个人博客地址:Spark的基本概念 | 一张假钞的真实世界
编程接口
- RDD:弹性分布式数据集(Resilient Distributed Dataset )。Spark2.0之前的编程接口。Spark2.0之后以不再推荐使用,而是被Dataset替代。
- Dataset:Spark2.0之后的编程接口,用来替代RDD。与RDD不同Dataset是强数据类型的,但是这一点不适用与pyspark,因为Python是弱类型的。Spark引擎针对Dataset做了更丰富的优化,所以比RDD有更高的性能。
- Dataframe:在Python(Pandas)和R中Dataset的组织形式;在Scala中没有这个概念。
架构
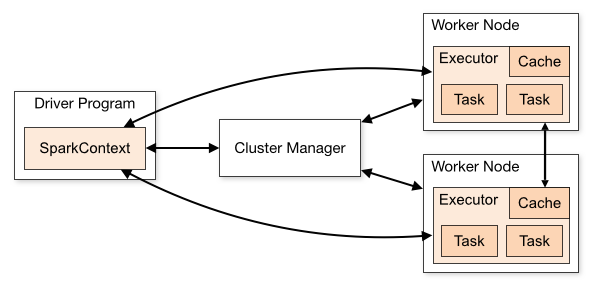
- Application:基于Spark构建的用户程序。包含驱动程序和执行器。
- Application jar:用户程序Jar包。
- Driver program:驱动程序。用户程序中运行main()方法及创建SparkContext的进程。
- Cluster manager:集群管理者。管理集群资源的外部服务。如:standalone manager, Mesos, YARN, Kubernetes。
- Deploy mode:用来指明驱动程序运行位置。集群模式下框架在集群中调起驱动程序;客户端模式下在集群之外的程序提交者调起驱动程序。
- Worker node:集群中运行应用程序的节点。
- Executor:Worker节点上调起的为用户应用程序的进程,运行任务并在内存中或磁盘是行保持数据。每个应用程序都有自己的Executor。
- Task:发送到Executor的工作单元。
- Job:由多个任务组成的并行计算,这些任务响应Spark操作(例如保存、收集)而生成;您将在驱动程序日志中看到这个术语。
- Stage:每个作业被划分为更小的任务集,称为相互依赖的阶段(类似于MapReduce中的map和reduce阶段);您将在驱动程序日志中看到这个术语。