首先建立的界面效果如下:
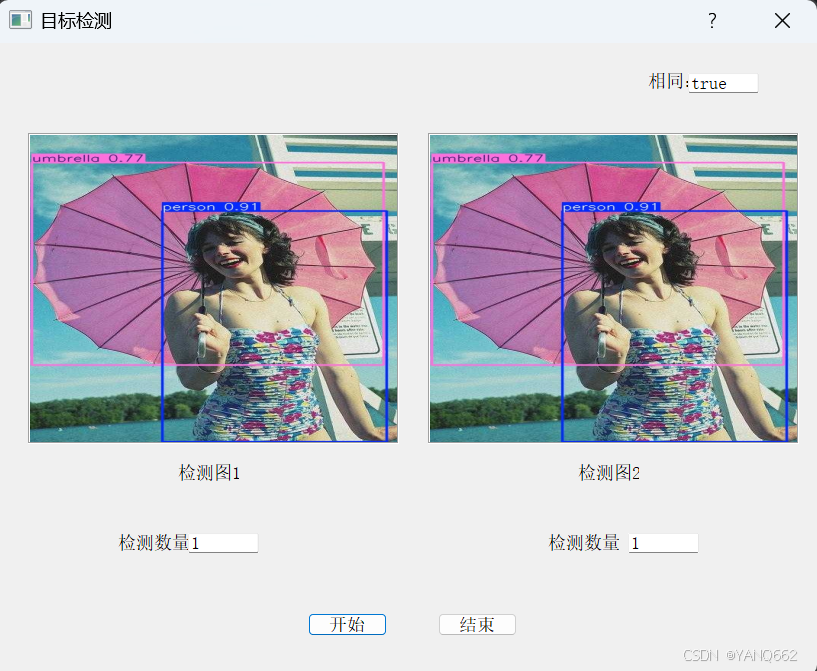
以上界面中,检测图1是yolov8模型检测得到的图片显示,检测图2是deeplabv3模型检测处理后得到的图片;下面检测数量是两个模型分别检测到的目标数量(图片中人的个数);右上角的相同是指两个模型的检测数量是否相同,若相同则显示"true",否则显示"false"。下面简单介绍该功能实现的步骤。
1.实现步骤
一、 读取图片
二、yolov8检测图片,得到检测结果(图片、类名称、目标数量)
四、deeplabv3检测图片,得到检测结果(图片、类名称、目标数量)
五、designer界面显示检测的结果
2.designer功能的实现
一、安装Qt Designer
在虚拟环境下终端运行以下代码即可
pip install PyQt5
pip install pyqt5-tools其他操作步骤可以看博客:Qt Designer 详细介绍-CSDN博客。
二、将.UI文件转为.py文件
在pycharm的终端运行以下代码即可:
# 对于 PyQt5
pyuic5 -x designer.ui -o ui_designer.py
# 对于 PySide2
pyside2-uic designer.ui > ui_designer.py修改后的结果如下:
from PyQt5 import QtCore, QtGui, QtWidgets
import cv2
import sys
class Ui_Dialog(object):
def setupUi(self, Dialog):
Dialog.setObjectName("Dialog")
Dialog.resize(819, 632)
self.start = QtWidgets.QPushButton(Dialog)
self.start.setGeometry(QtCore.QRect(310, 570, 79, 23))
self.start.setObjectName("start")
self.finish = QtWidgets.QPushButton(Dialog)
self.finish.setGeometry(QtCore.QRect(440, 570, 79, 23))
self.finish.setObjectName("finish")
self.detection1_text = QtWidgets.QLabel(Dialog)
self.detection1_text.setGeometry(QtCore.QRect(180, 420, 61, 20))
self.detection1_text.setObjectName("detection1_text")
self.detection_nums1 = QtWidgets.QLabel(Dialog)
self.detection_nums1.setGeometry(QtCore.QRect(120, 490, 71, 20))
self.detection_nums1.setObjectName("detection_nums1")
self.detection2_text = QtWidgets.QLabel(Dialog)
self.detection2_text.setGeometry(QtCore.QRect(580, 420, 61, 20))
self.detection2_text.setObjectName("detection2_text")
self.detection_nums2 = QtWidgets.QLabel(Dialog)
self.detection_nums2.setGeometry(QtCore.QRect(550, 490, 71, 20))
self.detection_nums2.setObjectName("detection_nums2")
self.compares = QtWidgets.QLabel(Dialog)
self.compares.setGeometry(QtCore.QRect(650, 30, 41, 16))
self.compares.setObjectName("compares")
self.nums1 = QtWidgets.QLineEdit(Dialog)
self.nums1.setGeometry(QtCore.QRect(190, 490, 71, 20))
self.nums1.setObjectName("nums1")
self.nums2 = QtWidgets.QLineEdit(Dialog)
self.nums2.setGeometry(QtCore.QRect(630, 490, 71, 20))
self.nums2.setObjectName("nums2")
self.true_false = QtWidgets.QLineEdit(Dialog)
self.true_false.setGeometry(QtCore.QRect(690, 30, 71, 20))
self.true_false.setObjectName("true_false")
self.img1 = QtWidgets.QLabel(Dialog)
self.img1.setGeometry(QtCore.QRect(30, 90, 371, 311))
self.img1.setAutoFillBackground(True)
self.img1.setFrameShape(QtWidgets.QFrame.Box)
self.img1.setFrameShadow(QtWidgets.QFrame.Sunken)
self.img1.setObjectName("img1")
self.img2 = QtWidgets.QLabel(Dialog)
self.img2.setGeometry(QtCore.QRect(430, 90, 371, 311))
self.img2.setAutoFillBackground(True)
self.img2.setFrameShape(QtWidgets.QFrame.Box)
self.img2.setFrameShadow(QtWidgets.QFrame.Sunken)
self.img2.setObjectName("img2")
self.retranslateUi(Dialog)
QtCore.QMetaObject.connectSlotsByName(Dialog)
def retranslateUi(self, Dialog):
_translate = QtCore.QCoreApplication.translate
Dialog.setWindowTitle(_translate("Dialog", "目标检测"))
self.start.setText(_translate("Dialog", "开始"))
self.finish.setText(_translate("Dialog", "结束"))
self.detection1_text.setText(_translate("Dialog", "检测图1"))
self.detection_nums1.setText(_translate("Dialog", "检测数量1:"))
self.detection2_text.setText(_translate("Dialog", "检测图2"))
self.detection_nums2.setText(_translate("Dialog", "检测数量2:"))
self.compares.setText(_translate("Dialog", "相同:"))
self.img1.setText(_translate("Dialog", "显示图片"))
self.img2.setText(_translate("Dialog", "显示图片"))
# UI界面更新实时数据
def real_time_update_paramas(self,detect_img1_nums,detect_img2_nums,true_or_false):
_translate = QtCore.QCoreApplication.translate
self.nums1.setText(_translate("Dialog", detect_img1_nums))# 图片1检测到的目标数量
self.nums2.setText(_translate("Dialog", detect_img2_nums))# 图片2检测到的目标数量
self.true_false.setText(_translate("Dialog", true_or_false))# 两个数量是否相同(true or false)
# UI界面显示图片
def show_img1(self,img_path1):
# 显示lena图像
pixmap = QtGui.QPixmap(img_path1) # 创建相应的QPixmap对象
ui.img1.setScaledContents(True) # 设置铺满
ui.img1.setPixmap(pixmap) # 显示lena图像
def show_img2(self,img_path2):
# 显示lena图像
pixmap = QtGui.QPixmap(img_path2) # 创建相应的QPixmap对象
ui.img2.setScaledContents(True) # 设置铺满
ui.img2.setPixmap(pixmap) # 显示lena图像
if __name__ == "__main__":
# ====================> 1.建立一个UI显示界面 <====================
app = QtWidgets.QApplication(sys.argv)
Dialog = QtWidgets.QDialog()
ui = Ui_Dialog()
ui.setupUi(Dialog)# 1.基本参数显示
# 下面用两种模型检测图片
# 读取图片
# =====================> 2.yolov8检测图片 <=====================
# ===================> 3.deeplabv3检测图片 <===================
# ================> 4.将两种检测结果在UI界面显示 <================
# 2.检验图片的显示
path1 = "D:\AI\\ultralytics-main\\tests\img3.jpg" # yolov8模型检测结果
path2 = "D:\AI\\ultralytics-main\\tests\img3.jpg" # deeplabv3模型检测结果
ui.show_img1(path1)
ui.show_img2(path2)
# 检验结果的文本显示
detect_img1_nums = "1"
detect_img2_nums = "1"
true_or_false = "true"
ui.real_time_update_paramas(detect_img1_nums,detect_img2_nums,true_or_false)
Dialog.show()
sys.exit(app.exec_())**注意:**上面代码留出了目标检测和语义分割模型检测的功能,容易实现。
3.yolov8功能的实现
yolov8的检测不需要所有的开源文件,比如要用yolo模型时,只需要复制出yolov8文件夹下的ultralytics文件即可,并和该文件同级别写个1.preds.py的检测文件,文件内容如下:
from ultralytics import YOLO
#from PIL import Image
import cv2
model = YOLO("yolov8n.pt")
im2 = cv2.imread("img1.jpg")
results = model.predict(source=im2, save=True, save_txt=True) # 将预测保存为标签
print()
for item in results:
if item == "name":
print(item)
if item == "save_dir":
print(item)
if item == "path":
print(item)其实,直接运行这个文件就可以了,但我们还可以对ultralytics文件内的一些文件进行删减,因为该文件不仅仅是yolo测试,还有其他检测。
我们进入该文件夹下的models文件夹下再次删减,删减后的结果如下:
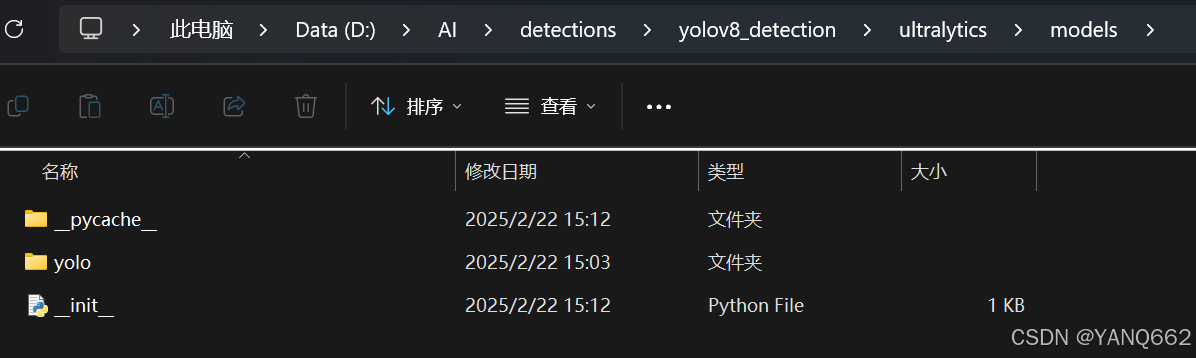
当然,删除后,该文件夹下的一些py文件需要修改:
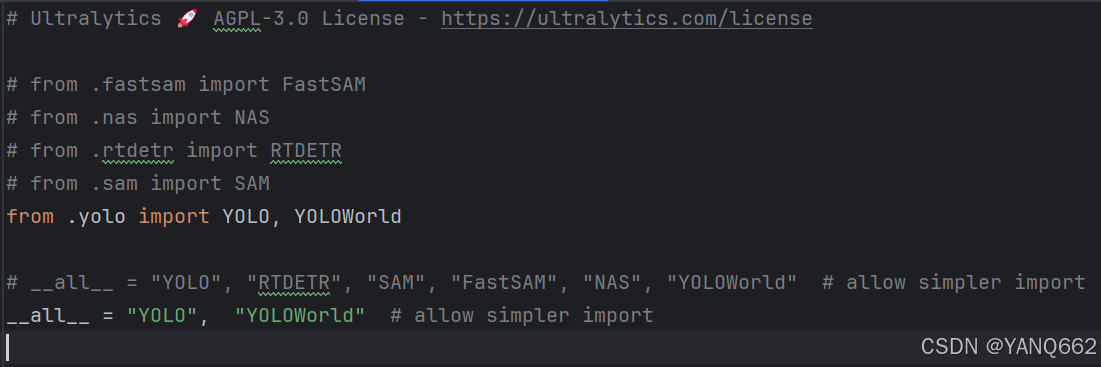
1.下图中的__init__.py文件的修改后的内容如下:


2.下图中的__init__.py文件的修改后的内容如下:
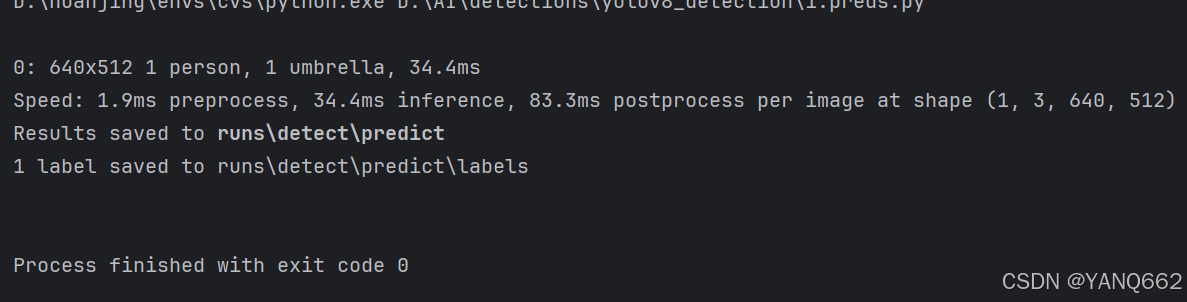
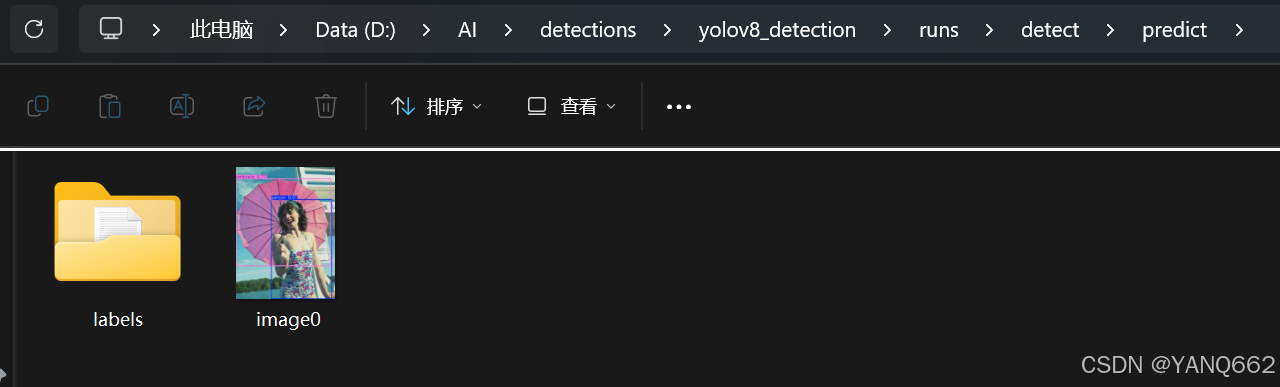
最后运行1.preds.py的代码,结果如下:
4.deeplabv3功能的实现
该模型可以看专栏专栏管理-CSDN创作中心,比较简单。