清华源
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple ***#要安装的name删除下载到本地的安装包
pip cache purge
C:\Users\16385\AppData\Local\Programs\Python\Python311\Lib\site-packages分词:有jieba分词(处理中文)和nltk(处理英文)
1、nltk
1)word_tokenize
word_tokenize 是一个用于将句子分割成单词(或标记,tokens)的函数,称为分词(tokenization)。分词的目的是将一段文本切分成更小的、可操作的单元,如单词或标点符号。
python
import nltk
from nltk.tokenize import word_tokenize
# 下载必要的NLTK资源
nltk.download('punkt')
text = "Hello, world! This is a test sentence."
tokens = word_tokenize(text)
print(tokens)
#结果
['Hello', ',', 'world', '!', 'This', 'is', 'a', 'test', 'sentence', '.']2、scikit-learn(sklearn)
1)TF-IDF
核心思想是:如果一个词在一篇文档中频繁出现但在其他文档中很少出现,这个词可能具有很强的区分性。
TF-IDF 是由两部分组成的:词频(Term Frequency, TF)和逆文档频率(Inverse Document Frequency, IDF)。
- 词频(TF)
词频表示一个词在一个文档中出现的频率。

- 逆文档频率(IDF)
逆文档频率衡量一个词在整个文档集合中出现的稀有程度。

- TF-IDF
TF-IDF 是 TF 和 IDF 的乘积:
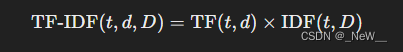
3、gensim
1)Word2Vec
定义
思想:能够将词汇映射到连续向量空间,使得语义相似的词在向量空间中距离较近。
Word2Vec 通过两个主要模型来学习词向量:


训练词向量模型
python
model = gensim.models.Word2Vec (documents, vector_size=150, window=10, min_count=2, workers=10)- vector_size=150: 这是词向量的维度。每个词将被表示为一个150维的向量。较高的维度通常能够捕捉到更多的语义信息,但也需要更多的计算资源。
**vector_size=150,**即每个单词将被表示为一个150维的向量。这意味着每个单词都由150个实数值组成,这些实数值代表了单词在高维空间中的位置。
这些元素本身并没有直接的可解释性,但它们的组合表示了单词的语义特征。
Word2Vec模型通过训练大量的文本数据来生成词向量(上述的词向量是通过给的文件训练得到的,如果不是特殊领域的,可以直接调用已经训练好的开源库)。在训练 过程中,模型会调整向量的值,使得相似的单词在向量空间中的距离更近 。相似性通常通过余弦相似度来衡量。
-
window=10: 这是上下文窗口的大小。Word2Vec算法在训练时会考虑一个词前后10个词的上下文。窗口越大,模型捕捉到的上下文信息越多,但计算复杂度也会增加。
-
min_count=2: 这是忽略词频小于2次的词。即在训练过程中,只考虑出现频率至少为2次的词,稀有词将被忽略。这有助于减少噪音,提升模型的性能。
-
workers=10: 这是并行训练时使用的CPU核心数。Gensim的Word2Vec实现支持多线程训练,以加速训练过程。这里指定了使用10个CPU核心。
python
model.train(documents, total_examples=len(documents), epochs=10)对模型进行进一步的训练或重新训练
epochs=10:
- 这是训练过程中迭代整个语料库的次数。在这个例子中,模型将遍历整个文档集10次。
- 更多的epoch通常会使模型学到更多的特征,但过多的epoch也可能导致过拟合,尤其是在较小的数据集上。
Word2Vec的使用场景
Word2Vec有很多应用场景。想象一下,如果你需要构建一个情感词典,通过在大量用户评论上训练Word2Vec模型可以帮助你实现这一点。你不仅可以获得情感词典,还可以获得词汇表中大多数单词的词典。
除了原始的非结构化文本数据,你还可以将Word2Vec用于更结构化的数据。例如,如果你有一百万个Stack Overflow问题和答案的标签,你可以找到与给定标签相关的标签,并推荐相关标签供探索。你可以通过将每组共现标签视为一个"句子"并在这些数据上训练Word2Vec模型来实现这一点。当然,你仍然需要大量的示例数据才能使其发挥作用。
4、其他
1)logging
python
import logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)logging.basicConfig() : 这是一个方便的方法,用于一次性配置logging模块的基本设置,如日志格式、日志级别等。
%(asctime)s: 日志记录的时间,格式为ISO 8601格式(默认情况)。%(levelname)s: 日志级别名(如INFO, DEBUG, WARNING等)。%(message)s: 实际的日志消息内容。
level : 这是一个整数或日志级别名,设置日志记录的最低级别。只有级别等于或高于该级别的日志消息才会被记录。logging.INFO表示设置日志级别为INFO,即INFO及以上级别(如WARNING, ERROR, CRITICAL)的消息都会被记录。(INFO:常规信息,表示正常运行的消息。)
日志级别:DEBUG,INFO,WARNING, ERROR, CRITICAL
2)打开文件操作
python
with gzip.open('reviews_data.txt.gz', 'rb') as f:with : 这是一个上下文管理器(context manager),用于确保在代码块执行完毕后,文件能够被正确地关闭。使用with语句可以避免手动调用f.close(),即使在代码块中发生异常,文件也会被安全关闭。
gzip.open(): 这个函数用于打开一个gzip压缩文件,并返回一个文件对象,可以像普通文件一样进行读取或写入操作。
'r'表示读模式(read)。'b'表示二进制模式(binary),这意味着文件将以二进制模式打开。gzip文件通常是二进制文件,因此需要使用'rb'模式。
3)余弦相似度
余弦相似度(Cosine Similarity)是一种常用的度量两个向量之间相似度的方法。它通过计算两个向量之间的夹角余弦值来衡量它们的相似程度。值越接近1,表示两个向量越相似;值越接近-1,表示两个向量越不相似。


