llama.cpp Sampling API
- [1. Sampling API](#1. Sampling API)
- References
llama.cpp
https://github.com/ggerganov/llama.cpp
1. Sampling API
/home/yongqiang/llm_work/llama_cpp_25_01_05/llama.cpp/include/llama.h
//
// Sampling API
//
// Sample usage:
//
// // prepare the sampling chain at the start
// auto sparams = llama_sampler_chain_default_params();
//
// llama_sampler * smpl = llama_sampler_chain_init(sparams);
//
// llama_sampler_chain_add(smpl, llama_sampler_init_top_k(50));
// llama_sampler_chain_add(smpl, llama_sampler_init_top_p(0.9, 1));
// llama_sampler_chain_add(smpl, llama_sampler_init_temp (0.8));
//
// // typically, the chain should end with a sampler such as "greedy", "dist" or "mirostat"
// // this sampler will be responsible to select the actual token
// llama_sampler_chain_add(smpl, llama_sampler_init_dist(seed));
//
// ...
//
// // decoding loop:
// while (...) {
// ...
//
// llama_decode(ctx, batch);
//
// // sample from the logits of the last token in the batch
// const llama_token id = llama_sampler_sample(smpl, ctx, -1);
//
// // accepting the token updates the internal state of certain samplers (e.g. grammar, repetition, etc.)
// llama_sampler_accept(smpl, id);
// ...
// }
//
// llama_sampler_free(smpl);
//
// TODO: In the future, llama_sampler will be utilized to offload the sampling to the backends (e.g. GPU).
// TODO: in the future, the entire sampling API that uses llama_model should start using llama_vocab
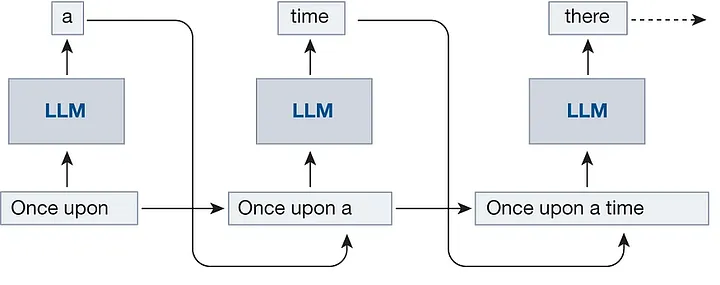
//- Autoregressive generation
/home/yongqiang/llm_work/llama_cpp_25_01_05/llama.cpp/examples/simple/simple.cpp
/home/yongqiang/llm_work/llama_cpp_25_01_05/llama.cpp/src/llama-sampling.h
/home/yongqiang/llm_work/llama_cpp_25_01_05/llama.cpp/src/llama-sampling.cpp
References
1 Yongqiang Cheng, https://yongqiang.blog.csdn.net/