title: 探索自联接(SELF JOIN):揭示数据间复杂关系的强大工具
date: 2025/1/11
updated: 2025/1/11
author: cmdragon
excerpt:
自联接(SELF JOIN)是一种特殊的联接操作,在同一表中多次引用自己,从而允许开发者获取更复杂的数据关系。通过自联接,可以有效处理层级、映射和关联数据的查找,极大丰富了 SQL 查询的灵活性和表达能力。
categories:
- 前端开发
tags:
- 自联接
- SQL
- 数据库查询
- 层级数据
- 关系型数据库
- 数据分析
- SQL优化

扫描二维码关注或者微信搜一搜:编程智域 前端至全栈交流与成长
自联接(SELF JOIN)是一种特殊的联接操作,在同一表中多次引用自己,从而允许开发者获取更复杂的数据关系。通过自联接,可以有效处理层级、映射和关联数据的查找,极大丰富了 SQL 查询的灵活性和表达能力。
1. 引言
在关系型数据库中,数据通常存储在表中,这些表往往存在复杂的关系。在许多情况下,数据项之间并非简单的 Parent-Child 关系,而是需要通过同一表的数据进行比较和查询。自联接(SELF JOIN)为处理这种复杂关系提供了一种优雅的解决方案。该操作允许开发者在同一表中多次引用,以便在查询中对数据进行更为深入的比较和分析。
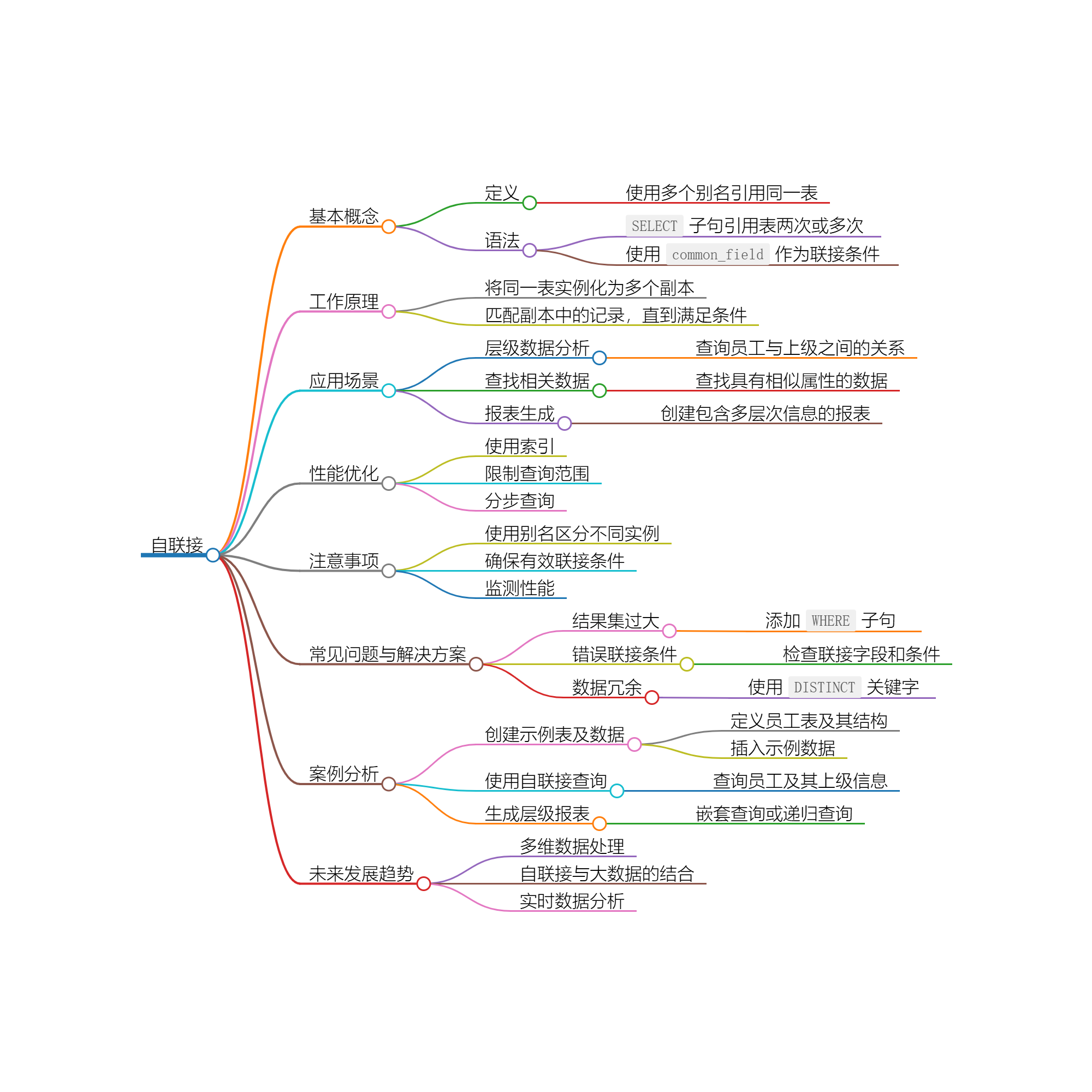
2. 自联接的基本概念
自联接是指在 SQL 查询中,将同一张表在逻辑上进行两次或多次引用,以便对其记录进行比较和联接。自联接实际上是用内联接或外联接的方式实现对自身表的操作。因此,自联接常常被视为一种特殊类型的联接。
2.1 自联接的语法
自联接的基本语法如下:
sql
SELECT a.column1, b.column2
FROM table_name a, table_name b
WHERE a.common_field = b.common_field;在此示例中,a 和 b 是表的两个别名,允许我们在同一查询中引用同一表的不同实例。
3. 自联接的工作原理
自联接的工作原理是将同一表实例化为多个副本,允许开发者在 SQL 中进行比较。有时为了方便理解,开发者会将同一表的不同副本视作"子表"。查询中,表的两个副本的每一行都会进行匹配,直到找到符合联接条件的记录。
4. 自联接的实际应用场景
自联接可应用于多种案例,尤其是在处理层级数据、查找相关条目时,极为有效。
4.1 层级数据分析
自联接常用于处理员工与上级之间的层级关系。例如,在一个员工表中,每个员工都有一列表示其上级的ID,开发者可以通过自联接轻松查询出某名员工的上级以及其所有下属。
4.2 查找相关数据
在产品管理、客户管理等领域,自联接可用于查找具有相似属性或特征的数据。例如,查询提供了相同产品类别的不同产品或客户。
4.3 生成报表
通过自联接,开发者可以创建包含多个层次信息的报表。例如,选择某个部门的所有员工以及他们的上级,以生成组织结构图等。
5. 自联接的性能优化
自联接可能会消耗大量资源,特别是在表较大的时候。以下是一些优化自联接性能的建议:
5.1 使用适当的索引
在自联接的字段上创建索引可以显著加快查询速度。这允许数据库引擎快速找到所需记录,减少全表扫描的时间消耗。
sql
CREATE INDEX idx_manager_id ON employees(manager_id);5.2 限制查询范围
在自联接查询中,通过限制结果集的大小(例如加上 WHERE 条件),可以提高查询性能,避免返回冗余数据。
sql
SELECT e1.name AS employee_name, e2.name AS manager_name
FROM employees e1
JOIN employees e2 ON e1.manager_id = e2.id
WHERE e1.department_id = 'Sales';5.3 分步查询
考虑将复杂的自联接查询分解为多个步骤,这使得每个步骤都更易于管理,性能相对容易提高。
6. 自联接的注意事项
在使用自联接时,需要注意以下几点:
6.1 别名使用
在自联接中,使用别名是比较重要的,以区别同一表的不同实例。确保每个实例都有清晰易懂的别名,以避免混淆。
6.2 确保联接条件有效
自联接的使用需要确保联接条件的正确性,以避免产生不必要的行或空值。
6.3 监测性能
在执行自联接查询时,监测其执行时间,以确保不会导致数据库资源的过度消耗。
7. 常见问题与解决方案
7.1 结果集过大
自联接可能返回大量数据,导致结果集过大。为此,可以通过添加 WHERE 子句来限制所查询的行。
7.2 错误的联接条件
确保联接条件成立,以避免产生无效或空的结果集。错误的条件可能导致返回结果不符合预期。
7.3 数据冗余
自联接返回多个记录时,要小心数据冗余。在设计查询时考虑使用 DISTINCT 关键字以消除重复记录。
8. 案例分析:员工与上级的自联接
通过具体的案例分析,帮助更好地理解自联接的应用。
8.1 创建示例表及数据
假设我们有一个员工表,结构如下:
sql
CREATE TABLE employees (
id SERIAL PRIMARY KEY,
name VARCHAR(50),
manager_id INT
);
INSERT INTO employees (name, manager_id) VALUES
('Alice', NULL),
('Bob', 1),
('Charlie', 1),
('David', 2);在这个示例中,Alice 是 Bob 和 Charlie 的上级,Bob 是 David 的上级。
8.2 使用自联接查询
我们想查询所有员工及其对应的上级:
sql
SELECT e1.name AS employee_name, e2.name AS manager_name
FROM employees e1
LEFT JOIN employees e2 ON e1.manager_id = e2.id;执行结果如下:
| employee_name | manager_name |
|---|---|
| Alice | NULL |
| Bob | Alice |
| Charlie | Alice |
| David | Bob |
8.3 生成层级报表
可以进一步生成层级结构报表,显示员工及其上级的信息,以便于管理分析。
9. 自联接
- 多维数据处理:如何在自联接中支持多维数据集,将成为未来数据分析中的一个重要课题。
- 自联接与大数据的结合:如何在大数据环境下有效利用自联接,提升查询性能与准确度,尤其在分布式数据库环境中。
- 实时数据分析:如何结合自联接实现对实时数据的有效分析,满足现代业务的快速反应需求。
10. 结论
自联接是一种强大的 SQL 查询工具,使得开发者能够在同一表中多次引用数据,从而揭示数据间复杂的关系。充分理解自联接的概念及其最佳实践,将有助于处理海量数据时产生更具洞察力的分析结果。
参考
- SQL and Relational Theory - Chris Date
- PostgreSQL Documentation: Self Join
- SQL Cookbook - Anthony Molinaro
- Effective SQL: 61 Specific Ways to Write Better SQL - John Viescas
- 数据库系统概念 - Abraham Silberschatz, Henry Korth & S. Sudarshan
余下文章内容请点击跳转至 个人博客页面 或者 扫码关注或者微信搜一搜:编程智域 前端至全栈交流与成长,阅读完整的文章:探索自联接(SELF JOIN):揭示数据间复杂关系的强大工具 | cmdragon's Blog
往期文章归档:
- 深入剖析数据删除操作:DELETE 语句的使用与管理实践 | cmdragon's Blog
- 数据插入操作的深度分析:INSERT 语句使用及实践 | cmdragon's Blog
- 特殊数据类型的深度分析:JSON、数组和 HSTORE 的实用价值 | cmdragon's Blog
- 日期和时间数据类型的深入探讨:理论与实践 | cmdragon's Blog
- 数据库中的基本数据类型:整型、浮点型与字符型的探讨 | cmdragon's Blog
- 表的创建与删除:从理论到实践的全面指南 | cmdragon's Blog
- PostgreSQL 数据库连接 | cmdragon's Blog
- PostgreSQL 数据库的启动与停止管理 | cmdragon's Blog
- PostgreSQL 初始化配置设置 | cmdragon's Blog
- 在不同操作系统上安装 PostgreSQL | cmdragon's Blog
- PostgreSQL 的系统要求 | cmdragon's Blog
- PostgreSQL 的特点 | cmdragon's Blog
- ORM框架与数据库交互 | cmdragon's Blog
- 数据库与编程语言的连接 | cmdragon's Blog
- 数据库审计与监控 | cmdragon's Blog
- 数据库高可用性与容灾 | cmdragon's Blog
- 数据库性能优化 | cmdragon's Blog
- 备份与恢复策略 | cmdragon's Blog
- 索引与性能优化 | cmdragon's Blog
- 事务管理与锁机制 | cmdragon's Blog
- 子查询与嵌套查询 | cmdragon's Blog
- 多表查询与连接 | cmdragon's Blog
- 查询与操作 | cmdragon's Blog
- 数据类型与约束 | cmdragon's Blog
- 数据库的基本操作 | cmdragon's Blog
- 数据库设计原则与方法 | cmdragon's Blog