前言
在当前竞争激烈的市场环境中,数据分析已成为企业实现差异化和精准营销的关键。通过分析用户行为数据,企业能够深入了解用户的习惯、偏好和行为模式,从而更精准地定位目标市场,制定个性化营销策略,并提供定制化推荐和服务。
在流处理和数据分析场景中,Kafka1 作为高吞吐量、低延迟的分布式消息系统,已成为这一领域的核心基础设施。而 AutoMQ2 基于云重新设计了 Kafka,将存储分离至对象存储,并在与 Apache Kafka 100%兼容的基础上,为用户提供高达 10 倍的成本优势和百倍的弹性。同样,Tinybird3 是一个强大的实时分析数据平台,它能够接收批处理和流式数据,并通过 API 支持 SQL 查询,帮助用户迅速构建高效的数据产品。
本文将通过分析用户订单信息的案例,深入探讨如何整合 AutoMQ 和 Tinybird,以优化用户订单信息的统计分析流程。借助这两个工具,我们能够实现实时用户数据收集、高效数据处理和直观数据展示,从而为业务提供更全面、准确的用户购买习惯和偏好,为精准营销提供有力支撑。通过阅读本篇文章,您将学会如何将网站的日志信息无缝导入到 Tinybird,并利用 Tinybird 进行用户行为数据的分析与可视化展示。
前置条件
-
可用的 Tinybird 环境:确保您拥有一个正常工作的 Tinybird 环境。如果尚未拥有,可以参考其官方文档4获取更多信息。
-
具备公网 IP 的 AutoMQ:需要一个具备公网 IP 并通过 SASL_SSL 协议启动的 AutoMQ 实例。由于 Tinybird 是基于 SaaS 模式构建的,它只能通过网络连接到 AutoMQ。出于用户信息安全的考虑,Tinybird 要求用户搭建的 AutoMQ 必须使用 SASL_SSL 安全协议启动,以保证数据传输的安全性和可靠性。SASL 用于客户端与服务器之间的身份验证,而 SSL 则确保数据在传输过程中的加密与保护。
第一步:使用 SASL_SSL 协议启动 AutoMQ
在启动 AutoMQ 并确保其使用 SASL_SSL 协议时,您应具备以下前置知识:
-
AutoMQ SASL 安全身份认证配置教程6
-
AutoMQ SSL 安全协议配置教程7
了解完以上内容后,本文将简要介绍启动可用的 AutoMQ 环境所需的关键配置文件,帮助您顺利完成配置。在操作过程中,请将相关文件路径替换为您实际资源所在的路径。
1. 关于 Broker 的配置
1.1 进行 SASL 相关配置
properties
listeners=BROKER_SASL://:9092,CONTROLLER_SASL://:9093
inter.broker.listener.name=BROKER_SASL
sasl.enabled.mechanisms=PLAIN
sasl.mechanism.inter.broker.protocol=PLAIN
sasl.mechanism.controller.protocol=PLAIN
listener.name.broker_sasl.plain.connections.max.reauth.ms=10000
controller.listener.names=CONTROLLER_SASL
listener.name.broker_sasl.plain.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required \
username="_automq" \
password="automq-secret" \
user__automq="automq-secret";
listener.name.controller_sasl.plain.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required \
username="_automq" \
password="automq-secret" \
user__automq="automq-secret";上述配置代表我们命名了两个监听器:BROKER_SASL、CONTROLLER_SASL,以及允许的安全机制为 PLAIN,并且为两个监听器分别创建了相同的用户 "_automq",密码为 "automq-secret"。
1.2 进行 SASL_SSL 相关配置
properties
listener.security.protocol.map=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL,BROKER_SASL:SASL_SSL,EXTERNAL:PLAINTEXT,CONTROLLER_SASL:SASL_SSL通过对listener.security.protocol.map对配置,我们把两个监听器名称与安全机制 SASL_SSL 进行了映射。
1.3 进行 SSL 相关配置
properties
# 如果要验证客户端则需要开启下面的设置
# ssl.client.auth=required
ssl.keystore.location=/root/automq/ssl/automq.space.jks
ssl.keystore.password=mhrx2d7h
# 私钥可以未加密形式提供,则无需配置密码
ssl.key.password=mhrx2d7h
#关闭主机名验证时设置以下参数
ssl.endpoint.identification.algorithm=上述配置文件,我们指定了需要的密钥库,并且关闭了主机名验证。这里密钥库指定为从云厂商下载的 jks 文件。
2. 关于 Client 的配置
本篇文章的案例的数据集您可以在 Kaggle8 网站上免费下载,订单信息需要通过 Client 端发送至 Broker 的 Topic 中。
2.1 给客户端配置云厂商提供的根证书
-
从云厂商下载根证书
-
将根证书添加进客户机的信任库
通过以下命令将根证书添加进入信任库:
properties
keytool -import -file /root/automq/ssl/DigicertG2ROOT.cer -keystore client.truststore.jks -alias root-certificate2.2 client.properties 具体配置
properties
sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="_automq" password="automq-secret";
security.protocol=SASL_SSL
ssl.truststore.location=/root/automq/ssl/client.truststore.jks
ssl.truststore.password=123456
# 这里其实也可以直接用证书作为信任库,如下
# ssl.truststore.location=/root/automq/ssl/automq.space.jks
# ssl.truststore.password=xxxxx
sasl.mechanism=PLAIN
# 关闭主机名验证时客户端也必须设置以下参数
ssl.endpoint.identification.algorithm=给客户端配置连接需要的账号密码,以及对应安全机制,并且提供客户端的信任库,以便服务端发送证书过来的时候进行证书的校验。
3. 配置文件启动 AutoMQ
bash
bin/kafka-server-start.sh /root/automq/config/kraft/sasl_ssl.properties第二步:为 AutoMQ 准备数据
现在我们有一些订单数据,信息包含了用户订单的 ID、订单创建时间、商品名称、商品条码、商品种类、收货地址、购买数量、商品单价、商品成本价、营业额、本单利润等信息,数据格式如下:
properties
{
"order_id": "141234",
"order_date": "2019/1/22 21:25:00",
"product", "iPhone",
"product_ean": "5563319511488",
"categorie": "Vêtements",
"purchase_address": "944 Walnut St, Boston, MA 02215",
"quantity_ordered": "1",
"price_each": "700",
"cost_price": "231",
"turnover": "700",
"margin": "469"
}首先我们需要在 AutoMQ 集群中创建 Topic:
bash
bin/kafka-topics.sh --bootstrap-server xxx.xxx.200.218:9092 --command-config /root/automq/bin/client.properties --create --topic automq-shop1然后我们要通过脚本的形式模拟网站数据流入 AutoMQ 集群的 Topic,实现的 data.sh 脚本如下:
bash
#!/bin/bash
BOOTSTRAP_SERVERS="47.252.41.105:9092"
TOPIC="automq-shop"
CSV_FILE="orders.csv"
messages=""
MAX_LINES=1000
line_count=0
while IFS=',' read -r order_date order_id product product_ean categorie purchase_address1 purchase_address2 purchase_address3 quantity_ordered price_each cost_price turnover margin; do
if [[ "$order_date" == "Order Date" ]]; then
continue
fi
((line_count++))
if [[ $line_count -gt $MAX_LINES ]]; then
break
fi
purchase_address="${purchase_address1},${purchase_address2},${purchase_address3}"
purchase_address=$(echo $purchase_address | tr -d '"')
order_json="{\"order_date\":\"$order_date\",\"order_id\":\"$order_id\",\"product\":\"$product\",\"product_ean\":\"$product_ean\",\"categorie\":\"$categorie\",\"purchase_address\":\"$purchase_address\",\"quantity_ordered\":\"$quantity_ordered\",\"price_each\":\"$price_each\",\"cost_price\":\"$cost_price\",\"turnover\":\"$turnover\",\"margin\":\"$margin\"}"
if [ -z "$messages" ]; then
messages="${order_json}"
else
messages="${messages}#${order_json}"
fi
done < "$CSV_FILE"
echo "$messages" | tr '#' '\n' | /Users/wzj/Desktop/app/automq/bin/kafka-console-producer.sh --broker-list "$BOOTSTRAP_SERVERS" --topic "$TOPIC" --producer.config client.properties创建以上脚本并运行它,这样我们就做好了数据的准备工作。
第三步:将数据流导入到 Tinybird
Tinybird 不仅支持 Kafka 进行数据导入,还支持如:Confluent、Amazon S3、BigQuery 等形式的数据导入。下面我们将教您如何将 AutoMQ 的数据导入到 Tinybird 中。
创建数据源
首先我们需要进入官网提供的控制面板,如下:
点击菜单栏的 Data Sources 再点击创建数据源:
由于 AutoMQ 是对 Kafka 100% 兼容的,所以我们可以点击以 Kafka 形式导入数据:
点击创建一个新的连接,并且把我们创建的集群配置写入:
其中的 Key 和 Secret 是我们创建集群配置 SASL 的用户名和密码
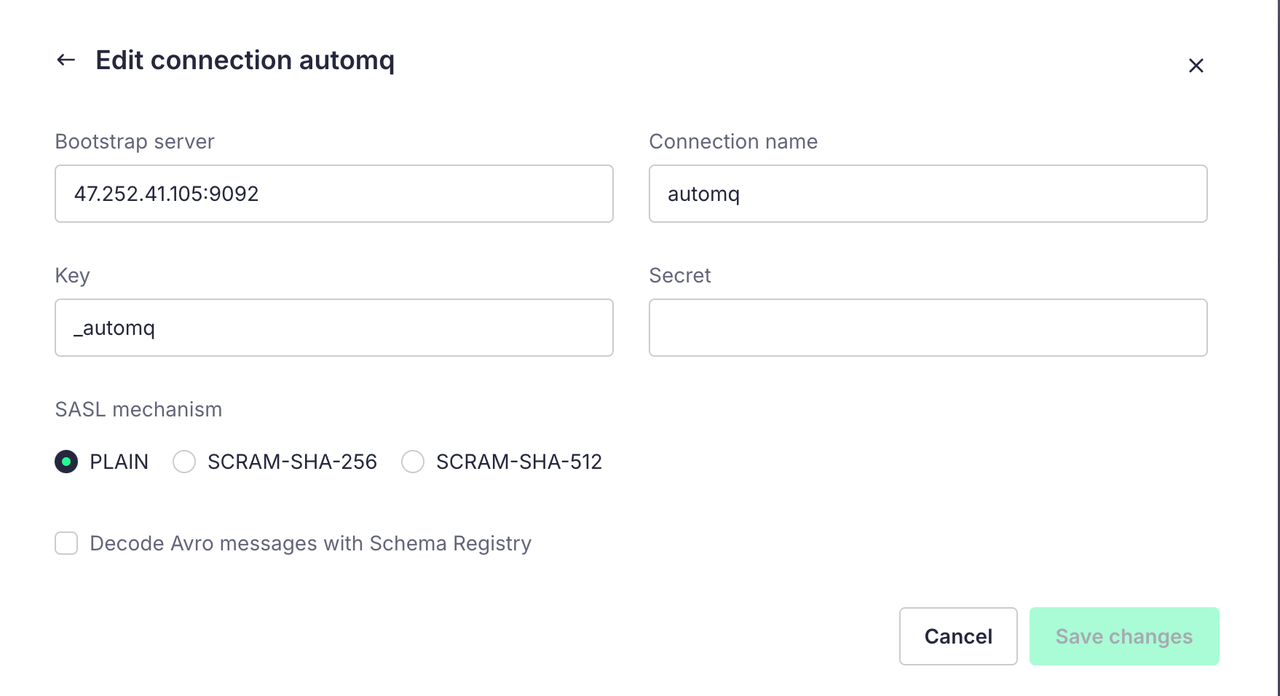
配置完毕后我们就可以点击下一步,进行 Topic 的选择:
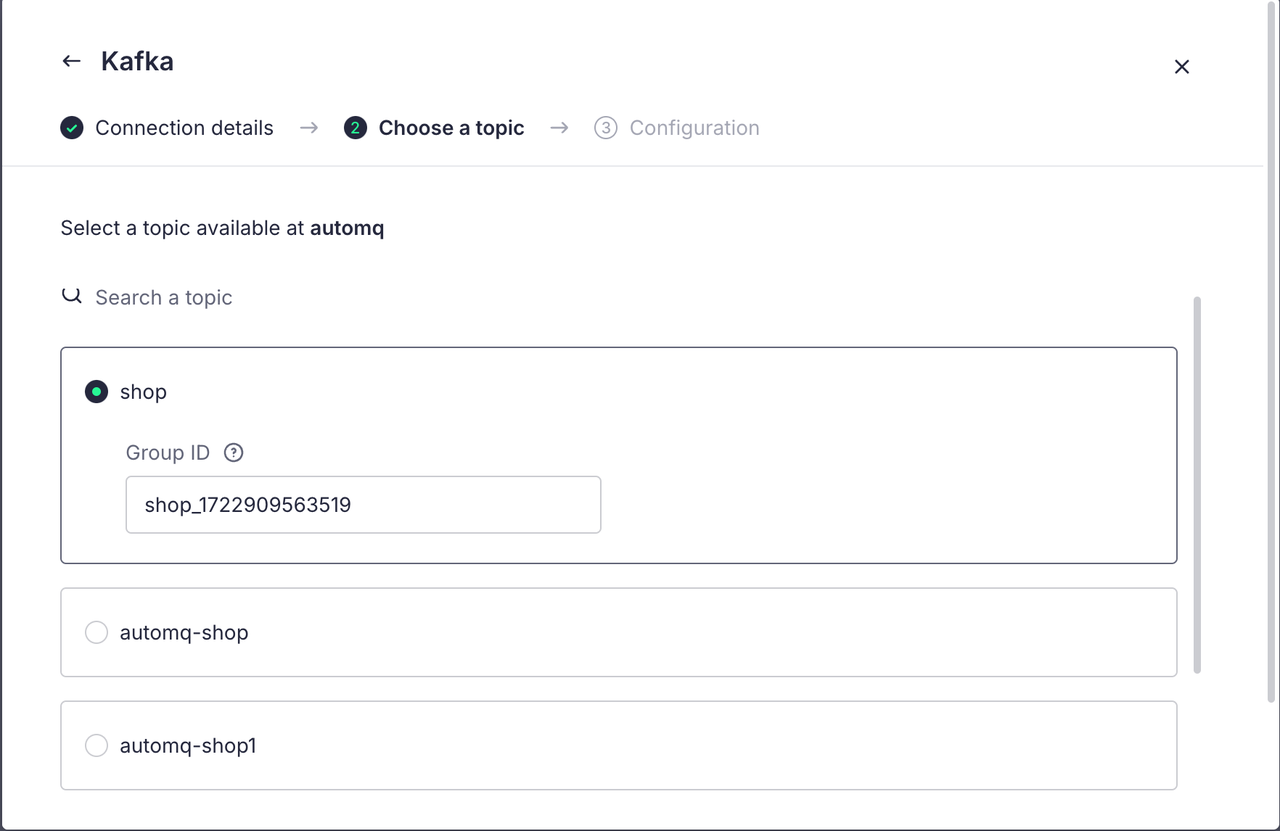
在下一步的配置中,我们可以选择一开始就获取所有的记录或者只获取创建数据源后新追加的记录,我们这里选择第一个:
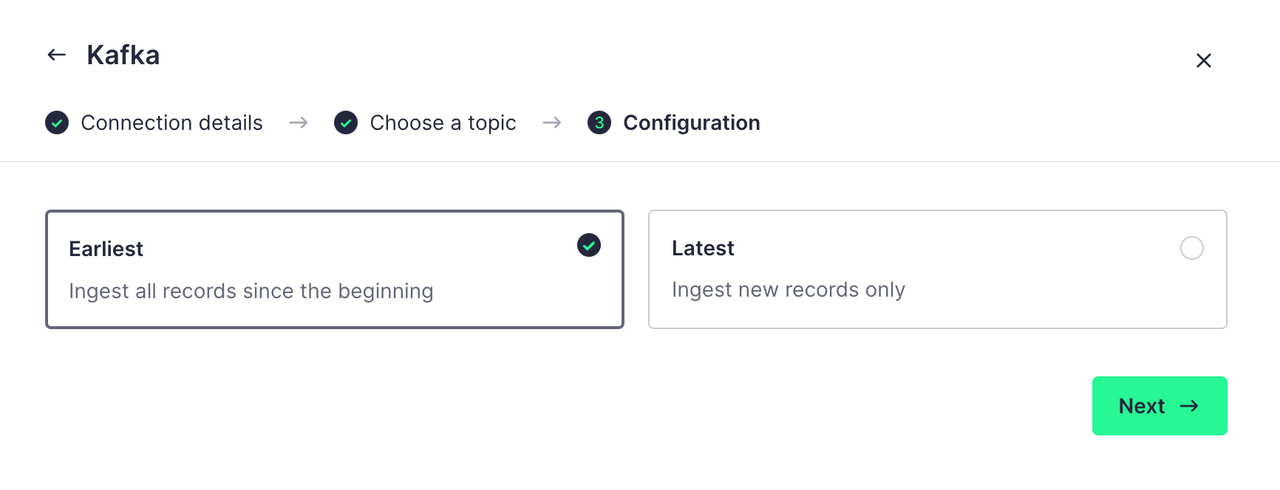
完成配置后,Tinybird 会自动解析 Topic 的数据格式并将其按表格展示出来:
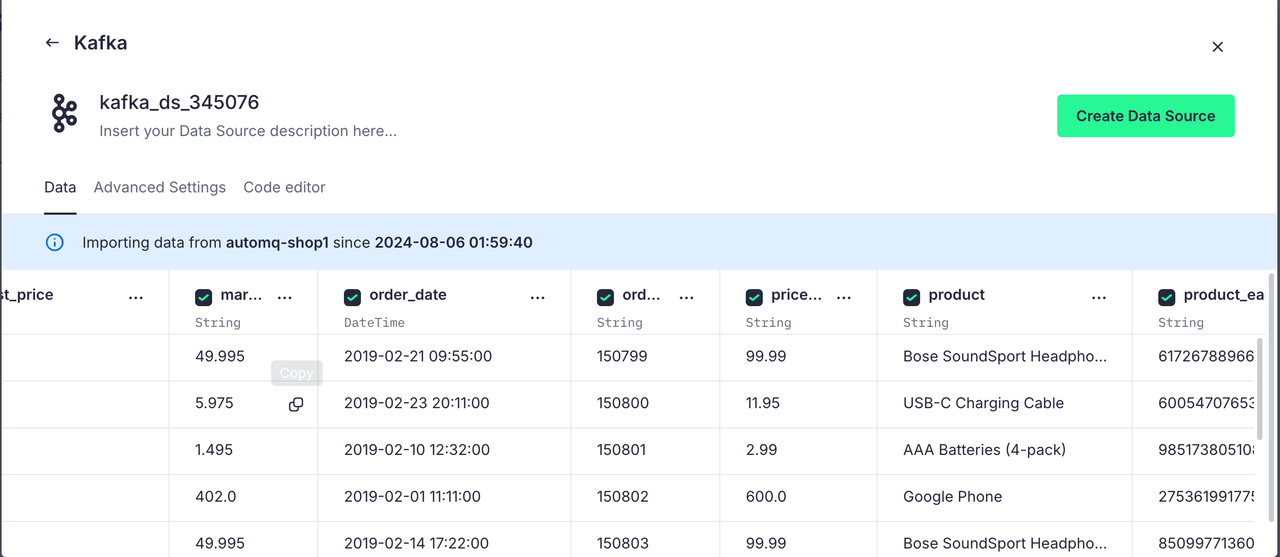
对于不符合我们预期的解析类型,我们也可以进行更改,方便我们后面进行 SQL 操作:
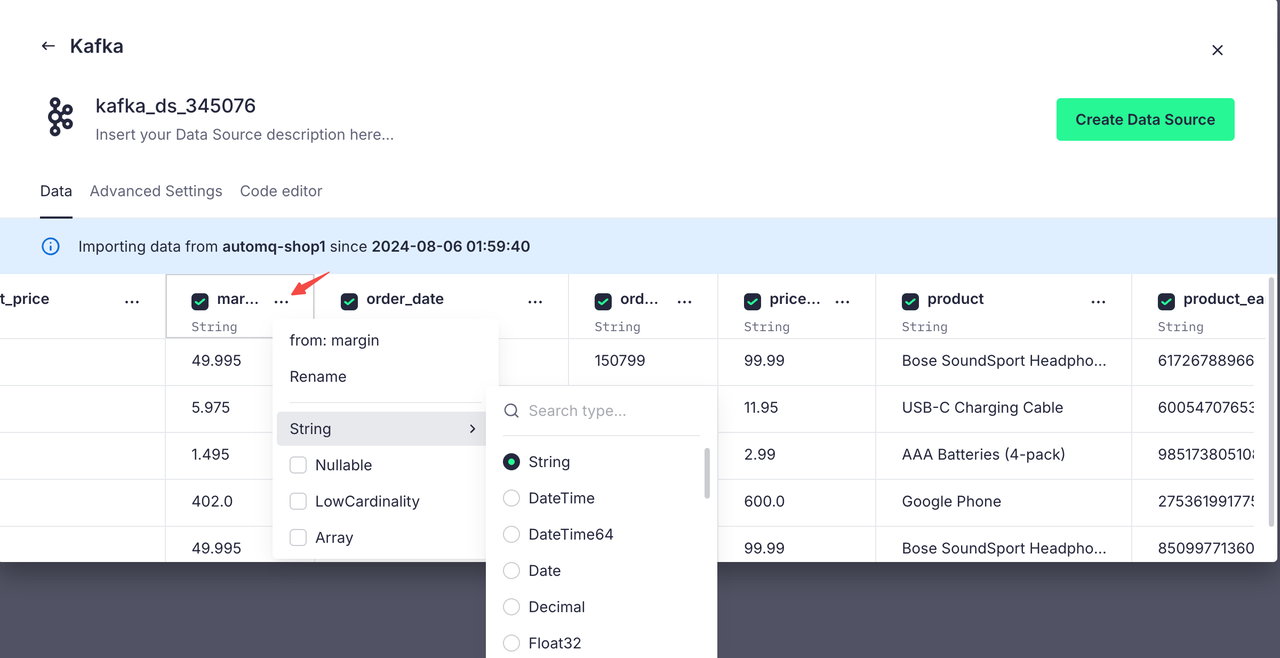
点击 Create Data Source 我们就成功的将 AutoMQ 的 Topic 与 Tinybird 进行了连接,接下来这个 Topic 上的数据都会被 Tinybird 接收到。数据源面板如下:
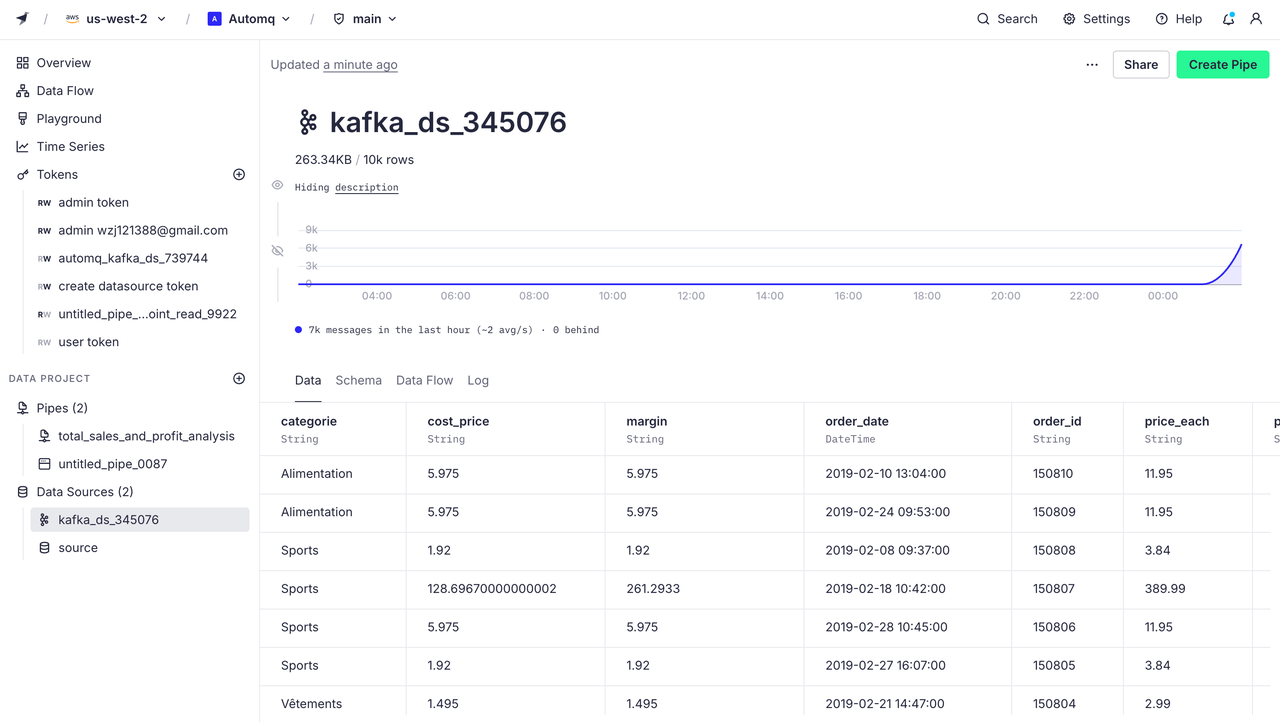
创建管道
Tinybird 提供了强大的 SQL 分析功能,可用于对数据进行过滤、聚合和连接等操作。我们可以通过创建管道来实现不同的 SQL 操作。
点击刚刚我们创建的数据源,在点击页面上的 Create Pipe 即可创建管道:
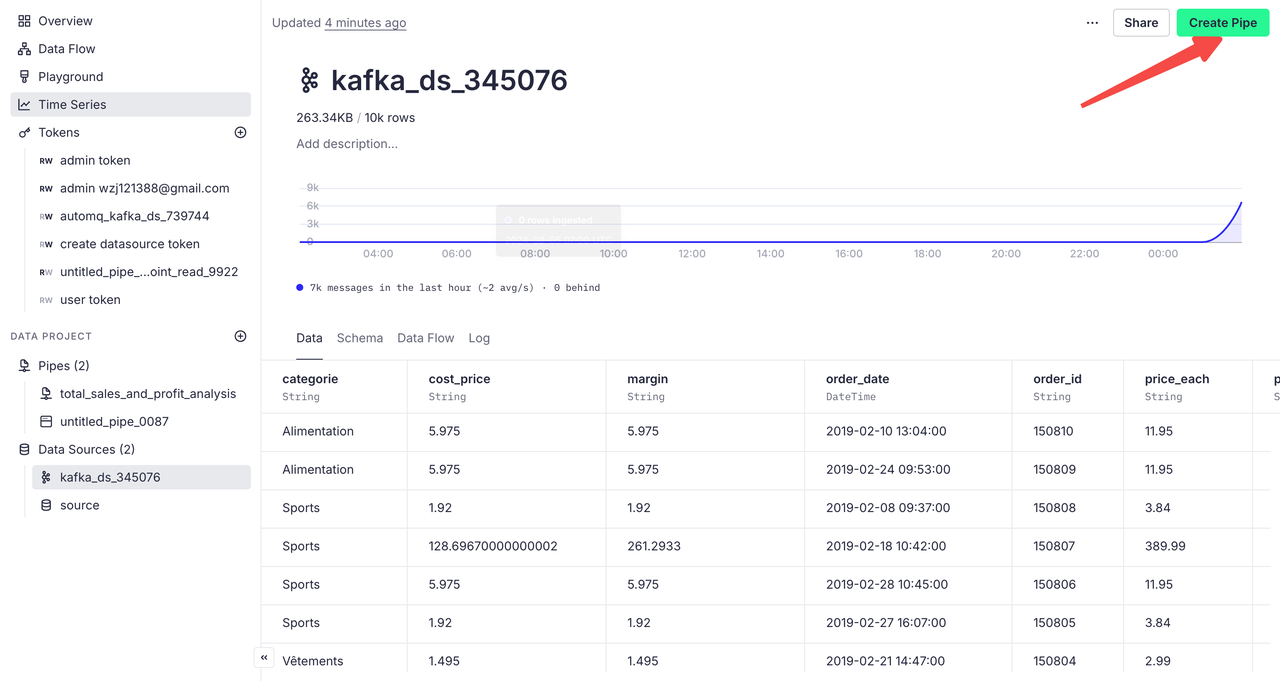
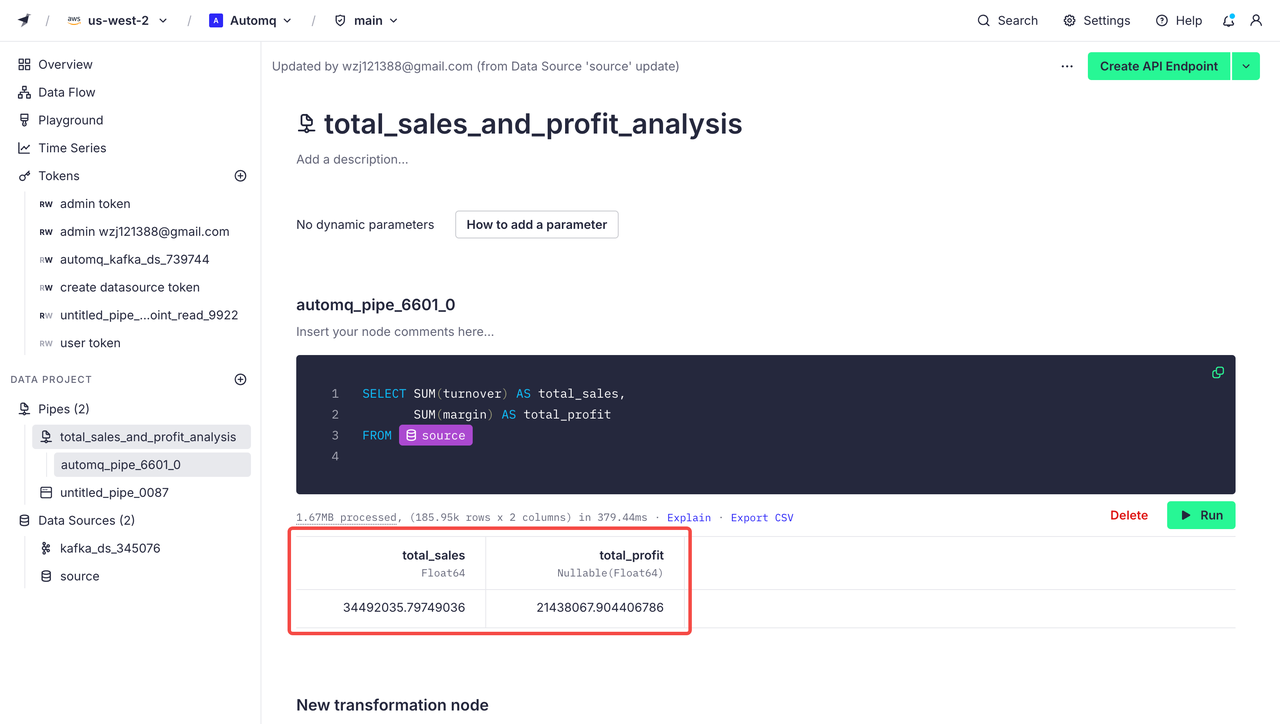
在管道页面,我们可以通过编写 SQL 语句进行数据过滤与分析,比如说我们想要对导入的订单数据进行销售总额与利润分析,在代码块中编写如下代码:
sql
SELECT SUM(turnover) AS total_sales,
SUM(margin) AS total_profit
FROM source运行代码后产生效果如下图所示:
Tinybird 同样支持我们进行复杂的 SQL 编写,比如说我们想要知道哪个产品销量最高,我们可以这样写:
sql
SELECT product,
SUM(quantity_ordered) AS total_quantity
FROM orders
GROUP BY product
ORDER BY total_quantity DESC
LIMIT 1运行后效果如下:
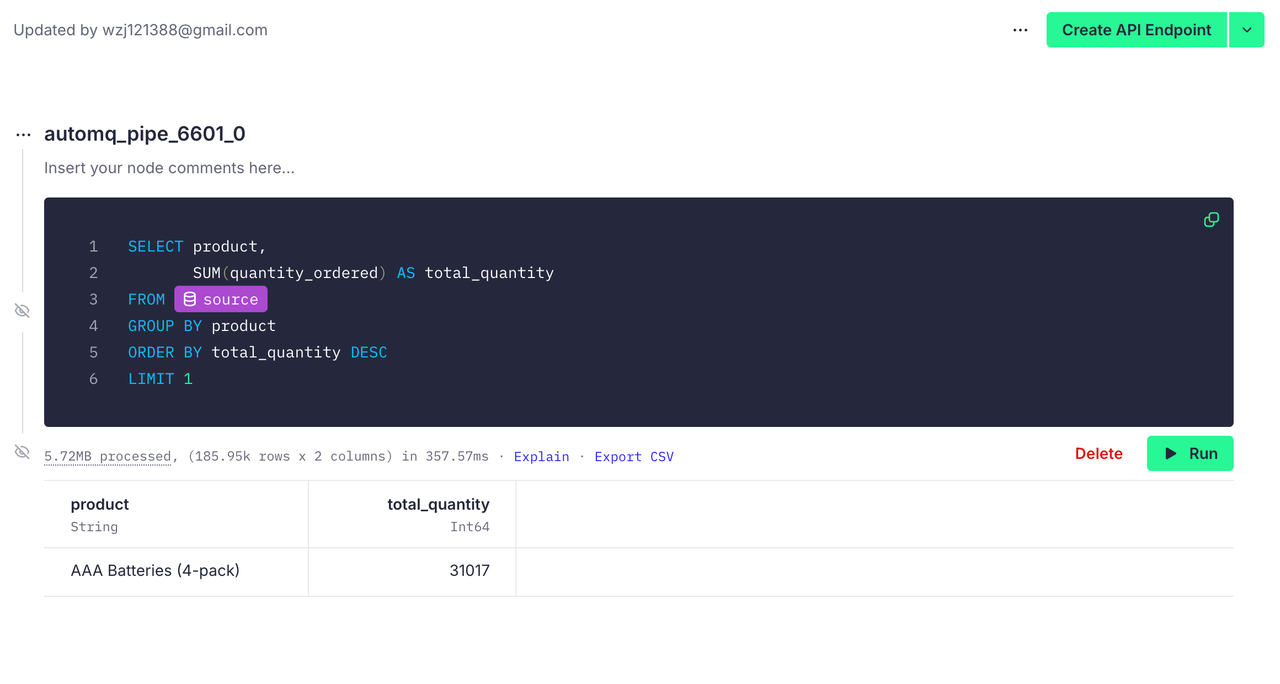
现在我们成功地建立了 AutoMQ 与 Tinybird 的连接,并利用 Tinybird 支持的 SQL 进行了数据分析操作。
第四步:数据可视化
Tinybird 不仅提供数据接口,支持与 Grafana 等可视化平台的集成,还可以进行基本的数据可视化分析。如需了解如何使用其他平台进行可视化,请参考 Tinybird 提供的文档教程9。本次我们将使用 Tinybird 自身提供的可视化工具进行场景分析。
场景一:区域销售最高产品分析
我们想要通过分析不同区域的销售数据,识别出在特定区域最受欢迎的产品和类别。这有助于公司在不同区域优化库存分配,避免缺货或滞销,提高客户满意度和销售额。
比如说我们想要获取 Boston 地区的销售数据 ,我们可以编写出如下 SQL:
sql
SELECT
SUBSTRING_INDEX(SUBSTRING_INDEX(purchase_address, ',', 2), ',', -1) AS region,
product,
SUM(quantity_ordered) AS total_quantity
FROM
source
GROUP BY
region, product
HAVING
region = ' Boston'
ORDER BY
region, total_quantity DESC通过运行所得如下:
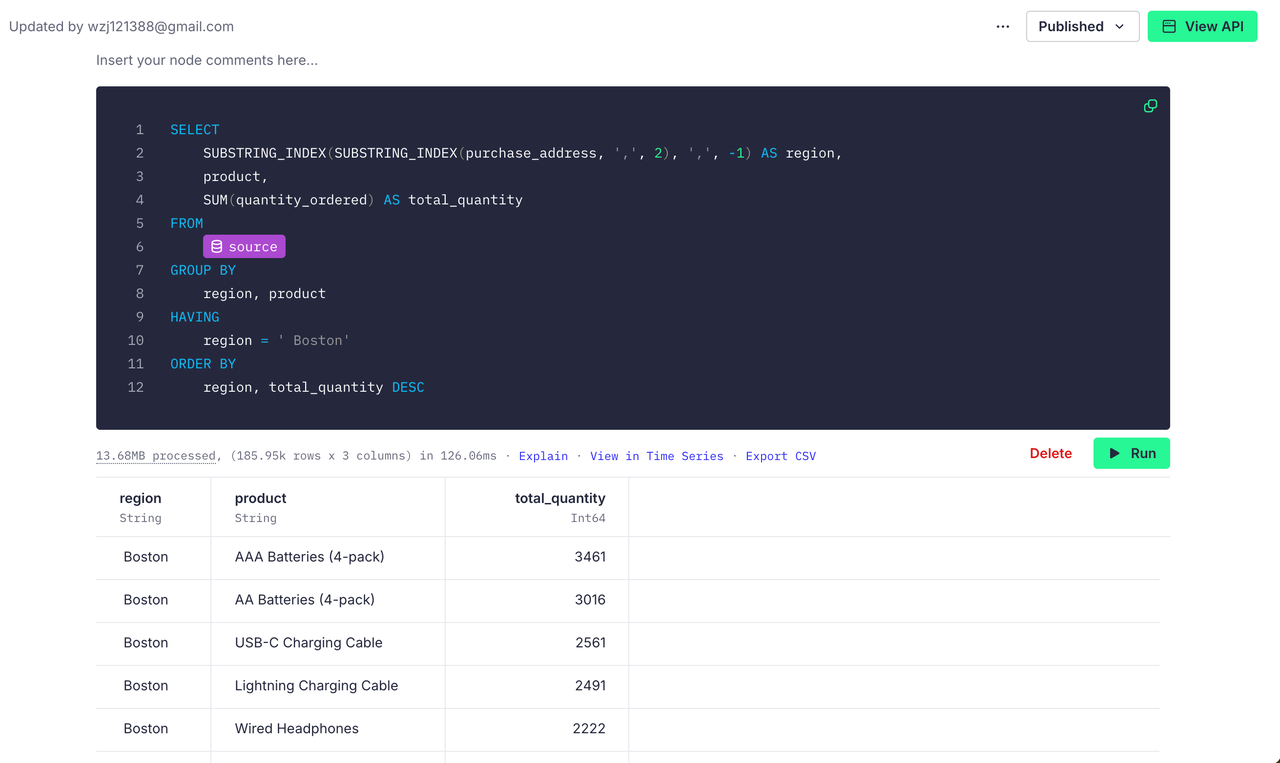
点击右上角的 Create API Endpoint 再点击 Create Chart,我们就能进入创建图标的页面:
在这里我们可以选择 Bar List 图标格式,选择产品作为下标,得出可视化结果如下:
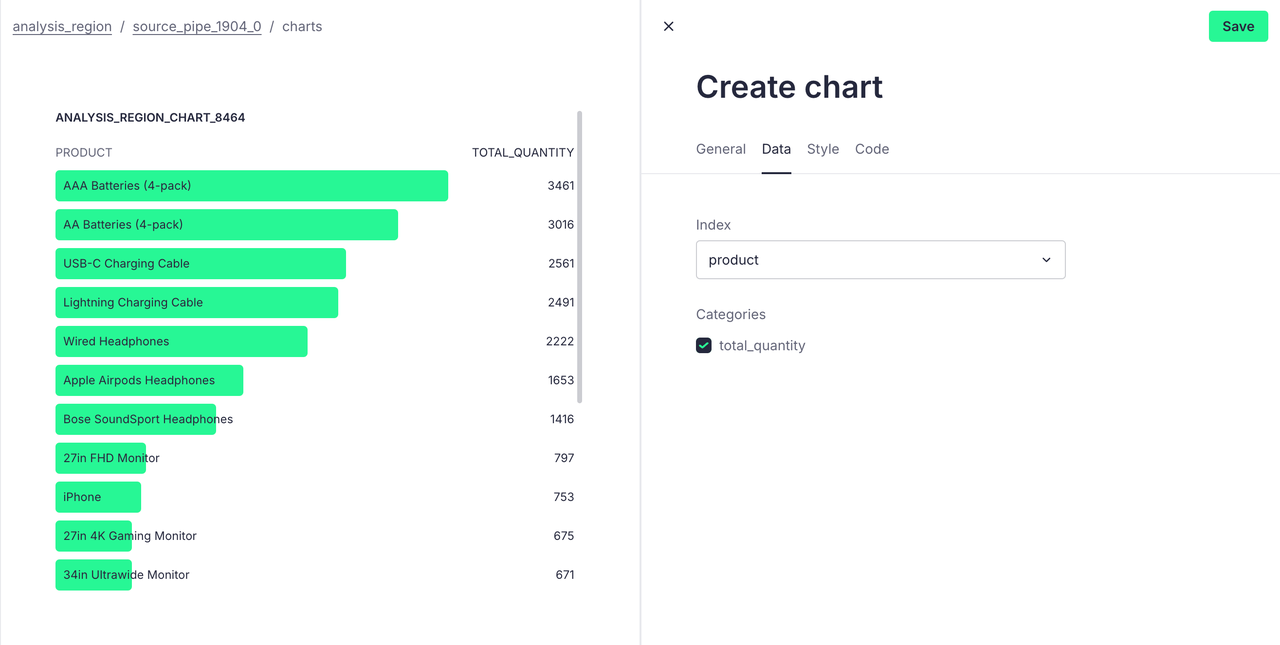
现在我们就可以针对 Boston 区域构建备货策略,确保有充足的库存来满足高需求,或者针对热销产品进行特定市场推广活动,例如折扣、赠品等,进一步提升销售。
场景二:地理位置销售分布分析
我们想要通过分析不同地理区域的销售情况,来识别主要市场在哪。了解哪些区域销售表现最好,可以帮助企业更清晰地定位其目标市场,并针对特定区域制定营销策略。
针对上述需求,我们可以编写出如下 SQL:
sql
SELECT SUBSTRING_INDEX(SUBSTRING_INDEX(purchase_address, ',', 2), ' ', -1) AS city,
SUM(turnover) AS city_sales
FROM source
GROUP BY city
ORDER BY city_sales DESC我们同样可以得到以下的可视化数据:
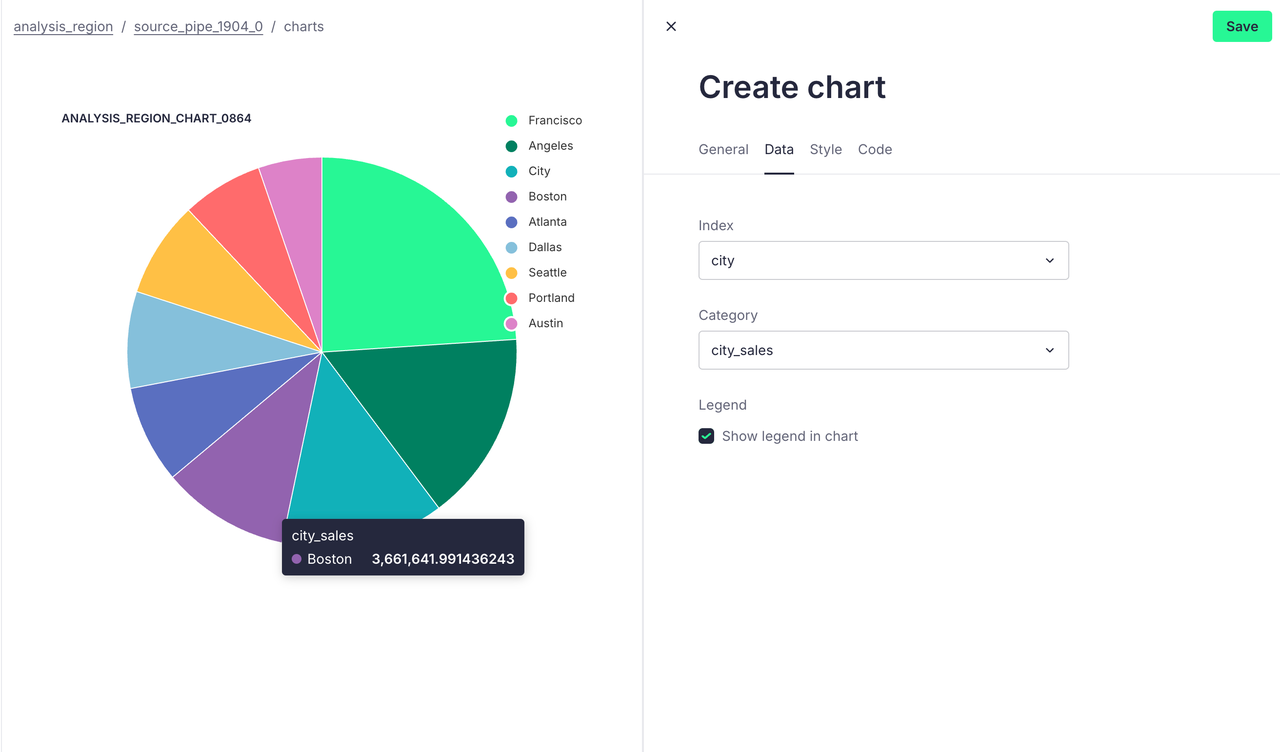
场景三:产品的月销量分析
我们想分析某产品的每月销量,可以识别出季节性销售高峰和低谷,便于企业针对季节制定营销策略;还可以了解产品在市场上的生命周期,有助于合理安排库存。
我们这以 iPhone 为例,根据需求写出如下 SQL 语句:
sql
SELECT
DATE_FORMAT(order_date, '%Y-%m') AS month,
SUM(quantity_ordered) AS total_quantity,
SUM(turnover) AS total_sales
FROM
source
WHERE
product = 'iPhone'
GROUP BY
month
ORDER BY
month通过可视化操作,我们可以得出下面这张表格:
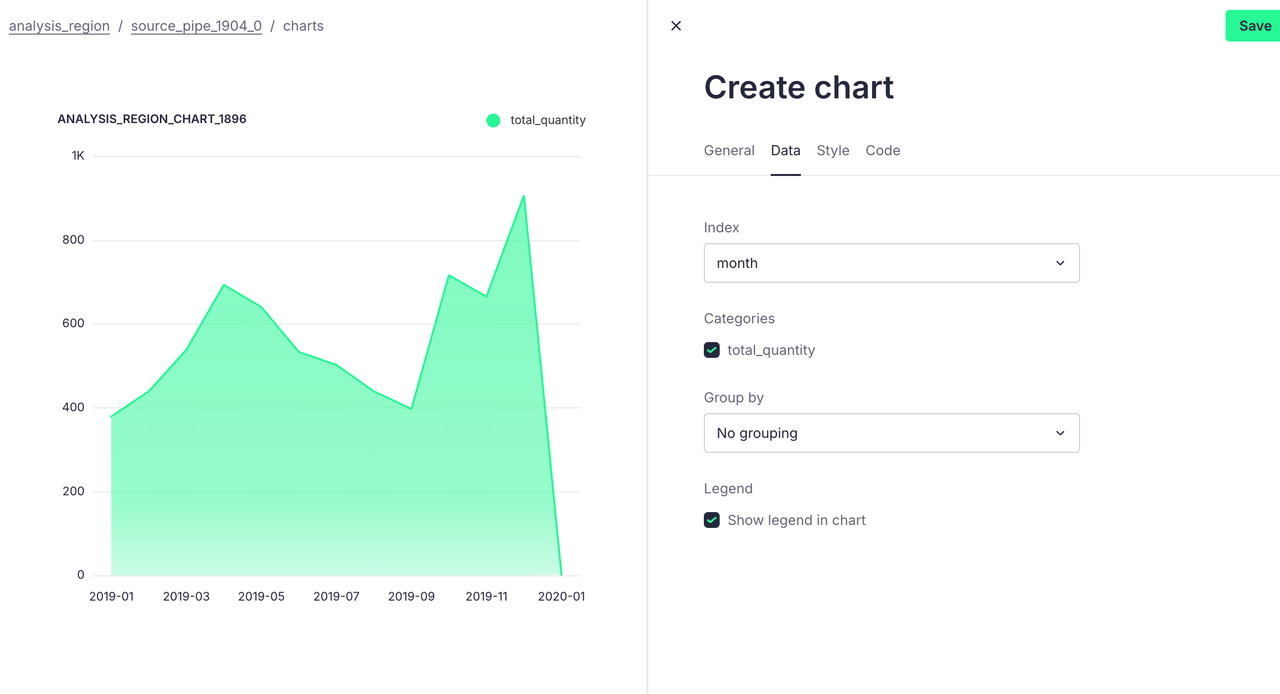
总结
本文详细介绍了如何整合 AutoMQ 与 Tinybird 进行简单的数据分析操作,文中展示的分析仅作示例。如果您的数据点已经准备就绪,并提供必要的数据,可以尝试通过在官网学习更复杂的分析和转换逻辑,并加以实现。如有任何问题或需要帮助,请随时联系我们。
参考资料:
1 Kafka: https://kafka.apache.org/
2 AutoMQ: https://www.automq.com
3 Tinybird: https://www.tinybird.co/
4 Quick start Tinybird: https://www.tinybird.co/docs/quick-start
5 Quick start AutoMQ: https://docs.automq.com/zh/automq/getting-started/cluster-deployment-on-linux
6 AutoMQ SASL 安全身份认证配置教程:https://www.automq.com/zh/blog/automq-sasl-security-authentication-configuration-guide
7 AutoMQ SSL 安全协议配置教程: https://www.automq.com/zh/blog/automq-ssl-security-protocol-configuration-tutorial
8 Data Source: https://www.kaggle.com/datasets/vincentcornlius/sales-orders
9 Consume API Endpoints in Grafana: https://www.tinybird.co/docs/guides/integrations/consume-api-endpoints-in-grafana