
项目背景
随着大语言模型(LLM)技术的发展,Ollama 是一个开源的零信任本地化 AI 框架,它允许您在本地运行大型语言模型,并通过简单的 API 实现实例化和推理。DeepSeek 提供了一个易于使用的 Python 接口库,可以快速集成 Ollama 模型并构建基于模型的应用。
本次项目的目标是:
- 在本地部署一个 Ollama 模型实例。
- 使用Chatbox实现界面对话
通过本项目的实现,读者将能够了解如何在本地运行 Ollama 模型,实现界面对话
项目目标
- 部署 Ollama 模型:使用 DeepSeek 提供的 API 在本地运行 Ollama 模型。
- 实现本地聊天界面:使用 ChatBox,支持用户与模型交互,并显示响应结果。
项目步骤
步骤 1:环境配置
我们需要先在本地安装必要的软件和依赖项。
1.1 安装系统要求(可选)
Ollama 和 DeepSeek 需要在 CPU 或 CUDA 环境中运行。为了能够利用 CUDA 加速,建议使用以下硬件:
- 至少一个高性能的 CPU(最好有至少 4 核心)。
- 具备支持 CUDA 的 GPU(如 NVIDIA 显卡)。
1.2 安装 CUDA 和cuDNN
如果选择使用 CUDA 加速,则需要安装 CUDA 和 cuDNN。
bash
mkdir -p /usr/local/cuda curl https://developer.nvidia.com/cuda-toolkit-linux64 \ -o /usr/local/cuda/cuda toolkit \ -O -N -q chmod 755 /usr/local/cuda cd /usr/local/cuda ./bin/batcu 步骤 2:部署 Ollama 模型
使用 DeepSeek 提供的 API 在本地运行 Ollama 模型。
官网下载olloma 然后安装
2.1 下载模型
我这里下载7b模型,如果电脑允许可以直接下载其他模型
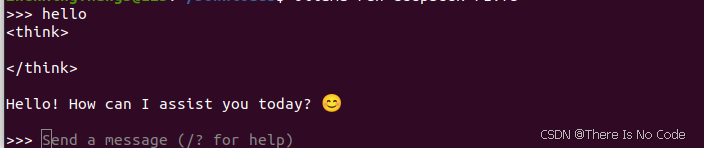
bash
ollama run deepseek-r1:7b执行成功后, 界面会显示命令行版本的deepseek:
步骤 3:安装 ChatBox 应用
官网下载对应的系统系统版本
为了开发 ChatBox,需要安装一些 Python 库。
Chatbox AI官网:办公学习的AI好助手,全平台AI客户端,官方免费下载
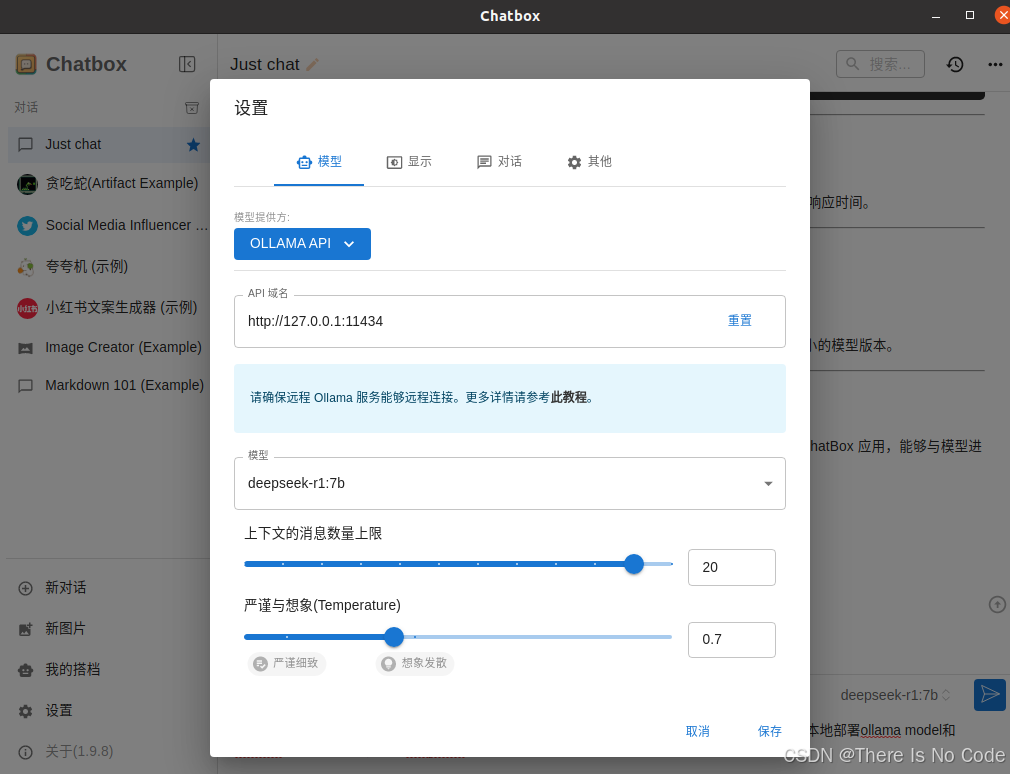
3.2 启动 ChatBox 应用
选择本地模型,选择已有的模型会直接在下拉框中展示
总结
通过以上步骤,您已经成功在本地部署了一个 Ollama 模型实例,并使用ChatBox 应用,能够与模型进行交互并显示响应结果。