目录
- 一、E-R模型
- 二、数据类型
- 三、字段命名规范
- 四、数据库创建与管理
-
- [4.1 创建数据库](#4.1 创建数据库)
- [4.2 删除数据库](#4.2 删除数据库)
- [4.3 列出数据库](#4.3 列出数据库)
- [4.4 备份数据库](#4.4 备份数据库)
- [4.5 还原数据库](#4.5 还原数据库)
- [4.6 使用某个数据库](#4.6 使用某个数据库)
- 五、数据表创建与管理
-
- [5.1 创建表](#5.1 创建表)
- [5.2 查看表结构](#5.2 查看表结构)
- [5.3 查看数据表](#5.3 查看数据表)
- [5.4 复制表结构](#5.4 复制表结构)
- [5.5 复制表数据](#5.5 复制表数据)
- [5.6 修改表名](#5.6 修改表名)
- [5.7 增加字段](#5.7 增加字段)
- [5.8 删除字段](#5.8 删除字段)
- [5.9 修改字段数据类型](#5.9 修改字段数据类型)
- [5.10 修改字段名称](#5.10 修改字段名称)
- [5.11 设置主键](#5.11 设置主键)
- [5.12 删除主键](#5.12 删除主键)
- [5.13 设置外键](#5.13 设置外键)
- [5.14 删除外键](#5.14 删除外键)
- 六、数据更新操作
-
- [6.1 插入记录(`INSERT`)](#6.1 插入记录(
INSERT)) -
- [6.1.1 插入单条记录](#6.1.1 插入单条记录)
- [6.1.2 插入多条记录](#6.1.2 插入多条记录)
- [6.1.3 子查询插入多条记录](#6.1.3 子查询插入多条记录)
- [6.2 删除记录(`DELETE`)](#6.2 删除记录(
DELETE)) - [6.3 更新记录(`UPDATE`)](#6.3 更新记录(
UPDATE)) - [⚠️ 重要提示](#⚠️ 重要提示)
- [6.1 插入记录(`INSERT`)](#6.1 插入记录(
- 七、数据查询操作
-
- [7.1 单表查询](#7.1 单表查询)
-
- [7 .1.2 条件过滤(WHERE)](#7 .1.2 条件过滤(WHERE))
- [7.1.3 排序(ORDER BY)](#7.1.3 排序(ORDER BY))
- [7.1.4 聚集函数](#7.1.4 聚集函数)
- [7.1.5 分组(GROUP BY)](#7.1.5 分组(GROUP BY))
- [7.2 连接查询](#7.2 连接查询)
-
- [7.2.1 简单连接(逗号分隔)](#7.2.1 简单连接(逗号分隔))
- [7.2.2 JOIN 连接](#7.2.2 JOIN 连接)
- [7.3 嵌套查询(子查询)](#7.3 嵌套查询(子查询))
-
- [7.3.2 比较运算符](#7.3.2 比较运算符)
- [7.3.3 `ANY` / `ALL` 谓语](#7.3.3
ANY/ALL谓语) - [7.3.4 `EXISTS` 谓语](#7.3.4
EXISTS谓语)
- [7.4 合并查询(UNION)](#7.4 合并查询(UNION))
-
- [⚠️ 关键安全提示](#⚠️ 关键安全提示)
一、E-R模型
实体-联系模型(E-R模型)提供了一种不受特定数据库管理系统(DBMS)约束的、面向用户的表达方法,在数据库设计中被广泛用作数据建模工具。在项目开发中,需提前使用E-R模型绘制ER图,以确保数据库结构清晰、合理。
DBMS 中的约束是用于强制限制可以插入、更新或删除到表中的数据或数据类型的一组规则。约束的整个目的是在执行更新、删除或插入操作时保持数据的完整性。
约束的类型
- 非空约束 (Not Null Constraint):确保列中的值不能为NULL,防止插入或更新空值。
- 唯一约束 (Unique Constraint):确保表中某一列或多列的值是唯一的,但允许空值存在。
- 默认约束 (Default Constraint):为列指定默认值,当插入新行时如果没有为该列提供值,则使用默认值。
- 检查约束 (Check Constraint):定义对列值的条件限制,确保数据满足特定的条件或范围。
- 主键约束 (Primary Key Constraint):唯一标识表中的每一行数据,要求值唯一且非空。
- 外键约束 (Foreign Key Constraint):确保表之间的引用完整性,要求一个表的列值必须在另一个表的主键列中存在。
知识库中提到的"域约束"实际上是检查约束的功能描述,而"映射约束"不是标准的数据库约束类型。数据库中标准的约束类型为上述六种。
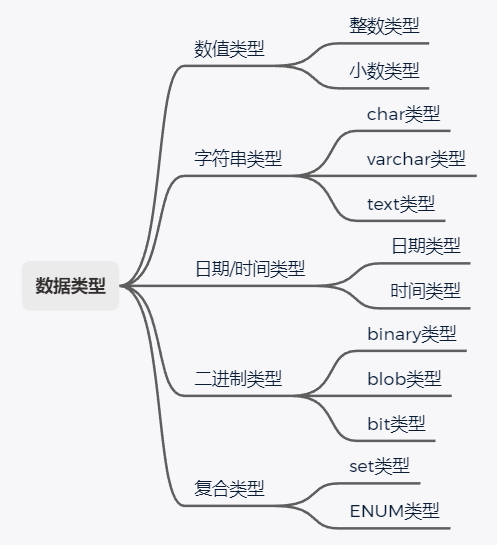
二、数据类型
三、字段命名规范
- 命名组成 :采用26个英文字母(区分大小写)、0-9数字(通常不使用)和下划线
_,确保命名简洁明确,多单词用下划线分隔(如user_id)。 - 大小写规范 :统一使用小写字母(如
is_active,而非IsActive)。 - 禁用关键字 :避免使用数据库保留字(如
table、time、datetime、primary)。 - 命名逻辑 :字段名应为名词或动宾短语(如
user_id、is_valid)。 - 长度限制 :名称需易读易懂,通常不超过三个英文单词(如
order_date,而非order_creation_timestamp)。
四、数据库创建与管理
4.1 创建数据库
语法 :CREATE DATABASE db_name;
示例 :CREATE DATABASE db_test;
4.2 删除数据库
语法 :DROP DATABASE db_name;
示例 :DROP DATABASE db_test;
4.3 列出数据库
语法 :SHOW DATABASES;
示例 :SHOW DATABASES;
4.4 备份数据库
语法 :mysqldump -h 主机名 -u 用户名 -p 密码 数据库名称 > 脚本文件路径;
示例 :mysqldump -u root -p000000 test > test.sql;
说明 :宿主机操作可省略
-h参数(如mysqldump -u root -p000000 test > test.sql;)。
4.5 还原数据库
语法1(命令行) :mysql -h 主机名 -u 用户名 -p 密码 数据库名称 < 脚本文件路径;
示例1 :mysql -u root -p000000 test < test.sql;
语法2(MySQL客户端) :SOURCE 脚本文件路径;
示例2 :SOURCE test.sql;
4.6 使用某个数据库
语法 :USE db_name;
示例 :USE db_test;
五、数据表创建与管理
5.1 创建表
语法 :CREATE TABLE table_name (col_name1 data_type1, col_name2 data_type2, ...);
说明:
-
data_type中的数字表示字段长度(如CHAR(20)表示最多存储 20 个字符)。
示例:CREATE TABLE t_test (id CHAR(20), name CHAR(10));
5.2 查看表结构
DESCRIBE table_name; -- 或简写为 `DESC table_name;`示例:
DESC t_test;5.3 查看数据表
语法 :SHOW TABLES;
示例:
SHOW TABLES;5.4 复制表结构
语法 :CREATE TABLE new_table_name LIKE old_table_name;
说明 :若复制其他数据库的表,需在 old_table_name 前添加数据库名(如 db_test.t_test)。
示例 (复制 t_test 结构到当前库,命名为 t_test2):
CREATE TABLE t_test2 LIKE t_test;5.5 复制表数据
-
表结构一致:
INSERT INTO table_name_new SELECT * FROM table_name_old; -
表结构不一致:
INSERT INTO table_name_new (col1, col2) SELECT col1, col2 FROM table_name_old;
5.6 修改表名
语法 :ALTER TABLE old_table_name RENAME new_table_name;
示例:
ALTER TABLE t_test1 RENAME t_test2;5.7 增加字段
语法:
ALTER TABLE table_name ADD col_name data_type;-
插入首位:
ALTER TABLE table_name ADD col_name data_type FIRST; -
插入指定字段后:
ALTER TABLE table_name ADD col_name data_type AFTER existing_col;
示例 (在 t_test 表首位添加 test_address):
ALTER TABLE t_test ADD test_address VARCHAR(255) FIRST;5.8 删除字段
语法 :ALTER TABLE table_name DROP col_name;
示例:
ALTER TABLE t_test DROP test1;5.9 修改字段数据类型
语法 :ALTER TABLE table_name MODIFY col_name new_data_type;
示例 (将 test2 类型从 VARCHAR 改为 CHAR(100)):
ALTER TABLE t_test MODIFY test2 CHAR(100);5.10 修改字段名称
语法 :ALTER TABLE table_name CHANGE old_col_name new_col_name data_type;
示例 (将 test_address 改为 address,类型为 CHAR(100)):
ALTER TABLE t_test CHANGE test_address address CHAR(100);5.11 设置主键
-
创建表时设置:
CREATE TABLE student ( xs_id CHAR(12), xs_name CHAR(10), PRIMARY KEY (xs_id) -- 单字段主键 ); CREATE TABLE student ( xs_id CHAR(12), xs_name CHAR(10), PRIMARY KEY (xs_id, xs_name) -- 组合主键 ); -
创建表后设置:
ALTER TABLE student ADD PRIMARY KEY (xs_id);
5.12 删除主键
语法 :ALTER TABLE table_name DROP PRIMARY KEY;
示例:
ALTER TABLE student DROP PRIMARY KEY;5.13 设置外键
作用 :确保引用完整性(如 t_test2.id 必须在 t_test1.id 中存在)。
语法:
ALTER TABLE table_name
ADD CONSTRAINT fk_name
FOREIGN KEY (foreign_col)
REFERENCES referenced_table (primary_col);示例 (将 t_test2.id 设为外键,引用 t_test1.id):
ALTER TABLE t_test2
ADD CONSTRAINT fk1
FOREIGN KEY (id)
REFERENCES t_test1(id);5.14 删除外键
步骤:
-
查找外键名:
SHOW CREATE TABLE table_name; -
删除外键:
ALTER TABLE table_name DROP FOREIGN KEY fk_name;
示例:-- 查看外键名
SHOW CREATE TABLE t_test2;-- 删除外键(假设外键名为 fk1)
ALTER TABLE t_test2 DROP FOREIGN KEY fk1;
六、数据更新操作
6.1 插入记录(INSERT)
6.1.1 插入单条记录
语法:
INSERT INTO 表名 [(字段1, 字段2, ...)] VALUES (值1, 值2, ...);说明:
-
字段列表可选(不指定则需按表结构顺序提供所有值)。
-
值类型需与字段数据类型匹配。
示例:-- 插入完整字段
INSERT INTO test (id, name) VALUES (123, 'tt');-- 插入指定字段(id)
INSERT INTO test (id) VALUES (124);
6.1.2 插入多条记录
语法:
INSERT INTO 表名 VALUES (值1, 值2, ...), (值1, 值2, ...), ...;示例:
INSERT INTO test VALUES
(125, 'ttww'),
(126, 'ttwwe'),
(127, 'ttqqq');6.1.3 子查询插入多条记录
语法:
INSERT INTO 表名1 [(字段1, 字段2, ...)]
SELECT 字段1, 字段2, ...
FROM 表名2 [WHERE 条件];说明:
-
目标表字段与查询字段数量、类型需一致。
示例:-- 插入所有字段
INSERT INTO test1 SELECT * FROM test2;-- 插入指定字段
INSERT INTO test1 (id, name) SELECT id, name FROM test2;
6.2 删除记录(DELETE)
语法:
DELETE FROM 表名 WHERE 条件;说明:
-
必须指定
WHERE条件 !否则会删除整表数据。
示例:-- 删除所有记录(危险!慎用)
DELETE FROM test;-- 删除指定条件记录
DELETE FROM test WHERE id = 123;
6.3 更新记录(UPDATE)
语法:
UPDATE 表名
SET 字段1 = 值1, 字段2 = 值2, ...
WHERE 条件;说明:
-
必须指定
WHERE条件 !否则会更新整表数据。
示例:-- 更新指定条件的记录
UPDATE test
SET name = 'new_name'
WHERE id = 123;-- 同时更新多字段
UPDATE test
SET name = 'updated', status = 1
WHERE id = 124;
⚠️ 重要提示
| 操作 | 未指定 WHERE 的后果 |
|---|---|
DELETE |
清空整表(不可逆!) |
UPDATE |
全表字段被覆盖(数据丢失) |
建议 :执行前先用
SELECT验证条件,或在测试环境操作。
七、数据查询操作
7.1 单表查询
7.1.1 基础语法
sql
SELECT [列名1, 列名2, ... | *] [AS 别名] FROM 表名;- 通配符
*:匹配所有列 - 别名
AS:为字段/结果指定临时名称(如name AS 姓名)
示例:
SELECT id, name AS 姓名 FROM test; -- 为name字段取别名
SELECT * FROM test; -- 查询所有列7 .1.2 条件过滤(WHERE)
| 关键字 | 作用 | 示例 |
|---|---|---|
AND/OR |
连接多个条件 | WHERE age > 20 AND salary > 5000 |
BETWEEN ... AND |
范围查询 | WHERE price BETWEEN 100 AND 200 |
IS NULL |
查询空值 | WHERE email IS NULL |
IN |
查询集合中值 | WHERE city IN ('北京', '上海') |
LIKE |
模糊查询 | WHERE name LIKE '张%'(以张开头) |
通配符:
%:匹配任意长度字符(如name LIKE '%明%')_:匹配单个字符(如name LIKE '张_')
7.1.3 排序(ORDER BY)
SELECT * FROM 表名 ORDER BY 列名 [ASC|DESC];-
默认升序(ASC) ,
DESC为降序
示例:SELECT * FROM books ORDER BY price DESC; -- 按价格降序
7.1.4 聚集函数
| 函数 | 作用 | 示例 |
|---|---|---|
COUNT() |
计数 | SELECT COUNT(*) FROM books; |
MAX() |
最大值 | SELECT MAX(price) FROM books; |
MIN() |
最小值 | SELECT MIN(price) FROM books; |
SUM() |
求和 | SELECT SUM(salary) FROM employees; |
AVG() |
平均值 | SELECT AVG(age) FROM students; |
7.1.5 分组(GROUP BY)
SELECT 聚集函数(列), 分组列 FROM 表名 GROUP BY 分组列;示例(统计出版社图书数量):
SELECT COUNT(*), pressName
FROM books
GROUP BY pressName;结果说明 :
pressName为 "人民邮电出版社" 的记录数 = 1,"清华大学出版社" = 6。
7.2 连接查询
7.2.1 简单连接(逗号分隔)
SELECT 表1.列, 表2.列
FROM 表1, 表2
WHERE 表1.关联列 = 表2.关联列;示例:
SELECT b.reader_id, br.book_name
FROM books b, borrow_record br
WHERE b.ISBN = br.ISBN;7.2.2 JOIN 连接
| 类型 | 语法 | 说明 |
|---|---|---|
| 内连接 | SELECT * FROM 表1 INNER JOIN 表2 ON 条件; |
仅返回匹配的记录 |
| 左连接 | SELECT * FROM 表1 LEFT JOIN 表2 ON 条件; |
保留左表所有记录 |
| 右连接 | SELECT * FROM 表1 RIGHT JOIN 表2 ON 条件; |
保留右表所有记录 |
示例(左连接):
SELECT * FROM books b
LEFT JOIN borrow_record br
ON b.ISBN = br.ISBN;⚠️ 注意 :
ON用于指定连接条件,不可用WHERE替代(否则会丢失左表空值记录)。
7.3 嵌套查询(子查询)
**7.3.1 IN 谓语
SELECT * FROM 表1
WHERE 列名 IN (SELECT 列名 FROM 表2 WHERE 条件);示例:
SELECT * FROM books
WHERE isbn IN (SELECT isbn FROM borrow_record WHERE reader_id = '201801');7.3.2 比较运算符
SELECT * FROM 表1
WHERE 列名 > (SELECT 列名 FROM 表2 WHERE 条件);示例:
SELECT * FROM books
WHERE isbn = (SELECT isbn FROM borrow_record WHERE reader_id = '201801');7.3.3 ANY / ALL 谓语
SELECT * FROM 表1
WHERE 列名 > ANY (SELECT 列名 FROM 表2 WHERE 条件);示例(查询未借阅的图书):
SELECT * FROM books
WHERE isbn <> ALL (SELECT isbn FROM borrow_record WHERE reader_id = '201801');7.3.4 EXISTS 谓语
SELECT * FROM 表1
WHERE NOT EXISTS (SELECT 1 FROM 表2 WHERE 表1.列 = 表2.列 AND 条件);示例(查询未借阅的图书):
SELECT * FROM books
WHERE NOT EXISTS (
SELECT 1
FROM borrow_record
WHERE isbn = books.isbn AND reader_id = '201801'
);7.4 合并查询(UNION)
作用:合并两个查询结果(去重)
SELECT 列 FROM 表1
UNION
SELECT 列 FROM 表2;示例:
SELECT * FROM t_major1
UNION
SELECT * FROM t_major;要求:
- 两个查询的列数和数据类型必须一致
- 默认去重,用
UNION ALL保留重复项
⚠️ 关键安全提示
| 操作 | 风险 | 避免方法 |
|---|---|---|
SELECT * |
传输冗余数据,影响性能 | 显式指定所需字段 |
无条件 DELETE/UPDATE |
清空整表数据 | 必须添加 WHERE 条件 |
| 嵌套查询未优化 | 慢查询导致数据库阻塞 | 确保子查询返回结果集小 |
最佳实践:
- 单表查询避免
SELECT *,只选必要字段- 连接查询优先用
JOIN语法(清晰、性能高)- 嵌套查询用
EXISTS替代IN(大数据集性能更好)