目录
前言
操作系统对计算机软件与硬件进行管理的方式是先描述再组织,而PCB就是那个"描述",那到底什么是PCB?PCB又在描述什么呢?更多Linux学习内容看准Linux专栏
1.1进程基本理解
在操作系统中,我们运行的一个个软件本质上都是程序。例如我们在windows上打开浏览器时,本质是运行一个.exe的可执行文件。当程序在计算机上动态运行时,操作系统为了方便管理程序的运行,会用一个叫进程控制块(Process Control Block)的数据结构存储管理程序运行时所需要的属性信息,再用链表将PCB存储起来,进而对进程进行管理,以此做到"先描述,再组织"。因此可以认为进程就是PCB数据结构+程序本身的代码和数据。
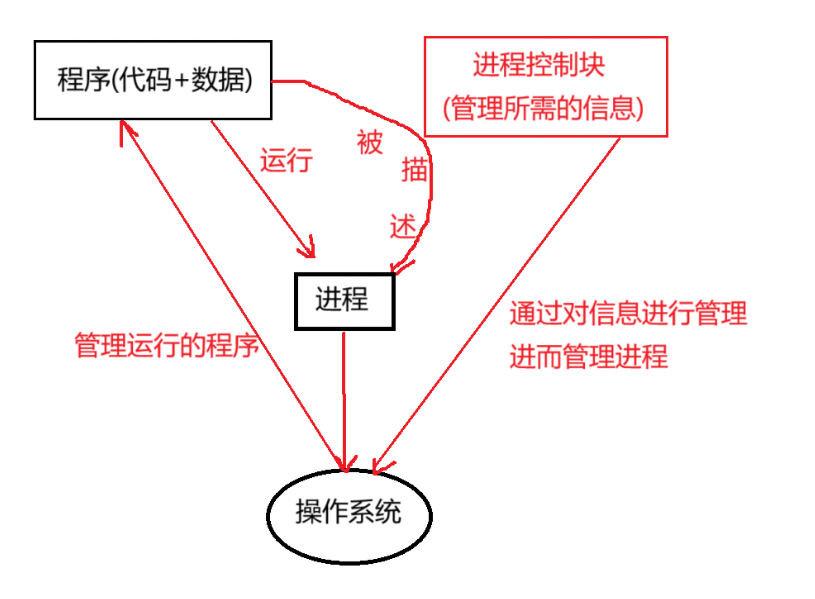
这里需要注意的是单一的程序不能被称为进程,当程序未被执行时本质还是普通文件中的一个数据。只有当程序被执行,加载到计算机内存中,操作系统能通过PCB对执行程序进行控制时,才能被称为进程。
1.2进程描述
对进程进行描述也就是记录进程信息是进程控制块(PCB),PCB数据结构中存储的信息就是进程的属性信息。在不同操作系统中对应的PCB数据结构会有不同,而在Linux中PCB数据结构对应的是task_struct结构体。
task_struct结构体本质是PCB的一种,是Linux内核中的一种数据结构,它会被加载到内存中并且包含Linux操作系统中进程的信息。
task_struct基本内容简介
• 标示符(Process Identifier):描述本进程的唯⼀标示符,⽤来区别其他进程。
• 状态: 任务状态,退出代码,退出信号等。
• 优先级: 相对于其他进程的优先级。
• 程序计数器: 程序中即将被执⾏的下⼀条指令的地址。
• 内存指针: 包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针
• 上下⽂数据: 进程执⾏时处理器的寄存器中的数据。
• I/O状态信息: 包括显示的I/O请求,分配给进程的I/O设备和被进程使⽤的⽂件列表。
• 记账信息: 可能包括处理器时间总和,使⽤的时钟数总和,时间限制,记账号等。
• 其他信息
• 具体详细信息后续会介绍
进程标示符与进程状态在后文会详细展开,下面简单介绍后面内容。
优先级:进程在运行时需要操作系统对其分配硬件资源(内存,CPU等),进程优先级就代表了分配资源的优先级。优先级主要涉及后续进程调度部分。
程序计数器:程序计数器本质是一个寄存器,用来指示程序下一步应该执行哪里。简单举例来说,若一个程序有500行,程序计数器记录程序已经执行到哪一行,进而计算机通过程序计数器来判断下一步程序应该执行哪一行。后面主要与进程切换有关。
内存指针:储存程序运行时的地址,方便操作系统对程序进行管理。
记账信息:类似于表示进程已经调度的时间。
后续更深入的内容会在各部分单独讲解。
1.3查看进程
在查看进程之前,我们需要获取到我们想要查看的那个进程的标识符(pid),pid作为描述进程的唯一标识符,用来区分其他进程。在获取到pid之后,我们可以查看在/proc文件夹下对应pid进程的进程信息。例如我们要查看pid为1的进程信息:
bash
ls /porc/1
当然我们也可以查看/proc文件夹下所有的进程信息(所有正在运行的程序)
bash
ls /proc/
1.4通过系统调用的基本进程操作
1.4.1通过系统调用获取pid
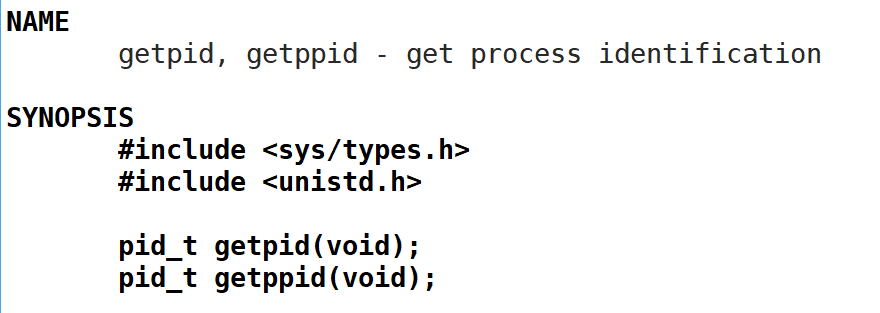
系统调用简而言之就是操作系统内置的库函数,最基本的,我们可以通过系统调用来获取进程的pid。Linux获取pid的库函数是getpid,可以通过man手册来查看其api。
bash
man getpid
可以看到getpid的返回类型为pid_t,不需要参数。这时通过自己编写程序来验证getpid是否真的能获取到pid:
cpp
#include<stdio.h>
#include<sys/types.h>
#include<unistd.h>
int main()
{
while(1)
{
pid_t pid = getpid();
printf("this is a process and pid is : %d\n", pid);
pid_t ppid = getppid();
printf("this is a process and ppid is : %d\n", ppid);
sleep(1);
//fflush(stdout);
}
return 0;
}这里通过死循环让程序一直保持运行状态,即进程运行状态,随后打印该进程的pid。来看看运行结果
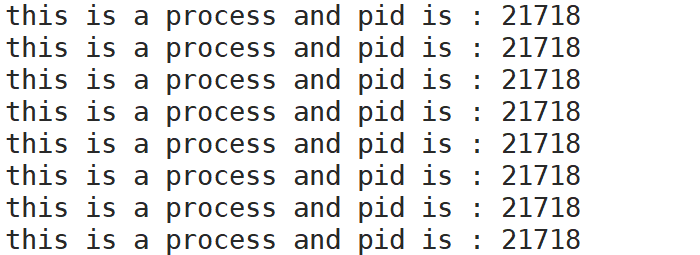
可以看到该程序进程的pid是21718,随后再看看程序运行过程中用proc了查看该进程信息
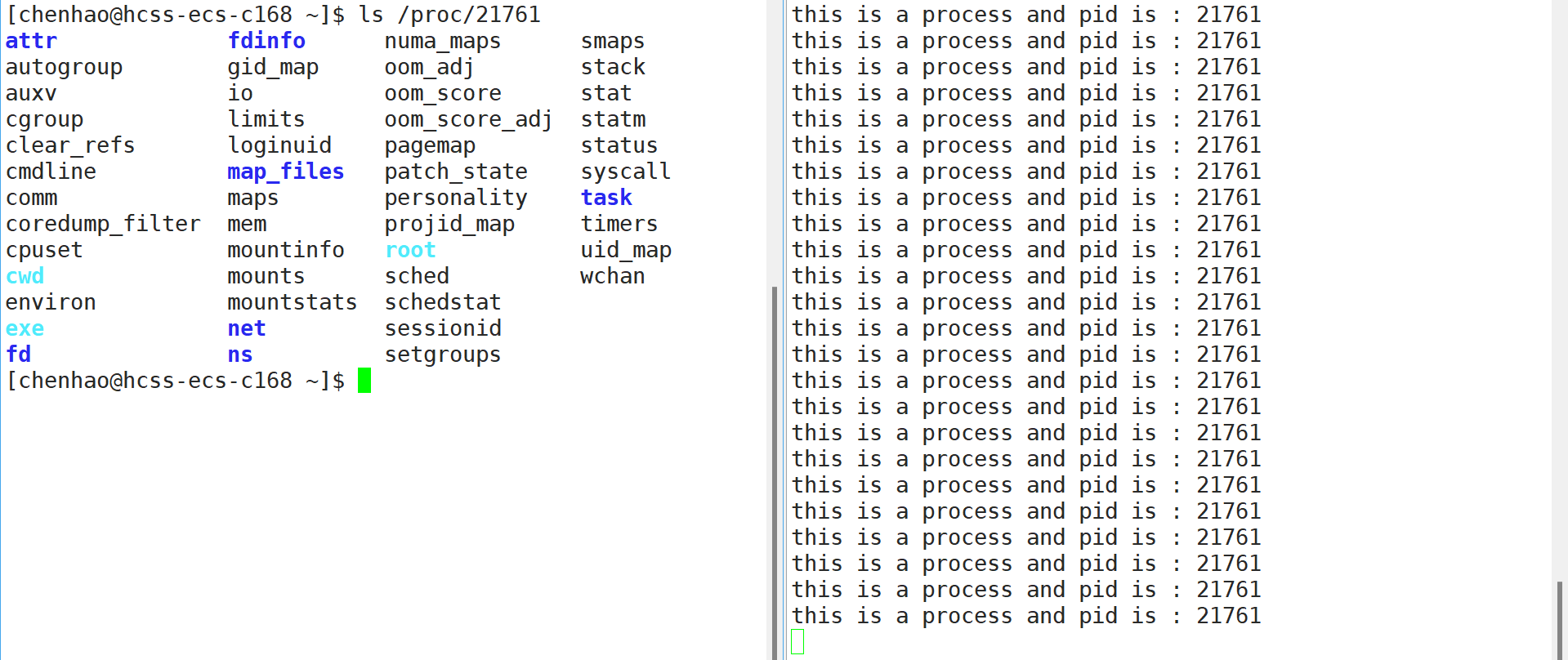
可以看到这时是可以查看到的,那如果停止程序运行呢?
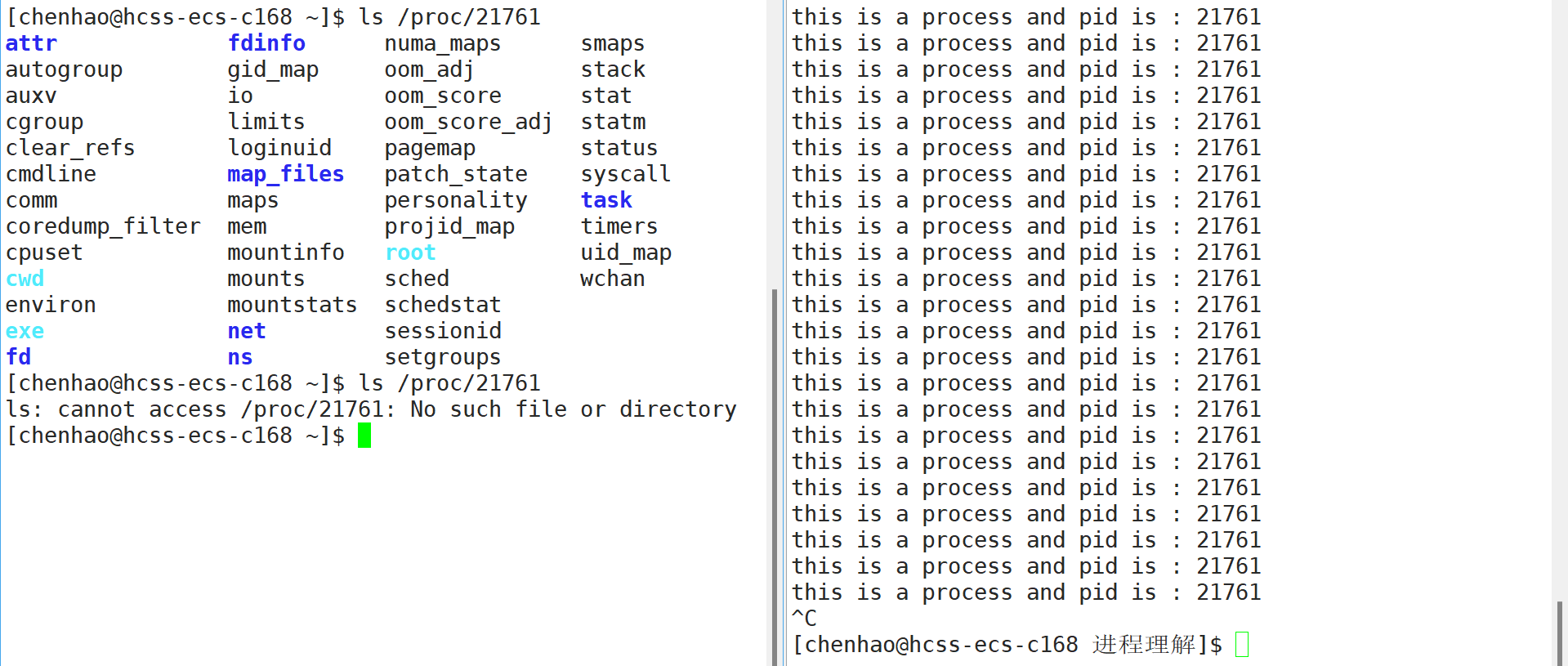
可以看到程序停止运行之后该pid进程就没有了,说明getpid获取的就是当前程序的pid。
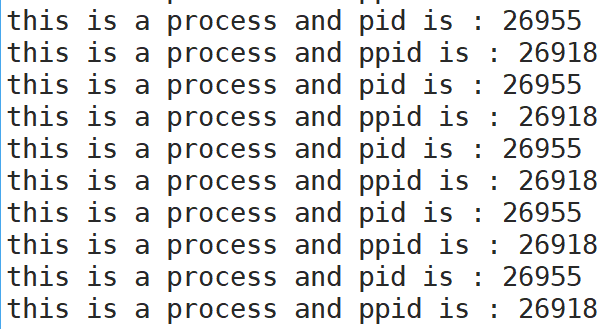
而当我们用man手册了查询pid时,可以看到还有一个叫getppid的函数。ppid同样也是task_strcut结构体中储存的信息之一,ppid代表父进程的pid,也就是当前程序父进程的标识符。
pid与ppid的用法类似:
cpp
#include<stdio.h>
#include<sys/types.h>
#include<unistd.h>
int main()
{
while(1)
{
pid_t pid = getpid();
printf("this is a process and pid is : %d\n", pid);
pid_t ppid = getppid();
printf("this is a process and ppid is : %d\n", ppid);
sleep(1);
//fflush(stdout);
}
return 0;
}
1.4.2通过系统调用创建进程
此时可以看到该进程的父进程pid就是26918,那到底什么是父进程呢?
我们先来看看pid为26918的进程是什么:利用ps -p <PID> -o comm命令可以查看该pid进程在系统中的命名
bash
ps -p 26918 -o comm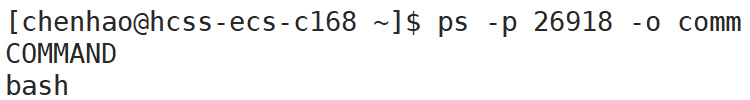
可以看到pid为26918的进程在系统中叫作bash,bash在Linux系统中就是我们看见的命令行提示器,就是Linux系统的shell外壳。也就是说我们自己程序创建的进程的父进程就是bash,当我们在bash中运行程序编译好的可执行文件时,同时也创建了新的进程,我们自己程序的进程就成为了bash的子进程。
所以当一个进程在运行过程中创建了一个新的进程时,这个新进程就是原进程的子进程,原进程就是新进程的父进程。那在Linux中如何创建进程呢?
创建进程属于系统层面的操作,因此需要系统调用。在Linux中创建子进程的系统调用函数为fork:
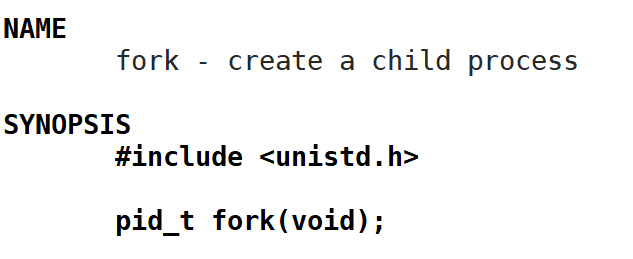
先不管其他的,我们先来创建一个子进程看一看:
cpp
#include<stdio.h>
#include<sys/types.h>
#include<unistd.h>
int main()
{
pid_t pid1 = getpid();
printf("原pid为%d\n", pid1);
fork();
pid_t pid2 = getpid();
pid_t ppid = getppid();
while(1)
{
printf("这个进程的pid为:%d,ppid为:%d\n", pid2, ppid);
sleep(2);
}
return 0;
}运行结果:
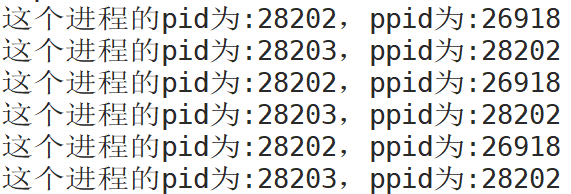
可以看到这里就是创建子进程成功了,再进一步了解fork:

这里for返回的是pid_t类型,但如果创建子进程成功父进程就是返回子进程的pid,而子进程则返回0;若失败则返回-1。先来验证下正确性:
cpp
#include<stdio.h>
#include<sys/types.h>
#include<unistd.h>
int main()
{
pid_t pid1 = getpid();
printf("原pid为%d\n", pid1);
pid_t id = fork();
while(1)
{
if(id == -1)
{
perror("fork faild!");
break;
}
else
{
if(id == 0)
{
printf("这是子进程,pid:%d\n", getpid());
}
else
{
printf("这是父进程,pid:%d\n", getpid());
}
}
sleep(1);
}
return 0;
}运行结果:

可以看到确实是这样的,那么这样fork就衍生出三个问题:
fork三问题
1.为什么给子进程返回的是0,给父进程返回的是子进程的id?
2.为什么fork作为一个函数能返回两个值?
3.为什么id仅仅一个变量,能接收两个值?
对于问题1:在更为复杂的系统工程项目中,有时需要创建多个子进程,为了方便对个子进程进行管理,因此父进程需要得到创建的子进程的id;而每个子进程只会有一个父亲,因此只需要一个0。
对于问题2:函数在进行返回时,基本功能已经完成。对应fork函数,在return之前子进程已经创建,因此return实际返回的不是两个值,而是在两个进程中个返回的一个值。
对于问题3:主要涉及虚拟内存部分的写时拷贝,更深入内容在后续讲解。