本文介绍基于Ubuntu系统如何搭建Hadoop和Spark集群,详细介绍了整个搭建流程,包括安装、配置、部署等。过程中若有疑问可提前移步答疑一节。
目录
[1.安装 MobaXterm](#1.安装 MobaXterm)
一、使用VMware安装虚拟机Ubuntu系统
1.安装ubuntu系统
由于某些原因,现在在VMware官网VMware by Broadcom - Cloud Computing for the Enterprise下载需要注册用户,根据其提示进行即可,注意使用的ISO映像文件。
VMware内安装虚拟机,选择Ubuntu系统,其余默认即可。安装完成后注册用户,在文件夹主目录下启动终端。
2.修改主机名
为方便后续的操作,我们需要修改机器的主机名 ,在终端中输入hostname可查看当前主机名(刚安装好系统,此时应为默认的主机名)
要修改系统设置需用超级账户root,这里我们使用sudo命令修改主机名,输入以下命令:
sudo hostnamectl set-hostname new_hostname(将"new_hostname"替换为要设置的新主机名)
完成后,要将此机器的IP地址添加到hosts中。
要获取IP地址:在终端输入(区分大小写!)
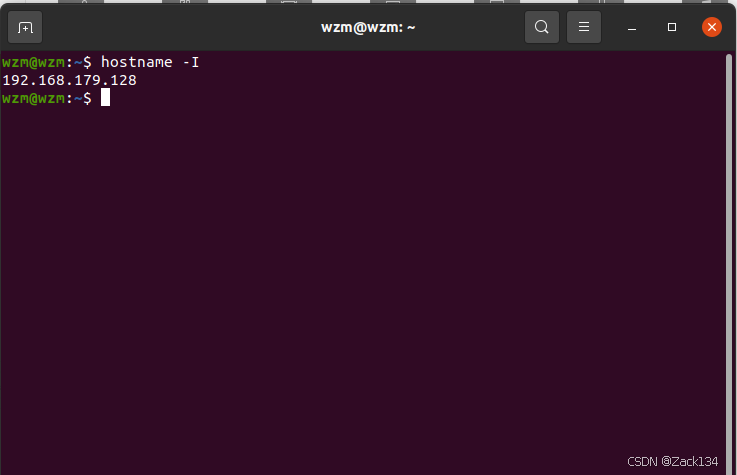
将得到的IP添加到hosts中:
sudo vim /etc/hosts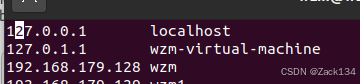
完成上述操作后,重启系统使其生效:
sudo reboot二、下载一个ftp软件用于上传压缩包
1.安装 MobaXterm
在Windows上下载一个ftp软件,这里选择使用MobaXterm,下载地址:支持 SSH、telnet、RDP、VNC 和 X11 的 MobaXterm Xserver - 家庭版
下载安装好后准备设置一个ftp或sftp,此时需要在Ubuntu上下载ssh服务并获取到虚拟机的IP地址:
2.下载ssh
在主目录中打开终端,输入以下语句安装ssh:
sudo apt-get update #更新系统包
sudo apt-get install openssh-server #安装ssh服务
sudo systemctl start ssh #启动ssh服务
sudo systemctl enable ssh #ssh开机自启动然后设置ssh免密登录(输入下面语句,过程中继续回车即可):
ssh-keygen -t rsa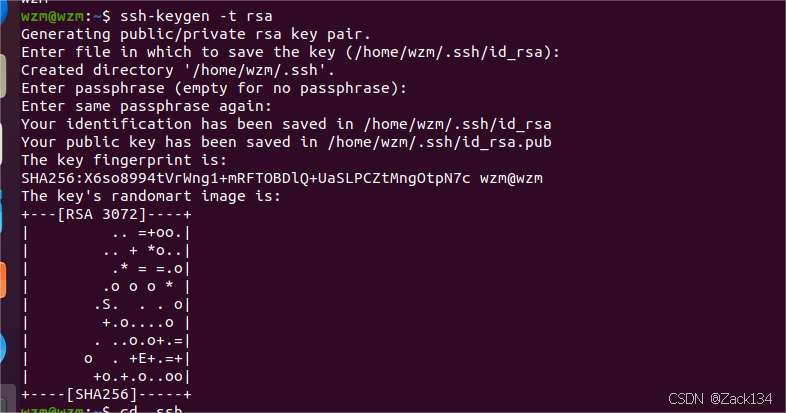
cp id_rsa.pub authorized_keys #将公钥文件拷贝授权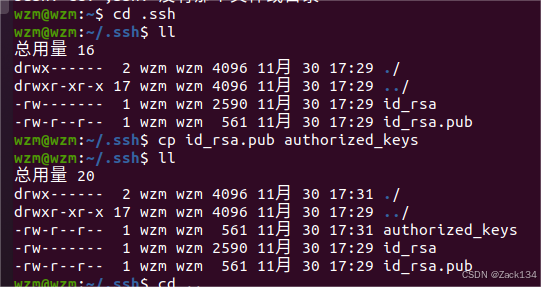
进行过此操作后,即可直接启动ssh,免密登录
另外需关闭防火墙以防节点之间受干扰
systemctl stop firewalld #停用防火墙
systemctl disable firewalld #永久关闭(从安全角度考虑会有不妥,但要实现节点间的连接)
部署完ssh后,就可以通过ftp或sftp将java、hadoop、spark安装包从Windows传给Ubuntu了
3.设置ftp
打开MobaXterm,点击session,创建ftp
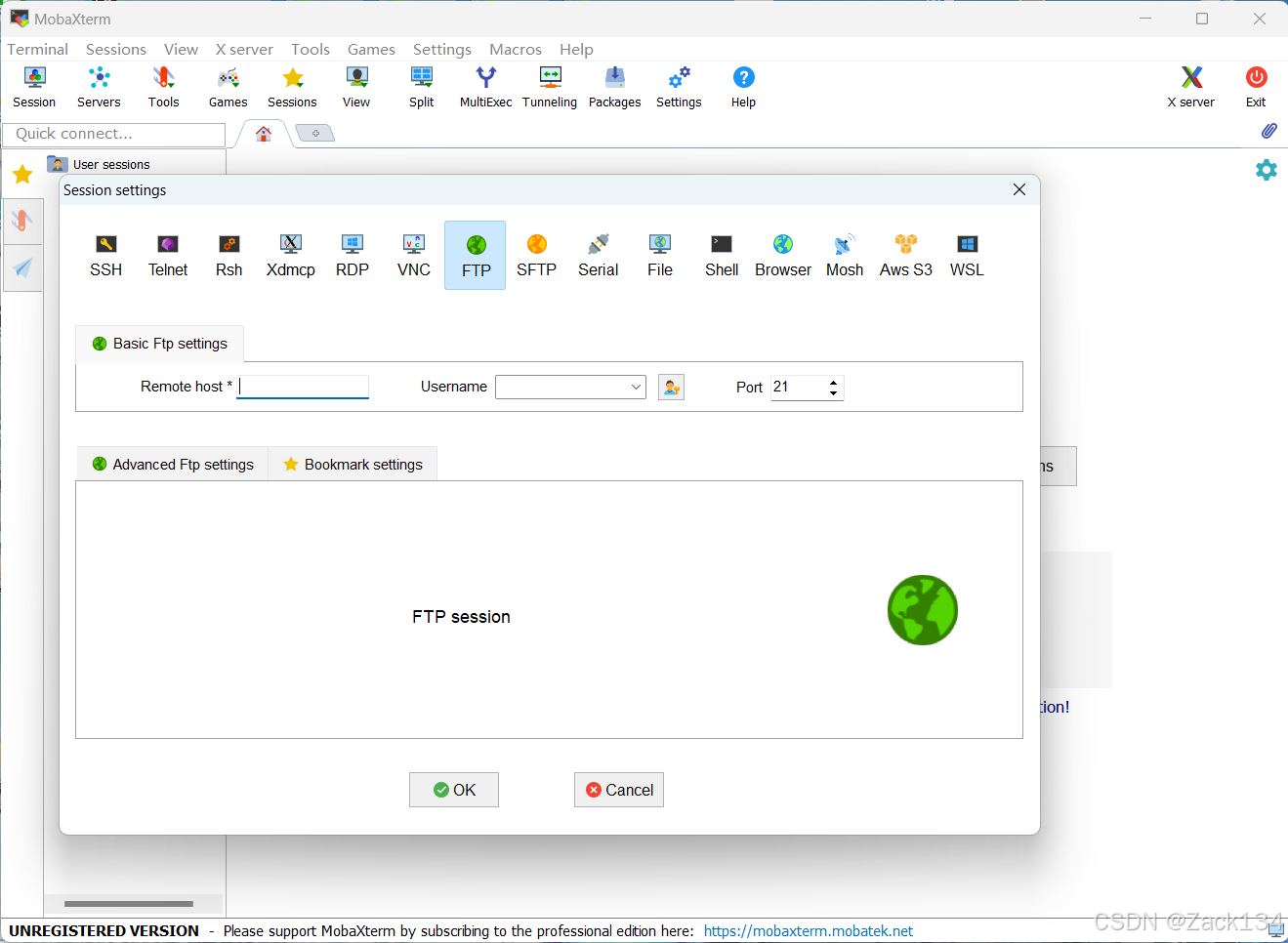
这里需要我们输入虚拟机的IP地址和用户名,这需要到Ubuntu查询,同前操作得到IP地址后填入,生成一个ftp,直接拖拽即可将文件(压缩包)传输
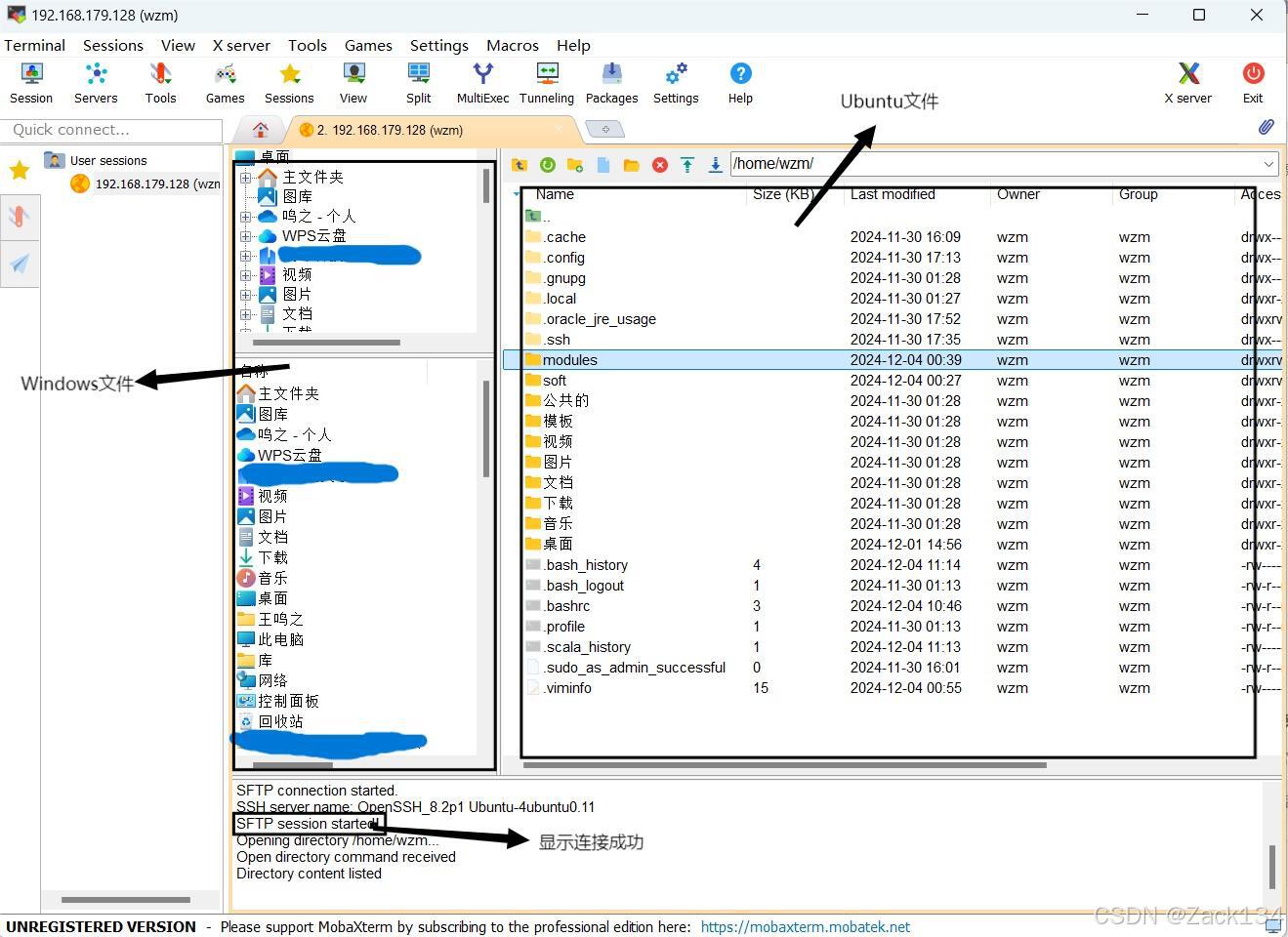
三、配置Java和Hadoop环境变量
1.下载压缩包
在Index of java-local/jdk/8u151-b12处下载jdk压缩包,此处我们选择jdk-8u151-linux-x64.tar.gz;
在apache-hadoop-common-hadoop-3.2.4安装包下载_开源镜像站-阿里云处下载hadoop压缩包,这里我选择了hadoop3的版本,可根需要选择,下载tar.gz文件;
下载好后通过ftp将其传至虚拟机。可以新建文件夹soft,将压缩包放入(直接拖拽即可)
2.解压缩
在终端soft目录下通过tar命令将压缩包解压至目的文件夹中(此处我新建了modules文件夹存放)
tar -zxf jdk-8u151-linux-x64.tar.gz -C ../modules解压后可进入modules通过ls命令查看是否存在该文件,
(为方便可用mv命令将文件名修改)
mv jdk1.8.0_151/ jdkhadoop压缩包解压同上:
tar -zxf hadoop-3.2.4.tar.gz -C ../modules3.配置环境变量
在主目录下使用vi命令进入.bashrc
vi .bashrc在该文件中添加以下内容
export JAVA_HOME=/home/wzm/modules/jdk
export PATH=$JAVA_HOME/bin:$PATH
export HADOOP_HOME=/home/wzm/modules/hadoop-3.2.4
export PATH=$HADOOP_HOME/bin:$PATH注意文件地址修改为本虚拟机所在位置(可直接进入文件夹中复制,粘贴即为文件地址)
修改好后使用source命令使其生效
source .bashrc以上完成后可通过检查版本验证是否成功:

可正常输出版本号即说明成功
四、搭建Hadoop集群
1.配置Hadoop单机
(1)文件配置
进入hadoop目录下的etc文件的hadoop文件夹中,执行ls命令可看到其所有文件,这里面我们需要修改4个文件:
(注:文件中所有文件地址均需要与自身虚拟机相对应)
①core-site.xml
使用vim core-site.xml进入编辑,添加以下内容:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hostname:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/wzm/modules/hadoop-3.2.4/tmp</value>
</property>
</configuration>其中hostname为本机节点名(终端中@后面的那个)
②hdfs-site.xml
使用vim hdfs-site.xml进入编辑,添加以下内容:
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/home/wzm/modules/hadoop-3.2.4/tmp/dfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/wzm/modules/hadoop-3.2.4/tmp/dfs/data</value>
</property>
</configuration>③yarn-site.xml
使用vim yarn-site.xml进入编辑,添加以下内容:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hostname</value>
</property>
</configuration><value>中的hostname为本机节点名
④mapred-site.xml
使用vim mapred-site.xml进入编辑,添加以下内容:
<configuration>
<property>
<name>mapreduce.map.memory.mb</name>
<value>2048</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>以上文件配置完成后进入到hadoop中的sbin文件夹下
./start-all.sh(2)启动服务进程
完成后输入jps检查是否有
secondaryNameNode、ResourceManager、DataNode、NodeManager、NameNode
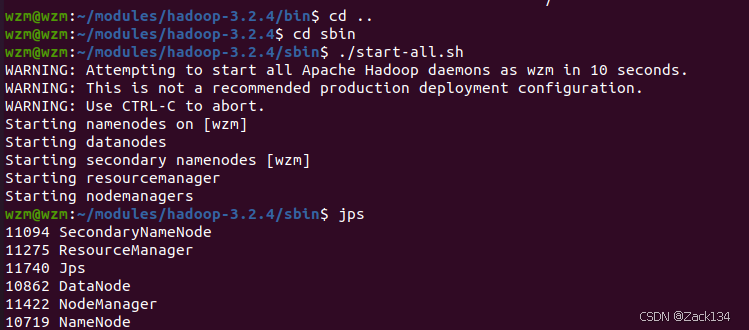
到此,Hadoop单机已配置完毕
2.完全分布式搭建
接下来要进行完全分布式的搭建
(1)克隆虚拟机
将虚拟机关机,克隆(如下图)得到两个从节点(原机为主节点)
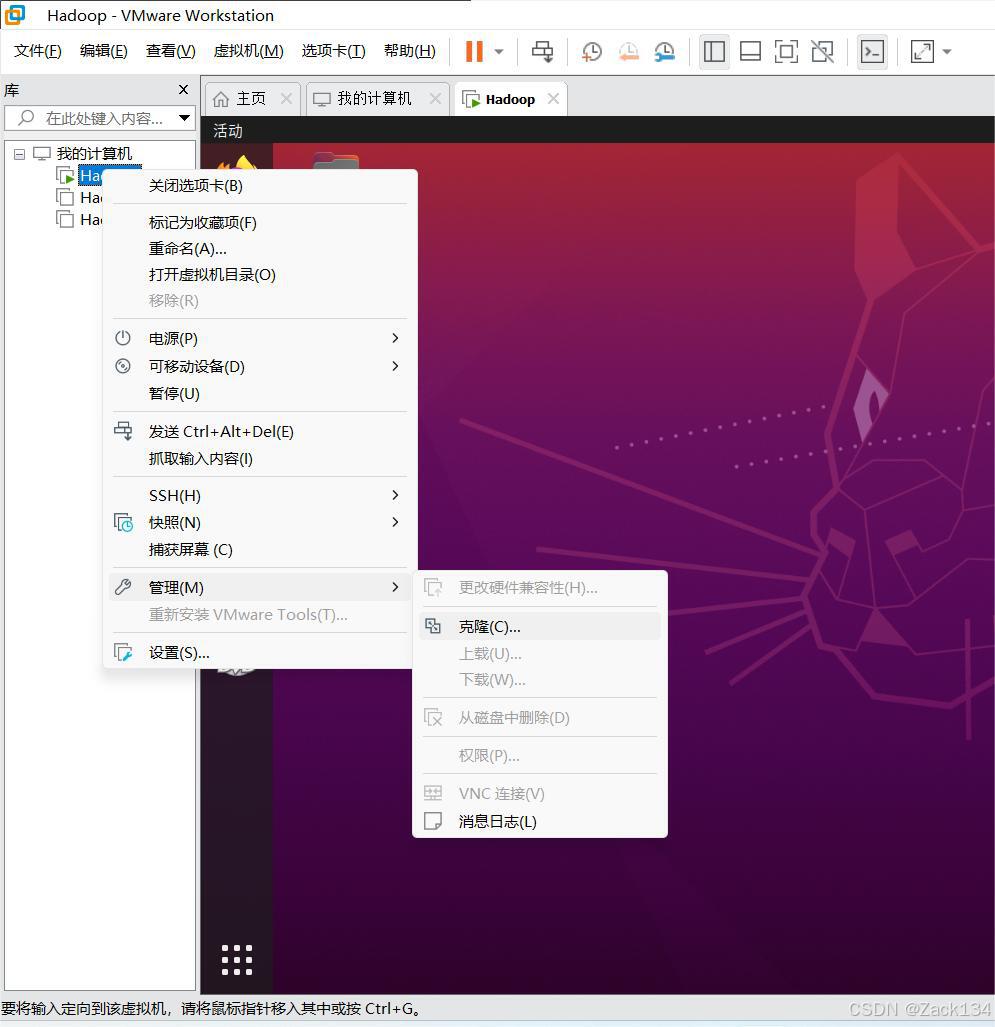
继续选择"下一步"即可,注意在克隆方法中要选择"创建完整克隆"。克隆完成后将原虚拟机和克隆的两台虚拟机(本篇中克隆了两台)开机,
(2)集群搭建
接下来要像第一台虚拟机一样修改克隆机的hostname(同前操作),并要将三台虚拟机的IP全部放到三台机器的hosts中,如下:
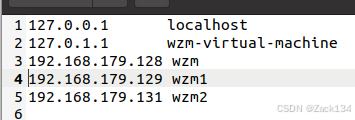
此外,还需在每个机器的hadoop/etc/hadoop目录下的workers中删掉原内容,将两台从节点的机器名写入
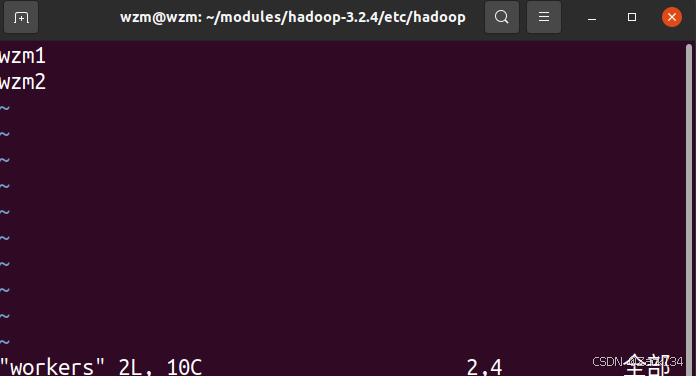
完成后,在hadoop目录下格式化namenode,输入:
hadoop namenode -format可进入tmp文件夹下的dfs中查看name文件内的current/检查
完成后要在机器中启动进程(同前sbin/start-all.sh),jps查看主节点上有至少四个进程,从节点上要有datanode、nodemanager。
可通过浏览器输入主节点IP地址:9870查看,若为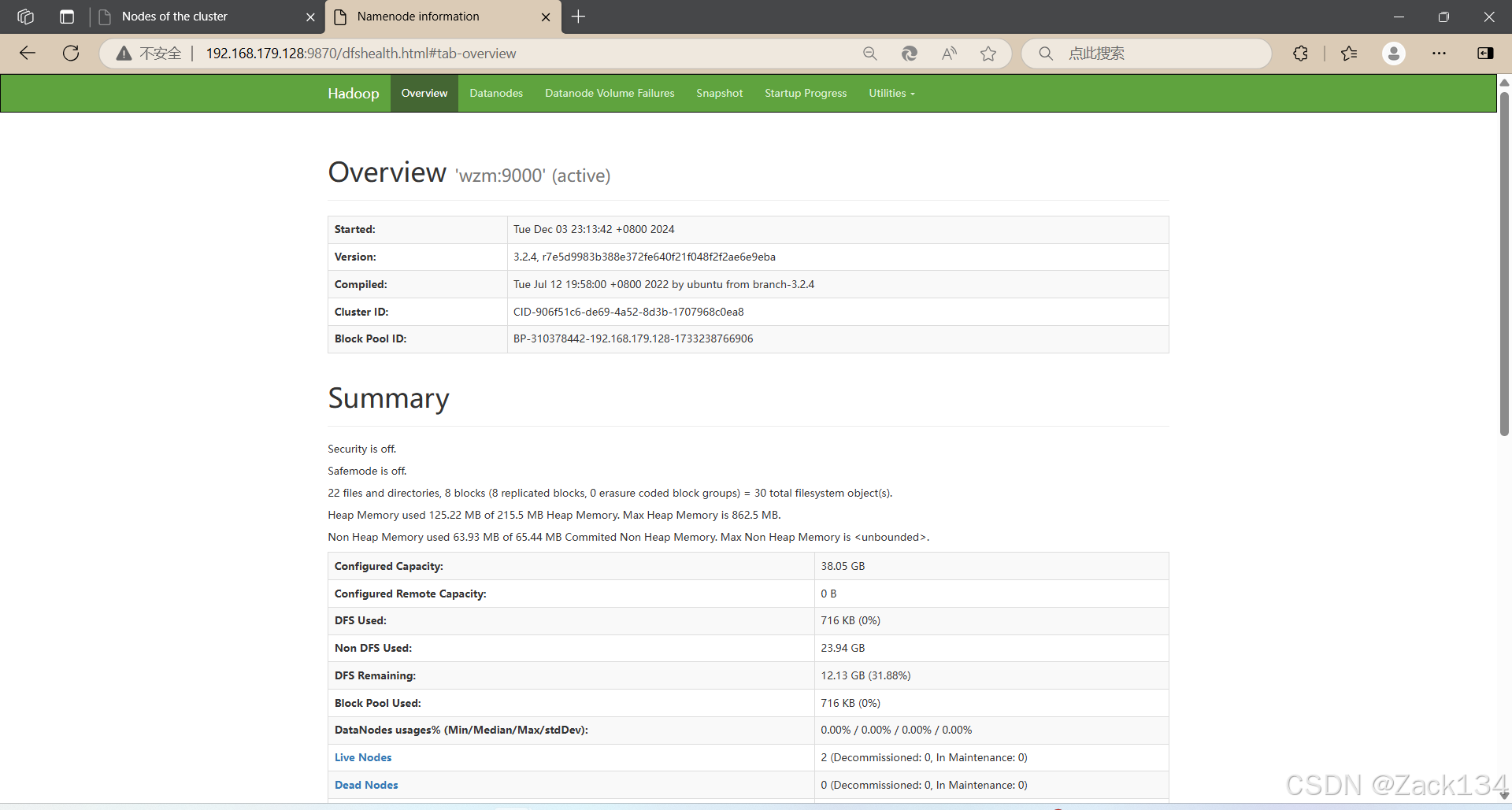 live nodes有2个节点,类似页面内容表示已部署完成。
live nodes有2个节点,类似页面内容表示已部署完成。
到此hadoop完全分布式集群搭建已完成。
(PS:若为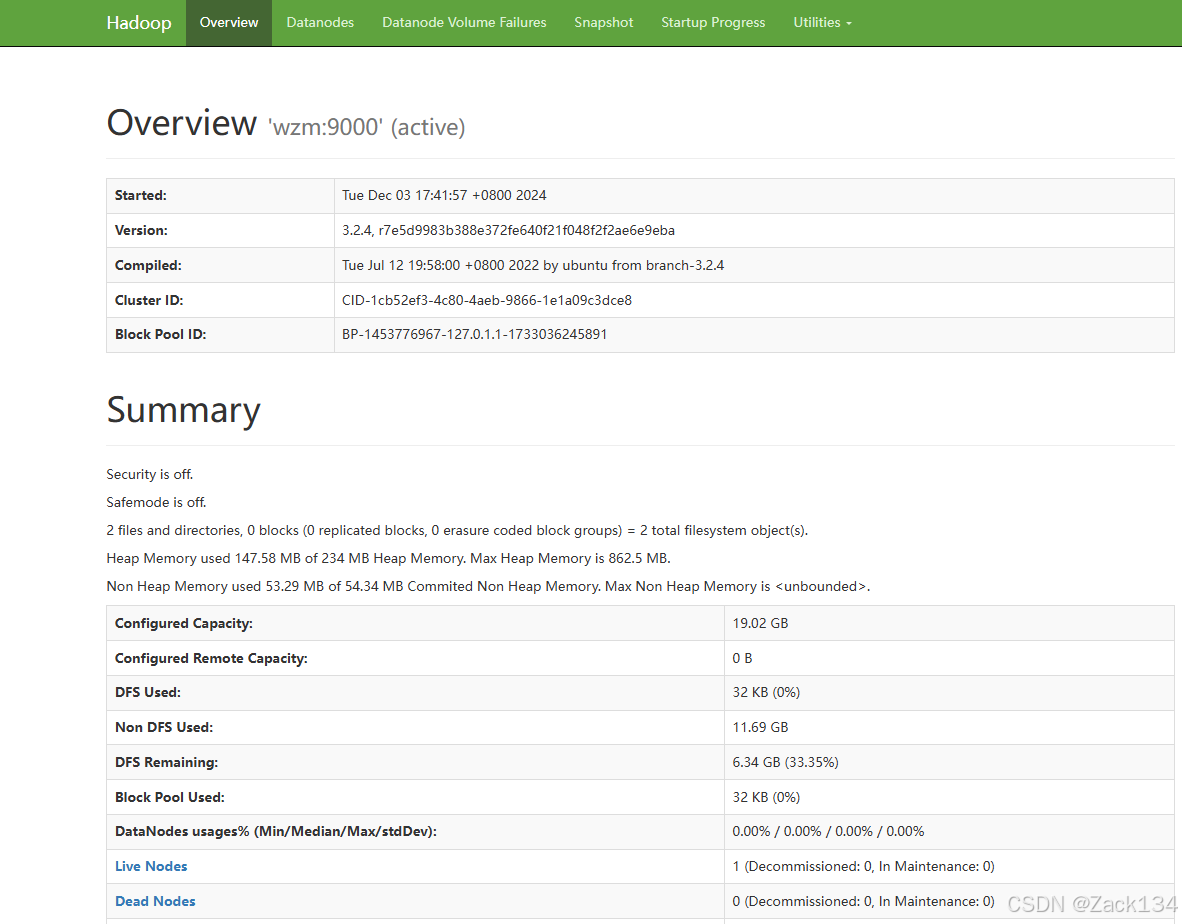 live nodes显示只有1个或直接没有,类似此页面,说明未搭建成功。)
live nodes显示只有1个或直接没有,类似此页面,说明未搭建成功。)
五、搭建Spark集群
1.解压,配置环境变量
在Index of /apache/spark处下载spark压缩包,这里以3.4.4为例(spark-3.4.4-bin-hadoop3.tgz),下载好后依然是通过ftp将其传至虚拟机 (传至主节点机,从节点机稍后会讲)
同前解压
tar -zxf spark-3.4.4-bin-hadoop3.tgz -C ../modules同前配置环境变量,在bashrc中添加以下内容
export SPARK_HOME=/home/wzm/modules/spark
export PATH=$SPARK_HOME/bin:$PATH(注意文件地址哦,再用source命令使其生效)
2.配置文件
在spark/conf下修改(创建)spark-env.sh
vim spark-env.sh在该文件中添加以下内容:
export JAVA_HOME=/home/wzm/modules/jdk
export HADOOP_HOME=/home/wzm/modules/hadoop-3.2.4
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_MASTER_IP=wzm
export MASTER=spark://<ip>:7077
export SPARK_LOCAL_DIRS=/home/wzm/modules/spark
export SPARK_DRIVER_MEMORY=512M注意文件路径
② workers(slaves)
在spark/conf下修改(创建)workers
vim workers删掉原来的localhost(如果有的话),在该文件中添加三台机器的主机名(主从节点都要有)
3.设置从节点机
由于在此之前我们已经将机器克隆,文件无法通过ftp传到从节点上(当然,也可以为克隆机创建新的ftp,但此处要讲另外的方法)。因此我们可以选择通过主节点传至从节点。
在modules目录下输入("wzn@wzm1"@前为用户名,@后为主机名,都改成自己机器的)
scp -r spark wzm@wzm1:/home/wzm/modules同样的方式发送到另一台从节点机上。
4.启动服务
同hadoop一样,我们要启动spark的进程,进入spark/sbin目录下
./start-all.sh并用jps检查是否有worker、master进程,若有说明启动成功
最后启动spark shell命令:
spark-shell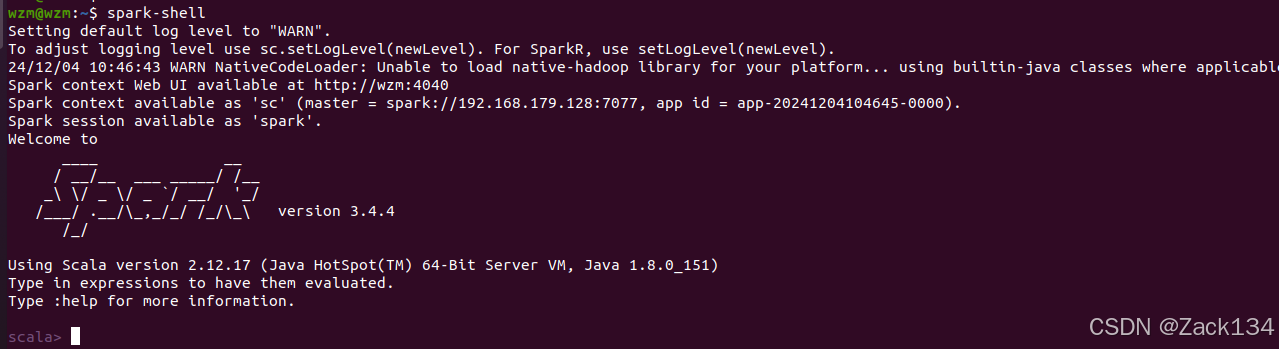
至此,Spark搭建完毕。
答疑------过程中可能遇到的问题
相关命令
cd xx文件地址 #进入该目录下
cd .. #返回上级目录
cd #返回主目录
ls #查看该目录下的文件
ll #查看该目录下的文件属性(本质是ls -l)
rm -r <文件夹路径> #删除文件夹命令
rm <文件路径> #删除文件命令
#两者区别在于删除文件夹还需递归删除其内所有文件,因此要加-rvi和vim是文本编辑器命令,用于编辑文本文件,偏向于使用vim,进入插入模式更加方便修改,使用前需通过sudo apt-get install vim下载但在修改.bashrc时只能使用vi命令。
主机名
修改主机名后可进入主目录下etc文件夹查看hostname是否已为修改好后的主机名,若否,直接在该文档中修改,然后重启系统。
防火墙
停用防火墙时可能会显示无防火墙服务,则无需再追究。
hadoop配置好后结果搭建未成功
首先检查一下配置及网络连接是否有问题,若确保无误仍未成功,再进行以下操作:
进入hadoop/tmp/dfs文件夹内查看是否有data文件夹,若有,将其删掉,再回到hadoop目录下将logs文件夹删掉,然后重新格式化namenode(所有虚拟机全部进行此操作)
以上操作完成后,回到浏览器检查是否配置成功。
(若进行此操作后仍未成功,则需考虑过程中其他的操作失误,如文件配置,hostname/hosts的修改,防火墙等)
以上为整个hadoop集群以及spark的搭建过程,后续会有案例更新,欢迎批评指正!