在一文带你入门 MCP(模型上下文协议)文章中,我们快速介绍了 MCP 的基本概念,并且通过一个示例让读者初步感受到了 MCP 的强大能力。本文将进一步深入,带领读者一步步学习如何开发一个完整的 MCP Server。本文的完整代码可以在这里找到:https://github.com/cr7258/hands-on-lab/tree/main/ai/claude/mcp/server/elasticsearch-mcp-server-example
MCP Server 核心原语
Model Context Protocol (MCP) 是一个专门为 LLM(大语言模型)应用设计的协议,它允许你构建服务器以安全、标准化的方式向 LLM 应用程序公开数据和功能。MCP Server 提供了 3 种核心原语,每种原语都有其特定的用途和特点:
- Tool(工具):
- Tool 允许服务器公开可执行的函数,这些函数可由客户端调用并由 LLM 使用来执行操作。Tool 不仅人让 LLM 能从外部获取信息,还能执行写入或操作,为 LLM 提供真正的行动力。
- 模型控制:Tool 直接暴露给 LLM 可执行函数,让模型可以主动调用。
- Resource(资源):
- Resource 表示服务器希望提供给客户端的任何类型的只读数据。这可能包括:文件内容、数据库记录、图片、日志等等。
- 应用控制:Resource 由客户端或应用管理,用于为 LLM 提供上下文内容。
- Prompt(提示模板) :
- Prompt 是由服务器定义的可重用的模板,用户可以选择这些模板来引导或标准化与 LLM 的交互过程。例如,Git MCP server 可以提供一个"生成提交信息"的提示模板,用户可以用它来创建标准化的提交消息。
- 用户控制:Prompt 通常由用户自行选择。
Elasticsearch MCP Server 示例
接下来,我们将通过构建一个 Elasticsearch MCP Server,分别演示 Tool、Prompt 和 Resource 的具体用法。
使用 Docker Compose 启动 Elasticsearch 集群
执行 docker-compose up -d 命令在后台启动一个 3 节点的 Elasticsearch 集群,并且提供了 Kibana 用于管理和可视化 Elasticsearch。
浏览器输入 http://localhost:5601 访问 Kibana 界面,用户名 elastic,密码 test123。
准备测试数据
在 Kibana 中打开 Management -> Dev Tools 页面, 执行以下代码创建两个索引 student 和 teacher,分别插入几条数据:
json
POST /student/_doc
{
"name": "Alice",
"age": 20,
"major": "Computer Science"
}
POST /student/_doc
{
"name": "Bob",
"age": 22,
"major": "Mathematics"
}
POST /student/_doc
{
"name": "Carol",
"age": 21,
"major": "Physics"
}
POST /teacher/_doc
{
"name": "Tom",
"subject": "English",
"yearsOfExperience": 10
}
POST /teacher/_doc
{
"name": "John",
"subject": "History",
"yearsOfExperience": 7
}
POST /teacher/_doc
{
"name": "Lily",
"subject": "Mathematics",
"yearsOfExperience": 5
}初始化项目
在本教程中,我们将使用 MCP Python SDK 来编写项目,使用 uv 来管理 Python 项目依赖。
安装 uv 可以参考 Installing uv。MacOS 用户可以使用 brew 进行安装:
bash
brew install uv执行以下命令初始化项目:
bash
uv init elasticsearch-mcp-server-example
cd elasticsearch-mcp-server-example添加依赖:
bash
uv add "mcp[cli]" elasticsearch python-dotenv创建 server.py 文件,接下来将会在该文件中编写代码:
bash
touch server.py在 Claude Desktop 中安装 MCP Server
在 .env 文件中设置好 Elasticsearch 的连接信息。
bash
ELASTIC_HOST=https://localhost:9200
ELASTIC_USERNAME=elastic
ELASTIC_PASSWORD=test123可以执行以下命令将 MCP Server 安装到 Claude Desktop 中:
--env-file参数指定了.env文件的路径,用于加载环境变量。--with-editable参数指定了 uv 依赖管理文件pyproject.toml所在的目录,用于安装项目的依赖。
bash
mcp install server.py --env-file .env --with-editable ./该命令会自动帮助你在 cluade_desktop_config.json 文件中添加 MCP Server 的配置。
json
{
"mcpServers": {
"elasticsearch-mcp-server": {
"command": "uv",
"args": [
"run",
"--with",
"mcp[cli]",
"--with-editable",
"/your/project/path/elasticsearch-mcp-server-example",
"mcp",
"run",
"/your/project/path/elasticsearch-mcp-server-example/server.py"
],
"env": {
"ELASTIC_HOST": "https://localhost:9200",
"ELASTIC_USERNAME": "elastic",
"ELASTIC_PASSWORD": "test123"
}
}
}
}接下来我们开始编写 Elasticsearch MCP Server 的相关代码。
Elasticsearch 客户端配置
首先创建 Elasticsearch 客户端,用于和 Elasticsearch 服务器进行交互。
python
def create_elasticsearch_client() -> Elasticsearch:
# Load environment variables from .env file
load_dotenv()
url = os.getenv("ELASTIC_HOST")
username = os.getenv("ELASTIC_USERNAME")
password = os.getenv("ELASTIC_PASSWORD")
# Disable SSL warnings
warnings.filterwarnings("ignore", message=".*TLS with verify_certs=False is insecure.*",)
if username and password:
return Elasticsearch(url, basic_auth=(username, password), verify_certs=False)
return Elasticsearch(url)初始化 FastMCP Server
MCP Python SDK 现在提供了全新的 FastMCP 类,它通过利用 Python 的类型注解(Type Hints)和文档字符串(Docstrings)特性,能够自动生成工具定义。这种方式让开发者可以更加便捷地创建和管理 MCP 的 Tool、Resource 以及 Prompt 等功能组件。
以下代码创建一个名为 mcp 的 FastMCP 对象。
python
from mcp.server.fastmcp import FastMCP
MCP_SERVER_NAME = "elasticsearch-mcp-server"
mcp = FastMCP(MCP_SERVER_NAME)添加 Tool
Tool 定义了允许 LLM 可以调用 MCP Server 执行的操作,除了查询以外,还可以执行写入操作。接下来定义了两个 Tool:
list_indices: 列出所有可用的索引。get_index: 获取指定索引的详细信息。
使用 @mcp.tool() 装饰器将这两个函数标记为 MCP 的 Tool。
python
@mcp.tool()
def list_indices() -> List[str]:
"""列出所有 Elasticsearch 索引"""
return [index["index"] for index in es.cat.indices(format="json")]
@mcp.tool()
def get_index(index: str) -> dict:
"""获取特定 Elasticsearch 索引的详细信息"""
return es.indices.get(index=index)然后重启 Claude Desktop,一切正常的话,你应该能在输入框的右下角看到一个锤子图标。点击锤子图标,可以看到 Elasticsearch MCP Server 提供的工具信息。
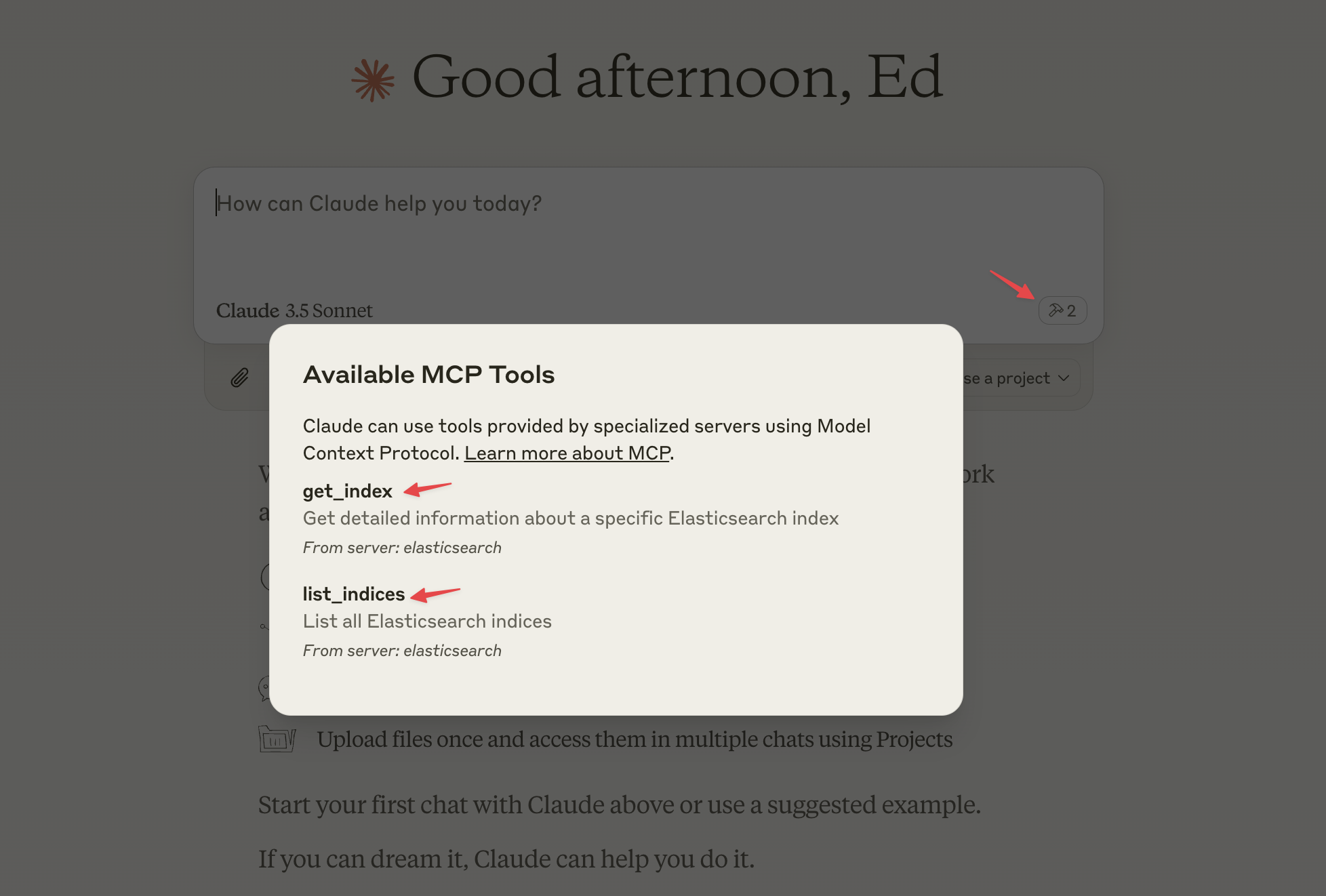
我们可以针对 Elasticsearch 的数据进行提问,比如:
Elasticsearch 中有哪些索引? 可以看到 Claude 调用了 list_indices 来列出所有索引。

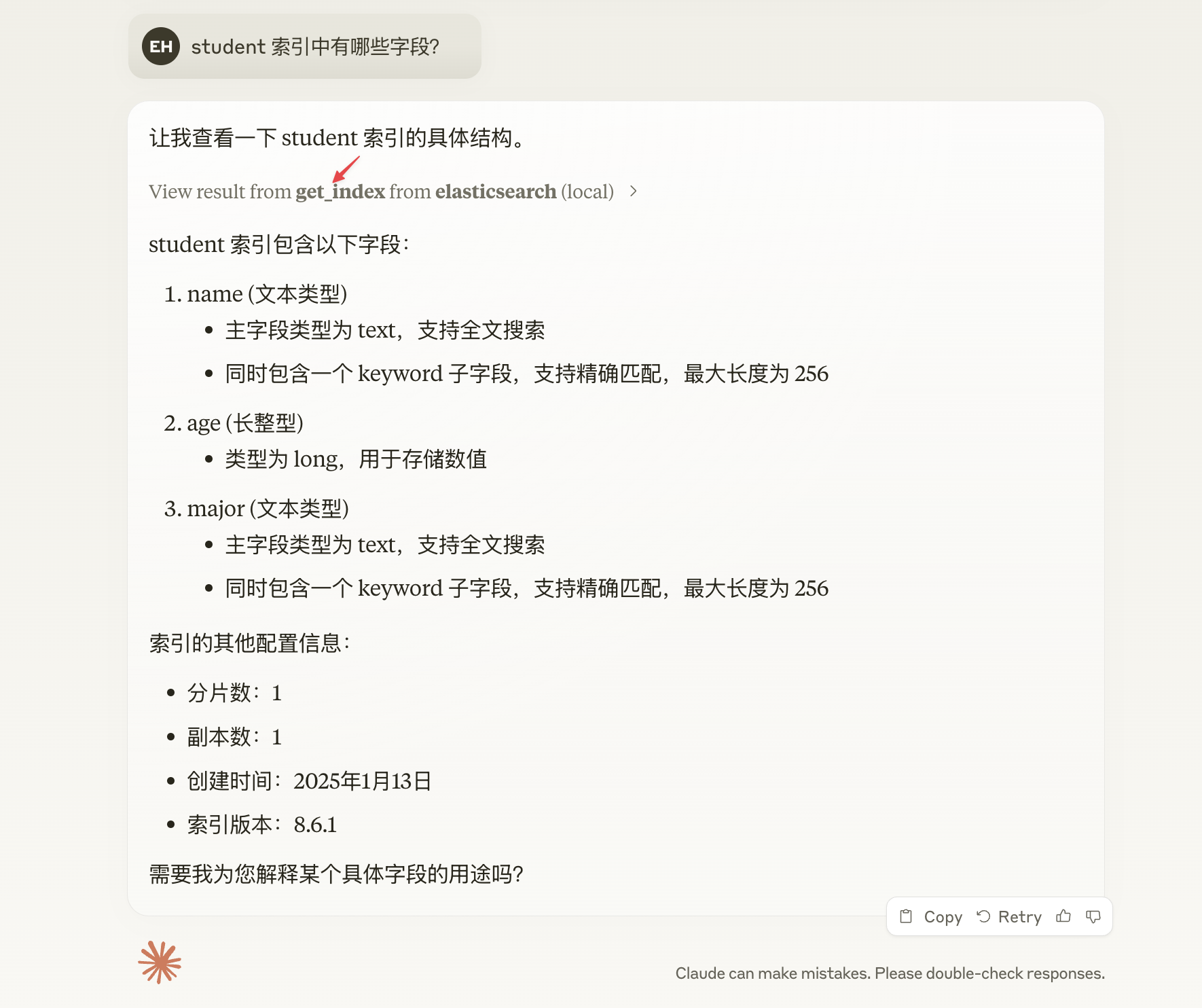
student 索引中有哪些字段? 可以看到 Claude 调用了 get_index 来获取 student 索引信息。
添加 Resource
Resource 定义了 LLM 可以访问只读的数据源,可以用于为 LLM 提供上下文内容。在这个示例中,我们定义了两个资源:
es://logs:允许 LLM 访问 Elasticsearch 容器的日志信息,通过 Docker 命令获取日志内容。file://docker-compose.yaml:允许 LLM 访问项目的docker-compose.yaml文件内容。
python
@mcp.resource("es://logs")
def get_logs() -> str:
"""Get Elasticsearch container logs"""
result = subprocess.run(["docker", "logs", "elasticsearch-mcp-server-example-es01-1"], capture_output=True, text=True, check=True)
return result.stdout
@mcp.resource("file://docker-compose.yaml")
def get_file() -> str:
"""Return the contents of docker-compose.yaml file"""
with open("docker-compose.yaml", "r") as f:
return f.read()使用 @mcp.resource() 装饰器将这些函数标记为 MCP 的 Resource,装饰器参数指定了 Resource 的 URI。
Resource 建议遵循以下格式的 URI 标识:
bash
[protocol]://[host]/[path]URI 的协议和路径结构由 MCP Server 自定实现定义。
重启 Claude,点击插头图标,可以看到 Elasticsearch MCP Server 提供的 Resource。
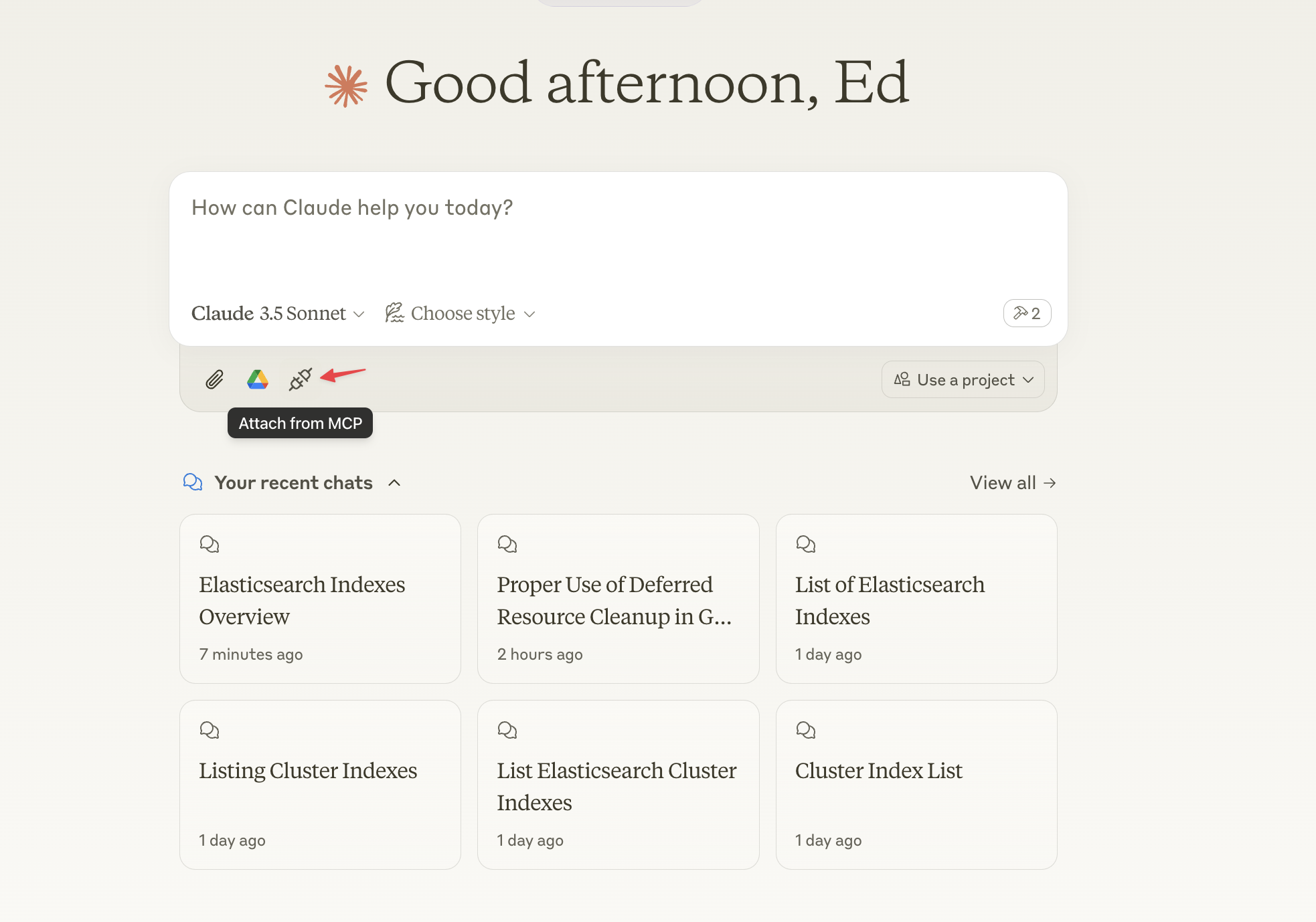
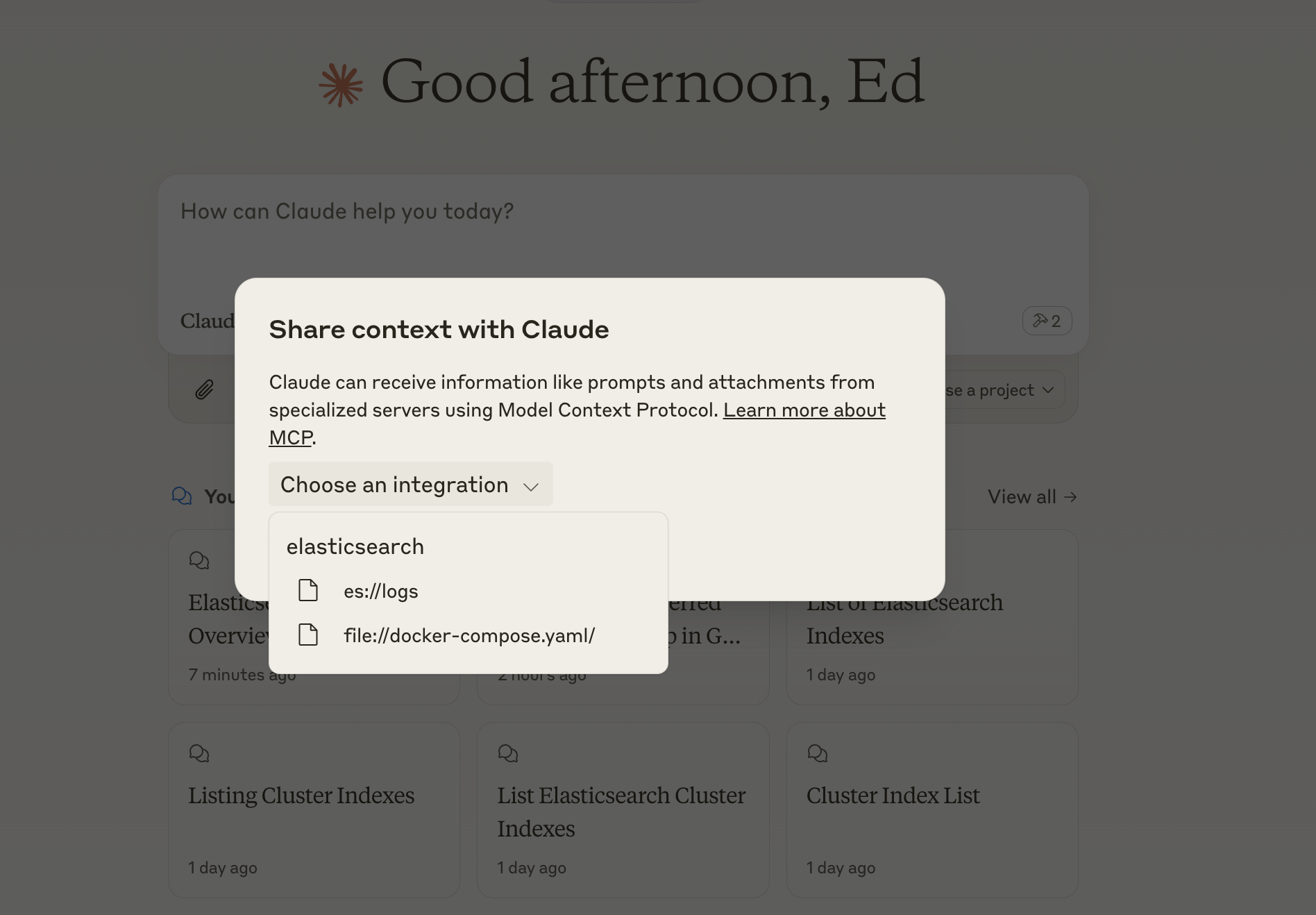
接下来我们可以选择 Resource 作为提问的上下文,让 LLM 进行回答。
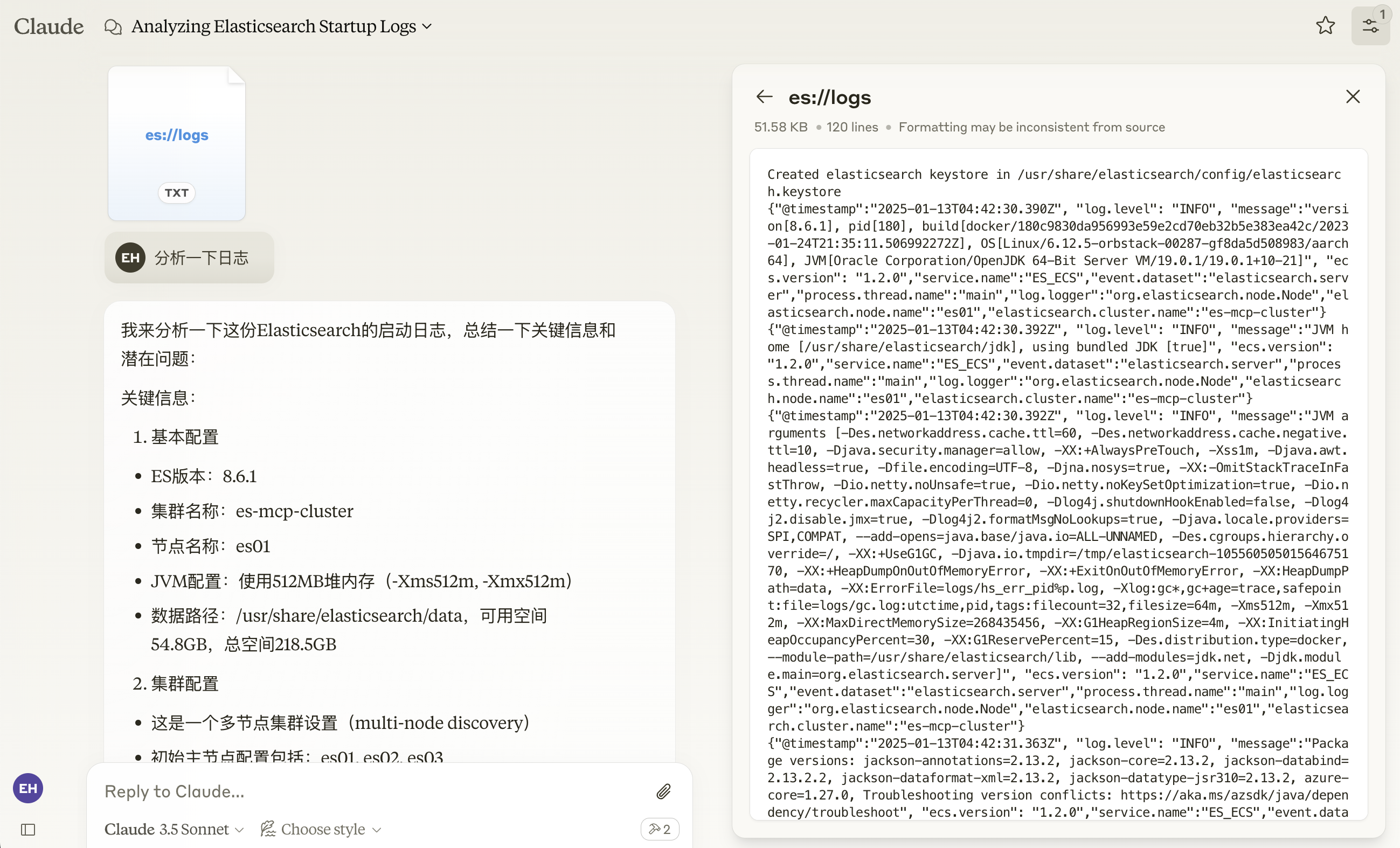
- 选择
es://logs,然后提问:分析一下日志。
- 选择
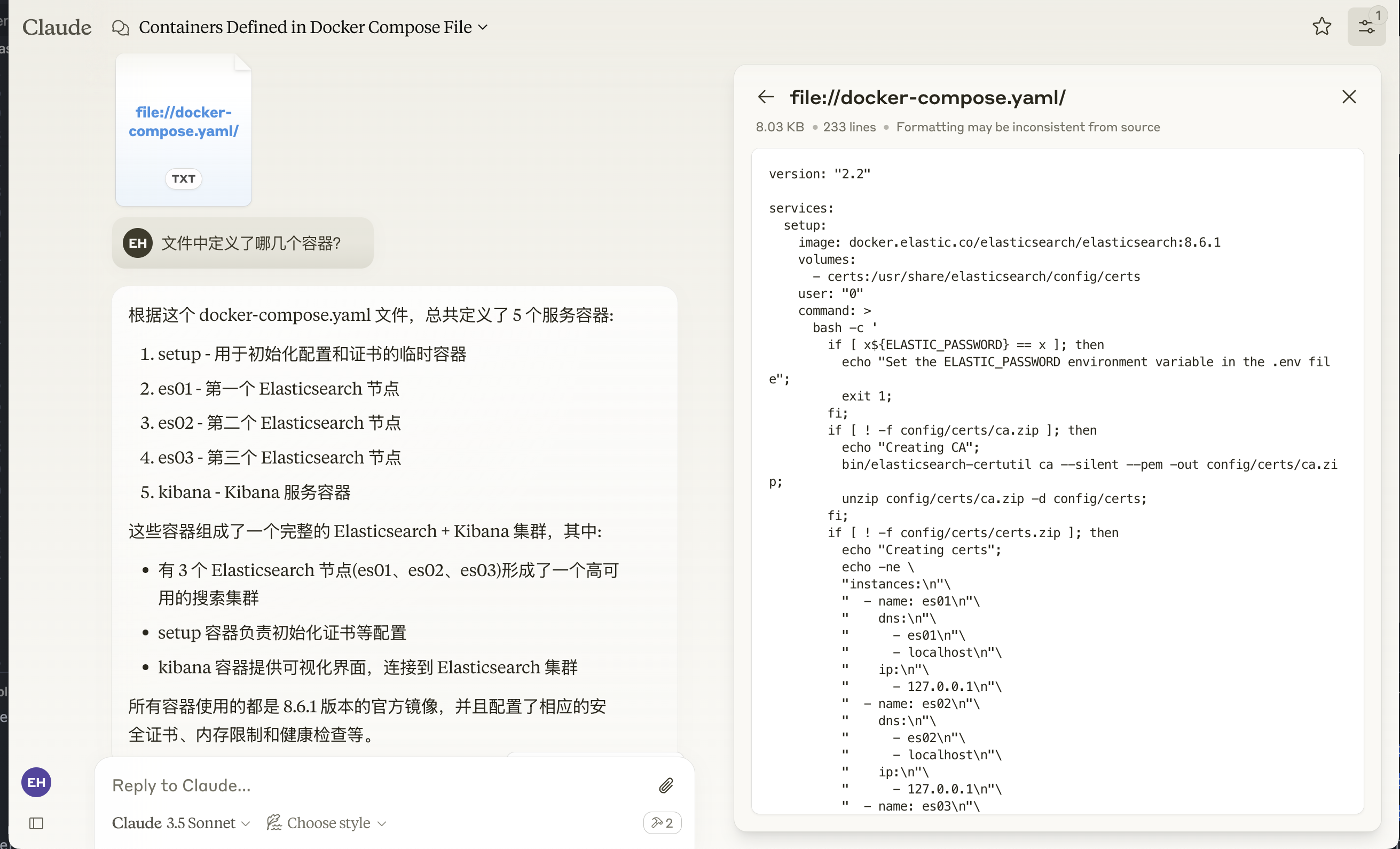
file://docker-compose.yaml,然后提问:文件中定义了哪几个容器?
添加 Prompt
Prompt 用于定义可重用的提示模板,帮助用户更好地引导 LLM 以标准化的方式完成任务。在这个示例中,我们定义了一个名为 es_prompt 的提示模板,引导 LLM 从多个维度(如索引设置、搜索优化、数据建模和扩展性等)对索引进行分析。
python
@mcp.prompt()
def es_prompt(index: str) -> str:
"""Create a prompt for index analysis"""
return f"""You are an elite Elasticsearch expert with deep knowledge of search engine architecture, data indexing strategies, and performance optimization. Please analyze the index '{index}' considering:
- Index settings and mappings
- Search optimization opportunities
- Data modeling improvements
- Potential scaling considerations
"""重启 Claude Desktop,点击插头图标,选择 es_prompt,并输入待分析的索引 student。
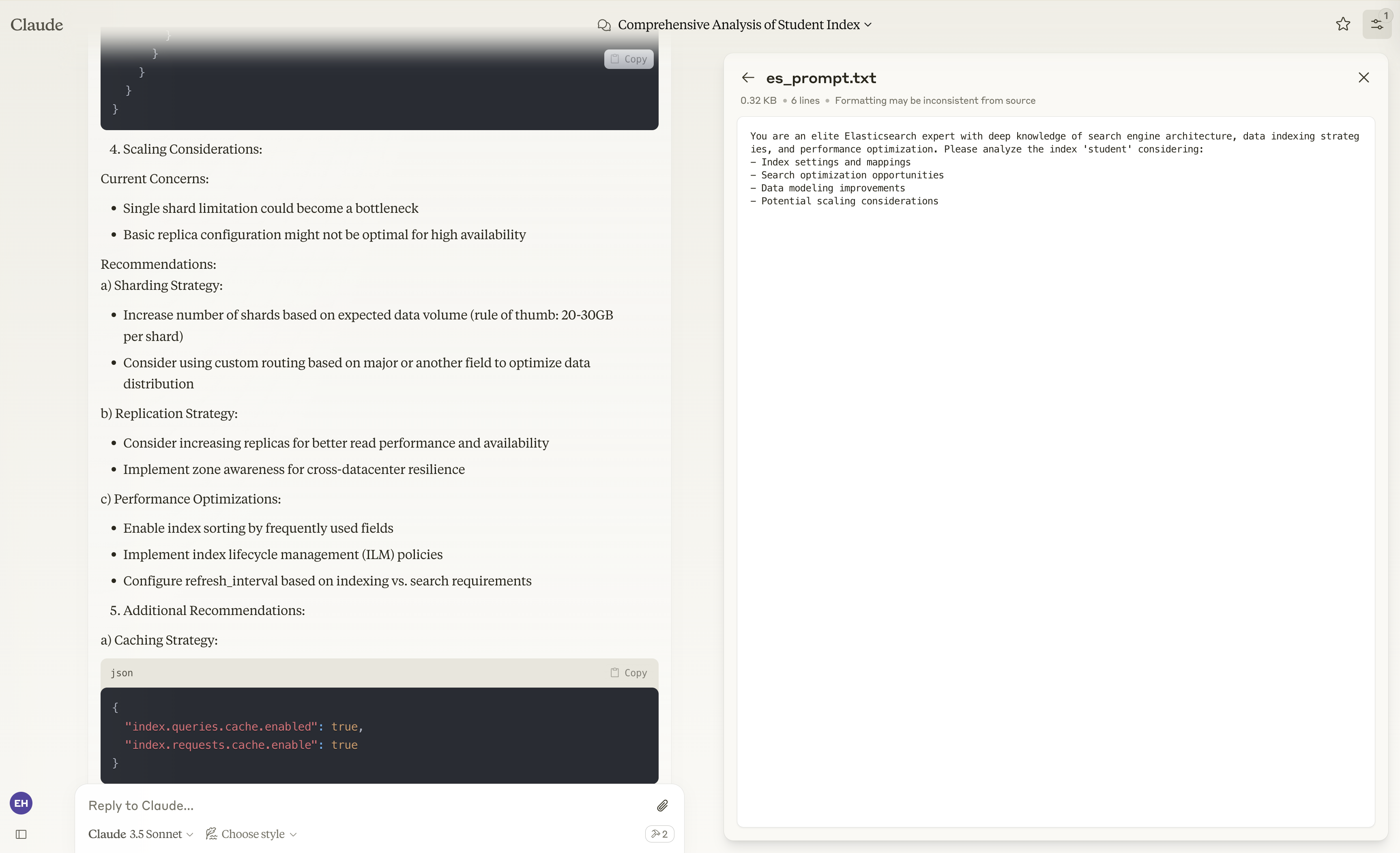
Claude 会调用 get_index Tool 来获取 student 索引的信息,并根据我们提供的 Prompt 给出多个维度的建议。
使用 MCP Inspector 调试 MCP Server
MCP Inspector 是一个交互式的开发者工具,专门用于测试和调试 MCP 服务器。它提供了一个图形化界面,让开发者能够直观地检查和验证 MCP 服务器的功能。
执行以下命令可以启动 MCP Inspector:
bash
mcp dev server.py 启动成功后,浏览数输入 http://localhost:5173 打开 MCP Inspector 界面。点击 Connect 连接 MCP Server。
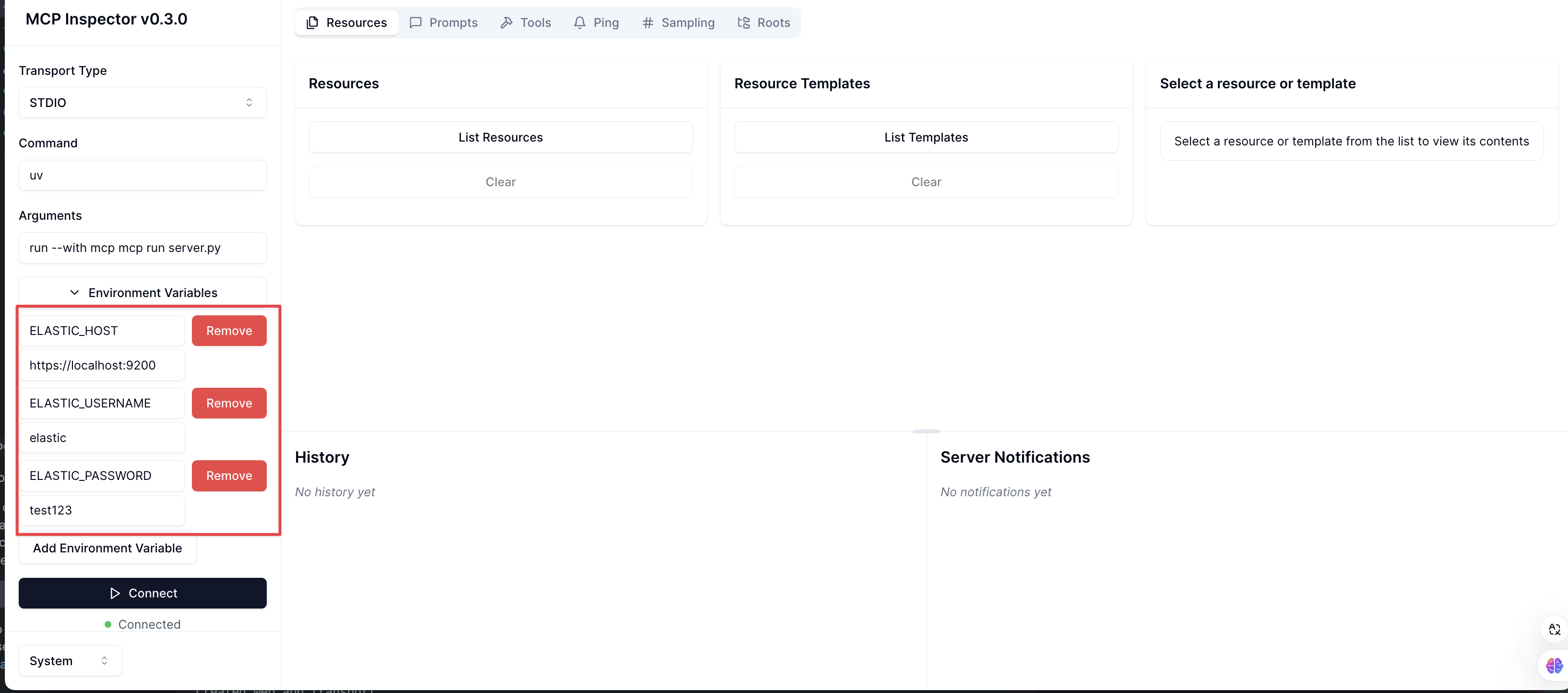
将 Elasticsearch 的连接信息添加到环境变量中。
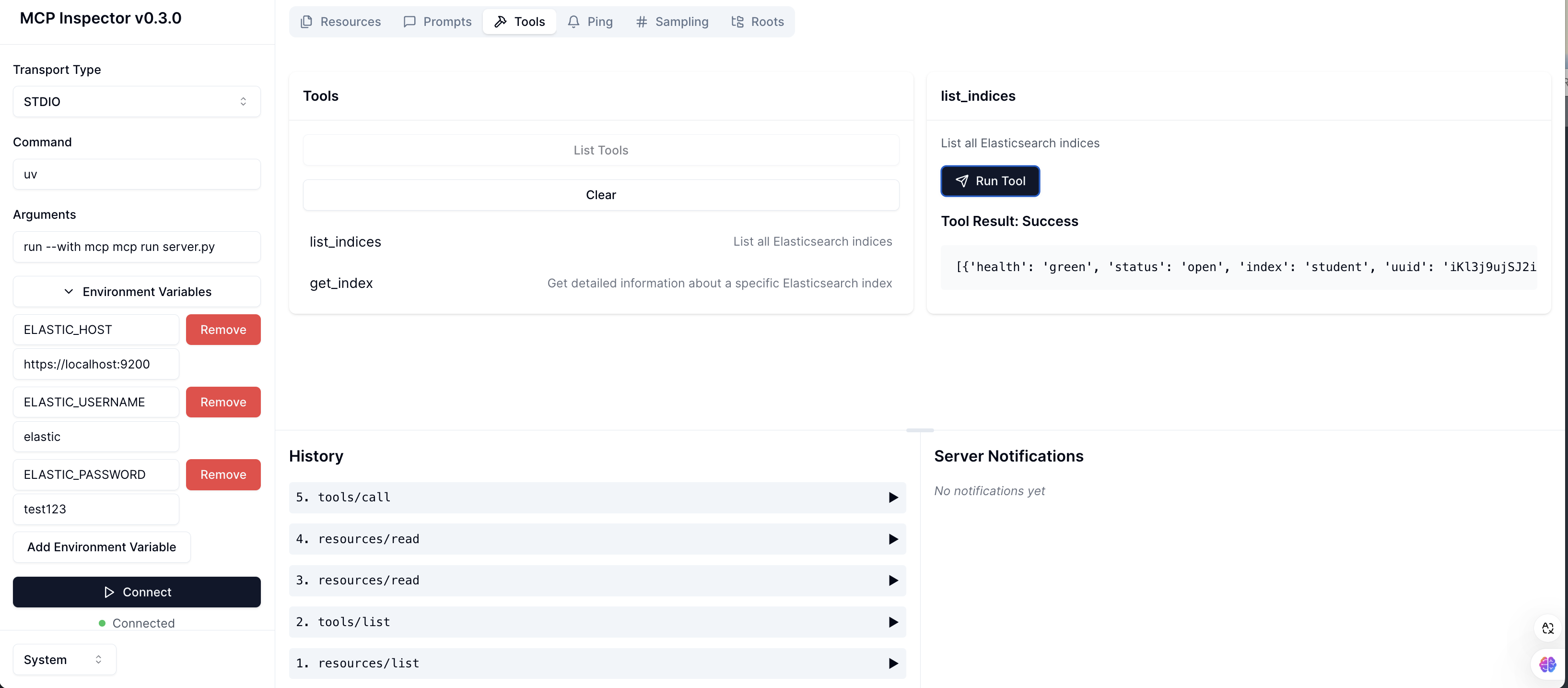
在 MCP Inspector 中可以列出和执行 Resource、Tool 和 Prompt。
组合示例
现在假设我们有这样一个需求,读取 movies.csv 文件,将文档写入 Elasticsearch 的 movies 索引中,如果电影票房超过 1 亿美元,则在文档中设置一个额外的字段 isPopular: true,否则设置为 isPopular: false。
在过去,我们可能会考虑使用 Elasticsearch Ingest Pipeline 的 Script processor 来实现这一需求。
现在我们可以通过 Resource 向 LLM 提供要读取的 movies.csv 文件,LLM 会对电影票房进行计算,然后设置文档的 isPopular 字段值,最后调用 write_documents Tool 来将文档写入 Elasticsearch 的 movies 索引中。实现的代码如下:
python
@mcp.resource("file://movies.csv")
def get_movies() -> str:
"""Return the contents of movies.csv file"""
with open("movies.csv", "r") as f:
return f.read()
@mcp.tool()
def write_documents(index: str, documents: List[Dict]) -> dict:
"""Write multiple documents to an Elasticsearch index using bulk API
Args:
index: Name of the index to write to
documents: List of documents to write
Returns:
Bulk operation response from Elasticsearch
"""
operations = []
for doc in documents:
# Add index operation
operations.append({"index": {"_index": index}})
# Add document
operations.append(doc)
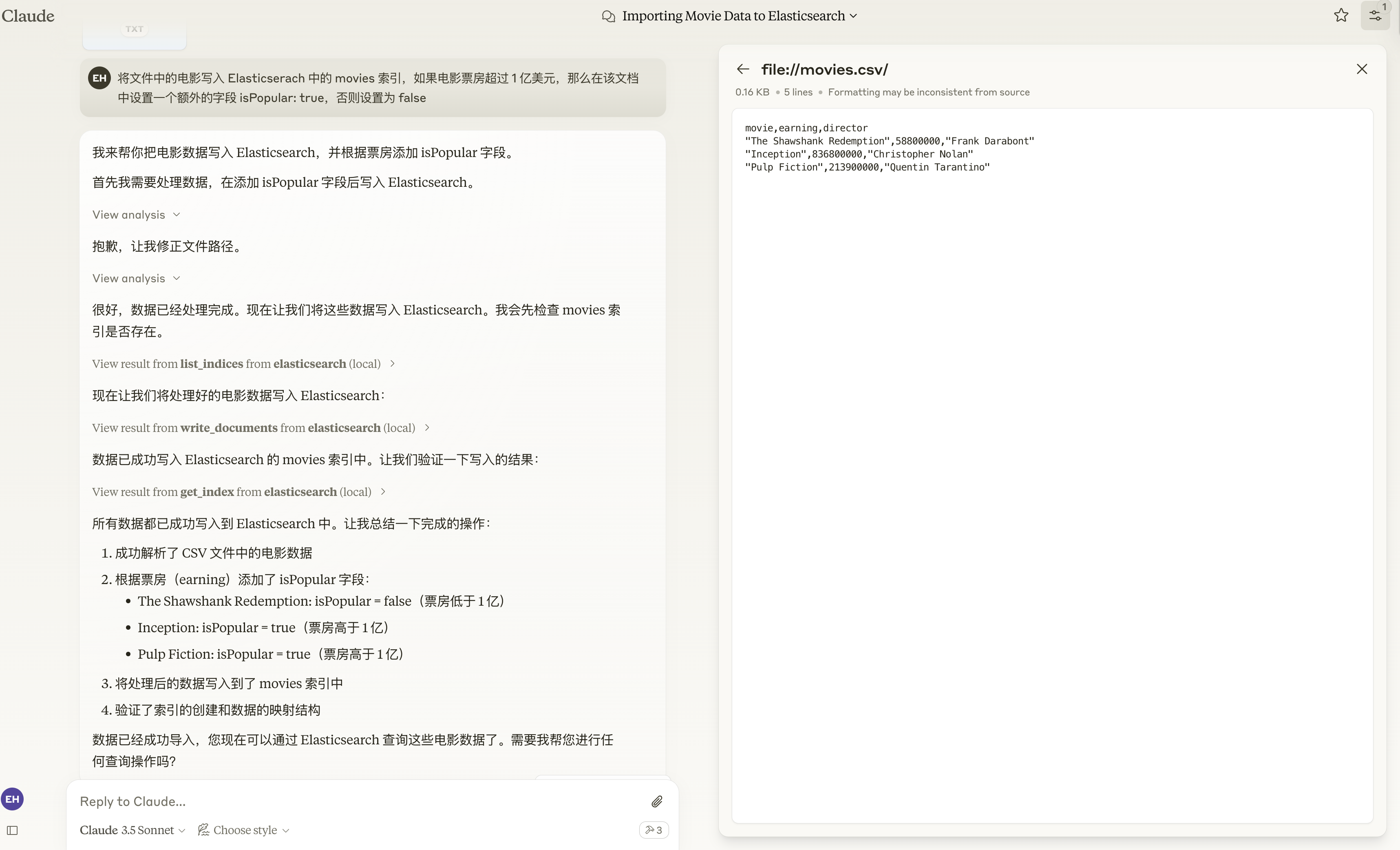
return es.bulk(operations=operations, refresh=True)重启 Claude,选择 file://movies.csv/ Resource,然后向 Claude 发送以下指令:将文件中的电影写入 Elasticserach 中的 movies 索引,如果电影票房超过 1 亿美元,那么在该文档中设置一个额外的字段 isPopular: true,否则设置为 false。
可以看到 Claude 顺利地完成了我们指定的任务。
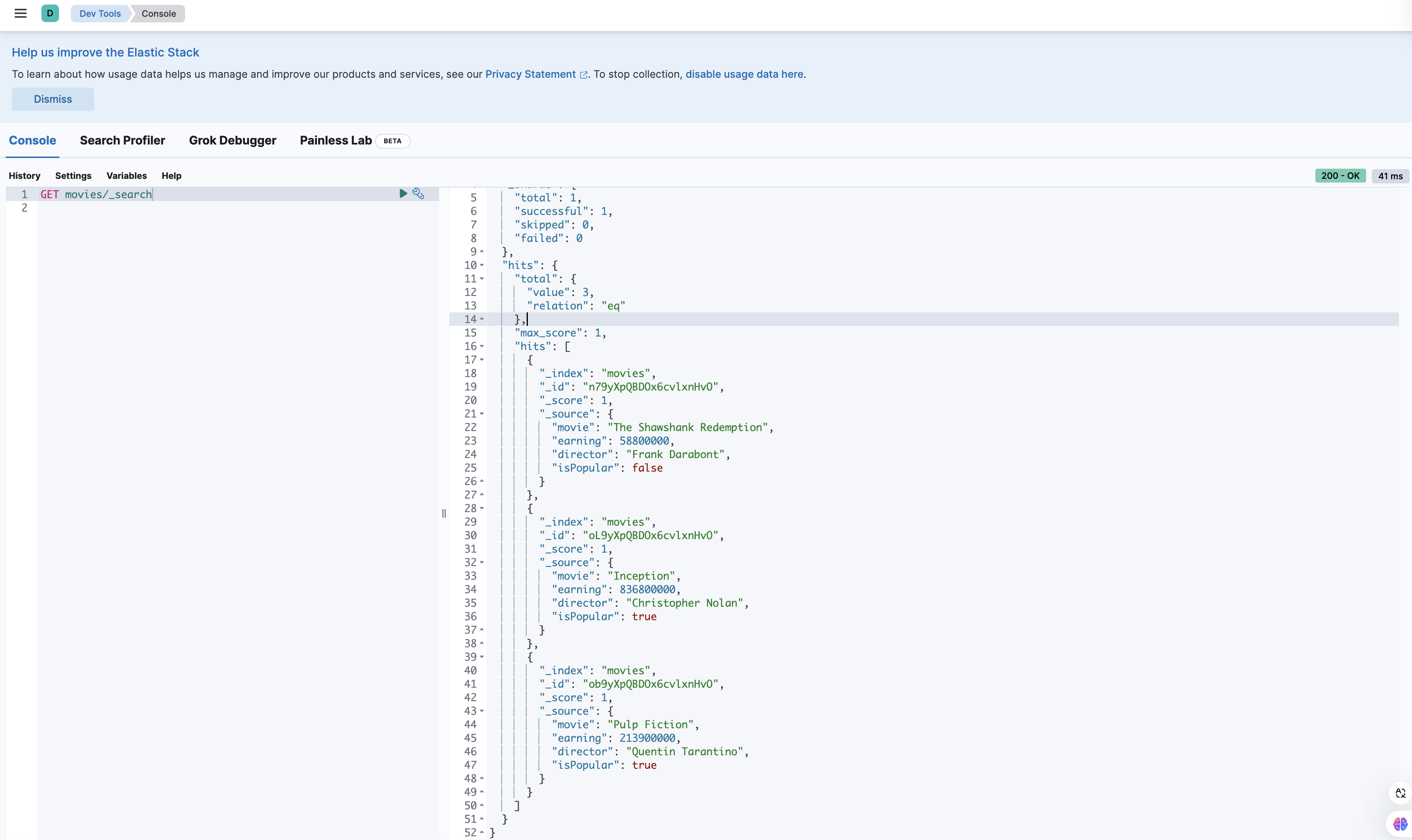
在 Kibana 中查询 movies 索引,可以看到我们的数据已经成功写入,并且 isPopular 字段也已经被正确设置了。
总结
本教程通过构建一个 Elasticsearch MCP Server 的实例,展示了如何利用 MCP 协议的三个核心原语(Tool、Resource 和 Prompt)来增强 LLM 的能力。通过 Tool 实现了索引操作和文档写入,通过 Resource 提供数据的访问能力,而 Prompt 则帮助 LLM 以标准化的方式完成任务。最后通过一个实际的组合示例,演示了如何让 LLM 利用这些组件完成更复杂的数据处理任务,充分体现了 MCP 在提升 LLM 应用开发效率方面的优势。
欢迎关注
