
模型:https://huggingface.co/Qwen 或 https://modelscope.cn/organization/qwen
github:https://github.com/QwenLM/Qwen2.5-VL
开源时间:2025年3月5日
Abstract
Qwen2.5-VL =>Qwen视觉语言系列的最新旗舰模型,在基础能力与创新功能上均有显著提升。该模型具备增强的视觉识别、精确目标定位 (支持边界框/点)、稳健的文档解析 及长视频理解能力。
核心技术创新包括:
- 引入动态分辨率处理 与绝对时间编码 ,支持原生感知空间尺度与时间动态,可处理任意尺寸图像和长达数小时的视频,并实现秒级事件定位。
- 采用从头训练的原生动态分辨率ViT 与窗口注意力(Window Attention),在保持原生分辨率的同时显著降低计算开销。
关键性能表现:
- Qwen2.5-VL-72B 在文档与示意图理解方面表现卓越,与GPT-4o和Claude 3.5 Sonnet相当。
- 更小版本 Qwen2.5-VL-7B 和 Qwen2.5-VL-3B 在同类模型中性能领先,适合资源受限环境。
该模型无需任务特定微调即可实现跨域强泛化 ,并支持推理、工具使用与任务执行,可作为交互式视觉代理应用于计算机与移动设备操作等场景。同时,保留了Qwen2.5 LLM的核心语言能力,语言性能稳健。
1 Introduction
大型视觉-语言模型(LVLMs)通过整合视觉感知与自然语言处理,推动多模态理解发展。当前模型在多项任务中表现尚可,但细粒度视觉感知能力仍不足 ,且面临高计算复杂性 、有限上下文理解 和序列长度不一致等问题。
本报告提出Qwen2.5-VL ,延续Qwen系列开源理念,在多个基准上性能超越顶级闭源模型。技术贡献包括:
- 视觉编码器中引入窗口注意力,优化推理效率;
- 动态帧率采样,将动态分辨率扩展至时间维度,支持不同采样率视频理解;
- 时间域升级MROPE ,与绝对时间对齐,增强复杂时间序列学习;
- 预训练与监督微调阶段构建高质量数据,预训练语料库从1.2万亿标记扩展至4.1万亿标记。
核心特性:
- 强大的文档解析能力:支持多语言、多场景文档,可处理手写体、表格、图表、化学公式、音乐谱等;
- 跨格式精确物体定位 :支持绝对坐标 与JSON格式输出,实现高级空间推理;
- 超长视频理解与细粒度定位 :原生支持数小时视频,实现秒级事件提取;
- 增强的设备代理功能:在计算机与移动设备上具备先进定位、推理与决策能力。
架构设计(如图1所谓):
- 视觉编码器以原始分辨率处理图像/视频 ,支持动态帧率采样,生成变长标记序列;
- MROPE沿时间轴对齐时间ID与绝对时间,提升节奏感知与精确时序定位;
- 采用重设计的ViT架构 ,集成SwiGLU激活函数 、RMSNorm归一化 与窗口注意力机制,显著提升性能与效率。
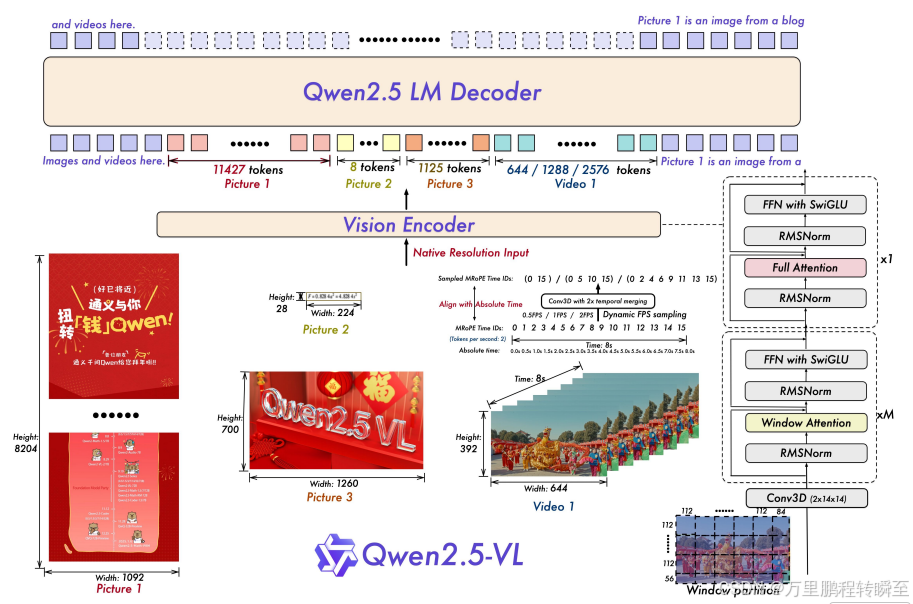
2 Approach
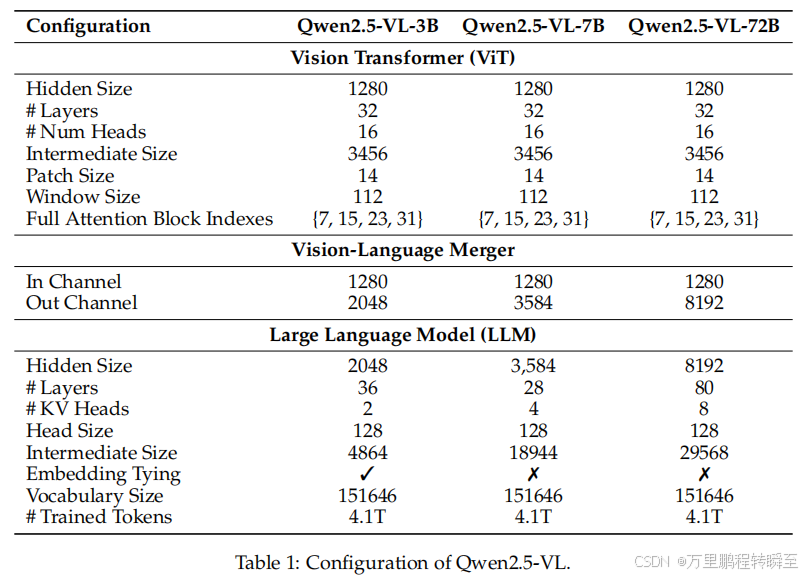
2.1 模型结构
Qwen2.5-VL的模型架构由以下三个核心组件构成:
Large Language Model:
- 采用 Qwen2.5 LLM 的预训练权重进行初始化;
- 对 1D RoPE 进行改进,升级为与绝对时间对齐 的多模态旋转位置编码(MRoPE),以支持图像和视频理解。
Vision Encoder:
- 使用重设计的视觉Transformer(ViT)架构;
- 引入 2D-RoPE 和 窗口注意力机制 ,支持原生分辨率输入并加速计算;
- 输入图像的高宽被调整为 28的倍数 ,并以 步长14 分割为补丁,生成图像特征。
MLP-based Vision-Language Merger:
为应对长序列特征的效率问题,采用 MLP压缩机制 :将空间上相邻的四组补丁特征分组、拼接 ,通过两层MLP 投影至与LLM文本嵌入对齐的维度;
实现动态压缩长度可变的视觉特征序列,降低计算负载的同时保留关键多模态信息。
2.1.1 高效视觉编码器
视觉编码器 采用重设计的ViT架构,解决原生分辨率输入带来的计算负载不平衡问题;
-
引入窗口化注意力(windowed attention) ,使计算成本与补丁数呈线性增长(而非二次方);
-
仅4层使用全自注意力 ,其余层采用最大窗口大小为112×112(8×8补丁)的窗口注意力;
-
小于112×112的区域无需填充 ,保留原始分辨率,实现原生分辨率处理;
-
使用2D RoPE 捕捉空间位置关系;
-
扩展至3D补丁分区 处理视频:以14×14图像补丁 为基础单位,每两帧连续帧组合 ,显著减少输入LLM的令牌数量;
-
架构对齐LLM设计:采用RMSNorm 归一化和SwiGLU激活函数 ,提升计算效率 与视觉-语言兼容性;
-
ViT从头训练,包含CLIP预训练 、视觉-语言对齐 和端到端微调阶段;
-
训练中采用动态原生分辨率采样 :图像按原始宽高比随机采样 ,增强对多分辨率输入的鲁棒性与泛化能力。
2.1.2 原生动态分辨率和帧率
-
在空间维度 ,Qwen2.5-VL 将不同尺寸图像动态转换为长度可变的标记序列;
-
直接使用图像实际尺寸 表示边界框、点等空间特征,无需归一化坐标 ,使模型原生学习尺度信息,提升多分辨率处理能力;
-
在时间维度 ,引入动态帧率(FPS)训练 与绝对时间编码;
-
模型通过自适应可变帧率,更准确捕捉视频时间动态;
-
提出MRoPE ID 与时间戳对齐 机制,无需额外头部或后处理,实现高效时间定位;
-
利用时间ID间隔建模时间节奏 ,支持跨不同采样率的一致理解,无额外计算开销。
2.1.3 多模态旋转位置嵌入对齐绝对时间
-
MRoPE 将位置嵌入分解为时间、高度、宽度三个组件:
- 文本输入:三者使用相同 ID,等效于1D RoPE;
- 图像输入:时间 ID 固定,高度/宽度 ID 基于空间位置分配;
- 视频输入:时间 ID 随帧递增,空间 ID 按图像规则分配。
-
Qwen2.5-VL 关键改进 :将 MRoPE 的时间组件与绝对时间对齐(而非仅依赖帧序号);
-
使模型能理解真实时间节奏 ,实现跨不同FPS视频的时间一致性建模。
2.2 预训练
2.2.1 预训练数据
- 预训练数据从 1.2万亿标记 扩展至约 4万亿标记;
- 数据来源包括:清理的网络数据、合成数据 ,涵盖以下多模态类型:
- 图像标题、交错图文、OCR、视觉知识(名人/地标/动植物)、多模态学术问题、定位数据 、文档解析数据、视频描述、视频定位、代理交互数据;
- 不同训练阶段动态调整数据比例,优化学习效果。
交错式图文数据处理
- 开发现代化数据清洗与评分流水线,确保高质量图文关联;
- 流程包含:标准清洗 + 四阶段内部模型评分,评估维度:
- 文本质量
- 图文相关性 (Image-text Relevance):高分表示图像有意义补充或解释文本,非装饰性;
- 信息互补性 (Information Complementarity):图像与文本提供独特细节,共同构成完整语义;
- 信息密度均衡 (Balance of Information Density):避免单模态信息过载,实现图文平衡。
基于绝对坐标的定位数据
- 采用原生分辨率训练 ,使用图像实际尺寸的绝对坐标表示边界框和点,优于相对坐标;
- 提升对真实尺度与空间关系的建模能力,增强目标检测与定位性能;
- 构建综合性定位数据集,融合公开与专有数据,支持多种格式(XML、JSON、自定义);
- 使用复制粘贴增强 及现成模型(如 Grounding DINO、SAM)进行数据合成;
- 扩展至**超过 10,000个物体类别**,提升开放词汇检测能力;
- 合成含不存在类别 及多实例的图像,增强极端检测场景鲁棒性;
- 构建指向数据集,来源包括:PixMo 、公开目标定位数据、自动化流水线生成的高精度指向标注。
Document Omni-Parsing Data
- 合成大规模多元素文档数据,支持:表格、图表、公式、自然/合成图像、乐谱、化学公式;
- 统一表示为 HTML 格式 ,嵌入布局框坐标 与插图描述至标签结构;
- 按典型阅读顺序 组织布局,并标注各模块(段落、图表等)的空间坐标;
- 实现文档的布局、文本、视觉内容 的标准化整合,支持端到端文档理解与转换。
对应的QwenVL HTML 格式

OCR Data
- OCR数据来自合成数据、开源数据和内部收集数据;
- 合成数据通过视觉文本生成引擎创建,生成高质量、自然场景下的文本图像;
- 构建大规模多语言OCR数据集,支持法语、德语、意大利语、西班牙语、葡萄牙语、阿拉伯语、俄语、日语、韩语、越南语等;
- 数据包含高质量合成图像与真实场景图像,确保多样性和鲁棒性;
- 图表数据:使用 matplotlib、seaborn、plotly 生成 100万样本,覆盖条形图、关系图、热力图等;
- 表格数据:处理 600万真实世界样本,通过离线端到端表格识别模型过滤低置信度、重叠及低密度单元格表格。
Video Data
- 训练中采用动态FPS采样 ,实现训练集内帧率的均匀分布,提升对不同FPS视频的鲁棒性;
- 针对超过半小时的长视频 ,通过目标合成流程生成长视频字幕;
- 视频时间戳标注采用秒级 和小时-分-秒(hmsf)格式,确保模型能准确理解与输出多种时间表示。
Agent Data
- 代理能力构建涵盖感知 与决策两方面;
- 感知 :收集移动、网页、桌面平台的截图 ,使用合成数据引擎 生成字幕 与UI元素标注,提升对图形界面的理解与外观-功能对齐;
- 决策 :将跨平台操作统一为共享动作空间的函数调用格式;
- 多步轨迹数据来自开源数据 与代理框架合成数据(Wang et al., 2025, 2024b,c),重格式化为函数调用序列;
- 每个操作步骤配备人工与模型标注的推理过程:基于操作前后截图与全局查询,编写意图解释;
- 使用基于模型的过滤器 剔除低质量推理,防止过拟合真实操作,增强现实场景中的泛化性与鲁棒性。
2.2.2 训练策略
我们从头训练视觉Transformer(ViT) 作为视觉编码器初始化,使用 DataComp(Gadre等,2023) 和内部数据集;同时采用预训练的 Qwen2.5 LLM(Yang等,2024a) 初始化语言模型组件。
预训练分为三个阶段(如表2所示),逐步提升模型能力:
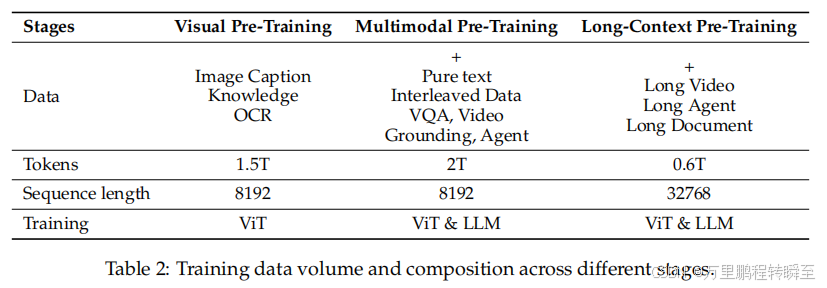
-
第一阶段 :仅训练 ViT,提升其与语言模型的对齐性;
- 数据源:图像标题、视觉知识、OCR数据;
- 目标:学习有意义的视觉表示,支持多模态融合。
-
第二阶段 :解冻所有参数,在多样化多模态图像数据上进行端到端训练;
- 引入复杂推理数据集:交错图文、多任务学习、VQA、多模态数学、代理任务、视频理解、纯文本数据;
- 增强视觉-语言深层关联建模能力。
-
第三阶段 :进一步提升在长序列、视频、代理任务上的推理能力;
- 扩展序列长度至 32,768,增强长程依赖与复杂推理处理能力。
为优化训练效率,应对不同图像尺寸与文本长度导致的计算负载不均:
- 主要开销来自 LLM 和视觉编码器;
- 视觉编码器因参数少且采用窗口注意力,计算需求较低;
- 重点通过动态数据打包平衡LLM在不同GPU上的负载;
- 第一、二阶段序列长度统一打包至 8,192 ,第三阶段提升至 32,768。
2.3 后训练
Qwen2.5-VL 采用双阶段后训练对齐框架:
- 监督微调(SFT) + 直接偏好优化(DPO)(Rafailov等,2023);
- 结合参数高效的领域适应 与人类偏好蒸馏 ,分别解决表征对齐 与行为优化。
2.3.1 Instruction Data
-
SFT 使用约 200万条 指令数据,纯文本(50%)与多模态(50%)均衡分布;
-
多模态数据包含图像-文本 和视频-文本组合,视觉/时序信息显著增加标记量与计算开销;
-
数据以中英文为主,辅以多语言条目,提升语言多样性;
-
包含单轮与多轮对话 ,情境覆盖从单图到多图序列,模拟真实交互;
-
查询来源:开源代码仓库 、筛选后的购买数据集 与在线查询数据;
-
数据集涵盖专用子集以增强专业能力:
- 通用VQA、图像描述、数学求解、编码任务、安全查询;
- 文档与OCR、定位、视频分析、智能体交互等特定领域数据。
该结构化设计实现预训练表示与下游任务需求的精准对齐,提升上下文感知 与性能稳健性。
2.3.2 Data Filtering Pipeline
训练数据质量直接影响模型性能。我们实施两阶段过滤流程以系统性提升SFT数据质量:
Stage 1: Domain-Specific Categorization
- 使用专用分类模型 Qwen2-VL-Instag(源自 Qwen2-VL-72B)执行层次化分类;
- 将问答对划分为 8个主要领域 ,细分为 30个子类别(如 Code_Debugging、Code_Generation 等);
- 支持领域感知与子领域定制化清洗策略,提升数据相关性与质量。
Stage 2: Domain-Tailored Filtering
结合基于规则 与基于模型的方法进行全面过滤:
-
基于规则的过滤:
- 移除重复模式、不完整/截断/格式错误响应;
- 舍弃无关或可能导致有害输出的样本,确保伦理合规与任务适配性。
-
基于模型的过滤:
- 使用在 Qwen2.5-VL 系列上训练的奖励模型进行多维度评估;
- 查询评估维度:复杂性、相关性;
- 答案评估维度:正确性、完整性、清晰度、实用性、视觉信息利用准确性;
- 仅保留高分样本进入SFT阶段。
2.3.3 拒绝采样以增强推理能力
-
采用拒绝采样 优化数据集,重点提升复杂推理任务表现(如数学、代码生成、特定VQA);
-
基于包含真实标注 的数据集,使用Qwen2.5-VL中间版本模型生成响应;
-
仅保留模型输出与标准答案匹配的样本,确保高质量;
-
进一步应用约束排除:
- 代码切换、过长响应、重复模式;
- 保证思维链(CoT)的清晰性与连贯性;
-
针对多模态CoT挑战(如忽略或误解视觉线索),开发:
- 基于规则与模型的验证机制 ,确保每步推理有效融合视觉与文本信息;
-
拒绝采样生成的高保真CoT数据显著提升模型推理能力,支持迭代优化。
2.3.4 训练方案
- 后训练包含两个阶段:
- SFT:在多种多模态数据上微调,包括图文对、视频、纯文本,来自通用问答、拒绝采样及专用数据集(文档、OCR、定位、视频、代理任务);
- DPO :使用图文与纯文本偏好数据,对齐人类偏好;
- ViT参数冻结,聚焦LLM优化;
- DPO阶段每个样本仅处理一次,确保高效优化。
3 Experiments
3.1 与当前最先进(SOTA)模型的比较
对比模型:Claude-3.5-Sonnet-0620、GPT-4o-0513、InternVL2.5、不同规模Qwen2-VL
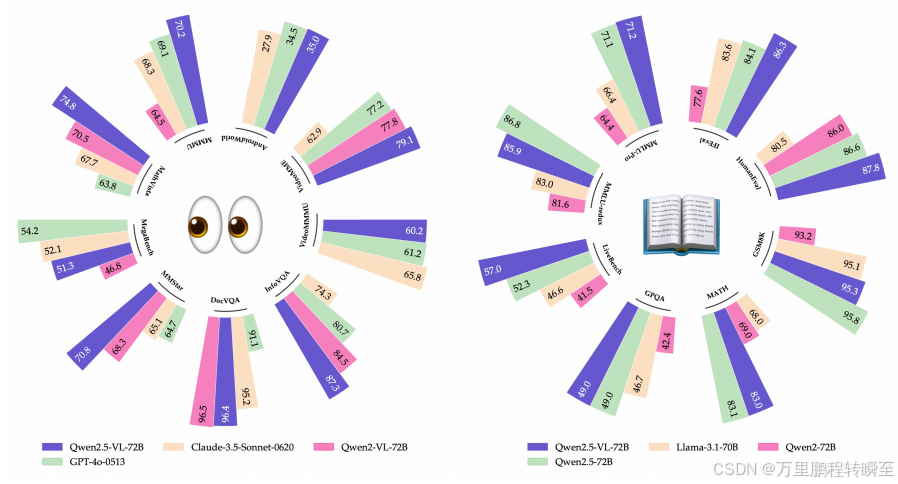
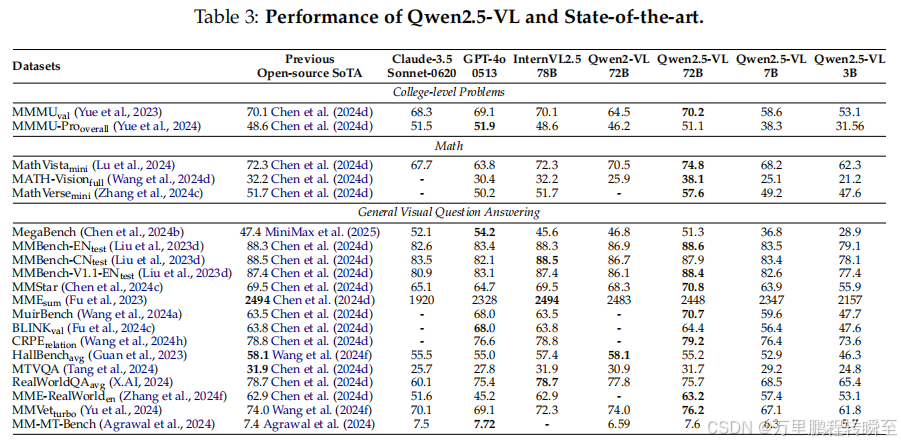
核心性能指标:大学级别问题:Qwen2.5-VL-72B 在 MMMU 得 70.2 分;MMMU-Pro 得 51.1 分(超越开源SOTA,媲美GPT-4o)
数学任务:MathVista 得 74.8 分(超越此前开源SOTA的72.3分);MATH-Vision 得 38.1 分,MathVerse 得 57.6 分(均具竞争力)
通用视觉问答:MMBench-EN 得 88.6 分(略高于此前最佳88.3分);MuirBench 得 70.7 分、BLINK 得 64.4 分;多语言(MTVQA)得 31.7 分;主观评估(MMVet 得 76.2 分、MM-MT-Bench 得 7.6 分,对话体验与用户满意度优秀)
3.2 纯文本任务上的性能
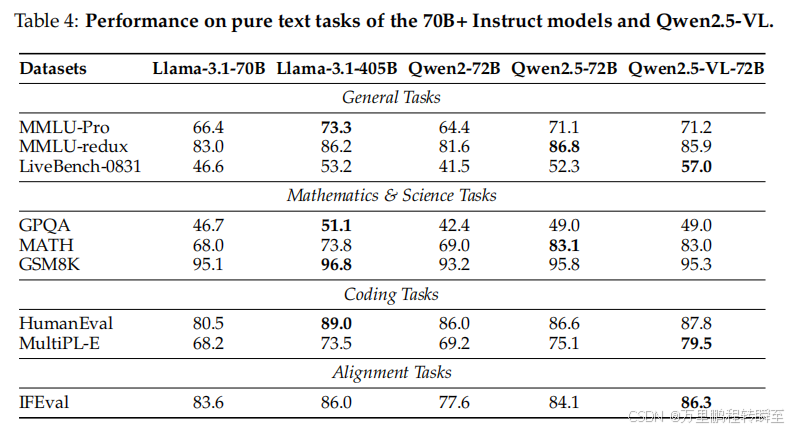
评估范围:通用任务、数学/科学任务、编程任务、对齐任务(代表性基准)
对比对象:同规模大语言模型(LLMs)
核心结论:Qwen2.5-VL 不仅多模态任务达SOTA,纯文本任务表现优异,具备多功能性与鲁棒性
3.3 定量结果
3.3.1 通用视觉问题回答(VQA)
评估范围:通用VQA、对话任务,覆盖MMBench系列、MMStar、MME、MuirBench等多类基准数据集
核心性能:Qwen2.5-VL 展现最先进性能,具体指标如下:MMBench-EN-V1.1(视觉细节理解与推理):Qwen2.5-VL-72B 准确率 88.4%,超越 InternVL2.5(78B)、Claude-3.5 Sonnet-0620
MMStar:Qwen2.5-VL 得分 70.8,领先其他模型;小规模版本中,7B 达 63.9%,3B 达 55.9%
MME-RealWorld(高分辨率现实场景):得分 63.2,展现最先进性能
MuirBench(多图像理解):得分 70.7,泛化能力卓越
架构优势:具备良好可扩展性,小规模版本仍保持强劲竞争力
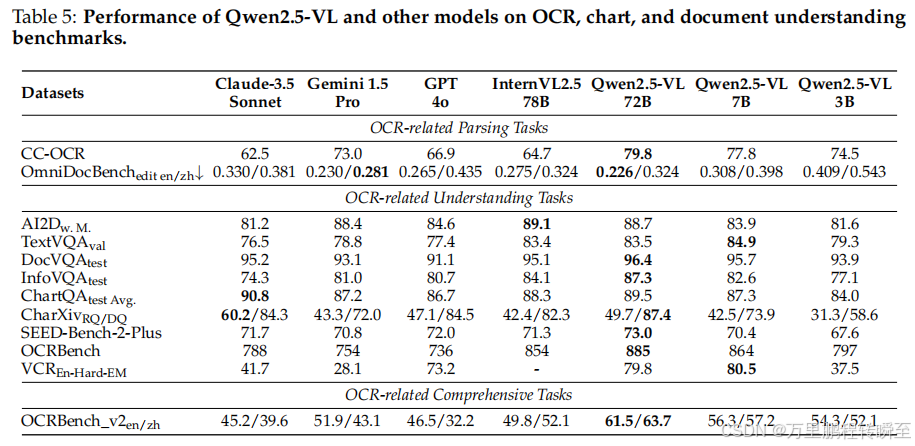
3.3.2 文档理解与OCR
- 评估范围:OCR、图表、文档理解,覆盖AI2D、TextVQA、DocVQA、OCRBench系列、CC-OCR等基准
- 核心性能:解析任务:Qwen2.5-VL-72B 依托优质训练数据与**大语言模型(LLM)**能力,成为CC-OCR、OmniDocBench基准新标杆
- 理解任务:在OCRBench、InfoVQA、SEED-Bench-2-Plus等基准大幅超越 InternVL2.5-78B
- 综合基准(OCRBench_v2):表现最佳,超越 Gemini 1.5-Pro,英语任务提升 9.6%,中文任务提升 20.6%
3.3.3 空间理解
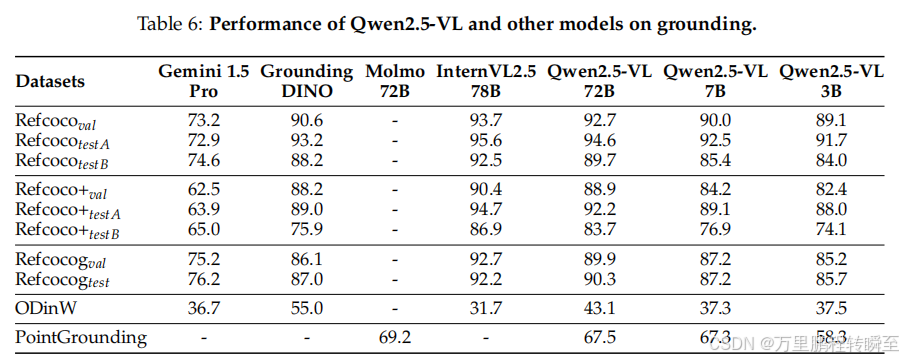
-
评估任务:视觉定位(边界框/点定位)、野外目标检测、计数,采用引用表达理解、ODinW-13、CountBench等基准
-
对比模型:Gemini、Grounding-DINO、Molmo、InternVL2.5
-
核心性能:开放式词汇目标检测(ODinW-13):mAP 达 43.1,超越多数多模态大模型
-
计数任务(CountBench):Qwen2.5-VL-72B 采用"检测然后计数"提示,准确率达 93.6
-
具备精确点定位能力,可解读图像特定部分细节
3.3.4 视频理解与定位
-
评估范围:覆盖几秒到数小时视频,含Video-MME、Video-MMMU、LVBench、MLVU等基准
-
核心技术:同步MRoPE,增强时间敏感视频理解能力(时间戳引用、时间定位等)
-
核心性能:长视频理解(LVBench、MLVU):Qwen2.5-VL-72B 显著优于 GPT-4o
-
事件定位(Charades-STA):mIoU 达 50.9,超越 GPT-4o
-
约束条件:单视频最大分析帧数768,视频令牌总数≤24,576


3.3.5 Agent
-
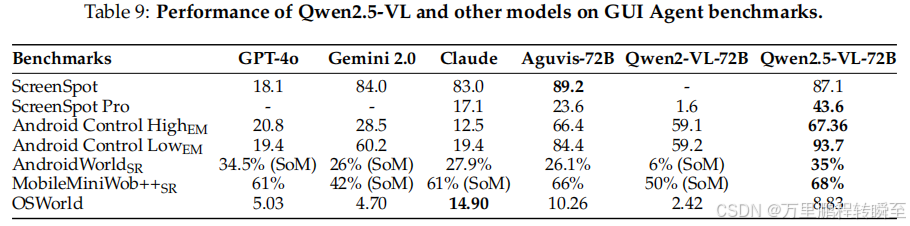
评估任务:GUI元素接地、离线/在线设备交互,采用ScreenSpot、ScreenSpot Pro、Android Control等基准
-
对比模型:GPT-4o、Gemini 2.0、Claude、Aguvis-72B、Qwen2-VL-72B
-
核心性能:GUI接地:ScreenSpot 准确率 87.1%(媲美Gemini 2.0、Claude);ScreenSpot Pro 准确率 43.6%,远超Aguvis-72B(23.6%)、Qwen2-VL-72B(1.6%)
-
离线评估:显著优于基线模型
-
在线评估:AndroidWorld、MobileMiniWob++ 优于基线;OSWorld 与基线相当,无需Set-of-Mark(SoM)辅助标记,可在真实动态环境发挥代理作用
4 结论
-
核心模型:Qwen2.5-VL(先进视觉-语言模型系列),多模态理解与交互能力显著提升
-
关键优势:增强视觉识别、目标定位、文档解析、长视频理解能力;原生动态分辨率处理 、绝对时间编码 (高效处理多样输入);Window Attention(降计算开销且保分辨率保真度)
-
性能定位:旗舰模型(72B):文档/图表理解比肩GPT-4o、Claude 3.5 Sonnet,纯文本任务性能强劲
-
小规模模型(7B、3B):优于同类竞争模型,兼顾效率与多功能性
-
价值意义:树立视觉-语言模型新基准,泛化能力卓越;为更智能交互系统铺路,弥合感知与现实应用鸿沟