目录
一、机器学习
1、实现原理
训练(归纳)和预测(演绎)
- 归纳: 从具体案例中抽象一般规律。从一定数量的样本(已知模型输入x和模型输出y)中,学习输出y与输入x的关系(可以想象成是某种表达式)。
- 演绎: 从一般规律推导出具体案例的结果,机器学习中的"预测"亦是如此。基于训练得到的y与x之间的关系,对新的输入x,计算出输出y。通常情况下,如果通过模型计算的输出和真实场景的输出一致,则说明模型是有效的。
2、实施方法

三个关键要素: 假设、 评价、 优化
- 模型假设:世界上的可能关系千千万,漫无目标的试探与X之间的关系显然是十分低效的。因此先圈定一个模型能够表达的关系可能,然后机器会进步在假设范围内寻找最优的 Y~X关系,即确定参数w。
- 评价函数:即定义损失函数。寻找最优之前,我们需要先定义什么是最优,即评价一个Y~X关系的好坏的指标。通常衡量该关系是否能很好的拟合现有观测样本,将拟合的误差最小作为优化目标。
- 优化算法:例如梯度下降。设置了评价指标后,就可以在假设圈定的范围内,将使得评价指标最优(损失函数最小/最拟合已有观测样本)的 Y~X关系找出来,这个寻找最优解的方法即为优化算法。最笨的优化算法即按照参数的可能,穷举每个可能取值来计算损失函数,保留使得损失函数最小的参数作为最终结果
二、深度学习
1、与机器学习的联系与区别
二者在理论结构上是一致的,即:模型假设、评价函数和优化算法;
其根本差别在于假设的复杂度。如下图所示的图像识别问题,给出一张美女照片,人脑可以接收到五颜六色的光学信号,能快速反应出这张图片是一位美女。但对计算机而言,只能接收到一个数字矩阵,对于美女这种高级的语义概念,从像素到高级语义概念中间要经历的信息变换非常复杂,这种变换已经无法用数学公式表达。

在深度学习兴起之前, 很多领域建模的思路是投入大量精力做特征工程, 将专家对某个领域的"人工理解" 沉淀成特征表达, 然后使用简单模型完成任务(如分类或回归)。
而在数据充足的情况下, 深度学习模型可以实现端到端的学习, 即不需要专门做特征工程, 将原始的特征输入模型中, 模型可同时完成特征提取和分类任务。

2、神经网络的历史发展

3、神经网络的基本概念
人工神经网络包括多个神经网络层, 如: 全连接层、 卷积层、 循环层等, 每一层又包括很多神经元, 超过三层的非线性神经网络都可以被称为深度神经网络。通俗的讲, 深度学习的模型可以视为是输入到输出的映射函数, 如图像到高级语义(美女) 的映射, 足够深的神经网络理论上可以拟合任何复杂的函数。
神经元:
- 神经网络中每个节点称为神经元, 由两部分组成:
1)加权和: 将所有输入加权求和;
2)非线性变换(激活函数): 加权和的结果经过一个非线性函数变换, 让神经元计算具备非线性的能力
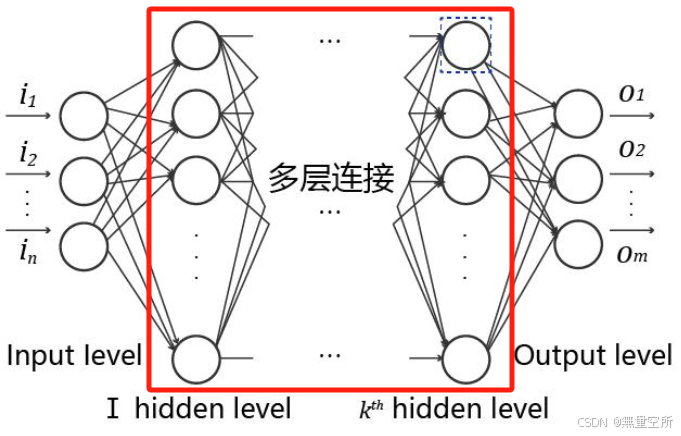
多层连接:
- 大量这样的节点按照不同的层次排布, 形成多层的结构连接起来, 即称为神经网络
前向计算:
- 从输入计算输出的过程, 顺序从网络前至后
计算图:
- 以图形化的方式展现神经网络的计算逻辑又称为计算图, 也可以将神经网络的计算图以公式的方式表达