论文标题:Wavelet Convolutions for Large Receptive Fields
论文原文 (Paper) :https://arxiv.org/abs/2407.05848
代码 (code) :https://github.com/BGU-CS-VIL/WTConv
GitHub 仓库链接(包含论文解读及即插即用代码) :https://github.com/AITricks/AITricks
哔哩哔哩视频讲解 :https://space.bilibili.com/57394501?spm_id_from=333.337.0.0
目录
-
-
- [1. 核心思想](#1. 核心思想)
- [2. 背景与动机](#2. 背景与动机)
-
- [2.1 文本背景总结](#2.1 文本背景总结)
- [2.2 动机图解分析](#2.2 动机图解分析)
- [3. 主要创新点](#3. 主要创新点)
- [4. 方法细节](#4. 方法细节)
-
- [4.1 整体网络架构与数据流](#4.1 整体网络架构与数据流)
- [4.2 核心模块图解分析](#4.2 核心模块图解分析)
- [4.3 理念与机制总结](#4.3 理念与机制总结)
- [4.4 图解总结:如何解决"动机"中的问题?](#4.4 图解总结:如何解决“动机”中的问题?)
- [5. 即插即用模块的作用](#5. 即插即用模块的作用)
- [6. 实验部分简单分析](#6. 实验部分简单分析)
- [7. 获取即插即用代码关注 【AI即插即用】](#7. 获取即插即用代码关注 【AI即插即用】)
-
1. 核心思想
本文提出了一种名为 WTConv (Wavelet Transform Convolution) 的新型卷积层,旨在解决卷积神经网络(CNN)难以高效获得全局感受野的问题。核心思想是利用 级联小波变换(Cascade Wavelet Transform) 将输入特征图分解为不同频率的子带,在这些降采样后的频带上执行小卷积操作,从而以 对数级(Logarithmic) 而非二次方级的参数增长,实现了接近全局的有效感受野。WTConv 可以作为现有网络(如 ConvNeXt、MobileNet)中深度卷积(Depth-wise Conv)的 即插即用 替代品,显著提升了模型的形状偏置(Shape Bias)和对图像腐蚀的鲁棒性。
2. 背景与动机
2.1 文本背景总结
在过去几年,Vision Transformers (ViTs) 凭借自注意力机制带来的全局感受野,在性能上超越了许多 CNN。为了弥补这一差距,研究者们尝试增大 CNN 的卷积核(例如 RepLKNet 中的 甚至更大)。然而,这种简单粗暴的"大核"策略面临两个严峻问题:
- 参数量爆炸:参数量随核大小 呈 二次增长。
- 性能饱和 :单纯增大核尺寸,性能在达到一定程度后不再提升,甚至下降,且仍然难以达到真正的全局感受野。
本文的动机就在于:能否利用信号处理工具(小波),在不引起参数爆炸的前提下,让卷积真正拥有全局感受野?
2.2 动机图解分析
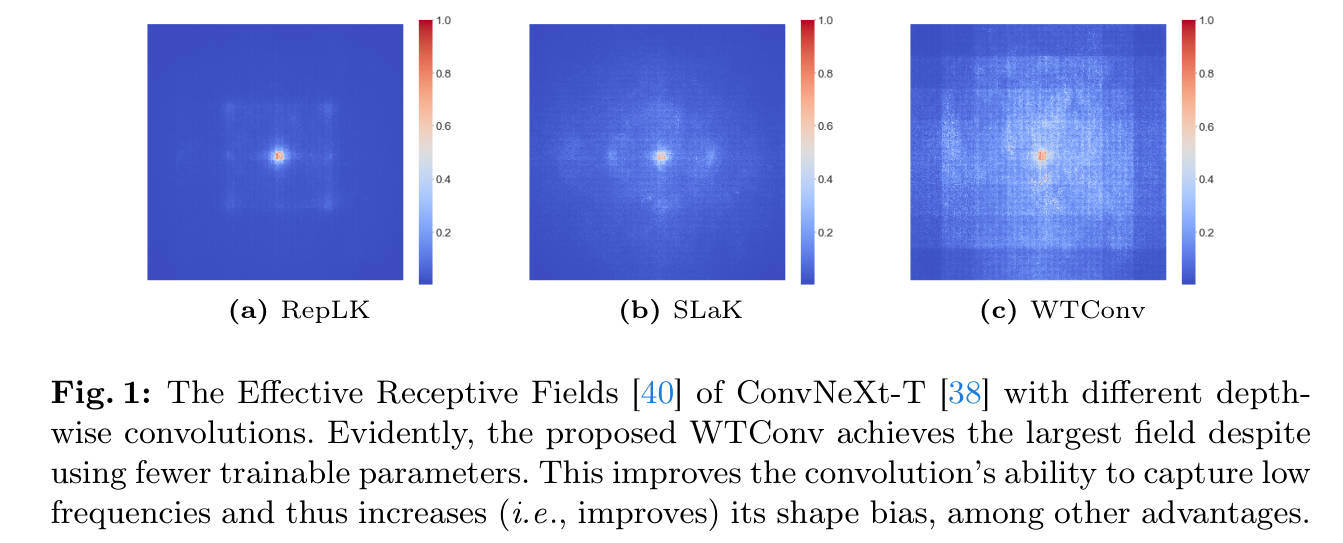
看图说话与痛点分析:
- 左图 (a) RepLK :这是使用单纯大卷积核(如 )的结果。我们可以看到,虽然中心区域亮起,但在远离中心的区域(边缘),响应非常微弱(深蓝色)。这说明即使加大了核尺寸,其实际有效感受野(ERF)依然是受限的,存在明显的局部性局限。
- 中图 (b) SLaK:这是使用稀疏大核的方法。相比 RepLK 略有改善,但依然存在明显的中心聚焦效应,未能覆盖全图。
- 右图 © WTConv (本文方法) :这是本文提出的方法。可以看到,整张特征图都呈现出明亮的响应,且分布均匀。
- 总结:这组对比图直观地揭示了现有大核方法的"效率瓶颈"------它们堆叠了大量参数却换不来真正的全局信息交互。而 WTConv 通过频域分解,用更少的参数实现了真正的全局感受野,完美解决了"大核不一定大感受野"的痛点。
3. 主要创新点
- 基于小波的卷积层 (WTConv):提出了一种利用小波变换进行多频率处理的新型层,作为深度卷积的通用替代品。
- 对数级参数增长:对于 的感受野,WTConv 的参数量增长仅为 ,而传统大核是 。这意味着你可以用极小的代价获得极大的感受野。
- 多频响应机制 :通过在低频分量上进行级联操作,WTConv 能够比标准卷积更好地捕捉图像的低频信息(通常对应物体的形状),从而增强了模型对形状的感知能力(Shape Bias)。
- 鲁棒性提升:实验证明,该方法在面对图像腐蚀、纹理失真等情况时,比传统 CNN 具有更强的鲁棒性。
4. 方法细节
4.1 整体网络架构与数据流
WTConv 的设计目标是替换深度卷积(Depth-wise Convolution)。其整体数据流遵循 "分解(WT) 卷积(Conv) 重构(IWT)" 的范式。
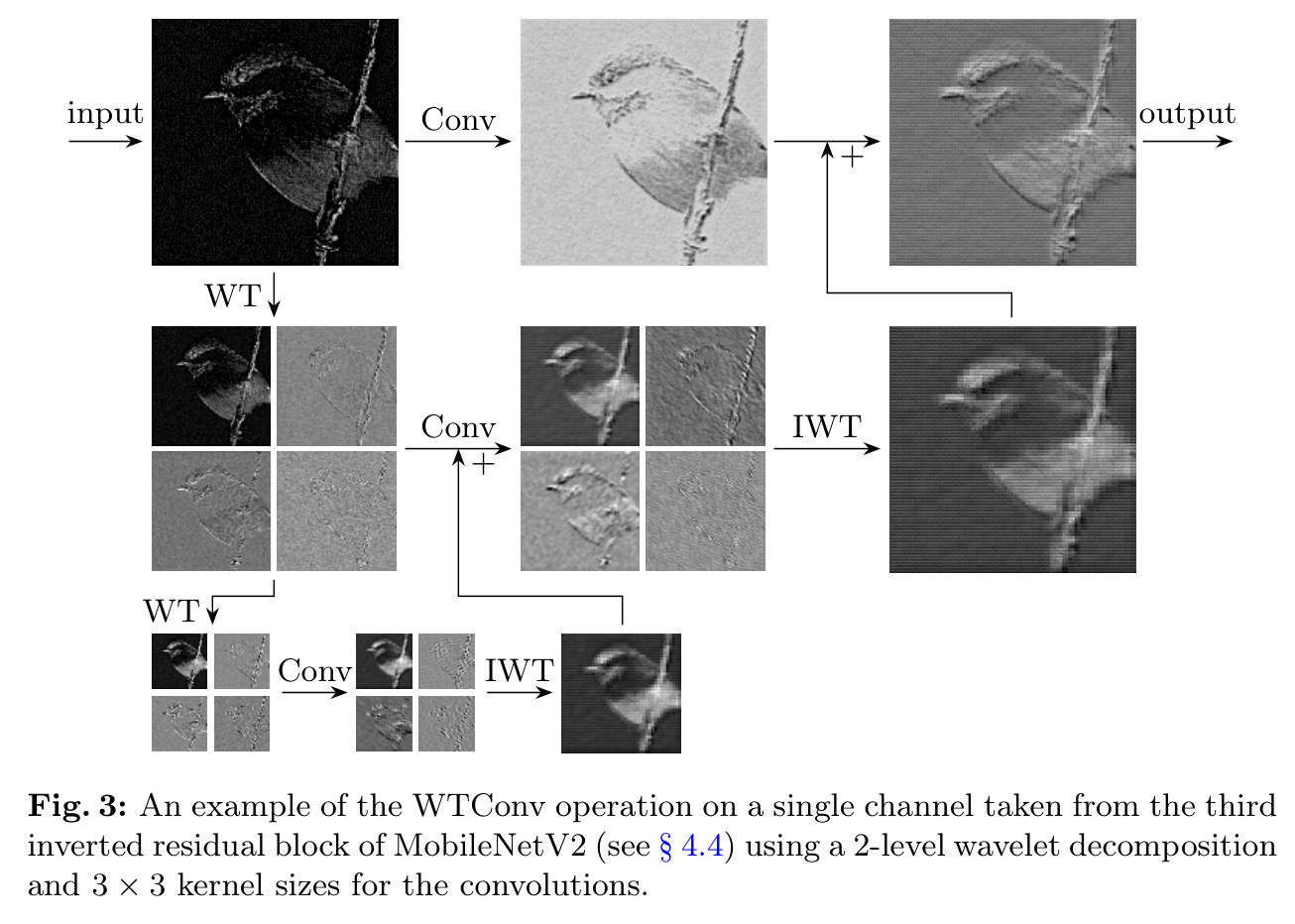
流程详解:
- 输入 (Input):原始特征图 。
- 多级小波分解 (Cascade WT):
- 利用 Haar 小波变换,将输入 分解为低频 () 和高频 () 分量。
- 关键点 :对生成的低频分量 递归地进行下一级分解。每一级分解后,特征图的空间分辨率减半,感受野范围对应翻倍。
- 多频带卷积 (Convolutions):
- 在每一层分解得到的特征图(包括低频和高频部分)上,分别执行一个小的深度卷积(例如 )。
- 由于是在降采样后的图上做卷积,一个 的核在第 2 层分解图上,实际上覆盖了原图 甚至更大的区域。
- 逆小波重构与求和 (IWT & Summation):
- 将卷积后的结果通过逆小波变换(IWT)逐级上采样并还原。
- 将不同层级处理后的特征进行相加融合,最终得到输出。
4.2 核心模块图解分析
我们将重点放在论文提到的 WTConv Layer 内部机制上。
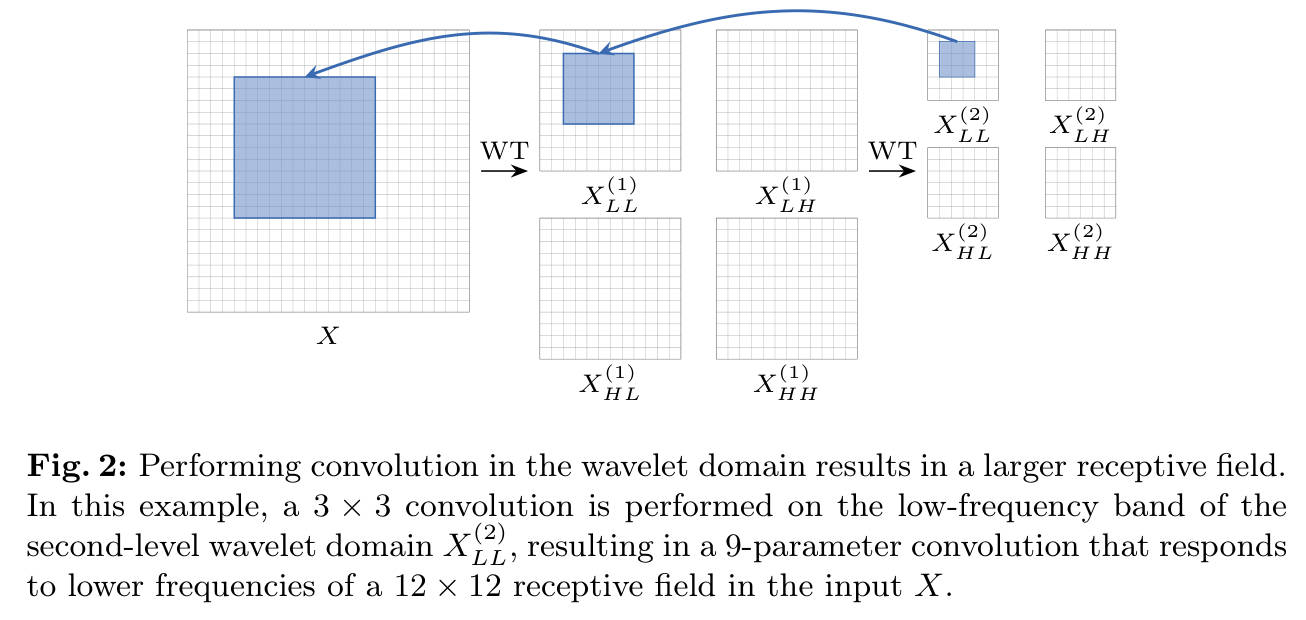
-
模块拆解:小波变换 (WT)
-
使用 Haar 小波基(包含加法和减法操作,计算极快)。
-
将输入 变为 4 个子图: (低频近似), (水平、垂直、对角线细节)。
-
作用:保留空间信息的同时分离频率,类似多分辨率金字塔。
-
模块拆解:级联卷积 (Cascade Conv)
-
在图 2 中,我们可以看到 的卷积核被应用在 (第2级低频图)上。
-
核心机制: 的 1 个像素对应原图 的区域。因此,这里的一个 卷积,其有效感受野在原图上被放大了 4 倍。
-
这就是为什么参数增长是对数级的:我们不需要增大核,只需要增加分解的层数(Level),每增加一层,感受野指数级扩大,但参数只增加一个该层的卷积核。
4.3 理念与机制总结
WTConv 的数学表达可以总结为:
其核心理念在于 "分而治之":
- 高频细节(纹理):在浅层分解中通过小卷积处理,保持局部细节。
- 低频主体(形状):在深层分解中处理,由于分辨率降低,小卷积也能覆盖全局形状。
4.4 图解总结:如何解决"动机"中的问题?
回到 Figure 1 的动机图,WTConv 之所以能点亮整个 ERF 图,是因为它在深层小波分解(低分辨率)上进行的卷积操作,通过 IWT 还原后,相当于在原图上执行了一个覆盖全图的超大卷积。它用"多尺度"代替了"大尺寸",从而在参数量极低的情况下(仅需几个小核),打破了 RepLKNet 等方法的物理局限。
5. 即插即用模块的作用
WTConv 是一个标准的 nn.Module,设计初衷就是为了替换现有的卷积层,特别是深度可分离卷积中的深度卷积部分。
适用场景:
- 大分辨率图像处理:由于小波变换的降采样特性,对大图处理非常友好。
- 需要捕捉全局信息的任务 :如 语义分割 (需要上下文)、目标检测(特别是大物体或背景复杂的场景)。
- 对鲁棒性要求高的场景:如自动驾驶、安防监控(抗模糊、抗噪声)。
在 YOLO 或其他网络中的应用:
你可以将 YOLO backbone 或 Head 中的 3x3 或 5x5 Depth-wise Conv 替换为 WTConv。
6. 实验部分简单分析
论文在 ImageNet 分类、ADE20K 分割和 COCO 检测上都进行了验证。
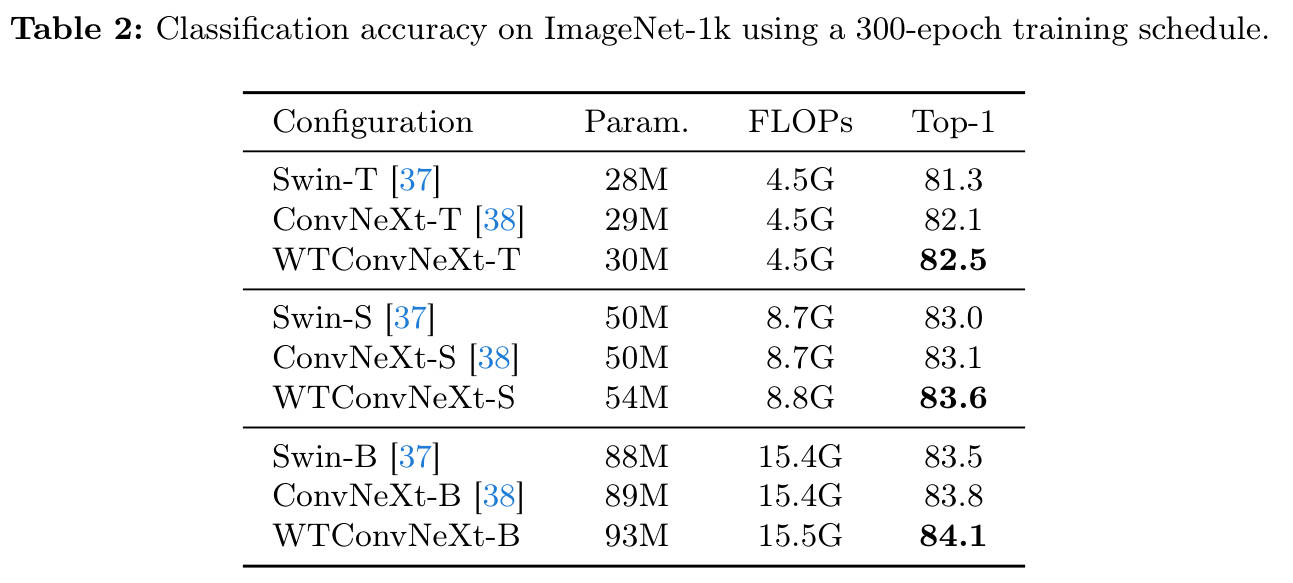
- ImageNet 分类:
-
在 ConvNeXt-T 架构下,WTConv 达到了 82.5% 的 Top-1 准确率,超过了 Swin-T (81.3%) 和 ConvNeXt-T (82.1%),且参数量增加很少。
-
关键结论:在参数量少于 RepLKNet 的情况下,性能更优。

- 下游任务 (检测与分割):
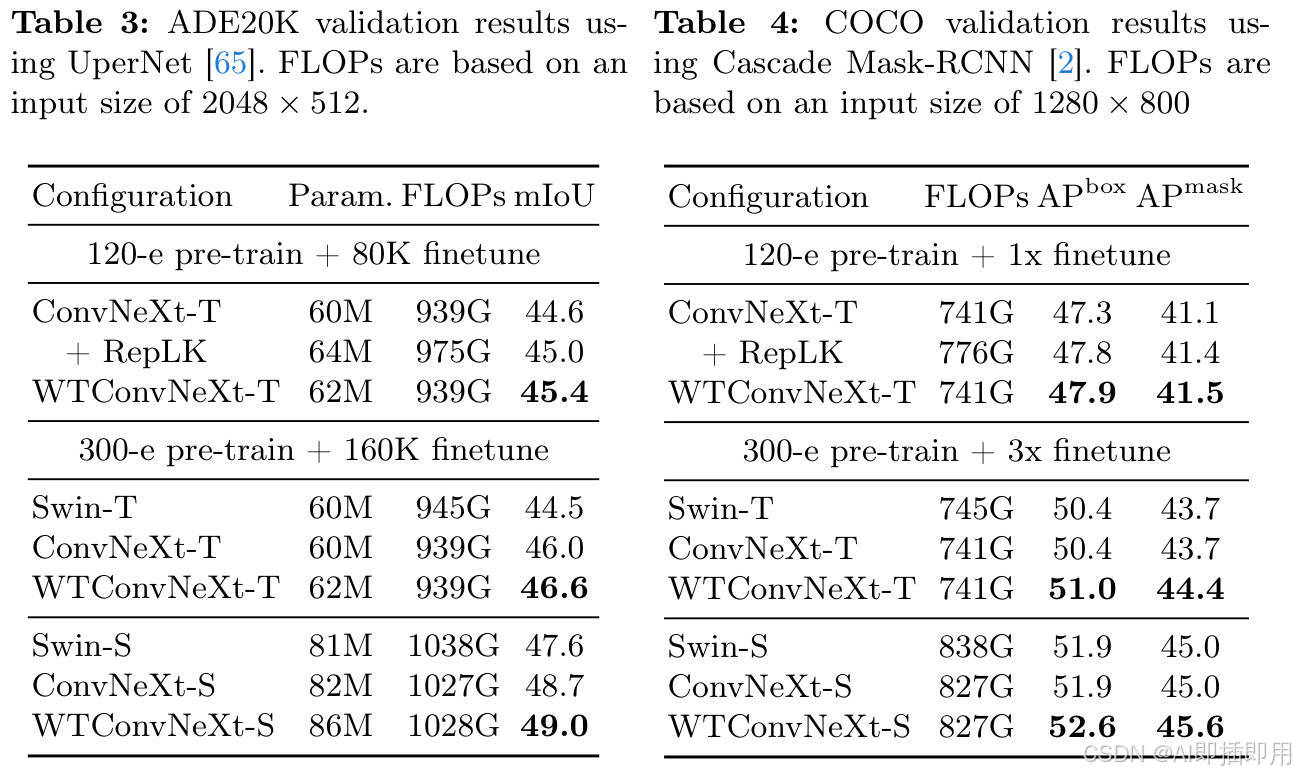
- 语义分割 (UperNet):mIoU 提升了 0.6% 左右。
- 目标检测 (Cascade Mask R-CNN) :Box AP 和 Mask AP 均有显著提升(+0.6~0.7%)。这对于一个即插即用的 Backbone 替换来说,提升是非常扎实的。
- 形状偏置与鲁棒性 (核心亮点):
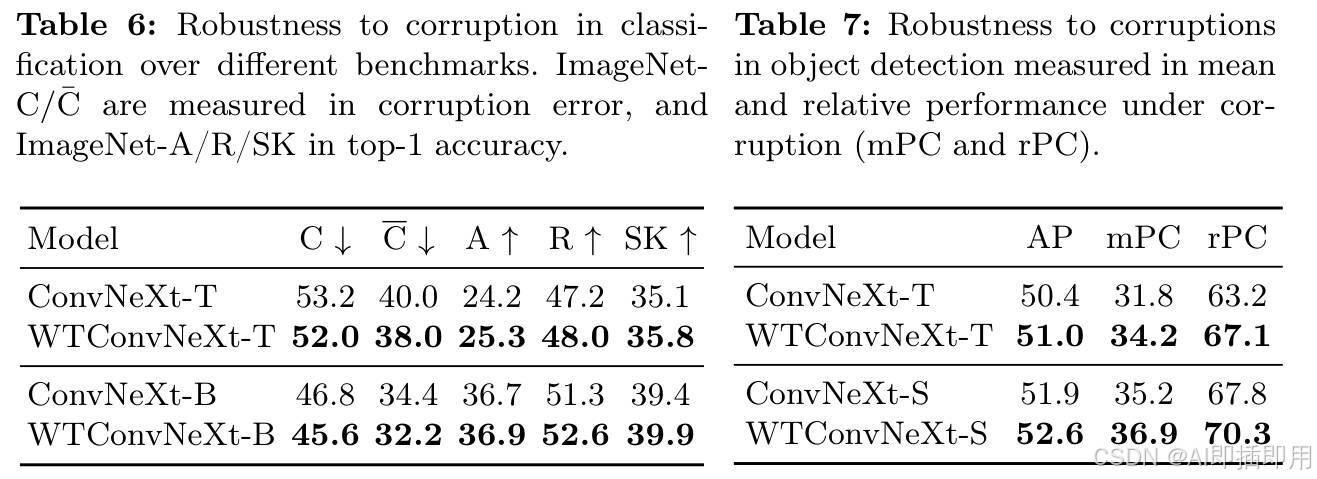
- Shape Bias:论文使用 Style Transfer 数据集测试,发现 WTConv 更倾向于利用"形状"而非"纹理"进行分类,这更接近人类视觉系统。
- 鲁棒性:在 ImageNet-C(腐蚀数据集)上,WTConv 的错误率明显低于基线,说明其学到的特征更加稳健。
到此,所有的内容就基本讲完了。如果觉得这篇文章对你有用,记得点赞、收藏并分享给你的小伙伴们哦😄。