混合专家模型(Mixture of Experts, MoE)是一种先进的机器学习技术,通过将复杂问题分解为多个子任务,并由多个专门的"专家"模型分别处理,最终通过门控网络(gating network)将这些专家的输出组合起来,以实现高效、准确的预测或决策。以下是关于混合专家模型的详细解析:
1. 基本概念与架构
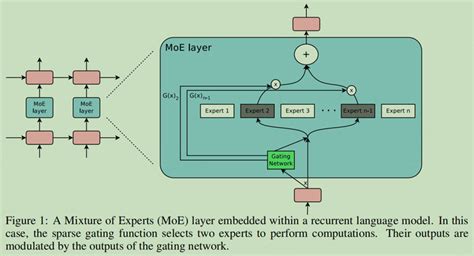
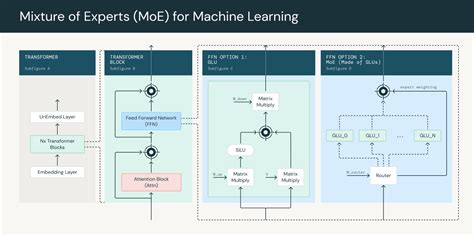
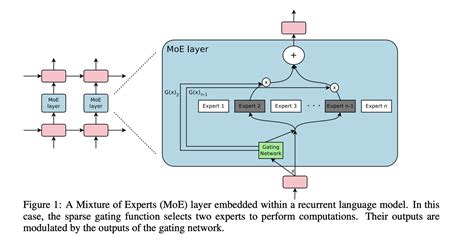
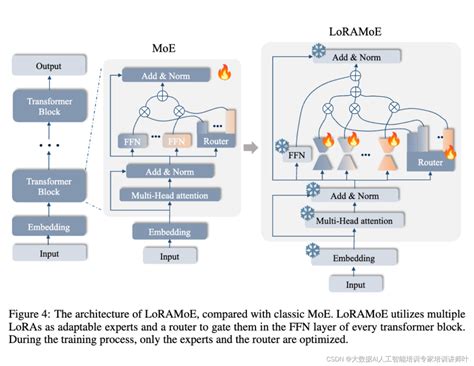
混合专家模型的核心思想是将一个大型问题分解为多个较小的子任务,每个子任务由一个专家模型负责处理。这些专家模型可以是神经网络、决策树或其他机器学习模型。门控网络的作用是根据输入数据动态选择最合适的专家模型进行处理,并对各专家的输出进行加权组合。
2. 关键组件
- 专家模型(Experts) :每个专家模型专注于处理特定类型的输入数据或任务。例如,在自然语言处理中,一个专家可能专门处理情感分析,另一个专家处理主题建模。
- 门控网络(Gating Network) :负责根据输入数据的特征动态选择最合适的专家模型。门控网络通常是一个简单的神经网络,通过计算输入与各个专家之间的相似度来决定每个专家的权重。
- 池化操作(Pooling) :用于整合各个专家的输出,常见的方法包括加权求和或softmax函数。
3. 工作流程
- 输入处理:输入数据首先通过门控网络,门控网络根据输入数据的特征动态选择最合适的专家模型。
- 专家处理:被选中的专家模型对输入数据进行处理,生成中间结果。
- 输出整合:门控网络根据每个专家的输出和权重,通过池化操作生成最终的预测结果。
4. 优势
- 高效扩展性:MoE模型可以在不显著增加计算资源的情况下,通过增加专家的数量来扩展模型的规模和能力。
- 计算效率:与稠密模型相比,MoE模型在训练和推理阶段可以显著减少计算资源的消耗。
- 灵活性:MoE模型可以根据输入数据的特点动态选择最合适的专家,从而提高模型的适应性和准确性。
5. 应用场景
- 自然语言处理(NLP) :MoE模型在文本分类、情感分析、机器翻译等任务中表现出色。
- 计算机视觉(CV) :在图像分类、目标检测等任务中,MoE模型能够有效处理复杂的空间特征。
- 推荐系统:通过动态选择最相关的专家模型,MoE可以提高推荐系统的准确性和个性化程度。
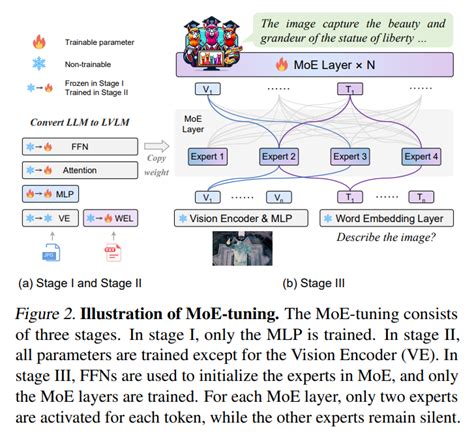
6. 挑战与改进
- 训练复杂性:MoE模型的训练需要同时优化多个专家模型和门控网络,增加了训练的复杂性。
- 负载均衡:如何平衡各个专家的负载,避免某些专家过载或资源浪费,是一个重要的研究方向。
- 软门控机制:为了解决传统硬门控机制的局限性,研究者提出了软门控机制,通过评分矩阵为每个专家分配令牌并做出路由决策。
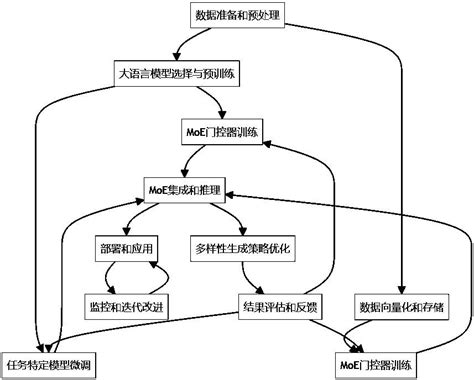
7. 未来展望
随着深度学习技术的不断发展,MoE模型在大规模预训练模型(如GPT-4、Mistral-8x7B等)中的应用越来越广泛。未来,MoE模型有望在更多领域实现突破,特别是在处理复杂、高维数据时,展现出更大的潜力。
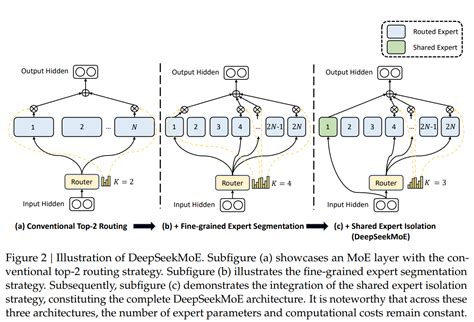
混合专家模型通过将复杂问题分解为多个子任务,并利用多个专家模型的集体智慧,不仅提高了模型的性能和效率,还为大规模机器学习任务提供了新的解决方案。然而,MoE模型的训练和优化仍面临一些挑战,需要进一步的研究和改进。
本文由博客一文多发平台 OpenWrite 发布!