一、任务背景
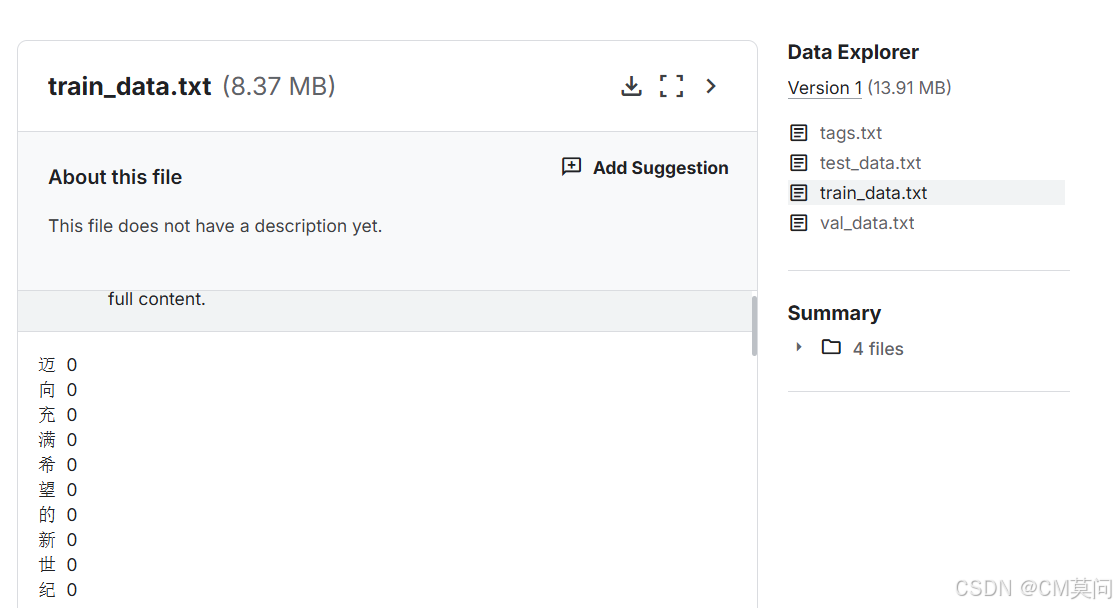
本文进行**中文命名实体识别** 的python实践,使用来自Kaggle的人民日报数据集《renMinRiBao》。这里,我们将构建一个Bert-BiLSTM-CRF模型,并基于该数据集对模型进行微调训练。从下图中可以看到,这个数据集总共包括四个文件,本次实践将会使用tags.txt中的标签信息,并使用train_data.txt中的数据训练模型,用test_data.txt中的数据测试模型。
二、python建模
1、数据读取
首先,我们读取训练集的数据。
python
train = pd.read_csv('/kaggle/input/renminribao/train_data.txt', header=None)
train.columns = ['标注']
print('数据量:', len(train))
train.head()
可以看到,总共有110多万行数据,每一行是一个汉字字符以及其对应的标注标签(BIO格式标注)。接着,我们根据需要来构建符合建模规范的数据集。
python
# 这里根据对数据集的探查,我们需要去掉一些空行或者没有标注的行
annotation = [li for li in train['标注'].tolist() if li.split(' ')[0].strip()!='' and li.split(' ')[1].strip()!='']
# 手动划分字符和对应的标签
data = [a.split(' ')[0].strip() for a in annotation]
label = [a.split(' ')[1].strip() for a in annotation]
# 对数据进行分块,每一个数据块长度为128个字符
data = [data[i:i+128] for i in range(0, len(data), 128)]
label = [label[i:i+128] for i in range(0, len(label), 128)]
print('原始数据量:', len(data))
tempd = []
templ = []
# 由于上面是简单的分块操作,不可避免会导致一些实体被分割到了不同的块中,因此需要去掉不合规的数据块
for d, l in zip(data, label):
# 数据块的开头不能是I,结尾不能是B,这样能够保证每一个数据块中的实体都是合规的,即B开头,I跟在B的后面
if 'I-' in l[0] or l[-1]=='B':
continue
tempd.append(d)
templ.append(l)
data, label = tempd, templ
print('清洗后的数据量:', len(data))
print('数据样例:', data[0])
print('标签样例:', label[0])
然后,我们获取标签信息并构建标签-索引字典,以便用于模型训练。
python
tags = pd.read_csv('/kaggle/input/renminribao/tags.txt', header=None)
tags.columns = ['标签']
# 构建标签-索引字典
tag_to_idx = {tag: i for i, tag in enumerate(tags['标签'].tolist())}
tag_to_idx['X'] = len(tag_to_idx) # 添加特殊标签 'X',用于表示padding部分的内容
print(tag_to_idx)
2、模型输入构建
这一步,我们初始化Bert模型并将句子和标签转换为Bert模型需要的输入格式。
python
from transformers import BertTokenizer, BertModel
# 加载预训练的BERT模型和分词器
model_name = "bert-base-chinese"
tokenizer = BertTokenizer.from_pretrained(model_name)
bert_model = BertModel.from_pretrained(model_name)
import torch
# 将句子和标签转换为BERT的输入格式,并对齐标签
def prepare_sequence_bert(sentences, tags, tokenizer, tag_to_ix):
input_ids = []
attention_masks = []
label_ids = []
for sentence, tag_seq in zip(sentences, tags):
input_id = []
for word, tag in zip(sentence, tag_seq):
# 由于这里的每个word就是单个汉字而bert-base-chinese的词典就是按照单个汉字来的,所以这里直接转换为索引即可
input_id.append(tokenizer.convert_tokens_to_ids(word))
attention_mask = [1] * len(input_id)
label_id = [tag_to_ix[tag] for tag in tag_seq]
input_ids.append(input_id)
attention_masks.append(attention_mask)
label_ids.append(label_id)
# 填充序列
max_len = max(len(seq) for seq in input_ids)
input_ids = [seq + [0] * (max_len - len(seq)) for seq in input_ids]
attention_masks = [seq + [0] * (max_len - len(seq)) for seq in attention_masks]
label_ids = [seq + [tag_to_ix['X']] * (max_len - len(seq)) for seq in label_ids]
return torch.tensor(input_ids), torch.tensor(attention_masks), torch.tensor(label_ids)
# 数据集
input_ids, attention_masks, label_ids = prepare_sequence_bert(data, label, tokenizer, tag_to_idx)
print('input_ids样例:', input_ids[0])
print('attention_masks样例:', attention_masks[0])
print('标签样例:', label_ids[0])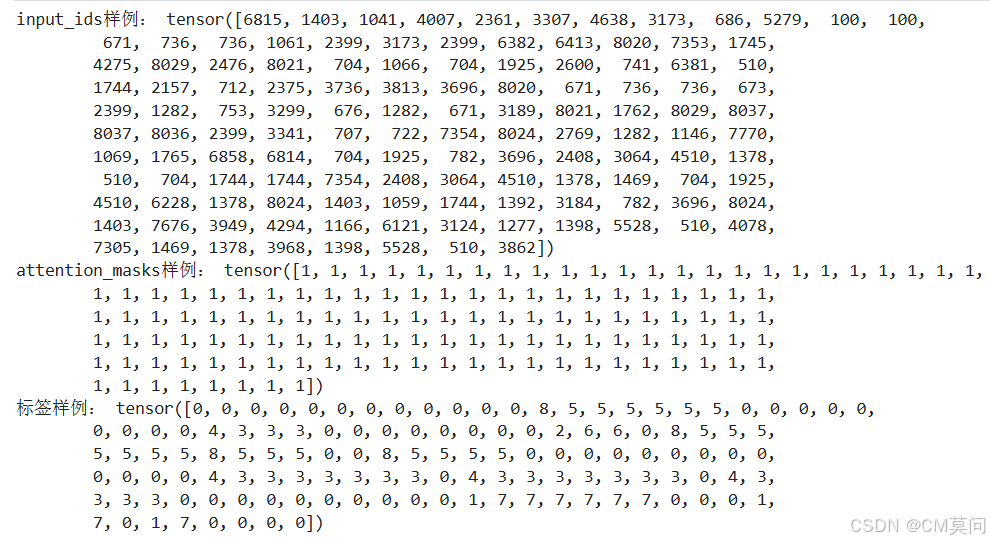
3、torch数据集类构建
接下来,我们构建一个类用于处理数据集。
python
from torch.utils.data import Dataset, DataLoader
class taskDataset(Dataset):
def __init__(self, input_ids, attention_masks, label_ids):
self.input_ids = input_ids
self.attention_masks = attention_masks
self.label_ids = label_ids
def __len__(self):
return len(self.input_ids)
def __getitem__(self, idx):
return torch.tensor(self.input_ids[idx], dtype=torch.long), torch.tensor(self.attention_masks[idx], dtype=torch.long),\
torch.tensor(self.label_ids[idx], dtype=torch.long)
train_dataset = taskDataset(input_ids, attention_masks, label_ids)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)4、torch模型类构建
接着,我们构建模型类。敲重点!下面代码中调用的torchcrf库,在安装的时候对应的库名是pytorch-crf,也就是要pip install pytorch-crf!此外,由于CRF的作用在于损失构建,这里的模型类中直接写一个函数来计算损失,同时再写一个predict函数用于预测,这与我们以往所构建的模型类有一定区别。
python
import torch.nn as nn
from torchcrf import CRF
class taskModel(nn.Module):
def __init__(self, bert, hidden_size, output_size):
super(taskModel, self).__init__()
self.bert = bert
self.lstm = nn.LSTM(self.bert.config.hidden_size, hidden_size // 2, num_layers=1, bidirectional=True)
self.hidden2tag = nn.Linear(hidden_size, output_size)
self.crf = CRF(output_size, batch_first=True)
def forward(self, input_ids, attention_mask):
# 获取BERT嵌入
bert_outputs = self.bert(input_ids=input_ids, attention_mask=attention_mask)
embeds = bert_outputs.last_hidden_state
lstm_out, _ = self.lstm(embeds)
emissions = self.hidden2tag(lstm_out)
return emissions
def loss(self, emissions, tags, attention_mask):
return -self.crf(emissions, tags, mask=attention_mask.byte())
def predict(self, input_ids, attention_mask):
emissions = self.forward(input_ids, attention_mask)
return self.crf.decode(emissions, mask=attention_mask.byte())5、模型训练
这里,我们设置参数,并实例化一个模型并设置必要的参数,例如我们仅让bert模型的最后一层的output子层参与微调过程中的反向传播。
python
# 参数设置
EPOCHS = 10
HIDDEN_DIM = 128
# 模型实例化
device = torch.device('cuda') if torch.cuda.is_available() else 'cpu'
model = taskModel(bert_model, HIDDEN_DIM, len(tag_to_idx))
optimizer = torch.optim.Adam(model.parameters(), lr=3e-3)
for name, param in model.named_parameters():
if '11.out' in name:
param.requires_grad = True
else:
param.requires_grad = False
for name, param in model.named_parameters():
if param.requires_grad:
print(name, len(param))
model.to(device)
接着,编写模型训练的代码训练一个Bert-BiLSTM-CRF模型。
python
from tqdm import tqdm
# 训练模型
model.train()
for epoch in range(EPOCHS):
total_loss = 0
for ids, masks, lids in tqdm(train_loader):
ids = ids.to(device)
masks = masks.to(device)
lids = lids.to(device)
optimizer.zero_grad()
emissions = model(ids, masks)
loss = model.loss(emissions, lids, masks)
total_loss += loss.item()
loss.backward()
optimizer.step()
print(f"Epoch {epoch + 1}/{EPOCHS}, Loss: {total_loss/len(train_loader)}")6、模型测试
这一步我们读取test_data.txt文件中的数据来测试模型。下列的演示代码中我们仅使用前5000个字符作为测试集。
python
test = pd.read_csv('/kaggle/input/renminribao/test_data.txt', header=None)
test.columns = ['标注']
test_annotation = [li for li in test['标注'].tolist() if li.split(' ')[0].strip()!='' and li.split(' ')[1].strip()!=''][:5000]
test_data = [a.split(' ')[0].strip() for a in test_annotation]
test_label = [a.split(' ')[1].strip() for a in test_annotation]
test_data = [test_data[i:i+128] for i in range(0, len(test_data), 128)]
test_label = [test_label[i:i+128] for i in range(0, len(test_label), 128)]
test_input_ids, test_attention_masks, test_label_ids = prepare_sequence_bert(test_data, test_label, tokenizer, tag_to_idx)预测环节,我们设置成单条数据预测,虽然速度慢,但是符合实际应用场景。但在汇总预测结果的时候我们使用单个列表汇总所有字符的预测结果,以便跟test_data.txt的格式对齐。
python
model.eval()
predict_tokens = []
predict_tags = []
real_tags = []
with torch.no_grad():
for ids, masks, lids in zip(test_input_ids, test_attention_masks, test_label_ids):
ids = ids.reshape(1, -1)
masks = masks.reshape(1, -1)
lids = lids.reshape(1, -1)
ids = ids.to(device)
masks = masks.to(device)
lids = lids.to(device)
prediction = model.predict(ids, masks)
tokens = tokenizer.convert_ids_to_tokens(ids.squeeze().tolist())
pred_tags = [list(tag_to_idx.keys())[list(tag_to_idx.values()).index(idx)] for idx in prediction[0]]
true_tags = [list(tag_to_idx.keys())[list(tag_to_idx.values()).index(idx)] for idx in lids.tolist()[0]]
predict_tokens += tokens
predict_tags += pred_tags
real_tags += true_tags可以打印一部分结果出来看看数据样例。看得出来训练出来的模型预测的结果还是会存在不合规(I前面不是B)、漏预测的情况。
python
for tok, ptag, rtag in zip(predict_tokens[:1000], predict_tags[:1000], real_tags[:1000]):
if rtag!='O':
print(tok, ' ', ptag, ' ', rtag)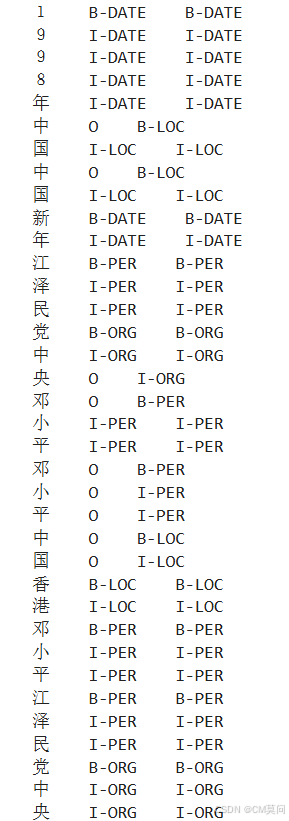
下面计算一下实体级别的召回率。
python
def calculate_entity_recall(true_labels, predicted_labels):
def extract_entities(labels):
entities = []
current_entity = []
for label in labels:
if label.startswith('B-'):
if current_entity:
entities.append(current_entity)
current_entity = []
current_entity.append(label)
elif label.startswith('I-'):
# 如果current_entity是空的,意味着I前面没有B,我们去掉这样的实体结果
if current_entity:
current_entity.append(label)
else:
if current_entity:
entities.append(current_entity)
current_entity = []
if current_entity:
entities.append(current_entity)
return entities
true_entities = extract_entities(true_labels)
predicted_entities = extract_entities(predicted_labels)
true_entity_set = set(tuple(entity) for entity in true_entities)
predicted_entity_set = set(tuple(entity) for entity in predicted_entities)
true_positives = len(true_entity_set.intersection(predicted_entity_set))
false_negatives = len(true_entity_set - predicted_entity_set)
recall = true_positives / (true_positives + false_negatives) if (true_positives + false_negatives) > 0 else 0
return recall
recall = calculate_entity_recall(real_tags, predict_tags)
print(f"实体级别的召回率: {recall:.2f}")可见召回率为0.73,还有进一步优化的空间!
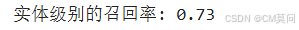
三、完整代码
python
import pandas as pd
from transformers import BertTokenizer, BertModel
from torch.utils.data import Dataset, DataLoader
import torch
import torch.nn as nn
from tqdm import tqdm
from torchcrf import CRF
train = pd.read_csv('/kaggle/input/renminribao/train_data.txt', header=None)
train.columns = ['标注']
print('数据量:', len(train))
# 这里根据对数据集的探查,我们需要去掉一些空行或者没有标注的行
annotation = [li for li in train['标注'].tolist() if li.split(' ')[0].strip()!='' and li.split(' ')[1].strip()!='']
# 手动划分字符和对应的标签
data = [a.split(' ')[0].strip() for a in annotation]
label = [a.split(' ')[1].strip() for a in annotation]
# 对数据进行分块,每一个数据块长度为128个字符
data = [data[i:i+128] for i in range(0, len(data), 128)]
label = [label[i:i+128] for i in range(0, len(label), 128)]
print('原始数据量:', len(data))
tempd = []
templ = []
# 由于上面是简单的分块操作,不可避免会导致一些实体被分割到了不同的块中,因此需要去掉不合规的数据块
for d, l in zip(data, label):
# 数据块的开头不能是I,结尾不能是B,这样能够保证每一个数据块中的实体都是合规的,即B开头,I跟在B的后面
if 'I-' in l[0] or l[-1]=='B':
continue
tempd.append(d)
templ.append(l)
data, label = tempd, templ
print('清洗后的数据量:', len(data))
print('数据样例:', data[0])
print('标签样例:', label[0])
tags = pd.read_csv('/kaggle/input/renminribao/tags.txt', header=None)
tags.columns = ['标签']
# 构建标签-索引字典
tag_to_idx = {tag: i for i, tag in enumerate(tags['标签'].tolist())}
tag_to_idx['X'] = len(tag_to_idx) # 添加特殊标签 'X',用于表示padding部分的内容
print(tag_to_idx)
# 加载预训练的BERT模型和分词器
model_name = "bert-base-chinese"
tokenizer = BertTokenizer.from_pretrained(model_name)
bert_model = BertModel.from_pretrained(model_name)
# 将句子和标签转换为BERT的输入格式,并对齐标签
def prepare_sequence_bert(sentences, tags, tokenizer, tag_to_ix):
input_ids = []
attention_masks = []
label_ids = []
for sentence, tag_seq in zip(sentences, tags):
input_id = []
for word, tag in zip(sentence, tag_seq):
# 由于这里的每个word就是单个汉字而bert-base-chinese的词典就是按照单个汉字来的,所以这里直接转换为索引即可
input_id.append(tokenizer.convert_tokens_to_ids(word))
attention_mask = [1] * len(input_id)
label_id = [tag_to_ix[tag] for tag in tag_seq]
input_ids.append(input_id)
attention_masks.append(attention_mask)
label_ids.append(label_id)
# 填充序列
max_len = max(len(seq) for seq in input_ids)
input_ids = [seq + [0] * (max_len - len(seq)) for seq in input_ids]
attention_masks = [seq + [0] * (max_len - len(seq)) for seq in attention_masks]
label_ids = [seq + [tag_to_ix['X']] * (max_len - len(seq)) for seq in label_ids]
return torch.tensor(input_ids), torch.tensor(attention_masks), torch.tensor(label_ids)
# 数据集
input_ids, attention_masks, label_ids = prepare_sequence_bert(data, label, tokenizer, tag_to_idx)
print('input_ids样例:', input_ids[0])
print('attention_masks样例:', attention_masks[0])
print('标签样例:', label_ids[0])
class taskDataset(Dataset):
def __init__(self, input_ids, attention_masks, label_ids):
self.input_ids = input_ids
self.attention_masks = attention_masks
self.label_ids = label_ids
def __len__(self):
return len(self.input_ids)
def __getitem__(self, idx):
return torch.tensor(self.input_ids[idx], dtype=torch.long), torch.tensor(self.attention_masks[idx], dtype=torch.long),\
torch.tensor(self.label_ids[idx], dtype=torch.long)
train_dataset = taskDataset(input_ids, attention_masks, label_ids)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
class taskModel(nn.Module):
def __init__(self, bert, hidden_size, output_size):
super(taskModel, self).__init__()
self.bert = bert
self.lstm = nn.LSTM(self.bert.config.hidden_size, hidden_size // 2, num_layers=1, bidirectional=True)
self.hidden2tag = nn.Linear(hidden_size, output_size)
self.crf = CRF(output_size, batch_first=True)
def forward(self, input_ids, attention_mask):
# 获取BERT嵌入
bert_outputs = self.bert(input_ids=input_ids, attention_mask=attention_mask)
embeds = bert_outputs.last_hidden_state
lstm_out, _ = self.lstm(embeds)
emissions = self.hidden2tag(lstm_out)
return emissions
def loss(self, emissions, tags, attention_mask):
return -self.crf(emissions, tags, mask=attention_mask.byte())
def predict(self, input_ids, attention_mask):
emissions = self.forward(input_ids, attention_mask)
return self.crf.decode(emissions, mask=attention_mask.byte())
# 参数设置
EPOCHS = 10
HIDDEN_DIM = 128
# 模型实例化
device = torch.device('cuda') if torch.cuda.is_available() else 'cpu'
model = taskModel(bert_model, HIDDEN_DIM, len(tag_to_idx))
optimizer = torch.optim.Adam(model.parameters(), lr=3e-3)
for name, param in model.named_parameters():
if '11.out' in name:
param.requires_grad = True
else:
param.requires_grad = False
for name, param in model.named_parameters():
if param.requires_grad:
print(name, len(param))
model.to(device)
# 训练模型
model.train()
for epoch in range(EPOCHS):
total_loss = 0
for ids, masks, lids in tqdm(train_loader):
ids = ids.to(device)
masks = masks.to(device)
lids = lids.to(device)
optimizer.zero_grad()
emissions = model(ids, masks)
loss = model.loss(emissions, lids, masks)
total_loss += loss.item()
loss.backward()
optimizer.step()
print(f"Epoch {epoch + 1}/{EPOCHS}, Loss: {total_loss/len(train_loader)}")
test = pd.read_csv('/kaggle/input/renminribao/test_data.txt', header=None)
test.columns = ['标注']
test_annotation = [li for li in test['标注'].tolist() if li.split(' ')[0].strip()!='' and li.split(' ')[1].strip()!=''][:5000]
test_data = [a.split(' ')[0].strip() for a in test_annotation]
test_label = [a.split(' ')[1].strip() for a in test_annotation]
test_data = [test_data[i:i+128] for i in range(0, len(test_data), 128)]
test_label = [test_label[i:i+128] for i in range(0, len(test_label), 128)]
test_input_ids, test_attention_masks, test_label_ids = prepare_sequence_bert(test_data, test_label, tokenizer, tag_to_idx)
model.eval()
predict_tokens = []
predict_tags = []
real_tags = []
with torch.no_grad():
for ids, masks, lids in zip(test_input_ids, test_attention_masks, test_label_ids):
ids = ids.reshape(1, -1)
masks = masks.reshape(1, -1)
lids = lids.reshape(1, -1)
ids = ids.to(device)
masks = masks.to(device)
lids = lids.to(device)
prediction = model.predict(ids, masks)
tokens = tokenizer.convert_ids_to_tokens(ids.squeeze().tolist())
pred_tags = [list(tag_to_idx.keys())[list(tag_to_idx.values()).index(idx)] for idx in prediction[0]]
true_tags = [list(tag_to_idx.keys())[list(tag_to_idx.values()).index(idx)] for idx in lids.tolist()[0]]
predict_tokens += tokens
predict_tags += pred_tags
real_tags += true_tags
def calculate_entity_recall(true_labels, predicted_labels):
def extract_entities(labels):
entities = []
current_entity = []
for label in labels:
if label.startswith('B-'):
if current_entity:
entities.append(current_entity)
current_entity = []
current_entity.append(label)
elif label.startswith('I-'):
# 如果current_entity是空的,意味着I前面没有B,我们去掉这样的实体结果
if current_entity:
current_entity.append(label)
else:
if current_entity:
entities.append(current_entity)
current_entity = []
if current_entity:
entities.append(current_entity)
return entities
true_entities = extract_entities(true_labels)
predicted_entities = extract_entities(predicted_labels)
true_entity_set = set(tuple(entity) for entity in true_entities)
predicted_entity_set = set(tuple(entity) for entity in predicted_entities)
true_positives = len(true_entity_set.intersection(predicted_entity_set))
false_negatives = len(true_entity_set - predicted_entity_set)
recall = true_positives / (true_positives + false_negatives) if (true_positives + false_negatives) > 0 else 0
return recall
recall = calculate_entity_recall(real_tags, predict_tags)
print(f"实体级别的召回率: {recall:.2f}")四、总结
本文使用了人民日报BIO标注数据集进行了命名实体识别的实践,所构建的Bert-BiLSTM-CRF模型取得了73%的实体级召回率,已经有一定的实际应用能力了,但还可以通过优化模型结构、增加训练次数、增加预测约束使得预测结果合规等方式进一步优化模型的性能。