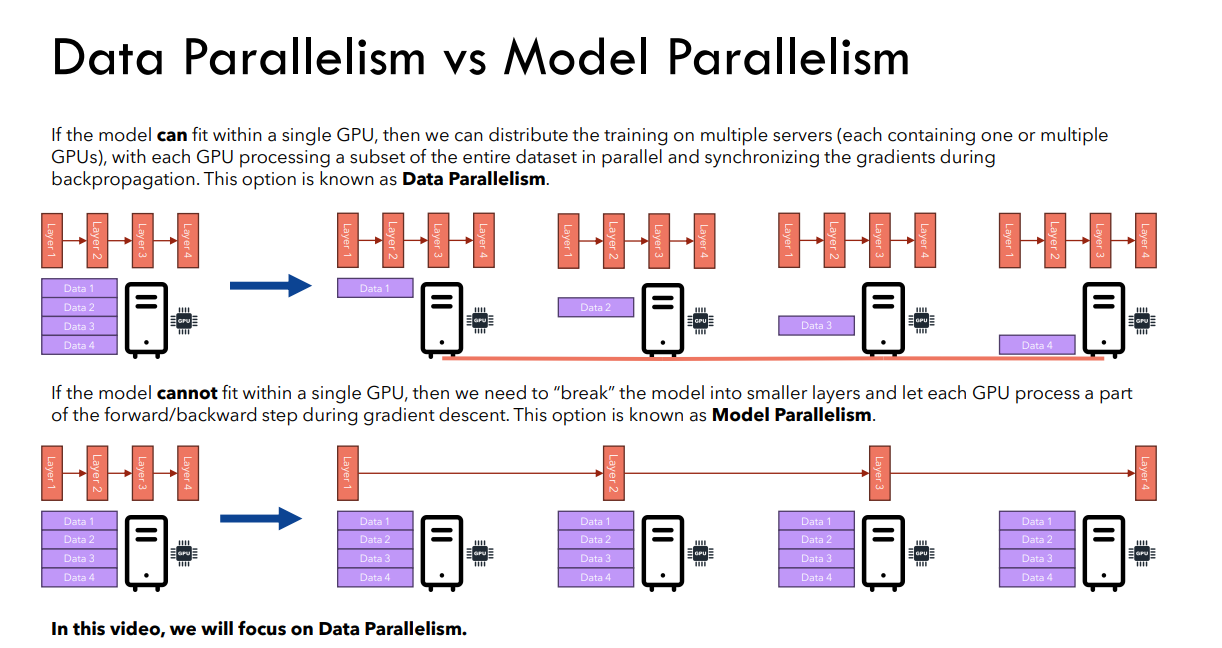
Image From : https://github.com/hkproj/pytorch-transformer-distributed
一、数据并行 (DP/DDP(主要介绍DDP))
核心思想: 将输入数据拆分成多个小批次(mini-batch),分别分配到多个设备(如 GPU)上进行计算,每个设备计算一个小批次的梯度,最后在主设备上合并梯度并更新模型参数。
- 二、模型并行*
核心思想 : 将模型的不同部分放在不同设备上,适用于模型过大无法单个设备存储的情况(如 GPT-3)。
实现方法: 1、手动将模型的不同部分分配到不同设备。2、前向传播时按设备顺序计算,反向传播时按相反顺序回传梯度。
1、数据并行
DP流程
缺点也是显而易见:
- 1、数据副本会冗余(因为要把数据先复制,然后进行分布);
- 2、前向传递前在 GPU 上复制模型(由于模型参数是在主 GPU 上更新的,因此必须在每次前向传递开始时重新同步模型);
- 3、GPU 利用率不均衡(损失计算在主 GPU 上进行,在主 GPU 上进行梯度降低和参数更新
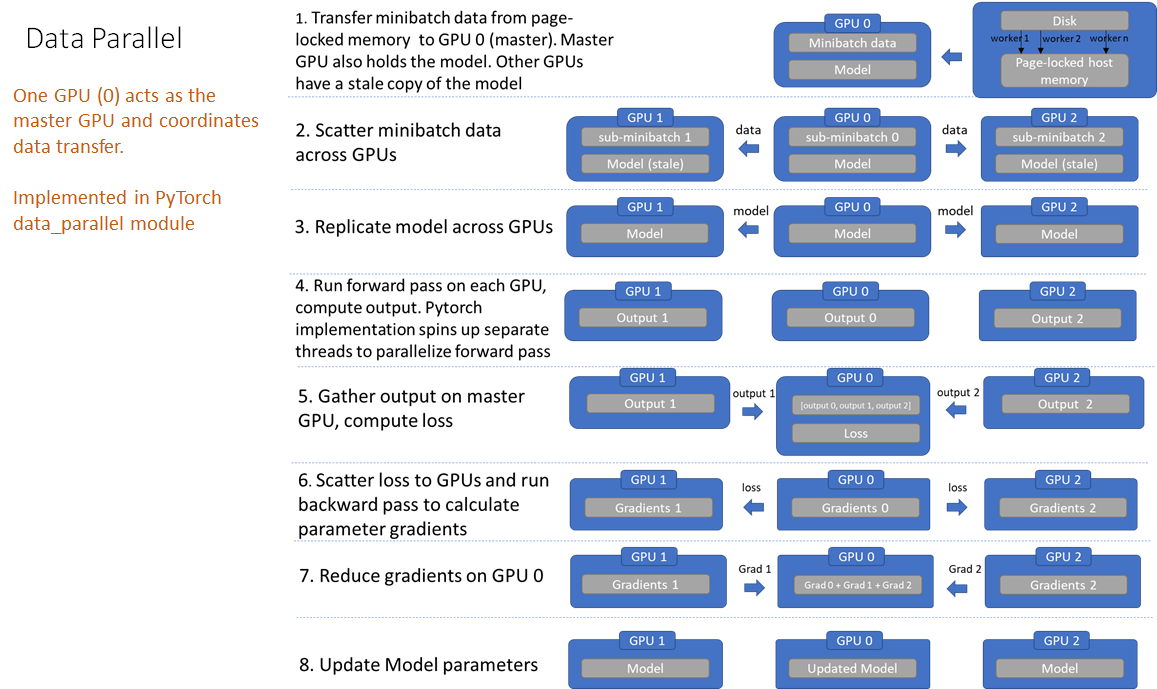
DDP流程
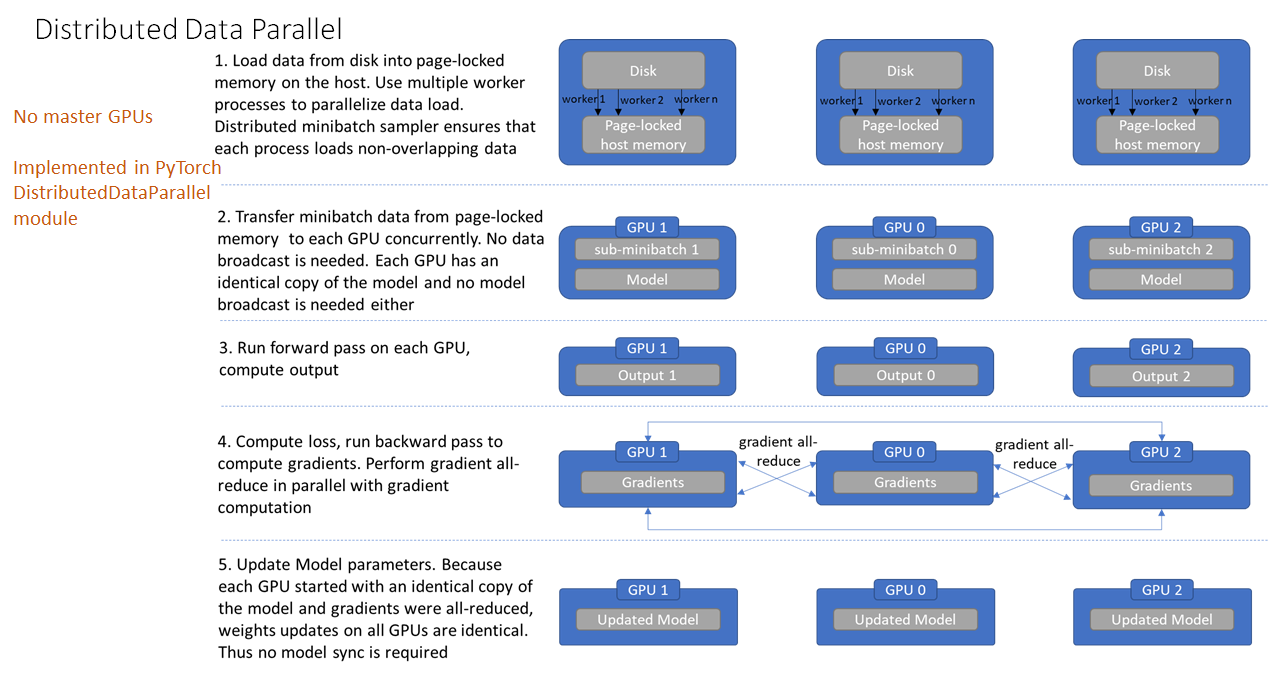
对比
DP和DDP1、
DP是一种集中-分发机制(优化器/梯度计算都是再master进程上处理好之后,然后分发到不同的进程中)2、
DDP是一种独立-运行机制(每个进程都有自己的优化器,并且在计算梯度过程中:各进程需要将梯度进行汇总规约到主进程,主进程用梯度来更新模型权重,然后其broadcast模型到所有进程(其他GPU)进行下一步训练)
Image From : https://www.telesens.co/2019/04/04/distributed-data-parallel-training-using-pytorch-on-aws/
整体流程:
1、加载模型阶段 。每个GPU都拥有模型的一个副本,所以不需要拷贝模型。rank为0的进程会将网络初始化参数broadcast到其它每个进程中,确保每个进程中的模型都拥有一样的初始化值。
2、加载数据阶段 。DDP 不需要广播数据,而是使用多进程并行加载数据。在 host 之上,每个worker进程都会把自己负责的数据从硬盘加载到 page-locked memory。DistributedSampler 保证每个进程加载到的数据是彼此不重叠的。
3、前向传播阶段 。在每个GPU之上运行前向传播,计算输出。每个GPU都执行同样的训练,所以不需要有主 GPU。
4、计算损失 。在每个GPU之上计算损失。
5、反向传播阶段 。运行后向传播来计算梯度,在计算梯度同时也对梯度执行all-reduce操作。
由于数据实在不同设备上,但是是一个模型,对于梯度的计算可以:直接将不同设备之间梯度相互传播(每个设备的数据是不一样的,但是模型是相同的,这样计算梯度会不同),然后计算平均(
alll-reduce计算方法)
6、更新模型参数阶段 。因为每个GPU都从完全相同的模型开始训练,并且梯度被all-reduced,因此每个GPU在反向传播结束时最终得到平均梯度的相同副本,所有GPU上的权重更新都相同,也就不需要模型同步了。注意,在每次迭代中,模型中的Buffers 需要从rank为0的进程广播到进程组的其它进程上
DDP代码实现
pytorch中实现DDP大致流程如下:
- 1、初始化不同进程组。这里主要是使用
init_process_group进行实现 - 2、将数据/模型进行并行 。主要主要是使用
nn.parallel.DistributedDataParallel处理模型,DistributedSampler处理数据
DistributedSampler:作用是将数据集划分为多个子集,每个子集分配给一个 GPU,使每个 GPU 在训练时处理不同的样本,从而避免重复计算和数据冗余
- 3、运行完毕之后,通过
destroy_process_group()销毁进程
简易Demo如下(单机多卡):
更加详细代码:https://pytorch.org/tutorials/intermediate/ddp_tutorial.html
pythonn
import os
import datetime
import torch
import torch.nn as nn
import torch.optim as optim
import torch.distributed as dist
from torch.utils.data.distributed import DistributedSampler
from torch.utils.data import DataLoader
dist.init_process_group(backend='nccl', timeout= datetime.timedelta(minutes= 5)) # 初始化不同进程
local_rank = int(os.environ['LOCAL_RANK']) # 这里主要是设置GPU数量
device = torch.device('cuda', local_rank)
torch.cuda.set_device(device)
class Model(nn.Module):
...
def train(..):
...
def val(..):
...
def main():
# 加载数据
train_dataset = ...
val_dataset = ...
train_sampler = DistributedSampler(train_dataset) # 对数据进行采样
train_loader = DataLoader(train_dataset, batch_size=.., shuffle=False, sampler=train_sampler, num_workers=16, pin_memory=True)
val_loader = DataLoader(val_dataset, batch_size=.., shuffle=False, num_workers=16, pin_memory=True)
# 加载模型
model = Model(..)
model.to(device)
# 分布式处理模型
model = nn.parallel.DistributedDataParallel(model, device_ids=[local_rank], output_device=local_rank)
# 优化器/loss
criterion = ..
optimizer = ..
for epoch in range(epochs):
train_sampler.set_epoch(epoch)
train(..)
if dist.get_rank()== 0: # 只在主进程上做检验
val(..)
dist.barrier() # 同步所有进程
# 销毁所有进程
dist.destroy_process_group()
if __name__ == '__main__':
main()
# 运行代码
# python -m torch.distributed.launch --nproc_per_node GPU数量 train.py- 代码解释
1、dist.init_process_group(backend='nccl', timeout= datetime.timedelta(minutes= 5))
backend: 通信后端, nccl(GPU)或 gloo(CPU)init_method: 用于初始化进程通信的方法,可以是 env://、tcp://hostname:port 或 file://world_size: 参与训练的进程总数rank: 当前进程的 ID(从 0 开始),用于区分各个进程
python
# 单机多卡
dist.init_process_group(
backend='nccl', # 使用 NCCL 后端进行 GPU 通信
init_method='env://', # 使用环境变量初始化进程组
world_size=2, # 总进程数
rank=int(os.environ['LOCAL_RANK']), # 当前进程的 rank
timeout=datetime.timedelta(minutes=5) # 设置超时时间
)
# 多机多卡
dist.init_process_group(
backend='nccl', # 使用 NCCL 后端进行 GPU 通信
init_method='tcp://<MASTER_IP>:23456', # 指定 master 节点的 IP 和端口
world_size=8, # 例如 4 台机器,每台 2 卡,world_size大小为 8
rank=int(os.environ['RANK']), # 当前进程的 rank
timeout=datetime.timedelta(minutes=5) # 设置超时时间
)
# 获取本地设备和设置
local_rank = int(os.environ['LOCAL_RANK'])
device = torch.device('cuda', local_rank)
torch.cuda.set_device(device)backend
nccl:适用于 GPU 上的分布式训练,基于 NVIDIA NCCL 库,专门优化了 GPU 间的通信。通常在多 GPU 训练时使用。
gloo:适用于 CPU 或 GPU 上的分布式训练,支持多种设备间的通信。在没有 NVIDIA GPU 的环境下,可以使用 gloo 后端。
mpi:使用 MPI(Message Passing Interface)库进行分布式训练,适用于跨节点训练。
tcp:通过 TCP 进行通信,较少使用,通常用于调试
2、流水线并行
补充1: pytorch实现流水线并行
From:
1、https://pytorch.org/docs/stable/distributed.pipelining.html
2、https://pytorch.org/tutorials/intermediate/pipelining_tutorial.html
- 第一步:定义模型结构,以及初始化
python
# Pipline
import torch
import torch.nn as nn
from dataclasses import dataclass
import os
import torch.distributed as dist
from torch.distributed.pipelining import pipeline, SplitPoint, PipelineStage, ScheduleGPipe
global rank, device, pp_group, stage_index, num_stages
def init_distributed():
global rank, device, pp_group, stage_index, num_stages
# 显卡数量
rank = int(os.environ["LOCAL_RANK"])
# 训练总共进程数
world_size = int(os.environ["WORLD_SIZE"])
# 指定设备
device = torch.device(f"cuda:{rank}") if torch.cuda.is_available() else torch.device("cpu")
dist.init_process_group()
pp_group = dist.new_group()
stage_index = rank
num_stages = world_size
@dataclass
class ModelArgs:
dim: int = 512
n_layers: int = 8
n_heads: int = 8
vocab_size: int = 10000
class Transformer(nn.Module):
def __init__(self, model_args: ModelArgs):
super().__init__()
self.tok_embeddings = nn.Embedding(model_args.vocab_size, model_args.dim)
# 因为流水线并行要用到将不同的模型放到不同的显卡上,因此可以先用 ModuleDict 将不同模型分
# 为不同的层,然后分配到不同设备
self.layers = torch.nn.ModuleDict()
for layer_id in range(model_args.n_layers):
self.layers[str(layer_id)] = nn.TransformerDecoderLayer(model_args.dim, model_args.n_heads)
self.norm = nn.LayerNorm(model_args.dim)
self.output = nn.Linear(model_args.dim, model_args.vocab_size)
def forward(self, tokens: torch.Tensor):
h = self.tok_embeddings(tokens) if self.tok_embeddings else tokens
for layer in self.layers.values():
h = layer(h, h)
h = self.norm(h) if self.norm else h
output = self.output(h).clone() if self.output else h
return output- 第二步:切割模型
这里假设两张显卡,将前4层放到显卡A。后四层放到显卡B
python
def manual_model_split(model) -> PipelineStage:
if stage_index == 0:
# prepare the first stage model
for i in range(4, 8):
del model.layers[str(i)]
model.norm = None
model.output = None
elif stage_index == 1:
# prepare the second stage model
for i in range(4):
del model.layers[str(i)]
model.tok_embeddings = None
stage = PipelineStage(
model,
stage_index,
num_stages,
device,
)
return stage- 第三步:训练
python
if __name__ == "__main__":
init_distributed()
num_microbatches = 4
model_args = ModelArgs()
model = Transformer(model_args)
# Dummy data
x = torch.ones(32, 500, dtype=torch.long)
y = torch.randint(0, model_args.vocab_size, (32, 500), dtype=torch.long)
example_input_microbatch = x.chunk(num_microbatches)[0]
# Option 1: Manual model splitting
stage = manual_model_split(model)
model.to(device)
x = x.to(device)
y = y.to(device)
def tokenwise_loss_fn(outputs, targets):
loss_fn = nn.CrossEntropyLoss()
outputs = outputs.reshape(-1, model_args.vocab_size)
targets = targets.reshape(-1)
return loss_fn(outputs, targets)
schedule = ScheduleGPipe(stage, n_microbatches=num_microbatches, loss_fn=tokenwise_loss_fn)
if rank == 0:
schedule.step(x)
elif rank == 1:
losses = []
output = schedule.step(target=y, losses=losses)
print(f"losses: {losses}")
dist.destroy_process_group()
# --nproc_per_node 2 两台设备
# torchrun --nnodes 1 --nproc_per_node 2 pipelining_tutorial.py2.1 GPipe实现流水线并行: https://torchgpipe.readthedocs.io
GPipe 将一个小批量(mini-batch)分割成多个微批量(micro-batch),使设备尽可能并行工作。这就是所谓的流水线并行。基本上,流水线并行是一个小型数据并行的堆栈。当每个分区处理完一个微型批次后,可以将输出扔给下一个分区,并立即开始处理下一个微型批次。现在,分区可以重叠。
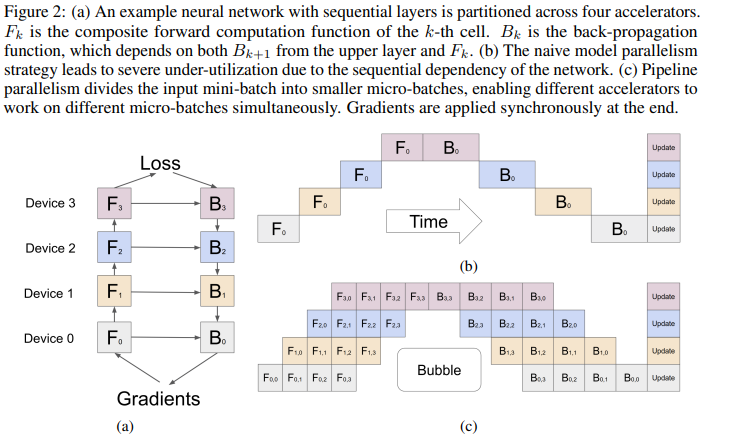
Image From: https://arxiv.org/pdf/1811.06965
上图中b、c分别表示为模型并行和流水线并行都会有一个"拆分"的处理(模型并行和流水线并行都会对模型进行拆分 ,但模型并行 主要关注模型的计算任务如何分布到不同设备,而流水线并行还结合了微批次化的数据处理,用于提升并行效率。)那么就会有存在一个问题:如何去处理梯度?(模型并行好理解,前向处理之后我直接反过来再去处理梯度即可)
对比数据并行 (From: https://www.cnblogs.com/rossiXYZ/p/15172816.html)
micro-batch 跟数据并行有高度的相似性:
- 数据并行是空间上的,数据被拆分成多个 tensor,同时喂给多个设备并行计算,然后将梯度累加在一起更新。
- micro-batch 是时间上的数据并行,数据被拆分成多个 tensor,这些 tensor 按照时序依次进入同一个设备串行计算,然后将梯度累加在一起更新。
当总的 batch size 一致,且数据并行的并行度和 micro-batch 的累加次数相等时,数据并行和 Gradient Accumulation 在数学上完全等价。Gradient Accumulation 通过多个 micro-batch的梯度累加使得下一个 micro-batch 的前向计算不需要依赖上一个 micro-batch 的反向计算,因此可以畅通无阻的进行下去(当然在一个大 batch 的最后一次 micro-batch 还是会触发这个依赖)
理解两种方式,我们假设数据数量:10,然后设备个数:5,同时假设我们也将模型分布到这5个设备上
数据并行 :每个设备会处理2个数据(10/5)
流水线并行 :因为模型分布在不同设备上(假设:\(ld_1, ld_2, ld_3, ld_4, ld_5\)),会有一个操作:将数据在拆分为不同micro-batch(这里假设为5,得到:md_1,md_2,md_3,md_4,md_5 \\(),这样一来随着前向传播:\\)t_0\\(时:\\)ld_1\\(处理\\)md_1\\(;\\)t_2\\(时:\\)(ld_1, md_2), (ld_2, md_1)\\(。对比 \*\*模型并行\*\* :假设\\)t_4\\(恰好\`流水线并行\`处理完数据,那么\\)t_0\\rightarrow t_5\\(:\\)(ld_1, (md_1...md_5))
这个过程,因为要等所有的模型处理完数据,就会不断将梯度进行累积。
梯度累计
pytorch代码:一般就是在loss.backward()(反向传播,计算当前梯度 )计算之后不去使用optimizer.step()(更新网络参数 )和optimizer.zero_grad()(清空过往梯度)
单卡训练,梯度累计代码示范:
python
for i, (images, target) in enumerate(train_loader):
# 1. input output
images = images.cuda(non_blocking=True)
target = torch.from_numpy(np.array(target)).float().cuda(non_blocking=True)
outputs = model(images) # 前向传播
loss = criterion(outputs, target) # 计算损失
# 2. backward
loss.backward() # 反向传播,计算当前梯度
# 3. update parameters of net
if ((i+1)%accumulation)==0:
# optimizer the net
optimizer.step() # 更新网络参数
optimizer.zero_grad() # reset grdient # 清空过往梯度数据并行梯度累计:
python
for i, (inputs, targets) in enumerate(data_loader):
inputs, targets = inputs.to(device), targets.to(device)
# 前向传播
outputs = model(inputs)
loss = criterion(outputs, targets) / accumulation_steps # 累计时按步数归一化
# 反向传播
loss.backward()
# 每 accumulation_steps 次更新一次参数
if (i + 1) % accumulation_steps == 0:
optimizer.step() # 更新参数
optimizer.zero_grad() # 清空梯度
# 如果最后的 mini-batch 不足以凑齐 accumulation_steps
if (i + 1) % accumulation_steps != 0:
optimizer.step()
optimizer.zero_grad()简单使用:
python
from torchgpipe import GPipe
model = nn.Sequential(a, b, c, d)
model = GPipe(model, balance=[2, 2], chunks=8)
# 1st partition: nn.Sequential(a, b) on cuda:0
# 2nd partition: nn.Sequential(c, d) on cuda:1
for input in data_loader:
output = model(input)在GPipe中会存在一个Bubbles问题(有进行任何有效工作的点)(比如说上图:\(F_{3,0}\)执行完成之前,\(F_{4,i}\)都只能等待,就会造成一个空档期)参考知乎上描述,可以通过增加microbatch来实现降低Bubbles的比例
2.2 PipeDream并行(https://zhuanlan.zhihu.com/p/617087561)
下图是PipeDream的调度图,4个GPU和8个microbatchs。蓝色的方块表示前向传播,绿色表示反向传播,数字则是microbatch的id。
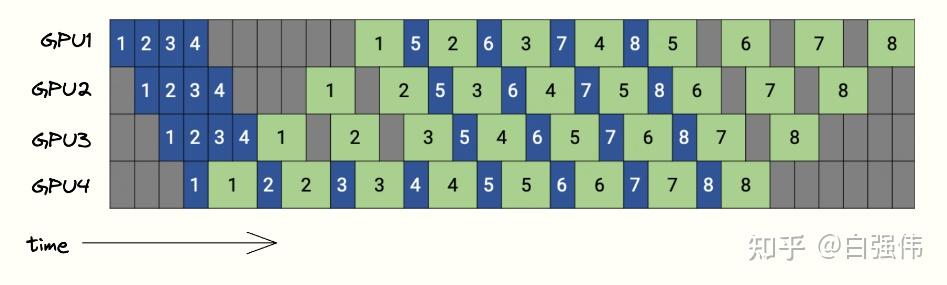
GPipe需要等所有的microbatch前向传播完成后,才会开始反向传播。PipeDream则是当一个microbatch的前向传播完成后,立即进入反向传播阶段
补充1 :gradient-checkpoint方法
是一种减少深度学习模型训练过程中显存使用的技术(用时间换内存 )。它通过在前向传播中有选择地存储部分中间激活值,并在需要反向传播时重新计算丢弃的激活值,显著降低显存占用,同时代价是额外的计算时间。
补充1.1:
内容占用:1、静态内存 :模型自身显存占用(模型的参数量);2、动态内存 :训练过程中的计算过程。
gradient-checkpoint做的就是减少动态内存占用
比如说:\(x \xrightarrow{x_1} a_1 \xrightarrow{x_2} a_2 \xrightarrow{x_3} a_3 \xrightarrow{x_4} a_4\)
\(loss=(a_4- y)^2\)那么在计算梯度过程 \(\frac{dloss}{dw_1}=2(a_4-y)w_4w_3w_2x\)
使用
gradient-checkpoint人为放弃部分中间过程值,比如说\(a_1, a_2\),如果放弃那就意味着后续在反向传播过程重新再计算\(a_1, a_2\)值即可From:https://www.bilibili.com/video/BV1nJ4m1M7Qw/?vd_source=881c4826193cfb648b5cdd0bad9f19f0
python
from torch.utils.checkpoint import checkpoint
class LargeModel1(nn.Module):
def __init__(self):
super(LargeModel1, self).__init__()
self.block1 = nn.Sequential(
nn.Linear(1024, 2048),
nn.ReLU()
)
self.block2 = ...
self.block3 = ...
def forward(self, x):
x = checkpoint(self.block1, x) # 仅存储 block1 的输入和输出
x = checkpoint(self.block2, x) # 仅存储 block2 的输入和输出
x = self.block3(x) # 最后一个 block 不使用 checkpoint
return x
'''
使用Checkpoint显存占用:2.00 MB
使用Checkpoint耗时:0.0015211105346679688 秒
不使用Checkpoint显存占用:34.77 MB
不使用Checkpoint耗时:0.0011744499206542969 秒
'''具体原理:
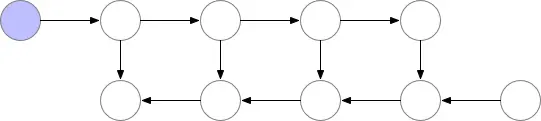
梯度检查点(gradient checkpointing) 的工作原理是从计算图中省略一些激活值(由前向传播产生,其中这里的"一些"是指可以只省略模型中的部分激活值,折中时间和空间,陈天奇在它的论文使用了如下动图的方法,即前向传播的时候存一个节点释放一个节点,空的那个等需要用的时候再backword的时候重新计算)。这减少了计算图使用的内存,降低了总体内存压力(并允许在处理过程中使用更大的批次大小)。
补充2 :数据并行+流水线并行
数据并行:将数据拆分然后分配到不同设备上
流水线并行:将模型进行拆分,然后处理所有数据
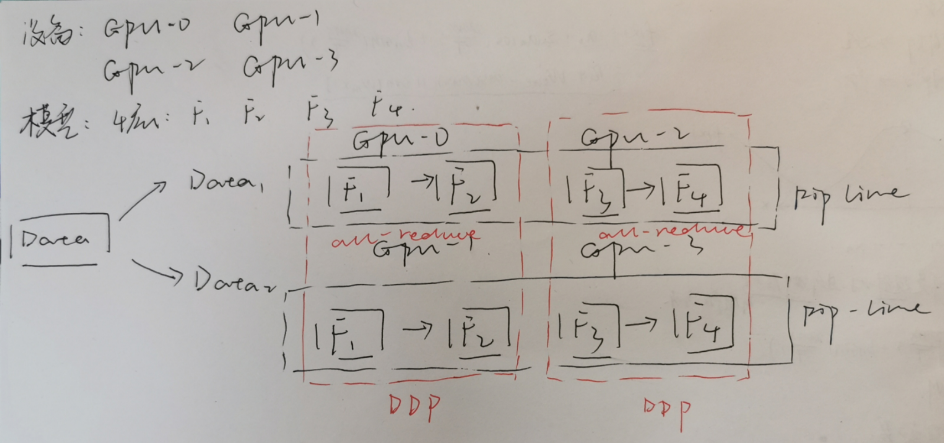
两种在"进程"上是垂直的,也就是可以叠加。比如说:假设有一个 4 层的神经网络,批量大小为 256,模型拆分为 2 个阶段,设备数量为 4。
- 第一步:假设对不同的设备分配模型(流水线并行拆分模型):
GPU 0+ GPU 1:处理第 1 和第 2 层
GPU 2+ GPU 3:处理第 3 和第 4 层
- 第二步:分配数据(数据并行分配数据),分配为2个不同的mini-batch
GPU 0+ GPU 2:处理第 1 个 mini-batch
GPU 1+ GPU 3:处理第 2 个 mini-batch
- 第三步:前向传播+ 反向传播
流水线并行过程发生在:GPU 0+ GPU 2 和 GPU 1+ GPU 3
数据并行过程发生在:GPU 0+ GPU 1 和 GPU 2+ GPU 3
python
# 数据并行+流水线并行 简单 demo
import os
import datetime
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
import torch.distributed as dist
from torch.utils.data.distributed import DistributedSampler
from torch.distributed.pipelining import PipelineStage, SplitPoint, pipeline, ScheduleGPipe
# 初始化
dist.init_process_group(backend='nccl', timeout= datetime.timedelta(minutes= 5)) # 初始化不同进程
local_rank = int(os.environ['LOCAL_RANK']) # 这里主要是设置GPU数量
device = torch.device('cuda', local_rank)
torch.cuda.set_device(device)
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.layer1 = ... # F1
self.layer2 = ... # F2
self.layer3 = ...
self.layer4 = ...
def forward(self, x):
x = self.layer1(x)
...
out = self.layer4(x)
return out
class PipeLineModel(nn.Module):
def __init__(self, model):
super(PipeLineModel, self).__init__()
self.stages = nn.ModuleList([
PipelineStage(model.layer1, device[0]),
...,
PipelineStage(model.layer1, device[3])
])
self.split_points = [SplitPoint(i) for i in range(1, len(self.stages))]
def forward(self, x):
schedule = ScheduleGPipe(self.stages, self.split_points)
return schedule(x)
def train():
...
def val():
...
def main():
train_dataset = ...
val_dataset = ...
train_sampler = DistributedSampler(train_dataset) # 对数据进行采样
train_loader = DataLoader(train_dataset, batch_size=..., shuffle=False, sampler=train_sampler, num_workers=16, pin_memory=True)
val_loader = DataLoader(val_dataset, batch_size=..., shuffle=False, num_workers=16, pin_memory=True)
model = Model()
model = PipeLineModel(model= model)
ddp_model = nn.parallel.DistributedDataParallel(model, device_ids=[local_rank], output_device=local_rank)
criterion = ...
optimizer = ...
for epoch in range(...):
train_sampler.set_epoch(epoch)
train(...)
if dist.get_rank()== 0:
val(...)
dist.barrier()
dist.destroy_process_group()
if __name__ == "__main__":
main()
# python -m torch.distributed.launch --nproc_per_node 4 train.py补充3: 流水线并行那么batch-norm如何使用?
因为data被拆分不同的micro-batch,数据小,用batch-norm不稳定,可以用SyncBatchNorm
建议还是不用正如
Gpipe中描述:But in the current implementation, it is slower than the vanilla batch normalization. That is why we turn off by default.
如果要去用全局就会导致速度上慢了(要进行同步)
https://cloud.tencent.com/developer/article/2126838
3、张量并行
张量并行是针对模型中的张量进行拆分,将其放置到不同的GPU上。张量切分方式分为按行进行切分和按列进行切分,分别对应行并行(Row Parallelism)(权重矩阵按行分割) 与列并行(Column Parallelism)(权重矩阵按列分割) 。假设计算过程为:\(y=Ax\)其中\(A\)为权重
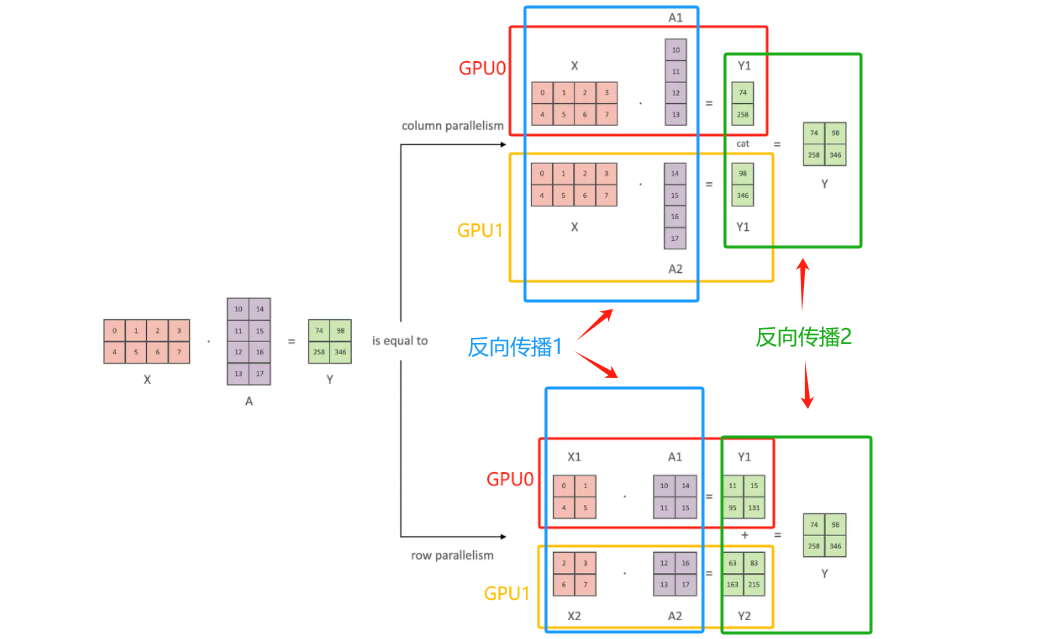
From:https://github.com/wdndev/llm_interview_note/blob/main/04.分布式训练/4.张量并行/4.张量并行.md
对于方向传播过程中梯度处理:\(y=Ax\)
代码初始化:
python
dist.init_process_group(backend='nccl', timeout=datetime.timedelta(minutes=5))
local_rank = int(os.environ['LOCAL_RANK'])
device = torch.device('cuda', local_rank)
torch.cuda.set_device(device)- 列并行
反向传播1:
\\\frac{\\partial L}{\\partial X}=\\frac{\\partial L}{\\partial X}\|_{A_1}+\\frac{\\partial L}{\\partial X}\|_{A_2} (\\text{all-reduce}) \\
反向传播2:\(Y=\text{cat}Y_1, Y_2\)
\\\frac{\\partial L}{\\partial Y_1} \\\\ \\frac{\\partial L}{\\partial Y_2} \\
python
# 列并行
class ColumnParallelLinear(nn.Module):
def __init__(self, input_size, output_size):
super(ColumnParallelLinear, self).__init__()
world_size = dist.get_world_size()
self.linear = nn.Linear(input_size, output_size // world_size) # 按列进行拆分
def forward(self, x):
local_output = self.linear(x)
# All-Gather
outputs = [torch.empty_like(local_output) for _ in range(dist.get_world_size())]
dist.all_gather(outputs, local_output)
return torch.cat(outputs, dim=-1)
def backward(self, grad_output):
# 通过All-Reduce同步梯度
dist.all_reduce(self.linear.weight.grad)
if self.linear.bias is not None:
dist.all_reduce(self.linear.bias.grad)- 行并行
反向传播1:
\\\frac{\\partial L}{\\partial X}=\[\\frac{\\partial L}{\\partial X_1}+\\frac{\\partial L}{\\partial X_2} (\text{all-gather}) \]
反向传播2:\(Y= Y_1+ Y_2\)
\\\frac{\\partial L}{\\partial Y_1}= \\frac{\\partial L}{\\partial Y} \\
python
class RowParallelLinear(nn.Module):
def __init__(self, input_size, output_size):
super(RowParallelLinear, self).__init__()
# 获取当前分布式环境中的进程总数(world size)和当前进程的秩(rank)
world_size = dist.get_world_size()
rank = dist.get_rank()
# 设置输出大小,并初始化线性层。每个设备负责一部分输入特征到所有输出特征的映射
self.output_size = output_size
self.linear = nn.Linear(input_size // world_size, output_size, bias=False)
# 初始化权重矩阵
with torch.no_grad():
# 创建一个完整的权重矩阵,并使用 Kaiming 均匀分布进行初始化
full_weight = torch.empty(input_size, output_size)
nn.init.kaiming_uniform_(full_weight, a=math.sqrt(5))
# 将权重矩阵按行分割成多个部分,每个部分对应一个设备
weight_chunks = list(full_weight.chunk(world_size, dim=0))
# 将对应的权重部分复制到当前设备上的线性层中
self.linear.weight.data.copy_(weight_chunks[rank])
# 如果有偏置项,则也需要按行分割并广播给所有进程
if self.linear.bias is not None:
with torch.no_grad():
# 将偏置项按行分割
bias_chunks = list(self.linear.bias.chunk(world_size, dim=0))
# 将对应的偏置部分复制到当前设备上的线性层中
self.linear.bias.data.copy_(bias_chunks[rank])
# 广播偏置到所有进程,确保所有设备上的偏置一致
dist.broadcast(self.linear.bias, src=0)
def forward(self, x):
"""
前向传播:
- 对输入张量 x 按最后一维(通常是特征维度)切片,每个设备只处理它负责的那一部分输入。
- 计算局部输出后,使用 All-Reduce 操作将所有设备的局部输出相加以获得完整的输出张量。
"""
# 对x根据设备切片
input_chunks = list(x.chunk(dist.get_world_size(), dim=-1))
local_input = input_chunks[dist.get_rank()]
local_output = self.linear(local_input)
# 使用 All-Reduce 收集所有设备的输出以获得完整的输出张量
dist.all_reduce(local_output, op=dist.ReduceOp.SUM)
return local_output
def backward(self, grad_output):
"""
反向传播:
- 在每个设备上本地计算输入梯度。
- 通过 All-Reduce 同步输入梯度、权重梯度以及偏置梯度(如果有)。
"""
# 本地计算输入梯度
local_grad_input = grad_output @ self.linear.weight.T
# 通过 All-Reduce 同步梯度
dist.all_reduce(local_grad_input)
dist.all_reduce(self.linear.weight.grad)
if self.linear.bias is not None:
dist.all_reduce(self.linear.bias.grad)参考
1、https://www.telesens.co/2019/04/04/distributed-data-parallel-training-using-pytorch-on-aws/
2、https://github.com/hkproj/pytorch-transformer-distributed
3、https://mp.weixin.qq.com/s/WdLpHfWLRvDLLxeanFduxA
4、https://torchgpipe.readthedocs.io
5、https://arxiv.org/pdf/1811.06965
6、https://www.cnblogs.com/rossiXYZ/p/15172816.html
7、https://www.bilibili.com/video/BV1nJ4m1M7Qw/?vd_source=881c4826193cfb648b5cdd0bad9f19f0