小T导读 :本篇文章是"2024,我想和 TDengine 谈谈"征文活动的优秀投稿之一,作者从数据库运维的角度出发,分享了利用 TDengine Cloud 提供的迁移工具,从 PostgreSQL 数据库到 TDengine 进行数据迁移的完整实践过程。文章详细记录了从创建数据库实例、配置代理,到添加数据源、同步数据的每一个步骤,并结合实际操作中遇到的问题与解决经验,展现了 TDengine Cloud 的便利性和研发团队的高效响应能力。对于关注数据库迁移的技术人员来说,这篇文章是一个宝贵的经验分享。
从数据库管理员(DBA)或运维人员的角度来看,判断数据库是否易用,最直观且通常最先面临的问题便是存量数据库的迁移。如果数据库厂商能够提供一款高效便捷的迁移工具,使用户能够快速将源数据库的数据迁移至目标数据库,不仅能为用户留下良好的第一印象,也将大大促进后续工作的顺利开展。由于线下缺乏合适的迁移工具,因此本文将利用 TDengine Cloud 提供的迁移工具,对从 PostgreSQL 数据库迁移至 TDengine 的过程进行初步体验和探索。
创建数据库实例
首先,我们需要在官方 TDengine Cloud 平台(https://cloud.taosdata.com/auth)上完成注册并创建数据库实例。该过程操作简便,此处不再赘述。
创建新的代理
由于我的源数据库位于本地虚拟机,而目标数据库托管于 TDengine Cloud,因此需要在本地虚拟机上安装代理,以确保 TDengine Cloud 能够访问本地虚拟机中的 PostgreSQL 数据库。
1.点击左侧数据写入菜单,在该界面中,再次点击创建新的代理。
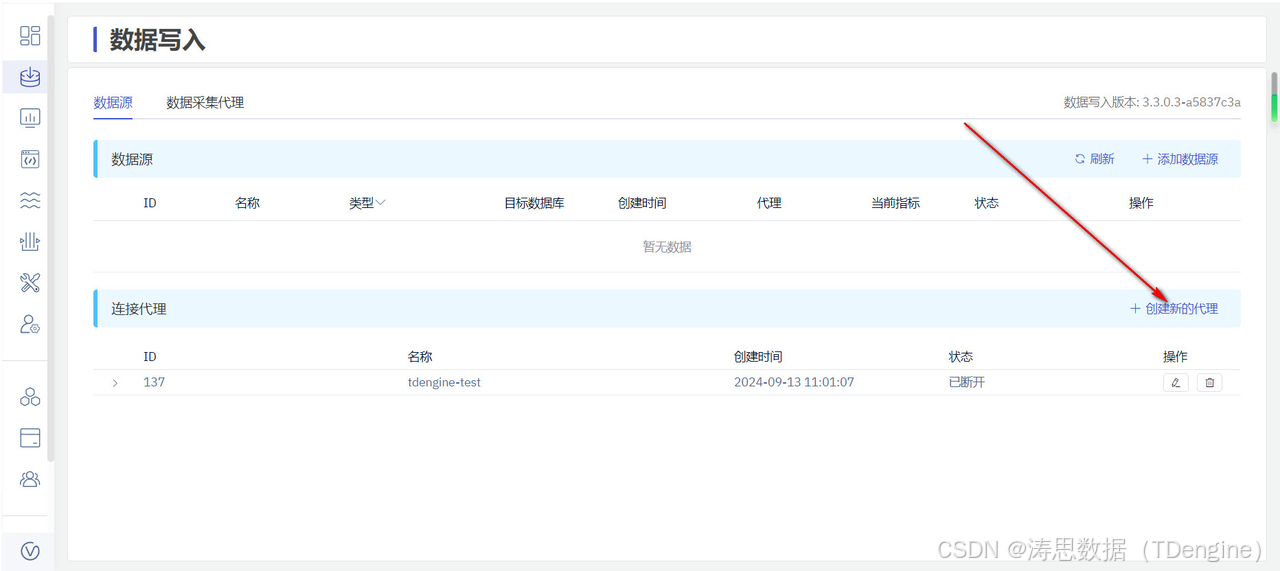
2.根据实际环境选择适配的代理软件版本进行下载。以官网提供的 Linux 版本为例,本文下载的是 x86 架构的代理程序。下载并安装完成后,通过命令 taosx-agent -V 验证安装是否成功,然后点击"下一步"继续操作。
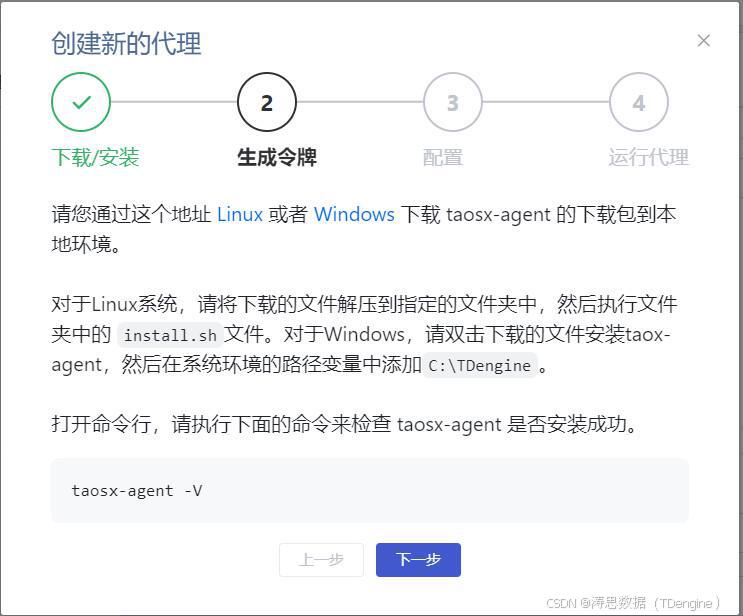
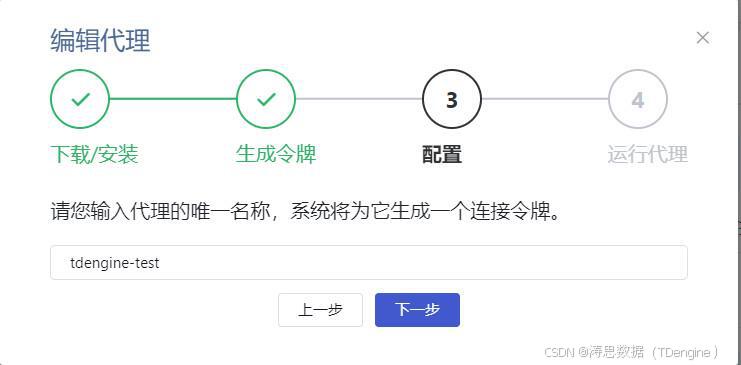
3.在该界面输入代理名称,系统将为它生成一个连接令牌。
4.在已安装代理程序的服务器上,进入 /etc/taos 目录,找到 agent.toml 文件,将系统生成的端点地址和令牌复制到该文件中进行配置。
endpoint="https://39.97.158.21"
token="eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJzdWIiOjEzNywiaWF0IjoxNzI2MTk2NDY3fQ.YmxGvRzlXdOgpXEKiUv-x68TFRzkYhXIRcJgRiWY0xk"
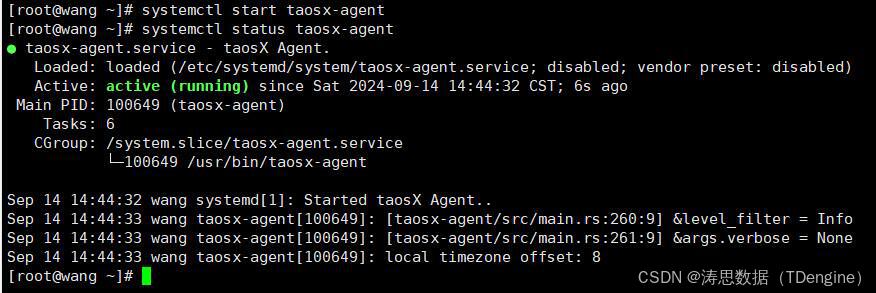
5.启动代理服务并查看服务器的状态。
添加数据源
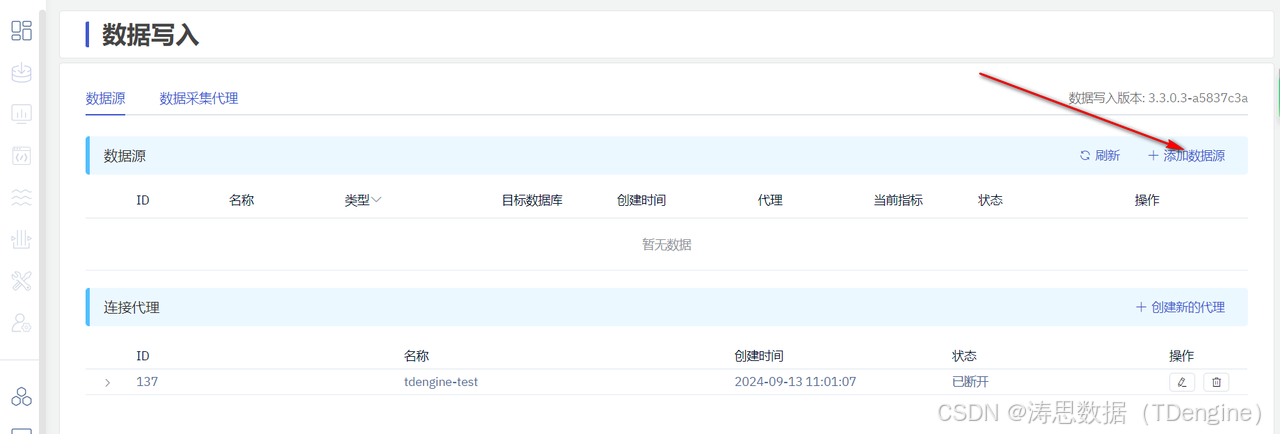
1.在数据写入的页面中,点击添加数据源。
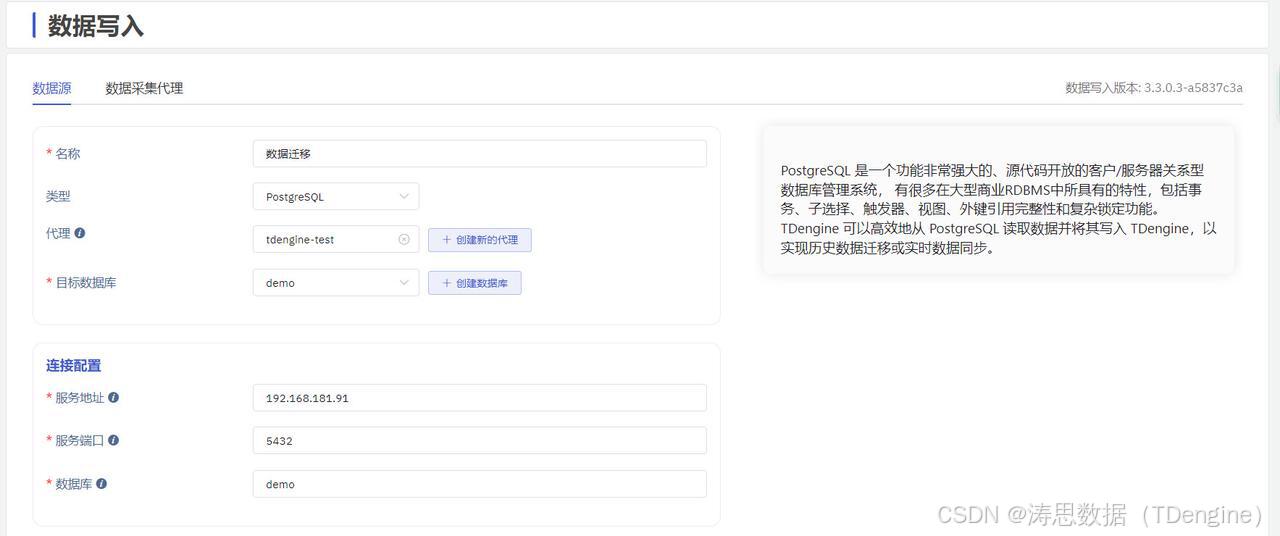
2.在数据源配置界面中,选择数据源类型为 PostgreSQL,代理选择之前创建的代理,目标数据库选择已创建的 demo 数据库(本文直接使用此前创建的数据库)。如果需要,也可参考下一步自行创建新数据库。
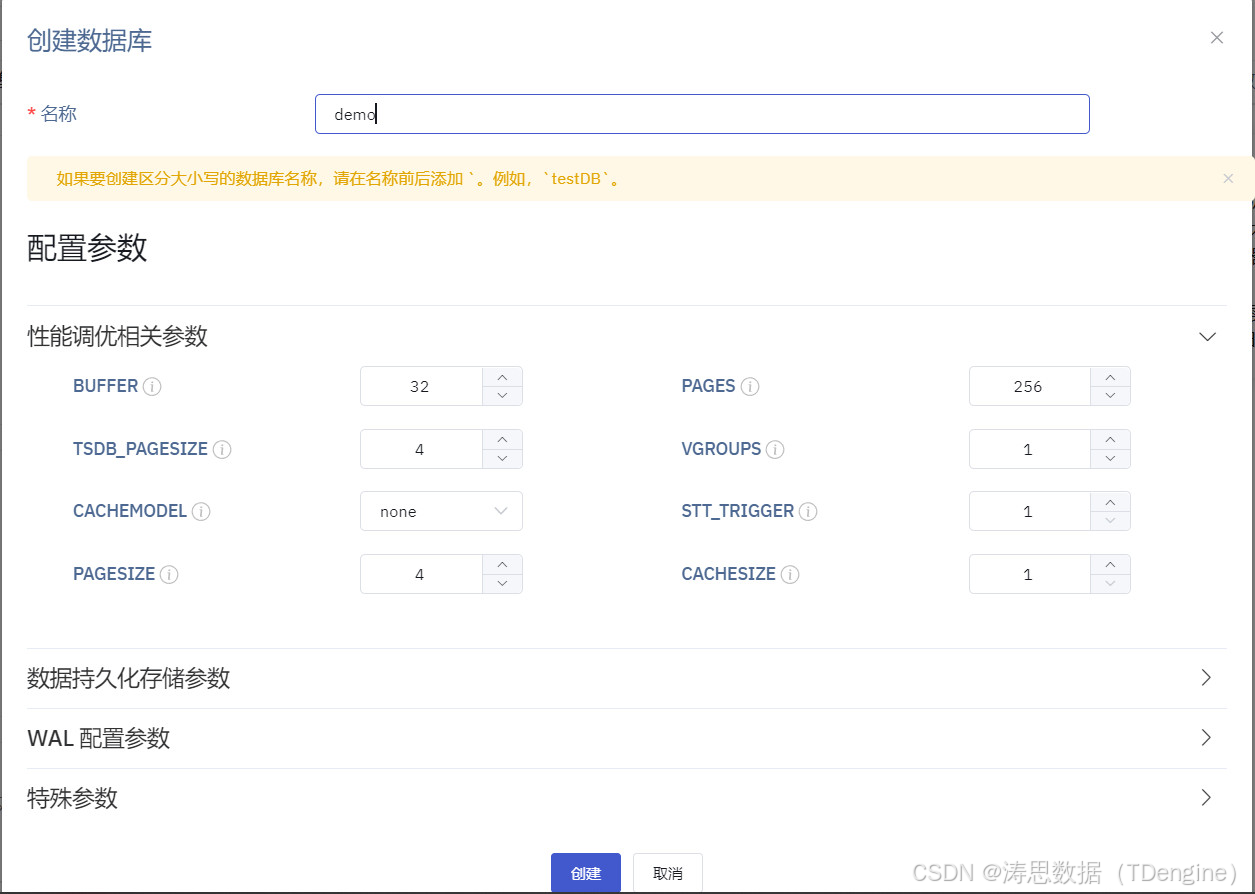
3.创建 demo 数据库。
4.填写 PostgreSQL 数据库 IP、端口、数据库名、用户名、密码等信息。
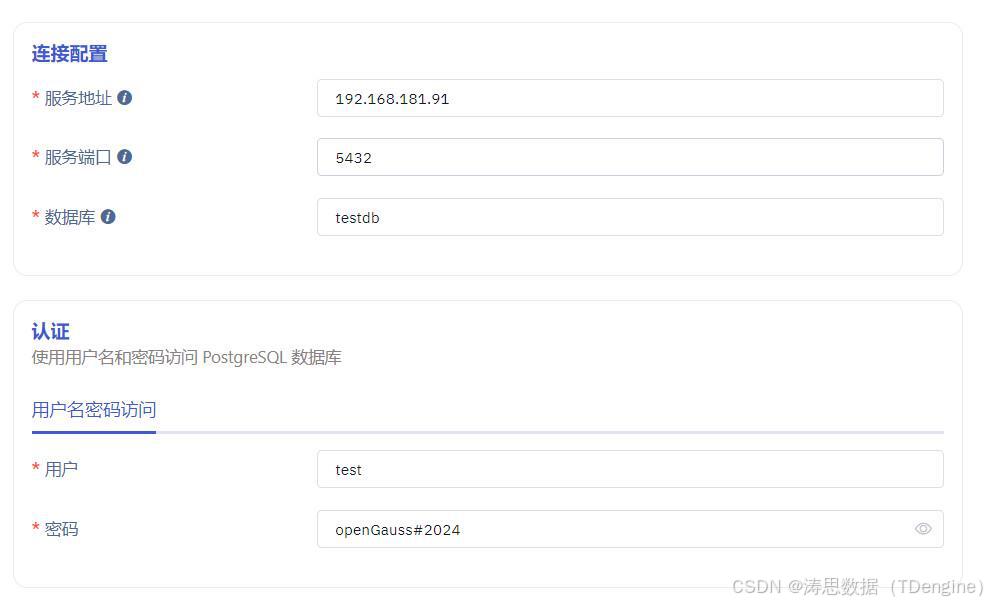
5.检查连通性,如果界面提示"您的数据源可以连通",就表示配置没什么问题。
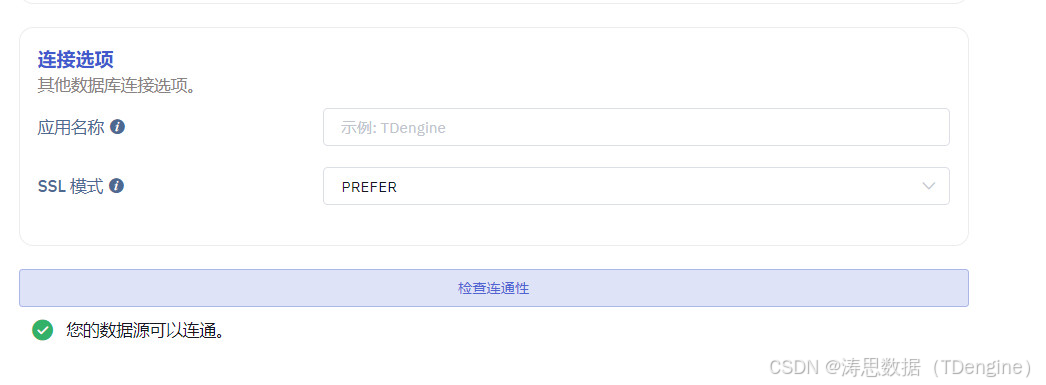
6.配置采集数据的 SQL,在 SQL 中必须包括开始时间与结束时间。
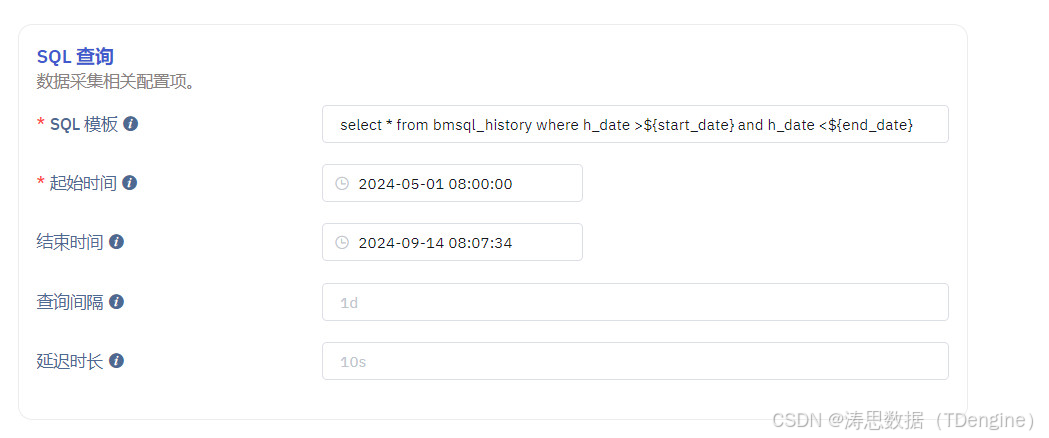
7.点击从服务器检索,观察是否可以成功获取到数据。如果报错,则根据报错提示,修改 SQL 配置。
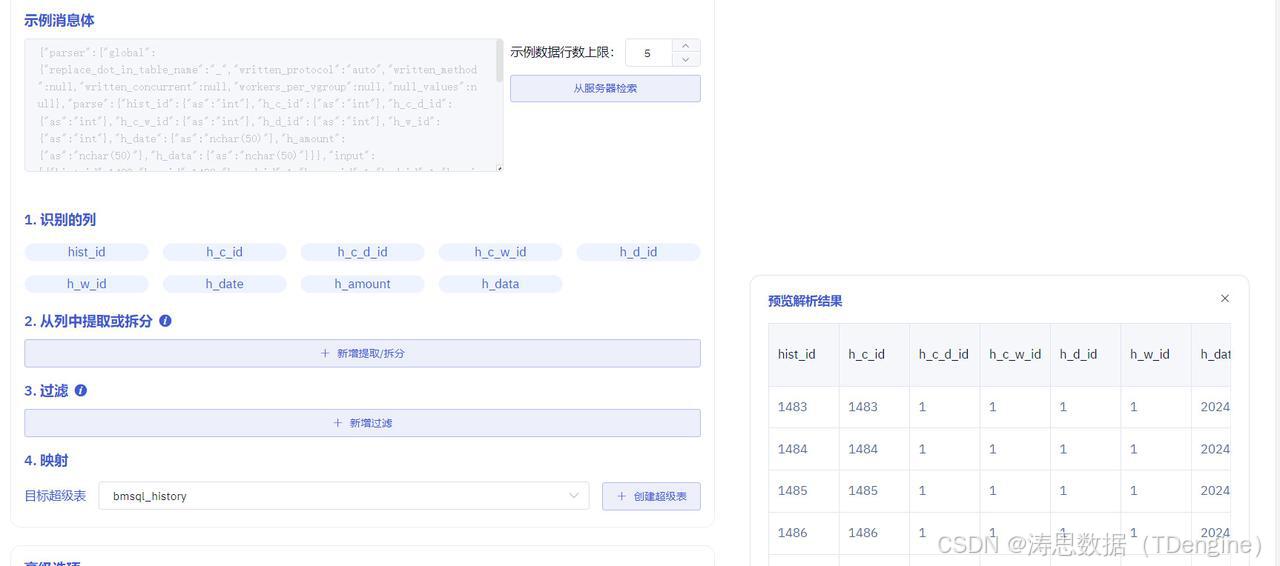
8.点击创建超级表,会自动关联刚才识别到的字段信息,根据需要修改字段类型、填写表名称,最后点击确定按钮。
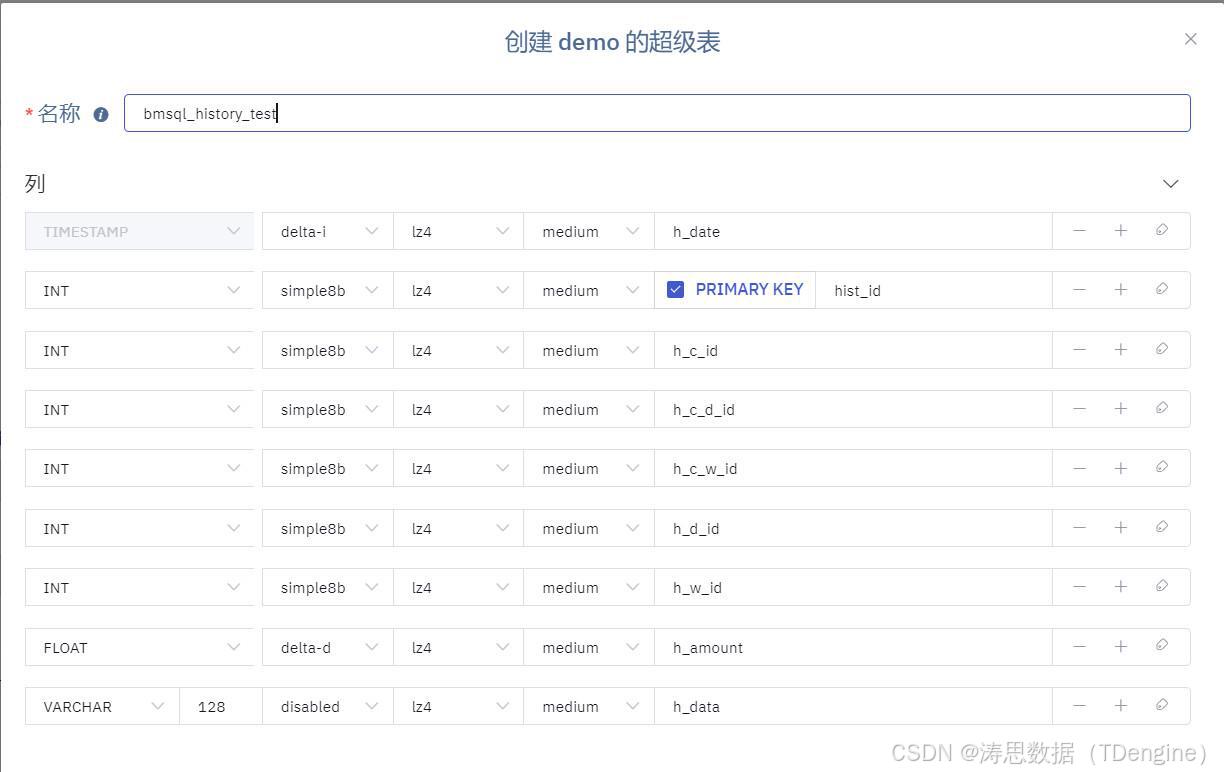
9.点击确认按钮后,超级表就创建成功了。接下来,我们需要在当前界面填写子表和 tag 列对应数据。

10.点击新增按钮,数据源添加成功,并可在数据源列表中查看相关信息。

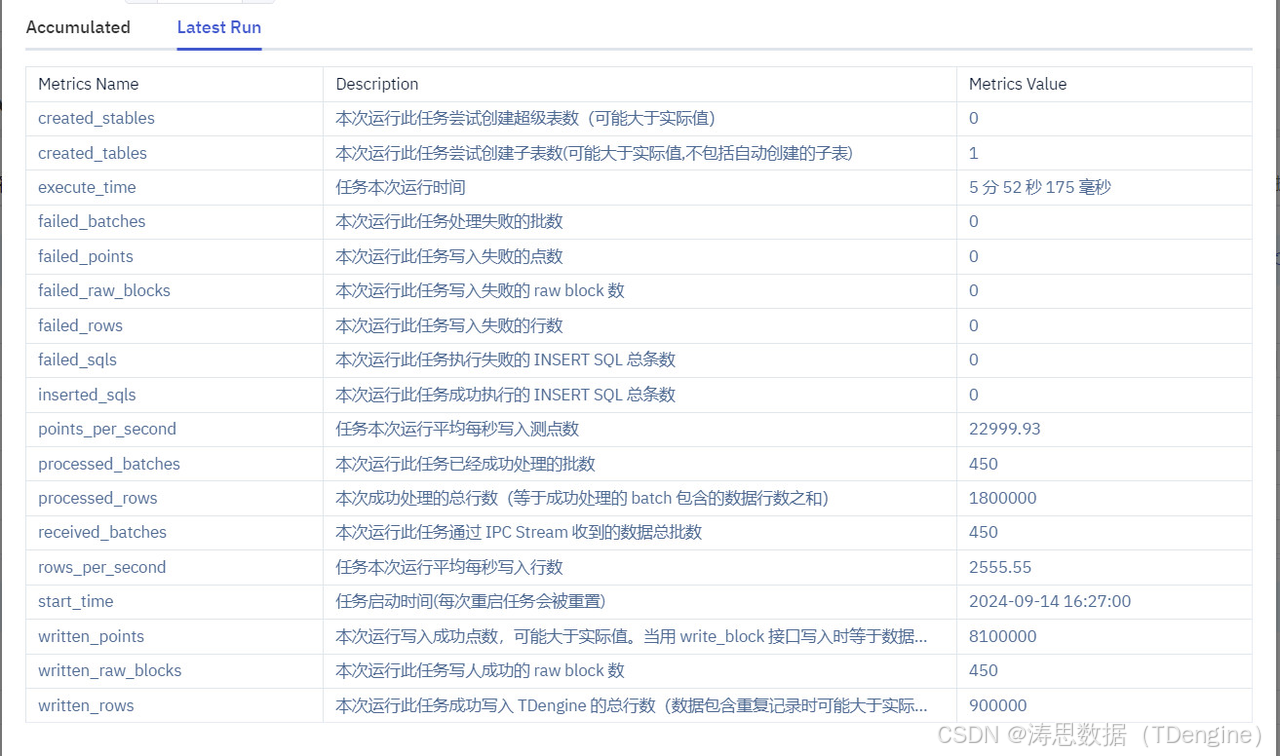
查看数据同步情况
点击刚刚接入数据源的"查看"按钮,即可查看同步信息,包括同步时长、写入速度以及已处理的行数等详细数据。
核对同步数据
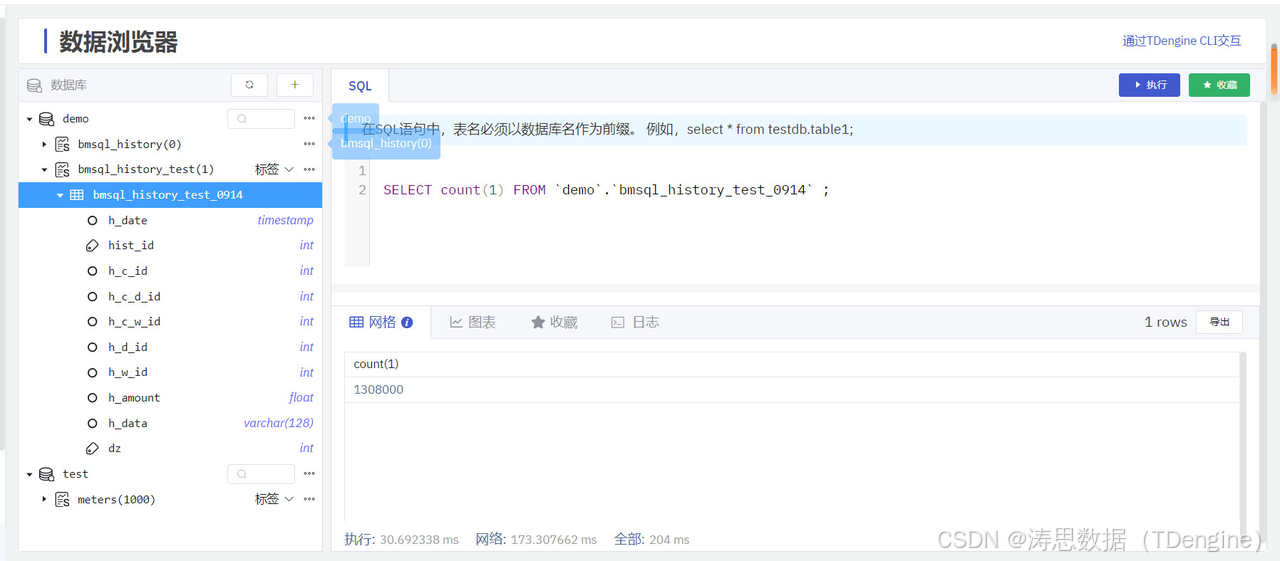
点击数据浏览器,选择对应的数据并查看业务表,就可以看到同步的数据。
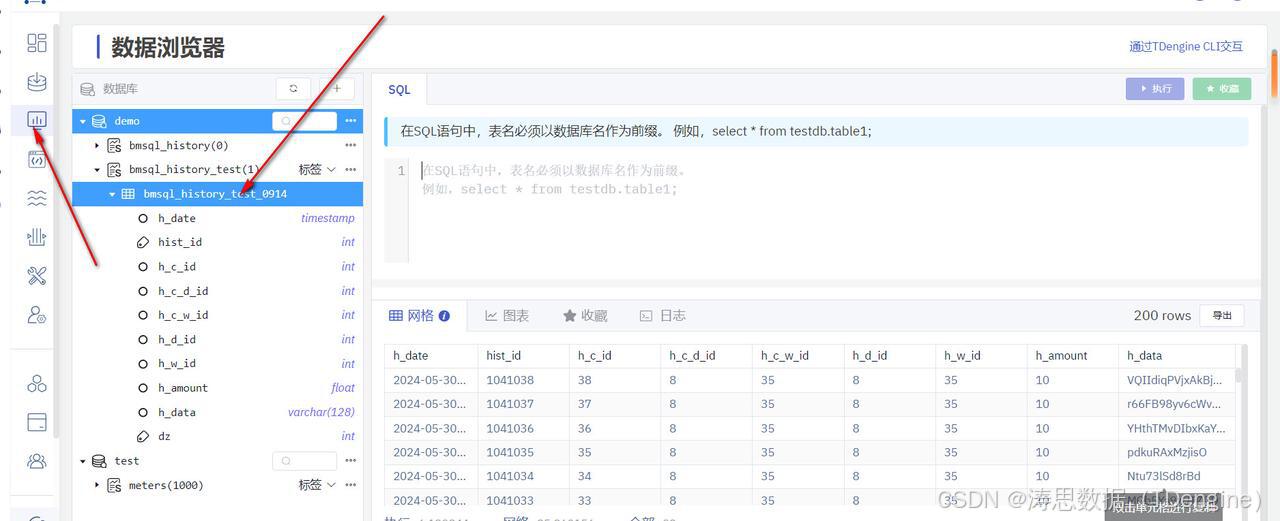
你也可以自行写 SQL 来核对已经同步的数据量。
结语
本次从 PostgreSQL 数据库迁移至 TDengine的体验整体非常流畅。即使在迁移过程中遇到问题,也能够借助官方提供的支持快速定位并解决,充分展现了 TDengine 工具的便捷性和研发团队的高效响应能力。如果你也对 TDengine 的迁移工具感兴趣,不妨亲自尝试操作,体验其强大的功能。
TDengine 有话说
作为一款专注于时序数据的高效数据库,我们始终致力于简化用户的迁移过程。在 TDengine 3.3.0.0 和 3.3.2.0 版本中,我们进一步增强了数据接入功能,实现了传统关系型数据库向 TDengine 的平滑迁移。这两次重要更新成功打通了 MySQL、PostgreSQL、Oracle 和 SQL Server 到 TDengine 的迁移路径,大幅提升了迁移效率和用户体验。
不仅如此,TDengine 在数据接入方面还支持与多种数据源的无缝对接,包括 AVEVA Historian、OPC、Kafka、MQTT、InfluxDB 和 PI System 等,充分满足用户在多样化场景中的数据管理需求。