目标分割的目标是 将感兴趣的目标区域从图像背景中分离出来,并得到目标在像素级别的精确轮廓。目标分割有两种类型,一种是语义分割,一种是实例分割。
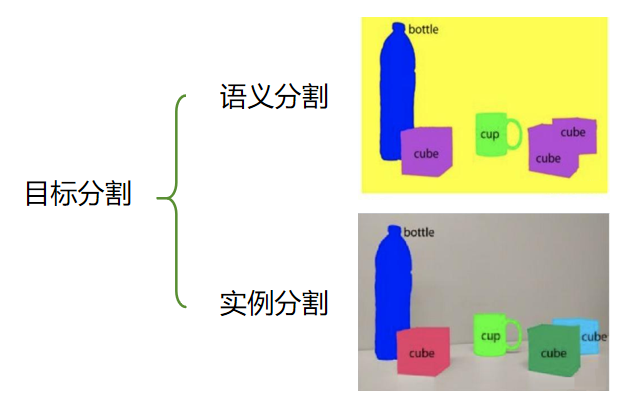
(1)语义分割(Semantic Segmentation)
-
只区分 "类别",不区分 "个体"。对图像中每个像素赋予一个类别标签(如人、车、树、背景),相同类别的不同个体被视为同一类
-
例子:在一张包含 3 个人的街景图中,语义分割会把 3 个人的所有像素都标为 "人" 类,不会区分这是第 1 个人、第 2 个人
(2)实例分割(Instance Segmentation)
-
既区分 "类别",又区分 "个体"。在语义分割的基础上,进一步为同一类别的不同个体赋予独立标签
-
例子:同样是 3 个人的街景图,实例分割会给 3 个人分别标为 "人 - 1""人 - 2""人 - 3",明确区分每个个体的像素范围
语义分割
对图像中的每一个像素进行分类,给它分配一个类别 不区分同一类里面的不同个体。
只关心像素属于哪个类别,而不是属于哪一个对象

早期思路
首先介绍一下目标分割的早期思路
将输入图像分成很多很多的小块,然后每个小块单独过神经网络,判断中线的像素属于哪类。这个方法计算复杂度会十分高,因为我们要标记图中的每个像素点。
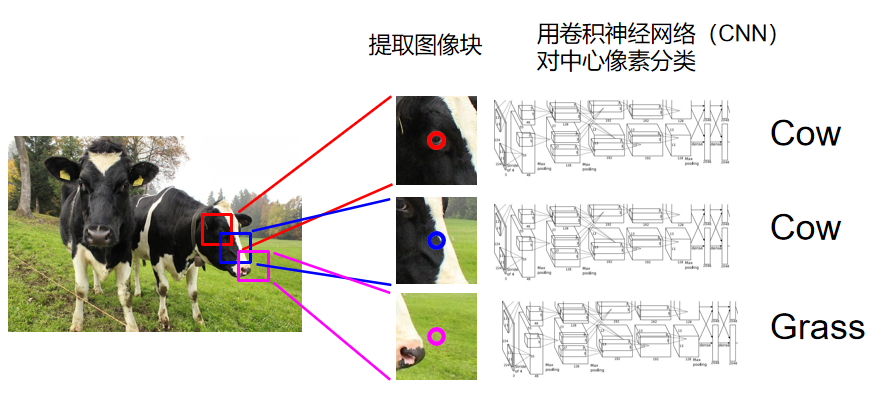
这种方法的问题是:效率极低,没有复用图像块之间的共享特征
全连接卷积网络
下一个表现更好的方法是全列检卷积网络。不同于每一个小块单独进行判断和计算,这个方法相当于很多卷积堆叠在一起。图像通过这个多层的卷积网络以后会变成一个张量,尺寸是C*H*W。其中,C是类的数量。
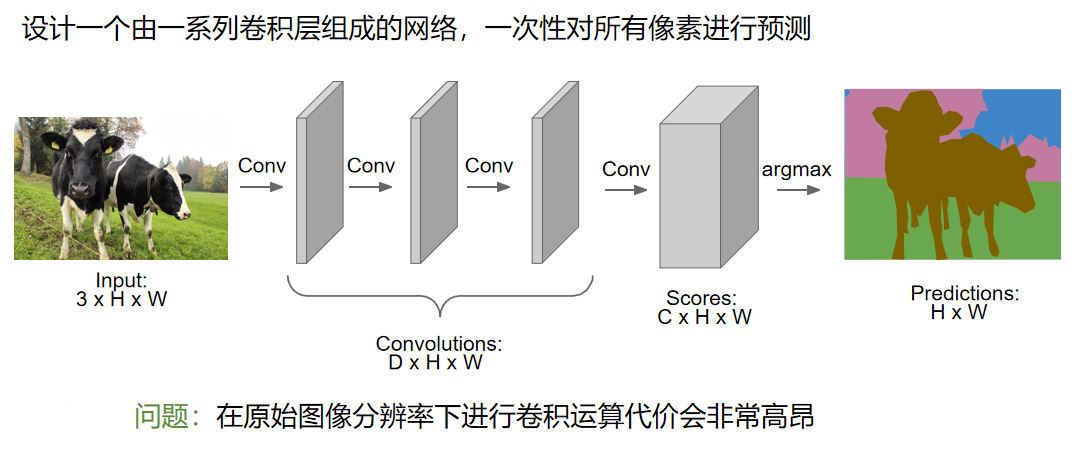
这个张量会为图像的每个像素进行分类和评分。训练这个模型,为每一个像素进行损失的训练。
问题是,当神经网络的层数过多的时候,这样的计算量依然很大。因此这个思想其实没有那么常用。
在实际上,更常见的方法如图所示。
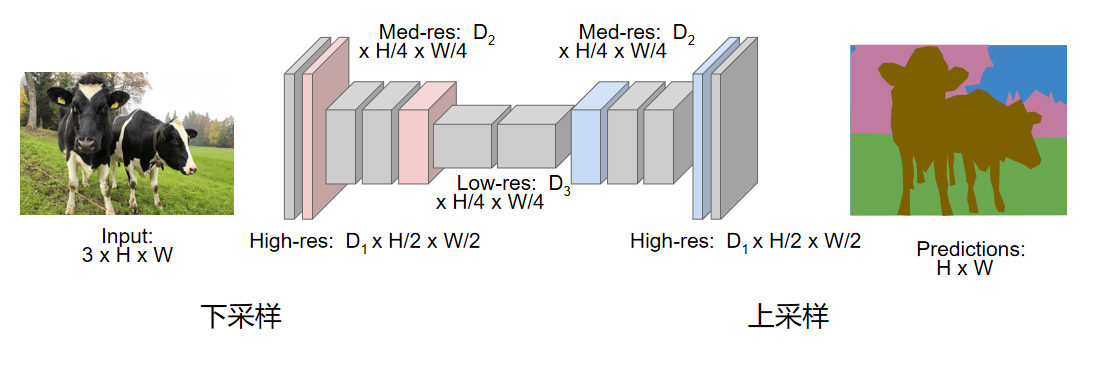
我们对图像进行下采样和上次采样。比起对整个图进行卷积,我们仅仅对一些特征图进行卷积。这很像用卷积网络分类的方法,但是不同的是,最后输出的时候并不经过全连接层,而是我们希望在后半部分的上次采样之中增加图片的清晰度。所以我们的输出可以和输入保持同样的尺寸。用这种方法,就可以很好的计算。 在之前学习CNN的过程中,我们已经讲过了基本的下采样方式和基本的池化方式。但是我们很少讨论上采样的方法。如何进行上采样呢?
反池化(Unpooling)
反池化是池化(Pooling,如最大池化、平均池化)的逆操作,池化的作用是下采样(降维、保留关键特征、减少计算量),而反池化则是通过特定规则,从池化后的低维特征图中恢复出高维特征图的空间结构。
反池化本身不是池化的严格逆运算(池化过程会丢失部分信息,比如最大池化只保留窗口内的最大值,丢弃其他像素值;平均池化会融合窗口内像素信息,无法完全还原原始数据),它的核心目的是尽可能恢复池化前的特征空间尺寸和关键细节,为后续像素级任务提供支撑。
- 最近邻插值(Nearest Neighbor): 直接把每个像素复制到更大区域
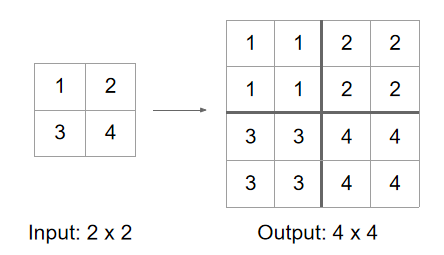
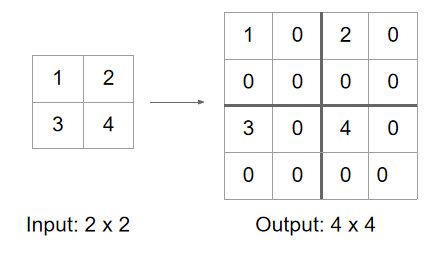
- Bed of Nails 在原位置放数值,其他位置填 0(像钉子床一样稀疏)
转置卷积(Transpose Convolution)
输入移动 1 个像素,滤波器(卷积核)在输出对应移动 2 个像素
步幅(stride)决定输出与输入移动量的比例
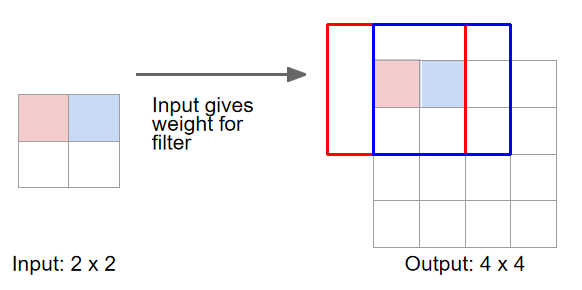
转置卷积也是一种上采样的方法。它既可以上采样特征图,也可以进行权重学习。
①这里举的例子是用3*3的卷积核做内积。我们把小方块的中心和图像最开始的元素重叠做内积,结果就是卷积的结果作为左上角的个的输出
②然后为每个像素重复这个过程直到得到最后的结果。
最大反池化(Max Unpooling)
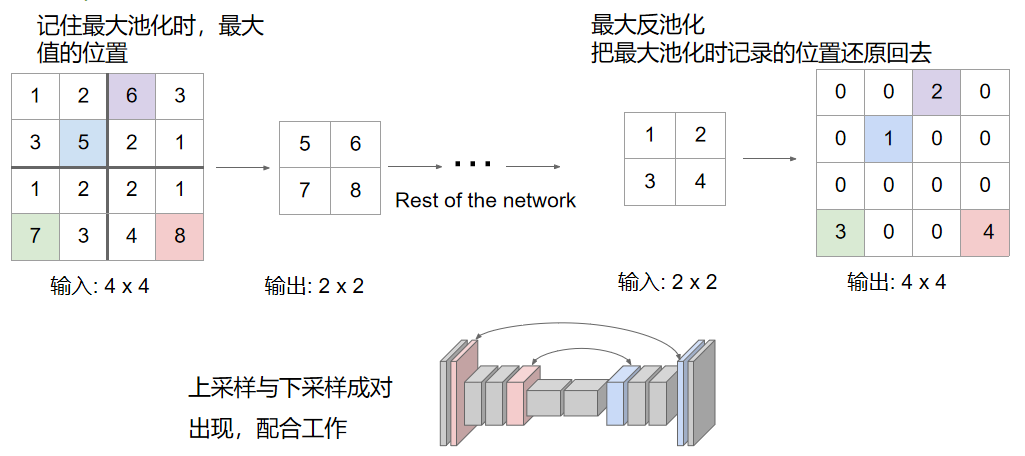
最大反池化的核心依赖 "记录位置 + 精准回填",分两步完成:
池化阶段(记录索引)
- 执行最大池化时,除输出窗口内最大值组成的低分辨率特征图外,额外记录每个最大值在池化窗口中的坐标索引(Switch Variables)。
- 例如:2×2 池化窗口中最大值在 (0,1) 位置,该索引会被同步保存。
反池化阶段(还原尺寸)
- 创建与目标高分辨率匹配的全 0 特征图。
- 将池化后的每个最大值,按记录的索引回填到对应位置,其余位置保持为 0,完成上采样。
语义分割模型
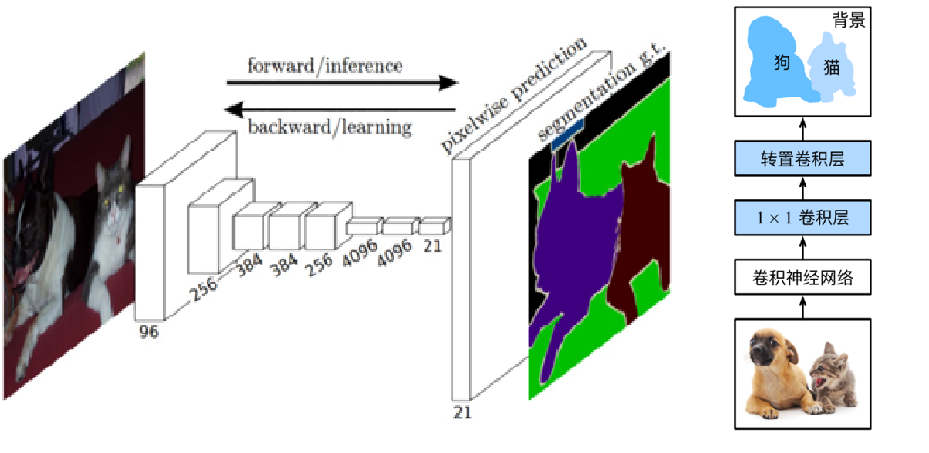
FCN(全卷积神经网络)
全卷积网络是是深度学习用于语义分割领域的开山之作。
FCN将传统CNN后面的全连接层换成了卷积层,这样网络的输出将是热力图而非类别;同时,为解决卷积和池化导致图像尺寸的变小,使用上采样方式对图像尺寸进行恢复
核心思想 不含全连接层的全卷积网络,可适应任意尺寸输入; 反卷积层增大图像尺寸,输出精细结果; 结合不同深度层结果的跳级结构,确保鲁棒性和精确性。
Unet
Unet是另一种十分常用的模型。它的本质也是:网络对每个像素点,给出"它属于哪一类"的概率。该网络结构具有编码器(Encoder)和解码器(Decoder)两个部分。UNet算法的关键创新是在解码器中引入了跳跃连接(Skip Connections),即将编码器中的特征图与解码器中对应的特征图进行连接。这种跳跃连接可以帮助解码器更好地利用不同层次的特征信息,从而提高图像分割的准确性和细节保留能力。 其优点在于:强大的分割能力、少样本学习、可扩展性。缺点是:计算资源需求较高:数据不平衡问题:对于大尺寸图像的处理存在内存不足
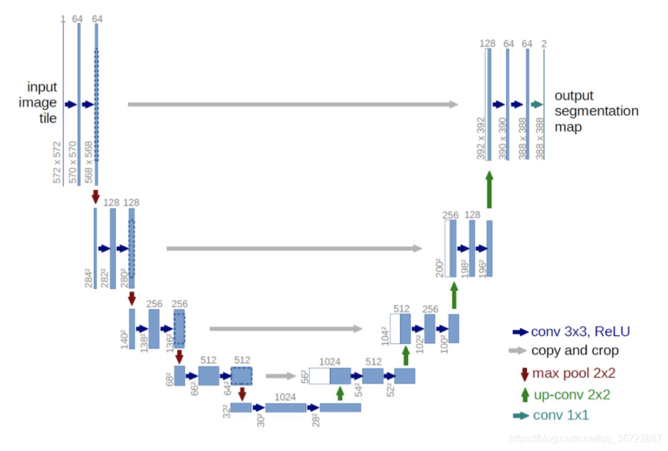
UNet算法的特点是采用了U型的网络结构,因此得名UNet。 该网络结构具有编码器(Encoder)和解码器(Decoder)两个部分。
- 编码器负责逐步提取输入图像的特征并降低空间分辨率。
- 解码器则通过上采样操作将特征图恢复到原始输入图像的尺寸,并逐步生成分割结果。
创新点:在解码器中引入了跳跃连接,帮助解码器更好地利用不同层次的特征信息,从而提高图像分割的准确性和细节保留能力。
DeepLab 系列
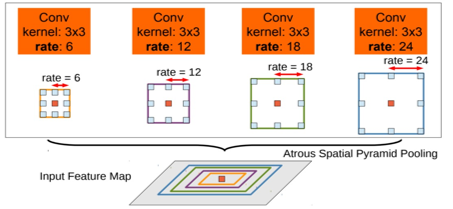
Deeplab 是谷歌在FCN的基础上搞出来的。FCN有个问题是结果就是:score map 太稀疏,上采样后分割边界模糊。Deeplab这里使用了一个非常优雅的做法:将VGG网络的pool4和pool5层的stride由原来的2改为了1,再加上 1 padding。这样的话尺寸就缩小为原本的8倍,特征图分辨率更高,预测更 dense。但是这样的话之后节点的感受野就会发生变化。
在 FCN 基础上优化 分辨率 & 感受野 的矛盾。使用空洞卷积(Atrous Convolution) 扩大感受野,同时保留分辨率
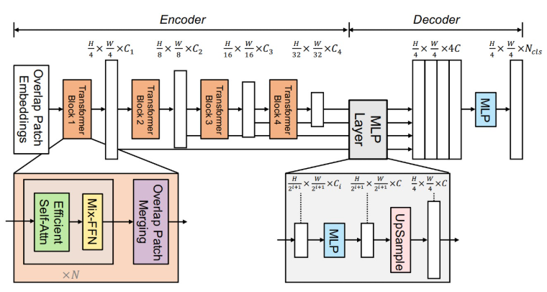
SegFormer
SegFormer则是一个基于Transformer的模型。它包含一个新颖的层次结构的Transformer编码器,它输出多尺度特征。它不需要位置编码,从而避免了位置编码的插值问题,当测试分辨率与训练不同时,导致性能下降。SegFormer避免了复杂的解码器。提出的MLP解码器从不同层级聚合信息,从而结合了局部注意力和全局注意力,以生成强大的表示。
舍弃繁琐的解码器,靠强大的 Transformer 编码器直接得到多尺度特征。
- 高效,推理速度快,特别适合实时分割。
- 核心思想:重编码、轻解码。靠 Transformer 的全局建模能力保证效果。
实例分割
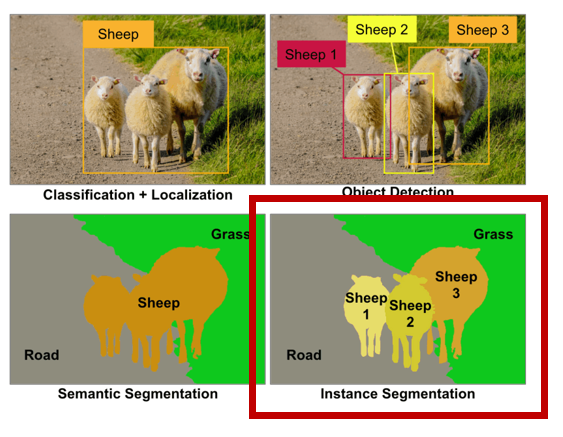
实例分割不仅需要识别出图像中的对象,还要区分对象的不同实例。实例分割师语义分割和目标检测的结合,可以看右边这个图。目标检测是左上,需要检测出不同的个体。语义分割是左下,只要区分出像素所属就行,不需要区分个体。而将他们结合就是右下,在区别类别的同时区分个体。
实例分割不仅需要识别出图像中的对象,还要区分对象的不同实例。是目标检测和语义分割的结合,它要求模型同时输出对象的类别和位置,以及对象的像素级掩码。 实例分割在应用上更注重个体的区分,如在拥挤场景下区分不同的人或物体。
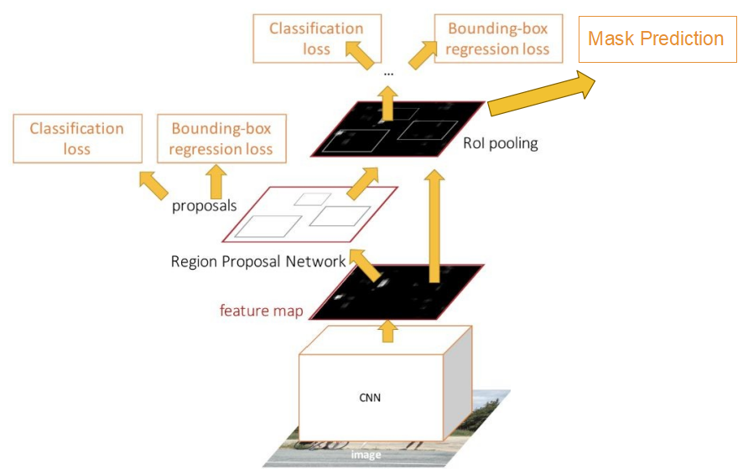
Mask R-CNN
Mask R-CNN在已有的Faster R-CNN目标检测框架上增加一个并行的分支来预测对象的掩码,从而实现像素级别的对象分割。 这个掩码分支是一个小型的全卷积网络(FCN),它应用于每个感兴趣区域(Region of Interest, RoI),以逐像素的方式预测对象的掩码。
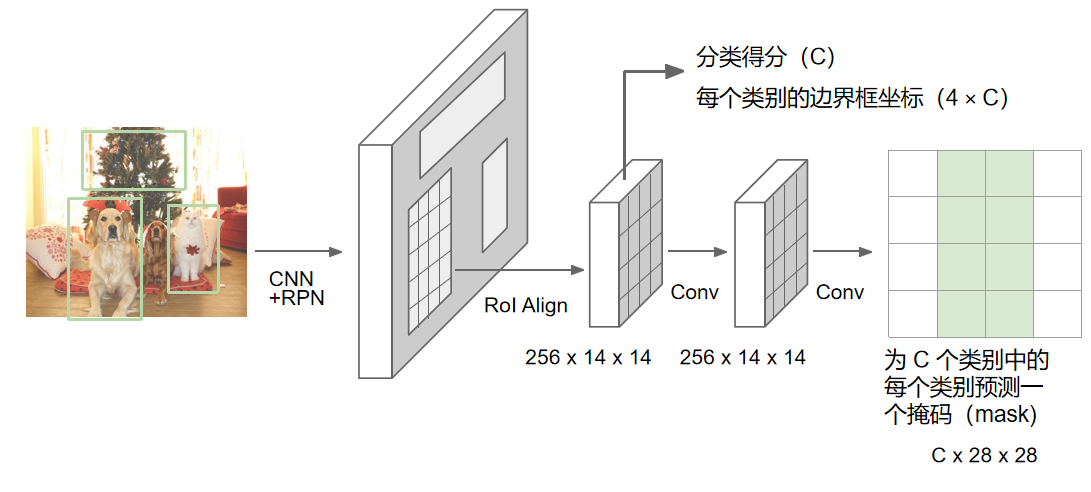
Mask R-CNN 是在 Faster R-CNN 基础上发展而来的一种实例分割方法。它首先将整张输入图像送入卷积神经网络提取特征,然后利用区域候选网络(RPN)生成一系列候选框。与 Faster R-CNN 相似,这些候选框会被映射到特征图上,并通过 RoIAlign 操作进行尺寸对齐。不同之处在于,Mask R-CNN 在此基础上并不止进行分类和边界框回归,还增加了一个并行的分割分支。具体来说,上层分支与 Faster R-CNN 类似,负责预测候选框的类别以及精确的边界框位置;而新增的下层分支则通过一个轻量级的全卷积网络,对每个候选区域内的像素逐一分类,从而生成该目标的二值掩码,实现了检测与实例级分割的统一。

单阶段实例分割方法:YOLACT
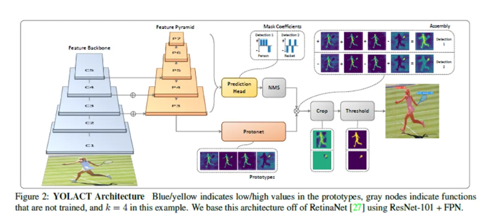
YOLACT(You Only Look At Coefficients) 是一款极具影响力的实时实例分割模型,核心优势是在保证高精度的同时实现极快的推理速度,打破了此前实例分割模型速度偏慢的瓶颈,广泛应用于对实时性要求较高的场景。
- 核心定位
-
特点:实时性优先,兼顾精度,是实时实例分割领域的标杆模型之一
-
对比:相较于 Mask R-CNN(准实时,约 5 FPS),YOLACT 推理速度提升 6 倍以上;相较于后续的 YOLACT++(YOLACT 改进版),YOLACT 更轻量、部署更便捷
- 核心创新
YOLACT 的核心突破是将实例分割任务拆解为两个并行的子任务,避免了 Mask R-CNN 那种 "先检测后分割" 的串行流程带来的延迟,实现高效推理:
-
生成通用原型掩码(Prototype Masks):一次性生成一批与类别无关的通用掩码,作为所有实例掩码的 "基础模板"。
-
预测实例系数(Instance Coefficients):为每个检测到的实例,预测一组对应的系数,通过系数与原型掩码的线性组合,快速生成该实例的专属掩码。
这种 "原型掩码 + 系数组合" 的思路,是 YOLACT 实现实时性的关键。

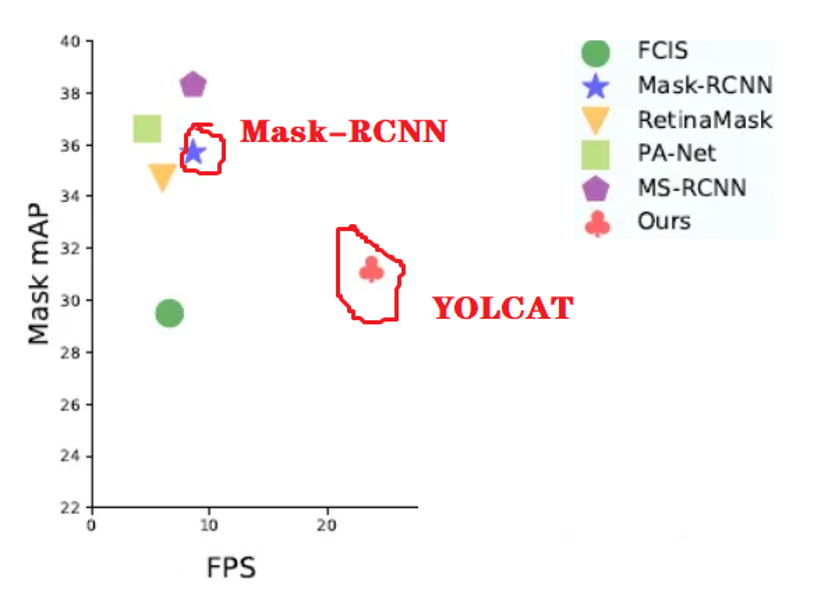
Mask - RCNN 是两阶段实例分割代表,图中它精度更高(Mask mAP 接近 36 - 38 ) ,但速度慢(FPS 约 5 - 10 ) ,适合静态图像、对精度要求极高(如医学影像分析)的场景。而 YOLACT 作为一阶段模型,通过 "原型掩码 + 系数组合" 的创新思路(简化传统分割的复杂后处理),大幅提升速度,填补了实时实例分割的需求空白。
更多模型和应用
Segment Anything(SAM)
Segment Anything是 Meta AI 在 2023 年 4 月发布的一个划时代的计算机视觉模型。其出现革新数据标注,并强大的"零样本"泛化能力,推动新一代视觉应用落地


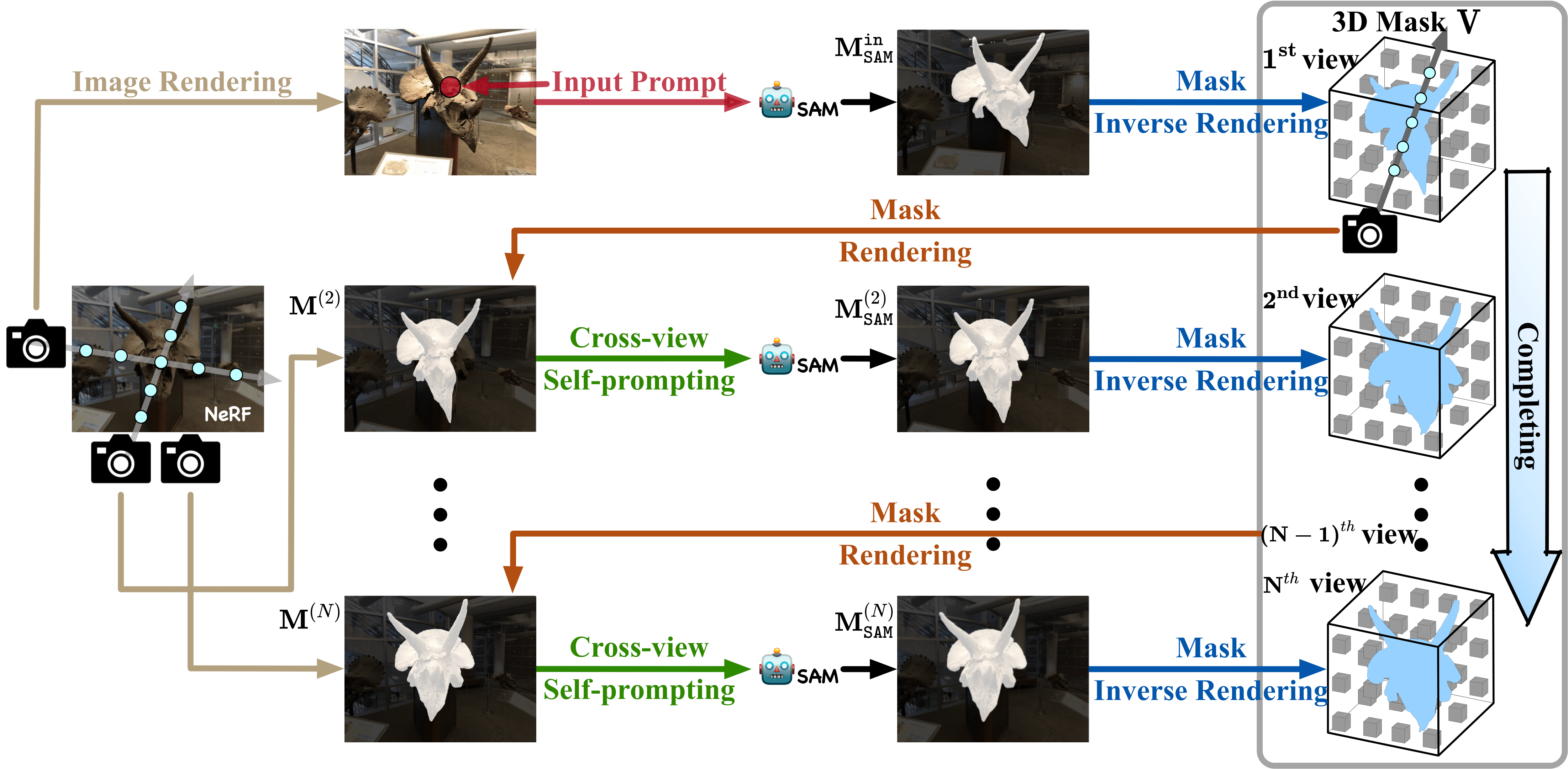
Segment Anything in 3D with NeRFs
一项三维分割任务
Segment Anything in 3D with NeRFs(SA3D)是一个基于神经辐射场(NeRF)的项目,由上海交通大学、华为和华中科技大学的研究团队开发,相关成果在 NeurIPS 2023 上发表。结合了 2D 分割基础模型 SAM 与辐射场模型(如 NeRF 和 3D Gaussian Splatting),无需重新设计或重新训练即可执行 3D 分割任务。通过 2D 分割模型的扩展,将 2D 图像信息提升到 3D 场景中,实现准确的 3D 分割。实现对场景中任意物体在 3D 空间中进行精确分割的技术


OVSeg
OVSeg由 Meta、UTAustin 的研究人员在 2023 年的计算机视觉与模式识别会议(CVPR)上提出。它旨在实现开放词汇的语义分割,即根据文本描述将图像分割成语义区域,这些区域在训练期间可能并未被看到。
OVSeg 的核心技术是基于 CLIP模型,并引入了 Mask-adapted 机制。具体来说,首先利用大规模的图像 - 文本对数据集对 CLIP 进行预训练,使其能够理解图像与文本之间的语义关系;然后通过对图像进行 Mask 处理,使得模型能够更好地聚焦于图像中的关键区域,从而提高语义分割的准确性;最后通过引入开放词汇机制,使得模型能够处理任意词汇的语义分割任务,而不仅仅局限于预定义的类别。
