文章目录
- [1. 基本概念](#1. 基本概念)
- [2. 知识(Knowledge)](#2. 知识(Knowledge))
-
- [2.1 Response-based](#2.1 Response-based)
- [2.2 Feature-based](#2.2 Feature-based)
- [2.3 Relation-based](#2.3 Relation-based)
- [2.4 Architecture-based](#2.4 Architecture-based)
- [3. 蒸馏算法](#3. 蒸馏算法)
-
- [3.1 offline distillation](#3.1 offline distillation)
- [3.2 online distillation](#3.2 online distillation)
- [3.3 self-distillation](#3.3 self-distillation)
- [4. 师生架构(Teacher-student architecture)](#4. 师生架构(Teacher-student architecture))
- [5. 蒸馏损失函数](#5. 蒸馏损失函数)
- [6. 知识蒸馏 vs. 传统神经网络](#6. 知识蒸馏 vs. 传统神经网络)
- 参考资料
1. 基本概念
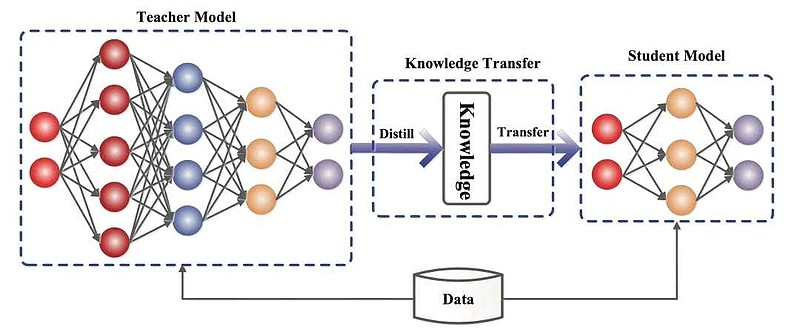
知识蒸馏是一种机器学习技术,目的是将预先训练好的大型模型(即 "教师模型")的学习成果转移到较小的 "学生模型"中。
知识蒸馏的概念最早由Hinton等人提出,论文:Distilling the Knowledge in a Neural Network
作者提出了一种称为知识蒸馏的策略,它学习的是教师模型(结构较为复杂的模型)的输出分布(logits),这种分布信息比原始的(0-1)label具有更加丰富的信息,能够让学生模型(架构较为简单的模型)取得更好的效果。
在深度学习中,它被用作模型压缩和知识转移的一种形式,尤其适用于大规模深度神经网络。知识蒸馏的本质是知识迁移,模仿教师模型的输出分布,使学生模型继承其泛化能力与推理逻辑。
知识蒸馏算法由三部分组成,分别是:
- 知识(Knowledge)
- 蒸馏算法(Distillation algorithm)
- 师生架构(Teacher-student architecture)
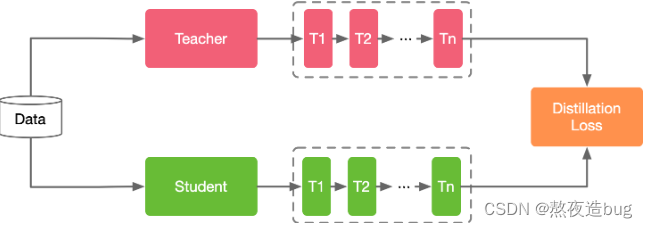
一般的师生架构如下图所示:
2. 知识(Knowledge)
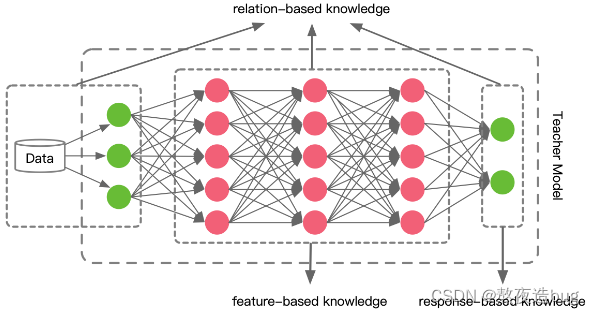
知识的类型可以分为四类,主要有 Response-based、Feature-based、Relation-based 三种,而 Architecture-based 类型很少。
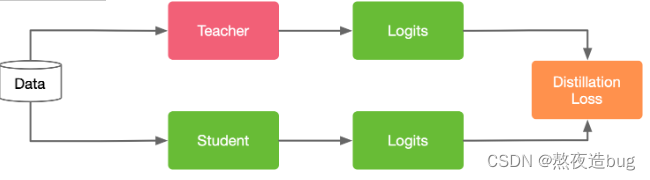
2.1 Response-based
当知识蒸馏对这部分知识进行转移时,学生模型直接学习教师模型输出层的特征。通俗的说法就是老师充分学习知识后,直接将结论告诉学生。
2.2 Feature-based
上面一种方法学习目标非常直接,学生模型直接学习教师模型的最后预测结果。考虑到深度神经网络善于学习不同层级的特征,教师模型的中间层的特征激活也可以作为学生模型的学习目标,对 Response-based knowledge 形成补充。下面是 Feature-based knowledge 的知识迁移过程。
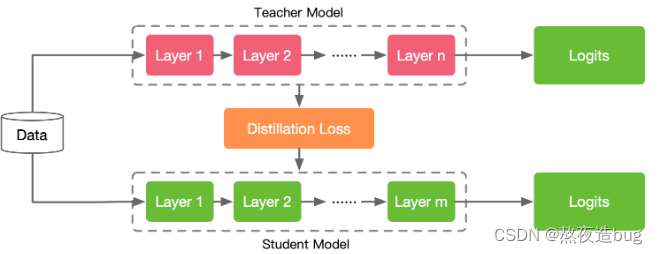
虽然基于特征的知识转移为学生模型的学习提供了更多信息,但由于学生模型和教师模型的结构不一定相同,如何从教师模型中选择哪一层特征激活(提示层),从学生模型中选择哪一层(引导层)模仿教师模型的特征激活,是一个需要探究的问题。另外,当提示层和引导层大小存在差异时,如何正确匹配教师与学生的特征表示也需要进一步探究,目前还没有成熟的方案。
2.3 Relation-based
上述两种方法都使用了教师模型中特定网络层中特征的输出,而基于关系的知识进一步探索了各网络层输出之间的关系或样本之间的关系。例如将教师模型中两层 feature maps 之间的 Gram 矩阵(网络层输出之间的关系)作为知识,或者将样本在教师模型上的特征表示的概率分布(样本之间的关系)作为知识。
2.4 Architecture-based
3. 蒸馏算法
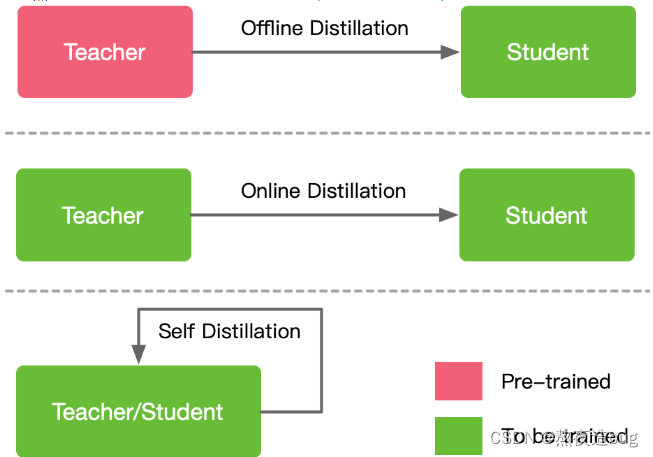
知识蒸馏的方式一般分为三种:offline distillation;online distillation;self-distillation。
3.1 offline distillation
这种方法是大部分知识蒸馏算法采用的方法,主要包含两个过程:
1)蒸馏前教师模型预训练;
2)蒸馏算法迁移知识。
因此该方法主要侧重于知识迁移部分。教师模型通常参数量大,训练时间比较长,一些大模型会通过这种方式得到小模型,比如 BERT 通过蒸馏学习得到 tinyBERT。但这种方法的缺点是学生模型非常依赖教师模型。
3.2 online distillation
这种方法要求教师模型和学生模型同时更新,主要针对参数量大、精度性能好的教师模型不可获得情况。而现有的方法往往难以获得在线环境下参数量大、精度性能好的教师模型。
3.3 self-distillation
是 online distillation 的一种特例,教师模型和学生模型采用相同的网络模型。
总结:用学习过程比喻,
- offline distillation 是知识渊博的老师向学生传授知识;
- online distillation 是老师和学生一起学习、共同进步;
- self-distillation 是学生自学成才。
4. 师生架构(Teacher-student architecture)
师生架构中主要包含有教师模型(Teacher Model)和学生模型( Student Model):
-
教师模型(Teacher Model):通常为参数量大、训练充分的复杂模型(如DeepSeek-R1),其输出不仅包含预测结果,还隐含类别间的相似性信息。
-
学生模型( Student Model):结构精简、参数较少的小型模型,通过匹配教师模型的"软目标"(Soft Targets)实现能力迁移。
通常,教师网络会比学生网络大,通过知识蒸馏的方法将教师网络的知识转移到学生网络,因此,蒸馏学习可以用于压缩模型,将大模型变成小模型。另外,知识蒸馏的过程需要数据集,这个数据集可以是用于教师模型预训练的数据集,也可以是额外的数据集。
5. 蒸馏损失函数
学生模型在训练时有两个损失函数:
- 一个是学生模型输出的类别概率与真实label的交叉熵
- 另一个是学生模型输出的类别概率与教师模型输出的类别概率的交叉熵(更多是KL散度)。
(1)总损失函数公式如下:
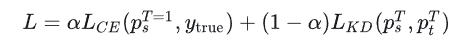
其中, L C E L_{CE} LCE 是学生模型与真实标签之间的交叉熵损失; L K D L_{KD} LKD 是学生模型与教师模型软目标之间的蒸馏损失; α \alpha α 是权重参数,平衡两部分损失的影响。
(2)交叉熵损失 L C E L_{CE} LCE:
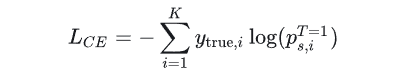
其中, y t r u e , i y_{true,i} ytrue,i 是样本属于第 i i i 个类别的one-hot标签,取0或1。
(3)蒸馏损失 L K D L_{KD} LKD:
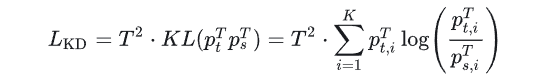
其中, K L KL KL 表示Kullback-Leibler散度,表示 使用学生网络的概率分布 P s T {P}^T_s PsT 近似教师网络 P t T {P}^T_t PtT 的软标签时所造成的信息损失 ,KL散度值越大,表示 P s T {P}^T_s PsT 对 P t T {P}^T_t PtT 的近似较差,反之亦然。
乘以 T 2 T^2 T2 是为了在反向传播时保持梯度的尺度一致性,具体来说,由于softmax函数的导数会引入 1 / T 1/T 1/T ,故损失函数对logits的梯度会包含 1 / T 1/T 1/T 这一项。换句话说,可以抵消梯度中的 1 / T 1/T 1/T 项,确保梯度的大小不受温度参数的影响。
关于知识蒸馏的更为详细的公式推导,可以参考博客:知识蒸馏(Knowledge Distillation)
6. 知识蒸馏 vs. 传统神经网络
1. 知识蒸馏和传统神经网络的学习目标不同
- 传统深度学习的目标是训练人工神经网络,使其预测结果更接近训练数据集中提供的输出示例。
- 而知识蒸馏与传统监督学习不同,知识蒸馏要求学生模型不仅拟合正确答案(硬目标),还让学生模型学习教师模型的"思考逻辑"------即输出的概率分布(软目标) 。
例如在图像分类任务中,教师模型不仅会指出"这张图是猫"(90%置信度),还会给出"像狐狸"(5%)、"其他动物"(5%)等可能性。
这些概率值如同老师批改试卷时标注的"易错点",学生模型通过捕捉其中的关联性(如猫与狐狸的尖耳、毛发特征相似),最终学会更灵活的判别能力,而非机械记忆标准答案。
2. 传统深度学习的问题
传统的深度学习方法在训练和部署阶段使用相同的模型。然而,训练阶段和部署阶段的需求往往是不同的。训练阶段可能更注重模型的准确性和表达能力,因此通常会使用大规模、复杂的模型来学习数据中的复杂模式和特征;而部署阶段则可能更关注模型的效率,如推理速度、内存占用等,以便在实际应用中能够快速、低成本地运行。
3. 知识蒸馏的意义
通过知识蒸馏,可以将训练阶段复杂模型(教师模型)中学习到的知识 "蒸馏" 到一个更简单、更高效的模型(学生模型)中。这样,学生模型可以在部署阶段满足效率要求,同时保留教师模型的大部分性能,实现了在不同阶段使用不同 "形态" 的模型来适应各自的需求。