线性化PDF是一种特殊的PDF文件组织方式。
总体而言,PDF是一种极为优雅且设计精良的格式。PDF由大量PDF对象构成,这些对象用于创建页面。相关信息存储在一棵二叉树中,该二叉树同时记录文件中每个对象的位置。因此,打开文件时只需加载这棵树,随后便可借助它加载显示页面所需的对象。无需读取整个文件,仅读取这棵树即可。树的位置始终存储在文件末尾,所以很容易找到,而且只需追加新信息和一棵新树,就能轻松修改文件。
然而,如果通过网络读取文件,它是以字节流的形式被访问的。这意味着,必须在整个PDF文件传输完毕后,才能读取位于文件末尾的引用。对于大文件而言,这可能需要一些时间。
如何创建线性化PDF
于是,Adobe创建了一种新的PDF布局方式,即线性化PDF。其文件格式依然不变,但在文件开头有一个特殊标记,创建第一页所需的所有对象(以及描述这些对象的一个小型二叉树)都存储在文件开头。一旦读取了这些数据,即可显示第一页,同时文件的其余部分继续下载。这使得整个过程看起来快得多,即便对于超大文件,用户也几乎能立刻看到一些内容。
线性化PDF与非线性化PDF有何区别
线性化PDF用于按页面顺序有序地组织内部组件,这有助于提升网页浏览体验,使用户能够尽快查看最想看的页面。而非线性化PDF的对象分散在整个文件中,必须完全下载后才能查看。
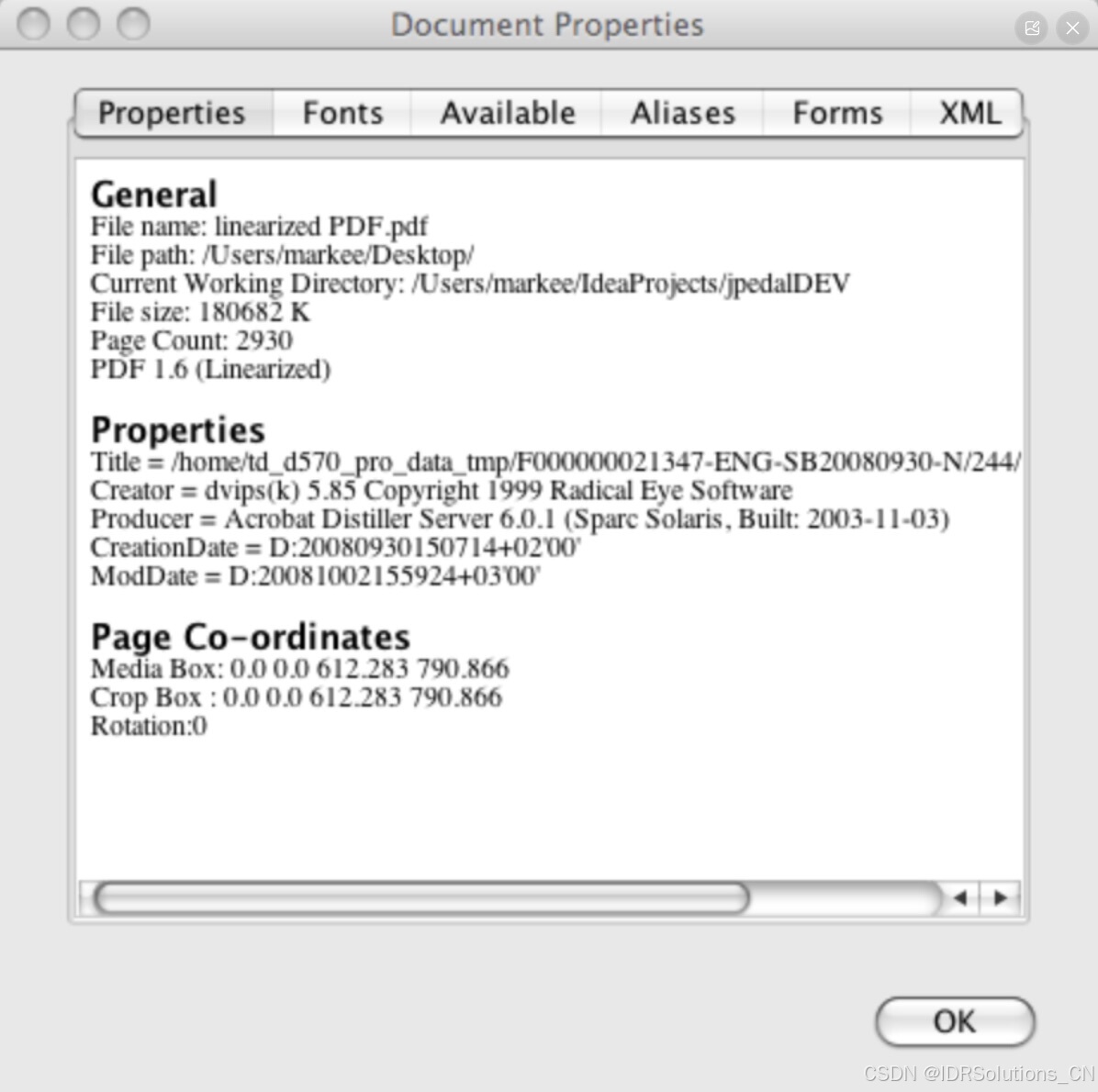
如何检查PDF是否为线性化的?
在Adobe Acrobat和Adobe Reader中,查看PDF是否为线性化的最佳方法是查看文档属性。如果文件是线性化PDF,"快速网络视图"这一项将显示"是"。

在JPedal PDF阅读器中,我们也添加了类似功能,可在文档属性中显示文件是否为线性化PDF。如果是线性化PDF,"linearized(线性化)"一词会出现在常规信息部分中PDF版本之后。
用于查看PDF文件是否为线性化的Java代码
在JPedal中,你也可以通过编程方式检查文件是否为线性化的,方法是查看Linearized对象是否存在------如果存在,那它就是一个线性化的PDF。
final PdfUtilities extract = new PdfUtilities(filename);
if (extract.openPDFFile()) {
final boolean isLinearized = extract.isPDFLinearized();
}
extract.closePDFfile();
为什么线性化PDF很重要?
简而言之,线性化PDF是一种组织PDF文件的方式,这样如果要通过互联网访问该文件,它的加载速度会显得快很多。而且它确实能很好地做到这一点!
我们的主页: PDF 转 HTML5、Java 图像库、Java PDF SDK - IDRsolutions
关注我们🛰️:IDRSolutions